
Потоковая репликация, которая появилась в 2010 году, стала одной из прорывных фич PostgreSQL и в настоящее время практически ни одна инсталляция не обходится без использования потоковой репликации. Она надежна, легка в настройке, нетребовательна к ресурсам. Однако при всех своих положительных качествах, при её эксплуатации могут возникать различные проблемы и неприятные ситуации.
Алексей Лесовский (@lesovsky) на Highload++ 2017 рассказал, как с помощью встроенных и сторонних инструментов, диагностировать различные типы проблем и как устранять их. Под катом расшифровка этого доклада, построенного по спиральному принципу: сначала мы перечислим все возможные средства диагностики, потом перейдем к перечислению типовых проблем и их диагностике, далее посмотрим, какие экстренные меры можно принять, и наконец как радикально справиться с задачей.
О спикере: Алексей Лесовский администратор баз данных в компании Data Egret. Одной из любимых тем Алексея в PostgreSQL является потоковая репликация и работа со статистикой, поэтому доклад на Highload++ 2017 был посвящен тому, как помощью статистики искать проблемы, и какие использовать методы для их устранения.
План
Зачем всё это? Эта статья поможет вам лучше разбираться в потоковой репликации, научиться быстро находить и устранять проблемы, чтобы сократить время реакции на неприятные инциденты.
Немного теории
В PostgreSQL есть такая сущность, как Write-Ahead Log (XLOG) — это журнал транзакций. Почти все изменения, которые происходят с данными и метаданными внутри базы данных, записываются в этом журнале. Если вдруг произошла какая-то авария, PostgreSQL запускается, читает журнал транзакций и восстанавливает записанные изменения на данных. Так обеспечивается надежность — одно из важнейших свойств любой СУБД и PostgreSQL в том числе.
Журнал транзакций может заполнятся двумя способами:
Самое важное то, что потоковая репликация основана на этом журнале транзакций. У нас есть несколько участников потоковой репликации:
Стоит помнить, что все эти журналы транзакций, хранятся в каталоге pg_xlog в $DATADIR — каталоге с основными файлами данных СУБД. В 10-й версии PostgreSQL этот каталог был переименован в pg_wal/, потому что нередки случаи когда pg_xlog/ занимает много места, и разработчики или администраторы, по незнанию путая его с логами, беспечно удаляют и становится все плохо.
В PostgreSQL есть несколько фоновых служб которые задействованы в потоковой репликации. Посмотрим на них с точки зрения операционной системы.
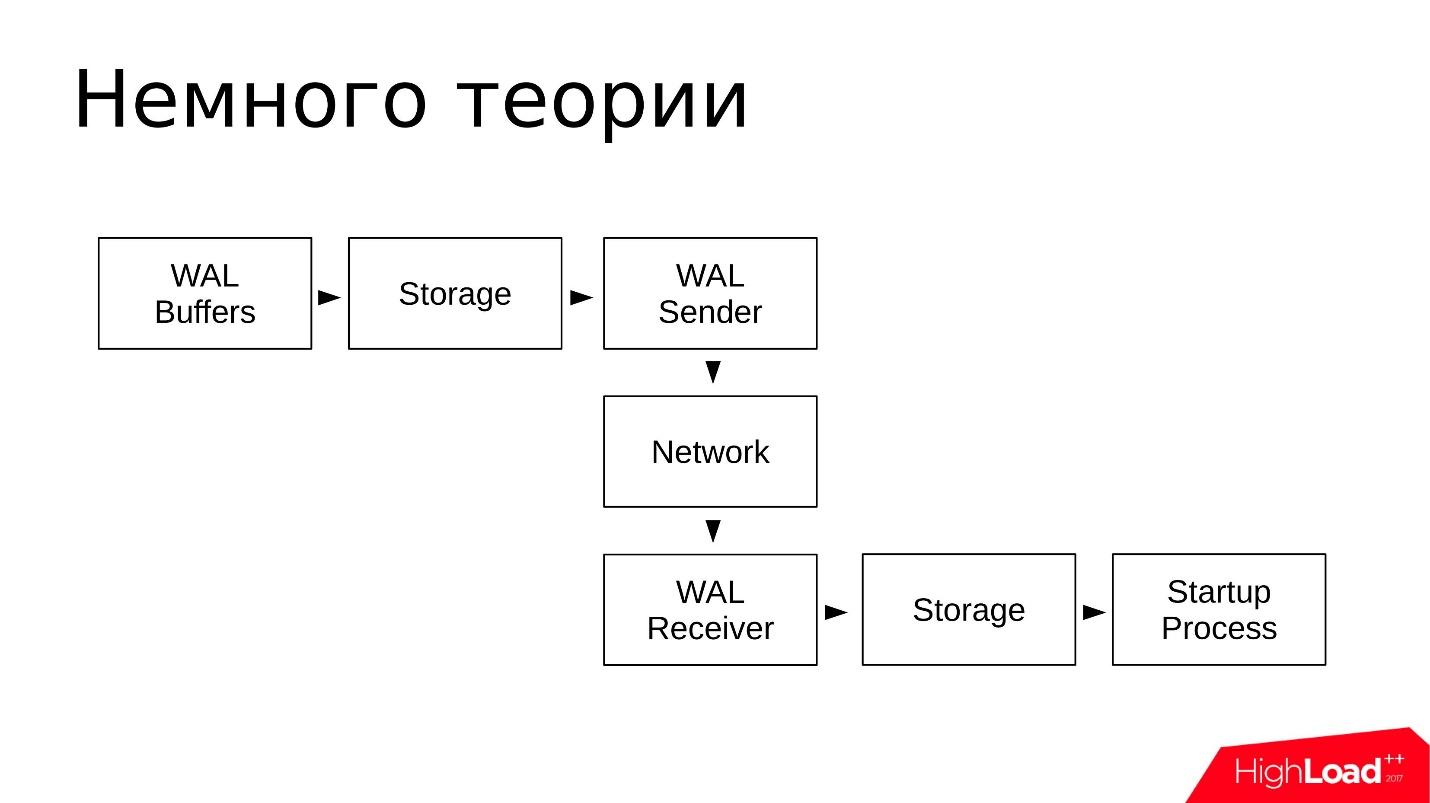
Схематично это выглядит примерно так:
Схема простая. Потоковая репликация работает довольно надежно и много лет прекрасно эксплуатируется.
Troubleshooting tools
Посмотрим, какие средства и утилиты предлагает сообщество и PostgreSQL для того, чтобы расследовать проблемы, возникающие с потоковой репликацией.
Сторонние инструменты
Начнем со сторонних инструментов. Это утилиты довольно универсального плана, ими можно пользоваться не только при расследовании инцидентов, связанных с потоковой репликацией. Это вообще утилиты любого системного администратора.
С помощью top смотрим: утилизацию процессоров (CPU), среднюю нагрузку (load average) и использование памяти и области подкачки.
С помощью iostat смотрим: утилизацию хранилища, сколько iops в данный момент, какая пропускная способность (throughput) на устройствах, какие задержки при обработке запросов на I/O (latency). Эта довольно подробная информация берется из файловой системы procfs и предоставляется пользователю уже в наглядном виде.
С помощью nicstat смотрим: аналогично — утилизацию интерфейсов, какие-то ошибки, которые возникают на интерфейсах, пропускную способность — тоже очень полезная утилита.
С помощью pgCenter смотрим: статистику по репликации. Можно смотреть лаг репликации, как-то оценивать его, и прогнозировать дальнейшие работы.
С помощью perf ищем: подземные стуки. Для полноценной работы perf c PostgreSQL, последний должен быть собран с debug символами, таким образом можно смотреть стек функций в процессах и какие функции занимают больше всего процессорного времени.
Все эти утилиты нужны, чтобы проверять гипотезы, возникающие при устранении неполадок — где и что тормозит, где и что нужно исправить, проверить. Эти утилиты помогают удостовериться, на правильном ли мы пути.
Встроенные средства
Что предлагает сам PostgreSQL?
Системные представления
Вообще средств для работы с PostgreSQL довольно много. Каждая компания-вендор, которая предоставляет поддержку PostgreSQL, предлагает свои средства. Но, как правило, эти средства основаны на внутренней статистике PostgreSQL. В этом плане PostgreSQL предоставляет системные представления (views), в которых можно делать различные select’ы и получать нужную информацию. То есть c помощью обычного клиента, как правило psql, мы можем делать запросы и смотреть, что происходит в статистике.
Существует довольно много системных представлений. Для того, чтобы работать с потоковой репликацией и исследовать проблемы, нам нужны лишь: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts, и вспомогательные pg_stat_activitу и pg_stat_archiver.
Их немного, но этого набора достаточно, чтобы проверить, нет ли каких-либо проблем.
Вспомогательные функции
С помощью вспомогательных функций можно брать данные из статистических системных представлений и преобразовывать их в более удобный для себя вид. Вспомогательных функций тоже всего несколько штук.
Полный список функций можно получить psql мета-командой: \df *(wal|xlog|lsn|location)*.
Ее можно набрать в psql и посмотреть все функции, которые содержат в себе wal, xlog, Isn, location. Таких функций будет порядка 20-30, и они тоже предоставляют различную информацию по журналу транзакций. Рекомендую ознакомиться.
Утилита pg_waldump
До версии 10.0 она называлась pg_xlogdump. Утилита pg_waldump нужна, когда мы хотим заглянуть в сегменты журнала транзакций, узнать какие ресурсные записи туда попали, и что PostgreSQL туда записал, то есть для более детального исследования.
Утилита pg_waldump просто декодирует содержимое XLOG сегментов в человеко-понятный формат. Можно посмотреть, какие так называемые ресурсные записи попадают в процессе работы PostgreSQL в журналы сегмента, какие индексы и heap-файлы были изменены, какая информация, предназначенная для stand-by, туда попала. Таким образом, очень много информации можно смотреть с помощью pg_waldump.
Можно воспользоваться командой:
Это аналог команды tail -f только для журналов транзакций. Эта команда показывает хвост журнала транзакций, которые прямо сейчас происходит. Можно запустить эту команду, она найдет последний сегмент с самой последней записью журнала транзакций, подключится к нему и начнет показывать содержимое журнала транзакций. Немного хитрая команда, но, тем не менее, она работает. Я часто ей пользуюсь.
Troubleshooting cases
Здесь мы рассмотрим самые частые проблемы, которые возникают в практике консалтеров, какие могут быть симптомы и как их диагностировать:
Лаги репликации — это наиболее частая проблема. Совсем недавно у нас была переписка с заказчиком:
Проблемы с лагами репликаций у нас бывают постоянно, и чуть ли не каждую неделю мы их решаем.
Распухание каталога pg_wal/, где хранятся сегменты журнала транзакций — это проблема, которая возникает реже. Но в этом случае необходимо предпринимать немедленные действия, чтобы проблема не превратилась в аварийную ситуацию, когда реплики отваливаются.
Долгие запросы, которые выполняются на реплике, приводят к конфликтам при восстановлении. Это ситуация, когда мы на реплику пускаем какую-то нагрузку, на репликах можно выполнять читающие запросы, и в этот момент эти запросы мешают воспроизведению журнала транзакций. Возникает конфликт, и PostgreSQL нужно решить, ждать завершение запроса или завершить его и продолжить воспроизведение журнала транзакций. Это конфликт репликации или конфликт восстановления.
Recovery process: 100% CPU usage —процесс восстановления журнала транзакций на репликах занимает 100% процессорного времени. Это тоже редкая ситуация, но она довольно неприятная, т.к. приводит к росту лага репликации и в целом её сложно расследовать.
Лаги репликации
Лаги репликации — это когда один и тот же запрос, выполненный на мастере и на реплике, возвращает разные данные. Это значит, что данные неконсистентны между мастером и репликами, и есть какое-то отставание. Реплике нужно воспроизвести часть журналов транзакций, чтобы догнать мастера. Основной симптом выглядит именно так: есть запрос, и они возвращают разные результаты.
Как искать такие проблемы?
В 10 версии pg_stat_replication появились дополнительные поля, которые показывают временной лаг уже на мастере, поэтому этот способ уже устаревший, но, тем не менее, его можно использовать.
Есть небольшой подводный камень. Если на мастере долгое время нет транзакций, и он не генерирует журналы транзакций, то последняя функция будет показывать увеличивающийся лаг. На самом деле система просто простаивает, на ней нет никакой активности, но в мониторинге мы можем увидеть, что лаг растет. Про этот подводный камень стоит помнить.
Представление выглядит следующим образом.

Оно содержит информацию по каждому WAL Sender и несколько важных для нас полей. Это в первую очередь client_addr — сетевой адрес подключенной реплики (как правило, IP адрес) и набор полей lsn (в старых версиях он называется location), про них я расскажу чуть дальше.
В 10-й версии появились поля lag — это отставание, выраженное во времени, то есть более человеко-понятный формат. Лаг может выражаться либо в байтах, либо во времени — можно выбрать, что больше нравится.
Как правило, я пользуюсь таким запросом.

Это не самый сложный запрос, который выводит pg_stat_replication в более удобном, понятном формате. Здесь я использую следующие функции:
Немного примеров

Выше цветом выделена реплика 10.6.6.8. У нее pending-лаг, она нагенерировала какие-то журналы транзакций, но они все еще не отправлены и лежат на мастере. Вероятнее всего, здесь какая-то проблема с сетевой производительностью. Мы будем это проверять с помощью утилиты nicstat.
Мы запустим nicstat, посмотрим утилизацию интерфейсов, нет ли там проблем и ошибок. Так мы сможем проверить эту гипотезу.

Выше отмечен write лаг. На самом деле этот лаг довольно редкий, я практически не вижу, чтобы он был большим. Проблема может быть с дисками, и мы используем утилиту iostat или iotop — смотрим утилизацию дисковых хранилищ, какой I/O создается процессами, и дальше уже выясняем, почему.

Flush и replay Лаги — чаще всего лаг бывает именно там, когда дисковое устройство на реплике не успевает просто проиграть все те изменения, которые прилетают с мастера.
Также утилитами iostat и iotop мы смотрим, что происходит с дисковой утилизацией и почему тормоза.
И последний total_lag — полезная метрика для систем мониторинга. Если у нас порог total_lag превышен, в мониторинге поднимается флажок, и мы начинаем расследовать, что же там происходит.
Проверка гипотезы
Теперь нужно разобраться, как дальше исследовать ту или иную проблему. Я уже сказал, если это сетевой лаг, то нужно проверить, все ли у нас в порядке с сетью.
Сейчас практически все хостеры предоставляют 1 Гб/с или даже 10 Гб/с, поэтому забитая полоса пропускания — это самый маловероятный сценарий. Как правило, нужно смотреть на ошибки. nicstat содержит информацию по ошибкам на интерфейсах, можно разобраться, что там — проблемы с драйверами, либо с самой сетевой картой, либо с кабелями.
Проблемы в хранилище мы исследуем с помощью iostat и iotop. iostat нужен для просмотра общей картины, связанной с дисковыми хранилищами: утилизация устройств, пропускная способность устройств, latency. iotop — для более точных исследований, когда нам нужно выявить, какой из процессов грузит дисковую подсистему. Если это какой-то сторонний процесс, его можно просто обнаружить, завершить и, возможно, проблема исчезнет.
Задержки восстановления и конфликты репликации мы прежде всего смотрим через top или pg_stat_activity: какие процессы запущены, какие запросы работают, время их выполнения, как долго они работают. Если это какие-то долгие запросы, мы смотрим, почему они долго работают, отстреливаем их, разбираемся и оптимизируем их — исследуем уже сами запросы.
Если это большой объем журналов транзакций, который генерируется мастером, мы можем это обнаружить по pg_stat_activity. Может быть, там какие-то бэкапные процессы запущены, запущены какие-то вакуумы (pg_stat_progress_vacuum), либо выполняется checkpoint. То есть если генерируется слишком большой объем журналов транзакций, и реплика просто не успевает его обработать, в какой-то момент она может просто отвалиться, и это будет уже проблемой для нас.
И конечно pg_wal_lsn_diff() для определения лага и определения, где у нас конкретно лаг находится — в сети, на дисках, либо на процессорах.
Варианты решения
Проблемы на уровне сети/хранения
Тут довольно все просто, но с точки зрения конфигурации это, как правило, не решается. Можно подкрутить некоторые гайки, но в целом есть 2 варианта:
Проверяем какие выполняются запросы. Может быть, запущены какие-то миграции, которые генерируют много журналов транзакций, либо это может быть перенос, удаление или вставка данных. Любой процесс, который генерирует журналы транзакций, может приводить к лагу транзакций. Все данные на мастере генерируются как можно быстрее, мы внесли изменение данных, отправили на реплику, а справится реплика или не справится — это уже мастера не волнует. Здесь может появиться лаг и нужно что-то с ним делать.
Самый тупой вариант — возможно, мы уперлись в производительность железа, и нужно его просто менять. Это могут быть старые диски либо некачественные SSD, либо затык в производительности RAID контроллера. Здесь мы исследуем уже не саму базу, а проверяем производительность наших железок.
Задержки восстановления
Если у нас возникли какие-то конфликты репликации из-за долгих запросов в результате чего увеличивается replay lag, мы первым делом отстреливаем долгие запросы, которые работают на реплике, потому что они задерживают воспроизведение журналов транзакций.
Если долгие запросы связаны с неоптимальностью самого SQL запроса (выясняем это с помощью EXPLAIN ANALYZE), нужно просто подходить по-другому к этому запросу и переписывать его. Либо есть вариант настройки отдельной реплики для отчетных запросов. Если мы делаем какие-то отчеты, которые долго работают, их нужно выносить на отдельную реплику.
Еще остается вариант просто ждать. Если у нас какой-то лаг на уровне нескольких килобайт или даже десятков мегабайт, но мы считаем, что это приемлемо, мы просто ждем, когда запрос выполнится и лаг сам рассосется. Это тоже вариант, и часто бывает, что он приемлем.
Большой объем WAL
Если мы генерируем большой объем журнала транзакций, нужно уменьшить этот объем в единицу времени, сделать так, чтобы реплике было нужно прожевывать меньше журналов транзакций.
Как правило, это делается с помощью конфигурации. Частичное решение в задании параметра full_page_writes = off. Этот параметр выключает/выключает запись полных образов изменяющихся страниц в журнал транзакций. Это означает, что, когда у нас произошла служебная операция записи контрольной точки (CHECKPOINT), при последующем изменении какого-то блока данных в области shared buffers, в журнал транзакций уйдет полный образ этой страницы, а не только само изменение. При всех последующих изменениях этой же самой страницы, в журнал транзакций будут попадать только изменения. И так до следующей контрольной точки.
После чекпоинта мы записываем полный образ страницы, и это сказывается на объеме записываемого журнала транзакций. Если чекпоинтов в единицу времени довольно много, допустим, в час делается 4 чекпоинта, и полных образов страниц будет записываться тоже очень много, это будет проблемой. Можно отключить запись полных образов и это скажется на объеме WAL. Но опять же это полумера.
Примечание: К рекомендации отключения full_page_writes, стоит отнестись вдумчиво, так как автор в ходе доклада забыл уточнить, что отключение параметра может, при некотором стечение обстоятельств в аварийных ситуациях (повреждение файловой системы или ее журнала, частичная запись в блоки и т.п.) потенциально привести к повреждению файлов базы данных. Поэтому будьте внимательны, отключение параметра может увеличить риск повреждения данных в аварийных ситуациях.
Другая полумера — это увеличить интервал между чекпоинтами. По умолчанию чекпоинт делается каждые 5 минут, и это довольно часто. Как правило, этот интервал увеличивают до 30–60 минут — это вполне приемлемое время, за которое все грязные страницы успевают стать синхронизированными на диск.
Но основной вариант решения — это, конечно же, посмотреть наш workload — какие там сейчас идут тяжелые операции, связанные с изменением данных, и, возможно, постараться эти операции по изменению делать пачками.
Допустим, у нас есть таблица, мы хотим удалить из нее несколько миллионов записей. Оптимальным вариантом будет не удалять эти миллионы разом одним запросом, а разбить их на пачки по 100–200 тысяч, чтобы, во-первых, генерировались небольшие объемы WAL, во-вторых, vacuum успевал проходить по удаленным данным, и следовательно лаг не был таким большим и критичным.
Распухание pg_wal/
Теперь, давайте поговорим, как можно обнаружить, что распух каталог pg_wal/.
По идее PostgreSQL всегда поддерживает его в оптимальном для себя состоянии на уровне определенных файлов конфигурации, и, как правило, он не должен расти выше определенных пределов.
Есть параметр max_wal_size, который определяет максимальное значение. Плюс есть параметр wal_keep_segments — дополнительное количество сегментов, которые мастер хранит для реплики, если вдруг реплика недоступна продолжительное время.
Посчитав сумму max_wal_size и wal_keep_segments, мы можем примерно оценить, сколько места будет занимать каталог pg_wal/. Если он быстро растет и занимает гораздо больше места, чем рассчитанное значение, это значит, что есть какая-то проблема, и нужно с этим что-то делать.
Как обнаружить такие проблемы?
В операционной системе Linux есть команда du -csh. Мы можем просто в мониторинг загнать значение и смотреть, сколько у нас там журналов транзакций; держать посчитанную метку, сколько он должен и сколько он по факту занимает, и как-то реагировать на изменение цифр.
Другое место, где мы смотрим, это представления pg_replication_slots и pg_stat_archiver. Наиболее частыми причинами, почему pg_wal/ занимает много места являются забытые слоты репликации или сломанная архивация. Другие причины также имеют место быть, но на моей практике встречались очень редко.
И, конечно же, всегда бывают ошибки в логах PostgreSQL, связанные именно с архивной командой. Других причин, которые связаны с переполнением pg_wal/, там, к сожалению, не будет. Мы можем там отловить только ошибки архивации.
Варианты проблем:
Тяжелый CRUD — тяжелые операции обновления данных — тяжелые INSERT, DELETE, UPDATE, связанные с изменением нескольких миллионов строк. Если PostgreSQL нужно сделать такую операцию, понятно, что будет генерироваться большой объем журнала транзакций. Он будет храниться в pg_wal/, и это приведет к увеличению занимаемого места. То есть опять же, как я сказал раньше, хорошей практикой является просто разбивать их на пачки, и делать обновление не всего массива, а по 100, 200, 300 тысяч.
Забытый или неиспользуемый слот репликации — другая частая проблема. Люди часто используют логическую репликацию для каких-то своих задач: настраивают шины, которые отправляют данные в Kafka, отправляют данные в стороннее приложение, которое делает декодинг логической репликации в другой формат и как-то их обрабатывают. Логическая репликация, как правило, работает через слоты. Бывает так, что мы настроили слот репликации, поигрались с приложением, поняли, что нам это приложение не подходит, выключили приложение, удалили, а слоты репликации продолжают жить.
PostgreSQL для каждого слота репликации сохраняет сегменты журнала транзакций на случай, если удаленное приложение или реплика снова подключатся к этому слоту, и тогда мастер сможет ему эти журналы транзакций отдать.
Но идет время, к слоту никто не подключается, журналы транзакций копятся, и в какой-то момент занимают 90% места. Нужно выяснять, что же там такое, почему занято так много места. Как правило, этот забытый и неиспользуемый слот нужно просто удалить, и проблема будет решена. Но об этом чуть дальше.
Другим вариантом может быть сломанная archive_command. Когда у нас есть какое-то внешнее хранилище журналов транзакций, которое мы держим для задач аварийного восстановления, обычно настраивается архивная команда, реже настраивается pg_receivexlog. Команда прописанная в аrchive_command — это очень часто, либо отдельная команда, либо какой-то скрипт, который берет сегменты журнала транзакций из pg_wal/ и копирует в архивное хранилище.
Бывает так, что провели какой-то апгрейд системных пакетов, допустим, в rsync версия поменялась, флаги обновились или изменились, либо в какой-то другой команде, которая использовалась в архивной команде, тоже поменялся формат — и скрипт или сама программа которая указана в archive_command ломается. Следовательно архивы перестают копироваться.
Если архивная команда отработала с выходом не 0, то в лог запишется сообщение об этом, а сегмент останется в каталоге pg_wal/. Пока мы не обнаружим, что у нас архивная команда сломалась, сегменты будут копиться, и место также в какой-то момент закончится.
Набор экстренных мер (100% used space):
??1. Отстрелить все долгие CRUD запросы, которые выполняются на данный момент на мастере — pg_terminate_backend().
Это могут быть какие-то копии запросов, выполняющиеся бэкапы, апдейты, которые обновляют миллион строк и т.д. Первым делом нам нужно отстрелить эти запросы, чтобы предотвратить дальнейший рост каталога pg_wal/, чтобы новые сегменты не генерировались.
??2. Уменьшить так называемое резервируемое место для файлов пользователя root — reserved space ratio (ext filesystems).
Это относится к файловым системам семейства ext и по умолчанию файловая система ext создается с резервным местом 5%. Представьте себе, что у вас файловая система на несколько сотен гигабайт, и 5% — довольно значительно. Поэтому, когда мы видим, что у нас остался 1% свободного места, мы быстро делаем команду tune2fs -m 1. Резервное место сразу становится доступным пользователю PostgreSQL и появляется время для того, чтобы исследовать проблему дальше. Таким образом есть мы откладываем 100% лимит заполненности на некоторое время.
??3. Добавить еще места (LVM, ZFS,...).
В случае использования LVM или ZFS, когда администратор резервирует свободное место в пуле LVM или ZFS, он может из этого резервного пула выделить свободное дополнительное место на том, где лежит база, и опять же с помощью команды файловой системы растянуть файловую систему. Таким методом можно экстренно отреагировать на то, что место заканчивается.
??4. И самое главное — НИКОГДА, НИЧЕГО, HE УДАЛЯТЬ РУКАМИ ИЗ pg_wal/.
Об этом говорят все постгресисты на всех конференциях и докладах, но люди все равно удаляют, удаляют и удаляют, а базы ломаются. Никогда ничего оттуда удалять нельзя! PostgreSQL сам оттуда периодически удаляет файлы, когда считает нужным. У него есть свои функции, свои алгоритмы, он сам определяет, когда это нужно сделать.
Кстати, pg_xlog/ переименовали в pg_wal/ именно по той причине — слово log сбивает с толку администраторов, и они думают, что, наверное, там какие-то ненужный логи — удалим их!
Что делать дальше
После того, как мы приняли экстренные меры и отложили наступление 100% заполнение CPU, можно перейти к устранению источников проблем.
Сначала нужно проверить workload и миграции. Что у нас там, что команда разработки запустила на этот раз? Может быть, они там хотели обновить какие-то данные, сделать загрузку данных или еще что-то. И на основании этого уже можно принимать архитектурное решение: добавить дополнительный диск, добавить новый tablespace, перенести данные между tablespace.
Дальше проверяем состояние репликации. Если у нас сгенерировалось много журналов транзакций, вполне вероятно, что мог образоваться лаг, и если образовался лаг, то, вполне возможно, что реплика не успела прожевать все журналы транзакций и могла попросту отвалиться. Нужно проверить реплики — все ли с ними в порядке.
Дальше нужно проверить настройки checkpoints_segments/max_wal_size, wal_keep_segments. Вполне возможно, что при конфигурации система, были выбраны слишком большие значения — 10-20 тысяч для wal_keep_segments, либо десятки гигабайт для max_wal_size. Может быть, есть смысл пересмотреть эти настройки и уменьшить их. Тогда PostgreSQL необходимые сегменты просто удалит и каталог pg_wal/ станет меньше.
Нужно проверить слоты репликации через представление pg_replication_slots — нет ли там неактивных слотов. Если они есть, то нужно проверить подписчика, который должен быть подписан на этот слот — все ли с ним в порядке. Если подписчика нет, он был давно удален, нужно слот просто удалить. Тогда проблема легко решается.
Если ошибки связаны с архивированием WAL, мы можем посмотреть эти ошибки в логе, либо посмотреть счетчик ошибок в pg_stat_archiver, там все это есть. Конечно, нужно починить архивную команду, разобраться, почему она не работает, и архивация не происходит.
После всех мер желательно вызывать команду checkpoint. Именно в этой команде зашита функция определения, какие сегменты журнала транзакций уже не нужны постгресу, и он может их спокойно удалить. Подчеркиваю, PostgreSQL сам определяет эти сегменты и сам их удаляет. Ничего не удаляем руками, только через команду checkpoint.
Долгие запросы и конфликты при восстановлении
Как я уже говорил, конфликты при восстановлении, конфликты репликации — это когда выполняющийся запрос на реплике выполняется долго. Он запросил какие-то данные и в этот момент с мастера прилетает изменение этих же самых данных, и репликация входит в конфликт с запросом. И вроде бы запрос нужно продолжить, но и эти данные на реплике тоже нужно изменить.
Основные симптомы — ошибки в логах PostgreSQL или приложения:
Первые 2 пункта — это наиболее частые причины, когда запрос идет именно на те данные, которые должны быть обновлены по репликации. Происходит следующий сценарий: есть параметр, который определяет задержку, которая будет отсчитываться при обнаружении конфликта. Как только эта задержка превысила заданный порог (по умолчанию 30 с), то PostgreSQL завершает запрос и репликация продолжает восстанавливать данные — все супер.
Следующая проблема возникает реже. Как правило, она связана с тем, что репликация с мастера передаёт некоторую информацию о блокировках на мастере в реплику. Если выполняющиеся запросы как-то конфликтуют с этими блокировками, то запрос также через timeout отстреливается и возникает эта ошибка. Такое бывает на миграциях — когда мы делаем ALTER, добавляем индексы в таблицы, такая ошибка может возникать.
Следующие ошибки возникают еще реже. Они обычно связаны с тем, что tablespace или база удалена на мастере, а запрос был запущен и работал с данными этой базы или tablespace. Это возникает редко, и обычно все знают, когда кто-то удаляет базу — мне так кажется.
Как обнаружить?
Для обнаружения у нас есть представления pg_stat_databases, pg_stat_databases_conflicts. В этих представлениях у нас есть информация о конфликтах, и их нужно мониторить. Если у нас есть конфликты, мы начинаем разбираться дальше.
Это действительно становится проблемой, если запросы отстреливаются по конфликту репликации очень часто. Мы считаем, что запросы очень важны нашим пользователям. Пользователи начинают страдать, и это уже проблема. Либо, когда возникает большой лаг репликации вследствие того, что запрос держит репликацию, и это тоже проблема.
Что делать?
Есть несколько вариантов, но все они — выбор наименьшего из зол:
Recovery process: 100% CPU usage
Бывает так, что процесс, который накатывает журнал транзакций, использует 100% ресурсов одного ядра. Он однопоточный, сидит только на одном ядре процессора, и полностью утилизирует его на 100%. Как правило, если посмотреть в pg_stat_replication, можно увидеть, что там большой лаг replay, то есть очень много данных нужно воспроизвести, и реплика не успевает.
Обнаруживаем это через:
Что и как искать
Это одна из самых нетривиальных проблем, алгоритмов поиска не сформировано. Как правило, мы прибегаем к использованию утилит:
Нужно посмотреть, какой стек функций, и где функции тратят больше всего времени. Типичным примером может быть workload, связанный с созданием и удалением временных либо обычных таблиц на мастере. Такое бывает, и чтобы удалить таблицу, PostgreSQL нужно просканировать все имеющиеся shared buffers и ссылки на эту таблицу удалить (очень упрощенно). Это довольно трудоемкая операция при воспроизведении журнала транзакций.
Решение
Как решать такие проблемы, тоже не всегда очевидно и зависит от результатов расследования. Где-то можно поменять workload, что-то поправить, где-то нужно написать патч разработчикам: «Я поковырялся в исходном коде и обнаружил, что то-то не оптимально».
Это можно писать в списках рассылки pgsql-hackers, pgsql-bugs, постить и ждать, когда разработчики отреагируют. К счастью, обычно это происходит быстро.
Но еще раз повторюсь — каких-то гарантированных решений здесь, к сожалению, нет.
Итоги
Проблемы потоковой репликации всегда распределены между хостами. Это значит, что причины проблем нужно искать на нескольких узлах и быть готовым к тому, что это распределенная проблема, которая находится не на одном узле.
Источниками проблем часто бывает пользовательская нагрузка. Я имею в виду, что, как правило, источником проблем являются запросы, которые генерирует приложение, и реже — оборудование.
Конечно же, нужно использовать мониторинг, без него — никуда. Добавьте нужные счетчики, которые я упоминал, в мониторинг, и тогда время реакции на проблему будет гораздо меньше.
Встроенные средства, про которые я рассказывал, желательно знать и использовать — тогда времени, которое вы тратите на поиск проблем, потребуется гораздо меньше.
Полезные ссылки
Алексей Лесовский (@lesovsky) на Highload++ 2017 рассказал, как с помощью встроенных и сторонних инструментов, диагностировать различные типы проблем и как устранять их. Под катом расшифровка этого доклада, построенного по спиральному принципу: сначала мы перечислим все возможные средства диагностики, потом перейдем к перечислению типовых проблем и их диагностике, далее посмотрим, какие экстренные меры можно принять, и наконец как радикально справиться с задачей.
О спикере: Алексей Лесовский администратор баз данных в компании Data Egret. Одной из любимых тем Алексея в PostgreSQL является потоковая репликация и работа со статистикой, поэтому доклад на Highload++ 2017 был посвящен тому, как помощью статистики искать проблемы, и какие использовать методы для их устранения.
План
- Немного теории, или как работает репликация в PostgreSQL
- Troubleshooting tools или что есть у PostgreSQL и сообщества
- Troubleshooting cases:
- проблемы: их симптомы и диагностика
- решения
- меры, которые нужно принимать, чтобы этих проблем не возникало.
Зачем всё это? Эта статья поможет вам лучше разбираться в потоковой репликации, научиться быстро находить и устранять проблемы, чтобы сократить время реакции на неприятные инциденты.
Немного теории
В PostgreSQL есть такая сущность, как Write-Ahead Log (XLOG) — это журнал транзакций. Почти все изменения, которые происходят с данными и метаданными внутри базы данных, записываются в этом журнале. Если вдруг произошла какая-то авария, PostgreSQL запускается, читает журнал транзакций и восстанавливает записанные изменения на данных. Так обеспечивается надежность — одно из важнейших свойств любой СУБД и PostgreSQL в том числе.
Журнал транзакций может заполнятся двумя способами:
- По умолчанию, когда бэкенды делают какие-то изменения в базе (INSERT, UPDATE, DELETE и т.д.), все изменения фиксируются в журнале транзакций синхронно:
- Клиент отправил команду COMMIT на подтверждение данных.
- Данные фиксируются в журнале транзакций.
- Как только фиксация произошла, управление отдается бэкенду, и он может дальше принимать команды от клиента.
- Клиент отправил команду COMMIT на подтверждение данных.
- Второй вариант — это асинхронная запись в журнал транзакций, когда отдельный выделенный процесс WAL writer с определенным интервалом времени пишет изменения в журнал транзакций. За счет этого достигается увеличение производительности бэкендов, поскольку не нужно ждать, когда завершится команда COMMIT.
Самое важное то, что потоковая репликация основана на этом журнале транзакций. У нас есть несколько участников потоковой репликации:
- мастер, где происходят все изменения;
- несколько реплик, которые принимают журнал транзакций от мастера и воспроизводят все эти изменения на своих локальных данных. Это — потоковая репликация.
Стоит помнить, что все эти журналы транзакций, хранятся в каталоге pg_xlog в $DATADIR — каталоге с основными файлами данных СУБД. В 10-й версии PostgreSQL этот каталог был переименован в pg_wal/, потому что нередки случаи когда pg_xlog/ занимает много места, и разработчики или администраторы, по незнанию путая его с логами, беспечно удаляют и становится все плохо.
В PostgreSQL есть несколько фоновых служб которые задействованы в потоковой репликации. Посмотрим на них с точки зрения операционной системы.
- Со стороны мастера — WAL Sender process. Это процесс, который отправляет журналы транзакций репликам, на каждую реплику будет свой WAL Sender.
- На реплике в свою очередь запущен WAL Receiver process, который по сетевому соединению от WAL Sender принимает журналы транзакций и передает их Startup process.
- Startup process читает журналы и воспроизводит на каталоге с данными все те изменения, которые записаны в журнале транзакций.
Схематично это выглядит примерно так:
- В WAL Buffers записываются изменения, которые потом будут записаны в журнал транзакций;
- Журналы находятся в хранилище (Storage) в каталоге pg_wal/;
- WAL Sender читает из хранилища журнал транзакций и передает их по сети;
- WAL Receiver принимает и сохраняет у себя в Storage — в локальном для себя pg_wal/;
- Startup Process читает все, что принято, и воспроизводит.
Схема простая. Потоковая репликация работает довольно надежно и много лет прекрасно эксплуатируется.
Troubleshooting tools
Посмотрим, какие средства и утилиты предлагает сообщество и PostgreSQL для того, чтобы расследовать проблемы, возникающие с потоковой репликацией.
Сторонние инструменты
Начнем со сторонних инструментов. Это утилиты довольно универсального плана, ими можно пользоваться не только при расследовании инцидентов, связанных с потоковой репликацией. Это вообще утилиты любого системного администратора.
- top из пакета procps. В качестве замены top можно использовать любые утилиты типа atop, htop и подобные им. Они предлагают похожую функциональность.
С помощью top смотрим: утилизацию процессоров (CPU), среднюю нагрузку (load average) и использование памяти и области подкачки.
- iostat из пакета sysstat и iotop. Эти утилиты показывают утилизацию дисковых устройств и какое I/O создается процессами в операционной системе.
С помощью iostat смотрим: утилизацию хранилища, сколько iops в данный момент, какая пропускная способность (throughput) на устройствах, какие задержки при обработке запросов на I/O (latency). Эта довольно подробная информация берется из файловой системы procfs и предоставляется пользователю уже в наглядном виде.
- nicstat — это аналог iostat, только для сетевых интерфейсов. В этой утилите можно смотреть утилизацию интерфейсов.
С помощью nicstat смотрим: аналогично — утилизацию интерфейсов, какие-то ошибки, которые возникают на интерфейсах, пропускную способность — тоже очень полезная утилита.
- pgCenter — это утилита для работы только с PostgreSQL. Она показывает статистику PostgreSQL в top-подобном интерфейсе, и в ней также можно смотреть статистику, связанную с потоковой репликацией.
С помощью pgCenter смотрим: статистику по репликации. Можно смотреть лаг репликации, как-то оценивать его, и прогнозировать дальнейшие работы.
- perf — это утилита для более глубокого расследования причин «подземных стуков», когда в эксплуатации происходят непонятные проблемы на уровне кода PostgreSQL.
С помощью perf ищем: подземные стуки. Для полноценной работы perf c PostgreSQL, последний должен быть собран с debug символами, таким образом можно смотреть стек функций в процессах и какие функции занимают больше всего процессорного времени.
Все эти утилиты нужны, чтобы проверять гипотезы, возникающие при устранении неполадок — где и что тормозит, где и что нужно исправить, проверить. Эти утилиты помогают удостовериться, на правильном ли мы пути.
Встроенные средства
Что предлагает сам PostgreSQL?
Системные представления
Вообще средств для работы с PostgreSQL довольно много. Каждая компания-вендор, которая предоставляет поддержку PostgreSQL, предлагает свои средства. Но, как правило, эти средства основаны на внутренней статистике PostgreSQL. В этом плане PostgreSQL предоставляет системные представления (views), в которых можно делать различные select’ы и получать нужную информацию. То есть c помощью обычного клиента, как правило psql, мы можем делать запросы и смотреть, что происходит в статистике.
Существует довольно много системных представлений. Для того, чтобы работать с потоковой репликацией и исследовать проблемы, нам нужны лишь: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts, и вспомогательные pg_stat_activitу и pg_stat_archiver.
Их немного, но этого набора достаточно, чтобы проверить, нет ли каких-либо проблем.
Вспомогательные функции
С помощью вспомогательных функций можно брать данные из статистических системных представлений и преобразовывать их в более удобный для себя вид. Вспомогательных функций тоже всего несколько штук.
- pg_current_wal_lsn() (старый аналог pg_current_xlog_location()) — самая нужная функция, которая позволяет посмотреть текущую позицию в журнале транзакций. Журнал транзакций — это непрерывная последовательность данных. С помощью этой функции можно посмотреть последнюю точку, получить позицию, где сейчас журнал транзакций остановился.
- pg_last_wal_receive_lsn(), pg_last_xlog_receive_location() — это аналогичная функция вышеупомянутой, только для реплик. Реплика получает журнал транзакций, и можно посмотреть последнюю полученную позицию журнала транзакций;
- pg_wal_lsn_diff(), pg_xlog_location_diff() — другая полезная функция. Мы передаем ей две позиции из журнала транзакций, и она показывает diff — дистанцию между этими двумя точками в байтах. Эта функция всегда полезна для определения лага между мастером и репликами в байтах.
Полный список функций можно получить psql мета-командой: \df *(wal|xlog|lsn|location)*.
Ее можно набрать в psql и посмотреть все функции, которые содержат в себе wal, xlog, Isn, location. Таких функций будет порядка 20-30, и они тоже предоставляют различную информацию по журналу транзакций. Рекомендую ознакомиться.
Утилита pg_waldump
До версии 10.0 она называлась pg_xlogdump. Утилита pg_waldump нужна, когда мы хотим заглянуть в сегменты журнала транзакций, узнать какие ресурсные записи туда попали, и что PostgreSQL туда записал, то есть для более детального исследования.
В версии 10.0 все системные представления, функции и утилиты которые включали в себя слово xlog были переименованы. Все вхождения слов xlog и location были заменены соответственно на слова wal и lsn. Тоже самое было сделано и с каталогом pg_xlog который стал каталогом pg_wal.
Утилита pg_waldump просто декодирует содержимое XLOG сегментов в человеко-понятный формат. Можно посмотреть, какие так называемые ресурсные записи попадают в процессе работы PostgreSQL в журналы сегмента, какие индексы и heap-файлы были изменены, какая информация, предназначенная для stand-by, туда попала. Таким образом, очень много информации можно смотреть с помощью pg_waldump.
Но есть оговорка, которая написана в официальной документации: pg_waldump может показывать чуть-чуть неверные данные при работающем PostgreSQL (Can give wrong results when the server is running — что бы это не означало )
Можно воспользоваться командой:
pg_waldump -f -р /wal_10 \
$(psql -qAtX -с "select pg_walfile_name(pg_current_wal_lsn())")
Это аналог команды tail -f только для журналов транзакций. Эта команда показывает хвост журнала транзакций, которые прямо сейчас происходит. Можно запустить эту команду, она найдет последний сегмент с самой последней записью журнала транзакций, подключится к нему и начнет показывать содержимое журнала транзакций. Немного хитрая команда, но, тем не менее, она работает. Я часто ей пользуюсь.
Troubleshooting cases
Здесь мы рассмотрим самые частые проблемы, которые возникают в практике консалтеров, какие могут быть симптомы и как их диагностировать:
Лаги репликации — это наиболее частая проблема. Совсем недавно у нас была переписка с заказчиком:
— У нас сломалась репликация master-slave между двумя серверами.
— Обнаружил лаг 2 часа, запущен pg_dump.
— ОК, понятно. Какой у нас допустимый лаг?
— 16 часов в max_standby_streaming_delay.
— Что случится, когда этот лаг будет превышен? Взвоет сирена?
— Нет, прибьются транзакции, и накатка WAL возобновится.
Проблемы с лагами репликаций у нас бывают постоянно, и чуть ли не каждую неделю мы их решаем.
Распухание каталога pg_wal/, где хранятся сегменты журнала транзакций — это проблема, которая возникает реже. Но в этом случае необходимо предпринимать немедленные действия, чтобы проблема не превратилась в аварийную ситуацию, когда реплики отваливаются.
Долгие запросы, которые выполняются на реплике, приводят к конфликтам при восстановлении. Это ситуация, когда мы на реплику пускаем какую-то нагрузку, на репликах можно выполнять читающие запросы, и в этот момент эти запросы мешают воспроизведению журнала транзакций. Возникает конфликт, и PostgreSQL нужно решить, ждать завершение запроса или завершить его и продолжить воспроизведение журнала транзакций. Это конфликт репликации или конфликт восстановления.
Recovery process: 100% CPU usage —процесс восстановления журнала транзакций на репликах занимает 100% процессорного времени. Это тоже редкая ситуация, но она довольно неприятная, т.к. приводит к росту лага репликации и в целом её сложно расследовать.
Лаги репликации
Лаги репликации — это когда один и тот же запрос, выполненный на мастере и на реплике, возвращает разные данные. Это значит, что данные неконсистентны между мастером и репликами, и есть какое-то отставание. Реплике нужно воспроизвести часть журналов транзакций, чтобы догнать мастера. Основной симптом выглядит именно так: есть запрос, и они возвращают разные результаты.
Как искать такие проблемы?
- Есть основное представление на мастере и на репликах — pg_stat_replication. Оно показывает информацию по всем WAL Sender, то есть по процессам, которые занимаются отправкой журнала транзакций. Для каждой реплики будет отдельная строчка, которая показывает статистику именно по этой реплике.
- Вспомогательная функция pg_wal_lsn_diff() позволяет сравнивать разные позиции в журнале транзакций и вычислять тот самый лаг. С её помощью мы можем получить конкретные цифры и определить, где у нас большой лаг, где маленький и уже как-то отреагировать на проблему.
- Функция pg_last_xact_replay_timestamp() работает только на реплике и позволяет посмотреть время, когда была выполнена последняя проигранная транзакция. Есть всем известная функция now(), которая показывает текущее время, мы из функции now() вычитаем время, которое нам показывается функцией pg_last_xact_replay_timestamp() и получаем лаг во времени.
В 10 версии pg_stat_replication появились дополнительные поля, которые показывают временной лаг уже на мастере, поэтому этот способ уже устаревший, но, тем не менее, его можно использовать.
Есть небольшой подводный камень. Если на мастере долгое время нет транзакций, и он не генерирует журналы транзакций, то последняя функция будет показывать увеличивающийся лаг. На самом деле система просто простаивает, на ней нет никакой активности, но в мониторинге мы можем увидеть, что лаг растет. Про этот подводный камень стоит помнить.
Представление выглядит следующим образом.
Оно содержит информацию по каждому WAL Sender и несколько важных для нас полей. Это в первую очередь client_addr — сетевой адрес подключенной реплики (как правило, IP адрес) и набор полей lsn (в старых версиях он называется location), про них я расскажу чуть дальше.
В 10-й версии появились поля lag — это отставание, выраженное во времени, то есть более человеко-понятный формат. Лаг может выражаться либо в байтах, либо во времени — можно выбрать, что больше нравится.
Как правило, я пользуюсь таким запросом.
Это не самый сложный запрос, который выводит pg_stat_replication в более удобном, понятном формате. Здесь я использую следующие функции:
- pg_wal_lsn_diff(), чтобы считать diff’ы. Но между чем я считаю diff’ы? У нас есть несколько полей — sent_lsn, write_lsn, flush_lsn, replay_lsn. Высчитывая diff между текущим и предыдущим полем, мы можем точно понять, где у нас произошло отставание, где конкретно происходит лаг.
- pg_current_wal_lsn(), которая показывает текущую позицию журнала транзакций. Здесь мы смотрим расстояние между текущей позицией в журнале и отправленной — сколько журналов транзакций сгенерировано, но не отправлено.
- sent_lsn, write_lsn — это сколько отправлено реплике, но не записано. То есть это то, что сейчас находится где-то в сети, либо оно получено репликой, но еще не записано из сетевых буферов на дисковое хранилище.
- write_lsn, flush_lsn — это записано, но не было выпущено командой fsync — как бы записано, но может находиться где-нибудь в оперативной памяти, в page-cache операционной системы. Как только мы делаем fsync, данные синхронизируются с диском, попадают на персистентное хранилище и вроде бы все надежно.
- replay_lsn, flush_lsn — данные сброшены, выполнен fsync, но не воспроизведены репликой.
- current_wal_lsn и replay_lsn — это некий суммарный лаг, который включает в себя все предыдущие позиции.
Немного примеров
Выше цветом выделена реплика 10.6.6.8. У нее pending-лаг, она нагенерировала какие-то журналы транзакций, но они все еще не отправлены и лежат на мастере. Вероятнее всего, здесь какая-то проблема с сетевой производительностью. Мы будем это проверять с помощью утилиты nicstat.
Мы запустим nicstat, посмотрим утилизацию интерфейсов, нет ли там проблем и ошибок. Так мы сможем проверить эту гипотезу.
Выше отмечен write лаг. На самом деле этот лаг довольно редкий, я практически не вижу, чтобы он был большим. Проблема может быть с дисками, и мы используем утилиту iostat или iotop — смотрим утилизацию дисковых хранилищ, какой I/O создается процессами, и дальше уже выясняем, почему.
Flush и replay Лаги — чаще всего лаг бывает именно там, когда дисковое устройство на реплике не успевает просто проиграть все те изменения, которые прилетают с мастера.
Также утилитами iostat и iotop мы смотрим, что происходит с дисковой утилизацией и почему тормоза.
И последний total_lag — полезная метрика для систем мониторинга. Если у нас порог total_lag превышен, в мониторинге поднимается флажок, и мы начинаем расследовать, что же там происходит.
Проверка гипотезы
Теперь нужно разобраться, как дальше исследовать ту или иную проблему. Я уже сказал, если это сетевой лаг, то нужно проверить, все ли у нас в порядке с сетью.
Сейчас практически все хостеры предоставляют 1 Гб/с или даже 10 Гб/с, поэтому забитая полоса пропускания — это самый маловероятный сценарий. Как правило, нужно смотреть на ошибки. nicstat содержит информацию по ошибкам на интерфейсах, можно разобраться, что там — проблемы с драйверами, либо с самой сетевой картой, либо с кабелями.
Проблемы в хранилище мы исследуем с помощью iostat и iotop. iostat нужен для просмотра общей картины, связанной с дисковыми хранилищами: утилизация устройств, пропускная способность устройств, latency. iotop — для более точных исследований, когда нам нужно выявить, какой из процессов грузит дисковую подсистему. Если это какой-то сторонний процесс, его можно просто обнаружить, завершить и, возможно, проблема исчезнет.
Задержки восстановления и конфликты репликации мы прежде всего смотрим через top или pg_stat_activity: какие процессы запущены, какие запросы работают, время их выполнения, как долго они работают. Если это какие-то долгие запросы, мы смотрим, почему они долго работают, отстреливаем их, разбираемся и оптимизируем их — исследуем уже сами запросы.
Если это большой объем журналов транзакций, который генерируется мастером, мы можем это обнаружить по pg_stat_activity. Может быть, там какие-то бэкапные процессы запущены, запущены какие-то вакуумы (pg_stat_progress_vacuum), либо выполняется checkpoint. То есть если генерируется слишком большой объем журналов транзакций, и реплика просто не успевает его обработать, в какой-то момент она может просто отвалиться, и это будет уже проблемой для нас.
И конечно pg_wal_lsn_diff() для определения лага и определения, где у нас конкретно лаг находится — в сети, на дисках, либо на процессорах.
Варианты решения
Проблемы на уровне сети/хранения
Тут довольно все просто, но с точки зрения конфигурации это, как правило, не решается. Можно подкрутить некоторые гайки, но в целом есть 2 варианта:
- Проверить workload
Проверяем какие выполняются запросы. Может быть, запущены какие-то миграции, которые генерируют много журналов транзакций, либо это может быть перенос, удаление или вставка данных. Любой процесс, который генерирует журналы транзакций, может приводить к лагу транзакций. Все данные на мастере генерируются как можно быстрее, мы внесли изменение данных, отправили на реплику, а справится реплика или не справится — это уже мастера не волнует. Здесь может появиться лаг и нужно что-то с ним делать.
- Upgrade hardware
Самый тупой вариант — возможно, мы уперлись в производительность железа, и нужно его просто менять. Это могут быть старые диски либо некачественные SSD, либо затык в производительности RAID контроллера. Здесь мы исследуем уже не саму базу, а проверяем производительность наших железок.
Задержки восстановления
Если у нас возникли какие-то конфликты репликации из-за долгих запросов в результате чего увеличивается replay lag, мы первым делом отстреливаем долгие запросы, которые работают на реплике, потому что они задерживают воспроизведение журналов транзакций.
Если долгие запросы связаны с неоптимальностью самого SQL запроса (выясняем это с помощью EXPLAIN ANALYZE), нужно просто подходить по-другому к этому запросу и переписывать его. Либо есть вариант настройки отдельной реплики для отчетных запросов. Если мы делаем какие-то отчеты, которые долго работают, их нужно выносить на отдельную реплику.
Еще остается вариант просто ждать. Если у нас какой-то лаг на уровне нескольких килобайт или даже десятков мегабайт, но мы считаем, что это приемлемо, мы просто ждем, когда запрос выполнится и лаг сам рассосется. Это тоже вариант, и часто бывает, что он приемлем.
Большой объем WAL
Если мы генерируем большой объем журнала транзакций, нужно уменьшить этот объем в единицу времени, сделать так, чтобы реплике было нужно прожевывать меньше журналов транзакций.
Как правило, это делается с помощью конфигурации. Частичное решение в задании параметра full_page_writes = off. Этот параметр выключает/выключает запись полных образов изменяющихся страниц в журнал транзакций. Это означает, что, когда у нас произошла служебная операция записи контрольной точки (CHECKPOINT), при последующем изменении какого-то блока данных в области shared buffers, в журнал транзакций уйдет полный образ этой страницы, а не только само изменение. При всех последующих изменениях этой же самой страницы, в журнал транзакций будут попадать только изменения. И так до следующей контрольной точки.
После чекпоинта мы записываем полный образ страницы, и это сказывается на объеме записываемого журнала транзакций. Если чекпоинтов в единицу времени довольно много, допустим, в час делается 4 чекпоинта, и полных образов страниц будет записываться тоже очень много, это будет проблемой. Можно отключить запись полных образов и это скажется на объеме WAL. Но опять же это полумера.
Примечание: К рекомендации отключения full_page_writes, стоит отнестись вдумчиво, так как автор в ходе доклада забыл уточнить, что отключение параметра может, при некотором стечение обстоятельств в аварийных ситуациях (повреждение файловой системы или ее журнала, частичная запись в блоки и т.п.) потенциально привести к повреждению файлов базы данных. Поэтому будьте внимательны, отключение параметра может увеличить риск повреждения данных в аварийных ситуациях.
Другая полумера — это увеличить интервал между чекпоинтами. По умолчанию чекпоинт делается каждые 5 минут, и это довольно часто. Как правило, этот интервал увеличивают до 30–60 минут — это вполне приемлемое время, за которое все грязные страницы успевают стать синхронизированными на диск.
Но основной вариант решения — это, конечно же, посмотреть наш workload — какие там сейчас идут тяжелые операции, связанные с изменением данных, и, возможно, постараться эти операции по изменению делать пачками.
Допустим, у нас есть таблица, мы хотим удалить из нее несколько миллионов записей. Оптимальным вариантом будет не удалять эти миллионы разом одним запросом, а разбить их на пачки по 100–200 тысяч, чтобы, во-первых, генерировались небольшие объемы WAL, во-вторых, vacuum успевал проходить по удаленным данным, и следовательно лаг не был таким большим и критичным.
Распухание pg_wal/
Теперь, давайте поговорим, как можно обнаружить, что распух каталог pg_wal/.
По идее PostgreSQL всегда поддерживает его в оптимальном для себя состоянии на уровне определенных файлов конфигурации, и, как правило, он не должен расти выше определенных пределов.
Есть параметр max_wal_size, который определяет максимальное значение. Плюс есть параметр wal_keep_segments — дополнительное количество сегментов, которые мастер хранит для реплики, если вдруг реплика недоступна продолжительное время.
Посчитав сумму max_wal_size и wal_keep_segments, мы можем примерно оценить, сколько места будет занимать каталог pg_wal/. Если он быстро растет и занимает гораздо больше места, чем рассчитанное значение, это значит, что есть какая-то проблема, и нужно с этим что-то делать.
Как обнаружить такие проблемы?
В операционной системе Linux есть команда du -csh. Мы можем просто в мониторинг загнать значение и смотреть, сколько у нас там журналов транзакций; держать посчитанную метку, сколько он должен и сколько он по факту занимает, и как-то реагировать на изменение цифр.
Другое место, где мы смотрим, это представления pg_replication_slots и pg_stat_archiver. Наиболее частыми причинами, почему pg_wal/ занимает много места являются забытые слоты репликации или сломанная архивация. Другие причины также имеют место быть, но на моей практике встречались очень редко.
И, конечно же, всегда бывают ошибки в логах PostgreSQL, связанные именно с архивной командой. Других причин, которые связаны с переполнением pg_wal/, там, к сожалению, не будет. Мы можем там отловить только ошибки архивации.
Варианты проблем:
Тяжелый CRUD — тяжелые операции обновления данных — тяжелые INSERT, DELETE, UPDATE, связанные с изменением нескольких миллионов строк. Если PostgreSQL нужно сделать такую операцию, понятно, что будет генерироваться большой объем журнала транзакций. Он будет храниться в pg_wal/, и это приведет к увеличению занимаемого места. То есть опять же, как я сказал раньше, хорошей практикой является просто разбивать их на пачки, и делать обновление не всего массива, а по 100, 200, 300 тысяч.
Забытый или неиспользуемый слот репликации — другая частая проблема. Люди часто используют логическую репликацию для каких-то своих задач: настраивают шины, которые отправляют данные в Kafka, отправляют данные в стороннее приложение, которое делает декодинг логической репликации в другой формат и как-то их обрабатывают. Логическая репликация, как правило, работает через слоты. Бывает так, что мы настроили слот репликации, поигрались с приложением, поняли, что нам это приложение не подходит, выключили приложение, удалили, а слоты репликации продолжают жить.
PostgreSQL для каждого слота репликации сохраняет сегменты журнала транзакций на случай, если удаленное приложение или реплика снова подключатся к этому слоту, и тогда мастер сможет ему эти журналы транзакций отдать.
Но идет время, к слоту никто не подключается, журналы транзакций копятся, и в какой-то момент занимают 90% места. Нужно выяснять, что же там такое, почему занято так много места. Как правило, этот забытый и неиспользуемый слот нужно просто удалить, и проблема будет решена. Но об этом чуть дальше.
Другим вариантом может быть сломанная archive_command. Когда у нас есть какое-то внешнее хранилище журналов транзакций, которое мы держим для задач аварийного восстановления, обычно настраивается архивная команда, реже настраивается pg_receivexlog. Команда прописанная в аrchive_command — это очень часто, либо отдельная команда, либо какой-то скрипт, который берет сегменты журнала транзакций из pg_wal/ и копирует в архивное хранилище.
Бывает так, что провели какой-то апгрейд системных пакетов, допустим, в rsync версия поменялась, флаги обновились или изменились, либо в какой-то другой команде, которая использовалась в архивной команде, тоже поменялся формат — и скрипт или сама программа которая указана в archive_command ломается. Следовательно архивы перестают копироваться.
Если архивная команда отработала с выходом не 0, то в лог запишется сообщение об этом, а сегмент останется в каталоге pg_wal/. Пока мы не обнаружим, что у нас архивная команда сломалась, сегменты будут копиться, и место также в какой-то момент закончится.
Набор экстренных мер (100% used space):
??1. Отстрелить все долгие CRUD запросы, которые выполняются на данный момент на мастере — pg_terminate_backend().
Это могут быть какие-то копии запросов, выполняющиеся бэкапы, апдейты, которые обновляют миллион строк и т.д. Первым делом нам нужно отстрелить эти запросы, чтобы предотвратить дальнейший рост каталога pg_wal/, чтобы новые сегменты не генерировались.
??2. Уменьшить так называемое резервируемое место для файлов пользователя root — reserved space ratio (ext filesystems).
Это относится к файловым системам семейства ext и по умолчанию файловая система ext создается с резервным местом 5%. Представьте себе, что у вас файловая система на несколько сотен гигабайт, и 5% — довольно значительно. Поэтому, когда мы видим, что у нас остался 1% свободного места, мы быстро делаем команду tune2fs -m 1. Резервное место сразу становится доступным пользователю PostgreSQL и появляется время для того, чтобы исследовать проблему дальше. Таким образом есть мы откладываем 100% лимит заполненности на некоторое время.
??3. Добавить еще места (LVM, ZFS,...).
В случае использования LVM или ZFS, когда администратор резервирует свободное место в пуле LVM или ZFS, он может из этого резервного пула выделить свободное дополнительное место на том, где лежит база, и опять же с помощью команды файловой системы растянуть файловую систему. Таким методом можно экстренно отреагировать на то, что место заканчивается.
??4. И самое главное — НИКОГДА, НИЧЕГО, HE УДАЛЯТЬ РУКАМИ ИЗ pg_wal/.
Об этом говорят все постгресисты на всех конференциях и докладах, но люди все равно удаляют, удаляют и удаляют, а базы ломаются. Никогда ничего оттуда удалять нельзя! PostgreSQL сам оттуда периодически удаляет файлы, когда считает нужным. У него есть свои функции, свои алгоритмы, он сам определяет, когда это нужно сделать.
Кстати, pg_xlog/ переименовали в pg_wal/ именно по той причине — слово log сбивает с толку администраторов, и они думают, что, наверное, там какие-то ненужный логи — удалим их!
Что делать дальше
После того, как мы приняли экстренные меры и отложили наступление 100% заполнение CPU, можно перейти к устранению источников проблем.
Сначала нужно проверить workload и миграции. Что у нас там, что команда разработки запустила на этот раз? Может быть, они там хотели обновить какие-то данные, сделать загрузку данных или еще что-то. И на основании этого уже можно принимать архитектурное решение: добавить дополнительный диск, добавить новый tablespace, перенести данные между tablespace.
Дальше проверяем состояние репликации. Если у нас сгенерировалось много журналов транзакций, вполне вероятно, что мог образоваться лаг, и если образовался лаг, то, вполне возможно, что реплика не успела прожевать все журналы транзакций и могла попросту отвалиться. Нужно проверить реплики — все ли с ними в порядке.
Дальше нужно проверить настройки checkpoints_segments/max_wal_size, wal_keep_segments. Вполне возможно, что при конфигурации система, были выбраны слишком большие значения — 10-20 тысяч для wal_keep_segments, либо десятки гигабайт для max_wal_size. Может быть, есть смысл пересмотреть эти настройки и уменьшить их. Тогда PostgreSQL необходимые сегменты просто удалит и каталог pg_wal/ станет меньше.
Нужно проверить слоты репликации через представление pg_replication_slots — нет ли там неактивных слотов. Если они есть, то нужно проверить подписчика, который должен быть подписан на этот слот — все ли с ним в порядке. Если подписчика нет, он был давно удален, нужно слот просто удалить. Тогда проблема легко решается.
Если ошибки связаны с архивированием WAL, мы можем посмотреть эти ошибки в логе, либо посмотреть счетчик ошибок в pg_stat_archiver, там все это есть. Конечно, нужно починить архивную команду, разобраться, почему она не работает, и архивация не происходит.
После всех мер желательно вызывать команду checkpoint. Именно в этой команде зашита функция определения, какие сегменты журнала транзакций уже не нужны постгресу, и он может их спокойно удалить. Подчеркиваю, PostgreSQL сам определяет эти сегменты и сам их удаляет. Ничего не удаляем руками, только через команду checkpoint.
Долгие запросы и конфликты при восстановлении
Как я уже говорил, конфликты при восстановлении, конфликты репликации — это когда выполняющийся запрос на реплике выполняется долго. Он запросил какие-то данные и в этот момент с мастера прилетает изменение этих же самых данных, и репликация входит в конфликт с запросом. И вроде бы запрос нужно продолжить, но и эти данные на реплике тоже нужно изменить.
Основные симптомы — ошибки в логах PostgreSQL или приложения:
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
Первые 2 пункта — это наиболее частые причины, когда запрос идет именно на те данные, которые должны быть обновлены по репликации. Происходит следующий сценарий: есть параметр, который определяет задержку, которая будет отсчитываться при обнаружении конфликта. Как только эта задержка превысила заданный порог (по умолчанию 30 с), то PostgreSQL завершает запрос и репликация продолжает восстанавливать данные — все супер.
Следующая проблема возникает реже. Как правило, она связана с тем, что репликация с мастера передаёт некоторую информацию о блокировках на мастере в реплику. Если выполняющиеся запросы как-то конфликтуют с этими блокировками, то запрос также через timeout отстреливается и возникает эта ошибка. Такое бывает на миграциях — когда мы делаем ALTER, добавляем индексы в таблицы, такая ошибка может возникать.
Следующие ошибки возникают еще реже. Они обычно связаны с тем, что tablespace или база удалена на мастере, а запрос был запущен и работал с данными этой базы или tablespace. Это возникает редко, и обычно все знают, когда кто-то удаляет базу — мне так кажется.
Как обнаружить?
Для обнаружения у нас есть представления pg_stat_databases, pg_stat_databases_conflicts. В этих представлениях у нас есть информация о конфликтах, и их нужно мониторить. Если у нас есть конфликты, мы начинаем разбираться дальше.
Это действительно становится проблемой, если запросы отстреливаются по конфликту репликации очень часто. Мы считаем, что запросы очень важны нашим пользователям. Пользователи начинают страдать, и это уже проблема. Либо, когда возникает большой лаг репликации вследствие того, что запрос держит репликацию, и это тоже проблема.
Что делать?
Есть несколько вариантов, но все они — выбор наименьшего из зол:
- Увеличить max_standby_streaming_delay (риск лага репликации). Это именно та самая задержка, которая будет отсчитываться при обнаружении конфликта репликации. Тем самым мы увеличиваем риск лага репликации.
- Включить hot_staпdby_feedback (риск распухания таблиц/индексов). Это вариант, когда vacuum нужно почистить какие-то строки, но эти строки пользуются транзакцией на реплике. В этом случае есть риск bloat таблицы индексов. Это тоже одно из зол, которое нужно либо принять, либо понять, нужно включать hot_staпdby_feedback или нет.
- Самый просто вариант для DBA и непростой для разработчика — это переписать долгие запросы. Нужно проверить все запросы, которые выполняются на реплике. Может быть, они написаны не оптимально, для них нет соответствующих индексов, и можно как-то их переписать и пересмотреть, добавить индексы.
- Последний вариант, который, как правило, устраивает и разработчика, и DBA — это настроить выделенную реплику для долгих запросов, например, для отчетных. В таком случае max_standby_streaming_delay задирается максимально. Такая реплика может выполнять долгие отчетные запросы, которые работают часами. При этом она может накапливать лаг, но то, что эта реплика отстает, всех устраивает. Это компромиссный для всех вариант — и отчетные запросы работают, и лаг никому не мешает.
Recovery process: 100% CPU usage
Бывает так, что процесс, который накатывает журнал транзакций, использует 100% ресурсов одного ядра. Он однопоточный, сидит только на одном ядре процессора, и полностью утилизирует его на 100%. Как правило, если посмотреть в pg_stat_replication, можно увидеть, что там большой лаг replay, то есть очень много данных нужно воспроизвести, и реплика не успевает.
Обнаруживаем это через:
- top — это очень быстро и легко проверяется — вы просто увидите 100% CPU usage на recovery process;
- pg_stat_replication — в мониторинге, если он настроен, мы это все быстро увидим.
Что и как искать
Это одна из самых нетривиальных проблем, алгоритмов поиска не сформировано. Как правило, мы прибегаем к использованию утилит:
- perf top/record/report (требуются debug—пакеты);
- GDB;
- Реже pg_waldump.
Нужно посмотреть, какой стек функций, и где функции тратят больше всего времени. Типичным примером может быть workload, связанный с созданием и удалением временных либо обычных таблиц на мастере. Такое бывает, и чтобы удалить таблицу, PostgreSQL нужно просканировать все имеющиеся shared buffers и ссылки на эту таблицу удалить (очень упрощенно). Это довольно трудоемкая операция при воспроизведении журнала транзакций.
Решение
Как решать такие проблемы, тоже не всегда очевидно и зависит от результатов расследования. Где-то можно поменять workload, что-то поправить, где-то нужно написать патч разработчикам: «Я поковырялся в исходном коде и обнаружил, что то-то не оптимально».
Это можно писать в списках рассылки pgsql-hackers, pgsql-bugs, постить и ждать, когда разработчики отреагируют. К счастью, обычно это происходит быстро.
Но еще раз повторюсь — каких-то гарантированных решений здесь, к сожалению, нет.
Итоги
Проблемы потоковой репликации всегда распределены между хостами. Это значит, что причины проблем нужно искать на нескольких узлах и быть готовым к тому, что это распределенная проблема, которая находится не на одном узле.
Источниками проблем часто бывает пользовательская нагрузка. Я имею в виду, что, как правило, источником проблем являются запросы, которые генерирует приложение, и реже — оборудование.
Конечно же, нужно использовать мониторинг, без него — никуда. Добавьте нужные счетчики, которые я упоминал, в мониторинг, и тогда время реакции на проблему будет гораздо меньше.
Встроенные средства, про которые я рассказывал, желательно знать и использовать — тогда времени, которое вы тратите на поиск проблем, потребуется гораздо меньше.
Полезные ссылки
- PostgreSQL official documentation — The Statistics Collector
- PostgreSQL Mailing Lists ( general, performance, hackers)
- PostgreSQL-Consulting company blog
В этом году мы запланировали две конференции для разработчиков высоконагруженных систем и ближайшая, Highload++ Siberia, пройдет уже 25 и 26 июня в Новосибирске. Судя по заявкам, она обещает быть даже круче, чем московская.
- Владислав Клименко и Валерий Панов представят утилиту репликации данных из MySQL в ClickHouse.
- Иван Шаров и Константин Полуэктов расскажут, какие проблемы возникают при миграциях продукта на новые версии базы данных Oracle.
- Николай Голов расскажет как можно реализовать транзакции, если деньги в одном сервисе, услуги — в другом, и у каждого сервиса своя изолированная база.
- Юрий Насретдинов подробно объяснит, для чего VK нужен ClickHouse, сколько хранится данных, и многое другое.
SergeyMax
За запросы в виде картинок — отдельное спасибо!)
Melkij
С презентации можно копировать, хотя конечно в самой статье прямая ссылка бы не помешала