
О чем эта статья?
Одной из основных отличительных черт C++ного фреймворка SObjectizer является наличие диспетчеров. Диспетчеры определяют где и как акторы (агенты в терминологии SObjectizer-а) будут обрабатывать свои события: на отдельной нити, на пуле рабочих нитей, на одной общей для группы акторов нити и т.д.
В состав SObjectizer-а уже входит восемь штатных диспетчеров (плюс еще один в наборе расширений для SObjectizer-а). Но даже при всем этом многообразии встречаются ситуации, когда под конкретную специфическую задачу имеет смысл сделать собственного диспетчера. В статье как раз и рассматривается одна из таких ситуаций и показывается как можно сделать собственный диспетчер, если штатные диспетчеры по каким-то причинам нас не устраивают. А заодно будет показано как просто поменять поведение приложения всего лишь привязав одного и того же актора к разным диспетчерам. Ну и еще несколько интересных мелочей и не очень мелочей.
В общем, если кому-то интересно прикоснуться к деталям реализации одного из немногих живых и развивающихся акторных фреймворков для C++, то можно смело читать дальше.
Преамбула
Недавно один из пользователей SObjectizer-а рассказал про специфическую проблему, с которой ему довелось столкнуться в процессе использования SObjectizer-а. Смысл в том, что на базе SObjectizer-овских агентов разрабатывается приложение для управления подключенными к компьютеру устройствами. Часть операций (а именно операция инициализации и переинициализации устройства) выполняется синхронно, что приводит к блокировке рабочей нити на некоторое время. Операции же ввода-вывода осуществляются асинхронно, поэтому иницирование чтения/записи и обработка результата чтения-записи выполняются значительно быстрее и не блокируют рабочую нить надолго.
Устройств много, от нескольких сотен до нескольких тысяч, поэтому использовать схему «одно устройство — одна рабочая нить» не выгодно. Из-за чего используется небольшой пул рабочих нитей, на котором выполняются все операции с устройствами.
Но такой простой подход имеет неприятную особенность. Когда возникает большое количество заявок на инициализацию и переинициализацию устройств, то эти заявки начинают распределяться по всем нитям из пула. И регулярно случаются ситуации, когда все рабочие нити пула заняты выполнением длительных операций, тогда как короткие операции, вроде чтения-записи, скапливаются в очередях и долго не обрабатываются. Данная ситуация стабильно наблюдается, например, при старте приложения, когда сразу формируется большая «пачка» заявок на инициализацию устройств. И пока эта «пачка» не будет разобрана, операции ввода-вывода на уже проинициализированных устройствах не выполняются.
Для устранения этой неприятности можно использовать несколько подходов. В данной статье разберем один из них, а именно — написание собственного хитрого thread_pool-диспетчера, анализирующего типы заявок.
Что мы хотим достичь?
Проблема состоит в том, что долго работающие обработчики (т.е. обработчики операций инициализации и переинициализации устройств) блокируют все имеющиеся в пуле рабочие нити и из-за этого заявки для коротких операций (т.е. операций ввода-вывода) могут ждать в очереди очень долго. Мы же хотим получить такую схему диспетчеризации, чтобы при появлении заявки для короткой операции, ее ожидание в очередях было сведено к минимуму.
Имитационный «стенд»
В статье мы будем использовать имитацию описанной выше проблемы. Почему имитацию? Потому, что, во-первых, мы имеем представление только о сути проблемы пользователя, но не знаем деталей и никогда не видели его кода. И, во-вторых, имитация позволяет сконцентироваться на наиболее значимых аспектах решаемой проблемы, не распыляя внимания на мелкие детали, коих в реальном продакшен-коде великое множество.
Однако, есть одна важная деталь, которая нам стала известна от нашего пользователя и которая самым серьезным образом сказывается на описываемом ниже решении. Дело в том, что в SObjectizer есть понятие thread-safety для обработчиков сообщений. Т.е. если обработчик сообщения помечен как thread-safe, то SObjectizer имеет право запустить этот обработчик в параллель с другими thread-safe обработчиками. И есть adv_thread_pool-диспетчер, который именно это и делает.
Так вот, наш пользователь для управления устройствами использовал stateless-агента, привязанного к adv_thread_pool-диспетчеру. Это сильно упрощает всю кухню.
Итак, что же мы будем рассматривать?
Мы сделали имитацию, состоящую из одних и тех же агентов. Один агент — это вспомогательный агент типа a_dashboard_t. Его задача — собирать и фиксировать статистику, по которой мы будем судить о результатах имитационных экспериментов. Реализацию данного агента мы рассматривать не будем.
Второй агент, реализованный классом a_device_manager_t, имитирует работу с устройствами. О том, как работает этот агент мы немного поговорим ниже, т.к. это может быть интересным примером того, как в SObjectizer-е могут быть реализованы агенты, не нуждающиеся в изменении своего состояния.
В имитацию входят два приложения, которые делают практически одно и то же: разбирают аргументы командной строки и запускают имитацию с агентами a_dashboard_t и a_device_manager_t внутри. Но первое приложение привязывает a_device_manager_t к диспетчеру adv_thread_pool. А вот второе приложение реализует собственный тип диспетчера и привязывает a_device_manager_t к этому собственному диспетчеру.
На основании результатов работы каждого из приложений можно будет увидеть, как разные типы диспетчеров влияют на характер обслуживания заявок.
Агент a_device_manager_t
В этом разделе мы попробуем осветить основные моменты в реализации агента a_device_manager_t. Все остальные детали можно увидеть в полном коде агента. Или уточнить в комментариях.
Агент a_device_manager_t должен имитировать работу с множеством однотипных устройств, но при этом он должен быть «stateless-агентом», т.е. он не должен менять своего состояния в процессе работы. Именно то, что агент не изменяет своего состояния и позволяет ему иметь thread-safe обработчики событий.
Однако, если агент a_device_manager_t не меняет своего состояния, то как же он определяет, какое устройство должно быть инициализировано, какое устройство должно быть переинициализировано, а с каким устройством нужно выполнять операции ввода-вывода? Все просто: вся эта информация пересылается внутри сообщений, которые агент a_device_manager_t отсылает сам себе.
При старте агент a_device_manager_t отсылает себе N сообщений init_device_t. Получив такое сообщение агент a_device_manager_t создает экземпляр «устройства» — объект типа device_t и выполняет его инициализацию. Затем указать на этот экземпляр отсылается в сообщении perform_io_t. Выглядит это так:
void on_init_device(mhood_t<init_device_t> cmd) const {
// Обновим статистику по этой операции.
handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd);
// Нужно создать новое устройство и проимитировать паузу,
// связанную с его инициализацией.
auto dev = std::make_unique<device_t>(cmd->id_,
calculate_io_period(),
calculate_io_ops_before_reinit(),
calculate_reinits_before_recreate());
std::this_thread::sleep_for(args_.device_init_time_);
// Отсылаем первое сообщение о необходимости выполнить IO-операцию
// на этом устройстве.
send_perform_io_msg(std::move(dev));
}Получив сообщение perform_io_t агент a_device_manager_t имитирует операцию ввода-вывода для устройства, указатель на которое находится внутри сообщения perform_io_t. При этом для device_t декрементируется счетчик IO-операций. Если этот счетчик достигает нуля, то a_device_manager_t либо отсылает сам себе сообщение reinit_device_t (если счетчик переинициализаций еще не обнулен), либо сообщение init_device_t для пересоздания устройства. Эта нехитрая логика имитирует поведение реальных устройств, которые имеют свойство «залипать» (т.е. переставать нормально выполнять IO-операции) и тогда их нужно переинициализировать. А также тот печальный факт, что у каждого устройства есть ограниченный ресурс, исчерпав который устройство должно быть заменено.
Если же счетчик IO-операций еще не обнулился, то агент a_device_manager_t еще раз отсылает сам себе сообщение perform_io_t.
В коде все это выглядит следующим образом:
void on_perform_io(mutable_mhood_t<perform_io_t> cmd) const {
// Обновим статистику по этой операции.
handle_msg_delay(a_dashboard_t::op_type_t::io_op, *cmd);
// Выполняем задержку имитируя реальную IO-операцию.
std::this_thread::sleep_for(args_.io_op_time_);
// Количество оставшихся IO-операций должно уменьшиться.
cmd->device_->remaining_io_ops_ -= 1;
// Возможно, пришло время переинициализировать устройство.
// Или даже пересоздавать, если исчерпан лимит попыток переинициализации.
if(0 == cmd->device_->remaining_io_ops_) {
if(0 == cmd->device_->remaining_reinits_)
// Устройство нужно пересоздать. Под тем же самым идентификатором.
so_5::send<init_device_t>(*this, cmd->device_->id_);
else
// Попытки переинициализации еще не исчерпаны.
so_5::send<so_5::mutable_msg<reinit_device_t>>(*this, std::move(cmd->device_));
}
else
// Время переинициализации еще не пришло, продолжаем IO-операции.
send_perform_io_msg(std::move(cmd->device_));
}Вот такая нехитрая логика, касательно которой может иметь смысл уточнение некоторых деталей.
Отсылка информации агенту a_dashboard_t
В обработчиках сообщений init_device_t, reinit_device_t и perform_io_t первой строкой идет подобная конструкция:
handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd);Это передача агенту a_dashboard_t информации о том, сколько конкретное сообщение провело в очереди заявок. На основании этой информации как раз и строится статистика.
В принципе, точную информацию о том, сколько времени сообщение провело в очереди заявок можно было бы получить разве что внедрившись в потроха SObjectizer-а: тогда мы бы могли зафиксировать время постановки заявки в очередь и время ее извлечения оттуда. Но для столь простого эксперимента мы таким экстримом заниматься не будем. Поступим проще: при отсылке очередного сообщения будем сохранять в нем ожидаемое время прибытия сообщения. Например, если мы отсылаем отложенное на 250ms сообщение, то мы ждем его прибытия в момент (Tc+250ms), где Tc — это текущее время. Если сообщение пришло через (Tc+350ms), значит 100ms оно провело в очереди.
Это, конечно же, не точный способ, но для нашей имитации он вполне подходит.
Блокирование текущей рабочей нити на некоторое время
Также в коде обработчиков сообщений init_device_t, reinit_device_t и perform_io_t можно увидеть обращение к std::this_thread::sleep_for. Это не что иное, как имитация синхронных операций с устройством, которые должны блокировать текущую нить.
Времена задержек можно задать через командную строку, а по умолчанию используются следующие значения: для init_device_t — 1250ms, для perform_io_t — 50ms. Длительность для reinit_device_t вычисляется как 2/3 от длительности init_device (т.е. 833ms по умолчанию).
Использование мутабельных сообщений
Пожалуй, самой интересной особенностью агента a_device_manager_t является то, как обеспечивается время жизни динамически созданных объектов device_t. Ведь экземпляр device_t создается динамически при обработке init_device_t и затем он должен оставаться живым до тех пор, пока не будут исчерпаны попытки переинициализации этого устройства. А когда попытки переинициализации исчерпаны, то экземпляр device_t должен быть уничтожен.
При этом a_device_manager_t не должен менять своего состояния. Т.е. мы не можем завести в a_device_manager_t какой-то std::map или std::unordered_map, который был бы словарем живых device_t.
Для решения этой задачки используется следующий трюк. В сообщениях reinit_device_t и perform_io_t передается unique_ptr, содержащий указатель на экземпляр device_t. Соответственно, когда мы обрабатываем reinit_device_t или perform_io_t и хотим отправить следующее сообщение для этого устройства, то мы просто перекладываем unique_ptr из старого экземпляра сообщения в новый экземпляр. А если экземпляр нам больше не нужен, т.е. мы для него больше не отсылаем ни reinit_device_t, ни perform_io_t, то экземпляр device_t уничтожается автоматически, т.к. уничтожается экземпляр unique_ptr в уже обработанном сообщении.
Но тут есть небольшой фокус. Обычно сообщения в SObjectizer отсылаются как иммутабельные объекты, которые не должны модифицироваться. Это потому, что SObjectizer реализует модель Pub/Sub и отсылая сообщение в mbox в общем случае нельзя с уверенностью сказать, сколько именно подписчиков получат сообщение. Может быть их будет десять. Может быть сто. Может быть тысяча. Соответственно, какие-то подписчики будут обрабатывать сообщение одновременно. И поэтому нельзя разрешать, чтобы один подписчик модифицировал экземпляр сообщения в то время, как другой подписчик пытается с этим экземпляром работать. Именно из-за этого обычные сообщения передаются в обработчик по константной ссылке.
Однако, бывают ситуации, когда сообщение гарантированно отсылается одному-единственному получателю. И этот получатель хочет модифицировать полученный экземпляр сообщения. Вот как в нашем примере, когда мы хотим забрать из полученного perform_io_t значение unique_ptr и отдать это значение в новый экземпляр reinit_device_t.
Для таких случаев в SObjectizer-5.5.19 была добавлена поддержка мутабельных сообщений. Эти сообщения специальным образом помечаются. И SObjectizer в run-time проверяет, отсылаются ли мутабельные сообщения в multi-producer/multi-consumer mbox-ы. Т.е. мутабельное сообщение может быть доставлено не более чем одному получателю. Поэтому оно передается получателю по обычной, не константной ссылке, что и позволяет модифицировать содержимое сообщения.
Следы этого обнаруживаются в коде a_device_manager_t. Например, вот такая сигнатура обработчика говорит о том, что обработчик ожидает мутабельное сообщение:
void on_perform_io(mutable_mhood_t<perform_io_t> cmd) constА вот этот код говорит о том, что отыслается экземпляр мутабельного сообщения:
so_5::send<so_5::mutable_msg<reinit_device_t>>(*this, std::move(cmd->device_));Имитация с использованием adv_thread_pool-диспетчера
Для того, чтобы посмотреть, как будет вести себя наш a_device_manager_t со штатным adv_thread_pool-диспетчером нужно создать кооперацию из агентов a_dashboard_t и a_device_manager_t, привязав a_device_manager_t к adv_thread_pool-диспетчеру. Что выглядит следующим образом:
void run_example(const args_t & args ) {
print_args(args);
so_5::launch([&](so_5::environment_t & env) {
env.introduce_coop([&](so_5::coop_t & coop) {
const auto dashboard_mbox =
coop.make_agent<a_dashboard_t>()->so_direct_mbox();
// Агента для управления устройствами запускаем на отдельном
// adv_thread_pool-диспетчере.
namespace disp = so_5::disp::adv_thread_pool;
coop.make_agent_with_binder<a_device_manager_t>(
disp::create_private_disp(env, args.thread_pool_size_)->
binder(disp::bind_params_t{}),
args,
dashboard_mbox);
});
});
}В результате тестового запуска с 20-ю рабочими нитями в пуле и остальными значениями по умолчанию получаем следующую картинку:

Можно увидеть большой «синий» пик в самом начале (это массовое создание устройств при старте), а также большие «серые» пики вскоре после начала работы. Сперва мы получаем большое количество сообщений init_device_t, часть из которых долго ждут своей очереди на обработку. Затем очень быстро обрабатываются perform_io_t и генерируется большое количество reinit_device_t. Часть из этих reinit_device_t ждут в очередях, отсюда и заметные серые пики. Также можно видеть заметные провалы в линиях зеленого цвета. Это падение количества обработанных perform_io_t сообщений в те моменты, когда идет массовая обработка reinit_device_t и init_device_t.
Наша задача как раз состоит в том, чтобы уменьшить количество «серых» всплесков и сделать «зеленые» провалы не такими глубокими.
Идея собственного хитрого thread_pool-диспетчера
Проблема с adv_thread_pool-диспетчером в том, что для него все заявки равноценны. Поэтому, как только у него освобождается рабочая нить, он отдает ей первую заявку из очереди. Совершенно не разбираясь с тем, какой у этой заявки тип. Это и приводит к ситуациям, когда все рабочие нити заняты обработкой заявок init_device_t или reinit_device_t, в то время как в очереди скапливаются заявки типа perform_io_t.
Чтобы избавится от этой проблемы сделаем свой хитрый thread_pool-диспетчер, который будет иметь два подпула из рабочих нитей двух типов.
Рабочие нити первого типа могут обрабатывать заявки любых типов. Приоритет отдается заявкам типа init_device_t и reinit_device_t, но если их в данный момент нет, то можно обрабатывать и заявки типа perform_io_t.
Рабочие нити второго типа не могут обрабатывать заявки типа init_device_t и reinit_device_t. Заявку типа perform_io_t обрабатывать могут, а вот заявку типа init_device_t не могут.
Тем самым, если у нас образуется 50 заявок типа reinit_device_t и 150 заявок типа perform_io_t, то первый подпул будет разгребать заявки reinit_device_t, а второй подпул в это же время будет разгребать заявки perform_io_t. Когда все заявки типа reinit_device_t будут обработаны, то рабочие нити из первого подпула освободятся и смогут помочь обработать оставшиеся заявки типа perform_io_t.
Получается, что наш хитрый thread_pool-диспетчер держит отдельное множество нитей для обработки коротких заявок и это позволяет не притормаживать короткие заявки даже когда имеется большое количество долгих заявок (как, скажем, в самом начале работы, при единовременной отсылке большого количества init_device_t).
Имитация с использованием хитрого thread_pool-диспетчера
Для того, чтобы проделать ту же самую имитацию, но уже с другим диспетчером нам нужно лишь немного переделать уже показанную выше функцию run_example:
void run_example(const args_t & args ) {
print_args(args);
so_5::launch([&](so_5::environment_t & env) {
env.introduce_coop([&](so_5::coop_t & coop) {
const auto dashboard_mbox =
coop.make_agent<a_dashboard_t>()->so_direct_mbox();
// Агента для управления устройствами запускаем на отдельном
// хитром диспетчере.
coop.make_agent_with_binder<a_device_manager_t>(
tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(),
args,
dashboard_mbox);
});
});
}Т.е. мы создаем все тех же агентов, только в этот раз мы привязываем a_device_manager_t к другому диспетчеру.
В результате запуска с теми же самыми параметрами мы увидим уже другую картинку:
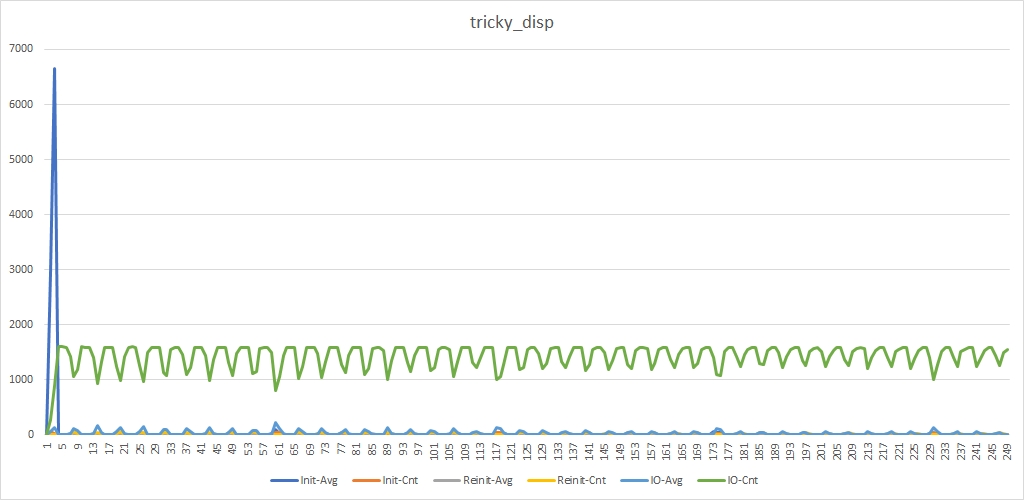
Присутствует все тот же «синий» пик. Теперь он стал даже повыше, что не удивительно, т.к. для обработки init_device_t теперь выделено меньше рабочих нитей. Зато мы не видим «серых» пиков и «зеленые» провалы стали менее глубокими.
Т.е. мы получили тот результат, который хотели. И теперь мы можем посмотреть на код этого самого хитрого диспетчера.
Реализация хитрого thread_pool-диспетчера
Диспетчеры в SObjectizer делятся на два типа:
Во-первых, публичные диспетчеры. У каждого публичного диспетчера должно быть свое уникальное имя. Обычно экземпляры диспетчера создаются еще до запуска SObjectizer-а, во время запуска SObjectizer-а публичные диспетчеры стартуют, а при завершении работы SObjectizer-а — останавливаются. У этих диспетчеров должен быть определенный интерфейс. Но это уже устаревший тип диспетчеров. Существует далеко не нулевая вероятность, что в следующей мажорной версии SObjectizer-а публичных диспетчеров уже не будет.
Во-вторых, приватные диспетчеры. Пользователь создает такие диспетчеры в любой момент после запуска SObjectizer-а. Приватный диспетчер должен стартовать сразу после создания и завершает он свою работу после того, как им перестают пользоваться. Как раз для своей имитации мы будем создавать диспетчера, который может использоваться только как приватный диспетчер.
Давайте рассмотрим основные моменты, связанные с нашим диспетчером.
disp_binder для нашего диспетчера
Приватные диспетчеры не имеют жестко определенного интерфейса, т.к. все основные операции осуществляются в конструкторе и деструкторе. Но у приватного диспетчера должен быть публичный метод, который обычно называется binder(), возвращающий специальный объект-binder. Этот объект-binder будет привязывать агента к конкретному диспетчеру. И вот у binder-а уже должен быть вполне себе определенный интерфейс — disp_binder_t.
Поэтому для своего диспетчера мы делаем собственный тип binder-а, реализующий интерфейс disp_binder_t:
class tricky_dispatcher_t
: public std::enable_shared_from_this<tricky_dispatcher_t> {
friend class tricky_event_queue_t;
friend class tricky_disp_binder_t;
class tricky_event_queue_t : public so_5::event_queue_t {...};
class tricky_disp_binder_t : public so_5::disp_binder_t {
std::shared_ptr<tricky_dispatcher_t> disp_;
public:
tricky_disp_binder_t(std::shared_ptr<tricky_dispatcher_t> disp)
: disp_{std::move(disp)} {}
virtual so_5::disp_binding_activator_t bind_agent(
so_5::environment_t &,
so_5::agent_ref_t agent) override {
return [d = disp_, agent] {
agent->so_bind_to_dispatcher(d->event_queue_);
};
}
virtual void unbind_agent(
so_5::environment_t &,
so_5::agent_ref_t) override {
// Ничего не нужно делать.
}
};
...
// Объект, реализующий интерфейс so_5::event_queue_t для того,
// чтобы выполнять привязку агентов к диспетчеру.
tricky_event_queue_t event_queue_;
...
public:
...
// Создать биндера, который сможет привязать агента к этому диспетчеру.
so_5::disp_binder_unique_ptr_t binder() {
return so_5::disp_binder_unique_ptr_t{
new tricky_disp_binder_t{shared_from_this()}};
}
};Наш класс tricky_dispatcher_t наследуется от std::enable_shared_from_this для того, чтобы мы могли использовать счетчик ссылок для контроля за временем жизни диспетчера. Как только диспетчер перестанет использоваться, счетчик ссылок обнуляется и диспетчер автоматически уничтожается.
В классе ticky_dispatcher_t есть публичный метод binder(), возвращающий новый экземпляр tricky_disp_binder_t. В этот экземпляр передается умный указатель на сам диспетчер. Это позволяет затем связать конкретного агента с конкретным диспетчером, что мы и видели ранее в коде run_example:
// Агента для управления устройствами запускаем на отдельном
// хитром диспетчере.
coop.make_agent_with_binder<a_device_manager_t>(
tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(),
args,
dashboard_mbox);
});
});
Объект-binder должен выполнять два действия. Первое — это привязывание агента к диспетчеру. Что выполняется в методе bind_agent(). Хотя, на самом деле, связывание агента с диспетчером выполняется в два этапа. Сперва в процессе регистрации кооперации вызывается метод bind_agent() и этот метод должен создать все необходимые для агента ресурсы. Например, если агент привязывается к диспетчеру active_obj, то для агента должна быть выделена новая рабочая нить. Это как раз должно происходить в bind_agent(). Метод bind_agent() возвращает функтор, который уже завершит процедуру привязки агента с использованием выделенных ранее ресурсов. Т.е. получается, что при регистрации кооперации сперва вызывается bind_agent(), а чуть позже — возвращенный bind_agent()-ом функтор.
В нашем случае bind_agent() очень простой. Никаких ресурсов не нужно выделять, достаточно просто вернуть функтор, который и свяжет агента с диспетчером (подробнее об этом ниже).
Второе действие — это отвязывание агента от диспетчера. Это отвязывание происходит когда агент изымается из SObjectizer-а (дерегистрируется). При этом может потребоваться очистить какие-то ресурсы, которые агенту были выделены. Например, диспетчер active_obj останавливает выделенную агенту рабочую нить.
За выполнение второго действия отвечает метод unbind_agent(). Но в нашем случае он пустой, поскольку для tricky_dispatcher_t очистка ресурсов при отвязывании агента не требуется.
tricky_event_queue_t
Выше мы говорили о «привязывании агента к диспетчеру», но в чем смысл этого привязывания? Смысл в двух простых вещах.
Во-первых, какие-то диспетчеры, вроде упоминавшегося выше active_obj, должны выделять те или иные ресурсы для агента в момент привязки.
Во-вторых, в SObjectizer агенты не имеют собственных очередей сообщений/заявок. В этом состоит принципиальное отличие SObjectizer от реализаций «классической Actor Model», в которой у каждого актора есть собственный mailbox (и, следовательно, собственная очередь сообщений).
В SObjectizer же очередями заявок владеют диспетчеры. Именно диспетчеры определяют, где и как хранятся заявки (т.е. адресованные агенту сообщения), где, когда и как заявки извлекаются и обрабатываются.
Соответственно, когда агент начинает работать внутри SObjectizer-а нужно установить связь между агентом и той очередью заявок, в которую должны складываться адресованные агенту сообщения. Для этого нужно вызвать у агента специальный метод so_bind_to_dispatcher() и передать в этот метод ссылку на объект, реализующий интерфейс event_queue_t. Что, собственно, мы и видим в реализации tricky_disp_binder_t::bind_agent().
Но вопрос в том, что именно tricky_disp_binder_t отдает в so_bind_to_dispatcher(). В нашем случае это специальная реализация интерфейса event_queue_t, которая служит всего лишь тоненьким прокси для вызова tricky_dispatcher_t::push_demand():
class tricky_event_queue_t : public so_5::event_queue_t {
tricky_dispatcher_t & disp_;
public:
tricky_event_queue_t(tricky_dispatcher_t & disp) : disp_{disp} {}
virtual void push(so_5::execution_demand_t demand) override {
disp_.push_demand(std::move(demand));
}
};Что скрывает за собой tricky_dispatcher_t::push_demand?
Итак, в нашем tricky_dispatcher_t есть один-единственный экземпляр tricky_event_queue_t, ссылка на который передается всем привязанным к диспетчеру агентам. А сам этот экземпляр просто делегирует всю работу методу tricky_dispatcher_t::push_demand(). Пришло время заглянуть внутрь push_demand-а:
void push_demand(so_5::execution_demand_t demand) {
if(init_device_type == demand.m_msg_type ||
reinit_device_type == demand.m_msg_type) {
// Эти заявки должны идти в свою собственную очередь.
so_5::send<so_5::execution_demand_t>(init_reinit_ch_, std::move(demand));
}
else {
// Это заявка, которая должна попасть в общую очередь.
so_5::send<so_5::execution_demand_t>(other_demands_ch_, std::move(demand));
}
}Здесь все просто. Для каждой новой заявки проверяется ее тип. Если заявка относится к сообщениям init_device_t или reinit_device_t, то ее кладут в одно место. Если же это заявка любого другого типа, то ее кладут в другое место.
Самое интересное — это что из себя представляют init_reinit_ch_ и other_demands_ch_? А представляют они ни что иное, как CSP-шные каналы, которые в SObjectizer называются mchain-ы:
// Каналы, которые будут использоваться в качестве очередей сообщений.
so_5::mchain_t init_reinit_ch_;
so_5::mchain_t other_demands_ch_;Получается, что когда для агента сформирована новая заявка и эта заявка дошла до push_demand, то ее тип анализируется и заявка отсылается либо в один канал, либо в другой. А уже извлекают и обрабатывают заявки рабочие нити, которые входят в пул диспетчера.
Реализация рабочих нитей диспетчера
Как говорилось выше, наш хитрый диспетчер использует рабочие нити двух типов. Теперь уже понятно, что рабочие нити первого типа должны читать заявки из init_reinit_ch_ и исполнять их. А если init_reinit_ch_ пуст, то нужно читать и исполнять заявки из other_demands_ch_. Если же оба канала пусты, то нужно спать пока в какой-то из каналов не поступит заявка. Либо пока оба канала не закроют.
С рабочими нитями второго типа еще проще: нужно читать заявки только из other_demands_ch_.
Собственно, именно это мы и видим в коде tricky_dispatcher_t:
// Обработчик объектов so_5::execution_demand_t.
static void exec_demand_handler(so_5::execution_demand_t d) {
d.call_handler(so_5::null_current_thread_id());
}
// Тело рабочей нити первого типа.
void first_type_thread_body() {
// Выполняем работу до тех пор, пока не будут закрыты все каналы.
so_5::select(so_5::from_all(),
case_(init_reinit_ch_, exec_demand_handler),
case_(other_demands_ch_, exec_demand_handler));
}
// Тело рабочей нити второго типа.
void second_type_thread_body() {
// Выполняем работу до тех пор, пока не будут закрыты все каналы.
so_5::select(so_5::from_all(),
case_(other_demands_ch_, exec_demand_handler));
}Т.е. нить первого типа висит на select-е из двух каналов. Тогда как нить второго типа — на select-е только из одного канала (в принципе, внутри second_type_thread_body() можно было бы использовать so_5::receive() вместо so_5::select()).
Собственно, это и все, что нам потребовалось сделать, чтобы организовать две thread-safe очереди заявок и чтение этих очередей на разных рабочих нитях.
Запуск-останов нашего хитрого диспетчера
Для полноты картины имеет смысл привести в статье еще и код, относящийся к запуску и останову tricky_dispatcher_t. Запуск выполняется в конструкторе, а останов, соответственно, в деструкторе:
// Конструктор сразу же запускает все рабочие нити.
tricky_dispatcher_t(
// SObjectizer Environment, на котором нужно будет работать.
so_5::environment_t & env,
// Количество рабочих потоков, которые должны быть созаны диспетчером.
unsigned pool_size)
: event_queue_{*this}
, init_reinit_ch_{so_5::create_mchain(env)}
, other_demands_ch_{so_5::create_mchain(env)} {
const auto [first_type_count, second_type_count] =
calculate_pools_sizes(pool_size);
launch_work_threads(first_type_count, second_type_count);
}
~tricky_dispatcher_t() noexcept {
// Все работающие нити должны быть остановлены.
shutdown_work_threads();
}В конструкторе также можно увидеть и создание каналов init_reinit_ch_ и other_demands_ch_.
Вспомогательные методы launch_work_threads() и shutdown_work_threads() выглядят следующим образом:
// Запуск всех рабочих нитей.
// Если в процессе запуска произойдет сбой, то ранее запущенные нити
// должны быть остановлены.
void launch_work_threads(
unsigned first_type_threads_count,
unsigned second_type_threads_count) {
work_threads_.reserve(first_type_threads_count + second_type_threads_count);
try {
for(auto i = 0u; i < first_type_threads_count; ++i)
work_threads_.emplace_back([this]{ first_type_thread_body(); });
for(auto i = 0u; i < second_type_threads_count; ++i)
work_threads_.emplace_back([this]{ second_type_thread_body(); });
}
catch(...) {
shutdown_work_threads();
throw; // Пусть с исключениями разбираются выше.
}
}
// Вспомогательный метод для того, чтобы завершить работу всех нитей.
void shutdown_work_threads() noexcept {
// Сначала закроем оба канала.
so_5::close_drop_content(init_reinit_ch_);
so_5::close_drop_content(other_demands_ch_);
// Теперь можно дождаться момента, когда все рабочие нити закончат
// свою работу.
for(auto & t : work_threads_)
t.join();
// Пул рабочих нитей должен быть очищен.
work_threads_.clear();
}Здесь, пожалуй, единственный хитрый момент — это необходимость ловить исключения в launch_work_threads, вызывать shutdown_work_threads, а затем пробрасывать исключение дальше. Все остальное вроде как тривиально и не должно вызывать затруднений.
Заключение
Вообще говоря, разработка диспетчеров для SObjectizer-а — это непростая тема. И входящие в состав SO-5.5 и so_5_extra штатные диспетчеры имеют гораздо более навороченную реализацию, чем показанный в этой статье tricky_dispatcher_t. Тем не менее, в каких-то специфических ситуациях, когда ни один штатный диспетчер не подходит на 100%, можно реализовать собственный диспетчер, специально заточенный под вашу задачу. Если не пытаться затрагивать такую сложную тему, как run-time-мониторинг и статистика, то написание собственного диспетчера не выглядит такой уж запредельно сложной темой.
Следует также отметить, что показанный выше tricky_dispatcher_t оказался простым из-за очень важного допущения о том, что события всех привязанных к нему агентов будут thread-safe и их можно будет вызывать параллельно ни о чем не задумываясь. Однако, обычно это не так. В большинстве случаев у агентов есть только thread-unsafe обработчики. Но даже когда встречаются thread-safe обработчики, то они существуют одновременно со thread-unsafe обработчиками. И при диспетчеризации заявок приходится проверять тип очередного обработчика. Например, если обработчик для очередной заявки thread-safe, а сейчас работает thread-unsafe, то нужно дождаться пока завершится ранее запущенный thread-unsafe обработчик. Как раз всем этим занимается штатный adv_thread_pool-диспетчер. Но применяется на практике он редко. Гораздо чаще используются другие диспетчеры, которые не анализируют флаг thread-safety для обработчиков, а считают, что все обработчики являются thread-unsafe.
Напоследок хочется сказать, что упоминавшаяся в статье возможность работы с мутабельными сообщениями была добавлена в SObjectizer после общения в кулуарах после доклада про SObjectizer на C++Russia 2017. Если кто-то хочет пообщаться с разработчиками SObjectizer вживую и высказать им все, что вы думаете по этому поводу, то это можно будет сделать на C++Russia 2018.