
В первой части статьи мы провели сравнительный анализ средств нагрузки на Java для JMeter, ушли от XML тест-планов и достигли 30K RPS с одной машины, нагружая «не-HTTP» сервис на примере Apache Thrift.
В этой статье рассмотрим еще один инструмент для нагрузочного тестирования — Gatling и, как и обещали ранее, постараемся увеличить его производительность в десятки раз.

Gatling — это opensource-инструмент для создания нагрузочных скриптов на Scala. Его легко можно подключить в свой проект любимым средством сборки. Под капотом там крутится модель акторов Akka, известная своей отменной производительностью.
Прежде чем окунуться глубже в написание нагрузочного скрипта для «не-HTTP» протокола, разберем простейший пример для HTTP:
В протокол-билдере укажем адрес. В билдере сценариев опишем имя сценария, имя конкретного запроса и HTTP-метод. В блоке настройки нагрузочного профиля добавим сценарий нагрузки и определим протокол. Более подробно информация изложена в документации.
Это было небольшое отступление — все-таки мы собирались тестировать «не-HTTP». Как и в случае с JMeter, мы все еще хотим иметь легко модифицируемый плагин, на каркасе которого возможно нагружать различные протоколы, заменяя лишь клиент. Поэтому стандартные расширения нам не подходят.
За основу был взят довольно древний, но понятный код из Github. Он уже конфликтовал с текущей версией Gatling (2.3.1), но работал со старой. Главное же его достоинство было в работе с акторами.
Простой переезд на новую версию омрачили поломка обратной совместимости разработчиками Gatling у минорных версий и глобальный рефакторинг внутренностей. В частности вот этот коммит избавляется от акторов там, где это не особо нужно:

О том, что такое актор и модель акторов, написана огромная непонятная статья в Википедии и чуть более понятная выдержка из статьи на Хабре:

Заказчик ремонта (мы с вами) просит у строительной компании отремонтировать ему несколько комнат. Прораб управляет очередью и загрузкой строителя, следит, чтобы он не перетруждался и не простаивал. Мы же напрямую не общаемся со строителем, а работаем с его представителем (компанией). Зная, как у нас медленно строят, мы отдаем задачу и даже не надеемся на ее быстрое исполнение (не ждем результата, а идем заниматься своими делами).
По аналогии с HTTP-примером и взяв за основу старый скрипт для описания кастомного протокола, напишем свой билдер. Он принимает некое действие клиента для нагрузки и работает с акторами:
Обработчик результатов прогона не входит в стандартную реализацию нагрузочных скриптов. Код из старого примера больше не работал, поэтому после миграции пришлось немного порыться в исходниках Gatling, изучая реализацию HTTP:
Клиента для Thrift мы уже написали в первой части статьи. Машину, с которой будем грузить — настроили. Микросервис тоже остался прежним и держит 50K RPS.
Пора грузить. Попробуем пристреляться линейно возрастающей нагрузкой с 1 до 2K RPS в течение 60 секунд:
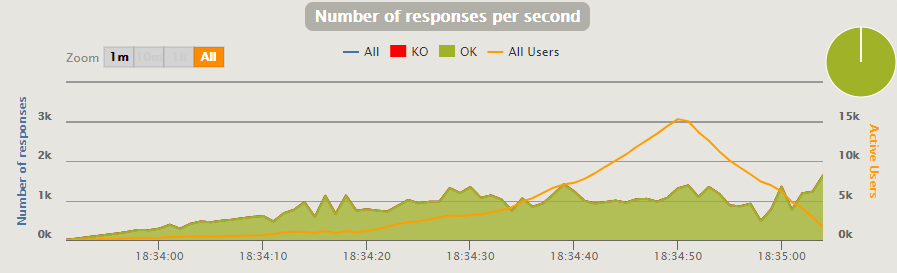
Видим отсутствие роста производительности от 1100 RPS и лавинообразный график Gatling-юзеров — обработчиков запросов. Странности добавляет увеличенное время прогона теста. Пока больше вопросов, чем ответов.
Самым простым и верным решением оказалось добавить sleep вместо вызова клиента, после которого запросы встали в длиннющую очередь. Похоже, мы создали средство для нагрузки с одним актором. Надо больше акторов! Создадим с ними пул, добавив всего одну строчку в ActionBuilder:
Запустим тест еще раз и увидим, что мы достигли 2K RPS:

Попробуем 10K:

Неплохо, а если 18K:

Опять схожие проблемы на 15K, но раздувать пул уже некуда. Порывшись в репозитории Gatling, обнаружили, что разработчики добавили возможность переконфигурировать саму настройку модели Akka-акторов. Делается это с помощью gatling-akka-defaults.conf файла, который по умолчанию выглядит вот так:
Предложим Gatling свой вариант:
Как мы будем работать с диспетчером, определяется стратегией в executor. Настройки с префиксом parallelism отвечают за количество тредов (наконец-то мы вспомнили о них) и зависят от возможностей машины и количества CPU. Throughput определяет максимум сообщений, обработанных одним актором, прежде чем поток отдаст сообщения другому актору. Также следует грамотно подойти к подбору коэффициентов для этих параметров.
Запустим с новыми настройками и пулом:
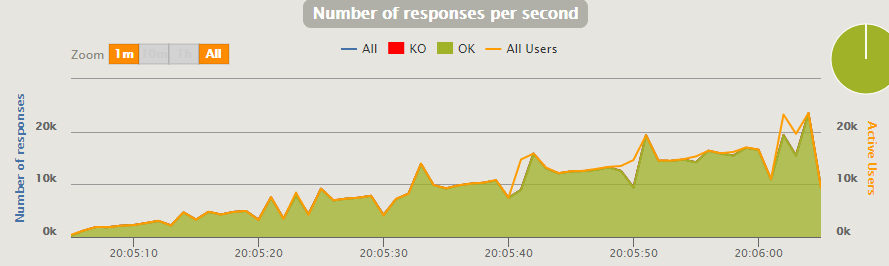
Справились с 18K, но стали замечать периодические проседания, связанные с GC и стратегией добавления Gatling-юзеров.
Помня, что машина выдавала 30K RPS с JMeter, попробуем дать схожую нагрузку на Gatling, и получим 32K:
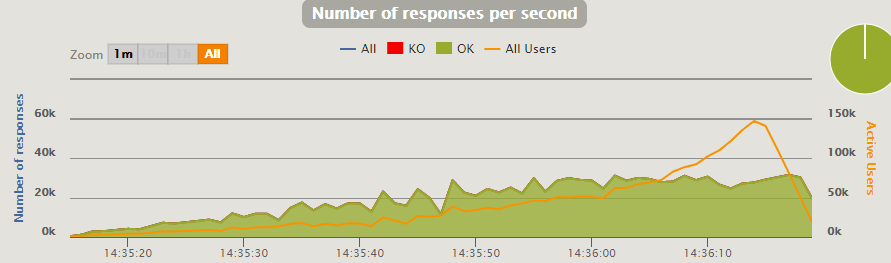

JMeter позволяет быстрее и проще получить результат, но при этом имеет чуть худшую производительность. Gatling позволяет грузить большими объемами (которые вам, возможно, и не нужны), но с ним сложнее работать. Выбор остается за вами.
15 марта ждем на QIWI SERVER PARTY 2.0, где, в том числе, расскажем про автотесты на Kotlin с помощью Spek.
В этой статье рассмотрим еще один инструмент для нагрузочного тестирования — Gatling и, как и обещали ранее, постараемся увеличить его производительность в десятки раз.
Gatling
Gatling — это opensource-инструмент для создания нагрузочных скриптов на Scala. Его легко можно подключить в свой проект любимым средством сборки. Под капотом там крутится модель акторов Akka, известная своей отменной производительностью.
Прежде чем окунуться глубже в написание нагрузочного скрипта для «не-HTTP» протокола, разберем простейший пример для HTTP:
class BasicSimulation extends Simulation {
val httpConf: HttpProtocolBuilder = http
.baseURL("http://123.random.com")
val scn: ScenarioBuilder = scenario("BasicSimulation")
.exec(http("request_1")
.get("/"))
setUp(
scn.inject(atOnceUsers(1))
).protocols(httpConf)
}
В протокол-билдере укажем адрес. В билдере сценариев опишем имя сценария, имя конкретного запроса и HTTP-метод. В блоке настройки нагрузочного профиля добавим сценарий нагрузки и определим протокол. Более подробно информация изложена в документации.
Выбор средства нагрузки
Это было небольшое отступление — все-таки мы собирались тестировать «не-HTTP». Как и в случае с JMeter, мы все еще хотим иметь легко модифицируемый плагин, на каркасе которого возможно нагружать различные протоколы, заменяя лишь клиент. Поэтому стандартные расширения нам не подходят.
За основу был взят довольно древний, но понятный код из Github. Он уже конфликтовал с текущей версией Gatling (2.3.1), но работал со старой. Главное же его достоинство было в работе с акторами.
Старая реализация
class PerfCustomProtocolSimulation extends Simulation {
val mine = new ActionBuilder {
def build(next: ActorRef, protocols: Protocols) = {
system.actorOf(Props(new MyAction(next)))
}
}
val userLog = csv("user_credentials.csv").circular
val scn = scenario("My custom protocol test")
.feed(userLog) {
exec(mine)
}
setUp(
scn.inject(
atOnceUsers(10)
)
)
}
class MyAction(val next: ActorRef) extends Chainable {
def greet(session: Session) {
// Call any custom code you wish, say an API call
}
def execute(session: Session) {
var start: Long = 0L
var end: Long = 0L
var status: Status = OK
var errorMessage: Option[String] = None
try {
start = System.currentTimeMillis;
greet(session)
end = System.currentTimeMillis;
} catch {
case e: Exception =>
errorMessage = Some(e.getMessage)
logger.error("FOO FAILED", e)
status = KO
} finally {
val requestStartDate, requestEndDate = start
val responseStartDate, responseEndDate = end
val requestName = "Test Scenario"
val message = errorMessage
val extraInfo = Nil
DataWriter.dispatch(RequestMessage(
session.scenarioName,
session.userId,
session.groupHierarchy,
requestName,
requestStartDate,
requestEndDate,
responseStartDate,
responseEndDate,
status,
message,
extraInfo))
next ! session
}
}
}
Простой переезд на новую версию омрачили поломка обратной совместимости разработчиками Gatling у минорных версий и глобальный рефакторинг внутренностей. В частности вот этот коммит избавляется от акторов там, где это не особо нужно:
Akka Actors Model
О том, что такое актор и модель акторов, написана огромная непонятная статья в Википедии и чуть более понятная выдержка из статьи на Хабре:
Актор Akka состоит из нескольких взаимодействующих компонентов. ActorRef – это логический адрес актора, позволяющий асинхронно отправлять актору сообщения по принципу «послал и забыл». Диспетчер отвечает за постановку сообщений в очередь, ведущую в почтовый ящик актора, а также приказывает этому ящику изъять из очереди одно или несколько сообщений, но только по одному за раз — и передать их актору на обработку. Akka не позволяет получить непосредственный доступ к актору и поэтому гарантирует, что единственный способ взаимодействия с актором — это асинхронные сообщения. Невозможно вызвать метод в акторе.Сложно. Попробуем объяснить на примере стройки:
Кроме того, необходимо отметить, что отправка сообщения актору и обработка этого сообщения актором — это две отдельных операции, которые, скорее всего, происходят в разных потоках. Разумеется, Akka обеспечивает необходимую синхронизацию, чтобы гарантировать, что любые изменения состояния будут видимы всем потокам.
Заказчик ремонта (мы с вами) просит у строительной компании отремонтировать ему несколько комнат. Прораб управляет очередью и загрузкой строителя, следит, чтобы он не перетруждался и не простаивал. Мы же напрямую не общаемся со строителем, а работаем с его представителем (компанией). Зная, как у нас медленно строят, мы отдаем задачу и даже не надеемся на ее быстрое исполнение (не ждем результата, а идем заниматься своими делами).
Нагрузочный сценарий
По аналогии с HTTP-примером и взяв за основу старый скрипт для описания кастомного протокола, напишем свой билдер. Он принимает некое действие клиента для нагрузки и работает с акторами:
val mine = new ActionBuilder {
def build(ctx: ScenarioContext, next: Action): Action = {
new ActorDelegatingAction(name,
ctx.system.actorOf(
Props(new MyAction(next, сlient, ctx))))
}
}
Обработчик результатов прогона не входит в стандартную реализацию нагрузочных скриптов. Код из старого примера больше не работал, поэтому после миграции пришлось немного порыться в исходниках Gatling, изучая реализацию HTTP:
val engine: StatsEngine = ctx.coreComponents.statsEngine
engine.logResponse(
session,
requestName,
ResponseTimings(start, end),
status,
None,
message,
Nil)
Первый запуск скрипта
Клиента для Thrift мы уже написали в первой части статьи. Машину, с которой будем грузить — настроили. Микросервис тоже остался прежним и держит 50K RPS.
Пора грузить. Попробуем пристреляться линейно возрастающей нагрузкой с 1 до 2K RPS в течение 60 секунд:
Видим отсутствие роста производительности от 1100 RPS и лавинообразный график Gatling-юзеров — обработчиков запросов. Странности добавляет увеличенное время прогона теста. Пока больше вопросов, чем ответов.
Самым простым и верным решением оказалось добавить sleep вместо вызова клиента, после которого запросы встали в длиннющую очередь. Похоже, мы создали средство для нагрузки с одним актором. Надо больше акторов! Создадим с ними пул, добавив всего одну строчку в ActionBuilder:
ctx.system.actorOf(RoundRobinPool(POOL_SIZE).props(
Props(new MyAction(next, сlient, ctx)))))
Скрипт c пулом
Запустим тест еще раз и увидим, что мы достигли 2K RPS:
Попробуем 10K:
Неплохо, а если 18K:
Опять схожие проблемы на 15K, но раздувать пул уже некуда. Порывшись в репозитории Gatling, обнаружили, что разработчики добавили возможность переконфигурировать саму настройку модели Akka-акторов. Делается это с помощью gatling-akka-defaults.conf файла, который по умолчанию выглядит вот так:
actor {
default-dispatcher {
throughput = 20
}
}
Предложим Gatling свой вариант:
actor {
default-dispatcher {
type = Dispatcher
executor = "fork-join-executor"
fork-join-executor {
parallelism-min = 10
parallelism-factor = 2.0
parallelism-max = 30
}
throughput = 100
}
}
Как мы будем работать с диспетчером, определяется стратегией в executor. Настройки с префиксом parallelism отвечают за количество тредов (наконец-то мы вспомнили о них) и зависят от возможностей машины и количества CPU. Throughput определяет максимум сообщений, обработанных одним актором, прежде чем поток отдаст сообщения другому актору. Также следует грамотно подойти к подбору коэффициентов для этих параметров.
Запустим с новыми настройками и пулом:
Справились с 18K, но стали замечать периодические проседания, связанные с GC и стратегией добавления Gatling-юзеров.
Предельная нагрузка
Помня, что машина выдавала 30K RPS с JMeter, попробуем дать схожую нагрузку на Gatling, и получим 32K:
Выводы
JMeter позволяет быстрее и проще получить результат, но при этом имеет чуть худшую производительность. Gatling позволяет грузить большими объемами (которые вам, возможно, и не нужны), но с ним сложнее работать. Выбор остается за вами.
P.S.
15 марта ждем на QIWI SERVER PARTY 2.0, где, в том числе, расскажем про автотесты на Kotlin с помощью Spek.