

А задумывались ли вы сколько сайтов в интернете и что с ними происходит?
Периодически попадаются статьи с исследованиями, построенными на выборке разных топ 1М сайтов. Но мне всегда было интересно, можно ли пробежаться по всем доменам интернета, не строя аналитику на очень малой выборке.
Впервые я задался этим вопросом больше года назад. Мы начали разработку краулера для вебсайтов и нужно было его тестировать на больших объемах. Взяв ядро краулера, я впервые пробежался по доменам рунета — это 5.5 млн доменов, а после и по всем 213 млн. доменов (осень 2017 года).
За прошедшее время было вложено немало сил и средств в разработку, алгоритмы стали получше, я решил вернуться к анализу интернета и собрать еще больше данных.
Цель этого сбора информации — получить достоверную выборку в первую очередь по рабочим хостам, редиректам, заголовкам server и x-powered-by.
Методика сбора
Само приложение написано на Go, используются собственные реализации для работы с dns и http клиент. В качестве очереди redis, бд — mysql.
Исходно есть только голый домен, вида example.com. Анализ состоит из нескольких этапов:
- проверить доступность
http://example.com, http://www.example.com, https://example.com, https://www.example.com - если хоть к какому то варианту удалось подключиться, то:
— анализируем /robots.txt
— проверяем наличие /sitemap.xml
Каждый день появляется и удаляется около 100 тыс доменов. Очевидно, что сделать одномоментный слепок состояния сети практически невозможно, но нужно делать это максимально быстро.
Мы развернули дополнительный кластер серверов краулера, что позволило достичь средней скорости 2 тыс доменов в секунду. Таким образом проверка 252 млн доменов заняла примерно полтора дня.
Данные
Самая главная цифра при анализе сети — это количество “живых” доменов. Мы называем домен “живым” на который резолвится IP и хоть одна из версий www/без_www http/https отдает любой код ответа.
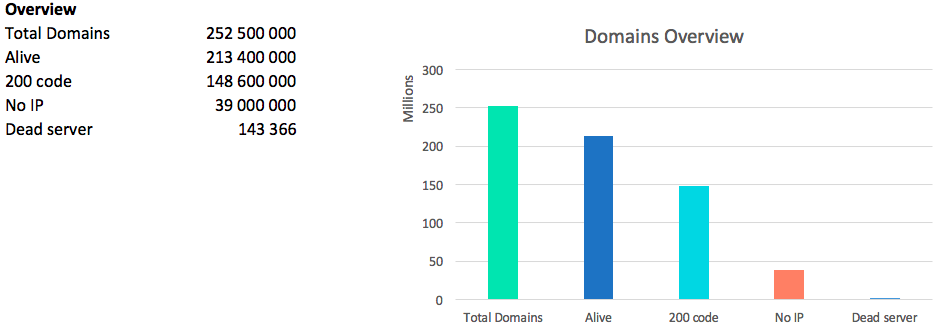
Конечно же нельзя забывать про код 418 — чайники: 2227 штук.
Всего было найдено 13.2 млн ip адресов. Стоит отметить, что по некоторым доменам отдается сразу несколько ip адресов, по другим только один, но каждый раз разный.
Таким образом,
Картина по статус кодам выглядит следующим образом:
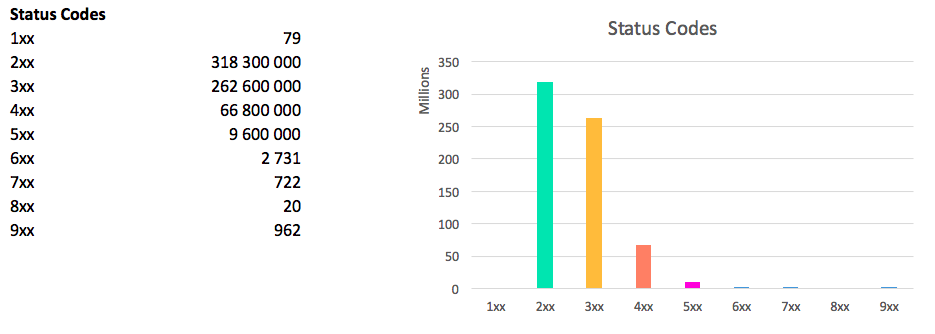
сумма больше общего количества доменов, т.к. каждый хост может отдавать 4 разных статус кода (комбинации www/non www, http/https)
Https
Переход на https является трендом последних лет. Поисковики активно продвигают внедрение защищенного протокола, а Google Chrome скоро начнет помечать http сайты как незащищенные.
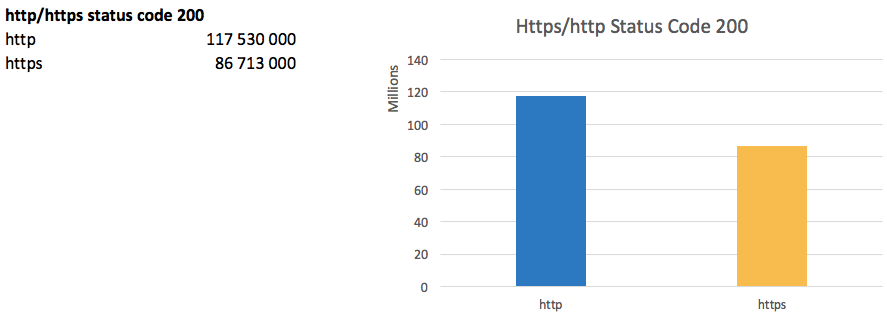
Таким образом доля работающих сайтов по https достигла 73% от количества сайтов работающих по http.
Самой большой проблемой перехода является практически неминуемая просадка трафика, т.к. для поисковиков http/https даже на одном домене технически являются разными сайтами. Новые проекты обычно сразу запускаются на https.
www или без www?
Поддомен www возник примерно вместе с самим Интернетом, но даже и сейчас некоторые люди не воспринимают адреса без www.
При этом 200 код ответа на версию без www отдает 118.6 млн. доменов, а с www — 119.1 млн доменов.
У 4.3 млн доменов не подвязаны ip на версию без www, т.е. вы не зайдете на сайт по example.com. У 3 млн. доменов не подвязаны ip на поддомен www.
Важный момент — это наличие редиректов между версиями. Т.к. если будут в обоих случаях отдаваться 200 коды, то для поисковика это два разных сайта с дублированным контентом. Хочется напомнить, не забывайте настраивать корректные редиректы.
Редиректов с www->без www 32 млн., без www->www 38 млн.
Глядя на эти цифры мне сложно сказать кто победил — www или без www.
Редиректы
В seo кругах бытует мнение, что самым эффективным методом продвижения сайта является простановкой на него редиректов с околотематических сайтов.
35.8 млн доменов редиректят на другие хосты и если сгруппировать их по назначению, видим лидеров:

Традиционно в топе находятся доменные регистраторы и парковки.
Если посмотреть на топ по количеству менее 10000 входящих редиректов, то можно увидеть много знакомых сайтов типа booking.com.
А в топ до 1000 появляются казино и прочие развлекательные сайты.
Server header
Наконец-то добрались до самого интересного!
186 млн доменов отдают не пустой заголовок Header. Это 87% от всех живых доменов, вполне достоверная выборка.
Если сгруппировать просто по значению, то получим:

Лидерами являются 20 серверов, которые в сумме имеют 96%:
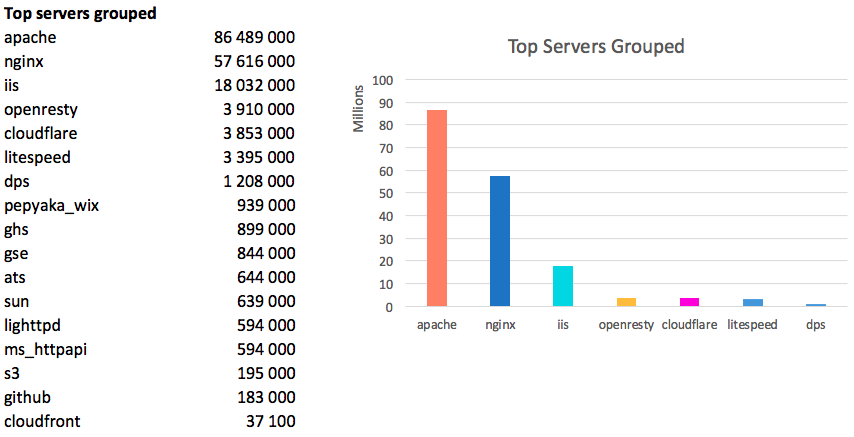
Мировой лидер — Apache, серебро у Nginx и замыкает троицу IIS. В сумме эти три сервера хостят 87% мирового интернета.
Страны консерваторы:

Примечательно, что в Рунете картина иная:
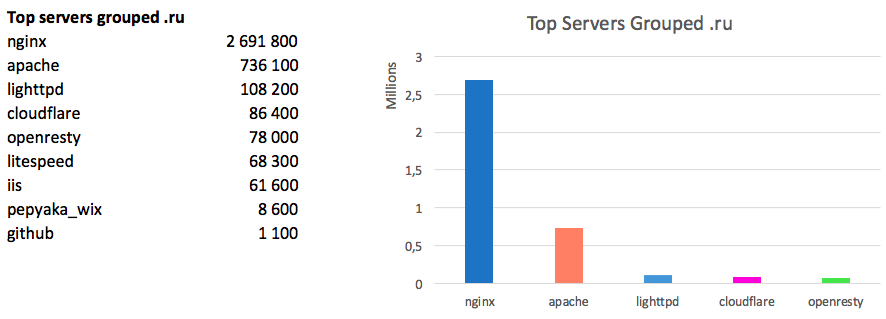
Здесь абсолютным лидером является Nginx, apache имеет долю в три раза меньше.
Где еще любят Nginx:
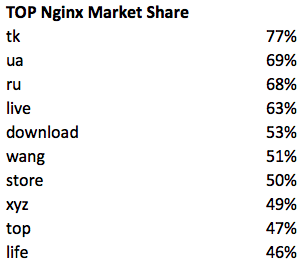
Оставшиеся сервера распределены следующим образом:

X-Powered-By
Заголовок X-Powered-By есть только у 57.3 млн хостов, это примерно 27% от живых доменов.
В сыром виде лидеры:
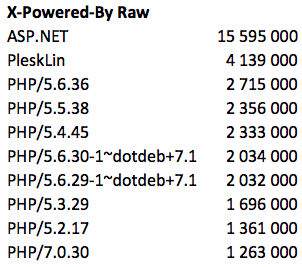
если обработать данные и отбросить мусор — то php побеждает:
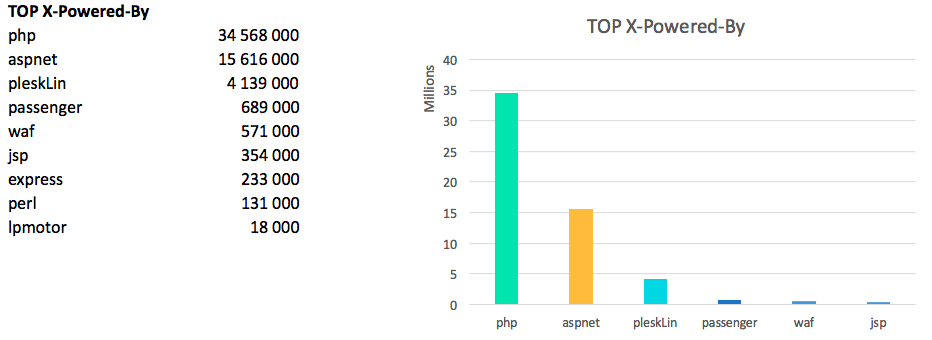
версии PHP:

Лично меня несколько удивляет такая популярность 5.6 и в тоже время радует, что суммарная доля семерок растет.
Также есть один сайт в рунете, который говорит, что работает на php/1.0, но правдивость этой цифры вызывает сомнения.
Cookies

Заключение
Я показал лишь очень малую часть информации, которую удалось найти. Копание в этих данных напоминает рытье в куче мусора с целью найти интересные артефакты.
Не раскрытыми остались темы с блокировкой ботов поисковиков и сервисов аналитики (ahrefs, majestic и другие). На такой выборке немало находится различных сеток саттелитов, как ни пытайся скрыть футпринты, но на тысячах доменов можно увидеть закономерности.
В ближайших планах собрать еще больше данных, в частности по ссылкам, словам, рекламных системам, кодам аналитик и многое другое.
Буду рад услышать ваши комментарии и замечания.
Комментарии (66)

olku
14.06.2018 11:23работает на php/1.0
поделитесь, кто это?sergebezborodov Автор
14.06.2018 11:41я боюсь, что мы его дружно положим хабраэффектом, скину вам в личку адрес
скрин заголовков:

nikitasius
14.06.2018 13:36Можно любой заголовок отдавать. Кто вообще им верит?
sergebezborodov Автор
14.06.2018 13:56согласен, но я очень сомневаюсь, что хотя бы каждый десятый подставляет фейк значение, чаще всего просто отключают
TheShock
15.06.2018 05:42Но ведь сайт такой только один) Да и, вроде, не было никогда версии PHP 1.0
Voltos
15.06.2018 09:35sergebezborodov Автор
15.06.2018 09:36как выяснили в переписке в личке, сама суть сайта — печать 3д появилась гораздо позже, чем пхп 1
pehat
14.06.2018 11:27А откуда вы набрали доменные имена? Если обходом в глубину — deep web в вашей выборке не присутствует, в противном случае остаётся либо базы регистраторов доменов, либо брутфорс.
sergebezborodov Автор
14.06.2018 11:32покупаем базу доменов у аггрегаторов, самая главная проблема этих баз — там нет поддоменов
Source
15.06.2018 01:10+1А меж тем поддомен — это вполне самостоятельный домен, на котором может быть и другой сервер и другой стек. Что делает статистику несколько неполной.
TheShock
15.06.2018 05:43Мне кажется, что проценты это поменяет лишь в рамках погрешности. Да и как отличать — поддомен это или один и тот же сайт, как раньше было с никами на хабре? Такие сайты как раз сместят статистику в сторону более ошибочной
kafeman
14.06.2018 11:29Как мы просканировали весь интернет и что мы узнали
резолвится IP и хоть одна из версий www/без_www http/https отдает любой код ответа
Вы не просканировали весь Интернет, а только попытались просканировать всемирную паутину, которая является его частью.sergebezborodov Автор
14.06.2018 11:34согласен с «паутиной», статьи я пока пишу хуже, чем код
к более глубокому сканированию мы идем постепенно, следующая цель собрать несколько млрд страниц со всех сайтов и по ним строить аналитикуmwambanatanga
14.06.2018 12:31+1kafeman, вероятно, имел в виду, что Интернет не ограничивается Вебом. Помимо веб-серверов, в сеть «смотрят» и другие, по другим протоколам.
vesper-bot
14.06.2018 11:32Лично меня несколько удивляет такая популярность 5.6
Ничего сверх-удивительного. Фреймворки берутся под 5.6, версия 5.6 берется доступная под платформу, 7 не берется из-за потенциальных проблем совместимости кода php5 с движком php7, а перепиливать фреймворк это дело небыстрое. Плюс легаси, в виде фреймворков же, но старых неподдерживаемых версий, плюс настройки вида "раз поднял, два забыл, так и крутится", плюс 5.6 это последняя версия пятого пыха. Всё вместе дает достаточный эффект.
sergebezborodov Автор
14.06.2018 11:37я очень помню как переходил на 5.6 с 5.4 кажется, было достаточно много правок
а когда с 5.6 на 7 — то толком ничего и не менял, запостил тогда скрин с пинбы:

JekaMas
14.06.2018 20:49Аналогично, переводили кодовую базу порядка миллиона строк кода. Для перехода с 5.4 на 5.6 потребовались усилия отдельной команды до 6 человек и месяца 4 работы.
А вот до 7 обновились менее чем за месяц.
Blogoslov
14.06.2018 11:44Скажите пожалуйста — а откуда берете список доменов по которым нужно ходить?
sergebezborodov Автор
14.06.2018 11:46не хочу никого рекламировать, ищется в гугле «buy all domains list»
Oplkill
14.06.2018 20:00А не проще ли простым перебором комбинаций(знаю, что бесконечно много), для получения экзотических сайтов на которые никто не ссылается, но вполне себе существуют и живут жизнью
sergebezborodov Автор
14.06.2018 21:30если домен существует, то он всегда будет в базах регистраторов.
с поддоменами уже сложнее, но перебор как мне кажется уж слишком дорогая операция получится
wlr398
14.06.2018 12:09А можно хотя бы в очень общих чертах, как монетизировать сию деятельность?
sergebezborodov Автор
14.06.2018 12:12мы практически не зарабатываем на этом (учесть серверные и прочие расходы)
главная цель для меня как технаря — интересно покопаться в дебрях сети, улучшить алгоритмы краулера (который коммерческий проект) и опыт с большими данными
Alexanevsky
14.06.2018 12:28А можете поделитеся, базу доменов где брали? Российские можно получить у рег.ру, а вот зарубежные и международные
sergebezborodov Автор
14.06.2018 12:35мы покупаем у аггрегаторов, несложно ищется в гугле «buy all domains list»
namikiri
14.06.2018 16:32pepyaka_wix— очень интересный сервер.sergebezborodov Автор
14.06.2018 17:18сам хедер там Pepyaka, я дописал _wix чтобы было понятнее
но этимология слова интересна, может кто-то и знаетKonachan700
14.06.2018 20:20+1Лексика Упячки же. Какой-то упячкоид поднял сервер, ну и подставил в заголовок словечко из своего сленга.
DjOnline
15.06.2018 11:21Wix — это же система создания сайтов, конструктор. И судя по данным, 125 тысяч доменов, которые покупались специально для wix и через wix, затем были заброшены и неоплачены, и именно поэтому идёт редирект на главную wix.com.
LChem
14.06.2018 16:33А можно подробней про стек, для чего редис и почему мускул итд. Почему своя реализация dns и http, можно в личку если не хочется на публику.
sergebezborodov Автор
14.06.2018 16:36секрета особого нет, редис и мускл — то, с чем хорошо умеем работать
своя реализация для dns и http — ради оптимизации ресурсов.
можно было собрать всю эту инфу и краулером на php, но тогда ты расходы на оборудование возросли в разы
DmitrySokolov
14.06.2018 17:17+1Таким образом доля работающих сайтов по https достигла 73% от количества сайтов работающих по http.
Тогда как вы назовёте "27% от количества сайтов работающих по http"?
Напрашивается так: "доля работающих сайтов не по https (а каких? если всего два типа в выборке) достигла 27% от количества сайтов работающих по http" (или "… по http… от… http", но это ещё хуже, т.к. явный бред).
Одно число может быть меньше/больше другого на Х (в Х раз). Например, "число сайтов, работающих по http больше в 1/0,73=1,37 раза числа сайтов работающих по https".
Процент — это "сотая доля ...". Доля — часть целого. В вашем случае — выборка про протоколам http и https это целое. https и http — это доли. Имеет смысл сравнивать доли между собой в разах (пример выше), но считать сколько одна доля составляет процентов от другой — смысла не имеет.
Выношу этот комментарий в паблик, поскольку весь интернет заполнен подобными "процентами" (да и на Хабре тоже часто встречается).
sergebezborodov Автор
14.06.2018 17:33согласен с Вами, правильнее было бы написать долю https от всего хостов отдающих код 200
TheShock
15.06.2018 05:46
Я так понял, что если 100х сайтов работает по http, то по https — 73хТаким образом доля работающих сайтов по https достигла 73% от количества сайтов работающих по http.
Тогда как вы назовёте «27% от количества сайтов работающих по http»?
Infthi
14.06.2018 17:23Ещё одна интересная околокраулерная штука — это поиск /.{git,svn,hg}. По собственному опыту года полтора назад, валидное содержание в них находилось где-то на одном проценте доменов.
sergebezborodov Автор
14.06.2018 17:35добавлю еще интересно количество открытых серверов редиса без пароля, mysql, memcached
но там нужны «правильные» ip, которые позволят забить на абузы
Forbidden
14.06.2018 19:08каким образом достигается резолвинг domain -> ip со скоростью 2к+ доменов в секунду? точнее, какие сервера способны с такой скоростью выдавать ответы?
sergebezborodov Автор
14.06.2018 21:33увы я таких серверов не нашел, для этой задачи нужно очень много dns серверов и очень много ip с которых их можно долбить, где эти сервера брать — отдельная задача
powerman
14.06.2018 22:02Я в начале 2000-ных на Perl+epoll писал подобное. Скорость получил довольно грубым методом: в процессе резолва имеющихся доменов я получал адреса их DNS-серверов, после чего просто проверял не открыт ли на этих серверах рекурсивный ресолвинг всем желающим — и таких было довольно много, так что дальше к ресолвингу подключались найденные "халявные" DNS-сервера. Очень быстро их набиралось достаточно много, чтобы рейт запросов к каждому был достаточно низким и никого не напрягал. Единственно что, на всякий случай делал дублирующую проверку через другой DNS, на случай если кто-то из "халявных" это специальный ханипот возвращающий левые ответы.
sergebezborodov Автор
14.06.2018 22:14о да, есть отдельная категория DNS возвращающих всякую хрень, поэтому результаты всегда нужно проверять еще на нескольких, что в сумме дает снижение общего rps
powerman
14.06.2018 22:17Если не путаю, у меня тогда был RPS порядка 900. Помню, огорчался что до тысячи не дотянул немного. Но… это был Perl 15 лет назад на одном 10Mbps сервере. Думаю, сейчас и на Go можно выжать намного больше 2k.
el777
14.06.2018 21:11Как быстро шел парсинг с одного сервера?
Как добились такой скорости?
Было бы интересно взглянуть на код.sergebezborodov Автор
14.06.2018 21:40самую первую версию краулера я написал где-то за пару часов, «ядром» там было что-то типа
resp, err := http.Get(url)
и оно работало, но очень на малых объемах и до 1-5 rps. Понадобилась куча времени в обнимку с мануалом, дебаггером, профайлером и уже моим любимым Wireshark, чтобы память и сокеты не текли. Код, увы, не opensource
auine
15.06.2018 00:10+2А как вы получили список доменов? Вы его где-то стянули или по ссылкам сайтов ходили?
Сорян, нашел ответ выше по коментариям. Но судя по всему говоря «а после и по всем 213 млн», по всем, что вы смогли у кого-то купить)?
sim2q
15.06.2018 04:25а я вас вижу в логах:)
capslocky
15.06.2018 09:47Админы публичных DNS серверов могуть извлечь из них большой список доменов, или даже просто провайдер может логировать домены из всех проходящих DNS запросов.
Есть и такая публичная вещь как Certificate Transparency logs, где сохраняются данные об https сертификатах. https://crt.sh/?id=358997645
DjOnline
15.06.2018 12:10Очень интересно увидеть пример скрытой сетки на тысячу доменов.
sergebezborodov Автор
15.06.2018 12:21такие данные шарить увы не могу, но могу сказать что тысяча доменов это не такая уж и большая сетка
когда я прошлый раз сканил инет зимой, я нашел сетку из 34 тыс сайтов в рунете! при чем сайты были самых разных тематик — от стройки до чуть ли не родов, в бурже все еще интереснееDjOnline
15.06.2018 12:51Это была сетка из абсолютно разных сайтов, или все они были похожи друг на друга по названию и внешнему виду? По каким признаком опозналась эта сетка? Один и тот же adsense Id? Это был тупо дорвей или рерайченный через биржу контент? На чём они зарабатывали, на партнёрке, или продаже ссылок, или на Adsense/РСЯ?
Можно пример хотя бы одного сайта из этих 34 тысяч?
HermaMora
Объем данных не пугает?
sergebezborodov Автор
та не, вполне нормально получается обрабатывать