
Этот блог обычно посвящен распознаванию автомобильных номеров. Но, работая над этой задачей, мы пришли к интересному решению, которое можно с легкостью применять для очень широкого круга задач компьютерного зрения. Об этом сейчас и расскажем: как делать систему распознавания, которая вас не подведет. А если подведет, то ей можно подсказать, где ошибка, переобучить и иметь уже чуть более надежное решение, чем прежде. Добро пожаловать под кат!

Представьте, перед Вами встала задача: найти на фотографии пиццу и определить, что это за вид пиццы.
Давайте коротко пройдемся тем стандартным путем, которым мы часто ходили. Зачем? Чтобы понять, как делать… не надо.
Шаг 1: наберем базу

Шаг 2: для надежности распознавания можно отметить что есть пицца, а что фон (так включим сегментационную нейронную сеть в процедуру распознавания, но оно часто того стоит):

Шаг 3: приведем ее в “нормализованный вид” и классифицируем с помощью еще одной сверточной нейронной сети:

Отлично! Теперь у нас есть обучающая база. В среднем размер обучающей базы может быть несколько тысяч изображений.
Берем 2 сверточные сети, например, Unet и VGG. Первая обучается на входных изображениях, затем нормализуем изображение и обучаем VGG для классификации. Отлично работает, передаем заказчику и считаем честно заработанные деньги.
К сожалению, почти никогда. Есть несколько серьезных проблем, которые возникают при внедрении:
В итоге, многим, кто руками потрогал всю эту механику, становится ясно, что все должно происходить совсем иначе. Примерно так:
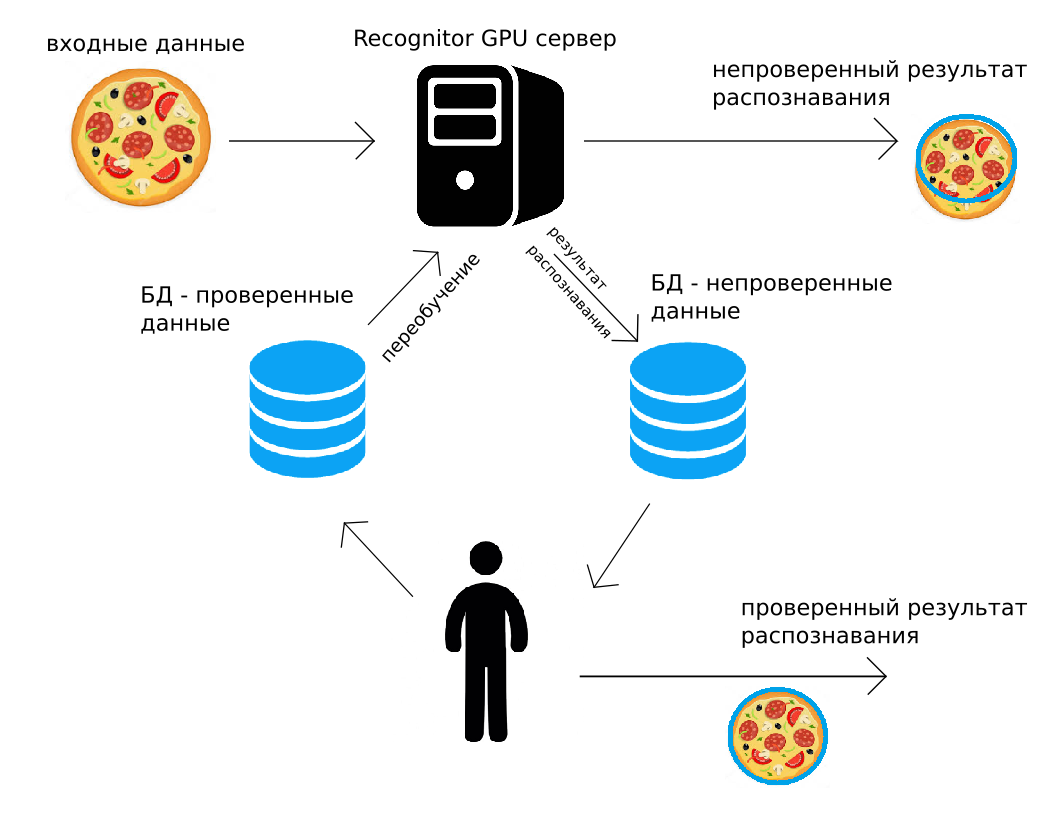
На наш сервер приходят данные (по http POST, либо с помощью Python API), GPU сервер распознает их “как смог”, сразу возвращая результат. Попутно этот же результат распознавания вместе с изображением складывается в архив. Человек потом контролирует все данные или случайную их часть, поправляет. Исправленный результат кладется во второй архив. А затем, когда это будет удобно сделать (например, ночью), переобучаются все использованные для распознавания сверточные нейронные сети, используя те данные, что поправил человек.
Такое замыкание распознавания, супервайзинг человеком и дообучение решают многие из перечисленных выше проблем. Кроме того, в тех решениях, где нужна высокая точность, можно использовать проверенные человеком выходные данные. Кажется, что это использование проверенных человеком данных слишком затратно, но дальше мы покажем, что это почти всегда имеет экономический смысл.
Мы реализовали описанный принцип и успешно его применяем уже на нескольких реальных задачах. Одна из них — распознавание номера на снимках контейнеров в ЖД терминалах, снятых с планшета. Это достаточно удобно — навести планшет на контейнер, получить распознанный номер и оперировать с ним в программе планшета.
Типичный пример снимка:

На снимке номер почти идеальный, лишь много визуального шума. Но случаются жесткие тени, снег, неожиданные компоновки надписей, серьезные наклоны или перспектива при съемке.
И вот так выглядит набор интернет-страницы, на которых вся “магия” и происходит:
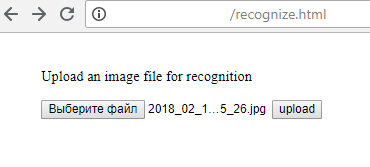
1) Отправка файла на сервер (конечно, это же можно сделать не с html страницы, а с помощью Python или любого другого языка программирования):
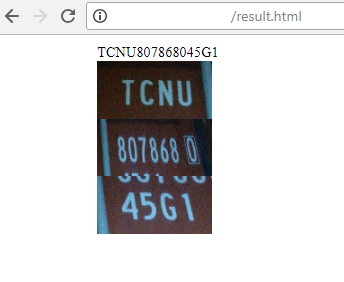
2) Сервер возвращает результат распознавания:
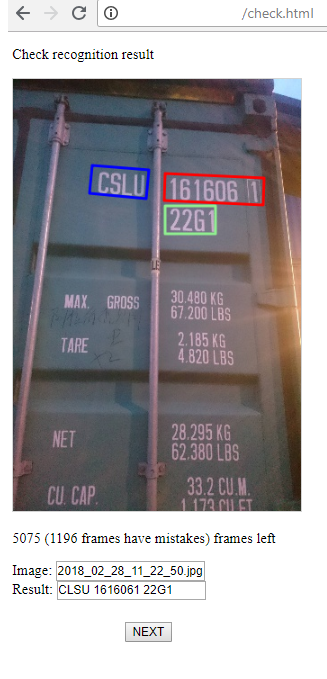
3) А это страница для оператора, который контролирует успешность распознавания, и при необходимости поправляет результат. Здесь есть 2 стадии: поиск областей групп символов, их распознавание. Все это оператор может исправить, если видит ошибку.
4) Тут простая страница, где можно запустить обучение каждой из стадий распознавания, и, запустив, видеть текущий loss.
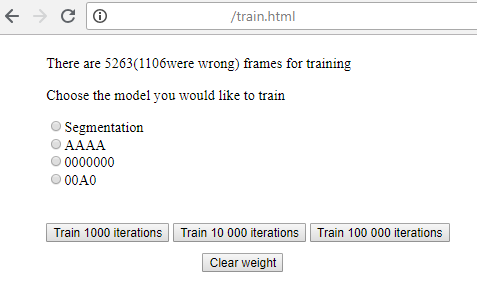
Суровый минимализм, зато прекрасно работает!
Как это может выглядеть со стороны компании, задумавшей воспользоваться описанным подходом (или нашим опытом и серверами Recognitor)?
Тема замкнутого цикла не нова. Множество компаний предлагают системы работы с данными того или иного типа. Но парадигма работы может быть выстроена совершенно различным образом:
Пожалуй, 70% задач автоматизируются таким образом. Самые подходящие задачи — разнообразные распознавания областей, содержащих текст. Например, автомобильные регистрационные знаки, про которые мы уже рассказывали, номера поездов (вот наш пример двухлетней давности), надписи на контейнерах.

Много символьной технической информации распознается на заводах для учета продукции и ее качества.
Очень помогает такой подход при распознавании продуктов на полках магазинов и ценников, хотя там довольно сложные решения распознавания приходится создавать.

Но, можно отвлечься от задач с технической информацией. Любая семантика, будь то instance segmentation, с детектированием автомобилей, архаров, лосей и морских котиков тоже отлично ляжет на такой подход.

Очень перспективное направление — поддерживать общение с людьми в голосовых и текстовых чат-ботах. Там будет довольно непривычный способ разметки: контекст, тип фразы, ее “наполнение”. Но принцип тот же: работаем в автоматическом режиме, человек контролирует корректность понимания и ответов. Можно прибегать к помощи оператора в случае недовольного или раздраженного тона клиента. По мере накопления данных переобучаем.
Если у Вас или внутри Вашей компании сложились необходимые компетенции (немного опыта в Machine Learning, работы с зоопарком Framework-ов, как offline, так и online), то не возникнет сложности с решением простых задач компьютерного зрения: сегментация, классификация, распознавание текста и др.
А вот для видео все не столь гладко. Как вообще разметить эти бесконечные объемы данных? Например, может оказаться, что раз в несколько секунд в кадре появляется объект (или несколько объектов), которые нужно размечать. В итоге все это может превратиться в покадровый просмотр и занимает столько ресурсов, что о дополнительном контроле человеком после запуска решения даже не приходится говорить. Но и это можно преодолеть, если представить видео в правильном виде для того, чтобы выделить кадры с областью интереса.
Например, мы столкнулись с огромными видео-рядами, в которых нужно было выделить единичный специфический объект — сцепку ЖД платформ. И это было действительно непросто. Оказалось, что все не так страшно, если взять монитор пошире, выбрать частоту кадров, например 10FPS и разместить 256 кадров на одном изображении, т.е. 25,6с в одном изображении:

Наверное, выглядит это пугающе. Но на деле нужно около 15с, чтобы прощелкать все до единого кадра, выбрав центр сцепки вагона на кадре. И даже один человек за день или два может разметить не менее 10 часов видео. Получится более 30 тысяч примеров для обучения. Кроме того, проезд платформ перед камерой в этом случае не постоянный процесс (а довольно редкий, нужно отметить), то вполне реально даже почти в реальном времени поправлять машину распознавания, пополняя обучающую базу! А если распознавание происходит в большинстве случаев верно, то час видео можно преодолеть за пару минут. И тогда пренебрегать тотальным контролем со стороны человека, как правило, экономически не выгодно.
Все еще облегчается, если на видео нужно отметить “да/нет”, а не локализацию объекта. Ведь события часто “слеплены”, и одним взмахом мышки можно отмечать до 16 кадров за раз.
Единственное, как правило, приходится использовать 2 стадии при анализе видео: поиск “кадров или области интереса”, а затем уже работа с каждым таким кадром (или последовательностью кадров) другими алгоритмами.
Насколько можно оптимизировать стоимость обработки визуальных данных? Так или иначе строго обязательно иметь человека для контроля распознавания данных. Если этот контроль выборочный, то тут затраты незначительные. Но если мы говорим о тотальном контроле, то насколько это может быть выгодно? Оказывается, что это имеет смысл почти всегда, если прежде эту же самую задачу человек выполнял без помощи машины.
Возьмем не самый лучший пример, приведенный в самом начале: поиск пиццы на изображении, разметка и выбор типа (а в реальности и ряда других характеристик). Хотя, задача не столь синтетическая, насколько это может показаться. Контроль внешнего вида продуктов сетей франшизы в реальности и правда существует.
Предположим, что для распознавания с помощью GPU сервера нужно 0.5с машинного времени, для полной разметки кадра человеком около 10с (выбрать тип пиццы и ее качество по ряду параметров), а для того, чтобы проверить, все ли верно определено компьютером, понадобится 2с. Конечно, здесь будет вызов в том, как удобно представить эти данные, но такие времена вполне сопоставимы с нашей практикой.
Нужны еще некоторые вводные по стоимости ручной разметки и аренды GPU сервера. Рассчитывать на полную загрузку сервера, как правило, не приходится. Пусть удастся добиться загрузки 100 000 кадров в день (займет 60% вычислительной мощности одного GPU) при ориентировочной стоимости месячной аренды сервера 60 000р. Выходит 2 копейки за анализ одного кадра на GPU. А анализ ручной при затратах 30 000р на 40 часов рабочего времени будет стоить 26 копеек за кадр.
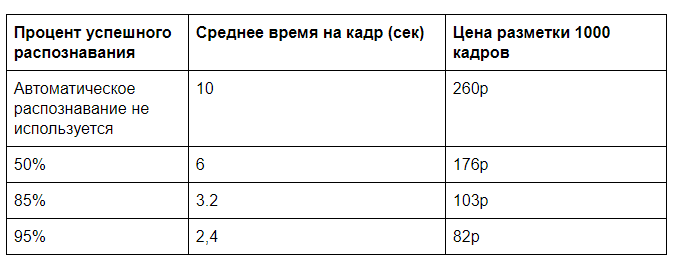
И если впоследствии убрать тотальный контроль, то удастся достичь цены почти 20р за 1000 кадров. Если входящих данных очень много, то можно оптимизировать алгоритмы распознавания, поработать над передачей данных и достигать еще большей эффективности.
На практике, разгрузка человека по мере обучения распознающей системы имеет еще один важный смысл — это позволяет значительно проще масштабировать Ваш продукт. Значительное увеличение объема данных позволяет лучше обучить сервер распознавания, точность повышается. А количество сотрудников, вовлеченных в процесс обработки данных, вырастет не пропорционально объему данных, что заметно упростит рост компании с организационной точки зрения.
Как правило, чем больше текста и выделения контуров приходится вводить вручную, тем выгоднее использовать автоматическое распознавание.
Конечно, не все. Но теперь некоторые направления бизнеса становятся не столь безумны, как раньше.
Хотите сделать offline услугу без человека на объекте? Посадить оператора удаленно и следить
по камерам за каждым клиентом? Получится чуть хуже, чем живой человек на месте. Да и операторов нужно чуть ли не больше. А если разгрузить оператора раз в 5? Это может быть и салон красоты без ресепшена, и контроль на производстве, и охранные системы. Не требуется 100% точности — можно и вовсе исключить оператора из цепочки.
Возможно организовывать довольно сложные системы учета существующих услуг для повышения их эффективности: контроль пассажиров, автотранспорта, времени оказания услуг, где есть риск “обхода” кассы, и т.п.
Если задача находится на текущем уровне развития компьютерного зрения и не требует совершенно новых решений, то это не потребует серьезных вложений в разработку.
Что получилось?
Представьте, перед Вами встала задача: найти на фотографии пиццу и определить, что это за вид пиццы.
Давайте коротко пройдемся тем стандартным путем, которым мы часто ходили. Зачем? Чтобы понять, как делать… не надо.
Шаг 1: наберем базу
Шаг 2: для надежности распознавания можно отметить что есть пицца, а что фон (так включим сегментационную нейронную сеть в процедуру распознавания, но оно часто того стоит):
Шаг 3: приведем ее в “нормализованный вид” и классифицируем с помощью еще одной сверточной нейронной сети:
Отлично! Теперь у нас есть обучающая база. В среднем размер обучающей базы может быть несколько тысяч изображений.
Берем 2 сверточные сети, например, Unet и VGG. Первая обучается на входных изображениях, затем нормализуем изображение и обучаем VGG для классификации. Отлично работает, передаем заказчику и считаем честно заработанные деньги.
Это так не работает!
К сожалению, почти никогда. Есть несколько серьезных проблем, которые возникают при внедрении:
- Изменчивость входных данных. Обучались на одном примере, в реальности все оказалось по-иному. Да просто во время эксплуатации что-то пошло не так.
- Очень часто точности распознавания так и остается недостаточно. Хочется 99,5%, а выходит от 60% до 90% в удачный день. А ведь хотели, как правило, автоматизировать решение, которое само работает, да еще и лучше людей!
- Такие задачи часто отдают на аутсорс, а, значит, договоры уже закрыты, акты подписаны и владельцу бизнеса приходится решать, вкладывать средства в доработку или отказаться от решения вовсе.
- Да просто со временем все начинает деградировать, как и в любой сложной системе, если не привлекать специалистов, которые участвовали в создании, или того же уровня квалификации.
В итоге, многим, кто руками потрогал всю эту механику, становится ясно, что все должно происходить совсем иначе. Примерно так:
На наш сервер приходят данные (по http POST, либо с помощью Python API), GPU сервер распознает их “как смог”, сразу возвращая результат. Попутно этот же результат распознавания вместе с изображением складывается в архив. Человек потом контролирует все данные или случайную их часть, поправляет. Исправленный результат кладется во второй архив. А затем, когда это будет удобно сделать (например, ночью), переобучаются все использованные для распознавания сверточные нейронные сети, используя те данные, что поправил человек.
Такое замыкание распознавания, супервайзинг человеком и дообучение решают многие из перечисленных выше проблем. Кроме того, в тех решениях, где нужна высокая точность, можно использовать проверенные человеком выходные данные. Кажется, что это использование проверенных человеком данных слишком затратно, но дальше мы покажем, что это почти всегда имеет экономический смысл.
Реальный пример
Мы реализовали описанный принцип и успешно его применяем уже на нескольких реальных задачах. Одна из них — распознавание номера на снимках контейнеров в ЖД терминалах, снятых с планшета. Это достаточно удобно — навести планшет на контейнер, получить распознанный номер и оперировать с ним в программе планшета.
Типичный пример снимка:
На снимке номер почти идеальный, лишь много визуального шума. Но случаются жесткие тени, снег, неожиданные компоновки надписей, серьезные наклоны или перспектива при съемке.
И вот так выглядит набор интернет-страницы, на которых вся “магия” и происходит:
1) Отправка файла на сервер (конечно, это же можно сделать не с html страницы, а с помощью Python или любого другого языка программирования):
2) Сервер возвращает результат распознавания:
3) А это страница для оператора, который контролирует успешность распознавания, и при необходимости поправляет результат. Здесь есть 2 стадии: поиск областей групп символов, их распознавание. Все это оператор может исправить, если видит ошибку.
4) Тут простая страница, где можно запустить обучение каждой из стадий распознавания, и, запустив, видеть текущий loss.
Суровый минимализм, зато прекрасно работает!
Как это может выглядеть со стороны компании, задумавшей воспользоваться описанным подходом (или нашим опытом и серверами Recognitor)?
- Выбираются state-of-art нейронные сети. Если все основано на существующих отлаженных решениях, то запустить сервера и настроить разметку можно за неделю.
- Организуется поток данных (желательно, нескончаемый) на сервер, размечаются несколько сотен кадров.
- Запускается обучение. Если все “сошлось”, то в результате получается 60-70% успешных распознаваний, что сильно помогает в дальнейшей разметке.
- Потом начинается планомерная работа по предъявлению всех возможных ситуаций, проверка результатов распознавания, правка, переобучение. По мере обучения, встраивание системы в бизнес-процесс становится все более и более рентабельным.
Кто еще так делает?
Тема замкнутого цикла не нова. Множество компаний предлагают системы работы с данными того или иного типа. Но парадигма работы может быть выстроена совершенно различным образом:
- Nvidia Digits — несколько достаточно хороших и сильных моделей, обернутых в понятный GUI, где пользователь должен подложить свои картинки и JSON. Основной плюс — минимальное знание программирования и администрирования дают вам неплохое решение. Минус — это решение может быть далеко от оптимального (например, хорошо искать автомобильные номера через SSD не получится). А понять, как оптимизировать решение, у пользователя не хватит знаний. Если же знаний хватит — ему не нужен DIGITS. Второй минус — нужно иметь свою аппаратуру, на которой всё настроить и развернуть.
- Сервисы разметки, такие как Mechanical Turk, Толока, Supervise.ly. Первые два предоставляют вам инструменты для разметки, а также людей, которые смогут сделать разметку данных. Последний предоставляет отличные инструменты, но без людей. Через сервисы можно автоматизировать человеческий труд, но нужно быть экспертом в постановке задачи.
- Компании, которые уже все обучили и предоставляют фиксированное решение (Microsoft,Google,Amazon). Подробнее писали про них тут (https://habr.com/post/312714/ ). Их решения бывают не гибкие, не всегда “под капотом” окажутся лучшие решения, необходимые именно в Вашем случае. Вообще, почти всегда оно не помогает.
- Компании, которые работают именно с вашим данными, например ScaleAPI (https://www.scaleapi.com/). У них великолепный API, для заказчика это будет черный ящик. Данные на вход — результат на выход. Очень вероятно, что внутри есть все самые лучшие решения автоматизации, но Вам не важно. Достаточно дорогие решения в пересчете на один кадр, но если Ваши данные действительно ценные — почему бы и нет?
- Компании, которые имеют инструментарий чтобы сделать почти полный цикл своими руками. Например PowerAI от IBM. Это почти как DIGITS, но Вам остается только разметка датасетов. Плюс никто не оптимизирует нейронные сети и решения. Но проработано много кейсов. Результирующую модель нейронной сети Вам развернут и дадут http доступ. Здесь есть тот же недостаток, что и в Digits, — нужно понимать, что делать. Именно Ваш случай может “не сходиться” или просто требовать необычного подхода к распознаванию. В целом, решение прекрасное, если у Вас довольно стандартная задача, с хорошо разделимыми объектами, которые нужно классифицировать.
- Компании, которые решают именно Вашу проблему своими инструментами. Таких компаний не много. Реально к ним бы я отнес только CrowdFlower. Тут за разумные деньги посадят разметчиков, выделят менеджера, развернут свои сервера, где запустят Ваши модели. И за более серьезные деньги смогут изменить или оптимизировать свои решения под Вашу задачу.
С ними работают крупные компании — ebay, oracle, tesco, adobe. Судя по их открытости, они успешно взаимодействуют и с небольшими компаниями.
Чем это отличается от разработки под заказ, которую делает, например, EPAM? Тем, что тут всё уже готово. 99% решения не пишется, а собирается из готовых модулей: разметка данных, выбор сети, обучение, развертка. Компании, которые разрабатывают под заказ, не имеют такой скорости, динамики развёртки решений, готовой инфраструктуры. Мы считаем, что тренд и подход, который обозначил CrowdFlower, верный.
Для каких задач это работает?
Пожалуй, 70% задач автоматизируются таким образом. Самые подходящие задачи — разнообразные распознавания областей, содержащих текст. Например, автомобильные регистрационные знаки, про которые мы уже рассказывали, номера поездов (вот наш пример двухлетней давности), надписи на контейнерах.
Много символьной технической информации распознается на заводах для учета продукции и ее качества.
Очень помогает такой подход при распознавании продуктов на полках магазинов и ценников, хотя там довольно сложные решения распознавания приходится создавать.
Но, можно отвлечься от задач с технической информацией. Любая семантика, будь то instance segmentation, с детектированием автомобилей, архаров, лосей и морских котиков тоже отлично ляжет на такой подход.
Очень перспективное направление — поддерживать общение с людьми в голосовых и текстовых чат-ботах. Там будет довольно непривычный способ разметки: контекст, тип фразы, ее “наполнение”. Но принцип тот же: работаем в автоматическом режиме, человек контролирует корректность понимания и ответов. Можно прибегать к помощи оператора в случае недовольного или раздраженного тона клиента. По мере накопления данных переобучаем.
А как работать с видео?
Если у Вас или внутри Вашей компании сложились необходимые компетенции (немного опыта в Machine Learning, работы с зоопарком Framework-ов, как offline, так и online), то не возникнет сложности с решением простых задач компьютерного зрения: сегментация, классификация, распознавание текста и др.
А вот для видео все не столь гладко. Как вообще разметить эти бесконечные объемы данных? Например, может оказаться, что раз в несколько секунд в кадре появляется объект (или несколько объектов), которые нужно размечать. В итоге все это может превратиться в покадровый просмотр и занимает столько ресурсов, что о дополнительном контроле человеком после запуска решения даже не приходится говорить. Но и это можно преодолеть, если представить видео в правильном виде для того, чтобы выделить кадры с областью интереса.
Например, мы столкнулись с огромными видео-рядами, в которых нужно было выделить единичный специфический объект — сцепку ЖД платформ. И это было действительно непросто. Оказалось, что все не так страшно, если взять монитор пошире, выбрать частоту кадров, например 10FPS и разместить 256 кадров на одном изображении, т.е. 25,6с в одном изображении:
Наверное, выглядит это пугающе. Но на деле нужно около 15с, чтобы прощелкать все до единого кадра, выбрав центр сцепки вагона на кадре. И даже один человек за день или два может разметить не менее 10 часов видео. Получится более 30 тысяч примеров для обучения. Кроме того, проезд платформ перед камерой в этом случае не постоянный процесс (а довольно редкий, нужно отметить), то вполне реально даже почти в реальном времени поправлять машину распознавания, пополняя обучающую базу! А если распознавание происходит в большинстве случаев верно, то час видео можно преодолеть за пару минут. И тогда пренебрегать тотальным контролем со стороны человека, как правило, экономически не выгодно.
Все еще облегчается, если на видео нужно отметить “да/нет”, а не локализацию объекта. Ведь события часто “слеплены”, и одним взмахом мышки можно отмечать до 16 кадров за раз.
Единственное, как правило, приходится использовать 2 стадии при анализе видео: поиск “кадров или области интереса”, а затем уже работа с каждым таким кадром (или последовательностью кадров) другими алгоритмами.
Машинно-человеческая экономика
Насколько можно оптимизировать стоимость обработки визуальных данных? Так или иначе строго обязательно иметь человека для контроля распознавания данных. Если этот контроль выборочный, то тут затраты незначительные. Но если мы говорим о тотальном контроле, то насколько это может быть выгодно? Оказывается, что это имеет смысл почти всегда, если прежде эту же самую задачу человек выполнял без помощи машины.
Возьмем не самый лучший пример, приведенный в самом начале: поиск пиццы на изображении, разметка и выбор типа (а в реальности и ряда других характеристик). Хотя, задача не столь синтетическая, насколько это может показаться. Контроль внешнего вида продуктов сетей франшизы в реальности и правда существует.
Предположим, что для распознавания с помощью GPU сервера нужно 0.5с машинного времени, для полной разметки кадра человеком около 10с (выбрать тип пиццы и ее качество по ряду параметров), а для того, чтобы проверить, все ли верно определено компьютером, понадобится 2с. Конечно, здесь будет вызов в том, как удобно представить эти данные, но такие времена вполне сопоставимы с нашей практикой.
Нужны еще некоторые вводные по стоимости ручной разметки и аренды GPU сервера. Рассчитывать на полную загрузку сервера, как правило, не приходится. Пусть удастся добиться загрузки 100 000 кадров в день (займет 60% вычислительной мощности одного GPU) при ориентировочной стоимости месячной аренды сервера 60 000р. Выходит 2 копейки за анализ одного кадра на GPU. А анализ ручной при затратах 30 000р на 40 часов рабочего времени будет стоить 26 копеек за кадр.
И если впоследствии убрать тотальный контроль, то удастся достичь цены почти 20р за 1000 кадров. Если входящих данных очень много, то можно оптимизировать алгоритмы распознавания, поработать над передачей данных и достигать еще большей эффективности.
На практике, разгрузка человека по мере обучения распознающей системы имеет еще один важный смысл — это позволяет значительно проще масштабировать Ваш продукт. Значительное увеличение объема данных позволяет лучше обучить сервер распознавания, точность повышается. А количество сотрудников, вовлеченных в процесс обработки данных, вырастет не пропорционально объему данных, что заметно упростит рост компании с организационной точки зрения.
Как правило, чем больше текста и выделения контуров приходится вводить вручную, тем выгоднее использовать автоматическое распознавание.
И это все меняет?
Конечно, не все. Но теперь некоторые направления бизнеса становятся не столь безумны, как раньше.
Хотите сделать offline услугу без человека на объекте? Посадить оператора удаленно и следить
по камерам за каждым клиентом? Получится чуть хуже, чем живой человек на месте. Да и операторов нужно чуть ли не больше. А если разгрузить оператора раз в 5? Это может быть и салон красоты без ресепшена, и контроль на производстве, и охранные системы. Не требуется 100% точности — можно и вовсе исключить оператора из цепочки.
Возможно организовывать довольно сложные системы учета существующих услуг для повышения их эффективности: контроль пассажиров, автотранспорта, времени оказания услуг, где есть риск “обхода” кассы, и т.п.
Если задача находится на текущем уровне развития компьютерного зрения и не требует совершенно новых решений, то это не потребует серьезных вложений в разработку.
killik
А где пицца?