
Поэтому у меня как бы две жизни: в одной помогаю чиновникам открывать данные, которые просят люди или организации, а в другой — пишу парсеры, которые превращают общедоступные базы особо «упрямых» госорганов в открытые данные и учу этому других, в надежде, что таких проектов станет много, государство смирится с неизбежным и все выложит в удобном нам виде.
Эта статья станет первым мануалом в серии «как получать машиночитаемые данные с госсайтов». Итак, сегодня — про статистику ДТП, а раз государство нам ее не дает, мы научимся забирать ее самостоятельно. По традиции, код и данные — прилагаются.

Про ДТП
Если верить отчету Всемирной организации здравоохранения, в России на 2013 год на ДТП приходилось 18.9 смертей на 100 тысяч человек, в Швеции — 2.8, а в Беларуси — 13.7.
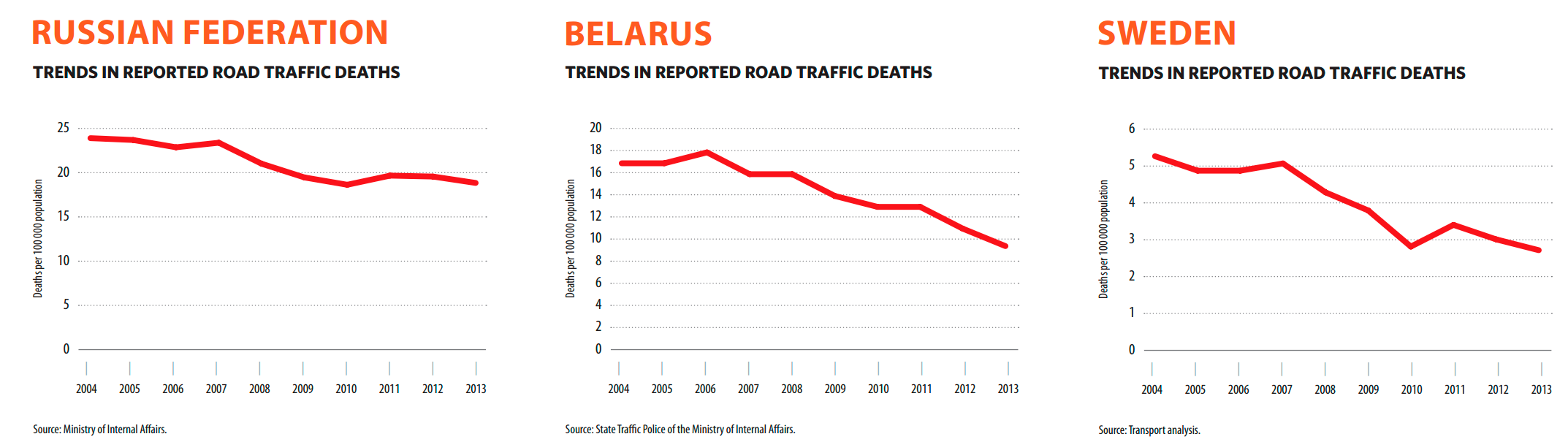
Однако уже в 2017 году в Беларуси смертность упала ниже, чем в странах Евросоюза, а вообще за 10 лет снизилась втрое. На картинках видно еще один интересный момент: в то время как для России ситуация практически не меняется с 2010 года, в Беларуси и Швеции красная линия смерти настойчиво стремится вниз.
Причина чуда — в шведской программе Vision Zero, которая говорит, что сложно заставить людей быть более внимательными и ответственными, однако можно сделать так, чтобы сама окружающая среда обеспечивала безопасность людей.
В Беларуси на базе этой идеи запустили программу «Минус сто» (минус 100 смертей каждый год), но в какой-то момент возможности «лежачих полицейских», снижение скорости и контроль движения перестали давать заметный эффект.
Тогда и пришлось обратиться к данным. Выводы, которые дал этот анализ, получились неожиданными: в Минске, например, вовсю боролись с пьяными водителями, а их оказалось 2%. Да и скорость народ соблюдал, так что дело было не в этом. Настоящей причиной оказались невидимые в темноте пешеходы и утренняя рассеянность водителей (32 из 41 погибших в Минске в 2017 году были пешеходами, а самые частые смертельные ДТП происходили между 00:00-03:00 и 06:00-09:00).
Конечно, и в России исследователи не раз приходили к мысли, что, изучив статистику ДТП, можно было бы найти и объяснить «нехорошие» места на дорогах. Еще в 2012 году новосибирские активисты создали карту ДТП с участием пешеходов, ежедневно с октября 2012 по март 2013 года собирая сводки местных органов ГИБДД, да и в целом мысль постоянно витала в воздухе.
Источники данных в России
Возможности провести адекватный анализ ДТП в России появились вместе с картой статистики ДТП от ГИБДД, под которой как минимум в 2016 году уже можно было найти данные с привязкой к точному адресу и времени, а в 2017 в общем(!) доступе появилась информация, о которой можно только мечтать: детали дорожной ситуации, время суток, подробности аварии и повреждений и прочее. Во всем этом было лишь одно «но»: данные можно было качать только… по одному муниципалитету за раз. Муниципалитет — это, например, один район Москвы.
Итак, Способ 1: три клика мышкой, чтобы добраться до данных по какому-нибудь району Москвы на stat.gibdd.ru, и еще три — чтобы их скачать (спасибо, что хотя бы в xml, а про json, дорогие питонисты, в этом варианте забудьте). Давайте посчитаем: на 85 регионов России у нас приходится 2423 муниципалитета, итого:
2423*6 = 14538 кликов мышки
Помедитировать:
Чтобы вы не расстраивались, есть еще Способ 2: ресурс Безопасныедороги.рф Минкомсвязи (есть подозрение, что они тоже качают stat.gibdd.ru).
На нем в разделе «Открытые данные» сначала появилась неполная статистика в «плоском» виде в csv, в 2017 она стала детализированной и в json, но… С этим ресурсом постоянно что-то случается: в июле 2017 выложили детальные данные, но весь август сайт не работал из-за истекшего сертификата безопасности. Потом снова заработал, но данные никто не обновлял. По состоянию на начало мая 2018 появилось обновление, зато снова исчезли детальные данные — погодные условия, характер повреждений ТС и многое другое (в цифрах это 90 Мб вместо 603 Мб за 2017 год).
Но русские программисты не сдаются, и за это время было создано много хороших проектов: статистика ДТП по Барнаулу и Москве от Сергея Устинова jimborobin, подробное исследование от Александра Кукушкина alexkuku, визуализация от Константина Варика.
upd: благодаря HuGo добавились еще два проекта: «Ноль смертей» в Красноярске и dtpstat.ru в Кирове.
И два долгосрочных проекта: «Ноль смертей» — наш ответ Vision Zero и совсем недавний проект по анализу и предсказанию аварийности на дорогах Санкт-Петербурга — посмотреть можно здесь (лучше через IE), ребята планируют его развитие в ближайшие месяцы.
Разумеется, под каждый проект на скорую руку создавался очередной парсер…
Парсим самостоятельно
Парсер, который, надеюсь, теперь работает полностью стабильно, я на самом деле написала ровно год назад (и да, к нему должна была прилагаться эта статья). Его задача — обеспечивать исследователей свежими данными, поэтому там даже есть командная строка и мануал.
Но прежде чем перейти к коду, давайте сначала научимся самостоятельно исследовать сайты. Нам понадобятся: браузер Chrome и приложение Postman (заодно установите дополнение Postman Interceptor).
После установки наберите в адресной строке хрома chrome://apps, откроется страничка с установленными приложениями, среди которых будет Postman.
Изучаем сайт
Есть разные движки сайтов. Самые простые управляются через адресную строку, в которой можно задавать параметры. stat.gibdd.ru другой: он работает по принципу комбинации url-команды и пакета данных в json. Тем не менее, стратегия исследования всех сайтов одинакова: запускаем Chrome DevTools, заставляем сайт делать то, что нам нужно, и внимательно следим за изменениями в окне отладчика.
Итак, давайте попробуем получить данные по какому-нибудь району Москвы.
Открываем stat.gibdd.ru, выбираем период, какой нравится (у меня весь 2017 год), нажимаем кнопку «Применить» рядом.

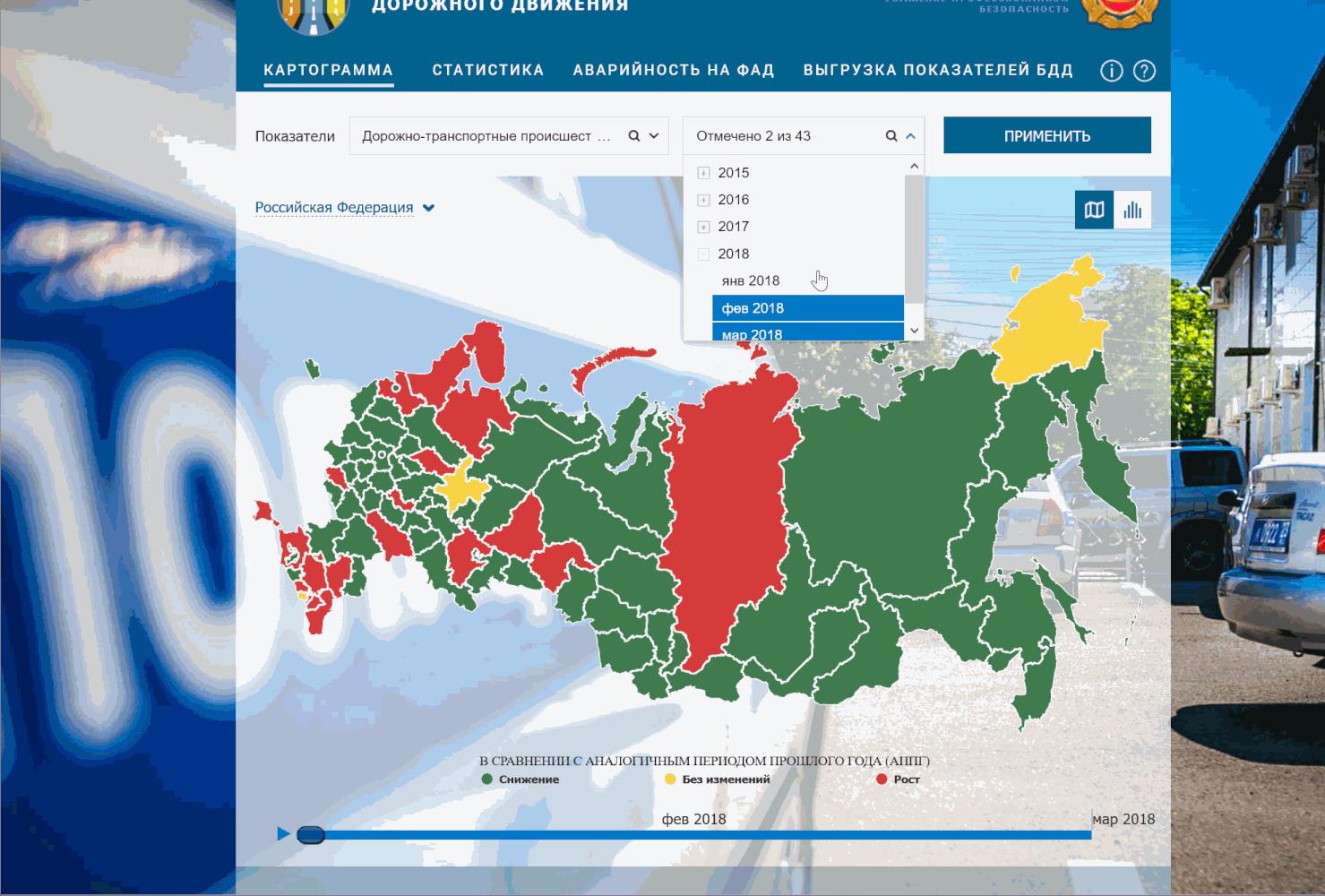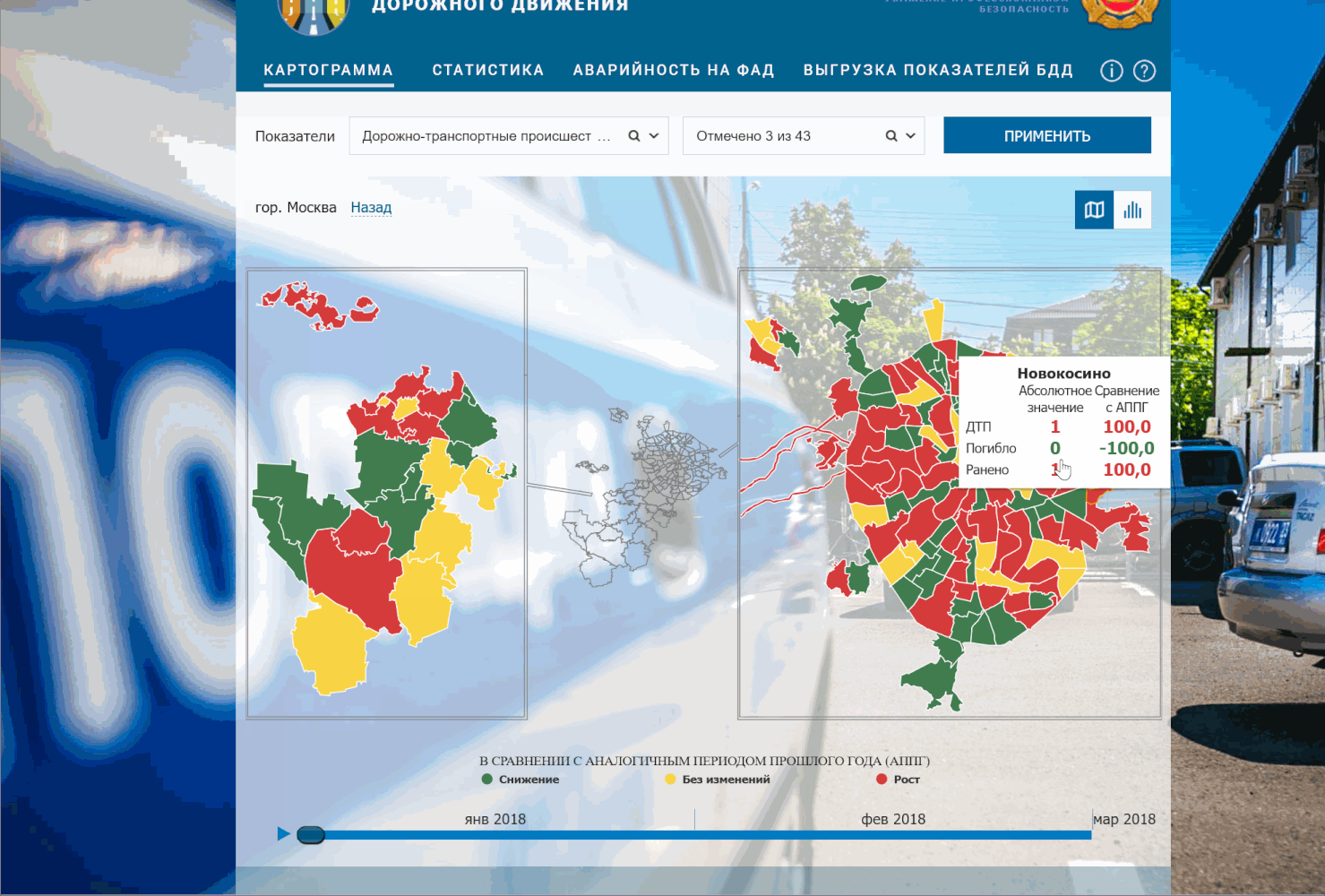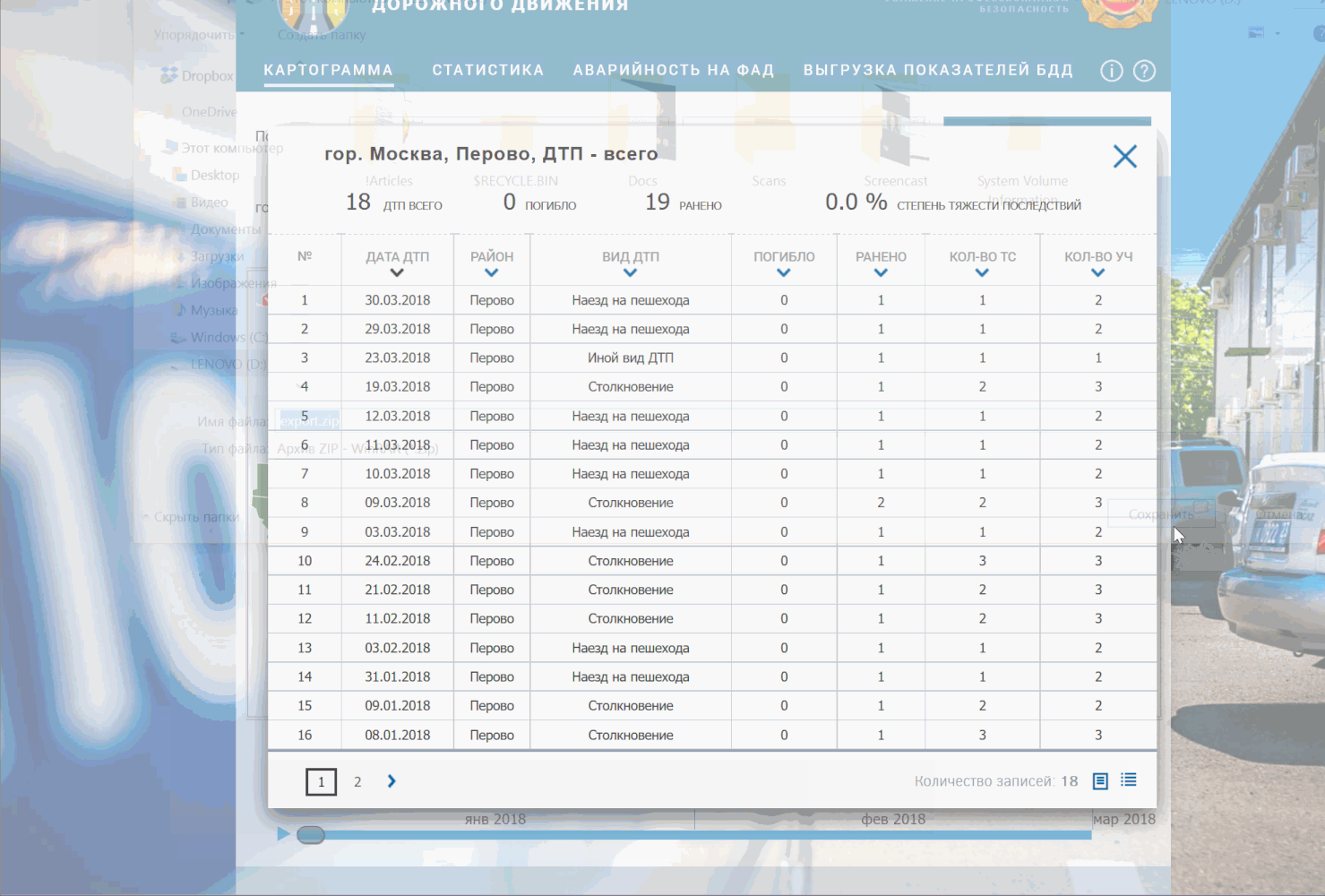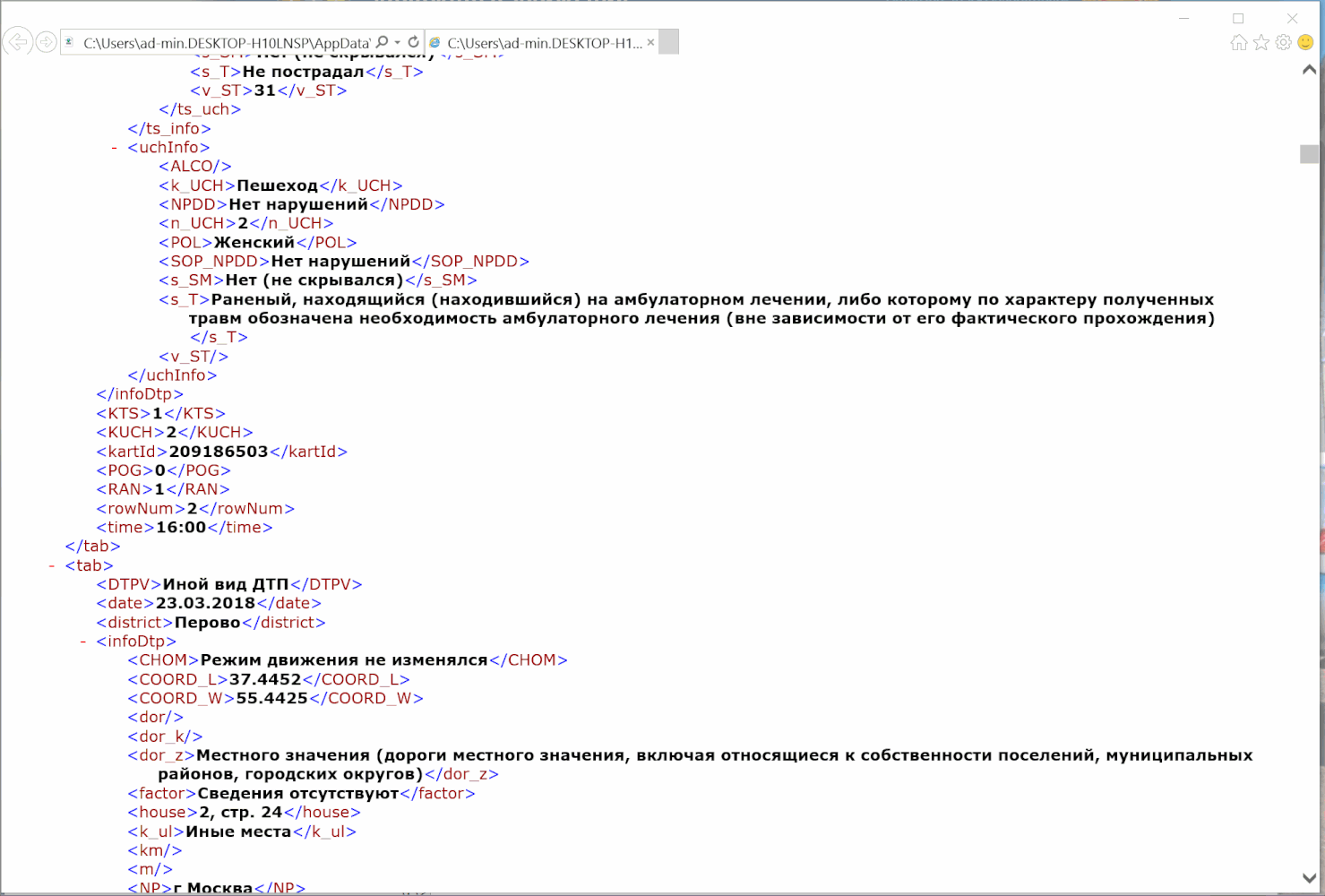
Дальше на карте выбираем Москву и можно запускать отладчик: ткнуть правой кнопкой мыши куда-нибудь в карту, выбрать «Просмотреть код» и увидим окно DevTools. Находим в нем в меню вкладку Network. Лучше сразу поменять фильтр с All на XHR, чтобы убрать лишние запросы, которые нам не нужны.
Выбираем понравившийся нам район (у меня Перово). Видим, что в окне DevTools слева появились два запроса под названием getDTPCardData. Если нажать на любой из них и выбрать в окне справа вкладку Headers, увидим заголовок запроса. Здесь нас интересуют точный url запроса и метод, которым отправляется запрос (это могут быть GET и POST). Для интересующихся подробности, а в нашем случае мы видим надпись POST и соглашаемся. Сразу под ним должно быть значение Status code: 200 — значит, что запрос прошел успешно и данные к нам пришли. Посмотреть все сразу на скриншоте:
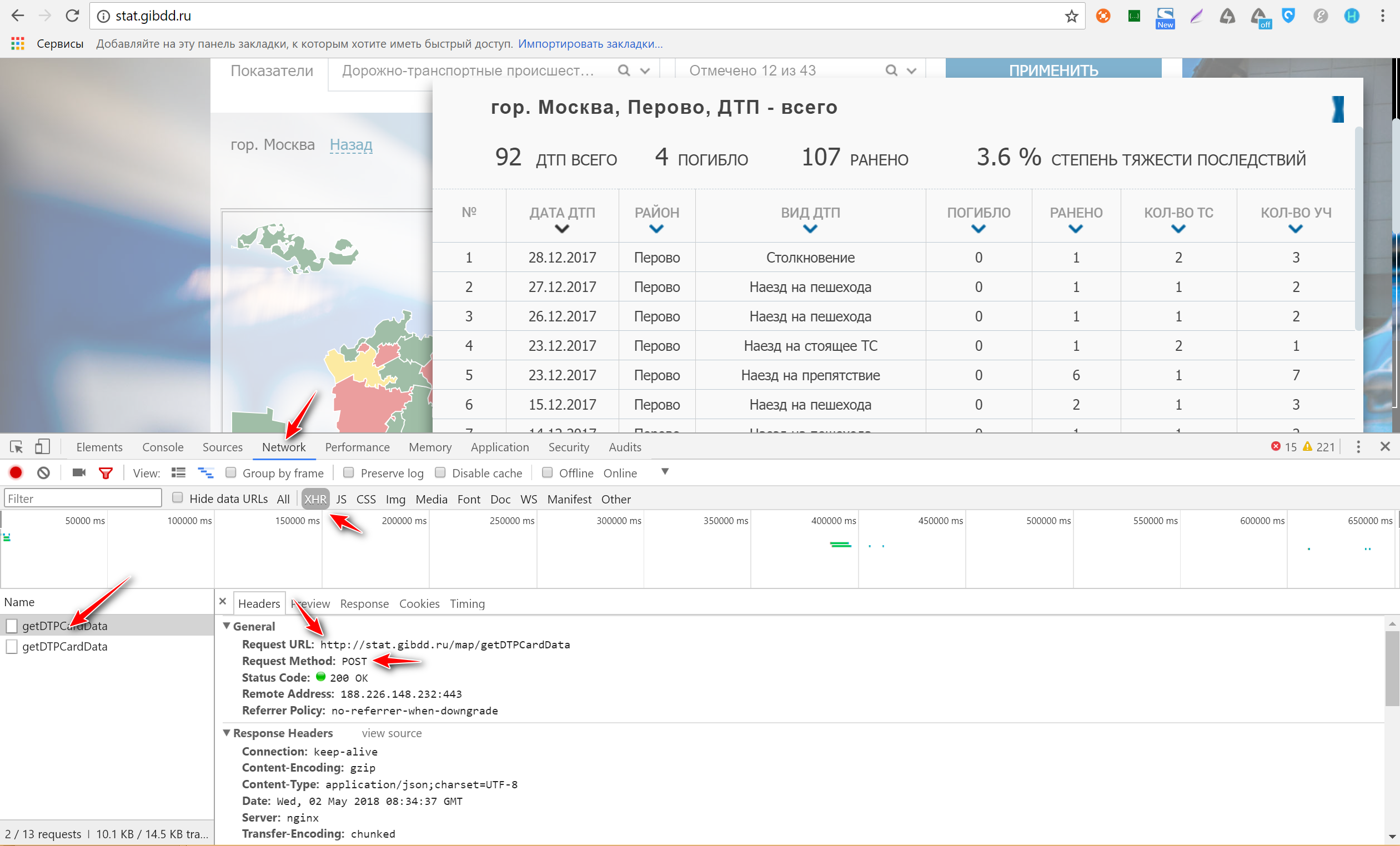
Качаем данные
Ссылка у нас теперь есть, осталось найти json-пакет. Для этого листаем окно Headers вниз до конца и видим раздел Request Payload. Нажимаем view source рядом с надписью Request Payload, чтобы получить пакет данных в исходном виде. Копируем его себе куда-нибудь. Теперь все готово к тому, чтобы получить данные напрямую у движка сайта через Postman.

Запускаем Postman и сразу включаем Interceptor (круглая иконка вверху, на которую указывает стрелка). Interceptor перехватит куки, т.к. без них сайт откажется выполнять наши запросы.
Дальше необходимо настроить запрос: выбрать в качестве метода отсылки — POST, вставить url команды, добавить ранее скопированный пакет данных (Body -> raw -> JSON (application/json)). В общем, идите по красным стрелкам.
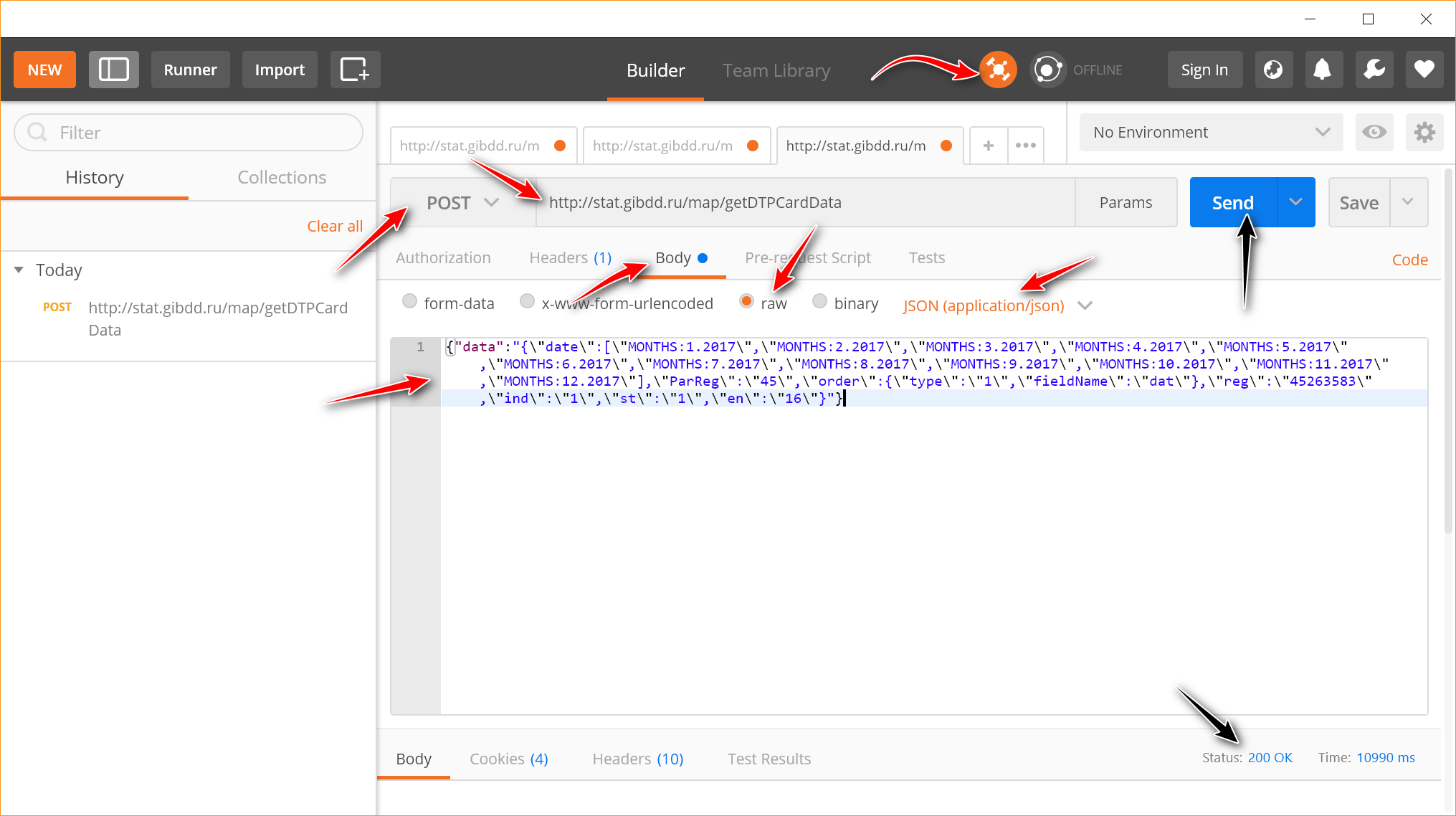
Дальше нажимаем Send либо Send and Download, чтобы сразу скачать данные. Внизу справа в окне появится надпись «Status: 200 OK» и откроется окно на скачивание файла json (теперь все внимание на две черные стрелки). В случае ошибки, скорее всего, отобразится статус 500, а вместо json будет скачан txt с текстом ошибки.
Надеюсь, все получилось, и давайте теперь разберем, что же у нас такое задано в json?

Первое — это очень длинный параметр «date», в котором задается временнОй период, причем каждый месяц мы должны прописать отдельно. Выглядит это как «MONTHS:1.2017», где «MONTHS» — обязательный ключ (и обязательно большими буквами), 1 — номер месяца (январь), 2017 — очевидно, год.
Следом идут еще два обязательных поля: «ParReg» — ОКАТО-код региона (в нашем случае это 45 — код г.Москва) и «reg» — ОКАТО-код муниципального образования (в нашем случае 45263583 — код района Перово).
И еще два важных поля, от которых зависит судьба парсинга: это пара полей «st» и «en», то есть номера первой и последней карточки ДТП, которые мы заберем с ресурса. По умолчанию сайт ставит 16 карточек (это можно проверить во всплывающем окошке на сайте), однако вы вполне можете указать st=1, en = 100 и получить сразу 100 ДТП, просто подождать придется подольше. Рекомендую не жадничать и не ставить очень много (например, 1000), т.к. сайт может прервать ваш запрос по таймауту. Если вам нужны следующие карточки, просто пишете так: st=101, en=200.
Будет хорошо, если вы уже задаетесь вопросом, а почему там везде "\"? Это уже детали упаковки json для передачи на сервер, но кратко можно объяснить так: все, что идет после «data» с двоеточием, — это строка. В строке символ кавычки просто так написать нельзя, поэтому перед ней ставится обратный слеш. Для Postman'а и других оболочек это критично, а вот если отправляете запрос через Python, он все сделает за вас.
И еще одна важная деталь, которая добавит боли невнимательным исследователям. Есть так называемая «компактная запись», для того чтобы данные, посылаемые на сервер, весили как можно меньше. Для нас это значит, что все пробелы, которые мы ставим «для красоты», запрещаются. stat.gibdd.ru очень чувствительно к этому относится, поэтому, если запрос вроде бы правильный, а возвращается HTTP 500 вместо 200, проверяйте, не вклинились ли у вас где-то пробелы.
Пишем парсер
Готовый и (надеюсь) хорошо откоментированный парсер тут.
Самое главное, что нужно про него знать:
1) Получение данных: r = requests.post (url, json = payload). Здесь url и payload – в точности те значения, что мы отловили через DevTools и добавляли в Postman.
Кусок псевдокода, благодаря которому мы получаем карточки ДТП:
cards_dict = {"data":{"date":["MONTHS:1.2017"],"ParReg":"71100","order":{"type":"1","fieldName":"dat"},"reg":"71118","ind":"1","st":"1","en":"16"}}
cards_dict["data"]["ParReg"] = "45" # город Москва
cards_dict["data"]["reg"] = "45263583" # район Перово
cards_dict["data"]["st"] = 1 # первая карточка
cards_dict["data"]["en"] = 100 # последняя карточка
cards_dict_json = {}
cards_dict_json["data"] = json.dumps(cards_dict["data"], separators=(',', ':')).encode('utf8').decode('unicode-escape') # вот так мы и упаковываем данные в строку
r = requests.post("http://stat.gibdd.ru/map/getDTPCardData", json=cards_dict_json) # ссылка на команду + настроечные данные к ней
2) Для работы с данными, которые пришли с сайта, нужно превратить их обратно в json: json.loads (r.content):
if r.status_code == 200:
cards = json.loads(json.loads(r.content)["data"])["tab"]
3) Для сохранения данных в файл пишем вот так: json.dump(json_data, f, ensure_ascii=False, separators=(',', ':')), где json_data — это ваши данные, f — файл, в который их записываем, ensure_ascii=False — спасет, если вам, так же как и мне, не нравится потом вместо кириллицы читать в файле вот такое: \u043D\u0435\20\u043D\u0440\u0430\u0432\u0438\u0442\u0441\u044F.
filename = os.path.join(data_dir, "{} {} {}-{}.{}.json".format(region["id"], region["name"], months[0], months[len(months) - 1], year))
with codecs.open(filename, "w", encoding="utf-8") as f:
json.dump(dtp_dict_json, f, ensure_ascii=False, separators=(',', ':'))
Еще немного полезных ссылок
json часто приходит с экранированными управляющими символами. Чтобы убрать экранирование, есть онлайн-сервис.
Для того, чтобы было легче читать информацию о ДТП в сыром виде, пригодится парсер json. К тому же в нем есть валидатор – удобно, когда нужно выкинуть большую часть файла и при этом перестают сходиться скобки.
Если кто-то тоже задавался вопросом, как оформлять пояснения на скриншотах, — рекомендую FastStone Capture.
А если вы не хотите парсер, а хотите сразу вжжжжух и данные, то ВОТ. Это вся статистика ДТП с 1 января 2015 по 3 апреля 2018. Кстати, парсер дает небольшой бонус по сравнению с сайтом ГИБДД: на сайте выгрузка ограничена точно месяцем, а вот парсер забирает вообще все данные, которые туда выложили. Поэтому у пользователей данные за март, а у нас — уже немножко за апрель.
Хороших вам данных и исследований. Берегите и не роняйте государственные сайты.
upd по результатам комментариев: если вы тоже парсили данные или делали проект по ДТП, напишите мне, пожалуйста, любым способом (комментарий, личка, nike64@gmail.com). Мы с коллегами собираем опыт таких проектов. Пообщаться про эти и другие открытые данные можно в телеграм-чате OpenDataRussiaChat.
Комментарии (30)

HuGo
03.05.2018 05:33Пару месяцев назад для общественного проекта тоже использовал эти данные. Собрал небольшой интерфейс для анализа и информационные файлы за 3 года (2015, 2016, 2017) по Красноярску и Кирову. В процессе анализа выяснилось, что данные по координатам инспекторы забивают откровенно плохо. Постоянно теряют цифры, меняют их местами, просто левые какие-то данные вносят. Поэтому по итогу пришлось прогонять через геокодирование Яндекса для уточнения. Если кому интересно — dtpstat.ru и файл для Красноярска ( yadi.sk/d/5jDgUtGM3VCYmw ) и Кирова ( yadi.sk/d/AyX0hjzE3VCYoh )
P.S. Проект сделан на скорую руку, вся логика на JSHuGo
03.05.2018 05:43Забыл… Исходники на Битбакете можно взять здесь bitbucket.org/mePersonal/accident-analysis
DS28
03.05.2018 11:34Почему Красноярск я догадался, а почему Киров?
HuGo
03.05.2018 11:48+1Сложная система общения в соц.сетях. Если коротко — друг из Красноярска на общественных началах занимается вопросами городского планирования и прочего. Для одной из его задач был сделан этот интерфейс как раз и собраны-переработаны данные (по Красноярску). Он разместил пост в ФБ и ЖЖ. Его увидел парень, который занимается аналогичными вопросами в Кирове. Попросил меня собрать данные для Кирова и немного доработали карту (нарастили функционал) для своей задачи по Кирову.
nike32 Автор
03.05.2018 16:54HuGo, спасибо! мне как раз интересен ваш и другие такие же общественные проекты и истории этих проектов. Стукните в личку, пожалуйста. Проблему с геоокоординатами, к сожалению, тоже замечаем постоянно. Видимо, следующим этапом придется все перекодировать (точно так же яндекс.геокодером) и перевыкладывать…
achekalin
03.05.2018 11:46-5Чую, привлекать будут за
экстре...раскрытие правды, когда этого не просили. Поскольку такой стати нет, припишут использование запрещенного мессанджерадля террори...Телеграмма. Хотя, тут тоже статьи нет. В общем, интересно, что придумают. Потому, что официально выводы (из тех же данных) звучат, вероятно, чуть по-другому.
IvanG
03.05.2018 14:42- Видим, что в окне DevTools слева появились два запроса под названием getMainMapData
На картинках другой метод
- В начале статьи говорится, что данные в xml, а далее уже под json рассказ.
Т.к. статья подробная, и ориентированая на людей, в том числе не очень разбирающихся в вопросе, лучше поправить, чтобы не было путаницы.
iveagle
03.05.2018 16:02+1Скажите, а не удавалось ли Вам получить полную базу ЕГРЮЛ или ЕГРИП? На сайте налоговой за разовый доступ к ней просят 50 тыс. руб, что, конечно, совершенно неприемлемо, если база нужна исключительно в исследовательских целях. Сгодилась бы даже неактуальная база (за 2015 год или более ранний период).
nike32 Автор
03.05.2018 16:08+2iveagle, мы с коллегами (например, k0shk) ведем очень давний спор с ФНС по поводу опубликования ЕГРЮЛ в виде открытых данных. За три года ни к чему полезному это не привело и на все аргументы про исследователей ФНС не реагирует. Как вариант, свяжитесь с ребятами из datafabric.cc (они строят онтологию на данных ФНС), или огрн.онлайн, или zachestnyibiznes.ru. Все они могут дать API для исследовательских целей.
k0shk
03.05.2018 16:16+1на самом деле мы даже не просим полные ЕГРЮЛ и ЕГРИП, мы просим раскрыть хотя бы ИНН/КПП/ОГРН/название организации, которых нам не хватает для связывания и обработки разных массивов данных (из практики — в каждом поле встречается куча ошибок, поэтому для идентификации организации ни одно поле использовать нельзя).
Самый последний ответ, официально полученный нами от Минфина пару недель назад, гласит о том, что «каждый человек или организация могут получить информацию об одной организации (в виде выписки pdf), а если вы хотите использовать эти данные в инф. системах, то Минфин России считает взимание платы обоснованным» (передаю простым языком и своими словами, но смысл такой). Мы, кстати, все еще продолжаем пытаться получить эти данные, а начали примерно в середине 2015 года :)
Layner
03.05.2018 16:09Спасибо за популяризацию Питона. Сам собираю данные какие мне надо таким образом. Любые JSON, XML, CSV… буквально на днях выкачал 26тыс координат населенных пунктов определенных областей, н.п. существовавших в 19 веке, а ныне не существующих. Под свою карту, более удобную. Ес-но не коммерческую. Ибо кто вводил координаты, проделали конечно титаническую работу, но совсем не правильно отображают метки на карте. Не знают что такое кластеризаторы на карте, что при показе более 1-3тыс меток браузер жутко подвисает. Так что Web Scraping живет! ))
nike32 Автор
03.05.2018 16:14Layner, спасибо за комментарий! Если не жалко, можете поделиться своими данными на портале hubofdata.ru — это негосударственный некоммерческий портал открытых данных, мы его развиваем для сообщества.
worldnomad
03.05.2018 16:15+1есть только одна проблема и глобальная. я назову её осторожно: а правильно ли вводятся исходные данные в систему? фальсификации всего и вся — есть такая забава. Например в полиции — не регистрация каких-то преступлений, регистрация одних преступлений под видом других и пр. — чтобы не портить статистику).
а когда нет веры исходным данным, то какая разница, что там напарсено?

vadimk60
03.05.2018 19:24+1Спасибо огромное за полезнейшую статью!
К сожалению, проходит месяц, прежде чем ДТП в попадает в статистику (по крайней мере, в нашем регионе)… Кстати, стало вдруг интересно, в каком регионе этот промежуток времени минимальный и сколько дней/недель составляет.
PS:
При запуске скрипта вылезла ошибка об отсутствии модуля requests.
Питон свежескачанный и свежеустановленный.
Помогло следующее:
python\scripts\easy_install.exe requestsnike32 Автор
03.05.2018 19:29vadimk60, спасибо за комментарий про requests. Допишу про установку на гитхабе. Кстати, после установки requests нормально работает скрипт?
ГИБДД правда публикует ДТП с временнЫм лагом в 1 месяц и вроде бы всю статистику сразу (поэтому наличие данных за апрель меня сильно удивило — думала, ошибка в коде, когда результат не сошелся на 5 карточек ДТП)
vaboretti
03.05.2018 20:37Отличная статья. Давно страдаю идеей визуализировать всевозможные данные по странам. Проблема с данными – нужно кучу парсеров.
Если общественности интересна эта тема тоже, то, может быть, возможно коллективно решить проблему с парсингом?nike32 Автор
03.05.2018 22:08vaboretti, это хорошее предложение, потому что куча программистов постоянно делают одну и ту же работу, вместо того чтобы просто обменяться данными. Не потому, что жалко, а потому, что друг про друга не знают. Если есть предложения, как это можно изменить, то я буду очень рада. Кстати, и каких данных по странам вам не хватает?
TrllServ
Например в простенький csv. Онлайн конверторы, что-то пасуют.
x67
Зачем онлайн? Пишем простенький скрипт с перебором джейсона /хмл и выводом через принт с использованием форматирования. Перенаправляем stdout в файлик и вуаля, даже записывать файлики программно не пришлось. Хотя я обычно халтурю и копипасчу прямо из консоли pycharm
TrllServ
nike32 Автор
Онлайн-конверторы пасуют, потому что там довольно сложный json. В «простенький csv», конечно же, можно, но его лучше сразу взять на безопасныедороги.рф/opendata. json приходится грузить только из-за детализации самого ДТП, там много вложенных разделов: про водителя, про машину и еще что-то. делаем csv = теряем эти данные. Либо нужно делать несколько связанных csv.