
Нам часто задают вопросы о том, как загрузить различные данные в Splunk. Одними из самых распространенных источников, представляющих интерес, оказались логи Windows и Linux, которые позволяют отслеживать неполадки операционных систем и управлять ими. Загружая данные в Splunk, Вы можете анализировать работу всех систем в одном месте, даже когда у Вас десятки или сотни различных источников.

В данной статье мы пошагово объясним Вам, как загрузить данные из Windows и Linux в Splunk, для последующей обработки и анализа.
Для того, чтобы начать собирать данные нам необходимы следующие элементы системы:
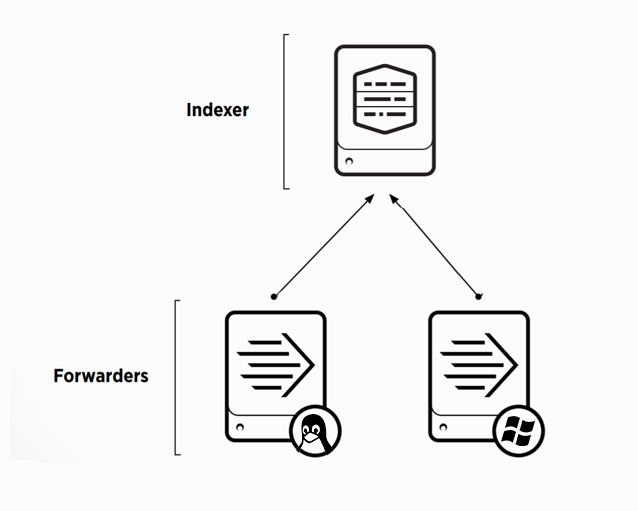
Для того, чтобы загружать логи в Splunk, необходимо сначала предварительно настроить индексер, для этого потребуется:
На этом этапе мы заканчиваем предварительную настройки индексера и переходим к установке агентов на машины Windows и Linux.
Универсальным инструментом для загрузки логов является специальный агент – Splunk Universal Forwarder. Universal Forwarder представляет собой версию Splunk Enterprise с существенно ограниченным функционалом, единственной задачей которого является сбор данных с хоста и отправка их.
Скачать его можно по этой ссылке.
На картинке выше видно, что Universal Forwarder можно установить как на Windows, так и на Linux, Solaris и другие операционные системы.
1. Устанавливаем Universal Forwarder
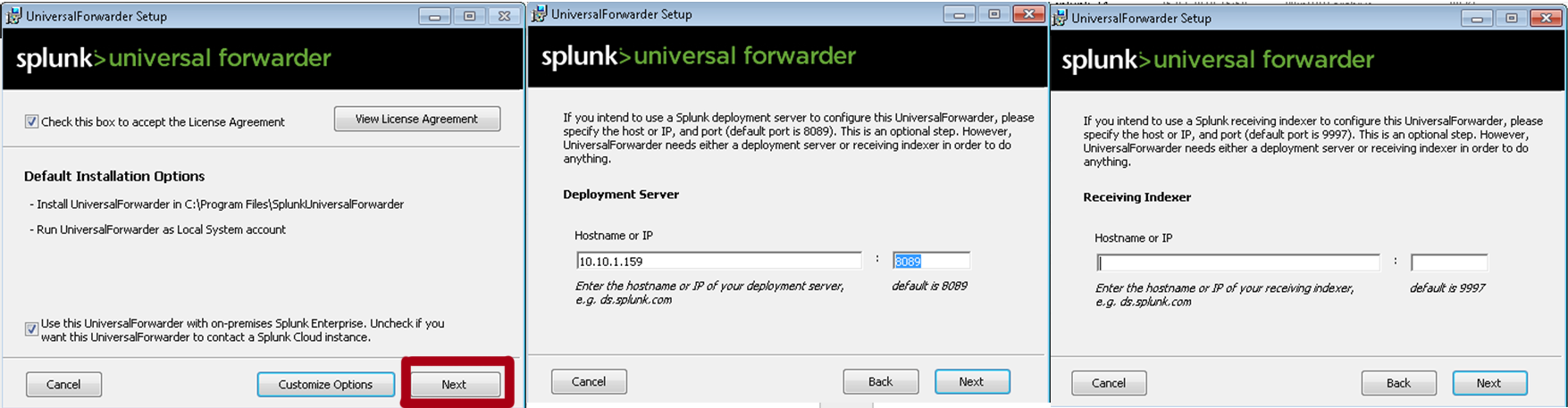
В качестве Deployment Server указываем IP-адрес или название Splunk индексера, где мы создали приложение «Send to indexer». Порт по умолчанию: 8089. Раздел Receiving Indexer оставим пустым, так как эти функции выполнит «Send to indexer».
2. Следующий шагом нам необходимо вернуться к Splunk и определить класс сервера для приложения «Send to indexer».
Класс сервера что-то похожее на правило, в котором мы указываем какие приложения мы будем распределять между какими целевыми машинами-клиентами. Критериями для формирования разных классов сервера могут стать тип машины, ОС, географическая область или тип приложения, причем классы могут пересекаться между собой. (Более подробно можно прочитать на официальном сайте)
Settings — Forwarder Management — edit action — add new classes.

3. После сохранения вам будет предложено добавить приложения, которые мы будем рассылать и целевые системы, так называемые клиенты, которым мы будем их рассылать.
Добавляем «Send to indexer» в раздел приложений.
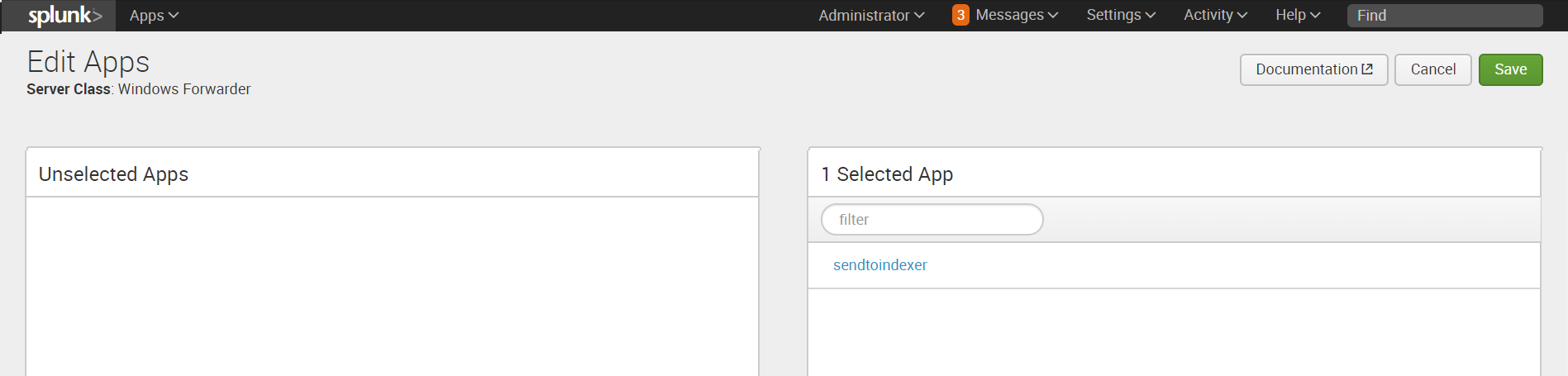
4. Затем добавляем клиента. Клиентом будет наша машина с Windows, на которую мы установили Universal Forwarder. Если Universal Forwarder был установлен правильно, то машина должна появиться в списке клиентов, подключенных к Deployment Server. Заносим ее в Include (whitelist).

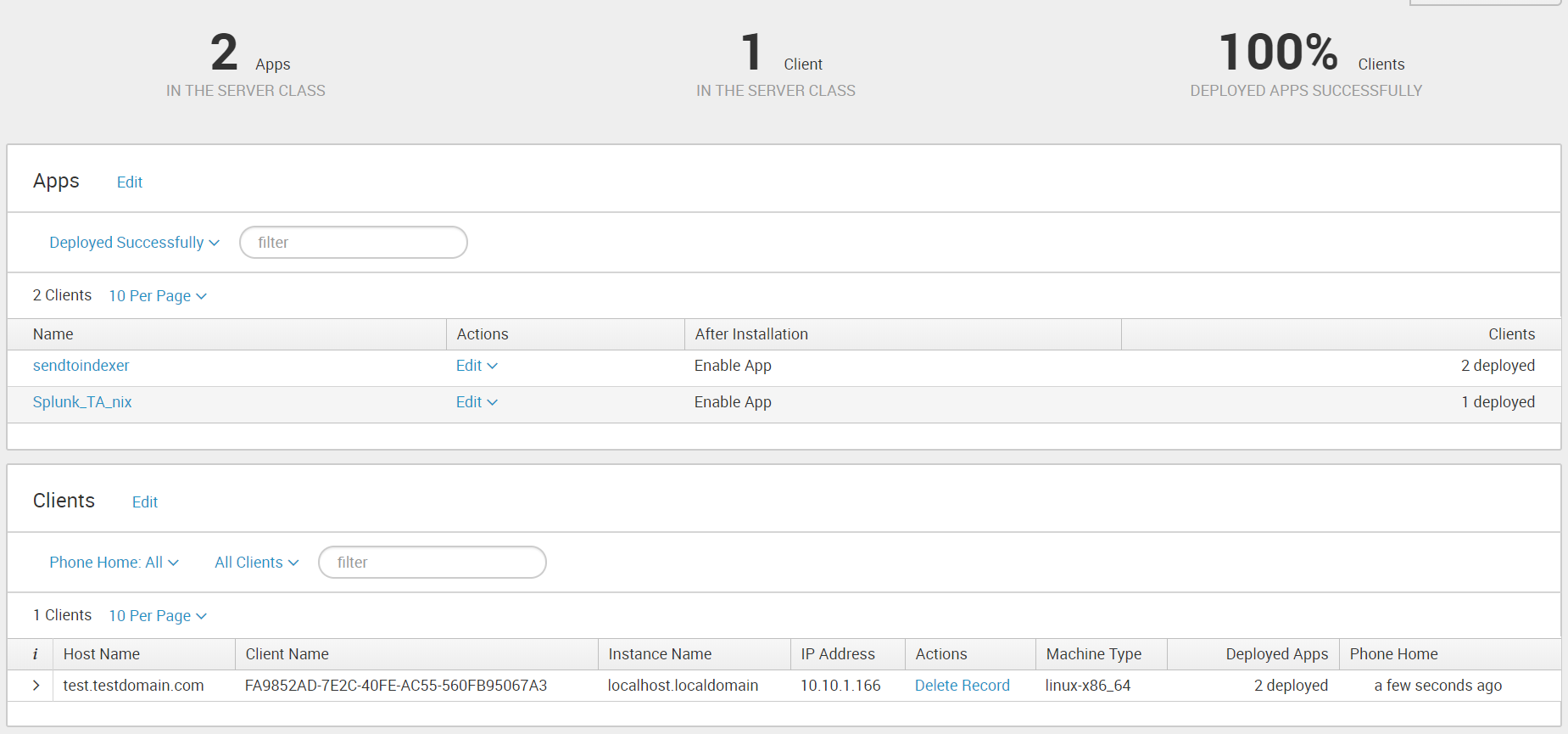
5. Проверить правильно ли все работает можно, посмотрев на содержимое индекса _internal. После добавления «Send to indexer» в класс сервера Universal Forwarder начинает отправлять свои внутренние логи туда. Также в этом индексе далее мы можем следить за тем, правильно ли работают наши агенты.
6. Далее скачиваем специальный Add-on с сайта SplunkBase, который позволяет собирать данные о работе Windows.
7. Устанавливаем приложение на Splunk-Indexer ( Apps — Manage Apps — Install app from file)
По умолчанию оно устанавливается в каталог ...\Splunk\etc\apps\Splunk_TA_windows, но нам необходимо скопировать его в папку deployment-apps, чтобы это приложение было доступно для deployment server, чтобы потом мы могли отправить его на другие машины также, как и «Send to indexer». (Важно: в папке apps оно также должно остаться, чтобы на индексере сформировались нужные нам индексы для данных).
8. Затем необходимо сделать преднастройку приложения.
Переходим в каталог ...\Splunk\etc\deployment-apps\Splunk_TA_windows
Создаем в нем под-каталог «local» (Важно: Вносить изменения в конфигурационные файлы необходимо всегда в каталоге local).
Скопируем файл inputs.conf из ...\Splunk\etc\deployment-apps\Splunk_TA_windows\default\inputs.conf в каталог local.
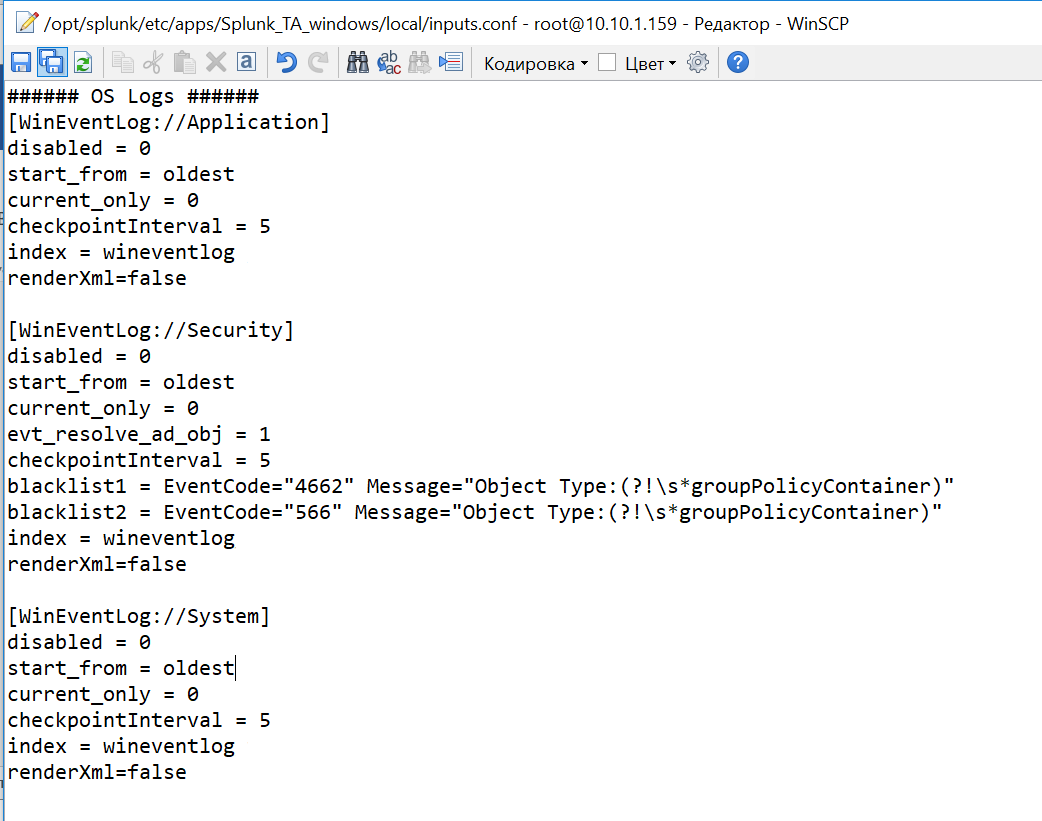
Включим индексацию требуемых данных. Для этого в файле inputs.conf из каталога local через текстовый редактор делаем некоторые изменения. Заменим значения disabled=1 на disabled=0 в необходимых блоках файла. Давайте добавим логи системы по Application, Security, System.
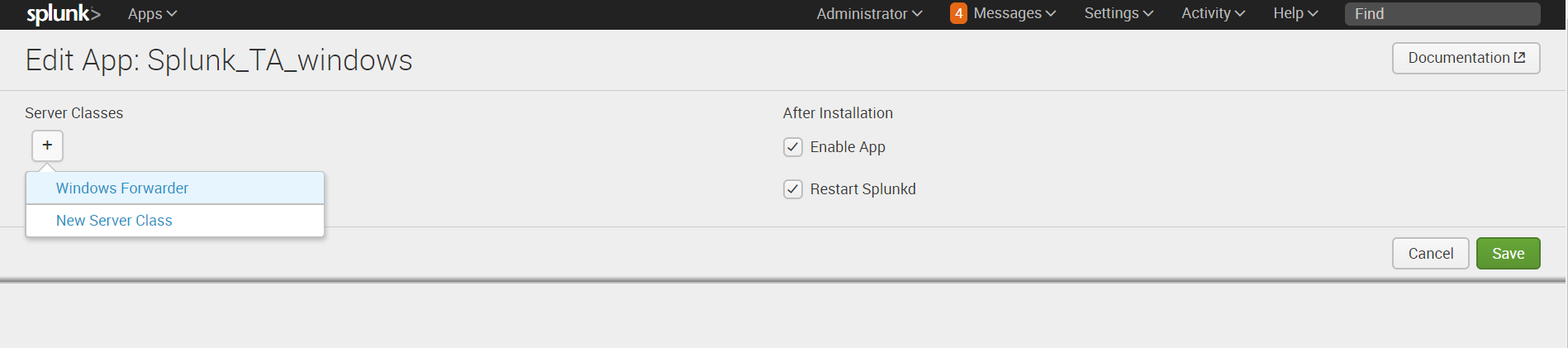
9. Далее, на Splunk-indexer, добавляем к приложению созданный ранее сервер-класс. (Settings — Forwarder Management — Apps — Splunk_TA_Windows – «+» — Windows Forwarder)
10. Перезагрузим deployment server, это можно сделать через командную строку из каталога … /splunk/bin:
Проверям, загружаются ли данные. (Settings – Indexes ) Они должны попадать в индекс wineventlog. Как видно на нашем рисунке последние данные, которые были загружены на данный момент имеют временную метку 3 минуты назад.

Одним из инструментов, позволяющих повысить уровень безопасности в Linux, является подсистема аудита auditd. C её помощью можно получить подробную информацию обо всех системных событиях. Именно данные, генерируемые этой системой мы будем индексировать в Splunk.
(Код будет представлен для Linux CentOS)
1. Проверим, если ли на машине предустановленная система аудита, если нет установим ее.
Добавим новое правило, которое мы будем отслеживать.
Проверить его наличие можно с помощью функции.
Логи, генерируемые auditd попадают в файл:
2. Далее, установим Universal Forwarder. Найти дистрибутив можно по ссылке.
Следует скачать файл формата .rpm, после скачивания которого появится возможность получить wget ссылку.
3. Далее на создадим нового пользователя, который будет отвечать за работу со splunk.
4. Дадим разрешения пользовалелю, которого мы только что создали и запустим UniversalForwarder от его имени.
5. Проведем настройку форвардера и укажем Deployment Server, также как в части с Windows, это IP-адрес или имя Splunk-indexer/
6. Можно проверить, работает ли форвардер, следующим образом:
7. Далее переходим в Splunk-indexer и устанавливаем на него специальный Add-on, позволяющий передавать логи с Linux. Скачать дистрибутив можно по ссылке.
8. После установки, находим папку с приложением по следующему адресу ../splunk/etc/apps/Splunk_TA_nix. Копируем папку Splunk_TA_nix из apps в deployment-apps. Чтобы это приложение появилось как доступное для deployment server.
В каталоге …/ deployment-apps/Splunk_TA_nix создаем папку local и копируем в нее файл input.conf из папки ../Splunk_TA_nix/default.
В файл …/ deployment-apps/Splunk_TA_nix/ local/ input.conf через текстовый редактор вносим изменения, которые покажут данные из каких папок мы хотим собирать. В нашем случае это /var/log/audit.
В input.conf есть раздел [monitor:///var/log], в котором необходимо изменить disabled=1 на disabled=0 (Важно: убедитесь, что необходимая папка есть в whitelist, если ее нет, но нужно ее добавить)
9. Далее проверим, увидел ли Deployment server нового клиента, нашу машину Linux. (Settings — Forwarder Management – Clients).
Если ее нет, то необходимо проверить название (Host name) машины, если он совпадает с названием машины индексера, то необходимо его изменить, иначе возникает ошибка.
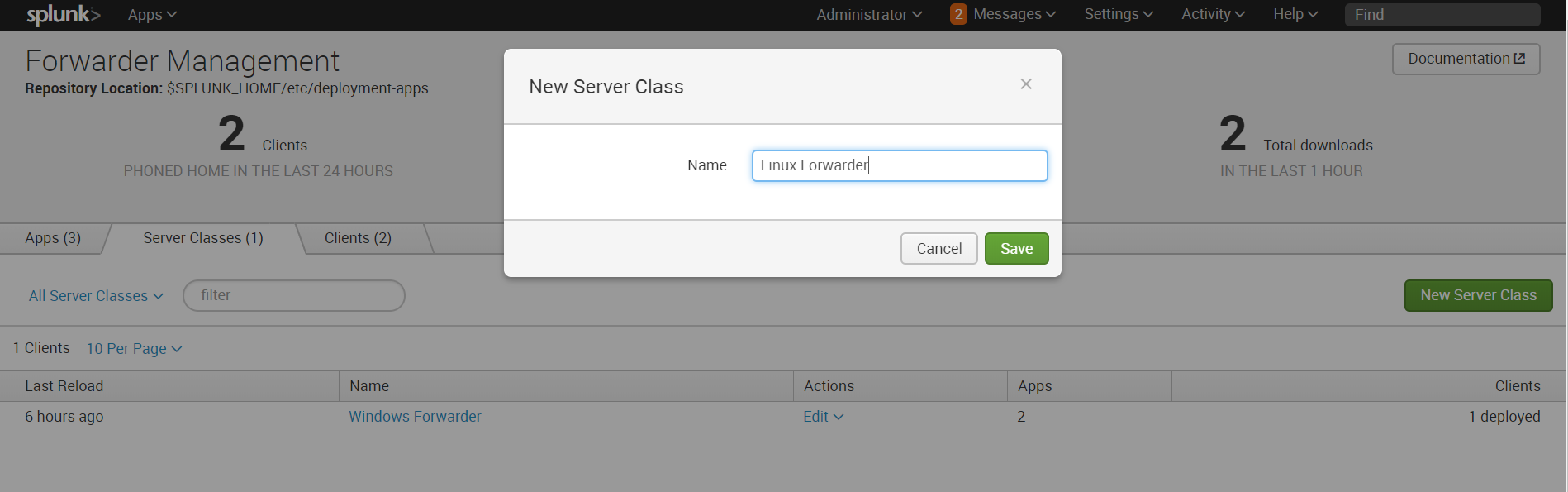
10. Затем создаем новый сервер класс, относящийся к Linux.
Settings — Forwarder Management – Server Classes — New Server Class
11. Добавляем в этот класс приложения «Send to indexer» и «Splunk_TA_nix», а в качестве клиента добавляет машину Linux.
Обратите внимание, что файлы не будут загружаться, если у Universal Forwarder (у юзера, под которым мы используем Universal Forwarder) нет доступа к папкам, которые необходимо мониторить. Так что необходимо учесть этот момент и разрешить доступ.
12. В конце необходимо перезагрузить deployment server, это можно сделать через командную строку из каталога … /splunk/bin :
После проведения выше описанных операций, Вы получите логи Linux, которые будут загружены в индекс OS.
Таким образом, мы показали вам, как загрузить ваши логи из Windows и Linux в Splunk для дальнейшего анализа и обработки. Надеемся, что эта информация будет полезна для Вас.
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Мы являемся официальным Premier Партнером Splunk.

Данный курс предназначен для ознакомления с платформой Splunk. Слушатели курса получат как теоретические знания о работе с системой, так и практические навыки работы, включая построение поисковых запросов, различных визуализаций и дашбордов.
Участие в обучении бесплатное
Необходима предварительная регистрация.
Дата: 19 апреля (четверг)
Время: 10:00 — 17:00
Место: г. Санкт-Петербург, «Технопарк „Ингрия“, пр. Медиков, 3а
В данной статье мы пошагово объясним Вам, как загрузить данные из Windows и Linux в Splunk, для последующей обработки и анализа.
Настройка базовой инфраструктуры
Для того, чтобы начать собирать данные нам необходимы следующие элементы системы:
- Splunk – Indexer
- Windows сервер
- Linux сервер
Для того, чтобы загружать логи в Splunk, необходимо сначала предварительно настроить индексер, для этого потребуется:
• Установить и настроить Splunk-indexer на прием данных;
В первую очередь, вам понадобится Splunk на машине, которая является нашим индексером. Если у вас нет установленного Splunk, то прочитать подробнее, как и на какие системы можно поставить его вы можете прочитать тут.
После установки необходимо настроить индексер на прием данных:
Settings -Forwarding and Receiving, затем в разделе Receive data добавить новую конфигурацию: Configure receiving.
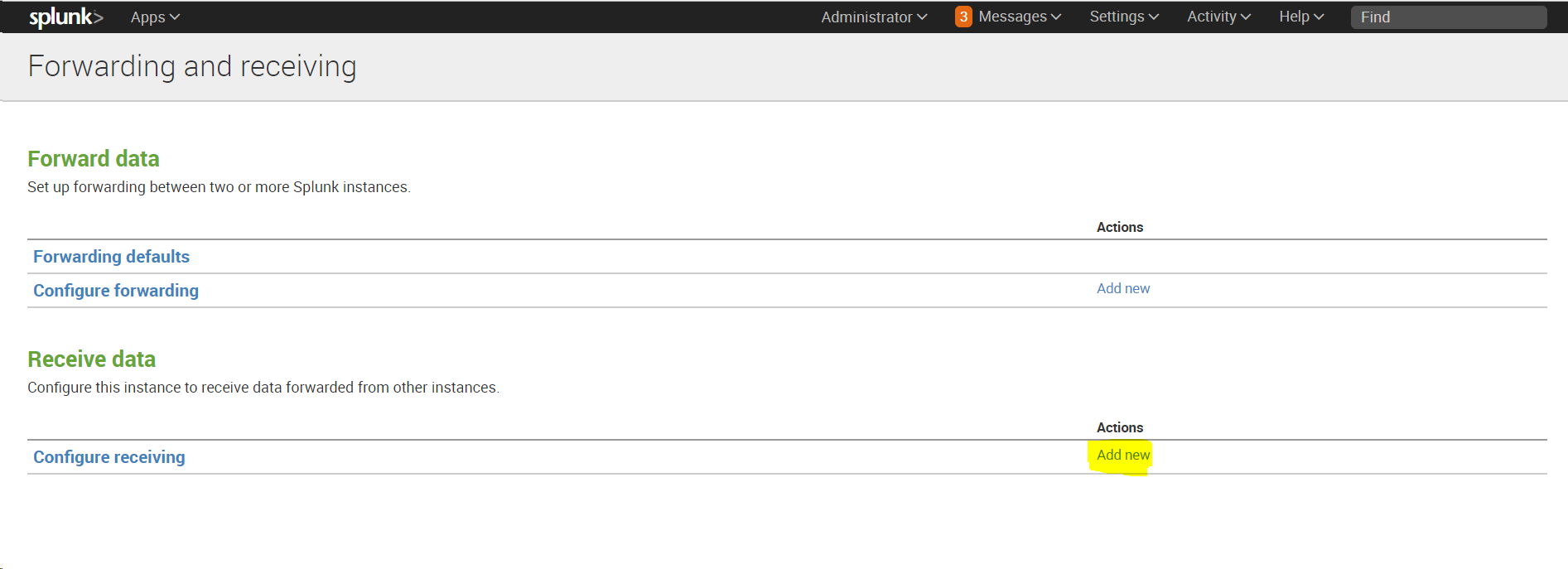
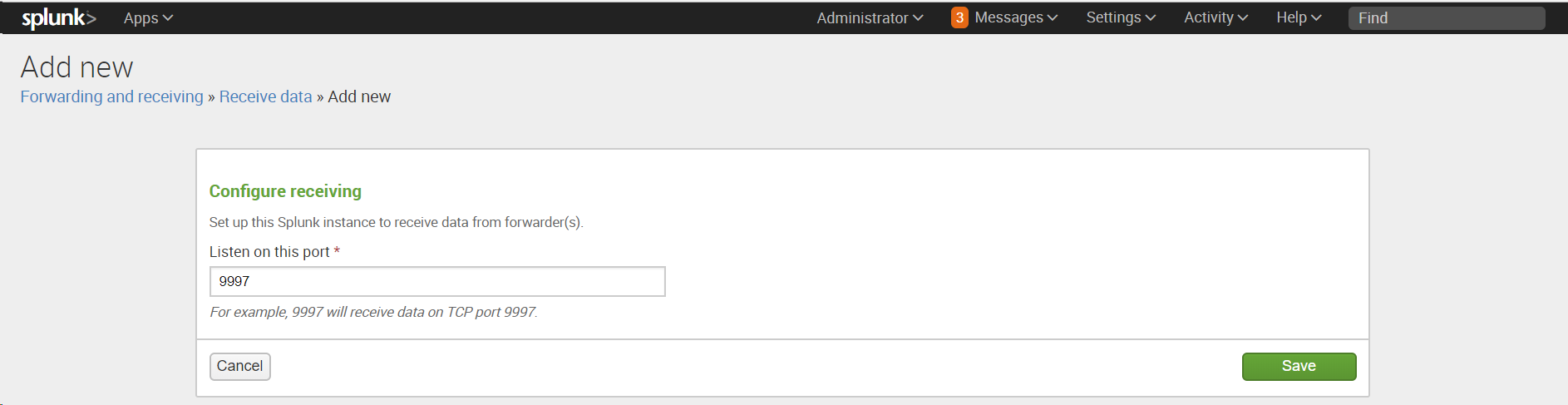
После установки необходимо настроить индексер на прием данных:
Settings -Forwarding and Receiving, затем в разделе Receive data добавить новую конфигурацию: Configure receiving.
• Создать приложение «Send to indexer», которое будет настраивать пересылку на всех источниках, отправляющих данные в индексер;
Это приложение необходимо для того, упростить управление источниками данных, когда этих источников много или доступ к ним для внесения изменений затруднителен. Также приложение позволит вам не совершать потенциально ошибочные изменения конфигурации на многих хостах, ограничивая изменением только на одном месте.
Создаем приложение: Apps — Manage Apps — Add New
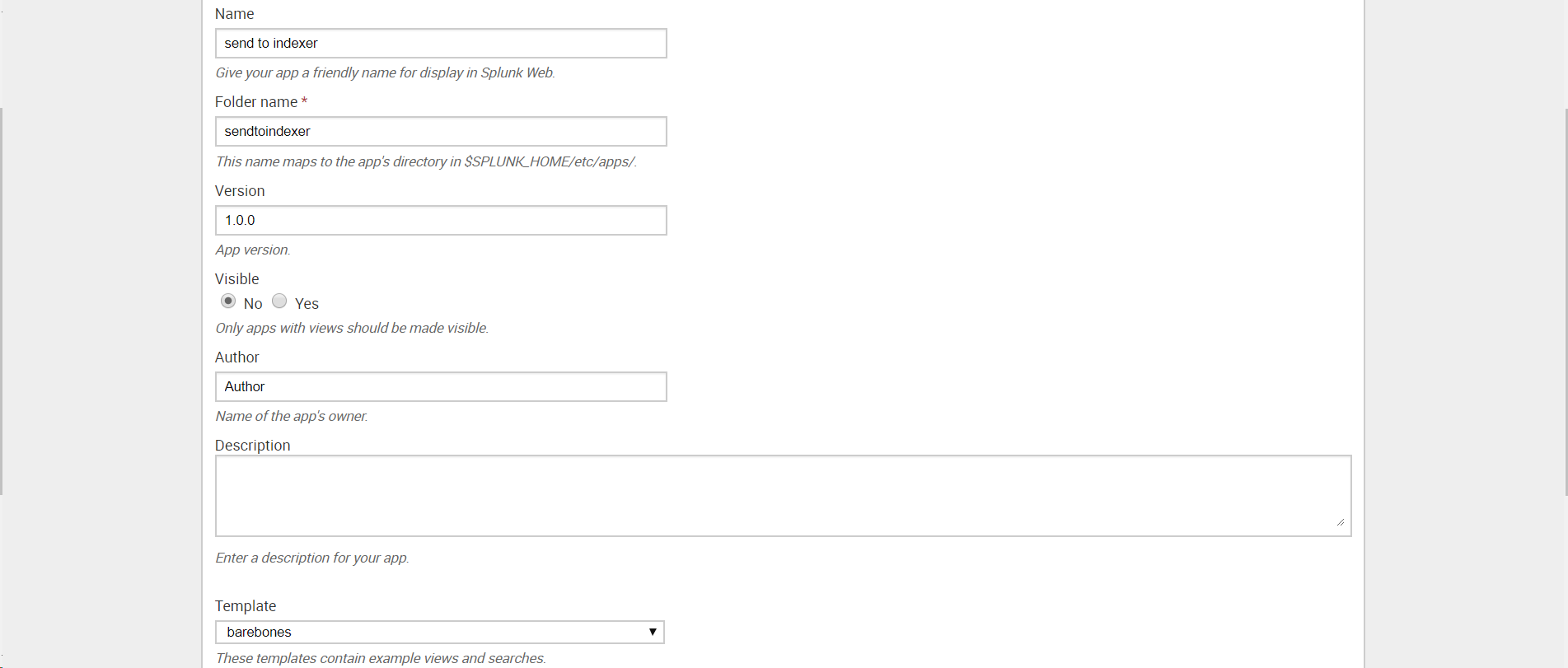
Создаем приложение: Apps — Manage Apps — Add New
•Сформировать конфигурационный файл оutputs.conf
После создания приложения, необходимо сформировать конфигурационный файл оutputs.conf (Подробнее об том файле Вы можете прочитать на официальном сайте Splunk)
В текстовом редакторе введите следующий текст, заменив indexer_hostname_or_ip_address именем хоста или IP-адресом индексера и получающим портом, установленным на предыдущем шаге:
Сохраните как outputs.conf и добавьте в папку \etc\apps\sendtoindexer\local (Папку local необходимо создать).
В текстовом редакторе введите следующий текст, заменив indexer_hostname_or_ip_address именем хоста или IP-адресом индексера и получающим портом, установленным на предыдущем шаге:
[tcpout]
defaultGroup = default-autolb-group
[tcpout:default-autolb-group]
server = <indexer_hostname_or_ip_address>:9997
[tcpout-server://<indexer_hostname_or_ip_address>:9997]Сохраните как outputs.conf и добавьте в папку \etc\apps\sendtoindexer\local (Папку local необходимо создать).
• Настроить Deployment Server для управления приложением «Send to indexer» и другими приложениями;
Deployment Server необходим для того, чтобы распространять приложения и конфигурации на все связанные экземпляры Splunk на других хостах. Чтобы активировать Deployment Server, необходимо поместить хотя бы одно приложение в папку %SPLUNK_HOME%\etc\deployment-apps. В нашем случае мы переместили туда приложение «Send to indexer». (Именно переместили, а не скопировали, как мы будем делать дальше с другими приложениями.)
На этом этапе мы заканчиваем предварительную настройки индексера и переходим к установке агентов на машины Windows и Linux.
WINDOWS
Универсальным инструментом для загрузки логов является специальный агент – Splunk Universal Forwarder. Universal Forwarder представляет собой версию Splunk Enterprise с существенно ограниченным функционалом, единственной задачей которого является сбор данных с хоста и отправка их.
Скачать его можно по этой ссылке.
На картинке выше видно, что Universal Forwarder можно установить как на Windows, так и на Linux, Solaris и другие операционные системы.
1. Устанавливаем Universal Forwarder
В качестве Deployment Server указываем IP-адрес или название Splunk индексера, где мы создали приложение «Send to indexer». Порт по умолчанию: 8089. Раздел Receiving Indexer оставим пустым, так как эти функции выполнит «Send to indexer».
2. Следующий шагом нам необходимо вернуться к Splunk и определить класс сервера для приложения «Send to indexer».
Класс сервера что-то похожее на правило, в котором мы указываем какие приложения мы будем распределять между какими целевыми машинами-клиентами. Критериями для формирования разных классов сервера могут стать тип машины, ОС, географическая область или тип приложения, причем классы могут пересекаться между собой. (Более подробно можно прочитать на официальном сайте)
Settings — Forwarder Management — edit action — add new classes.
3. После сохранения вам будет предложено добавить приложения, которые мы будем рассылать и целевые системы, так называемые клиенты, которым мы будем их рассылать.
Добавляем «Send to indexer» в раздел приложений.
4. Затем добавляем клиента. Клиентом будет наша машина с Windows, на которую мы установили Universal Forwarder. Если Universal Forwarder был установлен правильно, то машина должна появиться в списке клиентов, подключенных к Deployment Server. Заносим ее в Include (whitelist).
5. Проверить правильно ли все работает можно, посмотрев на содержимое индекса _internal. После добавления «Send to indexer» в класс сервера Universal Forwarder начинает отправлять свои внутренние логи туда. Также в этом индексе далее мы можем следить за тем, правильно ли работают наши агенты.
6. Далее скачиваем специальный Add-on с сайта SplunkBase, который позволяет собирать данные о работе Windows.
7. Устанавливаем приложение на Splunk-Indexer ( Apps — Manage Apps — Install app from file)
По умолчанию оно устанавливается в каталог ...\Splunk\etc\apps\Splunk_TA_windows, но нам необходимо скопировать его в папку deployment-apps, чтобы это приложение было доступно для deployment server, чтобы потом мы могли отправить его на другие машины также, как и «Send to indexer». (Важно: в папке apps оно также должно остаться, чтобы на индексере сформировались нужные нам индексы для данных).
8. Затем необходимо сделать преднастройку приложения.
Переходим в каталог ...\Splunk\etc\deployment-apps\Splunk_TA_windows
Создаем в нем под-каталог «local» (Важно: Вносить изменения в конфигурационные файлы необходимо всегда в каталоге local).
Скопируем файл inputs.conf из ...\Splunk\etc\deployment-apps\Splunk_TA_windows\default\inputs.conf в каталог local.
Включим индексацию требуемых данных. Для этого в файле inputs.conf из каталога local через текстовый редактор делаем некоторые изменения. Заменим значения disabled=1 на disabled=0 в необходимых блоках файла. Давайте добавим логи системы по Application, Security, System.
9. Далее, на Splunk-indexer, добавляем к приложению созданный ранее сервер-класс. (Settings — Forwarder Management — Apps — Splunk_TA_Windows – «+» — Windows Forwarder)
10. Перезагрузим deployment server, это можно сделать через командную строку из каталога … /splunk/bin:
./splunk reload deploy-server Проверям, загружаются ли данные. (Settings – Indexes ) Они должны попадать в индекс wineventlog. Как видно на нашем рисунке последние данные, которые были загружены на данный момент имеют временную метку 3 минуты назад.
LINUX
Одним из инструментов, позволяющих повысить уровень безопасности в Linux, является подсистема аудита auditd. C её помощью можно получить подробную информацию обо всех системных событиях. Именно данные, генерируемые этой системой мы будем индексировать в Splunk.
(Код будет представлен для Linux CentOS)
1. Проверим, если ли на машине предустановленная система аудита, если нет установим ее.
sudo yum list audit audit-libs
sudo yum install audit audit-libs Добавим новое правило, которое мы будем отслеживать.
sudo auditctl -w /etc/ -p wa -k test_auditПроверить его наличие можно с помощью функции.
auditctl -lЛоги, генерируемые auditd попадают в файл:
cd /var/log/audit/audit.log
cat audit.log2. Далее, установим Universal Forwarder. Найти дистрибутив можно по ссылке.
Следует скачать файл формата .rpm, после скачивания которого появится возможность получить wget ссылку.
yum install wget
cd /tmp/
wget -O splunkforwarder-7.0.3-fa31da744b51-linux-2.6-x86_64.rpm 'https://www.splunk.com/bin/splunk/DownloadActivityServlet?architecture=x86_64&platform=linux&version=7.0.3&product=universalforwarder&filename=splunkforwarder-7.0.3-fa31da744b51-linux-2.6-x86_64.rpm&wget=true'
rpm -i splunkforwarder-7.0.3-fa31da744b51-linux-2.6-x86_64.rpm3. Далее на создадим нового пользователя, который будет отвечать за работу со splunk.
adduser splunk4. Дадим разрешения пользовалелю, которого мы только что создали и запустим UniversalForwarder от его имени.
chown -R splunk:splunk /opt/splunkforwarder/
/opt/splunkforwarder/bin/splunk enable boot-start -user splunk5. Проведем настройку форвардера и укажем Deployment Server, также как в части с Windows, это IP-адрес или имя Splunk-indexer/
/opt/splunkforwarder/bin/splunk set deploy-poll <IP-адрес Splunk Indexer> :8089 -auth admin:changeme
/opt/splunkforwarder/bin/splunk edit user admin -password <Укажите новый пароль> -auth admin:changeme
/opt/splunkforwarder/bin/splunk restart6. Можно проверить, работает ли форвардер, следующим образом:
cd /opt/splunkforwarder/bin/
./splunk status7. Далее переходим в Splunk-indexer и устанавливаем на него специальный Add-on, позволяющий передавать логи с Linux. Скачать дистрибутив можно по ссылке.
8. После установки, находим папку с приложением по следующему адресу ../splunk/etc/apps/Splunk_TA_nix. Копируем папку Splunk_TA_nix из apps в deployment-apps. Чтобы это приложение появилось как доступное для deployment server.
В каталоге …/ deployment-apps/Splunk_TA_nix создаем папку local и копируем в нее файл input.conf из папки ../Splunk_TA_nix/default.
В файл …/ deployment-apps/Splunk_TA_nix/ local/ input.conf через текстовый редактор вносим изменения, которые покажут данные из каких папок мы хотим собирать. В нашем случае это /var/log/audit.
В input.conf есть раздел [monitor:///var/log], в котором необходимо изменить disabled=1 на disabled=0 (Важно: убедитесь, что необходимая папка есть в whitelist, если ее нет, но нужно ее добавить)
9. Далее проверим, увидел ли Deployment server нового клиента, нашу машину Linux. (Settings — Forwarder Management – Clients).
Если ее нет, то необходимо проверить название (Host name) машины, если он совпадает с названием машины индексера, то необходимо его изменить, иначе возникает ошибка.
cd /etc/hosts
cat hosts
hostname test.testdomain.com10. Затем создаем новый сервер класс, относящийся к Linux.
Settings — Forwarder Management – Server Classes — New Server Class
11. Добавляем в этот класс приложения «Send to indexer» и «Splunk_TA_nix», а в качестве клиента добавляет машину Linux.
Обратите внимание, что файлы не будут загружаться, если у Universal Forwarder (у юзера, под которым мы используем Universal Forwarder) нет доступа к папкам, которые необходимо мониторить. Так что необходимо учесть этот момент и разрешить доступ.
12. В конце необходимо перезагрузить deployment server, это можно сделать через командную строку из каталога … /splunk/bin :
./splunk reload deploy-server После проведения выше описанных операций, Вы получите логи Linux, которые будут загружены в индекс OS.
Заключение
Таким образом, мы показали вам, как загрузить ваши логи из Windows и Linux в Splunk для дальнейшего анализа и обработки. Надеемся, что эта информация будет полезна для Вас.
Мы рады ответить на все ваши вопросы и комментарии по данной теме. Также, если вас интересует что-то конкретно в этой области, или в области анализа машинных данных в целом — мы готовы доработать существующие решения для вас, под вашу конкретную задачу. Для этого можете написать об этом в комментариях или просто отправить нам запрос через форму на нашем сайте.
Мы являемся официальным Premier Партнером Splunk.
P. S.
19 апреля в Санкт-Петербурге пройдет однодневный обучающий курс: «Splunk Getting Started»
Данный курс предназначен для ознакомления с платформой Splunk. Слушатели курса получат как теоретические знания о работе с системой, так и практические навыки работы, включая построение поисковых запросов, различных визуализаций и дашбордов.
Участие в обучении бесплатное
Необходима предварительная регистрация.
Дата: 19 апреля (четверг)
Время: 10:00 — 17:00
Место: г. Санкт-Петербург, «Технопарк „Ингрия“, пр. Медиков, 3а
zar0ku1
Запись курса будет?