
История индустриальной экономики – это история потребления ограниченного ресурса. В случае с электричеством был ярко выраженный вечерний пик, и поэтому владельцы электростанций пролоббировали и современный городской транспорт, и создали с нуля, по сути, индустрию бытовой электроники. То есть поменяли образ жизни миллионов, чтобы электростанции были загружены более равномерно.
С вычислительными ресурсами примерно похожая история. Редко кто использует их полностью эффективно. Давайте поговорим об эксплуатации и немного о следующем поколении программирования под такие среды, где важно очень гибко разделять ресурсы.
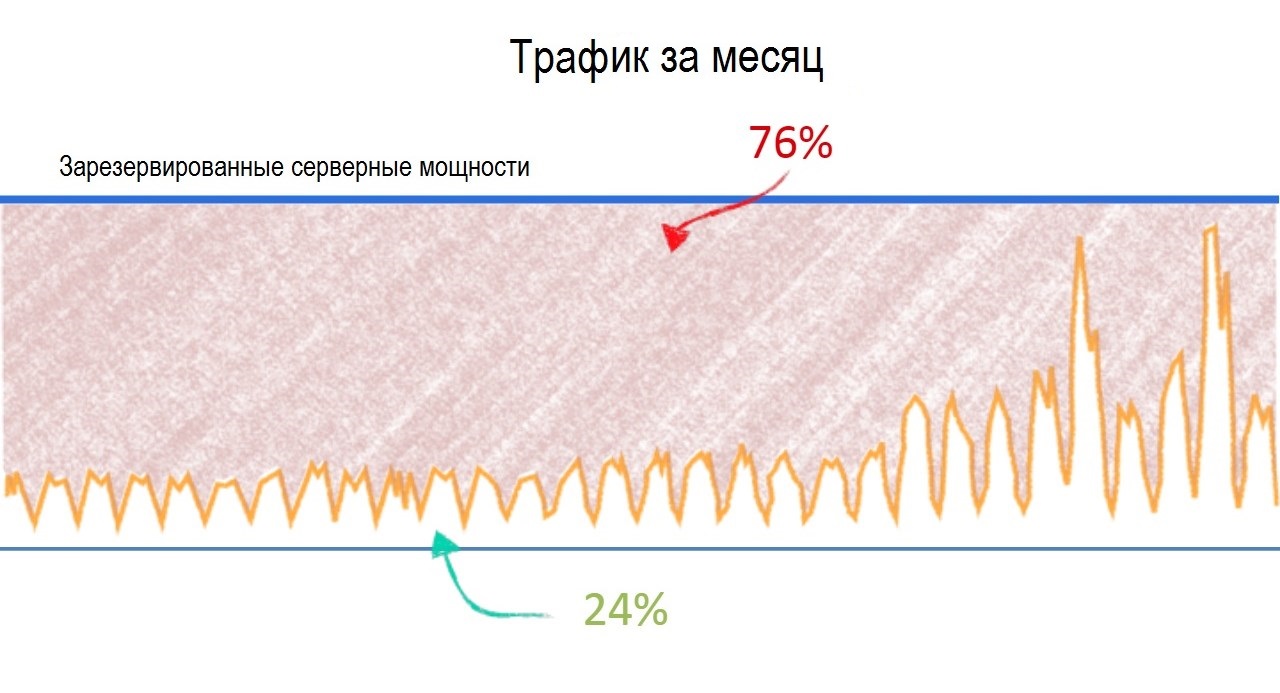
Сезонное потребление
Сезонное потребление у обычного заказчика выглядит как 11 месяцев спокойствия и месяц удвоенной-утроенной нагрузки. Каждый знает свой пик. Розница замораживает все активности к декабрю и новогодним распродажам, добирает виртуальных машин. У каждого ещё бывает свой сезон скидок и больших продаж – у кого-то на 1 сентября, у подарков на 8 марта и так далее. У всех B2C-сервисов есть понятная активность по сезону просто с рабочими часами, например, у интернет-банков. Мы в Техносерв Cloud не планируем на эти периоды сервисные работы.
Геологи приходят домой из экспедиции и начинают считать в облаке свои ископаемые. В крупных компаниях отчёты к концу периода собираются из кучи подсистем – где-то эффективно, а где-то со скрипом, почти до импакта базы. Машинное обучение и аналитика дают очень большие нагрузки, но делают это не перманентно.
Летние пики – туристическая сфера, но у них нет скачков значительных, зато есть DDoS в сезон, обычно, когда люди идут брать билеты на майские отпуска.
Обычное потребление
Наш средний заказчик в нашем облаке потребляет ресурсы «пилой» посуточно: утром с началом рабочего дня начинается подъём, в обед короткий спад, вечером спад в 2-3 раза. Ночью запускаются системные задачи — бекапы, переливы данных в аналитику, у розницы подсчёты запасов склада и логистики, прогнозы продаж. У финансов – разные кредитные истории и прочий кэш. АБС в облаке нет, у них, у сотовых операторов и у компаний вроде железных дорог ночью делается клиринг, то есть сводится дневной баланс по всем операциям. Это, условно говоря, не чтобы попасть на ночь, а чтобы за период собрать похожие транзакции в пакеты и взаимозачесть.
В общем, обычная офисная «пила». Самые прошаренные админы уже прописывают скейлинг, но мы пока видим только единичные примеры.
В простом случае он выглядит так: поднять ещё одну виртуальную машину в 11:00, поставить её с сервисами в балансировщик, аккуратно размигрировать к 19:00 и погасить. То есть оплата только за треть суток, а под пик готовность такая же, как при постоянной аренде дополнительной виртуальной машины.
Это потому что у нас дискретизация по часам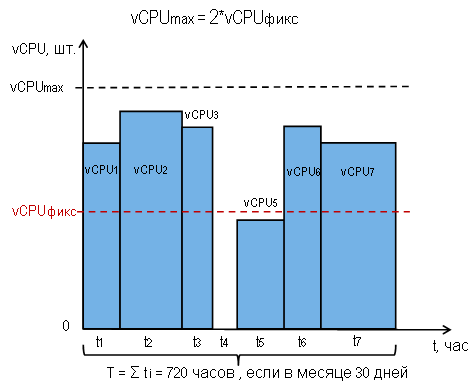
Наши заказчики часто интересуются другой вариацией этого скрипта – автоскейлингом. Когда потребление ресурсов вырастает до 80%, поднимается ещё машина. Падает до какого-то предела – машина выключается. В финансовом контракте у нас есть pay-as-you-go, то есть постоплата за фактически потреблённые ресурсы, квантование ВМ по часам. В консоли можно поднять некоторое количество машин самостоятельно. Админ заходит и делает это руками при нагрузках (например, в Чёрную пятницу, когда нагрузка на сайт растёт), либо же пишет скрипт, который запускает-тушит ВМ. Есть одна компания, разработчики, условно, банковских приложений – им автоскейлинг нужен для тестирования и пиков перемалывания базы данных. У них очень подходящая архитектура для автоматизации, и с ними мы тестируем полностью автоматическую систему, когда облако само выделяет нужное количество ВМ. То есть как, само – через отдельный витнес-сервер (выделенную ВМ или внешнюю машину), которая умеет через API управлять нагрузкой, распределением приложений и балансировкой. Они получают автоскейлинг первыми, помогают правильно расставить приоритеты. И при этом работают для нас тестерами, по сути. Продукт очень дёшево пишется под их потребности: у нас нет такого сервиса в облаке именно как подключаемой услуги, но мы экспериментируем. Пока всё вручную, плюс вот эта альфа: мы за работу имеем все отчёты и подробные разговоры продуктолога с их разработчиками. Так рождается продукт, который будет нужен всем подобным командам.
Архитектурные особенности софта
Почему мало админов с автоскейлингом, хотя это выгоднее? Потому что, чтобы правильно масштабировать нагрузку в облаке, надо иметь подготовленную архитектуру приложений и баз данных. Если приложение типа веб-фронта обычно легко масштабируется, то вот запись в базу данных – уже более интересный вопрос. Не у всех приложения элементарно разбиты на фронт-бек или микросервисы, чтобы разнести их на разные машины.
У кого такое есть – те, конечно, экономят. И получают плюс к стабильности, о чём мы писали вот тут в посте про частые ошибки архитектуры.
Естественно, под это надо переписывать софт. Что не всегда возможно быстро и не всегда возможно в принципе.
Но следующее поколение облачной истории выглядит даже ещё интереснее.
Контейнерная виртуализация
Следующее поколение – это контейнеры. Сейчас это представляется, как некое подобие лёгких виртуальных машин с микросервисами, которые поднимаются при обращении и выгружаются из оперативной памяти при отсутствии активности. То есть всплывают и вытесняются как приложения в оперативной памяти и свопе современных ОС – по мере использования. Звучит просто, и многие крупные игроки уже переписали свою архитектуру именно под контейнеры.
То есть это даже не отдельные ВМ, а просто процессы на них, что-то вроде цитриксовских ксен-приложений. Либо старые добрые ВМ в оболочке контейнера – то есть те же машины с глубоким автоскейлингом.
Но это только первый шаг. Дело в том, что дальше ещё более интересная вещь – контейнеризация функций. Это пока фантазия архитекторов, но если код писать сразу под систему всплывающих контейнеров, то можно заворачивать в каждый одну функцию. Есть ввод, есть вывод и есть «чёрный ящик» – сам контейнер. Функция вызвана в коде – контейнер «всплыл», отработал и ушёл обратно ждать следующего вызова.
Код, понятное дело, придётся отрефакторить и переоптимизировать весь. Но это того стоит, и это одна из возможных веток будущего. По нашей оценке, правда, очень отдалённого – года три минимум до первых внедрений у гигантов и лет 15 до промышленного использования в России.
Пока же контейнейры – увы, продукт для гиков, потому что работают они не очень хорошо. И запросов на них в России нет, зато появляются запросы на автоскейлинг. И уже ни один новый договор не подписывается без pay-as-you-go.
Комментарии (7)

easyman
20.06.2018 11:08Пока же контейнейры – увы, продукт для гиков, потому что работают они не очень хорошо
Это только у Вас так или в Google Cloud глючит k8s?MbBlinov Автор
20.06.2018 12:48Проблемы с контейнерами конечно возникают, но это не значит что они работают плохо.
Основные проблемы, с которыми сталкиваются при переходе к контейнерам:
Обновление дистрибутива контейнера
Вопросы к ИБ в контейнерах
Вопрос производительности ПО внтури контейнера
Переработка архитектуры сервиса перед переходом к контейнерам
electronus
20.06.2018 12:08Хех, PAYG это термин обозначающий предоплату. Как-бы антоним к тому, что вы этим назвали…
imanushin
20.06.2018 13:30В ряде случаев опасно "гибко распределять ресурсы" по двум причинам:
- Это добавляет сложности системе, всё надо тестировать при каждом релизе и т.д.
- В момент, когда вам потребовались дополнительные ресурсы, другим клиентам облака они тоже могут потребоваться. Если у вас свой сервер, то вы сможете ускориться. А в облаке — может быть и нет. Хороший пример: торги на биржах. Если у вас свой кабель, то при увеличении объема торгов (в момент условного брекзита), вы продолжите работать. Если вы используете общий кабель, то на маршруте биржа-биржа на нем может быть перегруз (причем, это реальный случай).
Так что динамическое расширение полезно далеко не всегда.
NewStahl
>Траффик
Дальше не читал. Это песец.
MbBlinov Автор
Спасибо, поправил.