
Всем привет! Я работаю в Avito и занимаюсь разработкой инструментов для тестирования. Когда у нас стало много UI-тестов, мы столкнулись с проблемой масштабирования Selenium-серверов, и сейчас я расскажу, как мы ее решили.
И так как же все-таки выполнять много UI-тестов параллельно, используя Selenium Grid? К сожалению — никак.
Selenium Grid не способен выполнять большое количество задач параллельно.
Хотите зарегистрировать действительно большое количество нод? Что ж, попробуйте.
Хотите скорости? Её не будет — чем больше нод зарегистрировано на гриде, тем менее стабильно выполняется каждый тест. Как следствие — перезапуски.
Хотите отказоустойчивость на случай, если Grid перестал отвечать? Тоже нет: вы не можете запустить несколько реплик и поставить перед ними балансировщик.
Хотите обновить Grid без даунтайма и чтобы тесты, выполняющиеся в данный момент, не упали? Нет, это не про Selenium Grid.
Хотите не держать тысячи Selenium-ов разных конфигураций в памяти, а поднимать их по требованию? Не получится.
Хотите знать, как решить все эти проблемы? Тогда приглашаю вас прочитать эту статью.
*(Мой доклад с таким же названием уже звучал на Heisenbug 2017 Moscow, и, возможно, кто-то из читателей с ним знаком. Под катом — более подробная текстовая версия рассказа об инструменте).

Небольшое отступление, о том как работает Selenium-сервер.
- Для того, чтобы начать управлять браузером нужно послать запрос
create sessionна Selenium-сервер. - В результате на ноде открывается браузер, а к вам возвращается токен
sessionId, отправляя который в каждом запросе, вы управляете браузером.
Окей, а зачем нужен Selenium Grid? Selenium Grid предоставляет единую точку для работы со множеством Selenium-серверов разной конфигурации:
- он позволяет создавать сессию на свободной ноде, подходящей под ваши критерии фильтрации, например, по версии браузера;
- хранит информацию о том, какая сессия открыта на какой ноде и проксирует все запросы на целевую ноду, таким образом для клиента нет разницы работать с одной нодой, или с гридом.
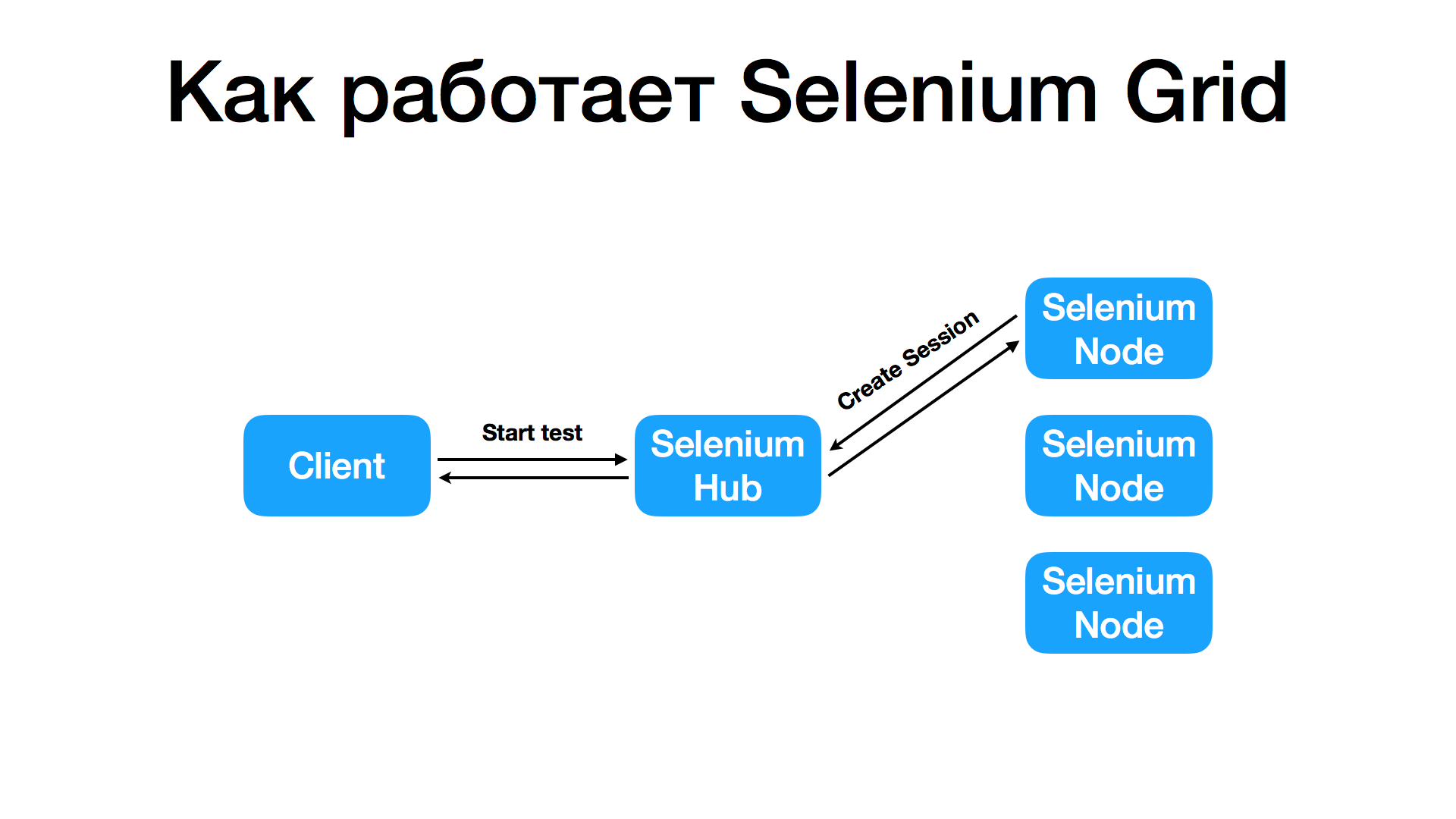
Замечательный инструмент, правда?

Но при его использовании мы столкнулись с рядом проблем.
1. Непредсказуемое поведение
Если кратко, то у вас отвалится что захочет и когда захочет, и вы никак не сможете на это повлиять.
- Мы очень часто сталкивались с ситуациями, когда тесты отлично работали в один поток, но при многопоточном выполнении через грид были непредсказуемые падения.

- Периодически на часть нод тесты просто не попадали, хотя физически они были доступны, на гриде скапливалась очередь из тестов. В итоге половина релизного сьюта отваливалась по таймауту.
2. Отсутствие поддержки большого количества нод
При попытке зарегистрировать много нод (а мы хотим много нод), регистрация произойдет, но протестировать приложение во много потоков все равно не получится, так как большая часть тестов упадет.

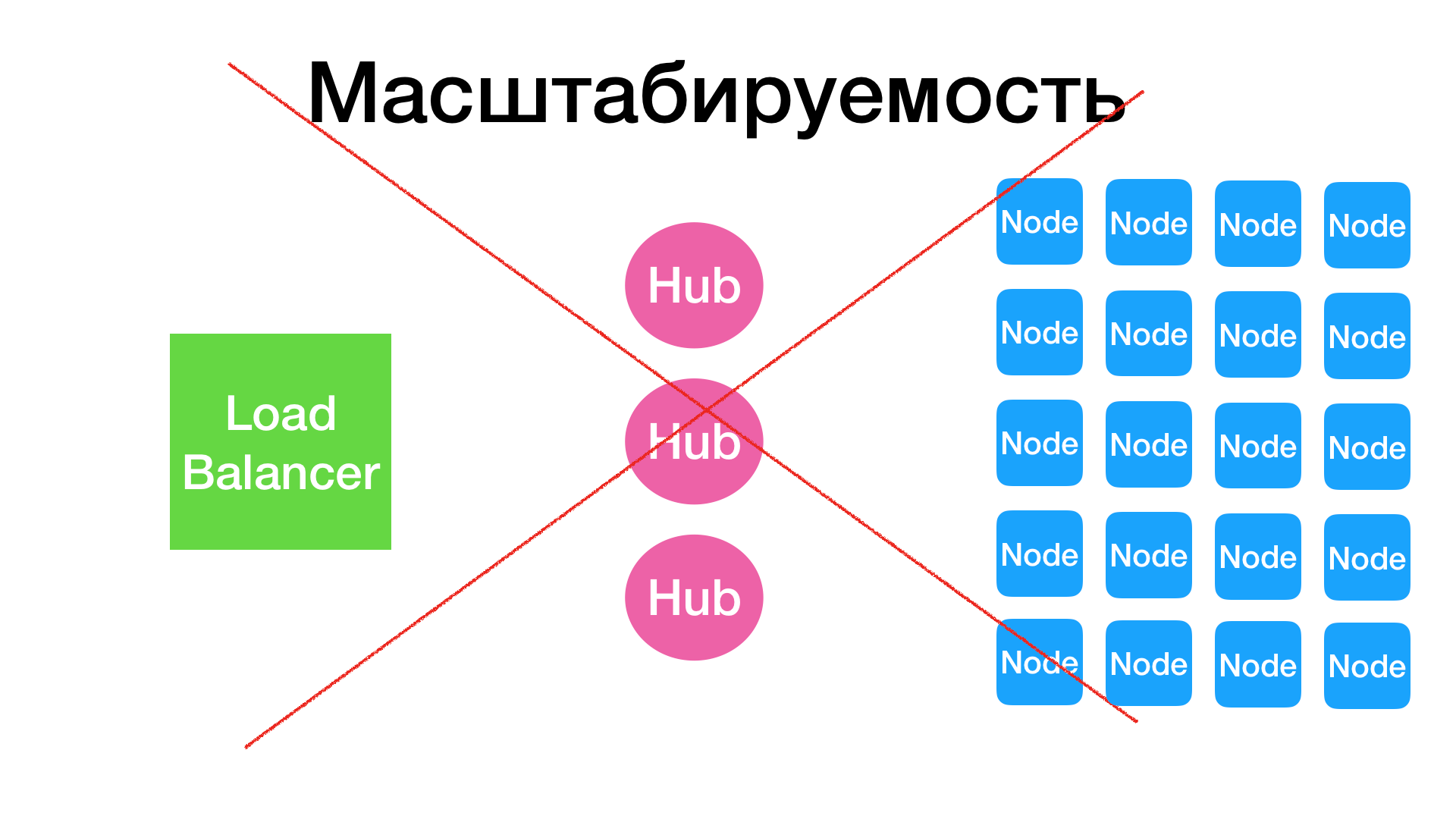
3. Масштабируемость
Первое, что приходит в голову, когда достигнут предел нод = N на селениум гриде, при котором не страдает стабильность, — это взять два, три, пять, (да хоть десять) гридов, зарегистрировать на каждый по N нод, вкрячить перед всем этим добром какой-нибудь балансировщик и запускать тесты в 10*N потоков. Но нет, Selenium Grid так не работает. Потому что вся информация о нодах и сессиях хранится в памяти у конкретной ноды и не шарится между ними. С этим тесно связана следующая проблема.
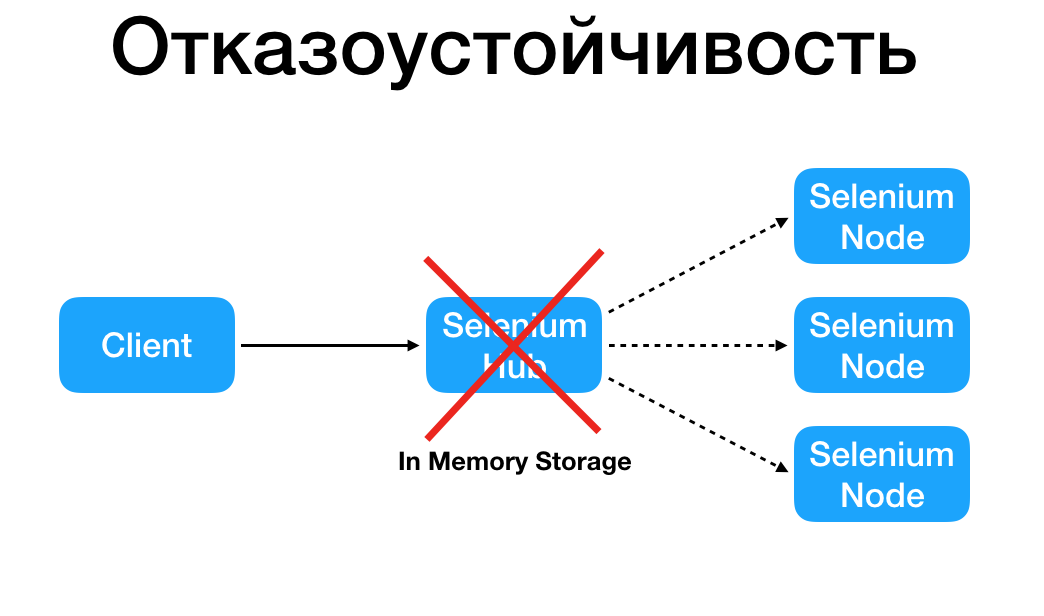
4. Отказоустойчивость
Если у вас выключается машина, где находится хаб, то все тесты сразу умирают, потому что у вас нет никаких резервных хабов, на которые могут идти следующие запросы, ибо опять же, все лежит в памяти. И это абсолютно никак не смасштабировать (конечно же, всегда можно переписать пару классов грида, но об этом позже). Слабое место — это Selenium Hub, при его падении ноды становятся недосягаемыми.
5. Отсутствие возможности динамического создания нод с использованием система оркестрации контейнерами
Если для тестирования вам необходимо множество различных конфигураций нод с разными конфигурациями браузеров, то возникает еще одна проблема: весь этот зоопарк занимает довольно много места в памяти. Предположим, у вас: 300 нод с Google Chrome (150GB RAM) + 300 нод с Firefox (150GB RAM) и еще 200 нод какого нибудь Firefox Nightly c магическими плагинами (100GB RAM). 400GB RAM постоянно заняты, плюс хочется эффективно перераспределять ноды в течение дня, скажем, занять все 400GB семью сотнями хромов при тестировании одного сьюта и гибко заменять их при появлении в очереди тестов с другими потребностями.
Для решения этой задачи идеально подойдет Docker, так как он позволяет быстро поднимать контейнер со свежим Selenium и так же быстро его убивать после завершения теста. И так как селениумов нам нужно много, на один железный сервер все это не влезет, возникает потребность в оркестрации контейнеров на кластере. На рынке существует несколько популярных решений для этой задачи, у нас используется Kubernetes. Почему мы выбрали Kubernetes, можно послушать здесь. Стандартными средствами Selenium эту проблему не решить.
6. Невозможно обновить/перезапустить грид без даунтайма
Еще одно следствие хранения сессий в памяти. Не то чтобы это суперкритичный минус, но всё равно неприятный.
Все вышеперечисленное — это ситуация, в которой мы в один прекрасный момент оказались.
Известные решения
Grid Router и новая реализация Go Grid Router — хорошее решение, но к сожалению далеко не идеальное. Основная проблема особенность, то что это не замена для Selenium Hub, это еще одна прокси сверху.
Отсюда и название — Grid Router, потому что он управляет не нодами, а гридами, поэтому есть минусы.
- Попытка создания новой сессии происходит не на гриде со свободными нодами, а на случайном (можно управлять распределением случайной величины при помощи весов). Если на одном из гридов не удалось создать сессию, запрос пойдет на следующий, и так пока не закончатся гриды. Таким образом время создания новой сессии может затягиваться на значительные промежутки времени.
- Если один из селениум хабов упадет, то вся информация о сессиях будет потеряна, а ноды отключены от сети. Так как до сих пор все взаимодействия идут через хаб и данные о сессиях хранятся в хабе.
- Довольно трудно добавить еще один хаб в систему, потому что данные о хабах хранятся в xml-файликах и синхронизация с файлами происходит по сигналу операционной системы. Транзакций нет, все плохо.
Selenoid — средство для запуска тестов в docker-контейнерах. При каждом запросе на создание сессии запускается свежий контейнер и при закрытии сессии удаляется. Инструмент замечательный, но есть минусы:
- не поддерживает ни одну систему оркестрации;
- все еще хранит информацию о сессиях в памяти, и, как следствие, имеет проблемы с масштабированием и отказоустойчивостью.
Когда мы столкнулись со всеми этими проблемами, мы решили поинтересоваться опытом других компаний. «Яндекс» писал в блоге на Habrahabr о том, что не получается регистрировать много нод и работать с ними, для решения этой проблемы они используют Grid Router. Для наших задач Grid Router не подходит.
«Альфа-Банк» писал о том, что у них все повисает, если grid какое-то время не использовать, и наш опыт это подтверждает — у нас то же самое было регулярно.
Конечно же мы не обделили вниманием github selenium, где нашли несколько issue… Вот пример отношения авторов к происходящему:
Q: «selenium-grid version 3.0+ support hub high availability?»
A: «I would recommend having a separate server monitor the hub and then if/when the hub goes down it would know how to restore the hub.»
Мы поняли, что надеяться нам не на что, и стали сами решать свои проблемы.
Исследование
Мы решили начать с простого пути, задеплоили в kubernetes кластер некоторое количество селениумов, сложили ip в БД и непосредственно в setUp() теста ходили в базу брали оттуда ip, который дольше всех не использовался и запускали тест, нигде не храня sessionId и не блокируя ноды. Так как воркеров с тестами было < количества селениумов, переполнения не должно было происходить.
Это решение сразу показало свою жизнеспособность.
Мы получили:
- предсказуемое поведение;
- отказоустойчивость на уровне БД;
- масштабируемость;
- поддержку большого количества нод;
- upgrade без остановки тестов, потому что это просто код, который лежит у вас в репозитории, и запускается, когда запускаются тесты.
Но столкнулись с рядом проблем:
- нет поддержки механизма выбора Capabilities;
- нет удобного механизма /grid/register;
- отсутстует Portability — система больше не работает как сервис, зависит от одного языка программирования и реализована в одном репозитории с тестами.
Последняя проблема — самая важная, потому что если вы зашиваете это в код тестового фреймворка, то вам автоматически нужно поддерживать это в каждом вашем тестовом фреймворке, во всех репозиториях на всех используемых языках.
Самое главное в этом эксперименте — полученный опыт. Мы убедились в том, что Selenium Grid можно реализовать нормально.
Окончательное решение
Первым делом мы стали рассматривать идею с форком/пулл реквестом селениума. Но после более детального знакомства с кодом проекта мы поняли, что дешевле и надежнее писать свой велосипед.
Давайте еще раз перечислим, что мы хотим от нового инструмента:
- предсказуемость поведения;
- отказоустойчивость;
- масштабируемость;
- portability;
- поддержка большого количества нод;
- поддержка Capabilities;
- on-demand Node in Kubernetes;
- сбор метрик в statsd;
- механизм /grid/register;
- upgrade без остановки тестов.
Что в итоге получилось:
- приложение, которое решает все вышеперечисленные задачи;
- кроссплатформенное приложение, тестировали на linux и macos;
- написано на Go;
- хранит данные в mysql.
В итоге нам удалось решить все задачи. Приложение написали на Go. Само приложение stateless — сессии хранятся в mysql, при желании не сложно поддержать любую другую БД. On-demand создание контейнеров реализовано только в Kubernrtes, но вы можете прислать пулл реквест с реализацией методов создания/удаления контейнера в любой другой системе. Go компилируется под разные платформы, но нам достаточно было протестировать работоспособность только на linux и macos, в теории других системах проблем быть не должно.
Теперь главный вопрос. Сколько нам строчек кода тестов пришлось переписать в процессе перехода на этот инструмент? Кто считает, что 10000/1000/100? Ноль! Ничего не надо было переписать, он полностью совместим. Просто нужно задеплоить приложение и указать его адрес, и все. Больше ничего делать не надо.
В итоге получилась такая схема:

Как этим пользоваться? Есть 2 режима:
- Persistent — здесь всё как раньше, запускаете селениум сервер c параметром
-role node, указываете где адрес хаба, нода регистрируется, можно пользоваться:
java -jar selenium-server.jar -role node -hub http://127.0.0.1:4444/grid/register
- On-demand — в конфиг грида нужно добавить докер-образы и информацию о том, какие capabilities они реализуют. Дальше запускаете грид, запрашиваете сессию, нода сама создается в кластере.
...
"type": "kubernetes",
"limit": 20,
"node_list": [
{
"params": {
"image":"myimage:latest",
"port": "5555"
},
"capabilities_list": [
{
"browserName": "firefox",
"browserVersion": 50
...Итог
Мы уже довольно долгое время используем это решение в продакшене, оно работает и не требует никакой поддержки. В процессе мы еще раз убедились в том, что не стоит бояться делать велосипеды. Популярные решения — это не всегда хорошо, нужно всегда исследовать возможности для решения проблем.
Комментарии (8)

podtserkovskiy Автор
29.03.2018 17:18+1Внутри кластера конфигурация у каждого будут отличаться в зависимости от версии kubernetes и практик принятых в компании. Бд можно положить снаружи и просто указать адрес в конфиге. Алгоритм strategy kubernetes: происходит сравнение capabilities из запроса с нодами из конфигурации из стратегии, при совпадаении создается под. Possible values поправил, спасибо за комментарий.
qwez
29.03.2018 21:10Не очень понятно, чем selenoid не подошел? Перед ним также можно поставить go grid router и балансер, проблем с масштабируемостью точно быть не должно. И оркестрация зачем вам? Обновлять образы контейнеров? У селеноид есть вроде менеджер конфигураций для этого.
А пулл реквестить селеноид и ggr не думали?podtserkovskiy Автор
29.03.2018 21:15Чем не подошел selenoid, написано в статье:
- не поддерживает ни одну систему оркестрации; - все еще хранит информацию о сессиях в памяти, и, как следствие, имеет проблемы с масштабированием и отказоустойчивостью.
Фундаментальная проблема в методе хранения сессий.
Образы обновляются в конфигурации, а оркестрация для гибкой работы с кластером.
podtserkovskiy Автор
29.03.2018 21:27Пулл реквест такого масштаба равен переписыванию selenoid. А ggr в нашем случае не нужен, так как мы решили проблему с другой стороны.

aandryashin
29.03.2018 22:05Да, Вы правы, недочеты есть, мы постарались исправить их в новом проекте:
aerokube.com/moon/latest/#_moon_vs_selenoid

vaniaPooh
30.03.2018 06:23Когда у вас взорвется под нагрузкой MySQL, расставленный в несколько датацентров, — вы знаете к кому идти. И система оркестрации тут вам не поможет. Системы, использующие БД для хранения сессий, пробовались 3 года назад.
podtserkovskiy Автор
30.03.2018 12:19+1Да, мы понимаем, что MySQL не самый подходящий для этого инструмент. И как только у нас появятся проблемы, сразу же напишем реализацию под другое хранилище, архитектура проекта позволяет очень легко это сделать. За счет наличия локального кеша в памяти у каждого инстанса приложения обращений к бд не так много.
RouR
Про Kubernetes немного непонятно.
В вашей инструкции github.com/qa-dev/jsonwire-grid прописан запуск локально, а не внутри кластера.
Итоговое решение для Kubernetes как конфигурировать? Можно ли положить всё, кроме БД, вовнутрь кластера. Какой алгоритм у strategy kubernetes и почему Possible values везде описаны как "-"?