

Задача старая и хорошо изученная, для английского языка существует масса коммерческих и открытых решений: Spacy, Stanford NER, OpenNLP, NLTK, MITIE, Google Natural Language API, ParallelDots, Aylien, Rosette, TextRazor. Для русского тоже есть хорошие решения, но они в основном закрытые: DaData, Pullenti, Abbyy Infoextractor, Dictum, Eureka, Promt, RCO, AOT, Ahunter. Из открытого мне известен только Томита-парсер и свежий Deepmipt NER.
Я занимаюсь анализом данных, задача обработки текстов одна из самых частых. На практике оказывается, что, например, извлечь имена из русского текста совсем непросто. Есть готовое решение в Томита-парсере, но там неудобная интеграция с Питоном. Недавно появилось решение от ребят из iPavlov, но там имена не приводятся к нормальной форме. Для извлечения, например, адресов («ул. 8 Марта, д.4», «Ленинский проезд, 15») открытых решений мне не известно, есть pypostal, но он чтобы парсить адреса, а не искать их в тексте. C нестандартными задачами типа извлечения ссылок на нормативные акты («ст. 11 ГК РФ», «п. 1 ст. 6 Закона № 122-ФЗ») вообще непонятно, что делать.
Год назад Дима Веселов начал проект Наташа. С тех пор код был значительно доработан. Наташа была использована в нескольких крупных проектах. Сейчас мы готовы рассказать о ней пользователям Хабра.
Наташа — это аналог Томита-парсера для Питона (Yargy-парсер) плюс набор готовых правил для извлечения имён, адресов, дат, сумм денег и других сущностей.В статье показано, как использовать готовые правила Наташи и, самое главное, как добавлять свои с помощью Yargy-парсера.
Готовые правила
Сейчас в Наташе есть правила для извлечения имён, адресов, дат и сумм денег. Есть ещё правила для названий организаций и географических объектов, но у них не очень высокое качество.
Имена
Воспользоваться готовыми правилами просто:
from natasha import NamesExtractor
from natasha.markup import show_markup, show_json
extractor = NamesExtractor()
text = '''
Благодарственное письмо Хочу поблагодарить учителей моего, теперь уже бывшего, одиннадцатиклассника: Бушуева Вячеслава Владимировича и Бушуеву Веру Константиновну. Они вовлекали сына в интересные внеурочные занятия, связанные с театром и походами.
Благодарю прекрасного учителя 1"А" класса - Волкову Наталью Николаевну, нашего наставника, тьютора - Ларису Ивановну, за огромнейший труд, чуткое отношение к детям, взаимопонимание! Огромное спасибо!
'''
matches = extractor(text)
spans = [_.span for _ in matches]
facts = [_.fact.as_json for _ in matches]
show_markup(text, spans)
show_json(facts)
>>> Благодарственное письмо Хочу поблагодарить учителей моего, теперь уже бывшего, одиннадцатиклассника: [[Бушуева Вячеслава Владимировича]] и [[Бушуеву Веру Константиновну]]. Они вовлекали сына в интересные внеурочные занятия, связанные с театром и походами.
Благодарю прекрасного учителя 1"А" класса - [[Волкову Наталью Николаевну]], нашего наставника, тьютора - [[Ларису Ивановну]], за огромнейший труд, чуткое отношение к детям, взаимопонимание! Огромное спасибо!
[
{
"first": "вячеслав",
"middle": "владимирович",
"last": "бушуев"
},
{
"first": "вера",
"middle": "константиновна",
"last": "бушуева"
},
{
"first": "наталья",
"middle": "николаевна",
"last": "волкова"
},
{
"first": "лариса",
"middle": "ивановна"
}
]
В 2016 году проходило соревнование factRuEval-2016 по извлечению именованных сущностей. Среди участников были крупные компании: ABBYY, RCO. У топовых решений F1-мера для имён была 0.9+. У Наташи результат хуже — 0.78. Проблема в основном c иностранными именами и сложными фамилиями, например: «Харуки Мураками», "… главой Афганистана Хамидом Карзаем", «Остап Бендер встречается с Кисой Воробьяниновым ...». Для текстов с русскими именами качество получается ~0.95. Можно, например, извлекать имена учителей с сайтов школ, агрегировать отзывы:
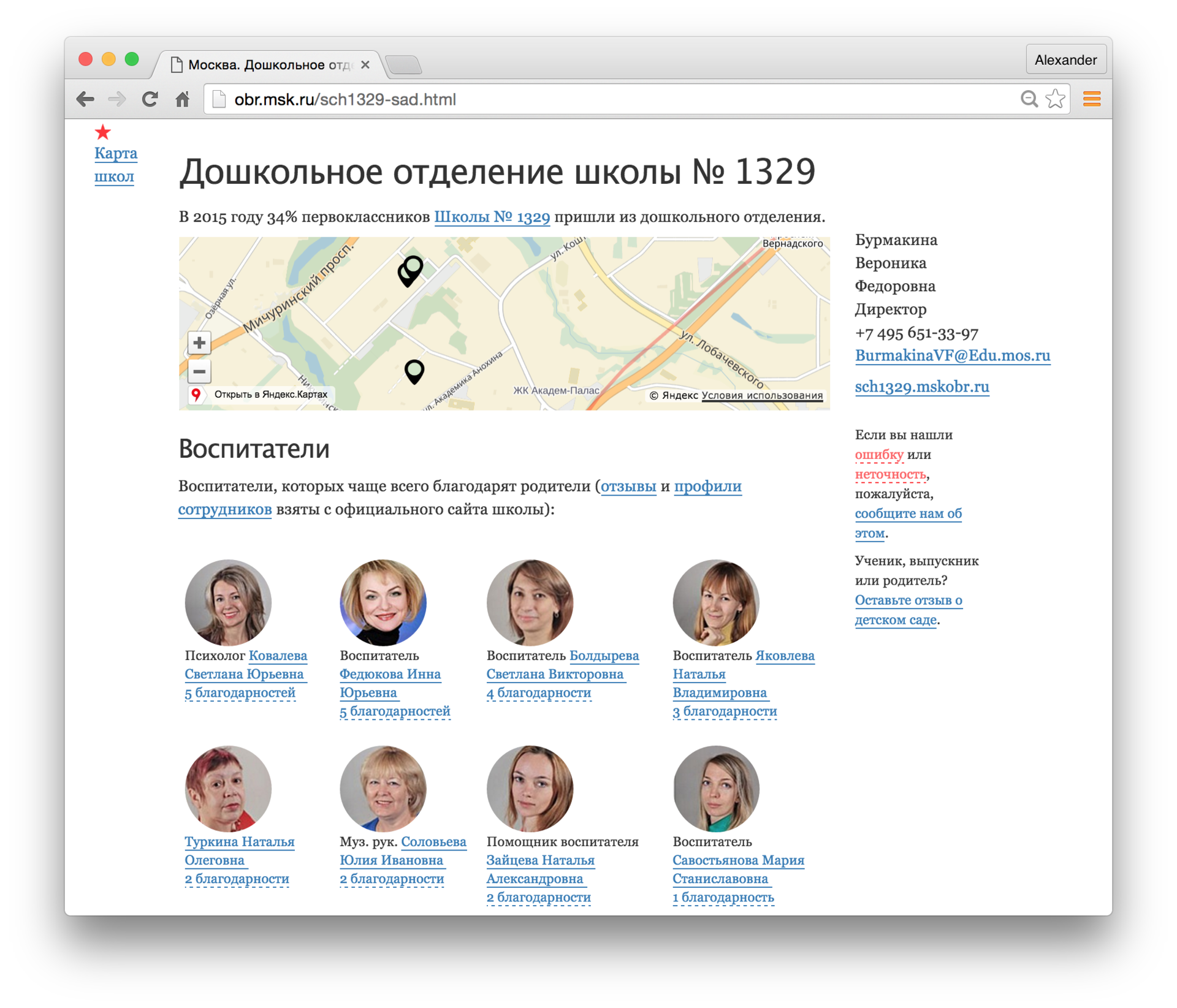
Адреса
Интерфейс такой же как для имён, только
NamesExtractor меняется на AddressExtractor:from natasha import AddressExtractor
from natasha.markup import show_markup, show_json
extractor = AddressExtractor()
text = '''
Предлагаю вернуть прежние границы природного парка №71 на Инженерной улице 2.
По адресу Алтуфьевское шоссе д.51 (основной вид разрешенного использования: производственная деятельность, склады) размещен МПЗ. Жители требуют незамедлительной остановки МПЗ и его вывода из района
Контакты О нас телефон 7 881 574-10-02 Адрес Республика Карелия,г.Петрозаводск,ул.Маршала Мерецкова, д.8 Б,офис 4
'''
matches = extractor(text)
spans = [_.span for _ in matches]
facts = [_.fact.as_json for _ in matches]
show_markup(text, spans)
show_json(facts)
>>> Предлагаю вернуть прежние границы природного парка №71 на [[Инженерной улице 2]].
По адресу [[Алтуфьевское шоссе д.51]] (основной вид разрешенного использования: производственная деятельность, склады) размещен МПЗ. Жители требуют незамедлительной остановки МПЗ и его вывода из района
Контакты О нас телефон 7 881 574-10-02 Адрес [[Республика Карелия,г.Петрозаводск,ул.Маршала Мерецкова, д.8 Б,офис 4]]
[
{
"parts": [
{
"name": "Инженерной",
"type": "улица"
},
{
"number": "2"
}
]
},
{
"parts": [
{
"name": "Алтуфьевское",
"type": "шоссе"
},
{
"number": "51",
"type": "дом"
}
]
},
{
"parts": [
{
"name": "Карелия",
"type": "республика"
},
{
"name": "Петрозаводск",
"type": "город"
},
{
"name": "Маршала Мерецкова",
"type": "улица"
},
{
"number": "8 Б",
"type": "дом"
},
{
"number": "4",
"type": "офис"
}
]
}
]
В factRuEval-2016 участникам предлагалось извлекать имена, названия организаций и географические объекты. Независимых тестовых данных для оценки качества работы с адресами, на сколько я знаю, не существует. За несколько лет работы у нас накопились сотни тысяч строк вида «Адрес: 443041 г. Самара ул. Ленинская, д.168», «Адрес г. Иркутск, ул. Байкальская, д. 133, офис 1 (вход со двора).». Для оценки качества сделана случайная выборка из 1000 адресов, результаты проверены вручную, ~90% строк обработались корректно. Проблемы возникают, в основном, с названиями улиц, например: «г. Волжск, 2-ая промышленная, стр. 2», «111674, г. Москва, Дмитриевского, д. 17».
В 2017 году параллельно с историей про реконструкцию в Москве обсуждались новые Правила землепользования и застройки (ПЗЗ). Был проведён опрос населения. Более 100 000 комментариев были выложены в открытый доступ в виде огромного pdf-файла. Никита Кузнецов с помощью Наташи извлёк упомянутые адреса и посмотрел в каких районах закон поддерживают, а в каких нет:
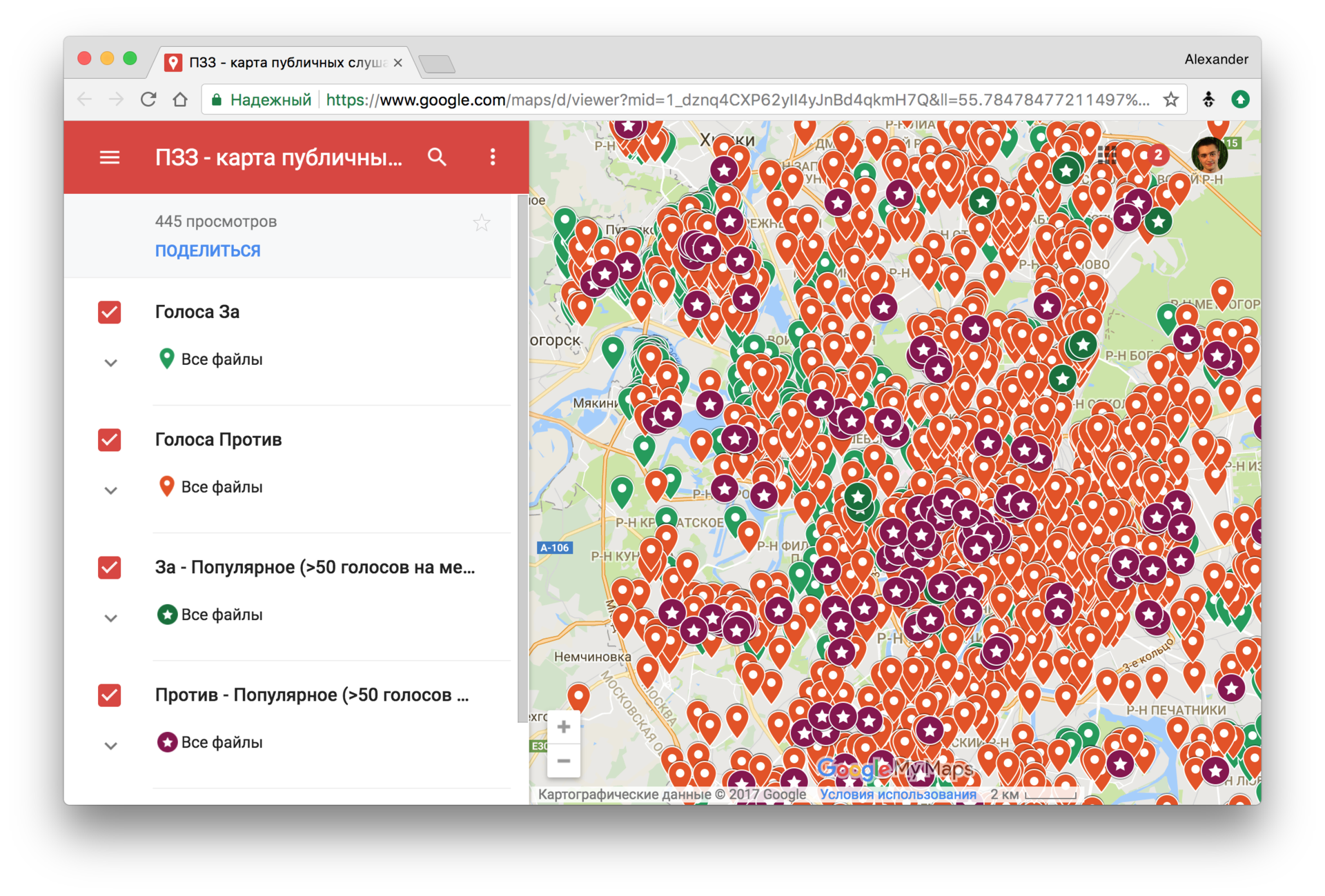
Визуально оценить качество работы
AddressExtractor на датасете с комментариями к ПЗЗ можно в репозитории с примерами.Другие правила
Ещё в Наташе есть правила для дат и денег. Интерфейс такой же как у
AddressExtractor и NamesExtractor.from natasha import (
NamesExtractor,
AddressExtractor,
DatesExtractor,
MoneyExtractor
)
from natasha.markup import show_markup, show_json
extractors = [
NamesExtractor(),
AddressExtractor(),
DatesExtractor(),
MoneyExtractor()
]
text = '''
Взыскать к индивидуального предпринимателя Иванова Костантипа Петровича дата рождения 10 января 1970 года, проживающего по адресу город Санкт-Петербург, ул. Крузенштерна, дом 5/1А 8 000 (восемь тысяч) рублей 00 копеей госпошлины в пользу бюджета РФ
'''
spans = []
facts = []
for extractor in extractors:
matches = extractor(text)
spans.extend(_.span for _ in matches)
facts.extend(_.fact.as_json for _ in matches)
show_markup(text, spans)
show_json(facts)
>>> Взыскать к индивидуального предпренимателя [[Иванова Костантипа Петровича]] дата рождения [[10 января 1970 года]], проживающего по адресу [[город Санкт-Петербург, ул. Крузенштерна, дом 5/1А]][[Крузенштерна]], дом 5/1А [[8 000 (восемь тысяч) рублей 00]] копеей госпошлины в пользу бюджета РФ
[
{
"first": "костантип",
"middle": "петрович",
"last": "иванов"
},
{
"last": "крузенштерн"
},
{
"parts": [
{
"name": "Санкт-Петербург",
"type": "город"
},
{
"name": "Крузенштерна",
"type": "улица"
},
{
"number": "5/1А",
"type": "дом"
}
]
},
{
"year": 1970,
"month": 1,
"day": 10
},
{
"integer": 8000,
"currency": "RUB",
"coins": 0
}
]
Интерфейс Наташи очень простой:
e = Extractor(); r = e(text); .... Пользователю недоступны никакие настройки. На практике обойтись только готовыми правилами получается редко. Например, Наташа не разберёт дату "«21» апреля 2017", потому что в правилах не предусмотрен номер дня в кавычках. Библиотека не разберёт адрес «Люберецкий район, деревня Мотяково, д. 61/2», потому что в нём нет названия улицы.Часто приходится опускаться на уровень ниже, дополнять готовые правила и писать свои. Для этого использует Yargy-парсер. Все правила в Наташе написаны на нём. Yargy — сложная и интересная библиотека, в этой статье мы рассмотрим только простые примеры использования.
Yargy-парсер
Yargy-парсер — аналог яндексового Томита-парсера для Питона. Правила для извлечения сущностей описываются с помощью контекстно-свободных грамматик и словарей.
Грамматики
Грамматики в Yargy записываются на специальном DSL-е. Так, например, будет выглядеть простое правило для извлечения дат в ISO-формате («2018-02-23», «2015-12-31»):
from yargy import rule, and_, Parser
from yargy.predicates import gte, lte
DAY = and_(
gte(1),
lte(31)
)
MONTH = and_(
gte(1),
lte(12)
)
YEAR = and_(
gte(1),
lte(2018)
)
DATE = rule(
YEAR,
'-',
MONTH,
'-',
DAY
)
parser = Parser(DATE)
text = '''
2018-02-23,
2015-12-31;
8 916 364-12-01'''
for match in parser.findall(text):
print(match.span, [_.value for _ in match.tokens])
>>> [1, 11) ['2018', '-', '02', '-', '23']
>>> [13, 23) ['2015', '-', '12', '-', '31']
>>> [33, 42) ['364', '-', '12', '-', '01']
Пока не очень впечатляет, похожую функциональность можно получить регуляркой
r'\d\d\d\d-\d\d-\d\d', правда она будет метчить ерунду типа «1234-56-78».Предикаты
gte и lte в примере выше — предикаты. В парсер встроено много готовых предикатов, есть возможность добавить свои. Для определения морфологии слов используется pymorphy2. Например, предикат, gram('NOUN') срабатывает на существительных, normalized('январь') метчит все формы слова «январь». Добавим правила для дат вида «8 января 2014», «15 июня 2001 г.»:from yargy import or_
from yargy.predicates import caseless, normalized, dictionary
MONTHS = {
'январь',
'февраль',
'март',
'апрель',
'мая',
'июнь',
'июль',
'август',
'сентябрь',
'октябрь',
'ноябрь',
'декабрь'
}
MONTH_NAME = dictionary(MONTHS)
YEAR_WORDS = or_(
rule(caseless('г'), '.'),
rule(normalized('год'))
)
DATE = or_(
rule(
YEAR,
'-',
MONTH,
'-',
DAY
),
rule(
DAY,
MONTH_NAME,
YEAR,
YEAR_WORDS.optional()
)
)
parser = Parser(DATE)
text = '''
8 января 2014 года, 15 июня 2001 г.,
31 февраля 2018'''
for match in parser.findall(text):
print(match.span, [_.value for _ in match.tokens])
>>> [21, 36) ['15', 'июня', '2001', 'г', '.']
>>> [1, 19) ['8', 'января', '2014', 'года']
>>> [38, 53) ['31', 'февраля', '2018']
Интерпретация
Найти подстроку с фактом обычно недостаточно. Например, для текста «8 мая по поручению президента Владимира Путина» парсер должен вернуть не просто «8 мая», «Владимира Путина», а
Date(month=5, day=8), Name(first='Владимир', last='Путин'), для этого в Yargy предусмотрена процедура интерпретации. Результат работы парсера — это дерево разбора:match = parser.match('05 февраля 2011 года')
match.tree.as_dot

(R0, R1 — технические вершины, «R» сокращение от «Rule»)
Для интерпретации пользователь «развешивает» на узлы дерева пометки с помощью метода
.interpretation(...):from yargy.interpretation import fact
Date = fact(
'Date',
['year', 'month', 'day']
)
DAY = and_(
gte(1),
lte(31)
).interpretation(
Date.day
)
MONTH = and_(
gte(1),
lte(12)
).interpretation(
Date.month
)
YEAR = and_(
gte(1),
lte(2018)
).interpretation(
Date.year
)
MONTH_NAME = dictionary(
MONTHS
).interpretation(
Date.month
)
DATE = or_(
rule(YEAR, '-', MONTH, '-', DAY),
rule(
DAY,
MONTH_NAME,
YEAR,
YEAR_WORDS.optional()
)
).interpretation(Date)
match = parser.match('05 февраля 2011 года')
match.tree.as_dot
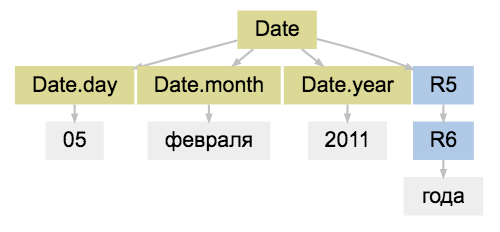
parser = Parser(DATE)
text = '''8 января 2014 года, 2018-12-01'''
for match in parser.findall(text):
print(match.fact)
>>> Date(year='2018', month='12', day='01')
>>> Date(year='2014', month='января', day='8')
Нормализация
В примере с датами нужно привести названия месяцев, дни и годы к числам, для этого в Yargy встроена процедура нормализации. Внутри
.interpretation(...) пользователь указывает, как нормировать поля:from datetime import date
Date = fact(
'Date',
['year', 'month', 'day']
)
class Date(Date):
@property
def as_datetime(self):
return date(self.year, self.month, self.day)
MONTHS = {
'январь': 1,
'февраль': 2,
'март': 3,
'апрель': 4,
'мая': 5,
'июнь': 6,
'июль': 7,
'август': 8,
'сентябрь': 9,
'октябрь': 10,
'ноябрь': 11,
'декабрь': 12
}
DAY = and_(
gte(1),
lte(31)
).interpretation(
Date.day.custom(int)
)
MONTH = and_(
gte(1),
lte(12)
).interpretation(
Date.month.custom(int)
)
YEAR = and_(
gte(1),
lte(2018)
).interpretation(
Date.year.custom(int)
)
MONTH_NAME = dictionary(
MONTHS
).interpretation(
Date.month.normalized().custom(MONTHS.__getitem__)
)
DATE = or_(
rule(YEAR, '-', MONTH, '-', DAY),
rule(
DAY,
MONTH_NAME,
YEAR,
YEAR_WORDS.optional()
)
).interpretation(Date)
parser = Parser(DATE)
text = '''8 января 2014 года, 2018-12-01'''
for match in parser.findall(text):
record = match.fact
print(record, repr(record.as_datetime))
>>> Date(year=2018, month=12, day=1) datetime.date(2018, 12, 1)
>>> Date(year=2014, month=1, day=8) datetime.date(2014, 1, 8)
match = parser.match('31 февраля 2014 г.')
match.fact.as_datetime
>>> ValueError: day is out of range for month
Ура, мы повторили маленький кусочек функциональности библиотеки dateparser. Если нужно извлечь из текста, например, только даты, то стоит выбрать готовую специализированную библиотеку. Решение будет работать быстрее, качество будет выше. Yargy нужен для объёмных, нестандартных задач.
Согласование
Рассмотрим простое правило для извлечения имён. В словаре Opencorpora, который использует pymorphy2, для имён ставится метка
Name, для фамилий — метка Surn. Будем считать именем пару слов Name Surn или Surn Name:from yargy.predicates import gram
Name = fact(
'Name',
['first', 'last']
)
FIRST = gram('Name').interpretation(
Name.first.inflected()
)
LAST = gram('Surn').interpretation(
Name.last.inflected()
)
NAME = or_(
rule(
FIRST,
LAST
),
rule(
LAST,
FIRST
)
).interpretation(
Name
)
У такого решения есть две проблемы:
1. Правило метчит имя и фамилию в разных падежах («Иванова Лёша», «Петрову Ромой»)
2. Женские фамилии после нормализации становятся мужскими
parser = Parser(NAME)
text = '''
... с улицы Грибоедова Антон свернул на ...
... Бушуева Вячеслава и Бушуеву Веру ...
'''
for match in parser.findall(text):
print(match.fact)
>>> Name(first='антон', last='грибоедов')
>>> Name(first='вячеслав', last='бушуев')
>>> Name(first='вера', last='бушуев')
Чтобы решить эти проблемы в Yargy есть механизм согласования. С помощью метода
.match(...) пользователь указывает ограничения на правила:from yargy.relations import gnc_relation
gnc = gnc_relation() # согласование по gender, number и case (падежу, числу и роду)
Name = fact(
'Name',
['first', 'last']
)
FIRST = gram('Name').interpretation(
Name.first.inflected()
).match(gnc)
LAST = gram('Surn').interpretation(
Name.last.inflected()
).match(gnc)
NAME = or_(
rule(
FIRST,
LAST
),
rule(
LAST,
FIRST
)
).interpretation(
Name
)
parser = Parser(NAME)
text = '''
... с улицы Грибоедова Антон свернул на ...
... Бушуева Вячеслава и Бушуеву Веру ...
'''
for match in parser.findall(text):
print(match.fact)
>>> Name(first='вячеслав', last='бушуев')
>>> Name(first='вера', last='бушуева')
Достоинства и недостатки
Наташа предоставляет под лицензией MIT решения, которых раньше не было в открытом доступе (или я о них не знаю). Например, раньше нельзя было просто взять и извлечь структурированные имена и адреса из русскоязычного текста, а теперь можно. Раньше для Питона не было чего-то вроде Томита-парсера, теперь есть.
Постараюсь коротко сформулировать недостатки:
- Вручную составленные правила.
Наташа разбирает только те словосочетания, для которых заранее были составлены правила. Может показаться, что нереально написать правила, например, для имён в произвольном тексте, слишком они разные. На практике всё не так плохо:
- Если посидеть недельку, то всё-таки для 80% имён составить правила можно.
- Обычно нужно работать не с произвольными текстами, а с текстами на контролируемом естественном языке: резюме, решения судов, нормативные акты, раздел сайта с контактами.
- В правилах для Yargy-парсера можно использовать разметку, полученную методами машинного обучения.
- Медленная скорость работы.
Начнём с того, что Yargy реализует алгоритм Earley parser, его сложностьO(n3), гдеn— число токенов. Код написан на чистом Питоне, с упором на читаемость, а не оптимизацию. Короче говоря, библиотека работает медленно. Например, на задаче извлечения имён Наташа в 10 раз медленнее Томита-парсера. На практике с этим можно жить:
- Хорошо помогает PyPy. Случается ускорение в 10 раз, в среднем в ~3-4 раза.
- Выполнение в несколько потоков, на нескольких машинах. Задача хорошо параллелится, машины в аренду сейчас легко доступны.
- Ошибки в стандартных правилах.
Например, качество извлечения имён у Наташи очень далеко от SOTA. На практике из коробки библиотека не всегда показывает хорошее качество, нужно дорабатывать правила под себя.
Мы надеемся, что сообщество поможет улучшить точность и полноту правил. Пишите багрепорты, присылайте пуллреквесты.
Ссылки
Адрес проекта на Гитхабе простой — github.com/natasha.
Установка —
pip install natasha. Библиотека тестируется на Python 2.7, 3.3, 3.4, 3.5, 3.6, PyPy и РyPy3.Документация для пакета стандартных правил короткая, интерфейс очень простой — natasha.readthedocs.io. Документация для Yargy более объёмная и сложная — yargy.readthedocs.io. Yargy интересный и непростой инструмент, возможно, существующей документации будет недостаточно. Есть желание опубликовать на Хабре серию уроков по Yargy. Вы можете написать в комментариях, какие темы стоит осветить, например:
- Скорость выполнения, обработка больших объёмов текстов;
- Ручные правила и машинное обучение, гибридные решения;
- Примеры применения библиотеки в разных областях: разбор резюме, парсинг названий товаров, чат-боты.
Чат пользователей Наташи — t.me/natural_language_processing. Там можно попробовать задать вопросы по библиотеке.
Стенд для демонстрации стандартных правил — natasha.github.io/demo. Можно ввести свой текст, посмотреть, как на нём отрабатывают стандартные правила:

Комментарии (28)

alatushkin
14.03.2018 20:01Аналогичную вещь реализовал на kotlin для departureBot.ru чтобы понимать запросы вроде "туры в Италию Испанию или Грецию в начале июня на 7-10 дней"
Не стал выкладывать т.к. парсер грамматик работает на выводе pymorphy (начальная форма + грамемы). Никто кст не знает живой аналогичной библиотеки с русским (и словарями) для jvm?

Ogoun
14.03.2018 20:07Томита-парсер условно доступен, когда я хотел использовать его, написал в поддержку яндекса вопрос о возможности применения в коммерческих решениях, на что получил запрос:
>> юристы просят подробностей о Вашем сервисе. Они хотят понять насколько он будет похож на Я.Новости. Например, речь идет обо всех новостях или только узко-специализированных?
После моего ответа о несхожести задач с сервисом Я.Новости и кратким описанием, ответов не получил.
В общем, стоит использовать с осторожностью, а лучше открытые аналоги.
nestor_by
14.03.2018 22:42Отличная штука, спасибо. Есть возможность обрабатывать не только слова с заглавными буквами?
Например: "петров петр петрович" не вернет ничего, в тоже время "Петров Петр Петрович" работает на ура.
Georg
14.03.2018 23:34Спасибо за классную штуку.
Однако поиск дат ложно срабатывает например на таком абзаце:
В соответствии с санитарной классификацией СанПиН 2.2.1/2.1.1.1200-03 «Санитарно-защитные зоны и санитарная классификация предприятий, сооружений и иных объектов», Объекты по обслуживанию грузовых автомобилей, относятся к 3 классу опасности с нормативной 300 метровой СЗЗ (п.3, класс 3, раздел 7.1.8).
Alter_Ego
14.03.2018 23:46Спасибо за полезный проект! А нормализацию времени скоро прикрутите?
alexkuku Автор
15.03.2018 00:02Если у вас есть потребность в таком экстракторе, я бы посоветовал прислать примеры строк, который должны разбираться, как это было сделано, например, для адресов github.com/natasha/natasha/issues/9#issuecomment-276799414

BalinTomsk
14.03.2018 23:56А как распарсится такое: «Абу Али аль Хусейн ибн-Абдаллах ибн-Сина»?
Или такое: «Ломион Хорвэграуг Морион Норнорос Яэрэ а’Моритарнон»alexkuku Автор
15.03.2018 00:00Плохо ))

Когда мне нужно было работать с такими именами я просто заводил словарь
'Абд Аль — Азиз Бин Мухаммад',
'Абд ар — Рахман Наср ас — Са ди',
'Абд ар — Рахман ибн Хасан',
'Абд — аль Хади ибн Али',
'Абд — уль — Кадим Заллюм',
'Абду — ль — Азиз Аль Абдуль — ли — Лятыф',
…
soshnikov
15.03.2018 01:58Для Абу Али аль Хусейн ибн-Абдаллах ибн-Сина будет проще и дешевле нанять людей с трехбуквенными именами, которые вручную распарсят имя Ломион Хорвэграуг Морион Норнорос Яэрэ а’Моритарнон и всех остальных его многочисленных друзей, родственников и животных :)
Авторам библиотеки — большое спасибо.elingur
15.03.2018 10:54Зачем «людей с трехбуквенными именами»? Это легко лечится правилами на пост обработке.
elingur
15.03.2018 10:52Хорошая работа. Правда, на счет
Для текстов с русскими именами качество получается ~0.95
— сомневаюсь. Скажем, «Маша мыла Раму» — ничего не находит. Пока есть проблемы со именами собственными, совпадающие с нарицательными.
А зачем вам нормализация? Она повышает точность не более чем на 1%, а скорость съедает довольно существенно. Нормализация нужна на пост обработке: при согласовании, агрегации, кореференци.alexkuku Автор
15.03.2018 12:11Может быть не совсем понятно написано. В предложении «Для текстов с русскими именами качество получается ~0.95» речь идёт только про github.com/natasha/natasha-examples/blob/master/02_sad/notes.ipynb. То есть утверждается что 95% качество в примере 02_sad/notes.ipynb
Если вы введёте полное предложение, например «придя с работы Маша мыла Раму» «Маша» найдётся. Такая специфика работы NamesExtractor сейчасelingur
15.03.2018 12:35Тогда вам есть куда расти. Нужно снимать частиречную омонимию (система должна понимать, что «маша» это noun, а не verb) и проверять по словарю имен собственных для работы с регистром (потому, как, например, «Путина» в начале предложения может быть и имя (в род. или вин. падеже) и слово нарицательное (в именительном)) — и таких примеров много. Хорошо бы еще снимать омонимию по морфо признакам. Но это уже чуть сложнее.
alexkuku Автор
15.03.2018 12:15Про нормализацию не понял вопрос. Нормализация делается после применения грамматик
elingur
15.03.2018 12:38Если у вас приоритет в скорости обработки, то нет смысла использовать нормализацию (даже больше: морфологию). Т.е. работать с плоским текстом. Нормализация почти не дает выигрыша. Ну а если качество — то да, лучше использовать. Иначе согласование и агрегацию одинаковых сущностей будет сделать сложно.
IBendrup
15.03.2018 11:42Вы пробовали оценить количество правил, необходимое для корректного извлечения адресов? Типовой адрес в РФ имеет 3-6 уровней адресации (например: область, район, город, улица, дом). Если просто предусмотреть для каждого уровня по 10 частных правил (правила для каждого уровня свои), то общее число правил для пяти-шести уровней достигнет 10^5-10^6. Есть ли какие-то варианты сократить число правил, необходимое для извлечения адреса?
alexkuku Автор
15.03.2018 12:11Правила не перемножаются. Вы можете почитать про en.wikipedia.org/wiki/Earley_parser
survivorm
15.03.2018 11:46Интересная вещь. Но вот некоторые комментарии в статье я бы подправил. Томита-парсеры для питона есть, и были. Например, Parglare, хотя под python 2.7 у него есть баг с обработкой unicode, возможно, будет исправлено позднее (под python 3 прекрасно работает) (подозреваю, что не только он, скорее всего любой GLR-парсер (или PEG) работающий под python3 не будет иметь проблем с русским языком).
Другое дело, не было инструмента с комплектом правил, заточенных под парсинг русских ФИО/дат/адресов — с этим спорить не буду (сам не сталкивался). В любом случае, хорошая статья, спасибо.alexkuku Автор
15.03.2018 12:18Я плохо знаю Parglare, но я бы не назвал его аналогом Томита-парсера. Вопрос в том как туда встроить работу с морфологией, нормализацией, согласованием.
survivorm
15.03.2018 12:32Давайте определимся. Томита-парсером называется всего лишь ЛЮБОЙ GLR парсер. Обратитесь к ru.wikipedia.org/wiki/GLR-%D0%BF%D0%B0%D1%80%D1%81%D0%B5%D1%80. Называется он Томита-парсером из-за того, что сам GLR предложен Масару Томита, а вовсе не за работу с морфологией и т.п.
Томита-парсер яндекса — одна из реализаций GLR, с некоторыми встроенными плюшками (как и Наташа, хотя в плане последней не уверен).
Давайте отделять алгоритмы от реализаций :)
То, о чем говорили вы, это парсер КСГ с продвинутыми механизмами работы с морфологией, нормализацией, согласованием. А не GLR(Томита) парсер :)
alexkuku Автор
15.03.2018 12:41Ой, я думал под словосочетание «Томита-парсер» вы подразумевали github.com/yandex/tomita-parser, про Масару Томита мало кто знает. Тогда «Я плохо знаю Parglare, но я бы не назвал его аналогом yandex/tomita-parser». Просто эти плюшки на практике 50% всей реализации: морфология, нормализаций, специальная процедура интерпретации, согласование, газеттир
survivorm
15.03.2018 12:44Так кто же спорит. Я же не говорю, что статья или упомянутый инструмент плохи — ровно наоборот, просто не стоит вводить людей в заблуждение и мир (к счастью) не ограничивается Yandex'ом
MooooM
17.03.2018 15:48Спасибо за опенсорс! Несколько лет назад действительно дико не хватало подобного открытого и рабочего решения для русского языка.
Приходилось писать правила для одного из упомянутых коммерческих решений. Работало оно хорошо, но уже одна необходимость использования хардварного лицензионного ключа порождала чудовищное количество проблем.
Пара вопросов:
1. Код еще не смотрел, но планируется ли возможноть писать, или использовать кастомные правила для английского языка? Например в тексте встретится английская имя фамилия которые хотелось бы получать вместе с русскими.
2. Это совсем далекое будущее но тем не менее… RCO и Abbyy помимо сущностей позволяют извлекать собственно факты как действия. То есть связывать сущности в тексте между собой, в основном через глаголы. Нечто подобное хотя бы в далеких планах имеется или основным направлением будет именно извлечение фактов сущностей?
kelegorm
А можно с помощью этого решения искать просто слова? Например, «Занятость» во всех формах (склонения, плюс занят, занятие)? Для некоторых вариантов еще может быть приставки.
Мне для чего нужно. Я перевожу книгу, и там одно слово перевожу определенным образом. А потом понимаю, что перевод должен быть другим. И я хочу найти все старые переводы слова и заменить на новый.
toly
Для этого подойдет лемматизация — приведение слова к нормальной форме
alexkuku Автор
Можно но это overkill. Лучше просто воспользоваться pymorphy2