
Эта статья основана на докладе Николая Самохвалова, который, в свою очередь, обобщил опыт ряда проектов, написанных на React, React Native и Swift и переходящих на парадигму noBackend за счёт PostgreSQL+PostgREST.
В конце, вы найдете список must-check-вопросов для работы с noBackend-подходом, а, если ваш Postgres-опыт позволяет, то сразу после прочтения вы можете приступить к разворачиванию безопасного, высокопроизводительного и годного для быстрого развития REST API.

О спикере: Николай Самохвалов больше десяти лет работает с PostgreSQL, является со-организатором российского сообщества RuPostgres.org и в данный момент помогает различным компаниям оптимизировать, масштабировать и автоматизировать процессы, связанные с эксплуатацией PostgreSQL. Далее — расшифровка доклада Николая на Backend Conf, рассчитанного и на бэкенд, и на фронтенд разработчиков.
Последние годы я много времени провожу в Силиконовой Долине и хочу поделиться с вами трендами, которые я там наблюдаю. Конечно, отсюда вы тоже прекрасно все видите, но там они нагляднее, потому что профессиональные разговоры о передовых технологиях ведутся буквально в каждом кафе.
Эпоха толстеющих клиентов
Давайте, сначала определим, что же такое толстеющий клиент и что за эпоха такая.
Любопытный факт. Знали ли вы что Ruby появился в один год с PHP, Java и JavaScript?

Эти четыре утенка появились в один год и, на самом деле, понятно кто из них гадкий, да? Естественно, это JavaScript.

Он был «на коленке» написан за 10 дней сотрудником, который, в рамках подготовки нового браузера Netscape, написал скриптовый язык. Вначале его даже назвали иначе, а потом, когда прикручивали Java, заодно решили и переименовать, и вот уже 23 года некоторые новички путают эти языки. Далее многие годы JavaScript выполнял второстепенную роль и был для того, чтобы сделать какую-нибудь анимацию или посчитать какую-нибудь реакцию в браузере.
Но постепенно, где-то с 2003-2004, началась шумиха вокруг WEB 2.0, появился GMail, Google Maps и прочее, и JavaScript конечно же обрел большее значение — клиенты стали толстеть. А сейчас у нас есть single-page applications и огромное количество фрэймворков на JS. Например, есть React Ecosystem для браузера и React Native для мобильных устройств. В Силиконовой Долине React — это огромное направление, которое вовлекло огромное количество людей. В один день и на соседних улицах Сан-Франциско проходило по несколько митапов по React с аудиторией несколько сотен человек.
C точки зрения JavaScript это история о дистрибьюции, о том, что бывают технологии вначале не очень хорошие, но если их установить во все браузеры и донести до каждой клиентской машины, то естественно, со временем нам всем придется иметь дело именно с этим, потому что другого, как правило, просто нет. Эта история о том, как дистрибьюция позволила этому языку развиться, занять лидерское положение среди других языков программирования.
Ниже график из исследования RedMonk.com за первый квартал 2018 года.
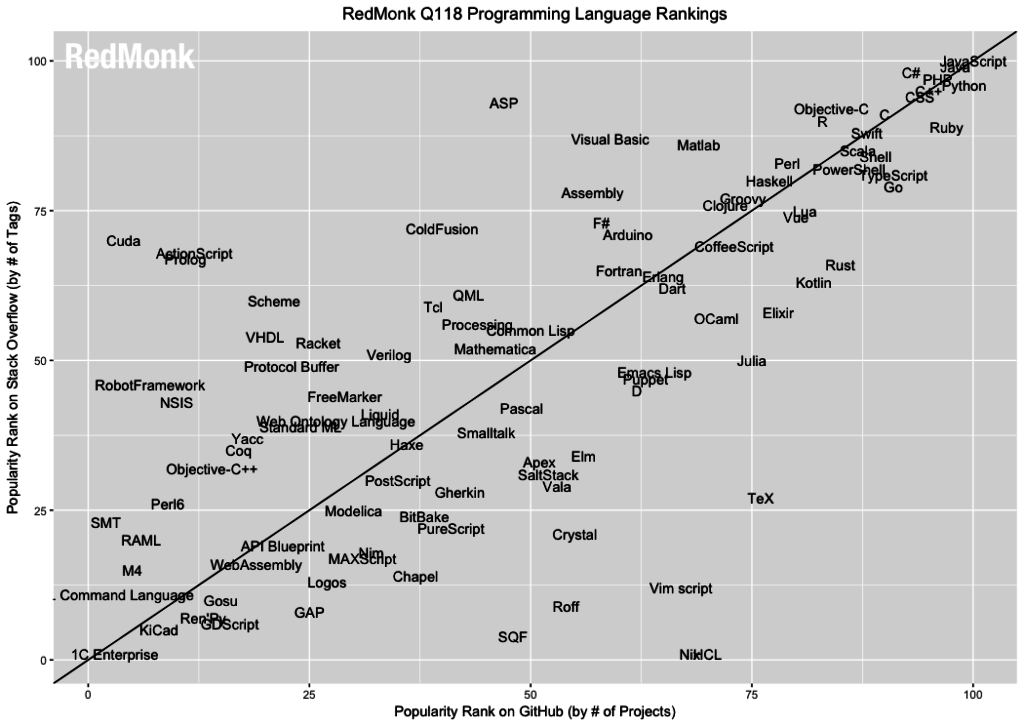
По OY — количество тегов в вопросах StackOverflow, а по OX — количество проектов в GitHub. Мы видим, что JavaScript побеждает в обеих номинациях,, но другие 3 утенка тоже совсем рядом: Java, вообще там приклеилась, PHP, Ruby тоже очень близко, то есть это 4 языка, которые родились в один год 23 года назад. Практически все другие исследования тоже подтверждают, что JavaScript опережает все языки программирования.
Я немного беспокоюсь за SQL, т.к. видел, что если SQL на GitHub немножко по-другому померять, то он даже JavaScript опередит, потому что он есть в очень многих проектах, несмотря на шумиху вокруг noSQL. Но понятно, что JavaScript это такой язык, который игнорировать невозможно.
И второй аспект толстеющих клиентов. Уже четыре года назад произошло опережение мобильных устройств над десктопом. Еще в 2015 году Google сообщила, что их поиском пользуются больше на мобильных устройствах, чем на компьютерах.

Эти два аспекта приводят нас к идее, что когда мы стартуем новый проект, то нам вообще не хочется думать про бэкенд.

Идея такая — давайте мы вообще не будем думать про Backend. Конечно, если у нас много пользователей и они как-то взаимодействуют, то нам где-то нужно хранить эти данные, естественно, на сервере и как-то с этим работать. Это просто должно быть: эффективно, надежно, безопасно.
Еще важный аспект, что если у вас не новый проект, а долгоиграющий, у которого есть сайт, приложение для iOS, Android, может быть, для smartTV и даже часов, то, естественно, вам требуется Backend и универсальный АPI.

Весь зоопарк должен унифицировано взаимодействовать и либо вы используете REST API, либо GraphQL из React Ecosystem — в любом случае, вам нужно что-то такое иметь.
Как выжить
Первый вариант. Облака
Давайте, у нас вообще не будет серверов, будем целиком жить в облаках. К сожалению, такие (специализированные облачные сервисы, предлагающие разворачивание API в облаке с минимум усилий) проекты онлайн не выжили. Два ярких представителя: StackMob.com и Parse.

И в том, и в другом случае компания, которая поглотила проект, просто перевела инженеров в более насущные проекты. Можно сказать, что в этих случаях была проиграна конкуренция облакам общего назначения типа амазоновских и гугловских, но есть еще и другие аспекты, типа непонятного API, отсутствия хранилища и невысокой производительности, но высокой цены и пр. Несколько лет назад была большая шумиха, но тем не менее эти сервисы не выжили.
В целом, мысль такая: если уж облака, то давайте более надежные, понятные, и которые завтра никуда не денутся, решения — это Amazon и Google. У них есть некоторые элементы noBackend-подхода, это Lambda и сервис для аутентификации/авторизации Cognito.
Если же вам сильно хочется совсем noBackend для API или чего-то ещё, то вот ссылка на специализированные решения для того, чтобы своих Backend-серверов не иметь вообще, а писать сразу клиентский код.
Второй вариант. PostgREST
А теперь я говорю, а давайте все-таки будем делать по-серьезному. И тут — PostgREST. Несмотря на то, что я всячески призываю его использовать, статья будет достаточно общая.

Есть такая активно развивающаяся штучка PostgREST — это по сути путь настоящего джедая, потому что позволяет довольно быстро получить всю силу.
Сила PostgREST
PostgREST написан на Haskell и распространятся по очень либеральной лицензии, активно развивается, а в gitter-чате можно получить поддержку. В настояший момент PostgREST дозрел до отличного состояния и «обкатан» во многих проектах..

На слайде выше показано, как это можно запустить: v1-схема — это схема, в которой, живет первая версия нашего API, мы можем быстренько создать табличку, либо, если у нас уже есть какие-то таблички, то можем собрать «виртуальную табличку» — представление (view). И тут же получим API-endpoint / person, у которого можно использовать параметры для фильтрации, постраничной навигации, сортировки, соединения с другими таблицами.
Поддерживается четыре метода: GET автоматически транслируется в SELECT для SQL, POST — в INSERT, PATCH — в UPDATE, DELETE — в DELETE.
Также вы можете написать хранимую процедуру и, скорее всего, если вы будете использовать PostgREST, вы будете это делать. Я знаю, что многие люди говорят, что хранимые процедуры —это зло. Но я так не считаю, у меня опыт довольно большой и я использовал разные СУБД и «хранимки» — не зло. Да, есть какие-то сложности с отладкой, но отладка вообще сложная штука.
PL/pgSQL — основной язык для хранимых процедур и для него есть дебаггеры. Но вы можете использовать также и другие языки, в том числе PL/Python или plv8 (это JavaScript, но такой, который не может общаться с внешним миром). То есть много разных возможностей, в том числе язык для аналитики и статистики PL/R. Хранимые процедуры могут вызываться с помощью POST /rpc/procedure_name (тогда в теле передаем именованные параметры) или GET /rpc/procedure_name (тогда можно использовать только GET-параметры, что влечет соответствующие ограничения).
Все уроки, которые будут в статье, в конце мы обобщим в памятку. Если вы «фронтендер», вы можете взять эту памятку и просто проверить по пунктам, насколько хорошее решение вы выбрали для бэкенда. Если же вы «бэкэндер», вам стоит проверить, насколько хорош бэкенд, который вы строите.
Качество
Начнем с первого урока, который мне пришлось выучить в нескольких проектах.
Кстати, PostgreSQL — это не обязательно чисто реляционная СУБД, вы можете и JSON там хранить, некоторые так и делают даже в платежных системах, такой своеобразный NoSQL.
Когда вы начинаете строить API, надо обложиться тестами практически сразу, обязательно. И, если вы еще не используете (хотя я думаю, большинство использует) инструменты Continuous Integration, то тут обязательно нужно это сделать и обложить тестами, особенно «плохими тестами», чтобы ничего не открыть из того, что нельзя открывать наружу. Одно дело, если вы сделали суперюзеров в базе данных и ваши рубисты это используют, другое дело — все это торчит наружу и можно сделать что-нибудь нехорошее. Какой-нибудь хакер рано или поздно придет, у меня такие случаи встречались много раз.

Незадолго перед докладом (2016 год) @backendsecret проводили опрос в Твиттере, и я вообще-то ожидал, что половина будет без Continuous Integration, но на самом деле уже все было довольно круто.
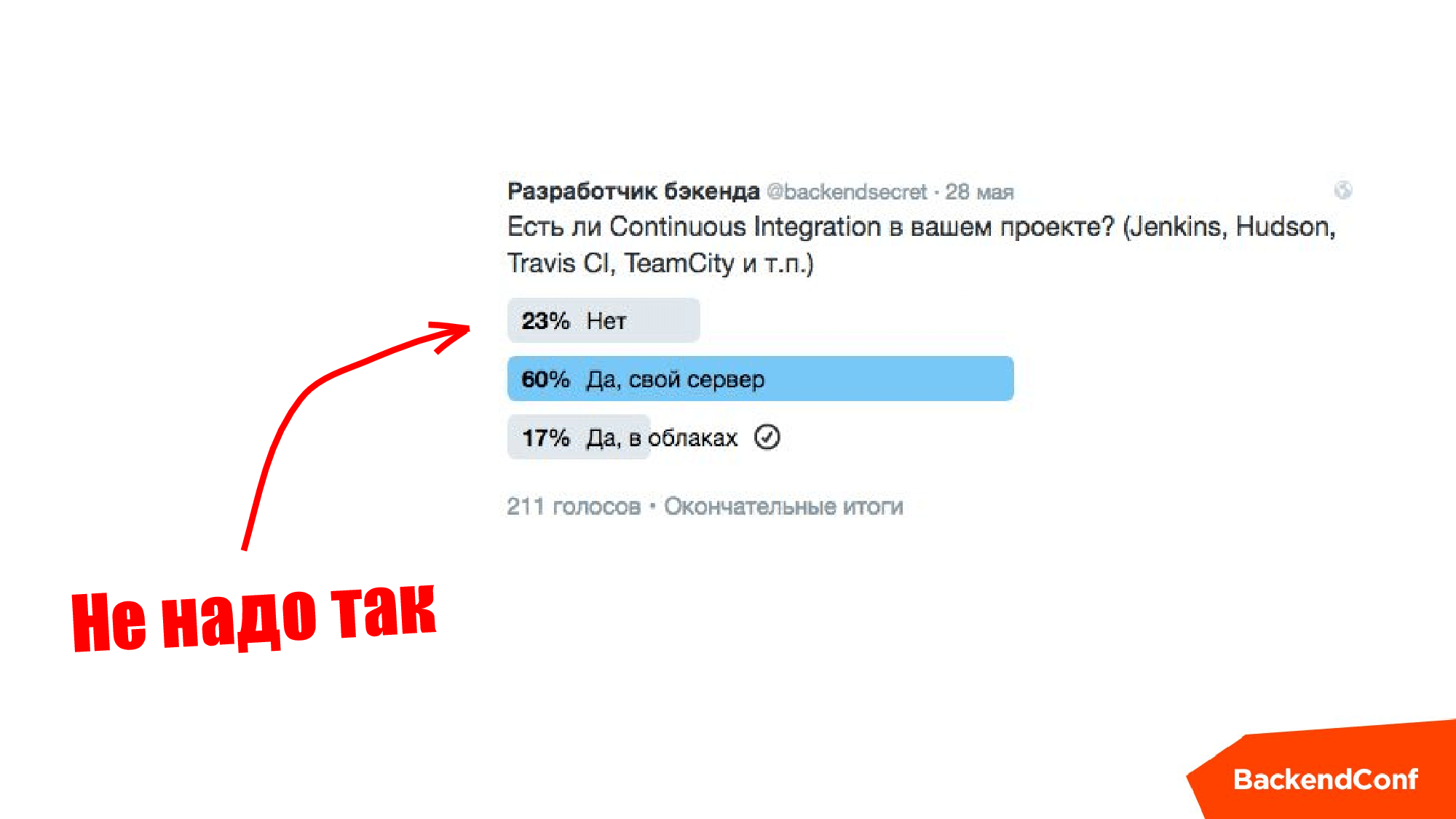
Если вы в первом пункте на слайде выше, то не надо так делать, это «лузерский» подход.
REST API
Не все знают, что можно прямо в Firefox запрос, который был сделан, просто поменять там есть Edit and Resend, есть cURL, есть консольная утилита HTTPie, в которой более удобный output.

Но главный наш инструмент — это расширение Postman для Google Chrome. Если вы работаете с API, то вам он очень пригодится. Он решает ряд проблем: вы можете накидать кучу запросов, сохранить их, сделать их абстрагированными от окружения. Т.е. у вас есть dev-сервер, staging-сервер, production-сервер — там разные хосты, там разные логины, пароли, все это можно завести как окружение, выгрузить в файлики и дальше, с помощью newman, который как бы добавка к Postman, вызвать из консоли. И разместить в вашем CI для того, чтобы тесты API выполнялись автоматически при каждом изменении в проекте.
Безопасность
Мало кто любит думать про безопасность, но делать это нужно. Например, если у нас есть табличка и мы просто создаем вьюшку в PostgREST как «SELECT * FROM эта табличка», то мы создаем себе проблему безопасности. Потому что, если у юзера, под которым действует наш API, есть права, то кто угодно может туда все что угодно заинсертить, включая, скажем, чужие user_id, то есть это вообще бардак полнейший.

В таком случае необходимо разобраться с правами реляционной базы данных и давать только те права, которые нужно. Если вы используете утилиты для миграции изменений DDL, то, например, в Sqitch есть возможность тестировать изменения, то есть их можно верифицировать с помощью migration-test. И в частности, можно назначать привилегии, но рекомендую вам такой трюк (на него ведет стрелочка на слайде выше): если случится деление на ноль, определится ошибка и это поможет проверить, что у юзера не появилась привилегия на эту таблицу.
С точки зрения API мы должны проверять, что API отвечает соответствующим кодом (в случае PostgREST чаще всего код будет 400). Если вы пишете тест в Postman, он автоматически выгружается, и дальше newman’ом все автоматически крутится и проверяется. Это нужно делать обязательно, и обязательно заранее подумать, где какие двери есть и как их закрыть.
На самом деле, в вопросе безопасности может быть три уровня проблем, поговорим о каждом отдельно.
Анонимные запросы
Первый уровень проблем — это валидация анонимного юзера, т.е. пользователя, у которого отсутствует заголовок подписи PostgREST. Если заголовок будет, но PostgREST его не опознает, то это будет «невалидный токен». Если же заголовка нет, то это считается анонимом и тогда его действия в базе PostgREST, будут выполняться под другим пользователем.

Ваша задача в том, чтобы у этого пользователя не было вообще никаких прав кроме: регистрации, логина и сброса пароля — этого хватит. Дальше вы можете написать тест и убедиться, чтобы у этого пользователя не было таких прав, как я рассказывал на предыдущих слайдах. Таким образом решается проблема анонимов.
Права на столбцы
О чем это? Если вы делаете SELECT* из таблицы «пользователь», то вы, как минимум, «светите» хэш паролей (я надеюсь, что вы храните их в хэшированном виде). Но вы «светите» и email — такого делать нельзя.

Если вы даете другим пользователям смотреть на список пользователей, вам как минимум стоит позаботиться о том, чтобы отсечь те столбцы, которые нельзя «светить». Это делается очевидным образом: при создании этой вьюшки вы перечисляете, какие поля можно читать, а не делаете «SELECT *». В PostgRESTе очень давно есть возможность показать таблицу анониму, если вдруг вам приспичило, и он сможет ее читать. Но вы можете убрать право читать на какие-то отдельные столбцы. Также можно поступить с INSERT и UPDATE и сделать это очень гибко. Например, очевидно, что пользователь не должен иметь право поменять свой ID. Права на столбцы помогают нам защитить данные, которые человек не должен иметь право менять.
Запрет доступа к «чужим» строкам
Это такой более сложный для визирования, но очень важный аспект — нельзя давать изменять чужие строчки. Т.е. если мы дали возможность апдейтить вьюшку, то по сути любой пользователь по умолчанию сможет проапдейтить и чужие строчки через API — и это беда.

Это еще одна дверь, закрытость которой надо автоматически проверять. А как ее закрыть? Если у вас самый современный PostgREST, то используйте Row-Level Security — это наиболее предпочтительный способ. Если у вас более старая версия, то пишем хранимые процедуры: PostgREST делает переменную сессии (claims.XXXXX), и мы знаем кто именно выполняет эту процедуру и можем все проверить.
Производительность
Начнем с типичного примера, допустим, у вас есть база пользователей и коллекции с постами, и допустим, что пользователей у вас миллионы и миллион блогов, и плюс еще связи между пользователями и коллекциями. На слайде ниже я отметил 4 таблицы: person, post, collection, person2collection — типичная модель любой social media и стандартная задача.

Конечно, гиганты, например, Инстаграм и Твиттер показывают нам новости не в хронологическом порядке, но в нашем примере мы будем строить хронологический порядок показов.
Есть два варианта решения этой задачи «в лоб». Первый способ на случай, если мы боимся джойнить: мы сначала выбираем посты, потом, зная из каких они коллекций, выбираем коллекции, дальше — выбираем автора.
Второй более в стиле PostgREST: написать JOIN из 4-х таблиц и дальше это все «переварить». Например, выше я привел row_to_json, и тогда PostgREST вернет вам json, в который будет вложен json с информацией об авторах и коллекциях.
Но оба эти запроса плохие в плане производительности. Но первый запрос намного хуже, потому что там 3 запроса, 3 API вызова. Когда вы пишете на Ruby/PHP/Python, то вы можете не сильно об этом беспокоиться, в некоторых СУБД удобнее сделать три быстрых и коротких SQL-запроса вместо одного. Но совсем другое дело, когда вы делаете это через API. Представьте, что человек из другой страны, и round-trip time может быть 100-200 миллисекунд, и вот у вас уже появляются 600 лишних миллисекунд. Их могло бы быть 200, а теперь 600. То есть, первый вариант нужно отмести сразу — мы должны стараться все делать одним запросом, если, конечно, это возможно
Итак, первый под-урок здесь в том, что в первую очередь мы должны думать про сетевую сложность.
Кстати, если вы работаете с реляционной базой, запомните, что ни в коем случае не надо использовать OFFSET для постраничной навигации. На слайде она сделана с помощью WHERE и использования предыдущего ID.
Если у вас большие объемы данных, то вы стопудово получите проблемы и со вторым методом, потому что он будет работать секунды, а то и десятки секунд.

С этим столкнулось много проектов, в том числе несколько моих, и меня очень выручил известный эксперт по PostgREST, проживающий в Австралии, — Максим Богук, очень рекомендую эту презентацию его доклада на PGday. Изучив ее, вы сможете освоить джедайские техники, такие как: работа с рекурсивными запросами, с массивами, сворачивание-разворачивание строки и, в том числе, подход очень экономно считывания данных Loose IndexScan.
Ниже приведен реальный запрос для одного из проектов аналогичный первым двум, но который работает единицы миллисекунд на тех же самых данных.
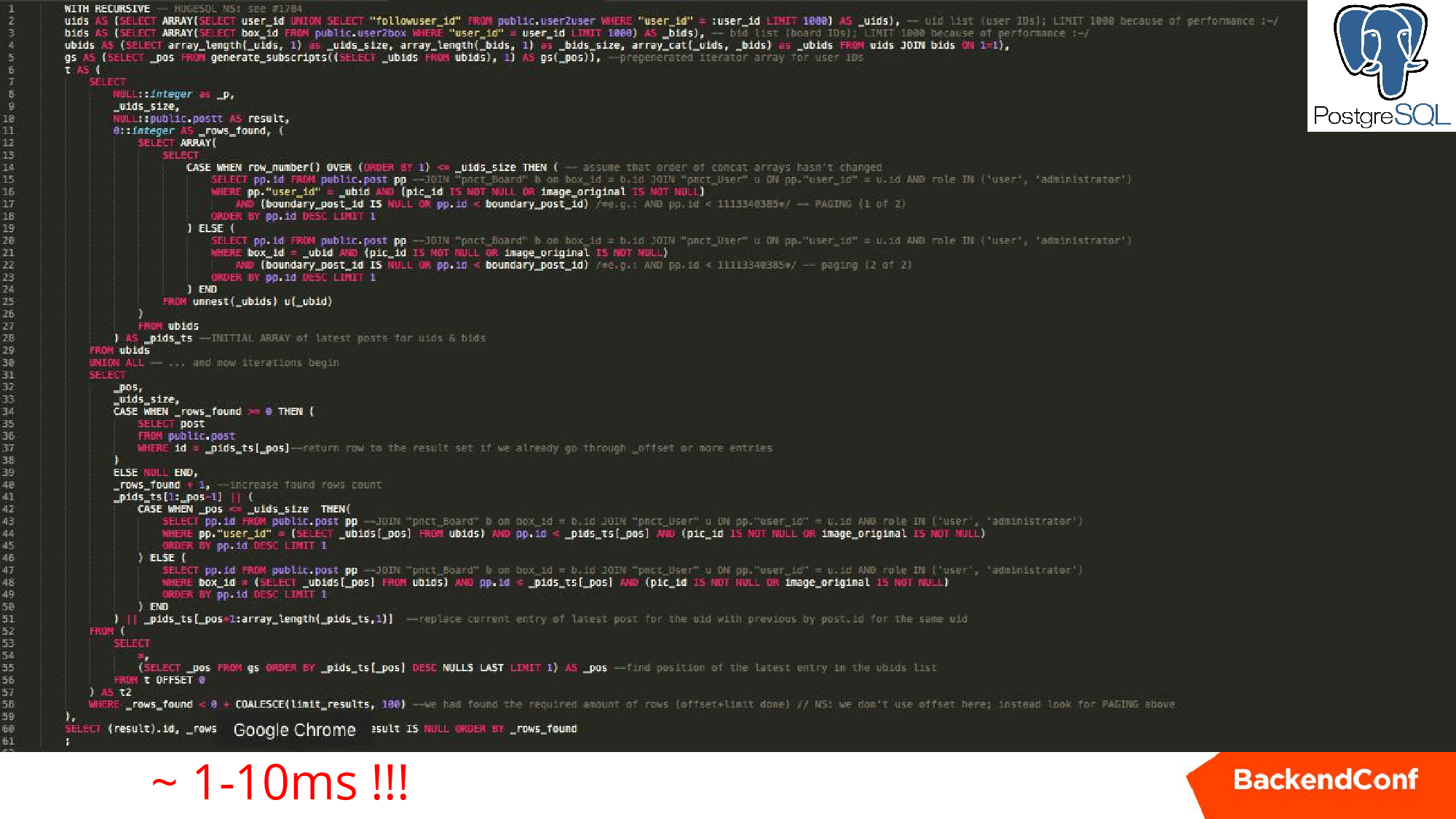
Он рекурсивно раскручивает нашу задачу, получая по одному посту из каждой коллекции, формирует набор, дальше идет замещая, замещая, пока не наберет 25 постов, которые уже можно показывать. Очень классная штука, советую изучить.
При использовании PostgREST у вас огромное количество инструментов, чтобы увеличить производительность, вы можете использовать силу.
Масштабируемость
Первый уровень: понятно, что у нас нет сессии, RESTful подход и PostgREST можно поставить на большое количество машин и он будет спокойно работать.
Второй уровень. Например, если вам нужно смасштабировать читающую нагрузку, то вы тоже можете настроить специальные PostgREST экземпляры, которые будут обращаться только к slave, и с помощью ngnix балансировать нагрузку. Здесь все прозрачно, в отличие от монолитных подходов.
Обратите внимание, вся эта тема очень похожа на Object-Relational Mapping. То есть это, конечно, не ORM, а такой JSON-Relational Mapping.
В данном случае, когда вы имеете GET, то 100% это только читающая транзакция SELECT (если только это не SELECT /rpc/procedure_name, о котором упоминалось выше). Поэтому ngnix несложно настроить конфигурацию, чтобы он часть трафика направил на другой хост. Все в руках админа, который занимается ngnix. Те, кому это все пока не нужно, могут быть уверены, что в будущем вы сможете масштабировать свой проект.
Вопрос: как масштабировать master? Сходу — пока никак, но в Poctgres-community над этим активно работают.

Еще есть философский аспект: вся эта шумиха вокруг WebScale. Когда вам нужно вскопать поле, что вы предпочтете: 100 гастарбайтеров с лопатами или трактор? Сейчас PostgreSQL приближается к тому, чтобы производить на одном сервере миллион транзакций в секунду. По сути, это трактор, который каждый год улучшают, каждый год выпускают новую версию, и он реально очень продвинутый.
Если же вы ставите решение типа MongoDB, то, во-первых, оно хуже работает на одной машине, и, во-вторых, у них просто нет возможностей PosgreSQL — это далеко не трактор. Вам, как и с гастарбайтерами, нужно обо всех них беспокоиться, серверы на MongoDB нужно обслуживать, они выходят из строя, капризничают.
Задача вскопать поле может решаться трактором намного эффективнее и по стоимости, и по времени, и на будущее это может оказаться лучше.
Что не стоит делать внутри?
Ответ очевиден! Если вы запрашиваете внешний сервер, не стоит делать этого прямо в PostgREST, потому что это займет непредсказуемое время, и не стоит удерживать бэкенд Posgres на master непонятное время.

Стоит пользоваться методами LISTEN/NOTIFY — это старая, уже давно отлаженная, штука. Или реализовать очередь прямо в БД, используя очень эффективную обработку во много потоков с помощью «SELECT… FOR UPDATE SKIP LOCKED».
Вы можете сделать скрипт на Node.js или RUBY или, на чем угодно, этот демон подпишется на события в PostgREST, а дальше хранимая процедура просто отправит сообщение в этом событии, а ваш демон его подхватит.
Если вам хочется, чтобы события, которые вдруг какое-то время никто не слушал, не пропали, то придется поменять все системы очередей. Для этого есть ряд решений, это тема довольно изъезженная, просто приведу несколько ссылок:
- LISTEN/NOTIFY (пример есть в документации по PostgREST postgrest.com/examples/users/#password-reset).
- mbus (Р. Друзягин, И. Фролков, доклад PgDay’15 pgday.ru/files/papers/23/pgday.2015.messaging.frolkov.druzyagin.pdf).
- Сообщения в AMPQ (например, PostgreSQL LISTEN Exchange: github.com/aweber/pgsql-listen-exchange).
И наконец, обещанная памятка. Это список всего, что мы сегодня обсудили. Если вы начинаете новый проект или переделываете старый на использование внутреннего API — проходитесь по этим пунктам и будет вам счастье.

Контакты и ссылки:
Email: ru@postgresql.org
Сайт: http://PostgreSQL.support
Твиттер: https://twitter.com/postgresmen
YouTube: https://youtube.com/c/RuPostgres
Митапы: http://RuPostgres.org
На ближайшей Backend Conf Николай продолжит нести Postgres в массы, в частности, обещает презентовать новый инструмент полуавтоматического поиска узких мест по производительности, не требующего глубокого знания внутренних компонентов.
Не забудьте и о Highload++ Siberia, до летней конференции разработчиков высоконагруженных проектов менее двух месяцев — самое время бронировать билеты.
Комментарии (85)

IvanNochnoy
15.05.2018 15:12Мне не очень понятно, как Cut из бэкенда и Paste во фронтенд облегчит мою жизнь. Подожду-ка я развития WebAssembly, бо недолго осталось.
Londoner
15.05.2018 15:58Мне не очень понятно, как Cut из бэкенда и Paste во фронтенд облегчит мою жизнь
Не знаю как Вам, а вот гавнокодерам (коих, кстати, во фронтэнде почему-то собирается всегда больше, чем в бэкэнде) это точно облегчит жизнь: почти весь их ароматный продукт теперь будет кушать память и процессор не на сервере, а в браузере пользователя — больше не надо заботиться ни о памяти, ни о производительности.F0iL
15.05.2018 16:31+1Учитывая, что разработчики Chromium, судя по последним выступлениям на конференциях, очень серьезно озаботились проблемой «фронтендеры делают говно и из-за этого процессы браузера падают с OOM» (на BlinkOn в апреле почти каждый третий доклад был на тему памяти и производительности), и намерены бороться с этим всеми способами (от развития инструментов профилирования и отлова утечек, до предупреждений прямо в браузере и понижения кривых сайтов в выдаче поисковиков), то халява продлится недолго.
Londoner
15.05.2018 17:00+2Пусть тогда начнут с себя и починят gmail.com
F0iL
15.05.2018 17:14+1Об этом тоже было. Они рассказывали, что ради интереса расчехлили все тулы и проанализировали десяток топовых веб-приложений, типа твиттера, фейсбука, и в том числе свои GMail, GDocs и другие. В 10 случаях из 10 нашлась хотя бы одна утечка. Так что, думаю, разрабам гмыла найденные результаты зарепортили.
Вот здесь вот доклад можно посмотреть: drive.google.com/file/d/1-PxC6GmMf-x-zg_MEaSKUZE2YFKdV3Ah/viewLondoner
15.05.2018 17:38И что, разрабы gmail-а и всех прочие побегут это фиксить в тот же день? Gmail, например, в первую минуту отжирает почти пол-гига оперативки, безо всяких утечек, они ещё не начались. Они это тоже пофиксят?
mayorovp
15.05.2018 17:40+1У меня он за день отжирает всего 200 метров. ЧЯДНТ?
Londoner
15.05.2018 17:53Хорошо, у Вас меньше — 200 мегабайт. Вы считаете эту цифру нормальной?
F0iL
15.05.2018 18:52+1Ну вообще-то да. Учитывая, что это практически полнофунциональный email-клиент, со встроенным визуальным редактором текста, поиском, интеграцией с календарем и контактами, и многим другим, плюс оффлайновый кэш. Это SPA, поэтому большая часть функционала грузится разом.
Для сравнения, посмотрите на Thunderbird и Evolution — они памяти потребляют не меньше.
Если вам не нравится SPA, используйте вариант Basic HTML, только и всего.Areso
15.05.2018 18:58Потому что Thunderbird это программа на движке Mozilla Firefox.
F0iL
15.05.2018 19:01Ну я как бы в курсе, да. А GMail — программа (SPA), работающая в Chromium.
Areso
15.05.2018 19:05SPA, если это не единственная открытая вкладка в браузере, делит среду выполнения с другими страницами, чем повышает утилизацию ресурсов (в теории). А Thunderbird загружает браузерный движок для себя одного-любимого.
У меня есть SPA, они не жрут память как не в себя. При том, что я программист в общем-то весьма посредственный.F0iL
15.05.2018 19:15+1И да, и нет. В современных браузерах есть разделение на browser process (головной) и кучу renderer processes (под одному на каждый сайт или даже каждую вкладку), взаимодействующих через IPC (что тоже ведет за собой накладные расходы). Что-то они шарят, что-то нет (можно посмотреть встроенными профилировщиками типа memory-infra, или через pmap/smap).
keydon2
15.05.2018 16:52+2Раньше вы это обнаруживали у себя на сервере и, если это вас не устраивает, можете что-то с этим сделать.
Теперь эти тормоза будет обнаруживать у себя пользователь в браузере. И далеко не факт, что захочет сообщить об этом и пользоваться вашим ресурсом.Londoner
15.05.2018 17:04-2О чём Вы? Большинство пользователей даже и не поймёт, какая из вкладок кушает ресурсы. Решит что надо новый ноут купить, а то это штой-то греться и тормозить стал.
Знаете, какой раньше был самый посещаемый ресурс в инете? Microsoft.com — потому что большинство пользователей не умеет настроить в IE дефолтный URL.Hardcoin
16.05.2018 11:22Пользователь, конечно, решит, что надо новый ноут купить. Но пока денег нет, будет пользоваться тем, что есть. И если ваш сайт не даёт исключительной ценности, вполне может на него и забить.
jakobz
15.05.2018 17:09+5Там же речь не о том, чтобы перенести что-то на клиента. Там речь — выкинуть самодельные реализации REST API с сервера, которые содержат тонну всякого ORM/OOP-шлака, а пользы особо давно уже не приносят, по крайней мере, в SPA-приложениях.
IvanNochnoy
15.05.2018 18:07+1Это все будет работать только если нужно только взаимодействие Клиенты -> База данных. В реальной жизни такого не бывает.
jakobz
15.05.2018 18:41Никто не мешает расчехлить и поставить рядом ту же java/.net/PHP/node — и реализовать дополнительные REST API, либо интеграции типа
[внешняя система] => БД. Все равно сэкономится большой кусок работы про велосипедостроение REST API.IvanNochnoy
15.05.2018 18:53+2Есть подозрение, что в этом случае придется делать двойную работу. Толстые клиенты были ещё в прошлом веке, только обращались напрямую к базе без всяких REST. Если кто-то хочет делать ИНТРАнет-приложения в браузере, это ещё как-то можно использовать в данном сценарии.
kekekeks
16.05.2018 01:10Ну вот пытался я как-то собрать софтину под WebAssembly этот ваш. Упёрся в лимит на 1000000 функций по достижению которых чудо-браузеры (FF, Chrome) отказываются грузить бинарник (хотя он сравнительно небольшой, 9 метров всего).
Так что вебассембле передают привет плюсовые шаблоны, которые она в приемлемых количествах жевать не умеет и в ближайшее время не собирается
Ztare
16.05.2018 20:02Самое интересное что не просто перенос, но еще и костылями формировать безопасность каждого запроса, каждой сущности, строки БД или колонки и при этом увеличивая шанс ошибки контроля доступа в тех проектах где можно было обходиться какими-то общими практиками/фреймворками. И весь контроль доступа как-то очень низкоуровневый оказывается.
R33GTRVspec
15.05.2018 17:44+1Спасибо за материал!
Только не совсем понял хронологию событий в докладе, он из прошлого(<=2016) или все же это 2018ый год?
gnomeby
16.05.2018 05:18-1В Силиконовой Долине
Нет, нет и нет. Вы можете сколь угодно ссылаться на то, что пошло в народ. Но на техническом ресурсе мы это не потерпим.
AntonRiab
16.05.2018 08:40Год назад, я просвещал аудиторию идеологический близкой архитектурой на базе своего велосипеда — nginx модуль на bulk requests, статья Страх и ненависть в MiddleWare.
Основные категории прилетевших тапков были из следующих направлений:
- ~50% — за регулярки — вы это обошли.
- ~50% — это неприязнь разработчиков к подобным архитектурам с логикой в базе. Возможно это вы тоже обошли — отсутствием публикации в хабе «Разработка веб-сайтов».
Удачи в развитии!mayorovp
16.05.2018 09:14С базой тут интереснее, дело не только в хабе. Заметьте: вы предлагали использовать на любой чих хранимые процедуры или триггеры, у которых нет особых преимуществ перед обычными языками программирования, но есть куча недостатков.
Здесь же предлагается работа напрямую с таблицами в СУБД.AntonRiab
16.05.2018 10:58Да — в postgrest встроены фиксированные: сериализация данных, синтаксис фильтрации столбцов и даже джоины.
Нет — postgrest не реализует прикладной логики.
Более того, вы не будете делать верификацию связей таблиц с клиента, логирование и всего того, что эффективней провернуть на стороне, которая ближе к данным, т.е. в СУБД.
И как только вам понадобиться что-то более сложное, чем просто записать или вытащить данные по элементарному условию через предлагаемый OpenAPI, вы вспомните следующую строку статьи:
Также вы можете написать хранимую процедуру и, скорее всего, если вы будете использовать PostgREST, вы будете это делать.
И можете — это мягко сказано. В документации к OpenAPI Postgrest написано ещё конкретее:
It prevents arbitrary, potentially poorly constructed and slow client queries. It’s good for quality of service, but means database administrators must create custom views and stored procedures to provide richer endpoints.
Как бы вам не хотелось, в данной архитектуре, вы очень быстро придёте всё к тем же хранимым процедурам, за исключением сериализации данных.jakobz
16.05.2018 13:35Как бы вам не хотелось, если у вас БД и нагрузка или сложная логика — придётся руками оптимизировать запросы. И все равно где и как они были написаны до необходимости их оптимизировать -в ORM на Java, или в клиентском коде в виде graphql или птичего query-string языка в Postgrest
pawlo16
16.05.2018 21:10из перечисленного проще всего оптимизировать традиционный бэкенд — отладчики, компиляторы, стат. типизация, тестовые фреймворки. Хранимки оптимизировать — это ужас. С другой стороны если перенести какую-нибудь примитивщину на этот самый постгрест, которую не надо дюже оптимизировать трёх этажными наговорами на SQL, то можно избавится от изрядного количества раздражающего бойлерплейта
jakobz
16.05.2018 21:54Так оптимизация на стандартном бекенде, даже с ORM — все равно сводится к тому, чтобы он делал более эффективные SQL-запросы. Кроме БД там нечему тормозить же. Можно оптимизировать SQL-запросы на уровне ORM — и это проще, да. Но смысл-то не меняется.
nikolay_samokhvalov
17.05.2018 03:33Есть мнение (и не только моё), что хранимки-то как раз *гораздо* проще оптимизировать, чем ORM. Спросите любого эксперта по оптимизации SQL, что ему будет удобнее — SQL в хранимке или ActiveRectord и прочие.
mayorovp
17.05.2018 06:02А эксперт по оптимизации ORM скажет ровно обратное :-)
nikolay_samokhvalov
17.05.2018 06:07О как.
Я всегда с удовольствием готов изучать что-то новое.
Расскажите, что это за зверь такой.mayorovp
17.05.2018 08:49Да ровно то же самое, только в другом месте…
nikolay_samokhvalov
17.05.2018 10:18Какой-то не особо пока известный науке зверь получается.
А чего и как он там оптимизирует, не имея нормальных средств для диагностики (статистика, explain) и собственно оптимизации (индексы, параметры СУБД, БД и её объектов)?
IvanNochnoy
17.05.2018 10:41+1Да почему не имеет-то? Смотреть он может в том же SQL-профилировщике, а оптимизировать запрос в самом ORM.
nikolay_samokhvalov
17.05.2018 10:57Уходим на второй круг. Где почитать про это можно?
IvanNochnoy
17.05.2018 11:23Там ничего нового для себя Вы не узнаете. Просто пишется SQL-запрос который сохраняется в файле, ORM его выполняет, смотрится лог, профилировщик, статистика. Если что-то не так, запрос изменяется. В большинстве случаев это работает. В особых случаях пишется хранимка, которая вызывается как метод из ORM. Разработчики Entity Famework могут использовать LINQ вместо SQL, а Hibernate, составлять запросы объектно-ориентированно в виде Criteria. Отладка происходит точно так же, как при использовании обычного SQL.
nikolay_samokhvalov
17.05.2018 11:56-2Вы только что описали стандартный сценарий, в котором вся идея ORM – асбтрагироваться от SQL и «ненавистной базаданщины» — сводится на нет.
Да, именно так обычно и происходит при росте нагрузки и проблемах с производительностью — SQL-лапша, созданная в недрах ORM, шевелит волосы у DBA и, чтобы снизить энтропию, запрос фиксируется или начинается нормальная работа по оптимизации. Завод по производству (ORM) со всей его дурной мощью вдруг становится не нужен, программист получает нормально отформатированный и отдаженный SQL (или хранимку! об этом я и говорил изначально — её отлаживать проще, когда нужно ехать, а не «шашечки») и вся роль этой лапшефабрики сводится к дёрганию метода query(..) или аналога, а такой метод есть и в самом драйвере вашего любимого языка к СУБД.
Есть много статей на тему «почему ORM – зло», наблюдаю их лет 15 ежегодно. Тема очень, очень и очень холиварная, но в целом сводится к тому, что лучше тратить время на изучение SQL, чем на штуку, которая позволяет якобы от него отойти.
На самом деле, если рассуждать дальше, PostgREST и подобные прокладки — в целом тоже похожее зло. Но всё же чуть меньшее, потому что:
- меньше степеней свободы (сложнее отсрелить себе ноги, используя какую-нибудь ООП-ориентированную конструкцию, трансляция GET/POST/PATCH/PUT в SQL гораздо более примитивная вещь, чем ORM),
- поощряется изучение SQL так или иначе — когда определяете вьюшки, вы испольузете SQL и это проще отлаживать,
- аналогично с хранимками, чем больше их используете, тем глубже понимаете работу БД и делаете вещи более оптимально, SQL внутри PL/pgSQL – абсолютно родное и естественное тело (
var1 := 0;– это на самом делеselect 0 into var1;. А как легко и приятно писать штуки типаif (select count(1) from blabla) > 0 then ...!).
IvanNochnoy
17.05.2018 13:24Любая абстракция возможна только при потере детализации. То что ORM — это крайне текучая абстракция над БД — известый факт. ORM не способна волшебным образом преврать реаляционную (и даже документную (не путать с объектной)) базу в граф объектов в памяти. Эта абстракция работает ровно до тех пор, пока кто-то кривым запросом не вытащит в память всю базу данных целиком. Так что оптимизровать ручками, либо автоматом, либо ИИ придется рано или поздно, ORM не решает этой задачи (почти). И не должна (неоторые ORM способны оптимизировать до некоторой степени). Суть ORM отображена в названии — спроецировать объектную модель на реляционную. Не всем людям нравится получать ассоциативный массив со строковыми ключами, как, например, иногда делают в PHP; они хотят иметь настоящий объект с возможностью его безболезненного рефакторинга. Это особенно приятно, если есть возможность писать запросы на основном языке программирования. Ну или хотя бы Query Builder какой-нибудь.
Что касается простоты отладки хранимок: возможно. Но за все нужно платить: хранимки жестко прибиты к конкретной базе данных, их тяжело рефакорить, они требуют наличия специалиста. Иногда это выгодно, иногда нет.
mayorovp
17.05.2018 13:31Вот не надо так категорично, далеко не все сводится на нет.
Запрос лежит вместе с исходниками и изменяется с ними же, в то время как хранимки лежат в БД и в лучшем случае изменяются миграциями. Как результат — я всегда могу сделать git blame запросу, но зачастую не могу то же самое проделать с хранимкой.
В строго типизированных языках ORM берет на себя раскладывание результатов запроса по полям структуры или объекта с контролем типа. Можно в одну строчку выполнить запрос и получить коллекцию результатов.
Если же отбросить ORM — то то же самое придется делать вручную. На сложный запрос может уйти целая страница кода только для подготовки параметров и чтения результатов… Казалось бы, причем тут оптимизация? А при том, что чем меньше кода — тем проще его менять. Главный враг оптимизации — мысли "ну вот, я щас что-нибудь поменяю — и опять все поломается".
Ваше утверждение "хранимку отлаживать проще" ничем не обосновано. И от того что вы его повторите еще пять раз — оно не станет истиной.
Точно так же ничем не обоснована эмоциональная оценка, которую вы дали разным технологиям ("ORM со всей его дурной мощью" и "нормально отформатированный и отдаженный SQL"). Я точно так же могу написать "с появлением нормальных ORM программисты получили возможность писать нормально отлаженный и отформатированный код вместо SQL со всей его дурной мощью" — и это будет ничуть не менее правдиво (и не более).
nikolay_samokhvalov
17.05.2018 13:48Так, стоп, стоп. Я вас узнал :-)
Отматываем чуть назад и ждём обоснований ваших прошлых утверждений. Напоминаю:
> А эксперт по оптимизации ORM скажет ровно обратное :-)
Вопрос: Я всегда с удовольствием готов изучать что-то новое.
Расскажите, что это за зверь такой.
> Да ровно то же самое, только в другом месте…
Вопрос: А чего и как он там оптимизирует, не имея нормальных средств для диагностики (статистика, explain) и собственно оптимизации (индексы, параметры СУБД, БД и её объектов)?mayorovp
17.05.2018 14:01А кто вам сказал что нет средств для диагностики и оптимизации?
Статистику собрать несложно. Explain делается тоже довольно просто: перехватывается запрос и делается ему этот самый explain. На всякий случай уточняю: тот факт что в какой-то момент программист увидел SQL никоим образом не нарушает абстракцию.
Индексы и параметры СУБД настраиваются точно так же как и раньше: ORM абстрагирует от DML, а не от DDL.nikolay_samokhvalov
17.05.2018 14:10-1Вы сами и сказали только что.
Ну и осталось ещё один шаг в рассуждениях сделать, чтобы понять, что раз ORM никак не помогает в оптимизации, то она, наоборот, мешает (затрудняет доступ к реальному SQL, часто производя ту самую неотформатированную, малопредсказуемую и малоуправляемую лапшу, о которой уже была речь выше).
Думаю, тут мы уже всё прояснили и копать больше некуда.mayorovp
17.05.2018 14:18Откуда взялось утверждение "ORM никак не помогает в оптимизации"? ORM помогает в написании запросов, а значит и во всех связанных занятиях (в том числе в их оптимизации).
Почему вы рассматриваете "доступ к реальному SQL" как нечто самоценное?
jakobz
17.05.2018 10:56+1Я немного неправильно выразился. Скорее «дешевле» чем «проще»
Вынуть кусок кода из ORM в хранимку, и оптимизировать там — проще, да, там сразу можно кучу фичей недоступных в ORM взять, например разбить запрос через временные таблицы, или CTE какие-нибудь взять.
Но как только это сделал — оно будет аукаться на каждом изменении схемы БД. Ну, например рефакторинги, и find usages в IDE — хранимку не видят. Поэтому оставаться в рамках ORM — дешевле в долгосрочной перспективе. Можно же прям в ORM запрос поменять, разбить на пару запросов попроще, индексы докинуть на таблички.nikolay_samokhvalov
17.05.2018 12:12Верно. Тут ключевое даже не временные таблицы или CTE, а RTT — сетевая сложность. Хранимка даёт возможность отработать всё на сервере с использованием индексов и алгоритмов СУБД и выдать уже краткий результат без лишнего бегания туда-сюда.
Что касается рефакторинга. Мне немного сложно понять, о чём тут речь, т.к. я много лет в tmux+vi и не понимаю, о какой IDE тут речь и о каких её средствах.
Но как-то похоже на то, что подразумевается, что код хранимки — это что-то такое, что где-то там запрятано в недрах БД. Это, конечно, не так (а если так — это беда и так делать нельзя). Хранимка — это обычный код, должен быть в git, версионироваться и нормально рефакториться. Другое дело, что, может быть, «find usages» вашей IDE пока не поддерживают plpgsql (а может, поддерживают? доступные плагины смотрели?).mayorovp
17.05.2018 13:47Хранимка — это обычный код, должен быть в git, версионироваться и нормально рефакториться.
Отлично, осталось найти способ разместить его там. Так, чтобы изменения в нем автоматически применялись к БД при развертывании.
Особенно весело когда хранимка зависит от таблицы, а в таблице есть вычисляемый атрибут, который обращается к пользовательской функции. Вот как автоматически построить порядок в котором вся эта радость должна создаваться в базе, причем с учетом того что база прошлой версии уже есть и дропать ее нельзя?
nikolay_samokhvalov
17.05.2018 13:57Ага, «вычисляемый атрибут». MySQL? Теперь я ничего не имею против того, что вы не любите хранимки и плохо меня понимаете. Подождите ещё несколько лет, пока их, а также транзакционный DDL, недостатки поддержки целостности данных (типа stackoverflow.com/questions/2115497/check-constraint-in-mysql-is-not-working) допилят до нормального состояния. В MySQL 8 и свежих MariaDB дела с некоторыми из этих вещей уже сильно лучше, советую обновиться.
А лучше переезжайте уже на Постгрес, чтобы понять, что такое нормальные хранимки, поддержка целостности, транзакционность DDL, больше современных фич стандартного SQL.
Код каждого объекта — в отдельном файле, конечно же в git. В качестве системы миграций — sqitch.org (или другая, есть много разных со своими плюсами-минусами. Только обязательно что-то выбрать надо — ничего страшного и стыдного нет, что вы ещё это не сделали, все через это когда-то проходили). Для версионирования хорошо помогают схемы (каждая версия — в отдельной схеме). Также по этим темам полезно послушать доклады Яндекса, Авито и других крупных компаний. Много чего можно найти тут: www.youtube.com/playlist?list=PL6sRAkPwcKNnwScnpKomNXechZQ3WZe1jnikolay_samokhvalov
17.05.2018 14:02Да, sqitch вы можете и с MySQL использовать, он мультиплатформенный. Как и какой-нибудь более «энтерпрайзовый» liquibase.
Это ответ на вопрос «как разместить в git».
mayorovp
17.05.2018 14:02Нет, не угадали, MS SQL. Кстати, его-то sqitch и не поддерживает, а я уж обрадовался…
mayorovp
17.05.2018 14:28Да, глянул документацию на sqitch внимательнее… К сожалению, эта штука не в состоянии сама установить зависимости между объектами базы. А значит, возможен вариант когда из-за забытой зависимости миграция сломается через два месяца и сразу на проде.
А еще пугает ее способность rebase, которая дропает из базы все данные...
mayorovp
17.05.2018 14:32Вот еще интересный вопрос. sqitch же требует revert-скрипта для любого объекта.
Как сделать revert для
alter table Foo drop column Bar?
jakobz
17.05.2018 21:21Я как-то давным-давно писал тулзу, чтобы мигрировать БД. Схема мигрировалась как обычно — дельта-скриптами и табличкой в БД чтобы знать какие скрипты уже накатили. А хранимки/функции/view — лежали на диске, по файлу на объект.
Алгоритм был такой:
— сносим все хранимки/прочие объекты с БД
— прогоняем дельта-миграции
— кладем все *.sql файлы с хранимками/вьюхами/UDF в список-очередь
— накатываем по одному объекта из списка. Если при накатывании SQL кидает ошибку — кладем в конец списка и продолжаем накатывать следующий
— если мы пробежались по кругу, и очередь не уменьшилась — кидаем все ошибки в консоль.
Таким образом обрабатывались даже нетривиальные зависимости, вроде той что ты пишешь.
Работало все отлично, шустро, и без проблем.
Было это лет 7 назад. А известной статье — blog.codinghorror.com/get-your-database-under-version-control — по мотивам которой я эту тулу и делал — уже 10 лет. С тех пор, я так и не увидел ни одной тулы для миграций БД, которая реализовала бы такой механизм. В современных тулах для миграции, хранимки предполагается класть в миграции — и это совсем тупо, да. И многие так и делают, от чего хочется плакать.mayorovp
17.05.2018 21:27А что вы будете делать с вычислимым атрибутом (колонкой)? Тоже дропать его? А если по нему строится индекс?..
Еще будут проблемы с материализованными (индексированными) представлениями. Все-таки терабайтная вьюха пересоздается слишком долго чтобы ее можно было дропать без повода…
jakobz
17.05.2018 14:37+1Чтобы был контекст: у меня .NET/Entity Framework, SQL Server, бизнес-приложения, нагрузка — низкая, сложность запросов — высокая (в основном — из-за сложных security-правил).
В SQL Server — совершенно убогий язык T-SQL. Я видел проекты где все на хранимках в T-SQL — там совершенный ад был.
В других раскладах, например если java, где запросы в ORM — просто строки, и есть Postgres — где человеческий встроенный язык — расклад может быть другой.
С .NET/EntityFramework, ты можешь в Visual Studio нажать правой кнопкой на поле класса, которое соответствует полю таблички, выбрать rename, ввести новое имя, и весь код гарантированно корректно поправиться. Миграция БД сделается почти автоматически.
С хранимками же — тебе надо будет руками ходить и каждую править. Файлы .sql с хранимками — они не прозрачны для IDE, она не понимает даже про какую БД они. Из удобств — только поиск по тексту. Возможно, в других БД иначе, но в SQL Server/SQL Server Management Studio — оно так.
Т.е. я не говорю что совать всю логику в хранимки — плохо. Но чтобы делать хранимки надо хороший язык в БД, хороший тулинг, нужно толковых базистов. И нужно выкидывать ORM и все делать тогда в БД. Пополам-напополам — получается шиза и бардак.
Да и в целом, код и данные должны быть близко. Для этого можно тащить код к данным (хранимки, Tarantool, и т.п.), или тащить данные ближе к коду (Datomic). А ORM — это дураций костыль, возникший от того что есть хорошие БД, но они — black box — и в них нормальный язык не всунешь, и их как библиотеку к себе код не вставишь. Думаю эта проблема решится потихоньку, и ORM вообще отсохнут со временем.pawlo16
17.05.2018 21:12Мне вот не хватает мотивации для ORM, хотя и от написания хранимых процедур я не в восторге. Например, учёные всего мира безуспешно бьются над вопросом — как обучить ORM древовидным/рекурсивным структурам данных, которые довольно часто встречаются. Я тоже пытался — никак.
Но даже для реализации банального отношения one-to-many в ORM нужно прописывать не типизированные метаданные, просто вывести SQL запрос из класса ORM не может. Для этого надо выкурить на много больше доков по ORM, чем знание пары тройки SQL инструкций, которые она генерирует. То есть возни много, а на выходе пшик.
Миграция с переименованием полей не на столько частый рефакторинг чтобы из-за него тащить с собой EF (у меня контекст аналогичный, низкая нагрузка, сложные данные, стек другой). И тот же DataGrip в раз сделает все переименования в хранимках, в t-sql в т.ч.IvanNochnoy
17.05.2018 21:34Но даже для реализации банального отношения one-to-many в ORM нужно прописывать не типизированные метаданные, просто вывести SQL запрос из класса ORM не может.
Будет время, примерчик бросьте, пожалуйста, а то не очень понятно, о чем речь.
mayorovp
17.05.2018 21:34Но даже для реализации банального отношения one-to-many в ORM нужно прописывать не типизированные метаданные, просто вывести SQL запрос из класса ORM не может.
Да ладно? Entity Framework Code First:
public class Foo { public long Id { get; set; } [Required] public Bar Bar { get; set; } } public class Bar { public long Id { get; set; } public ICollection<Foo> Foos { get; set; } }
Все, one-to-many автоматически вывелось из этих классов! Если совсем минимизировать пример то можно даже из двух навигационных свойств оставить только одно.
Сложности возникают только когда есть несколько параллельных связей. Но даже там при желании можно сделать все типизировано.
TimsTims
16.05.2018 14:13И как только вам понадобиться что-то более сложное, чем просто записать или вытащить данные по элементарному условию через предлагаемый OpenAPI
+1. Потом появляется задача вроде «если на картинке имеется кошка, то...» и тут вдруг оказывается, что на движке БД этого не сделать, и всё-равно нужен бэкенд.
По теме «вся логика — на плечах бд»: кажется пару лет назад проскакивала тема, что это плохая тема, что БД со временем начинает загибаться от кучи триггеров, дебажить это становится очень сложно, и всё плохо с парралелизмом. Это еще актуально?kaljan
16.05.2018 21:22судя по всему это снова актуально, 4 года прошло, выросло новое поколение, и снова по тем же граблям
nikolay_samokhvalov
17.05.2018 03:36Это было актуально ещё когда многие здесь комментирующие ходили в начальную школу. Посмотрите, как реализована логика в любой АБС-ке. Код на PL/SQL не считается злом, почему он должен считататься злом на PL/pgSQL?
Крупные, очень крупные проекты не боятся хранимок. Их боится в основном те, кто в целом СУБД боится.
nikolay_samokhvalov
17.05.2018 03:34Ошибаетесь.
madlib.apache.org
Загибаться БД может по массе причин. В основном это монструозные бездумные запросы от ORM-ок. Хватит уже валить на хранимки и хватит их бояться.Ztare
17.05.2018 15:01Думаю что многим не нравится идея хранимок в абсолютно непревзойденной убогости языка на котором они пишутся. И это плюс один-два языка (sql и tsql) в оперативный контекст работы программиста. Если была бы возможность в том же Sql Server писать сразу приложения на C# в виде набора хранимок\классов, то возможно и обсуждать было бы нечего. (про сборки знаю, но это лютый костыль)
savarez
16.05.2018 20:02У нас аналогичный подход, правда не postgrest, а самописная проксирующая тулза. Новые методы для rest создаются написанием psql функций определённого формата.
Скорость разработки просто потрясающая.
Но, пройдя многолетний путь, мы упёрлись в производительность постгреса. Использовали все механизмы распараллеливания, но всё равно. Такой сервис довольно легко завалить умеючи.
В итоге концепцию пока сохранили, но используем программные обёртки в нашем postgrest для хитрого выборочного кэширования.
В целом концепция интересная, живая, но не без нюансов на высоконагруженных сервисах.nikolay_samokhvalov
17.05.2018 03:40«Скорость разработки просто потрясающая» — именно!
На моих глазах целая команда рубистов заменялась одним человеком, готовым писать SQL и коллекции тестов в postman/newman.
Что именно с производительностю? PostgREST ведь stateless, запускайте его на N машинах, часть из которых направляйте на read-only реплики.
Как я понимаю, проблема была в Постгресе самом? Что именно тормозило-то?TimsTims
17.05.2018 17:42запускайте его на N машинах
Есть предположение, что 1 хорошо написанный backend может заменить N машин с обычным PostgRest. Самое первое что лезет на ум — кеширование запросов.
Плюс бесконечно добавлять N машин не получится, рано или поздно, расходы на постоянную синхронизацию огромного количества данных будут класть реплики, и нужно будет уже думать над горизонтальном масштабировании (данные пользователей от 1 до 100 лежат на серверах №1, данные пользователей 101-200 на серверах №2), и уже это будет очень сложно и трудоёмко реализовывать силами лишь PostgRest.mayorovp
17.05.2018 19:39Поправка: «добавлять N машин» — это и есть горизонтальное масштабирование. А то что вы так назвали правильно называется «шардинг».
kaljan
16.05.2018 21:16-2Итак, вы решили писать толстый клиент
Ниже будет сумбурный поток сознания почему этого не стоит делать
1. Хотя бы по деньгам
Вы берете одного фронта, и даете ему эту дичь
Нанимаете админа, который будет разбираться с базой
Нанимаете DBA, который будет вам перепиливать хранимки
А могли нанять одного толкового фуллстека
1.1. Так же не забывайте, что фронтов сейчас много, и скорее всего вы наймете кодера, т.к. нормальные программисты к вам, скорее всего, не пойдут
2. Не стоит забывать и то, что когда вы переносите свою логику в толстого клиента — вам надо будет таки конкретно заморочиться с версионированием базы, т.к. толстые клиенты для разных ОС обновляются не все сразу, а как пойдет, и на последнем обновлении вам, например, надо будет откатиться, вот это будет веселье)
3. логика на уровне бд плохо тестируется unit-тестами
3.1. Да и вообще, о какой логике на уровне БД идет речь, у нас же толстый клиент, а это значит что логика на клиенте!
4. Пример подобных технологий в свое время изобрела MS — OData, но фронтэнд «переизобрел» эту технологию, обозвав GraphQL. На GraphQL не смотрел, но OData осуждаю, слишком много геморроя нам принесла
5.Кстати, PostgreSQL — это не обязательно чисто реляционная СУБД, вы можете и JSON там хранить, некоторые так и делают даже в платежных системах, такой своеобразный NoSQL.
Да, а еще то же можно сделать в MySql, MS SQL, Oracle
Так же еще можно туда XML кидать и по XPath вычитывать
А еще MS SQL поддерживает теперь NoSQL — столбцы, чтобы можно было работать с JSON-объектом в поле как с документом, так что тут Postgre отстает
6. Три пункта с безопасностью — бестолковщина
1. Анонимные запросы — пришлось пилить свою авторизацию. И тут появился бэкенд.
Теперь прикрутите к этому решению. Упс, у нас уже кажется начинает вырисовываться полноценная приложуха)
2. Права на столбцы — пришлось пилить вьюшки — логика в бд — несоблюдение концепции тонкого клиента
3. Запрет доступа к чужим строкам — мажемся user_id, это значит что каждая вьюшка будет тащить его за собой
7. Производительность
Тут нам приводится пример диких JOIN-ов (хотя можно воспользоваться денормализацией БД) и как их героически победили с помощью диких запросов
Очень поддерживаемо, BUS-фактор прям рад
8. Масштабируемость
Тут мы почему-то сравниваем монгу и postgre
Эм
Без комментариев
9. Что не стоит делать внутри?
Тут нам советуют не писать бизнес-логику внутри
Итог
Если у вас нет никаких критичных данных, и вы-таки пилите приложение без авторизации, оплаты, у вас ничего нельзя украсть, пароль от бд не спарсить из JS-кода, и просто делаете свой сборщик данных — почему нет, но таких приложений — два-три на страну, ну и дипломных работ можно невозбранно нагенерить
mayorovp
16.05.2018 21:421.1 Не понимаю почему «фронтов сейчас много» вдруг оказалось недостатком. Обычно это считается основным преимуществом…
2. Какое нафиг обновление толстого клиента и разные ОС? Ау, речь идет о веб-приложении! Главное достоинство веб-приложений — всегда актуальная версия клиента. Это работает независимо от того толстый там клиент или тонкий.
3. Вот именно, на уровне БД не должно быть никакой логики кроме контроля доступа. Тестировать отсутствующую логику очень просто, даже если это БД.kaljan
17.05.2018 00:00Мое имхо —
- поддерживвть толстого клиента сложнее, чем толстый бэкенд,
- конфиденциальные данные мы на толстый клиент передавать не можем — (пароли ведь неспроста хеширтся)
- поддерживать это все в итоге выйдет по совокупности гораздо дороже, чем обычный бэкенд
- все еще не решена проюлема с масштабированием и производительностью
kaljan
17.05.2018 00:102.
В статье как раз и предлагается решение для множества клиентов — идет выбор между нормальным API, развернуть в облаке которое автор не осилил, и OData, которое назвали PostgRest, которым сейчас уже никто не пользуется (хмм, с чего бы)
3. Тесты на банальный функционал не пишутся
nikolay_samokhvalov
17.05.2018 03:41(прочитал только первую строчку, на неё и реагирую)
это не я решил, а весь мир решил и уже давно. Похоже, я недостаточно ясно эту мысль донёс.
SirEdvin
А сервер posgres обслуживают единороги?
hazratgs
Stanislavvv
Про хуже по производительности не скажу, а пару лет назад ставили кластер из 3-х из-за того, что терялись новые записи.