
Много ли мы генерируем данных, используя информационные системы каждый день? Огромное количество! Но знаем ли мы все возможности по работе с такими данными? Определенно, нет! В рамках этой статьи мы расскажем какие типы данных мы можем загружать для дальнейшего операционного анализа в Splunk, а также покажем как подключить загрузку логов Fortinet и логов нестандартной структуры, которые необходимо разделять на поля вручную.
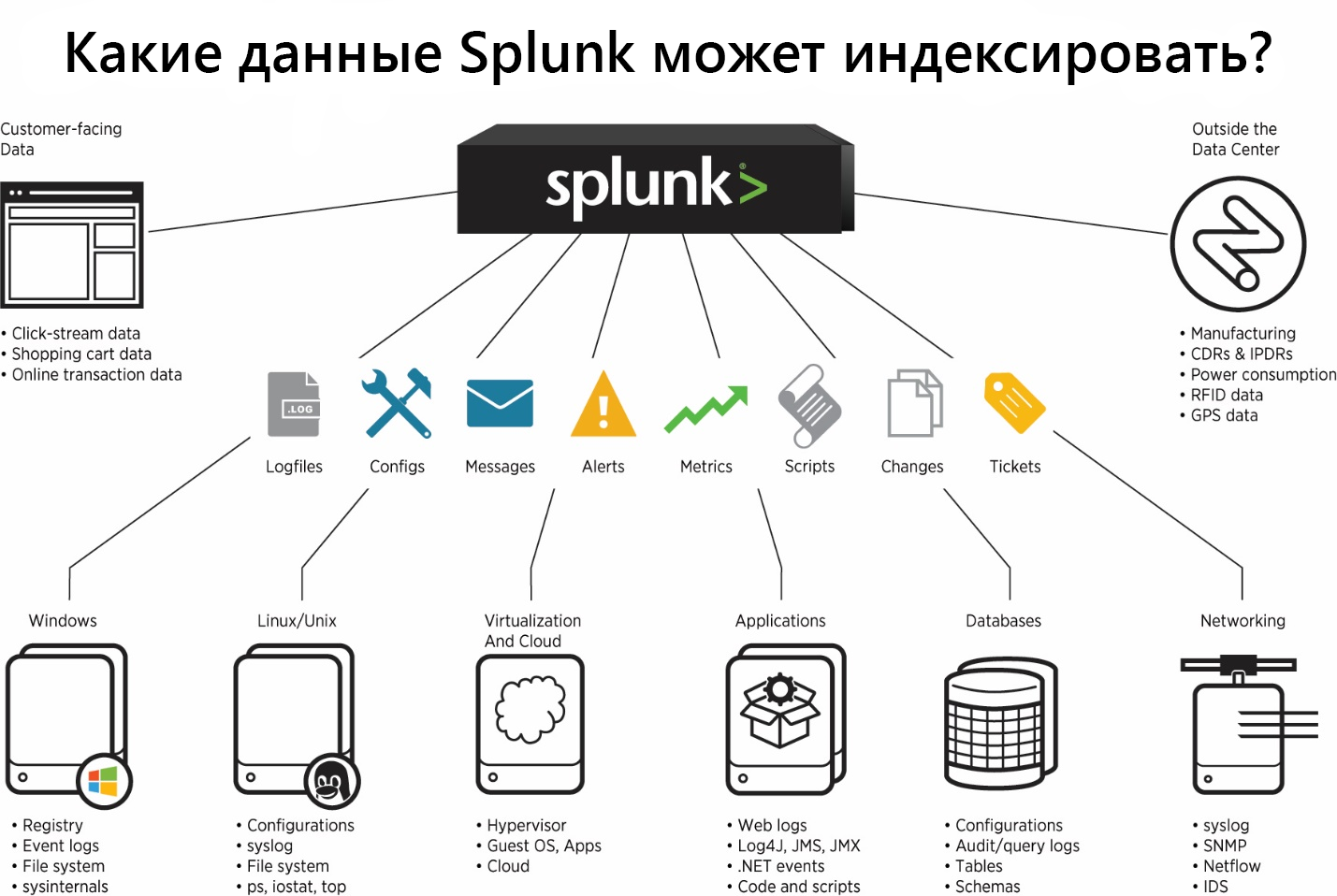
Splunk может индексировать данные с различных источников, которые могут хранить логи как локально на одной машине с Splunk-индексером, так и на удаленном устройстве. Для сбора данных с удаленных машин на них ставится специальный агент – Splunk Universal Forwarder, который будет отправлять данные на индексер.
Splunk предлагаем множество уже готовых приложений и надстроек (Add-ons) с предварительно настроенными параметрами для загрузки определенного типа данных, например Add-on есть для данных, генерируемых Windows, Linux, Cisco, CheckPoint и тд. Всего на данный момент создано более 800 аддонов, которые можно найти на сайте SplunkBase.
Все поступающие данные можно разделить на несколько групп по их источникам:
Файлы и каталоги
Большинство данных поступает в Splunk непосредственно из файлов и каталогов. Необходимо просто указать путь к каталогу, из которого вы хотите забирать данные и после этого он будет постоянного его мониторить и по мере появления новых данных они будут сразу подгружаться в Splunk. Далее в этой статье мы покажем, как это реализуется.
Сетевые события
Также Splunk может индексировать данные с любого сетевого порта, например удаленные данные syslog или других приложений, которые передают данные по TCP или UDP порту. Этот тип источника данных мы далее рассмотрим на примере Fortinet.
Источники Windows
Splunk позволяет настраивать загрузку множества различных данных
Windows, например данные журнала событий, реестра, WMI, Active Directory, а также данные мониторинга производительности. Более подробно о загрузке данных из Windows в Splunk мы писали в предыдущей статье. (ссылка)
Другие источники данных
Уже реализовано множество инструментов, которые могут осуществлять загрузку почти любых ваших данных, но если даже из них вам ничего не подходит, то можно создать собственные скрипты или модули, о которых мы поговорим с одной из следующих статей.
В данном разделе мы разберем, как реализовать загрузку логов Fortinet.
1. Сначала необходимо скачать Add-on с сайта SplunkBase по этой ссылке.
2. Далее необходимо установить его на Ваш Splunk-indexer ( Apps — Manage Apps — Install app from file).
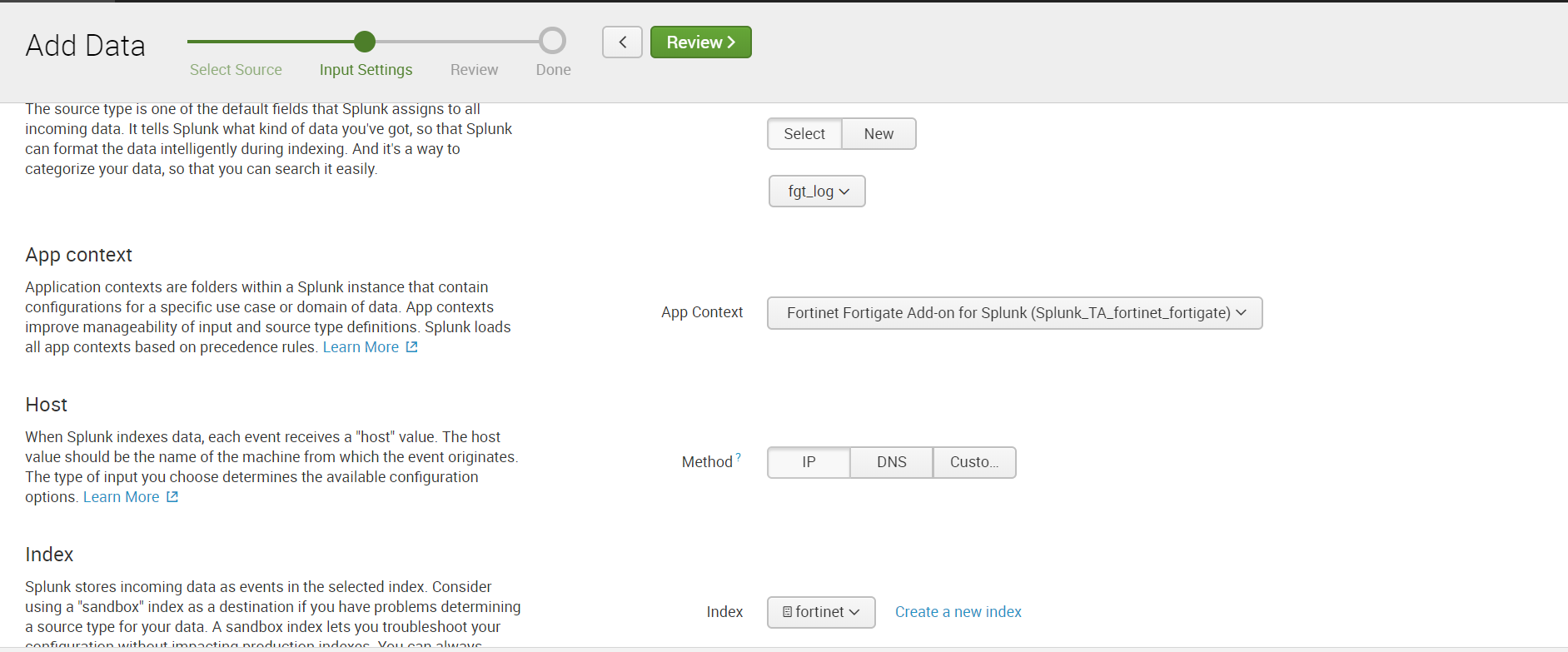
3. Затем настраиваем прием данных по порту UDP. Для этого необходимо пройти: Settings – Data Inputs – UDP – New. Указываем порт, по умолчанию это 514 порт.

Выбираем Sourcetype: fgt_log, также выбираем необходимый индекс или создаем новый.
4. Настраиваем отправку данных по UDP в самом Fortinet, указывая такой же порт, что и в Splunk.
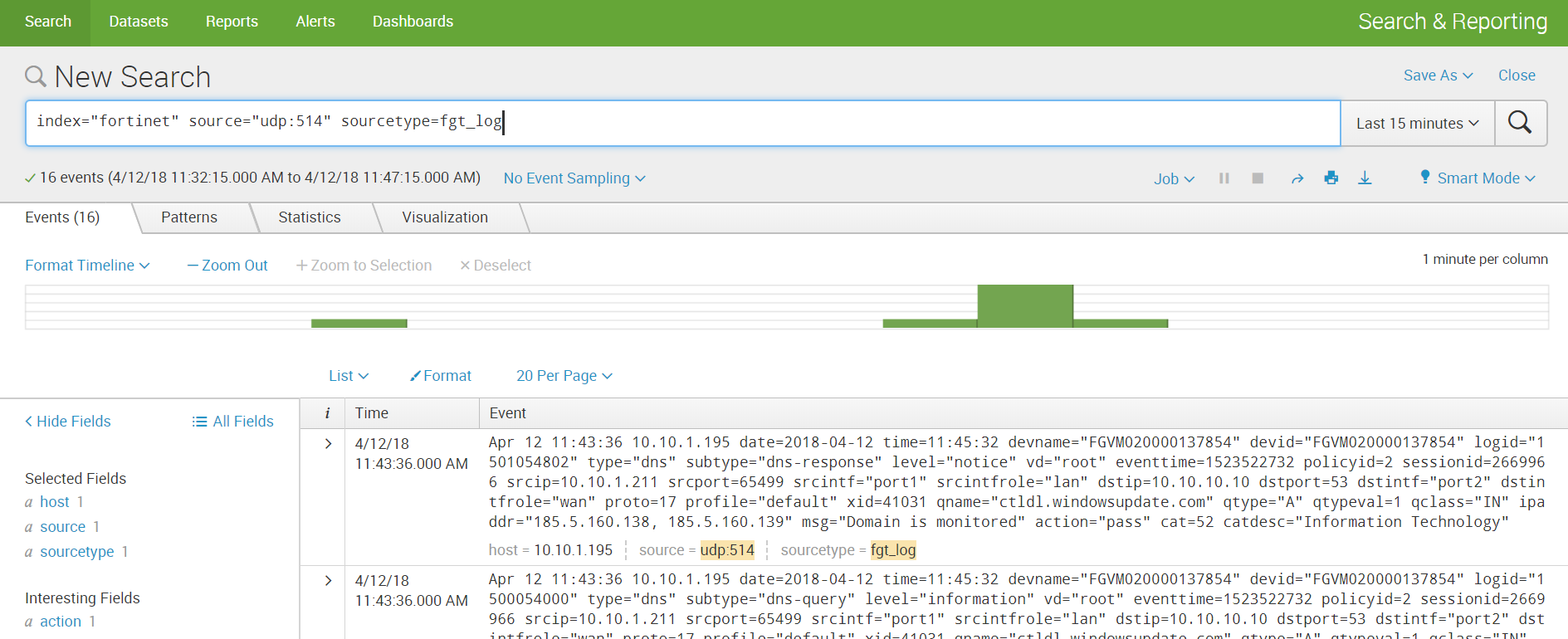
5. Получаем данные и строим аналитику.

Под нестандартным логом мы будем понимать лог, который имеет неизвестный для Splunk sourcetype, и поэтому не имеет заранее прописанных правил разбора на поля. Для того чтобы получить значения полей необходимо будет предварительно совершить несколько несложных манипуляций.
На примере этого лога помимо разбора мы покажем, как реализовать загрузку данных из каталогов. Есть два сценария развития, которые зависят от того, где лежат данные: на локальной машине индексера или на удаленной машине.
Если Ваши данные хранятся на локальной машине Splunk, то загрузка осуществляется очень легко:
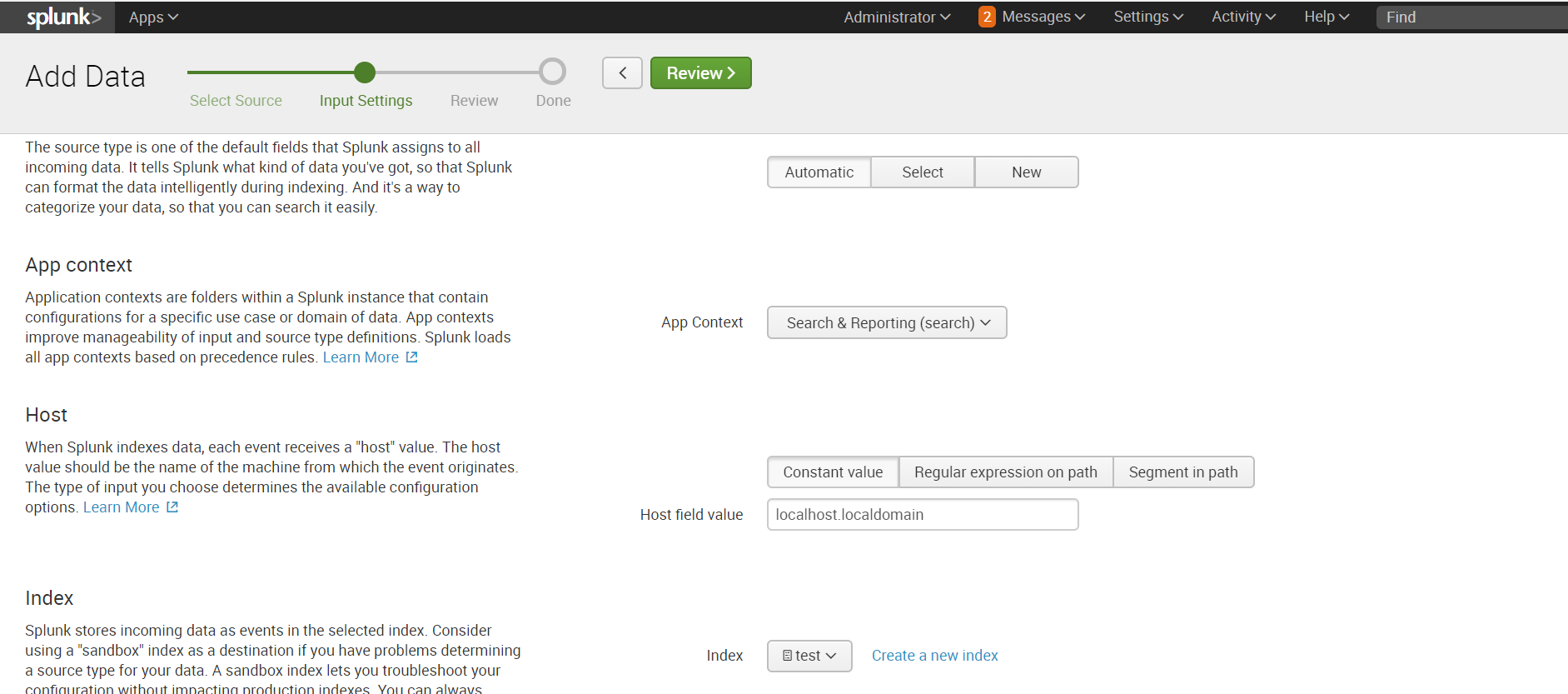
Settings – Add data – Monitor – Files & Directories

Выбираем необходимый каталог, если необходимо можем прописать Whitelist или Blacklist.
Выбираем индекс или создаем новый, остальное по дефолту.
Если каталог, в котором хранятся нужные данные находится на удаленной машине, то алгоритм действия будет несколько другим. Для забора данных нам понадобится агент на целевой машине (Splunk Universal Forwarder), настроенный Forwarder Management на Splunk индексере, приложение sendtoindexer и приложение которое расскажет какие каталоги мы будет просматривать.
Подробно как устанавливать агента и настраивать забор данных с удаленной машины мы рассказывали в предыдущей статье, поэтому повторяться не будем и предположим, что все те настройки у Вас уже есть.
Создадим специальное приложение, которое будет отвечать на то, чтобы агент пересылал данные из указанных каталогов.

Приложение автоматически сохраняется в папке ..splunk/etc/apps, необходимо перенести его в папку ..splunk/etc/deployment-apps.
В папку ..monitor/local необходимо поместить конфигурационный файл inputs.conf, в котором мы укажем какие папки необходимо пересылать.
Мы хотим просматривать папку test, лежащую в корневом каталоге.
Подробнее о файлах inputs.conf можно прочитать на официальном сайте.
Добавляем приложение в Server Class, относящийся к целевой машине. Как и зачем это необходимо делать, мы говорили в предыдущей статье.
На напомним, что это можно сделать, пройдя по следующему пути: Settings – Forwarder Management.
Для того, чтобы данные загружались необходимо, чтобы существовал индекс, который был указан в inputs.conf, если его нет, то создайте новый.
После загрузки мы получили данные не разделенные на поля. Для того чтобы выделить поля необходимо перейти в меню Extract Fields (All Fields – Extract New Fields)

Разбирать на поля можно с помощью встроенного инструментария, который на основе регулярных выражений выделит поля, которые вы укажете. Либо можно самостоятельно прописать регулярное выражение, если результат автоматической работы вас не устраивает.
Шаг 1. Выбираем поле

Шаг 2. Выбираем метод разделения
Мы будем использовать регулярные выражения.

Шаг 3. Выделяем значения, которые будут относиться к одному полю и называем его.

Шаг 4. Проверяем правильно ли в других событиях выделилось поле, если нет, то добавляем это событие в выбранные поля.

Шаг 5. Выбираем поле во всех различных по структуре событиях.
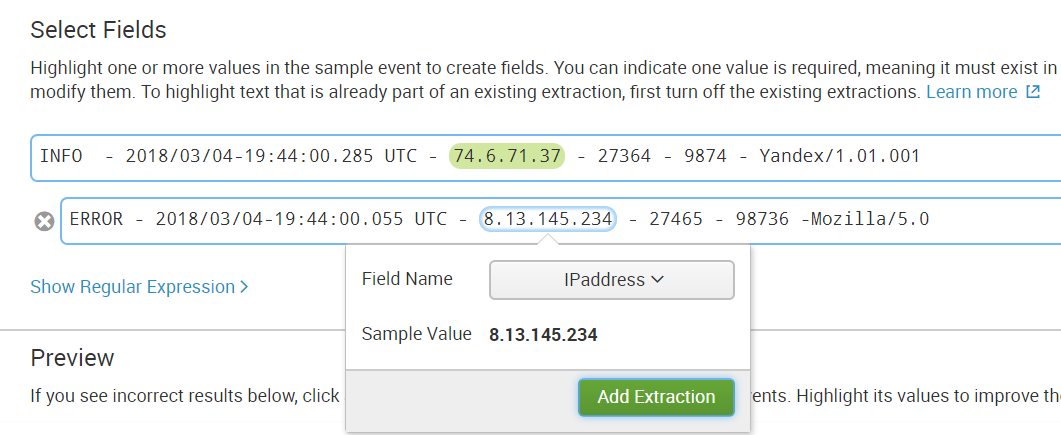
Шаг 6. Проверяем не выделилось ли что-то лишнее, если, например, в событии нет такого поля.
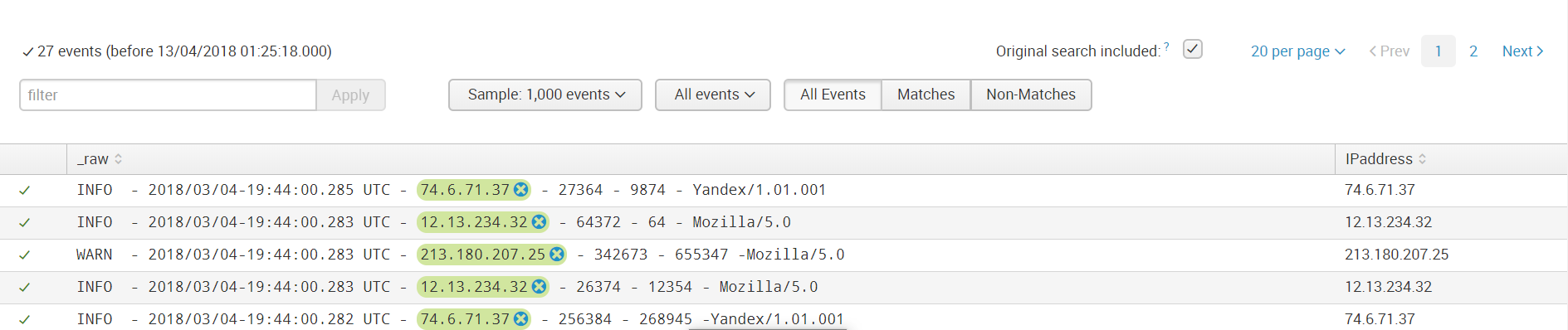
Затем сохраняем поле и теперь при загрузке данных с таким же sourcetype к ним будет применяться такое правило выделения значения поля.
Далее мы создаем все поля, которые нам необходимы. И теперь данные готовы для дальнейшего анализа.
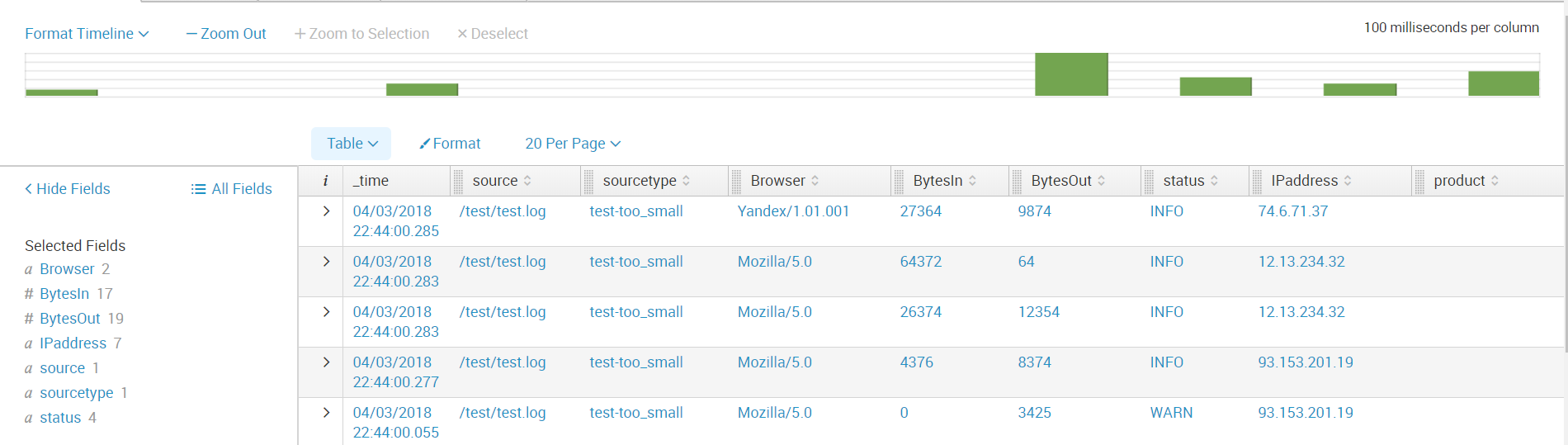
Таким образом, мы рассказали вам из каких источников можно загружать данные в Splunk, показали, как настроить получения с сетевых портов, а также как загрузить и распарсить нестандартный лог.
Надеемся, что эта информация будет полезна для Вас.
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Мы являемся официальным Premier Партнером Splunk.

Splunk может индексировать данные с различных источников, которые могут хранить логи как локально на одной машине с Splunk-индексером, так и на удаленном устройстве. Для сбора данных с удаленных машин на них ставится специальный агент – Splunk Universal Forwarder, который будет отправлять данные на индексер.
Splunk предлагаем множество уже готовых приложений и надстроек (Add-ons) с предварительно настроенными параметрами для загрузки определенного типа данных, например Add-on есть для данных, генерируемых Windows, Linux, Cisco, CheckPoint и тд. Всего на данный момент создано более 800 аддонов, которые можно найти на сайте SplunkBase.
Типы источников данных
Все поступающие данные можно разделить на несколько групп по их источникам:
Файлы и каталоги
Большинство данных поступает в Splunk непосредственно из файлов и каталогов. Необходимо просто указать путь к каталогу, из которого вы хотите забирать данные и после этого он будет постоянного его мониторить и по мере появления новых данных они будут сразу подгружаться в Splunk. Далее в этой статье мы покажем, как это реализуется.
Сетевые события
Также Splunk может индексировать данные с любого сетевого порта, например удаленные данные syslog или других приложений, которые передают данные по TCP или UDP порту. Этот тип источника данных мы далее рассмотрим на примере Fortinet.
Источники Windows
Splunk позволяет настраивать загрузку множества различных данных
Windows, например данные журнала событий, реестра, WMI, Active Directory, а также данные мониторинга производительности. Более подробно о загрузке данных из Windows в Splunk мы писали в предыдущей статье. (ссылка)
Другие источники данных
- Метрики
- Скрипты
- Кастомные модули загрузки данных
- HTTP Event Collector
Уже реализовано множество инструментов, которые могут осуществлять загрузку почти любых ваших данных, но если даже из них вам ничего не подходит, то можно создать собственные скрипты или модули, о которых мы поговорим с одной из следующих статей.
Fortinet
В данном разделе мы разберем, как реализовать загрузку логов Fortinet.
1. Сначала необходимо скачать Add-on с сайта SplunkBase по этой ссылке.
2. Далее необходимо установить его на Ваш Splunk-indexer ( Apps — Manage Apps — Install app from file).
3. Затем настраиваем прием данных по порту UDP. Для этого необходимо пройти: Settings – Data Inputs – UDP – New. Указываем порт, по умолчанию это 514 порт.
Выбираем Sourcetype: fgt_log, также выбираем необходимый индекс или создаем новый.
4. Настраиваем отправку данных по UDP в самом Fortinet, указывая такой же порт, что и в Splunk.
5. Получаем данные и строим аналитику.
Нестандартный лог
Под нестандартным логом мы будем понимать лог, который имеет неизвестный для Splunk sourcetype, и поэтому не имеет заранее прописанных правил разбора на поля. Для того чтобы получить значения полей необходимо будет предварительно совершить несколько несложных манипуляций.
На примере этого лога помимо разбора мы покажем, как реализовать загрузку данных из каталогов. Есть два сценария развития, которые зависят от того, где лежат данные: на локальной машине индексера или на удаленной машине.
Локальная машина
Если Ваши данные хранятся на локальной машине Splunk, то загрузка осуществляется очень легко:
Settings – Add data – Monitor – Files & Directories
Выбираем необходимый каталог, если необходимо можем прописать Whitelist или Blacklist.
Выбираем индекс или создаем новый, остальное по дефолту.
Удаленная машина
Если каталог, в котором хранятся нужные данные находится на удаленной машине, то алгоритм действия будет несколько другим. Для забора данных нам понадобится агент на целевой машине (Splunk Universal Forwarder), настроенный Forwarder Management на Splunk индексере, приложение sendtoindexer и приложение которое расскажет какие каталоги мы будет просматривать.
Подробно как устанавливать агента и настраивать забор данных с удаленной машины мы рассказывали в предыдущей статье, поэтому повторяться не будем и предположим, что все те настройки у Вас уже есть.
Создадим специальное приложение, которое будет отвечать на то, чтобы агент пересылал данные из указанных каталогов.
Приложение автоматически сохраняется в папке ..splunk/etc/apps, необходимо перенести его в папку ..splunk/etc/deployment-apps.
В папку ..monitor/local необходимо поместить конфигурационный файл inputs.conf, в котором мы укажем какие папки необходимо пересылать.
Мы хотим просматривать папку test, лежащую в корневом каталоге.
[monitor:///test]
index=test
disabled = 0Подробнее о файлах inputs.conf можно прочитать на официальном сайте.
Добавляем приложение в Server Class, относящийся к целевой машине. Как и зачем это необходимо делать, мы говорили в предыдущей статье.
На напомним, что это можно сделать, пройдя по следующему пути: Settings – Forwarder Management.
Для того, чтобы данные загружались необходимо, чтобы существовал индекс, который был указан в inputs.conf, если его нет, то создайте новый.
Парсинг данных
После загрузки мы получили данные не разделенные на поля. Для того чтобы выделить поля необходимо перейти в меню Extract Fields (All Fields – Extract New Fields)
Разбирать на поля можно с помощью встроенного инструментария, который на основе регулярных выражений выделит поля, которые вы укажете. Либо можно самостоятельно прописать регулярное выражение, если результат автоматической работы вас не устраивает.
Шаг 1. Выбираем поле
Шаг 2. Выбираем метод разделения
Мы будем использовать регулярные выражения.
Шаг 3. Выделяем значения, которые будут относиться к одному полю и называем его.
Шаг 4. Проверяем правильно ли в других событиях выделилось поле, если нет, то добавляем это событие в выбранные поля.
Шаг 5. Выбираем поле во всех различных по структуре событиях.
Шаг 6. Проверяем не выделилось ли что-то лишнее, если, например, в событии нет такого поля.
Затем сохраняем поле и теперь при загрузке данных с таким же sourcetype к ним будет применяться такое правило выделения значения поля.
Далее мы создаем все поля, которые нам необходимы. И теперь данные готовы для дальнейшего анализа.
Заключение
Таким образом, мы рассказали вам из каких источников можно загружать данные в Splunk, показали, как настроить получения с сетевых портов, а также как загрузить и распарсить нестандартный лог.
Надеемся, что эта информация будет полезна для Вас.
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Мы являемся официальным Premier Партнером Splunk.