
Антон любит инфраструктурные задачи и автоматизацию всего, что можно автоматизировать, поэтому его рассказ основан на примере настройки инфраструктуры в дата-центре и сопутствующих технологиях (Docker, Consul, Puppet...). Но аспекты, мешающие качественной работе и способы их решения максимально универсальны и подходят практически для любой исполнительной команды. Так что милости просим под кат за расшифровкой этого доклада.

Badoo с каждым годом растет, вот несколько чисел, которые это отражают: 350 млн сообщений в сутки, 364 млн зарегистрированных пользователей по всему миру, 300 тысяч новых пользователей в день. Но это далеко не самое главное, для человека, который в Badoo работает, главное — это в первую очередь образ мышления и команда. Badoo — это семья, это про людей и это круто!
Хочу начать с провокации, которую, возможно, кто-то не поддержит:
Админ — это главный человек в компании!
Думаю, вы со мной согласитесь: админ — это тот человек, без которого ничего в компании не заработает: оборудование приезжает к нему, систему ставит он, выделяет новое оборудование опять же он. Поэтому я и считаю, что он — главный.
Приведу пример из личной практики в Badoo. Судите об этой ситуации сами: был у нас новый проект, который назывался ReThink. Мы обновили наш логотип: изменили шрифт и цвет букв с разноцветного на фиолетовые, добавили сердечко — однообразно и круто. Но админов предупредить о том, что случится ReThink — мы просто возьмем и переключим — предупредили в последний вечер практически перед уходом домой. И тут бахнула несколько непрогнозируемая нагрузка в одном из кластеров. Спасибо человеку, который дежурил и помог остальной части команды просто найти дополнительные серверы и их докинуть. Проект на самом деле выстрелил, мы не упали, нормально выкатились и все были счастливы.
В подтверждение своих слов хочу сказать, что счастливый и продуктивный админ в компании — это, в том числе, выгодно и интересно компании. Я бы хотел попросить все компании делать своих админов счастливыми. Тогда и у вас все будет хорошо!

Давайте задумаемся о том, что заставляет админа печалится. Многим в голову придет, что админ грустит от упавшего сервера и потерянных бэкапов. Это все так, но, если бы админ каждый раз задумывался бы и уходил в печаль, когда он сделал что-то не так — а он каждый день делает что-то не так — нервов бы не хватило.
Поэтому я обозначаю проблему, которая заключается в некоем человеческом факторе, а именно в переключении контекста.
Переключение контекста
Есть достаточное большое количество исследований о том, что происходит, когда человека отрывают, и почему это плохо. Одно из последних хороших исследований — работа Криса Парнина, сотрудника технологического университета Джорджии. Он собрал кучу различных данных на эту тему и сделал достаточно много выводов, главный из которых звучит так:
Человеку, которого оторвали от работы над задачей, требуется 10–15 минут, чтобы вернуться к ней.
Это среднестатистическая цифра. У кого-то она может быть больше, у кого-то — меньше, в зависимости от переключений. Простым сложением можно посчитать, что если вас 4-5 раз в течение одного часа на что-то отвлекли, целый час рабочего времени, скорее всего, будет потерян, и свою задачу вы вряд ли сделаете.
Это теория — человек исследовал, пришел к выводам. На практике вы, вероятно, сталкивались с такой ситуацией: приходишь на работу, провел весь рабочий день в запаре — весь день что-то делал, пообедать не успел, на мессенджеры и почту не ответил. К концу рабочего дня ты весь замученный, тебе кажется, что ты сделал очень много всего. Но в лучшем случае, к вечеру ты понимаешь, что не сделал и половины того, что планировал на рабочий день. Хуже, когда к тебе подходит менеджер или коллега и спрашивает: «А что ты сегодня вообще сделал?» и ты понимаешь, что бегал, бегал, бегал — а на выходе нет ничего.
Во многом это происходит от переключения нашего контекста и невозможности сконцентрироваться на задаче. Для админа — простого исполнителя — это так.
Но есть еще менеджеры/тимлиды и обратная сторона. Фишка тимлидов заключается в том, что они, как маньяки, этот context-switching не то, что умеют переживать, но даже себе его иногда увеличивают, чтобы потом сократить. То есть они сосредотачивают много встреч с этим переключением в несколько часов, а потом отдыхают вечером, работая над одной задачей. Навык переключения бывает развит до того, что уходит всего 5 минут на погружение в новую задачу. Это очень круто, и за одно то, что они умеют это делать, менеджеров можно ценить и уважать. Но для админа и исполнителя лучше от переключений избавляться.
Непрозрачность процессов
Второй важной проблемой является непрозрачность процессов, которую можно разделить на две зоны:
- непрозрачность процессов внутри команды;
- непрозрачность процессов вне команды.
Внутри команды — это то, на что мы можем повлиять: недоговорки или отсутствие согласования между участниками команды. Самое плохое, к чему вас может привести непрозрачность процессов внутри команды — это дублирование работы. В принципе, это неплохо, не считая того, что вы теряете, скорее всего, рабочее время одного из сотрудников.
Здесь можно найти плюсы и сказать: «Возможно, Вася сделал лучше, чем Петя! Давайте возьмем его решение». Но они могли бы поговорить между собой, а делал бы кто-нибудь один. Это важно.
Если непрозрачные процессы находятся за пределами команды, например, в целом что-то непонятно происходит в компании, внутри команды это может привести к неправильной приоритизации по задачам.

Например, пришел ко мне разработчик из мобильного веба и сказал, что ему важно поднять некий сервис, который будет что-то отдавать для нового API, сегодня. У меня много других задач, и мне вообще не кажется, что его задача приоритетная. Он ждал свой релиз неделю, подождет еще два дня, сделаю потом. Для бизнеса это не всегда так. Если к нам сверху придет команда о том, что у текущей задачи высокий приоритет, потому что она является частью очень большой следующей задачи, то важно, чтобы это даже не менеджер доносил, но чтобы каждый член команды это понимал просто без лишних слов.
На решении этих двух основных проблем внутри команды именно с точки зрения исполнителя и админа я бы хотел построить свое повествование сегодня. Я расскажу о том, как мы нашли несколько правил для того, чтобы максимально минимизировать переключение контекста и сделать процессы максимально прозрачными.
Как решить проблему переключения контекста
Пришел админ на работу, выпил чашку кофе, прочитал почту, бэкапы работают, ничего не упало — сиди, работай, что может помешать.
Рассмотрим обычную ситуацию. Человек пришел свежий, все хорошо, он открыл свои рабочие инструменты, написал в чат и в почту, и тут телефон зазвонил — спрашивают, что ночью упало — отвлекся. Дальше жена или девушка выложила клевую фотку — надо зайти полайкать, в Facebook тоже происходит движуха. Тут приходят друзья обсудить вчерашнюю футбольную встречу, зовут вечером попить пива или сейчас чаю. И все это к человеку приходит со всех сторон понемножку.

Что делать с данной проблемой? У нас есть человек, есть его общая социальная жизнь, есть ее рабочий аспект. В данном случае мы можем рассматривать и оптимизировать только ту часть, которая касается его рабочих инструментов. Мы не можем ему запретить ходить пить пиво после работы или пользоваться социалочками, потому что мы же не в тюрьме в конце концов.
Поэтому мы решили посмотреть на то, какие рабочие инструменты есть у админа, откуда его часто дергают, и что мы можем сделать с тем, чтобы это уменьшить.
Первая идея достаточно странная, но мы ее пробовали — это разрешить админу просто не пользоваться чатом, потому что в чат пишут много. Работаешь над задачей, а тебе один написал, что ему важно это, другой — что ему важно то. И мы разрешили админам не использовать чат — не отвечать и ничего не писать там.
Идея, ясное дело, не взлетела, потому что помимо того, что в чате тебе пишут то, что надо читать, чат — это самый быстрый способ коммуникации. Тебе просто необходимо туда писать. Буквально через неделю стало понятно, что идея утопична, мы решили от нее отказаться и пошли дальше.

Мы приняли отчасти странное решение — выделили одного члена команды и сказали ему: «Чувак, ты будешь условным лидером! Это — не повышение по карьерной лестнице, просто ты довольно много знаешь о том, кто из твоих коллег в какой области хорош, ты знаешь общий поток задач и более-менее про приоритеты. Поэтому, давай, ты будешь работать по следующему сценарию. Есть пул задач, которые сваливаются на всех админов в команде, ты видишь, кто чем занят, знаешь, какие сроки по задаче, и всегда можешь отдать ее человеку, который максимально быстро справится с ней; либо, если времени на выполнение много, можно поручить ее джуниору. Джуниору необходимо рассказать базовые вещи, но ты знаешь, что, если ему помогут, он прокачается и все будет круто». В принципе, идея вполне здравая.
Одна из причин, почему она до конца не зашла, заключается в том, что у нас все админы любят работать над тем, что им нравится. Мы можем делать таски, когда все горит и надо делать — мы не разбираемся, берем и делаем, неважно, кто. Другое дело, когда у тебя есть выбор: «Я сейчас работаю над одной задачей и хочу настроить репликацию в MySQL, Puppet трогать не хочу — пусть кто-нибудь другой его делает».
Люди начали бугуртить, кому-то мало задач, кому-то много, кому-то достаются неинтересные — что-то такое непонятное и необъяснимое. Возможно, это был наш просчет, но этот подход не сработал.
Приблизительно в тот же момент времени мы пытаемся догрузить Арбитра еще одной обязанностью. Команде админов другие команды ставят задачи сделать что-то — забэкапить, восстановить и т.д. Человек с такой заявкой — это, по сути, клиент, и он всегда ждет фидбэка. Когда, поставив задачу, он видит, что задача перешла в общем пуле со статуса «не назначено» на «назначено» на конкретного исполнителя, прошло 2-3 часа, один рабочий день, другой, а у задачи нет отбивок, не понятно, вообще занимаются его задачей или нет.
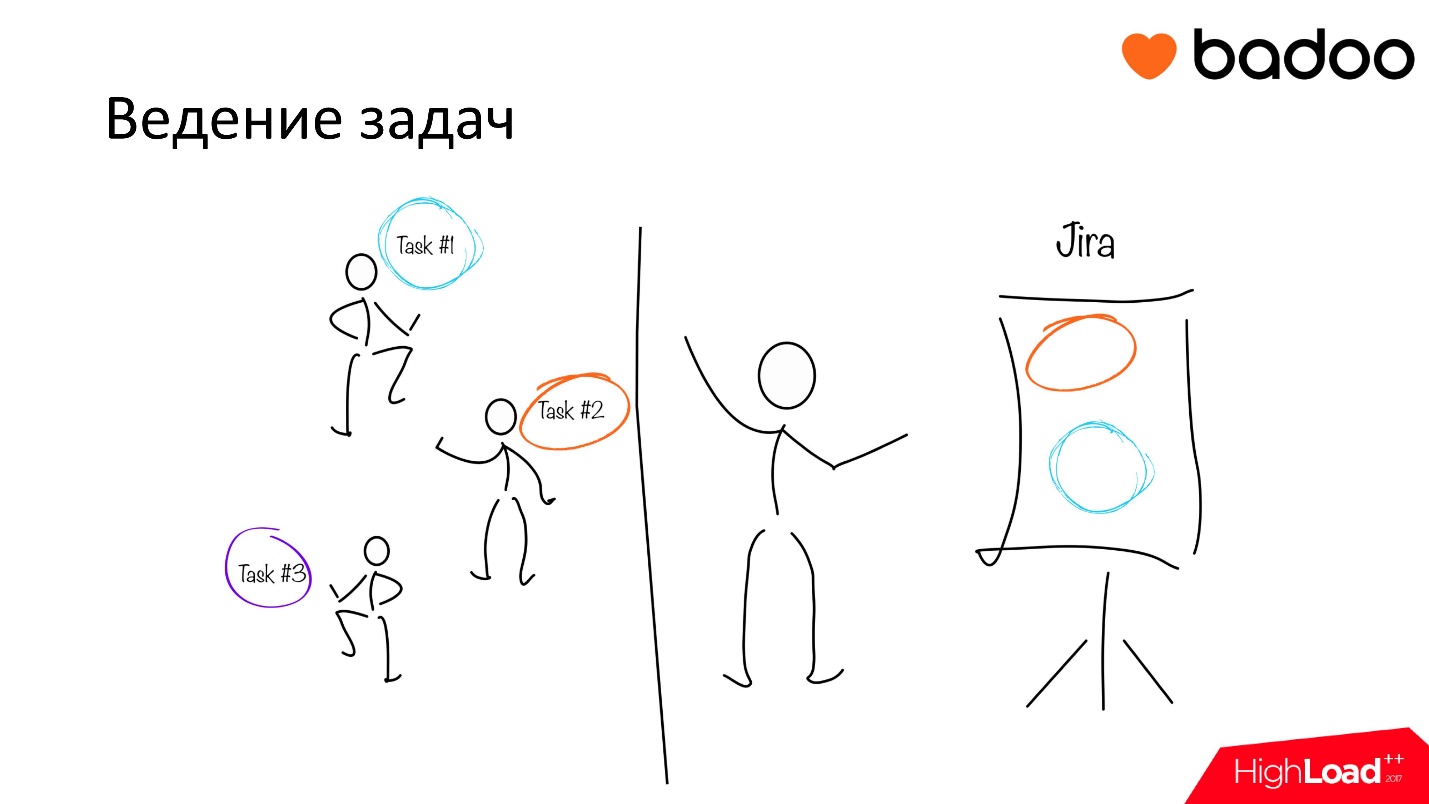
Есть админы, которые не очень любят вести свои задачи именно в виде переписки. Поэтому Арбитру теперь стало нужно устраивать one-to-one митинги с каждым членом своей команды, вести практически каждую задачу, спрашивать, есть ли по задаче трудности, чем можно помочь, и резюмировать собранную информацию раз в 1-2 дня.
Задачи начали как-то вестись. Но все застопорилась, потому что наш текущий Арбитр просто зарылся в таком количестве знаний. Ведь для того, чтобы тебе что-то резюмировать, тебе нужно разобраться в каждой предметной области, додуматься, до какого этапа дошел сотрудник, что ему мешает, и это написать. Когда таких задач становится много, Арбитр просто бросает что-то писать, и задачи точно так же перестают вестись. Поэтому нужно было двигаться дальше и снова что-то менять.
Матрица Эйзенхауэра
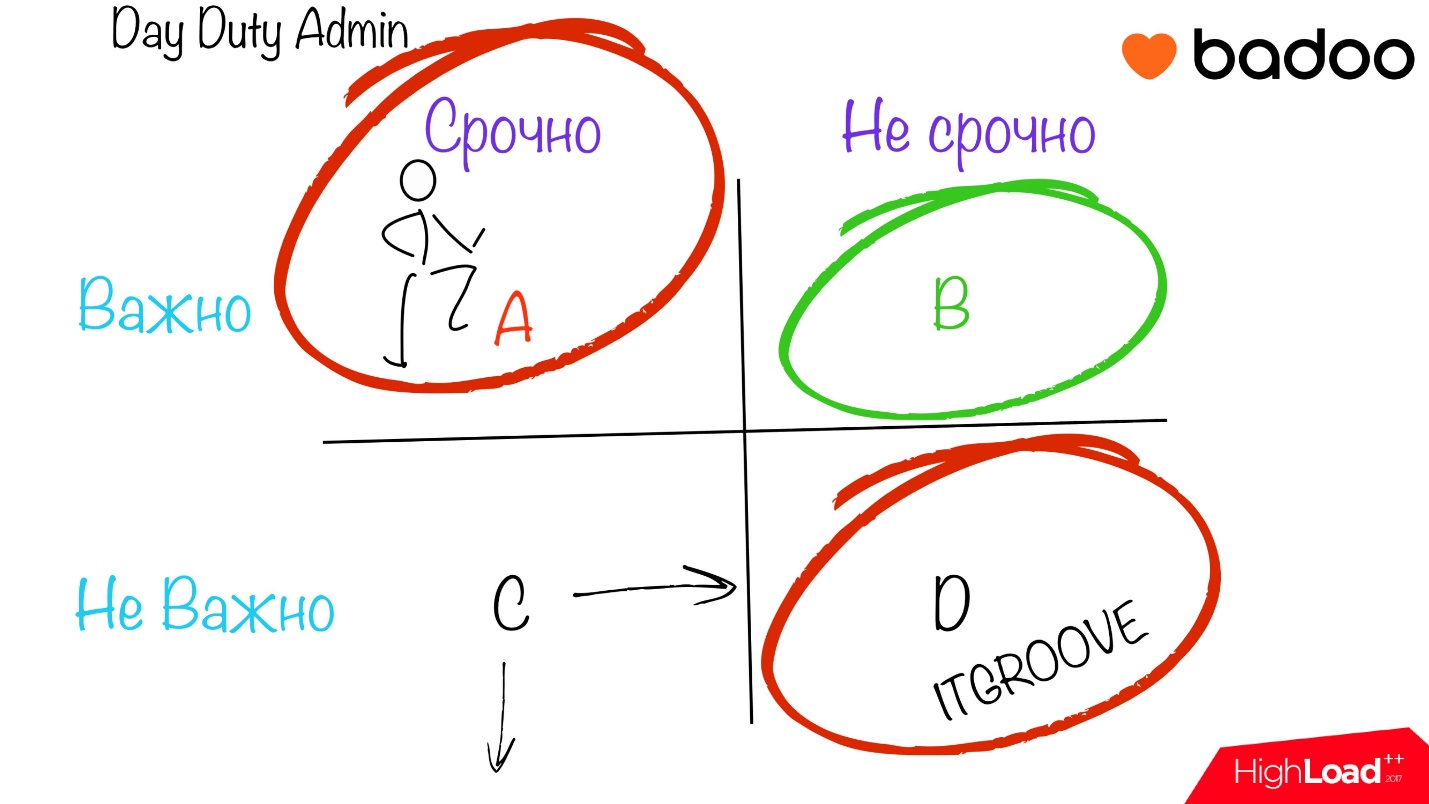
Возможно, вы уже видели эту матрицу, просто не знаете названия. Суть заключается в том, что мы делим лист с задачами на 4 части по двум параметрам:
- срочно / не срочно;
- важно / не важно.
Все наши задачи мы просто раскидываем в эту замечательную табличку, и начинаем работать.
Стоит сразу заметить, что самая производительная и комфортная для исполнителя клеточка B — задача важная и не срочная. Это отличный мотиватор для человека, когда твоя задача важна либо для команды, либо для проекта, либо просто для тебя. Ты понимаешь, что работаешь не просто над какой-то ерундой, а над тем, чем люди будут пользоваться, и это добавляет стимула. Плюс несрочности заключается в том, что ты предоставлен сам себе. У тебя есть время почитать, протестировать, произвести какие-то расчеты.
Мы посидели, подумали и придумали разделить все задачи, поступающие в отдел эксплуатации, а задачи формата не очень важные и не очень срочные выделить в отдельный проект, который мы назвали ITGROOVE. Сюда мы относили задачи, которые в перспективе, может быть, когда-нибудь действительно перерастут в проблему, но сейчас проблемой не являются, и сделать их было бы неплохо в каком-то обозримом будущем — неделя, две.
После этого мы ввели функцию дневного дежурного админа, суть которого заключается в следующем. У нас есть первая линия поддержки и реакции на срабатывания аварий и триггеры, мониторинг. Если она не может справиться с проблемой и принимает решение о том, что нужно эскалировать, то первый человек, который вовлекается в решение этой задачи в дневное время — это дневной дежурный админ.
Если до этого я рассказывал, что мы избавляемся от влияния переключения контекста, то здесь мы человека просто кидаем на амбразуру и говорим заниматься вообще всем подряд, переключаться, как только можешь.
На самом деле, это не совсем так, потому что дневной дежурный админ выполняет следующие действия: либо производит эскалацию проблемы и передает ее лучшему специалисту отдела в данной предметной области, который доступен в данный момент, либо сам практически машинально занимается исправлением проблемы. Это не умственная деятельность — человека ночью разбуди, он пойдет и починит.
Как дополнительный бонус, мы предложили дневному дежурному, если ему делать нечего и скучно, заниматься проектом ITGROOVE. Мало того, что человек прикрывает всю остальную команду, он еще и закрывает неважные и несрочные задачи!
Введя роль дневного дежурного и разделив задачи на совсем неважные и проектные, мы позволили всей остальной команде работать в самой комфортной зоне B над несрочными, но при этом важными задачами. Люди просто вынырнули из пункта A, посмотрели по сторонам, а там есть пункт B — и мне комфортно, и всем хорошо — круто! Будем работать!
Не оставлю без внимания задачи из пункта С. Звучит как-то бредово: «Срочно, но не важно» — либо срочно, либо не важно. В нашем случае обычно работы в этом сегменте не происходит. Задачи с критериями «не важно, но срочно» либо становятся «не важно и не срочно», либо просто исчезают, и мы над ними не работаем.
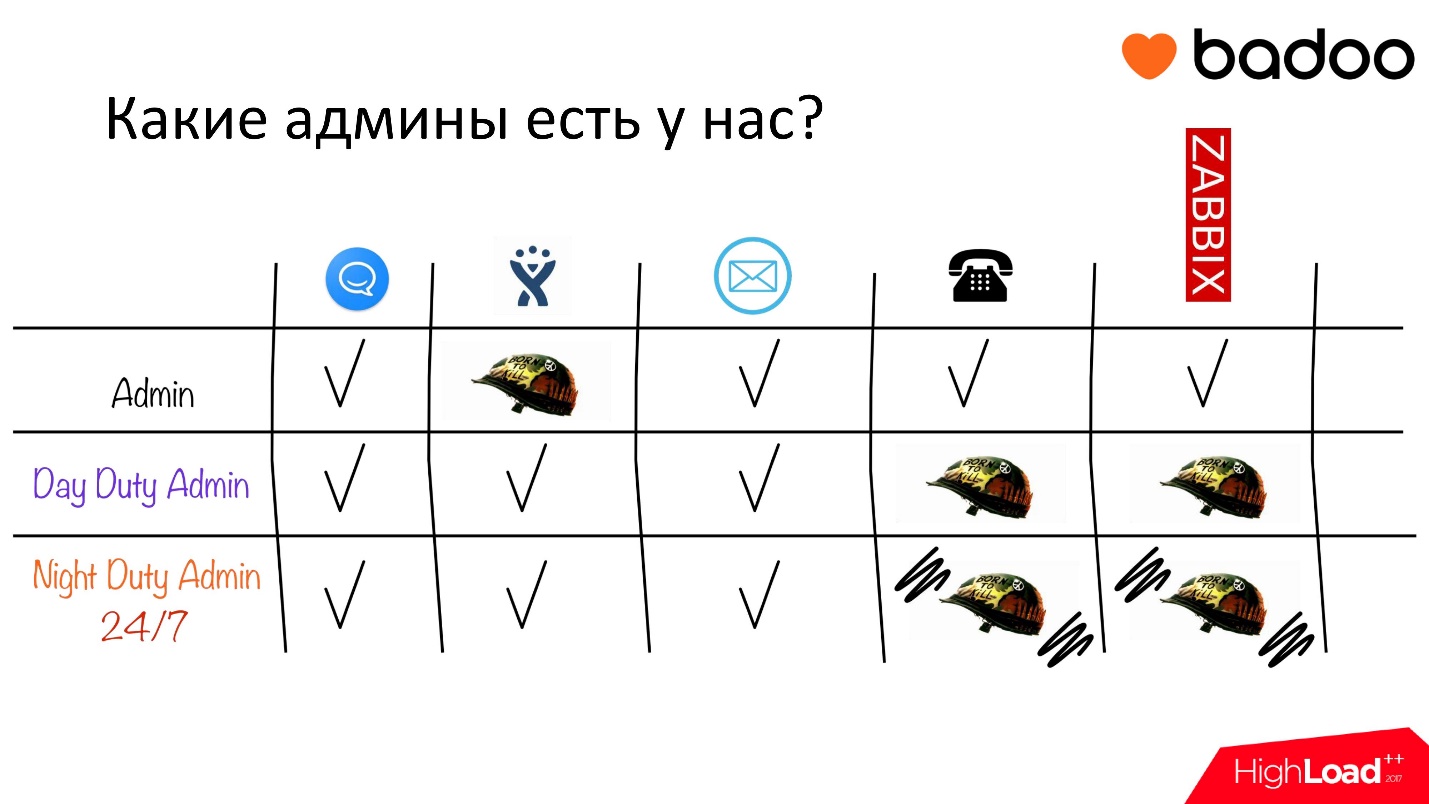
Так как я коснулся того, что мы ввели роль дневного дежурного админа, давайте кратко пройдемся по тому, какие вообще админы у нас есть:
- Админ обыкновенный. В принципе, все занимаются всем всегда, но админ обыкновенный преимущественно работает над тасками в Jira.
- Дневной дежурный админ преимущественно отвечает на телефон и на эскалации от мониторинга.
- Ночной дежурный админ — некая смесь админа обыкновенного и дневного — ночью отвечает на звонки и эскалации, а днем работает как админ обыкновенный.
Как сделать процессы прозрачными
Сложность нашей конкретной команды заключается в том, что одна ее часть находится в Лондоне, другая в Москве, это достаточно большой сдвиг по часовым поясам. В Москве ребята начинают работать сильно раньше, в Лондоне только приходят на работу, а они уже что-то сделали. В свою очередь мы в Лондонском офисе, дорабатывая вечером, делаем еще какие-то вещи, о которых люди в Москве, уходя домой, не знали. Для координации процессов внутри команды у нас есть еженедельный понедельничный митинг.
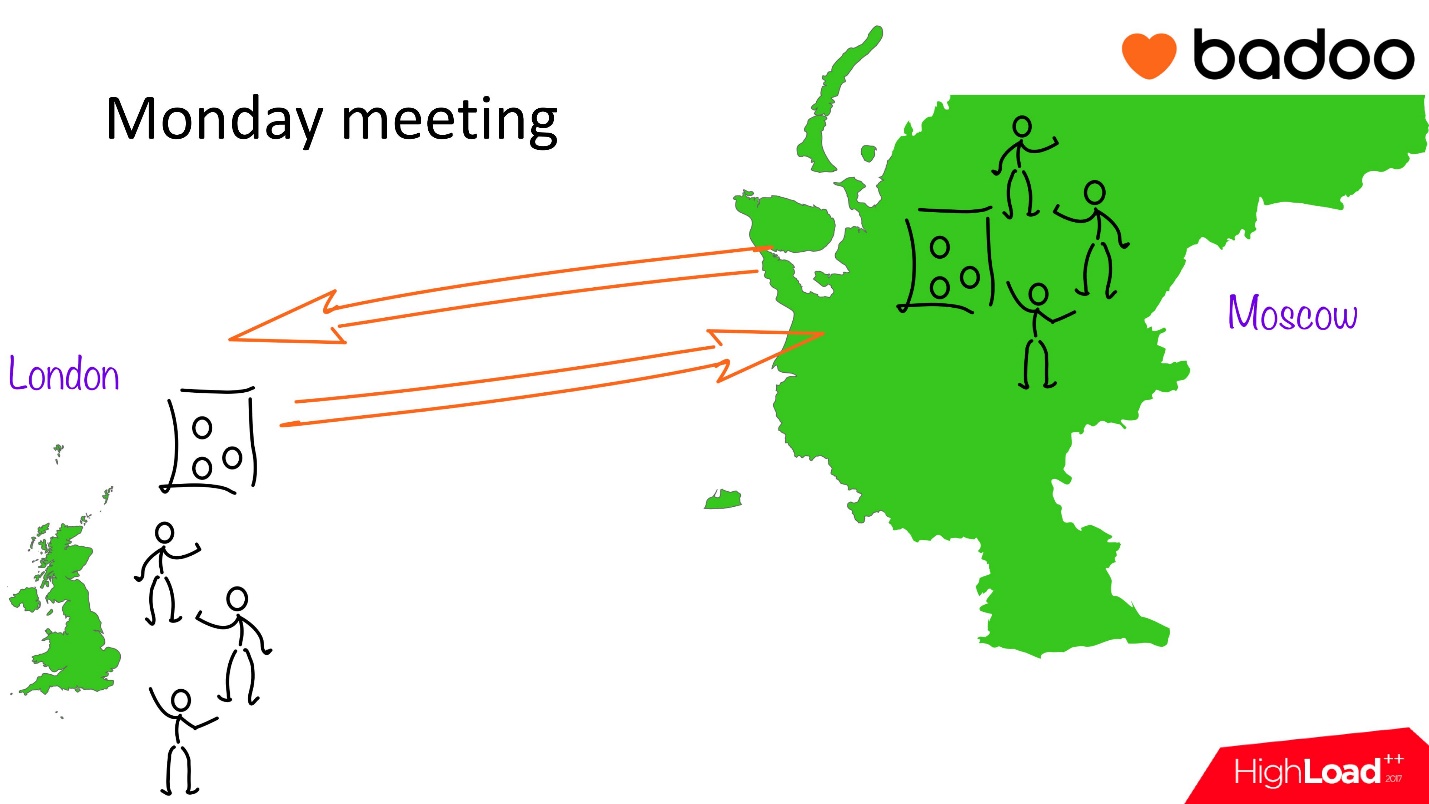
Это выглядит так:
- Мы занимаем одну переговорку в Москве, одну в Лондоне.
- Причем время установлено так, что в Лондоне только пришли на работу, а в Москве уже вернулись с обеда. Чтобы настроиться на рабочий всем надо порядка 40 мин. Поэтому мы в неформальной обстановке собираемся по телевизору, берем агенду и начинаем обсуждать.
- Это обсуждение «многие ко многим». Мы рассказываем друг другу, какие важные проекты мы сделали, что ожидаем, что планируем делать, назначаем встречи друг другу.
Но проблема заключается в том, что где-то уже к вечеру вторника или к утру среды координация действий немножко теряется. Например, я начал работать над задачей, ушел в сторону, задачи на эту неделю у меня уже другие, у коллеги из Москвы происходит что-то аналогичное. Мы рассинхронизируемся до следующего понедельника, до следующей агенды — с этим надо что-то делать.
Status Hero
Существует клевый инструмент, который называется Status Hero. Его суть в том, что, приходя на работу, ты планируешь сам для себя определенные задачи. В Status Hero есть 3 поля для заполнения. Причем это не обязательный инструмент, мы можем его не заполнять и им не пользоваться.
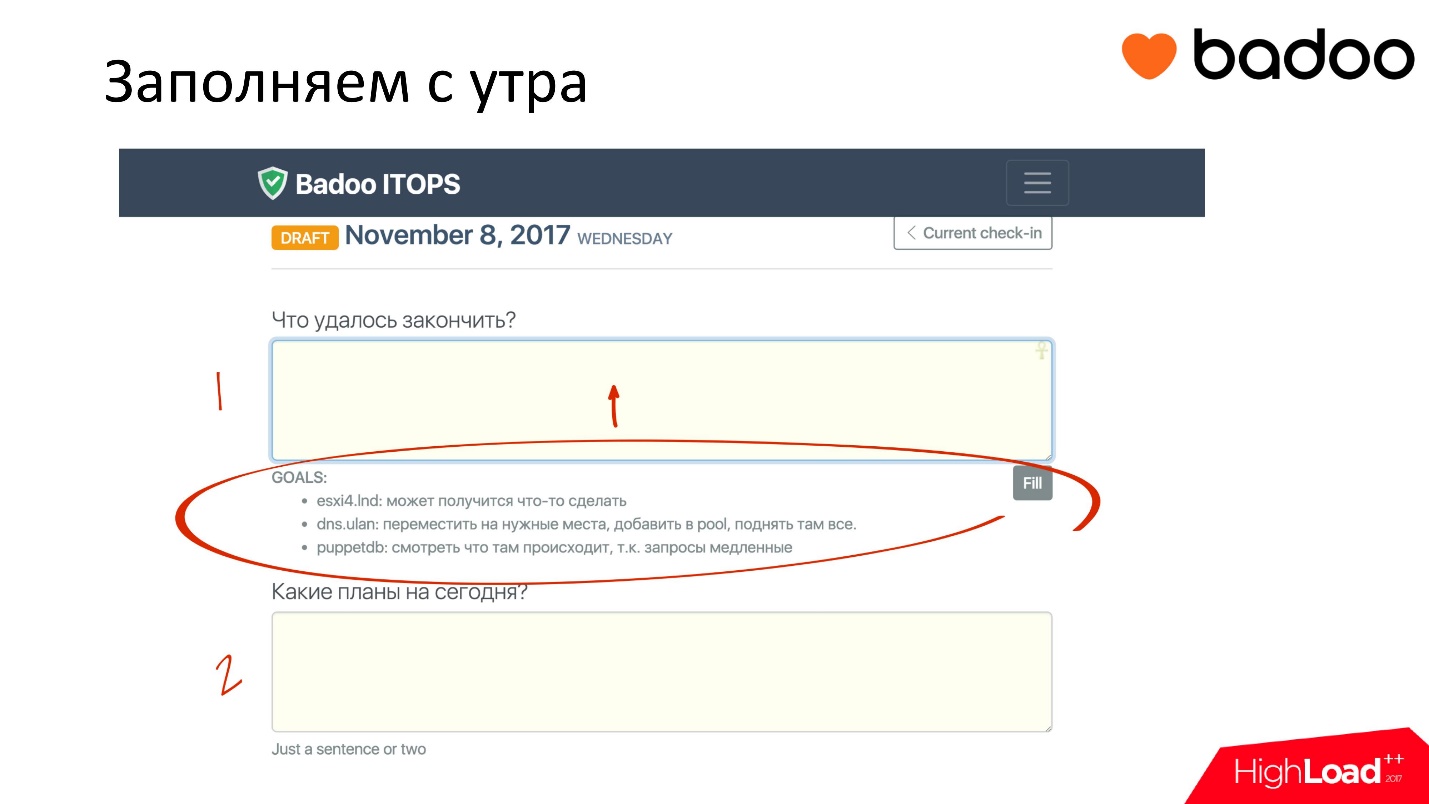
Фишка заключается в следующем: я пришел на работу свежий, и знаю, что сегодня хочу починить какие-нибудь DNS, настроить сброс метрик в Prometheus, посмотреть, как будут работать новые графики, и возможно, закрыть текущие задачи. Я вписываю все это в план на сегодня.
Но над планом на сегодня у меня мерцает строчка, которая говорит о том, что вчера ты себе обещал сделать вот это, и давай, ты сначала напишешь, что ты сделал за вчера из того, что обещал, а потом уже то, что будешь делать сегодня.
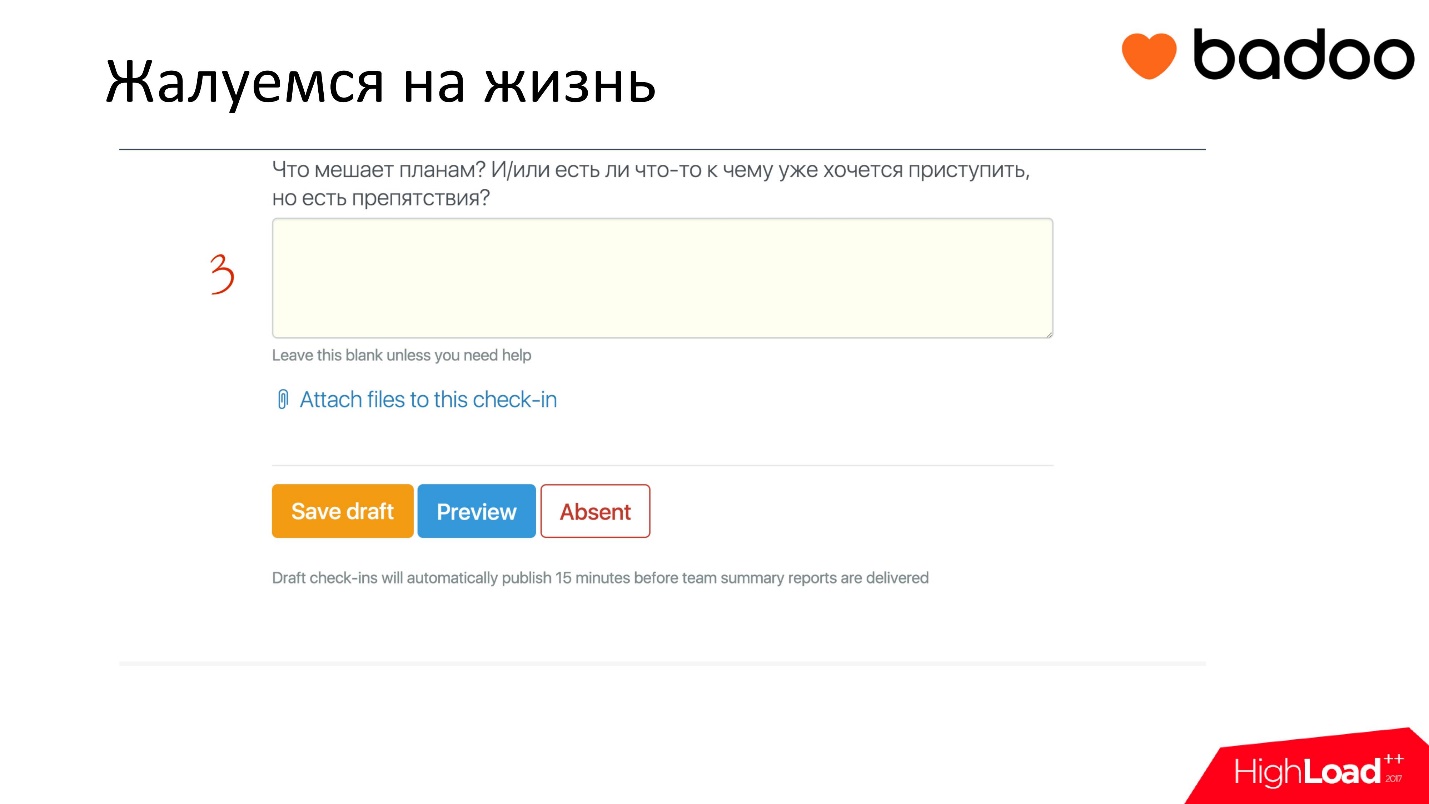
Также там есть замечательный третий пункт. Это поле для того, чтобы обозначить некие внешние события, которые блокируют выполнение задач. Например, кто-то из другой команды не предоставил тебе не важно, что — патч, фикс, необходимые данные для выполнения работы, а ты — парень стеснительный и не можешь ему позвонить и потребовать. Сейчас ты можешь написать что-то такое сюда, это подсветится красным, и тебе поможет либо менеджер, либо ребята из команды. То есть ты озвучишь свою проблему, и не будешь сидеть молча и ждать, когда же независящая от тебя проблема решится и ты сможешь заняться своей задачей.

В свою очередь команда это тоже видит. У нас есть специальная группа в HipChat, где после того, как кто-то заполнил форму, это показывается всей команде. Человеку беглого взгляда достаточно, чтобы просмотреть чат и понять, что будут делать его коллеги. Если вдруг есть какой-то блокер, который он может разрешить и помочь тем самым своему коллеге, то он это делает. Это круто!
Почему Status Hero работает?
- Самый важный аспект заключается в том, что ты обещаешь себе. Из практике могу сказать, если ты обещаешь себе с понедельника до пятницы, то, скорее всего, к четвергу ты сделаешь хотя бы один из пунктов, который написал в понедельник. Status Hero каждый день тебе будет мозолить глаза и говорить: «Обещал — не сделал!» А еще и коллеги знают, которым ты фактически тоже пообещал, поэтому берешь и делаешь, просто через силу.

- Следующий положительный момент заключается в том, что полученная прозрачность дает возможность помогать друг другу. Когда я вижу, что, например, мой коллега собрался выполнить определенную задачу, в которой мои знания, возможно, больше, или я могу просто чем-то помочь, я говорю: «Давай, я тебе помогу. Я знаю, куда отправить документацию и что почитать, или сделай здесь сразу так, чтобы не потерять пару дней работы. Это будет лучше для тебя».

- Теперь те тихони, которые сидели и не говорили о том, что им что-то мешает работать, могут также тихо написать, и им помогут. Возможно, решится какая-то проблема, с которой иначе было не справиться.
Status Hero вскрыл проблему
Но мало того, что Status Hero помог нам в организации этой деятельности, он еще вскрыл для нас одну достаточно странную проблему. Она заключалась в том, что на тот момент эксплуатационной документации либо не было вообще, либо ее было недостаточно.
Понять это удалось приблизительно тогда, когда ты стал видеть, над чем работают коллеги, помогать им и рассказывать, как что-то сделать. Когда ты шестой раз объясняешь одно и то же, то понимаешь, что, если бы ты один раз это написал, коллега один раз прошелся бы по сценарию, внес бы правки и комментарии, и все — не нужно было бы отвлекаться на объяснения эти шесть раз. Человеку в свою очередь не нужно было бы спрашивать о банальных вещах, о которых можно прочитать.
Документация была, но в недостаточном количестве, как выяснилось. Как только начали пользоваться Status Hero, статей во внутренней Wiki стало действительно больше, статьи стали править и комментировать, даже лайки ввели в Confluence, а также стали дополнять триггеры в системах мониторинга, которые срабатывают. Мы стали писать более внятно, человеческим языком о том, что же там на самом деле происходит, кому позвонить и куда посмотреть.
И это еще не все. Есть еще один аспект, в котором нам Status Hero тоже помогает.
Team Contribution
Алексей Рыбак выступал на HighLoad++ срассказом про процесс Review в Badoo. Это крутая, преимущественно менеджерская штука, потому что им надо оценивать свои кадры: как мы работаем, как работает команда. С точки зрения менеджера это клевый инструмент, с помощью которого вся информация становится структурированной.
С точки зрения админа — простого сотрудника — все наоборот. Это почти как с подготовкой к экзаменам в сессию. На заполнение Review отводится неделя, за которую надо написать, что ты делал последние полгода. Но обычно это дотягивается до последнего дня, который практически весь тратится на то, чтобы перечитать свои тикеты за долгое время, вникнуть в них и что-то написать о своих достижениях.
Чтобы процесс написания Review не был таким больным, нам предлагается заполнять snippets. Это можно делать как в конце рабочего дня, так и в конце рабочей недели.

Но, так как мы уже говорили о проблеме переключения контекста, то, очевидно, не всегда возможно в пятницу, например, вспомнить, что я делал в понедельник или во вторник. В лучшем случае я напишу, что я делал в четверг и в пятницу, в худшем это будут 3 последних часа работы в пятницу. Что касается daily snippets — рабочий день бывает разным, и вечером хочется пойти домой, в паб, — что угодно, но не заниматься писаниной того, что же я сделал за сегодня.
Здесь снова на помощь приходит Status Hero. Мы писали в нем каждый день, что обещали сделать и что сделали. За срок, который нам нужен, можно просто сделать выборку положительных моментов — того, что мы на самом деле сделали.
Мало того, что эта выборка позитивная, есть еще один плюс: в Status Hero мы писали для себя, и когда мы делаем выборку для написания полугодового отчета, то читая то, что сам для себя написал, ты погружаешься в перспективе в контекст. Тебе не нужно лезть в тикеты и вспоминать, что же ты там делал, долго или не долго.
Это прекрасно и замечательно, но
«Теория без практики мертва, практика без теории — слепа»
А. Суворов
Один день из жизни админа
Чтобы мои утверждения, что Status Hero клевый, не были голословными, давайте посмотрим на один день из жизни админа в Badoo. Ситуация полувыдуманная, но вполне реальная.

Приходит человек на работу с утра, например, после выходных. Он отдохнул и знает, что у него в перспективе большой проект. Первое, что ему нужно сделать, чтобы начать работать, это спланировать рабочий день. Допустим, он решил настроить инфраструктуру в новом дата-центре.
Мы все прекрасно помним про совесть и про то, что если он пообещал в понедельник, то к пятнице, наверное, сделает. Но рассмотрим идеальную ситуацию, что задача закроется в течение одного рабочего дня.
Человек это написал и подумал о том, что для того, чтобы поднять новый дата-центр, ему необходимо настроить инфраструктуру для xCAT.
Тут присоединяются ребята, которые тем временем пришли на работу в Лондоне, и каждый из них добавляет, что еще нужно поставить Puppet поставь — без него не заведешь, Consul тоже нужен, и как же без Docker, а glpi, и так далее. Слишком подробно про каждую из этих систем рассказывать времени не хватит, рассмотрим их вкратце.
Наш дата-центр состоит из пяти элементов паззла, на базе которых мы можем начать работать дальше.

Первый основной инструмент менеджмента — железо, которое только приехало с завода. Его поставили в дата-центр, смонтировали в стойки. Админу нужно обновить прошивки, поставить ОС, собрать Raid, и машину переместить на то место, в котором она потом будет работать.
Мы пользовались и продолжаем пользоваться продуктом под названием xCAT, который в себе содержит PXE сервер и dhcp сервер. Там мы храним базу всех наших подсетей, dns адреса, динамические диапазоны и прочую информацию. Для нас это является базой серверов, но базой в формате сервер — имя — mac адрес — сетевые интерфейсы и постоянный IP непосредственно в том кластере, в котором он будет располагаться, если мы переносим сервер в кластер.
Немаловажно, что xCAT предоставляет возможность следить за тем, что происходит в консолях серверов. Если происходит какой-то Kernel Panic, то мы получаем слепок с монитора просто в текстовом виде и потом можем им воспользоваться. То есть xCAT работает в формате, менеджмент-ноды, которая знает все обо всем, но может снять часть своей нагрузки, передавая ее сервисной ноде, на которой в свою очередь мы и поднимаем сервер консолей. Если дата-центр будет маленький — условно 100 машин, то все поместится на одной менеджмент-ноде, мы не будем поднимать вторую. Если дата-центр большой, серверов с консолями много, мы возьмем и просто горизонтально увеличим количество SN и подцепим их все к мастеру. Поэтому на схеме xCAT SN находятся в квадратных скобках.
На самом деле, человек, которые поднимает ДЦ и настраивает xCAT, запускает один контейнер с менеджмент-нодой, вносит туда информацию о новых подсетях, которые будут в этом ДЦ, генерирует файл с dhcp и сообщает, если это необходимо, сетевым инженерам о том, что для этих подсетей dhcp helper будет находиться на новом контейнере.
В случае, если необходимо поднять сервер консолей на отдельном контейнере, мы запускаем просто следующий и все становится замечательно, по крайней мере, у нас появляется базово настраивать оборудование.
Docker
Я был бы не я, если бы я не сказал здесь слово Docker — шапку пришлось бы снять в конечном итоге. Но рассказывать глубоко про Docker не буду, его инфраструктура для любого нашего дата-центра выглядит приблизительно так.

Суть Docker здесь не в нем самом, а в том, как устроены registry, потому что он нам необходим для того, чтобы стягивать оттуда уже дальнейшие контейнеры наших сервисов и служб. У этой схемы было несколько итераций, пока мы внедряли Docker и им пользовались, но на данный момент рабочая схема registry в Badoo находятся в таком виде, как показано выше. Все образы, все слои и все остальное мы храним в Ceph через Swift API.
Для того, чтобы хранить кэш из нашего registry, мы используем Redis. HTTP ноды, которые являются Docker distribution сервисом, мы можем горизонтально масштабировать сколько угодно, единственное условие заключается в том, что нам всегда необходимо вести все docker-registry ноды к одному адресу кэширующего сервиса Redis и указывать соответственно один endpoint для Ceph.
Перед HTTP сервисом в качестве балансировщика стоит nginx, который терминирует SSL, делает basic Auth. Дальше находятся наши целевые серверы, которые обращаются к registry с тем, чтобы сделать pull или push.
Consul
В современных реалиях в новом дата-центре обязательно понадобится Consul, который на данный момент используется, скорее, не как service discovery для всего Badoo, а как service discovery для инфраструктурной части.
Демонстрировать, как базово выглядит инсталляция Consul в любом из дата-центров, наверное, никакого смысла не имеет. Это обычно, как минимум 3 master-сервера и синхронизация со всеми имеющимися дата-центрами.
Зачем инфраструктуре, тем более нового дата-центра Consul?
Puppet
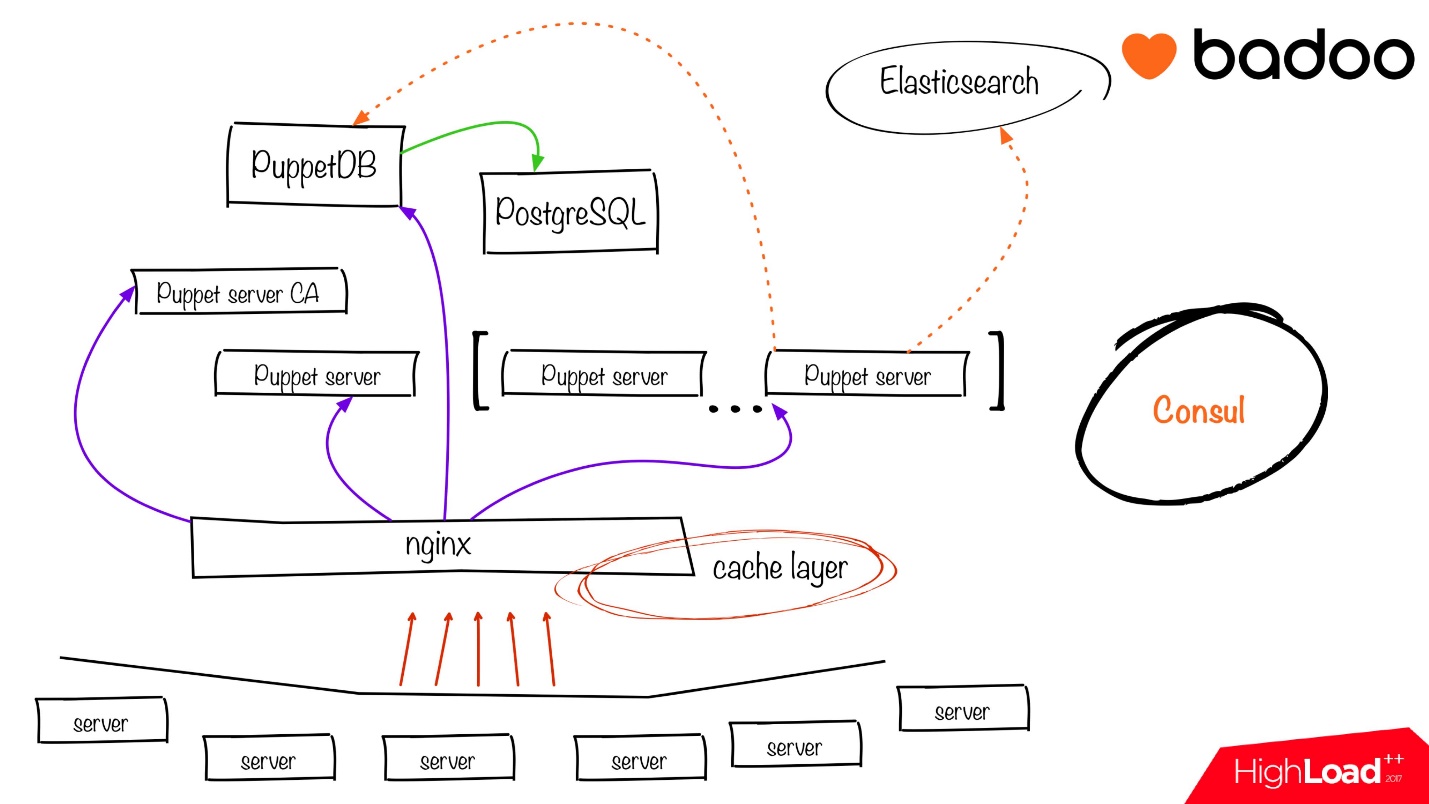
Давайте посмотрим на нашу замечательную инфраструктуру Puppet.
Суть Consul здесь заключается в том, что мы поднимаем инфраструктуру сверху вниз (если смотреть на слайд выше):
- Для начала работы нужен PostgreSQL, который будет в свою очередь необходим для PuppetDB.
- Поднимая PostgreSQL, мы регистрируем его в Consul. Поднимая PuppetDB, мы берем информацию из Consul о PostgreSQL, коннектимся к нему и передаем информацию о PuppetDB обратно в Consul.
- Дальше мы поднимаем необходимое количество Puppet-server нод на Java. Информацию для них мы берем из Consul, информацию о них мы кладем в Consul.
- Последним этапом мы поднимаем load balancing на nginx, который занимается SSL терминированием, обслуживает 3 порта:
- порт для непосредственно Puppet агентов;
- порт для Puppet DB;
- порт для статистики.
Все остальные клиенты ходят через load balancing.
GLPI
У нас есть такая штука, которая называется glpi, она необходима для любого дата-центра. Все довольно топорно и просто — это сервис для инвентаризации.
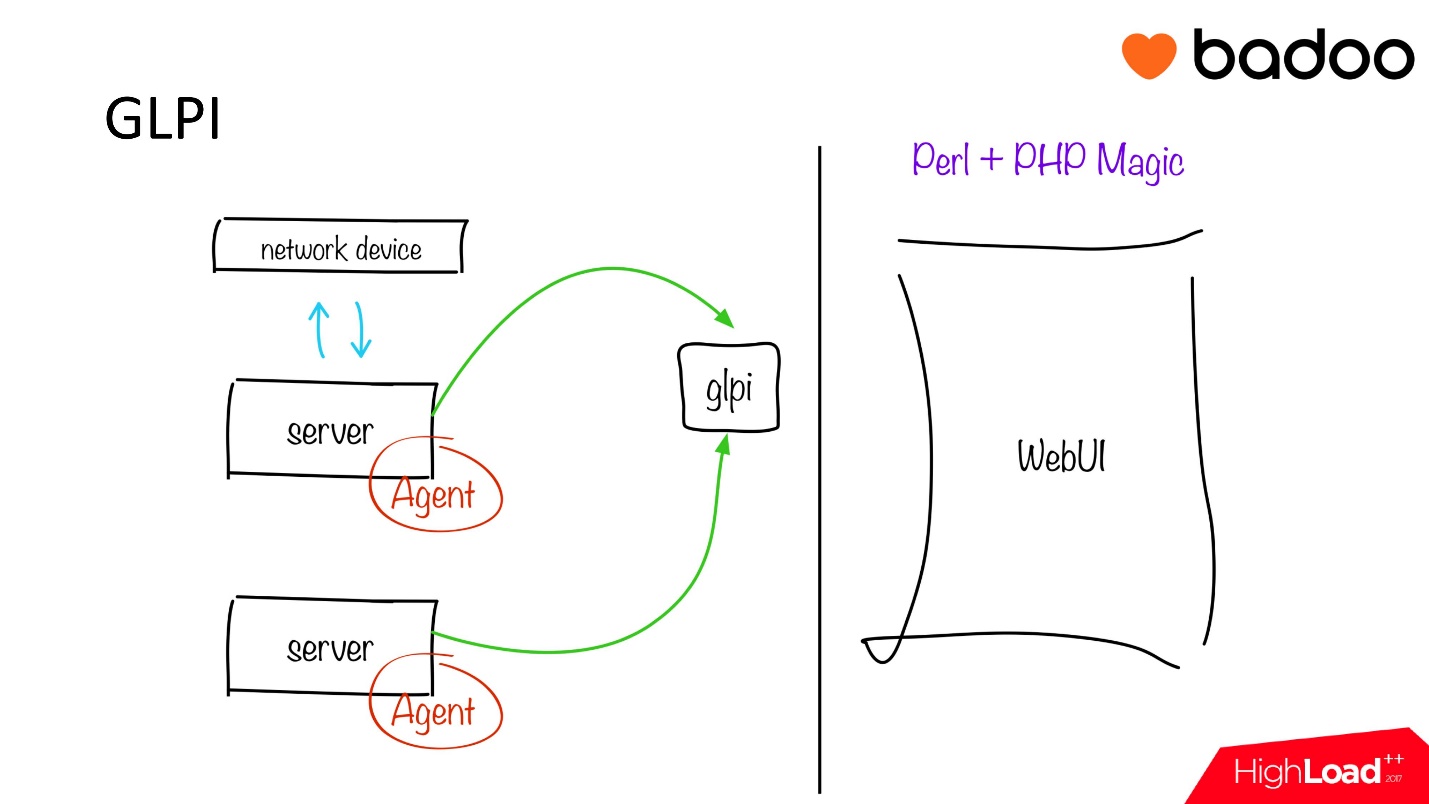
Он работает следующим образом:
- На каждом сервере запускается простой FusionInventory Agent, которые собирает всю информацию по железу, софту, антивирусам, файловым системам — все зависит от настроек. Нам обычно интересны всякие «железные» показатели: какой памяти сколько, какие диски, контроллер, кэш и т.д.
- Эту информация через определенный временной интервал (в нашем случае раз в сутки) отправляется на некий PHP endpoint, в котором происходит обработка и передача данных в glpi базу данных.
Еще одно преимущество использования GLPI и FusionInventory состоит в том, что мы можем инвентаризировать не только серверное оборудование, но и сетевое, для того чтобы получить информацию, какие есть порты и какая на них скорость, и самое главное — какой сервер с каким серийником, находясь в какой стойке, подключен в какой сетевой узел и в какие порты. Результатом всего этого действа становится веб страничка, на которой можно смотреть всю эту информацию.
Мы рассмотрели 5 инструментов, которые были описаны в нашей Wiki, наш гипотетический админ посмотрел на них и запустил по каждому не более 3-5 контейнеров — инфраструктура готова. Мы получили домик счастливых людей, которые продуктивно работают: один задачу обозначил, другие ему помогли, в общем и целом ознакомились, почитали — и подняли такую штуку.

В Badoo таких человечков с шариками в команде админов больше, но мы продуктивные и точно счастливые в большинстве своем. Нашу команду дружных профессионалов удалось создать, потому что мы смогли обозначить три проблемы и научились с ними справляться.
Итак, что необходимо для исполнителей (мне кажется, не только для админа):
- Уменьшать переключение контекста. Дайте человеку работать — если он технарь, пускай сидит и работает, не отрывайте!
- Делать процессы прозрачными. Если вы срываете сроки и есть подозрение, что что-то не так приоритизацией задач, дайте команде информацию о том, почему конкретная задача важна. Человек должен видеть дальше своего монитора, и знать, что его участие в проекте важно. Тогда он будет работать иначе, он будет понимать срочность и полезность своей работы.
- Писать хорошую документацию. Причем хорошо, если эта документация будет разделена на разные части. Она может быть подробной и глубокой, если ты хочешь ознакомиться и зарыться. Но при этом у вас должна быть выдержка про сервис или службу, которая помещается на одну страницу и содержит набор из 5-6 действий, которые необходимо сделать до эскалации. Более того, документацию важно всегда держать в актуальном состоянии.
Когда вы увеличиваете прозрачность работы в отделе, проблема обновления документации решается сама собой, потому что вы видите, какие итерации происходят, и у вас постоянно спрашивают: «Обнови, обнови, обнови».
References
Это ссылки на различные исследования на тему context-switching, как грамотно работать, как не отвлекаться и делать больше, а также ссылки на все продукты, про которые я рассказывал, которые являются базой и опорой любого из дата-центров Badoo.
- Why developers hate being interrupted,
- Programmer Interrupted,
- Interrupts: just a minute never is,
- A diary study of task switching and interruptions,
- No task left behind?: examining the nature of fragmented work,
- xCAT,
- GLPI, FusionInventory,
- Puppet,
- Consul,
- Status Hero.
Сибирская версия конференции для разработчиков высоконагруженных проектов Highload++ Siberia стартует уже в понедельник и займет 25 и 26 июня. На ней Антон расскажет об эволюции инструментов и сервисов на вооружении команды эксплуатации Badoo,
И еще 30 признанных экспертов и представителей лидеров индустрии представят свои наработки и поделятся опытом — смотрите программу.
Комментарии (41)

AndreyYu
21.06.2018 12:35+2До этого поста я считал что «джентельменский набор сисадмина» выглядит слегка «иначе» :)
banuchka
21.06.2018 12:46+1В этот раз вышло так, что содержание не совсем соответствует тому, что написано на упаковке. Да, я про название и, в итоге, содержание.
В следующий раз постараюсь так не делать :)scruff
22.06.2018 08:04Ну так исправьте заголовок. В чём вопрос? Лично я зашёл под кат с целью узнать что-нибудь новое о Putty, Wireshark, netstat и прочего зоопарка утилит. В итоге сложилось впечатление «зачем я здесь».
alexq2
21.06.2018 16:07+1banuchka Вопрос по GLPI. Как вы это делаете? В GLPI только стойка или еще юнит в стойке?
какой сервер с каким серийником, находясь в какой стойке, подключен в какой сетевой узел и в какие порты.
banuchka
21.06.2018 16:21В GLPI для сервера/любой железки прописаны:
— стойка
— юнит в стойке
, при условии, что у вас:
— должны быть заведены параметры стойки
— должны быть заведены параметры «железки» (сколько юнитов та или иная платформа занимает)
Вопрос заполнения данной информации – это вопрос целой дискуссии. Решение зависит от того как много оборудования, как далеко от вас ДЦ, как часто вы что-то переставляете/добавляете и тд.
Используется плагин Rack enclosures managementalexq2
21.06.2018 17:10Вопрос заполнения данной информации – это вопрос целой дискуссии. Решение зависит от того как много оборудования, как далеко от вас ДЦ, как часто вы что-то переставляете/добавляете и тд.
Самый больной вопрос. Ввод\вывод из эксплуатации ежегодно 40-50 серверов и информация заносится вручную. Иногда бывает, что человек приехавший в ДЦ находит в стойке сервер списанный два года назад.
Вот еще хороший плагин GLPI-Datacenters-managementbanuchka
21.06.2018 17:2440-50 – это не так много.
Да, так, к сожалению, бывает. Автоматизация и слежение за тем, что делают люди – в нашем случае работники ДЦ – трудоемкая задача, т.к. не очень просто уследить за тем, произошел ли демонтаж или нет.
zeronice
21.06.2018 16:35Если админ (админ, не технический директор) — третий человек в конторе (а то и самый важный, по вбросу в статье) то, управленческая ошибка уже совершена, техническое обеспечение должно быть абстрагировано от бизнес-процессов, а не спаяно с ними.
scruff
22.06.2018 10:31Для разделения необходимо иметь еще несколько человек-прослоек в штате, что далеко не многие организации могут позволить себе такую раскошь. Разрабатывая модель бизнесс-процессов для своей организации (по IT-части), я заметил особенность, что IT, в той или иной степени, «сидит» чуть ли не в каждом под-процессе — так что абстрагировать, даже в самом начале, просто так не получится. Это даже не управленческая ошибка, а больше фитча, ну или суровая реальность, с которой мы либо миримся, либо платим деньги за штат «человеков-прослоек», этаких «наблюдунов». Уверен большинство склонится к 1-му пункту, т.к., опять же, далеко не многие организации, в начале свой жизнедеятельности, готовы сразу нанять банч людей для разделения.
zeronice
22.06.2018 15:23В небольших организациях это решается нормальным трудовым договором, должностной инструкцией и документированием ИТ-решений. Чтобы и от фактора автобуса не пострадать и от нечистоплотности админов, и просто быстро найти замену, если админ решил сменить работодателя. А все беды ровно от того, что руководитель смотря на ИТ машет рукой "И так сойдет" и слепо доверяет админу
shekelgruber
21.06.2018 17:17> Админ — это главный человек в компании!
После вахтера и уборщицы, разумеется.AbstractGaze
22.06.2018 06:52Не путайте админа с эникеем, который считает себя админом.
scruff
22.06.2018 10:36Зачастую и «нормального» админа считают первым после уборщицы. Великого комбинатора может спасти качественно разработанноая IT-политика, заверенная CEO-ом, и активное продвижение/применение её тезисов «в массы», на всех уровнях орг.структуры.
Firz
23.06.2018 15:51А все они вместе взятые после электрика/энергетика. Даже уборщица не будет в темноте убираться.
Sleuthhound
21.06.2018 20:04Не осилил весь этот бред, но по 20-ти летнему опыту админства скажу, что нет, сейчас админ уже не стоит на 3 или даже 5 месте по важности в компании, это было в далеких 90-х или начале 2000-х, но не сейчас, не нужно строить иллюзий на эту тему. Незаменимых людей не бывает.
DMGarikk
21.06.2018 20:24в мелких и жадных конторах вполне бывают незаменимые люди, и таких контор немало
scruff
22.06.2018 10:46Стоит и еще как стоит! Просто этого никто не замечает ну или делает вид, что не замечает (обычно второе). Посмотрите на то бурление и коллапс внутри компании, когда ее покидает админ. По своему опыту скажу — это огромноый стресс для процессов компании, которые завязаны на ИТ, а как я писал выше, таких процессов чуть меньше чем все. По поводу незаменимости — полностью согласен с Вами, но посчитайте, при ситуации, через какой период новый админ выйдет на «стандартный режим»? На моей практике — это от месяца до трех (в лучшем случае), даже при должной передаче дел. Пока идет «транзитный режим» — все процессы и их участники ощущают это. К примеру, когда уходит главбух или директор по маркетинку, да тот же самый CEO — стресс минимален и врядли встанут какие-либо процессы, ну за исключением одобрения какой-нибудь бумажки, но это кратковременно.
fivehouse
22.06.2018 01:54По факту профессия админа маргинализируется с каждым днем. Массовое сознание почему-то начинает считать, что сервера это что-то типа холодильников или пылесосов. А «сервер RDBMS» это вообще придумали комедианты. А вот когда в компании 1000 нагруженных серверов, несколько машзалов, сторадж площадка площадью 2500 кв метров, админы являются частью инфраструктурного подразделения, а менеджеры управляющие инфраструктурой пытаются всем подряд вставить мОзги, там админы еще как-то живут. Но тоже все сильнее и сильнее понижаются в правах. Все по той же причне. А в остальных местах на них смотрят как на дармоедов не пойми что делающих. В результате имеет место тотальная деградация самой инфраструктуры. Но вот к этому тупо готовы привыкать по всей вертикали. За то сэкономили 120 т.р. на зп «бездельника».
scruff
22.06.2018 10:55Еще вся проблема в том, что реально стОящие админы готовы «вкалывать» за копейки. Давече общался с одним парнем — он получает 400$ (за шестидневный фул-тайм), при этом шарит в виртуализации чуть ли не на уровне разраба. И это тоже печально.
1nd1g0
23.06.2018 09:04Описанное Вами является следствием повышенного проникновения IT в обычную бытовую жизнь обывателей. Как следствие, лица, принимающие решения, вырабатывают очередной шаблонный рефлекс, позволяющий лишний раз не думать. Их логика проста — раз у меня дома 4 компьютера и избалованный, ленивый и ненадёжный сын-малолетка «всё в них понимает», значит все «понимающие в компьютерах» — инфантильные бездельники и мозгов там не нужно, а мне, такому крутому начальнику, просто в эти игрушки некогда играться и разбираться что там к чему.
sbh
22.06.2018 06:29+1у автора голова мерзнет?
banuchka
22.06.2018 12:25Это единственная причина задать вопрос?
sbh
22.06.2018 12:36-1Ну ты шубу одень летом а потом когда тебя спросят нафига ты ее надел отвечай что это единственная причина задать вопрос
HappyGroundhog
22.06.2018 14:41-1Смотря во что одевать шубу) Я бы тоже спросил человека, одевшего шубу в разную одежду «зачем?!». Шубу, её все же надевают…
KiloLeo
22.06.2018 11:26«Думаю, вы со мной согласитесь: админ —… главный.»
Да не, главный человек в конторе — это уборщица. Без неё все грязью зарастут. Или нет, самый главный — это повар в столовке. Без еды ведь все помрут. Или нет, завхоз самый главный. Он стулья обеспечивает, а на них все сидят.
В общем, каждый может считать себя самым главным в конторе.
Seboreia
22.06.2018 13:49+1Двоякое ощущение от статьи. Вроде бы и интересно, но вот что бросается в глаза:
1.… выделили одного члена команды и сказали ему: «Чувак, ты будешь условным лидером! Это — не повышение по карьерной лестнице, просто ты довольно много знаешь о том, кто из твоих коллег в какой области хорош, ты знаешь ...
Т.е. вы наделили чувака доп. обязанностями (менеджерскими, как я понимаю), но подчеркиваете, что это не повышение. На мой взгляд не совсем «здоровая» ситуация
2.Люди начали бугуртить, кому-то мало задач, кому-то много, кому-то достаются неинтересные...
Вот здесь (и далее по статье) я так и не понял, как у вас в итоге распределяются задачи?
А в целом с выводами полностью согласен. Жаль только, что совесть может быть далеко не у всех людей в коллективе.banuchka
22.06.2018 14:17Т.е. вы наделили чувака доп. обязанностями (менеджерскими, как я понимаю), но подчеркиваете, что это не повышение. На мой взгляд не совсем «здоровая» ситуация
Вы всё верно поняли. Данный подход показал себя в нашем случае как «не рабочий».
Вот здесь (и далее по статье) я так и не понял, как у вас в итоге распределяются задачи?
Я рассказывал в течении доклада, что людям нравится формат – «Мне нравится задача, я могу и хочу ей заниматься», вот такой формат и остается по сей день. Да, бывает такое, что менеджер видит срочность и принимает решение, пообщавшись с исполнителем, что именно он возьмет и будет заниматься задачей.
А в целом с выводами полностью согласен. Жаль только, что совесть может быть далеко не у всех людей в коллективе.
Спасибо. Люди – не роботы :)
andrewmillion
22.06.2018 16:39Отличная статья, спасибо. Как мотивируете читать чат с репортами коллег?
banuchka
22.06.2018 17:30Отличная статья, спасибо.
Спасибо.
Как мотивируете читать чат с репортами коллег?
По-разному. Для кого-то работает: «там уведомление горит, прочту», а для кого-то «холодный душ по телефону», например «вот ты не читал, а я про это писал сегодня/вчера и т.д. Ай-яй! читай, пожалуйста». Пару-тройку таких итераций и подобного более не повторяется.
Т.е. основная идея тут – это общая польза как для «читателя», так и для «писателя».
Dvlbug
22.06.2018 20:55Все-таки, «джентльменский набор» это все-таки другое, я изначально рассчитывал современный набор софта.
По теме, мою работу сейчас контролируют с помощью Jira, Мегаплана. В итоге один из самых бесполезных в офисе, потому что все было починено или доведено до ума (не до абсурдного айптайма, как иногда требует начальство)

cyberbolt
23.06.2018 09:04Порекомендую тут хорошую книгу Томаса Лимончелли Практика системного администрирования. Там и про организацю работы админа и про «джентельменский набор» есть. Она хоть и 2009 года, но до сих пор актуальна.
box4
23.06.2018 09:04если не задокументированы услуги, процессы, сервисы, каталог, роли, ответственности, то да, админ главный
uldashev
23.06.2018 10:55Есть такая штука itil, есть аналог от microsoft mof, но мы всегда будем идти своим путем.
fivehouse
24.06.2018 01:09У ITIL-a есть существенный дефект, сводящий его на нет в местных реалиях. По ITILу заказчика IT услуг заставляют нести ответственность не только за запрос самой IT услуги, но и за состав и параметры услуги, которые под подпись пытаются с ним обговорить заранее. И это приводит к тотальному фейлу. Местные (и не только) заказчики и менеджеры в принципе ни за что никакую ответственность нести не желают. Ссылаются они на то, что они не ИТшники и ничего (ни в чем?) не понимают. А так, в ITIL-е все как бы правильно. Читаешь и плачешь. Плачешь и читаешь. Искусственно раздутое псведонепонимание потребителями IT услуг всего в IT создает дополнительный зазор в оправдании личных фейлов всех зависимых от IT. А тут какие-то «программисты» пытаются не просто лишить VIP менеджеров хорошего механизма оправдания личных низких показателей, так еще и возложить на VIP менеджеров же ответственность за что-то там в ИТ, как они с истерикой пытаются представить внедрение чего-то хоть как-то похожего на ITIL! В результате RIP ITIL, и все что хоть как-то пытается быть на него похожим тоже RIP. И чем существенней и дороже услуга, тем категоричней сопротивление.
nehrung
Где-то читал такое мнение, что сисадмин — третий человек в конторе, по уровню включённости в её секреты (после гендира и главного бухгалтера). И если гендир этого не сознаёт и не заинтересовывает сисадмина (да, и материально тоже!), то может спровоцировать его на совершение противоправных действий своими специфическими методами. Что и бывало не раз.
Quagga_Gsom
Если системный администратор ощутимо вовлечён в коммерческую тайну предприятия, то нужно срочно нанять безопасника, который объяснит различие между системным, администратором прикладного ПО и администратором СУБД.
Кстати, над всеми тремя стоит уборщица с ключами от всех помещений.