

Статический анализатор PVS-Studio известен в мире C, C++ и C# как инструмент для выявления ошибок и потенциальных уязвимостей. Однако у нас мало клиентов из финансового сектора, так как выяснилось, что сейчас там востребованы Java и IBM RPG(!). Нам же всегда хотелось стать ближе к миру Enterprise, поэтому, после некоторых раздумий, мы приняли решение заняться созданием Java анализатора.
Введение
Конечно, были и опасения. Легко занять рынок анализаторов в IBM RPG. Я вообще не уверен, что существуют достойные инструменты для статического анализа этого языка. В мире Java дела обстоят совсем иначе. Уже есть линейка инструментов для статического анализа, и чтобы вырваться вперед, нужно создать действительно мощный и крутой анализатор.
Тем не менее, в нашей компании был опыт использования нескольких инструментов для статического анализа Java, и мы уверены, что многие вещи мы сможем сделать лучше.
Кроме того, у нас была идея, как задействовать всю мощь нашего С++ анализатора в Java анализаторе. Но обо всём по порядку.
Дерево
В первую очередь нужно было определиться с тем, каким образом мы будем получать синтаксическое дерево и семантическую модель.
Синтаксическое дерево является базовым элементом, вокруг которого строится анализатор. При выполнении проверок анализатор перемещается по синтаксическому дереву и исследует его отдельные узлы. Без такого дерева производить серьезный статический анализ практически невозможно. Например, поиск ошибок с помощью регулярных выражений является бесперспективным.
При этом стоит отметить, что одного лишь синтаксического дерева недостаточно. Анализатору необходима и семантическая информация. Например, нам нужно знать типы всех элементов дерева, иметь возможность перейти к объявлению переменной и т.п.
Мы рассмотрели несколько вариантов получения синтаксического дерева и семантической модели:
- ANTLR (с грамматикой для Java)
- JavaParser и JavaSymbolSolver
- Eclipse's ASTParser из Eclipse JDT
- Spoon
От идеи использования ANTLR мы отказались практически сразу, так как это неоправданно усложнило бы разработку анализатора (семантический анализ пришлось бы реализовывать своими силами). В конечном итоге решили остановиться на библиотеке Spoon:
- Является не просто парсером, а целой экосистемой — предоставляет не только дерево разбора, но и возможности для семантического анализа, например, позволяет получить информацию о типах переменных, перейти к объявлению переменной, получить информацию о родительском классе и так далее.
- Основывается на Eclipse JDT и умеет компилировать код.
- Поддерживает последнюю версию Java и постоянно обновляется.
- Неплохая документация и понятный API.
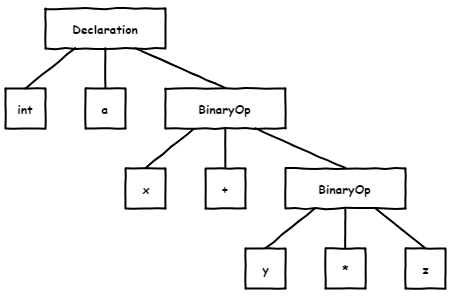
Вот пример метамодели, которую предоставляет Spoon, и с которой мы работаем при создании диагностических правил:
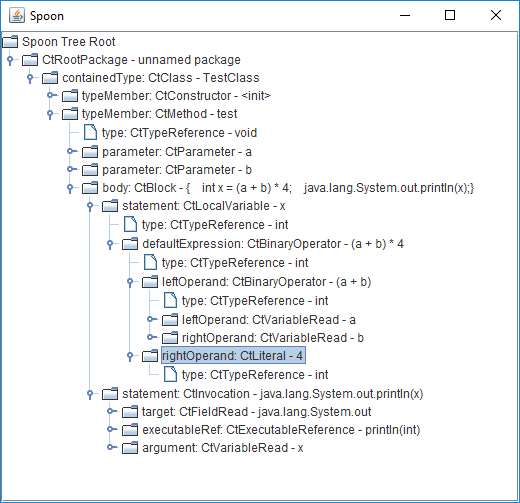
Эта метамодель соответствует следующему коду:
class TestClass
{
void test(int a, int b)
{
int x = (a + b) * 4;
System.out.println(x);
}
}Одной из приятных особенностей Spoon является то, что он упрощает синтаксическое дерево (удаляя и добавляя узлы) для того, чтобы с ним было проще работать. При этом гарантируется семантическая эквивалентность упрощенной метамодели исходной.
Для нас это означает, например, что не нужно больше заботиться о пропуске лишних скобок при обходе дерева. Помимо этого, каждое выражение помещается в блок, раскрываются импорты, производятся еще некоторые похожие упрощения.
Например, такой код:
for (int i = ((0)); (i < 10); i++)
if (cond)
return (((42)));будет представлен следующим образом:
for (int i = 0; i < 10; i++)
{
if (cond)
{
return 42;
}
}На основе синтаксического дерева производится так называемый pattern-based анализ. Это поиск ошибок в исходном коде программы по известным шаблонам кода с ошибкой. В простейшем случае анализатор ищет в дереве места, похожие на ошибку, согласно правилам, описанным в соответствующей диагностике. Количество подобных шаблонов велико и их сложность может сильно варьироваться.
Простейшим примером ошибки, обнаруживаемой с помощью pattern-based анализа, может служить следующий код из проекта jMonkeyEngine:
if (p.isConnected()) {
log.log(Level.FINE, "Connection closed:{0}.", p);
}
else {
log.log(Level.FINE, "Connection closed:{0}.", p);
}Блоки then и else оператора if полностью совпадают, скорее всего, имеется логическая ошибка.
Вот еще один подобный пример из проекта Hive:
if (obj instanceof Number) {
// widening conversion
return ((Number) obj).doubleValue();
} else if (obj instanceof HiveDecimal) { // <=
return ((HiveDecimal) obj).doubleValue();
} else if (obj instanceof String) {
return Double.valueOf(obj.toString());
} else if (obj instanceof Timestamp) {
return new TimestampWritable((Timestamp)obj).getDouble();
} else if (obj instanceof HiveDecimal) { // <=
return ((HiveDecimal) obj).doubleValue();
} else if (obj instanceof BigDecimal) {
return ((BigDecimal) obj).doubleValue();
}В данном коде находятся два одинаковых условия в последовательности вида if (....) else if (....) else if (....). Стоит проверить этот участок кода на наличие логической ошибки, либо убрать дублирующий код.
Data-flow analysis
Помимо синтаксического дерева и семантической модели, анализатору необходим механизм анализа потока данных.
Анализ потока данных позволяет вычислять допустимые значения переменных и выражений в каждой точке программы и, благодаря этому, находить ошибки. Мы называем эти допустимые значения виртуальными значениями.
Виртуальные значения создаются для переменных, полей классов, параметров методов и прочего при первом упоминании. Если это присваивание, механизм Data Flow вычисляет виртуальное значение путем анализа выражения стоящего справа, в противном случае в качестве виртуального значения берется весь допустимый диапазон значений для данного типа переменной. Например:
void func(byte x) // x: [-128..127]
{
int y = 5; // y: [5]
...
}При каждом изменении значения переменной механизм Data Flow пересчитывает виртуальное значение. Например:
void func()
{
int x = 5; // x: [5]
x += 7; // x: [12]
...
}Механизм Data Flow также выполняет обработку управляющих операторов:
void func(int x) // x: [-2147483648..2147483647]
{
if (x > 3)
{
// x: [4..2147483647]
if (x < 10)
{
// x: [4..9]
}
}
else
{
// x: [-2147483648..3]
}
...
}В данном примере при входе в функцию о диапазоне значений переменной x нет никакой информации, поэтому он устанавливается в соответствии с типом переменной (от -2147483648 до 2147483647). Затем первый условный блок накладывает ограничение x > 3, и диапазоны объединяются. В результате в then блоке диапазон значений для x: от 4 до 2147483647, а в else блоке от -2147483648 до 3. Аналогичным образом обрабатывается и второе условие x < 10.
Кроме того, необходимо иметь возможность производить и чисто символьные вычисления. Простейший пример:
void f1(int a, int b, int c)
{
a = c;
b = c;
if (a == b) // <= always true
....
}Здесь переменной а присваивается значение c, переменной b также присваивается значение c, после чего а и b сравниваются. В этом случае, чтобы найти ошибку, достаточно просто запомнить кусок дерева, соответствующий правой части.
Вот чуть более сложный пример с символьными вычислениями:
void f2(int a, int b, int c)
{
if (a < b)
{
if (b < c)
{
if (c < a) // <= always false
....
}
}
}В таких случаях уже приходится решать систему неравенств в символьном виде.
Механизм Data Flow помогает анализатору находить ошибки, которые с помощью pattern-based анализа найти весьма затруднительно.
К таким ошибкам относятся:
- Переполнения;
- Выход за границу массива;
- Доступ по нулевой или потенциально нулевой ссылке;
- Бессмысленные условия (always true/false);
- Утечки памяти и ресурсов;
- Деление на 0;
- И некоторые другие.
Data Flow анализ особенно важен при поиске уязвимостей. Например, в случае, если некая программа получает ввод от пользователя, есть вероятность, что ввод будет использован для того, чтобы вызвать отказ в обслуживании, или для получения контроля над системой. Примерами могут служить ошибки, приводящие к переполнениям буфера при некоторых входных данных, или, например, SQL-инъекции. В обоих случаях для того, чтобы статический анализатор мог выявлять подобные ошибки и уязвимости, необходимо отслеживать поток данных и возможные значения переменных.
Должен сказать, что механизм анализа потока данных — это сложный и обширный механизм, а в этой статье я коснулся лишь самых основ.
Рассмотрим несколько примеров ошибок, которые можно обнаружить с помощью механизма Data Flow.
Проект Hive:
public static boolean equal(byte[] arg1, final int start1,
final int len1, byte[] arg2,
final int start2, final int len2) {
if (len1 != len2) { // <=
return false;
}
if (len1 == 0) {
return true;
}
....
if (len1 == len2) { // <=
....
}
}Условие len1 == len2 выполняется всегда, поскольку противоположная проверка уже была выполнена выше.
Еще один пример из этого же проекта:
if (instances != null) { // <=
Set<String> oldKeys = new HashSet<>(instances.keySet());
if (oldKeys.removeAll(latestKeys)) {
....
}
this.instances.keySet().removeAll(oldKeys);
this.instances.putAll(freshInstances);
} else {
this.instances.putAll(freshInstances); // <=
}Здесь в блоке else гарантированно происходит разыменование нулевого указателя. Примечание: здесь instances — это то же самое, что и this.instances.
Пример из проекта JMonkeyEngine:
public static int convertNewtKey(short key) {
....
if (key >= 0x10000) {
return key - 0x10000;
}
return 0;
}Здесь переменная key сравнивается с числом 65536, однако, она имеет тип short, а максимально возможное значение для short — это 32767. Соответственно, условие никогда не выполняется.
Пример из проекта Jenkins:
public final R getSomeBuildWithWorkspace()
{
int cnt = 0;
for (R b = getLastBuild();
cnt < 5 && b ! = null;
b = b.getPreviousBuild())
{
FilePath ws = b.getWorkspace();
if (ws != null) return b;
}
return null;
}В данном коде ввели переменную cnt, чтобы ограничить количество проходов пятью, но забыли ее инкрементировать, в результате чего проверка бесполезна.
Механизм аннотаций
Кроме того, анализатору нужен механизм аннотаций. Аннотации — это система разметки, которая предоставляет анализатору дополнительную информацию об используемых методах и классах, помимо той, что может быть получена путем анализа их сигнатуры. Разметка производится вручную, это долгий и трудоемкий процесс, так как для достижения наилучших результатов необходимо проаннотировать большое количество стандартных классов и методов языка Java. Также имеет смысл выполнить аннотирование популярных библиотек. В целом аннотации можно рассматривать как базу знаний анализатора о контрактах стандартных методов и классов.
Вот небольшой пример ошибки, которую можно обнаружить с помощью аннотаций:
int test(int a, int b) {
...
return Math.max(a, a);
}В данном примере из-за опечатки в качестве второго аргумента метода Math.max была передана та же переменная, что и в качестве первого аргумента. Такое выражение является бессмысленным и подозрительным.
Зная о том, что аргументы метода Math.max всегда должны быть различны, статический анализатор сможет выдать предупреждение на подобный код.
Забегая вперед, приведу несколько примеров нашей разметки встроенных классов и методов (код на C++):
Class("java.lang.Math")
- Function("abs", Type::Int32)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Returns(Arg1, [](const Int &v)
{ return v.Abs(); })
- Function("max", Type::Int32, Type::Int32)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotEquals(Arg1, Arg2)
.Returns(Arg1, Arg2, [](const Int &v1, const Int &v2)
{ return v1.Max(v2); })
Class("java.lang.String", TypeClassification::String)
- Function("split", Type::Pointer)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotNull(Arg1))
.Returns(Ptr(NotNullPointer))
Class("java.lang.Object")
- Function("equals", Type::Pointer)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotEquals(This, Arg1))
Class("java.lang.System")
- Function("exit", Type::Int32)
.Set(FunctionClassification::NoReturn)Пояснения:
- Class – аннотируемый класс;
- Function – метод аннотируемого класса;
- Pure – аннотация, показывающая, что метод является чистым, т.е. детерминированным и не имеющим побочных эффектов;
- Set – установка произвольного флага для метода.
- FunctionClassification::NoDiscard – флаг, означающий, что возвращаемое значение метода обязательно должно быть использовано;
- FunctionClassification::NoReturn – флаг, означающий, что метод не возвращает управление;
- Arg1, Arg2, ..., ArgN – аргументы метода;
- Returns – возвращаемое значение метода;
- Requires – контракт на метод.
Стоит отметить, что помимо ручной разметки существует еще один подход к аннотированию – автоматический вывод контрактов на основе байт-кода. Понятно, что такой подход позволяет вывести только определенные виды контрактов, но зато он дает возможность получать дополнительную информацию вообще из всех зависимостей, а не только из тех, что были проаннотированы вручную.
К слову, уже существует инструмент, который умеет выводить контракты вроде @Nullable, NotNull на основе байт-кода – FABA. Насколько я понимаю, производная от FABA используется в IntelliJ IDEA.
Сейчас мы тоже рассматриваем возможность добавления анализа байт-кода для получения контрактов для всех методов, так как эти контракты могли бы хорошо дополнить наши ручные аннотации.
Диагностические правила при работе часто обращаются к аннотациям. Помимо диагностик, аннотации использует механизм Data Flow. Например, используя аннотацию метода java.lang.Math.abs, он может точно вычислять значение для модуля числа. При этом писать какой-либо дополнительный код не приходится – только правильно разметить метод.
Рассмотрим пример ошибки из проекта Hibernate, которую можно обнаружить благодаря аннотации:
public boolean equals(Object other) {
if (other instanceof Id) {
Id that = (Id) other;
return purchaseSequence.equals(this.purchaseSequence) &&
that.purchaseNumber == this.purchaseNumber;
}
else {
return false;
}
}В данном коде метод equals() сравнивает объект purchaseSequence с самим собой. Наверняка это опечатка и справа должно быть that.purchaseSequence, а не purchaseSequence.
Как доктор Франкенштейн собирал из частей анализатор
Поскольку сами по себе механизмы Data Flow и аннотаций не сильно привязаны к определенному языку, было принято решение переиспользовать эти механизмы из нашего C++ анализатора. Это позволило нам в короткие сроки получить всю мощь ядра C++ анализатора в нашем Java анализаторе. Кроме того, на это решение также повлияло и то, что эти механизмы были написаны на современном C++ с кучей метапрограммирования и шаблонной магии, а, соответственно, не очень хорошо подходят для переноса на другой язык.
Для того, чтобы связать Java часть с ядром на C++, мы решили использовать SWIG (Simplified Wrapper and Interface Generator) – средство для автоматической генерации врапперов и интерфейсов для связывания программ на C и C++ с программами, написанными на других языках. Для Java SWIG генерирует код на JNI (Java Native Interface).
SWIG отлично подходит для случаев, когда имеется уже большой объем C++ кода, который необходимо интегрировать в Java проект.
Приведу минимальный пример работы со SWIG. Предположим, у нас есть C++ класс, который мы хотим использовать в Java проекте:
CoolClass.h
class CoolClass
{
public:
int val;
CoolClass(int val);
void printMe();
};CoolClass.cpp
#include <iostream>
#include "CoolClass.h"
CoolClass::CoolClass(int v) : val(v) {}
void CoolClass::printMe()
{
std::cout << "val: " << val << '\n';
}Сперва нужно создать интерфейсный файл SWIG с описанием всех экспортируемых функций и классов. Также в этом файле при необходимости производятся дополнительные настройки.
Example.i
%module MyModule
%{
#include "CoolClass.h"
%}
%include "CoolClass.h"После этого можно запускать SWIG:
$ swig -c++ -java Example.iОн сгенерирует следующие файлы:
- CoolClass.java – класс, с которым мы будем непосредственно работать в Java проекте;
- MyModule.java – класс модуля, в который помещаются все свободные функции и переменные;
- MyModuleJNI.java – Java врапперы;
- Example_wrap.cxx – С++ врапперы.
Теперь нужно просто добавить получившиеся .java файлы в Java проект и .cxx файл в C++ проект.
Наконец, нужно скомпилировать C++ проект в виде динамической библиотеки и подгрузить ее в Java проект с помощью System.loadLibary():
App.java
class App {
static {
System.loadLibary("example");
}
public static void main(String[] args) {
CoolClass obj = new CoolClass(42);
obj.printMe();
}
}Схематически это можно представить следующим образом:
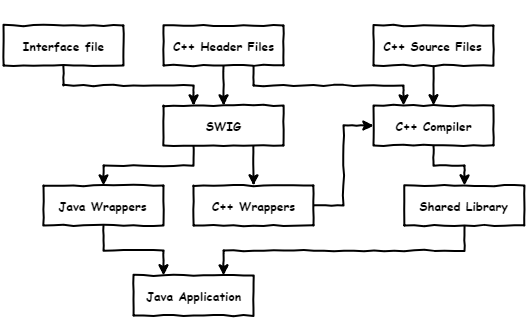
Конечно, в реальном проекте все не настолько просто и приходится приложить чуть больше усилий:
- Для того, чтобы использовать шаблонные классы и методы из C++, их нужно инстанцировать для всех принимаемых шаблонных параметров с помощью директивы %template;
- В некоторых случаях может понадобиться перехватывать исключения, которые выбрасываются из C++ части в Java части. По умолчанию SWIG не перехватывает исключения из C++ (возникает segfault), однако, имеется возможность это сделать, используя директиву %exception;
- SWIG позволяет расширять плюсовый код на стороне Java, используя директиву %extend. Мы, например, в нашем проекте добавляем к виртуальным значениям метод toString(), чтобы можно было их просмотреть в отладчике Java;
- Для того, чтобы эмулировать RAII поведение из C++, во всех интересующих классах реализуется интерфейс AutoClosable;
- Механизм директоров позволяет использовать кросс-языковый полиморфизм;
- Для типов, которые аллоцируются только внутри C++ (на своём пуле памяти), убираются конструкторы и финализаторы, чтобы повысить производительность. Сборщик мусора будет игнорировать эти типы.
Подробнее обо всех этих механизмах можно почитать в документации SWIG.
Наш анализатор собирается при помощи gradle, который зовет CMake, который, в свою очередь, зовет SWIG и собирает C++ часть. Для программистов это происходит практически незаметно, так что никаких особых неудобств при разработке мы не испытываем.
Ядро нашего C++ анализатора собирается под Windows, Linux, macOS, так что Java анализатор также работает в этих ОС.
Что из себя представляет диагностическое правило?
Сами диагностики и код для анализа мы пишем на Java. Это обусловлено тесным взаимодействием со Spoon. Каждое диагностическое правило является визитором, у которого перегружаются методы, в которых обходятся интересующие нас элементы:

Например, так выглядит каркас диагностики V6004:
class V6004 extends PvsStudioRule
{
....
@Override
public void visitCtIf(CtIf ifElement)
{
// if ifElement.thenStatement statement is equivalent to
// ifElement.elseStatement statement => add warning V6004
}
}Плагины
Для максимально простой интеграции статического анализатора в проект мы разработали плагины для сборочных систем Maven и Gradle. Пользователю остается только добавить наш плагин к проекту.
Для Gradle:
....
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
outputFile = 'path/to/output.json'
....
}Для Maven:
....
<plugin>
<groupId>com.pvsstudio</groupId>
<artifactId>pvsstudio-maven-plugin</artifactId>
<version>0.1</version>
<configuration>
<analyzer>
<outputFile>path/to/output.json</outputFile>
....
</analyzer>
</configuration>
</plugin>После этого плагин самостоятельно получит структуру проекта и запустит анализ.
Помимо этого, мы разработали прототип плагина для IntelliJ IDEA.
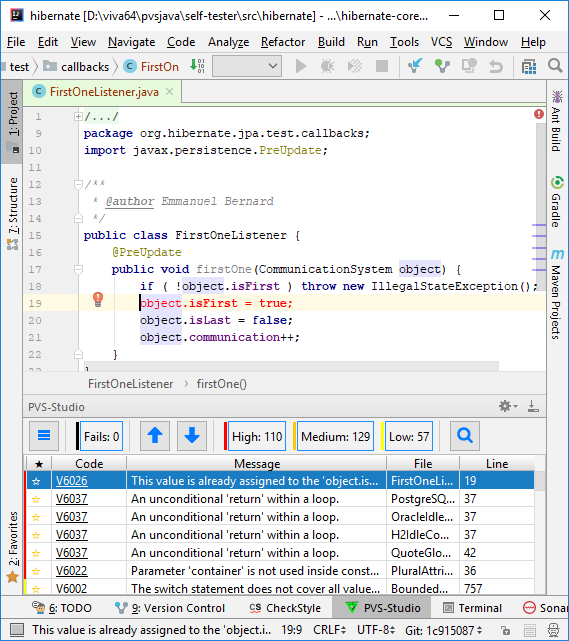
Также этот плагин работает и в Android Studio.
Плагин для Eclipse сейчас находится в стадии разработки.
Инкрементальный анализ
Мы предусмотрели режим инкрементального анализа, который позволяет проверять только измененные файлы и тем самым значительно сокращает время, необходимое для анализа кода. Благодаря этому, разработчики смогут запускать анализ так часто, как это необходимо.
Инкрементальный анализ включает в себя несколько этапов:
- Кеширование метамодели Spoon;
- Перестроение изменившейся части метамодели;
- Анализ изменившихся файлов.
Наша система тестирования
Для тестирования Java анализатора на реальных проектах мы написали специальный инструментарий, позволяющий работать с базой открытых проектов. Он был написан на коленке^W Python + Tkinter и является кроссплатформенным.
Он работает следующим образом:
- Тестируемый проект определенной версии выкачивается с репозитория на GitHub;
- Выполняется сборка проекта;
- В pom.xml или build.gradle добавляется наш плагин (при помощи git apply);
- Выполняется запуск статического анализатора при помощи плагина;
- Получившийся отчет сравнивается с эталоном для этого проекта.
Такой подход гарантирует, что хорошие срабатывания не пропадут в результате изменения кода анализатора. Ниже показан интерфейс нашей утилиты для тестирования.
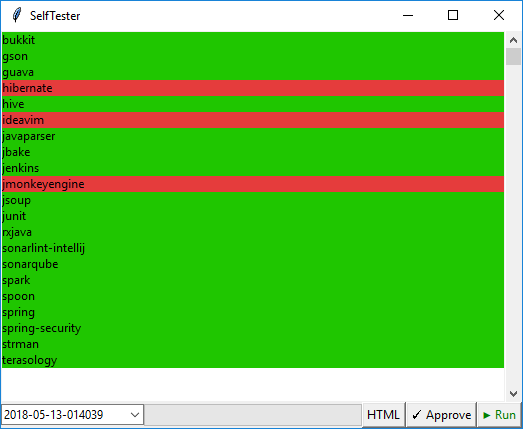
Красным отмечаются те проекты, в отчетах которых есть какие-либо различия с эталоном. Кнопка Approve позволяет сохранить текущую версию отчета в качестве эталона.
Примеры ошибок
По традиции приведу по несколько ошибок из разных открытых проектов, которые нашел наш Java анализатор. В будущем планируется написание статей с более детальным отчетом по каждому проекту.
Проект Hibernate
Предупреждение PVS-Studio: V6009 Function 'equals' receives odd arguments. Inspect arguments: this, 1. PurchaseRecord.java 57
public boolean equals(Object other) {
if (other instanceof Id) {
Id that = (Id) other;
return purchaseSequence.equals(this.purchaseSequence) &&
that.purchaseNumber == this.purchaseNumber;
}
else {
return false;
}
}В данном коде метод equals() сравнивает объект purchaseSequence с самим собой. Скорее всего, это опечатка и справа должно быть that.purchaseSequence, а не purchaseSequence.
Предупреждение PVS-Studio: V6009 Function 'equals' receives odd arguments. Inspect arguments: this, 1. ListHashcodeChangeTest.java 232
public void removeBook(String title) {
for( Iterator<Book> it = books.iterator(); it.hasNext(); ) {
Book book = it.next();
if ( title.equals( title ) ) {
it.remove();
}
}
}Срабатывание, аналогичное предыдущему – справа должно быть book.title, а не title.
Проект Hive
Предупреждение PVS-Studio: V6007 Expression 'colOrScalar1.equals(«Column»)' is always false. GenVectorCode.java 2768
Предупреждение PVS-Studio: V6007 Expression 'colOrScalar1.equals(«Scalar»)' is always false. GenVectorCode.java 2774
Предупреждение PVS-Studio: V6007 Expression 'colOrScalar1.equals(«Column»)' is always false. GenVectorCode.java 2785
String colOrScalar1 = tdesc[4];
....
if (colOrScalar1.equals("Col") &&
colOrScalar1.equals("Column")) {
....
} else if (colOrScalar1.equals("Col") &&
colOrScalar1.equals("Scalar")) {
....
} else if (colOrScalar1.equals("Scalar") &&
colOrScalar1.equals("Column")) {
....
}Здесь явно перепутали операторы и вместо '||' использовали '&&'.
Проект JavaParser
Предупреждение PVS-Studio: V6001 There are identical sub-expressions 'tokenRange.getBegin().getRange().isPresent()' to the left and to the right of the '&&' operator. Node.java 213
public Node setTokenRange(TokenRange tokenRange)
{
this.tokenRange = tokenRange;
if (tokenRange == null ||
!(tokenRange.getBegin().getRange().isPresent() &&
tokenRange.getBegin().getRange().isPresent()))
{
range = null;
}
else
{
range = new Range(
tokenRange.getBegin().getRange().get().begin,
tokenRange.getEnd().getRange().get().end);
}
return this;
}Анализатор обнаружил, что слева и справа от оператора && стоят одинаковые выражения (при этом все методы в цепочке вызовов являются чистыми). Скорее всего, во втором случае необходимо использовать tokenRange.getEnd(), а не tokenRange.getBegin().
Предупреждение PVS-Studio: V6016 Suspicious access to element of 'typeDeclaration.getTypeParameters()' object by a constant index inside a loop. ResolvedReferenceType.java 265
if (!isRawType()) {
for (int i=0; i<typeDeclaration.getTypeParams().size(); i++) {
typeParametersMap.add(
new Pair<>(typeDeclaration.getTypeParams().get(0),
typeParametersValues().get(i)));
}
}Анализатор обнаружил подозрительный доступ к элементу коллекции по константному индексу внутри цикла. Возможно, в данном коде присутствует ошибка.
Проект Jenkins
Предупреждение PVS-Studio: V6007 Expression 'cnt < 5' is always true. AbstractProject.java 557
public final R getSomeBuildWithWorkspace()
{
int cnt = 0;
for (R b = getLastBuild();
cnt < 5 && b ! = null;
b = b.getPreviousBuild())
{
FilePath ws = b.getWorkspace();
if (ws != null) return b;
}
return null;
}В данном коде ввели переменную cnt, чтобы ограничить количество проходов пятью, но забыли ее инкрементировать, в результате чего проверка бесполезна.
Проект Spark
Предупреждение PVS-Studio: V6007 Expression 'sparkApplications != null' is always true. SparkFilter.java 127
if (StringUtils.isNotBlank(applications))
{
final String[] sparkApplications = applications.split(",");
if (sparkApplications != null && sparkApplications.length > 0)
{
...
}
}Проверка на null результата, возвращаемого методом split, бессмысленна, так как этот метод всегда возвращает коллекцию и никогда не возвращает null.
Проект Spoon
Предупреждение PVS-Studio: V6001 There are identical sub-expressions '!m.getSimpleName().startsWith(«set»)' to the left and to the right of the '&&' operator. SpoonTestHelpers.java 108
if (!m.getSimpleName().startsWith("set") &&
!m.getSimpleName().startsWith("set")) {
continue;
}В данном коде слева и справа от оператора && стоят одинаковые выражения (при этом все методы в цепочке вызовов являются чистыми). Скорее всего, в коде присутствует логическая ошибка.
Предупреждение PVS-Studio: V6007 Expression 'idxOfScopeBoundTypeParam >= 0' is always true. MethodTypingContext.java 243
private boolean
isSameMethodFormalTypeParameter(....) {
....
int idxOfScopeBoundTypeParam = getIndexOfTypeParam(....);
if (idxOfScopeBoundTypeParam >= 0) { // <=
int idxOfSuperBoundTypeParam = getIndexOfTypeParam(....);
if (idxOfScopeBoundTypeParam >= 0) { // <=
return idxOfScopeBoundTypeParam == idxOfSuperBoundTypeParam;
}
}
....
}Здесь опечатались во втором условии и вместо idxOfSuperBoundTypeParam написали idxOfScopeBoundTypeParam.
Проект Spring Security
Предупреждение PVS-Studio: V6001 There are identical sub-expressions to the left and to the right of the '||' operator. Check lines: 38, 39. AnyRequestMatcher.java 38
@Override
@SuppressWarnings("deprecation")
public boolean equals(Object obj) {
return obj instanceof AnyRequestMatcher ||
obj instanceof security.web.util.matcher.AnyRequestMatcher;
}Срабатывание аналогично предыдущему – здесь имя одного и того же класса записано разными способами.
Предупреждение PVS-Studio: V6006 The object was created but it is not being used. The 'throw' keyword could be missing. DigestAuthenticationFilter.java 434
if (!expectedNonceSignature.equals(nonceTokens[1])) {
new BadCredentialsException(
DigestAuthenticationFilter.this.messages
.getMessage("DigestAuthenticationFilter.nonceCompromised",
new Object[] { nonceAsPlainText },
"Nonce token compromised {0}"));
}В данном коде забыли добавить throw перед исключением. В результате объект исключения BadCredentialsException создается, но никак не используется, т.е. исключение не выбрасывается.
Предупреждение PVS-Studio: V6030 The method located to the right of the '|' operators will be called regardless of the value of the left operand. Perhaps, it is better to use '||'. RedirectUrlBuilder.java 38
public void setScheme(String scheme) {
if (!("http".equals(scheme) | "https".equals(scheme))) {
throw new IllegalArgumentException("...");
}
this.scheme = scheme;
}В данном коде использование оператора | неоправданно, так как при его использовании правая часть будет вычислена даже в случае, если левая часть уже является истинной. В данном случае это не имеет практического смысла, поэтому оператор | стоит заменить на ||.
Проект IntelliJ IDEA
Предупреждение PVS-Studio: V6008 Potential null dereference of 'editor'. IntroduceVariableBase.java:609
final PsiElement nameSuggestionContext =
editor == null ? null : file.findElementAt(...); // <=
final RefactoringSupportProvider supportProvider =
LanguageRefactoringSupport.INSTANCE.forLanguage(...);
final boolean isInplaceAvailableOnDataContext =
supportProvider != null &&
editor.getSettings().isVariableInplaceRenameEnabled() && // <=
...Анализатор обнаружил, что в данном коде может произойти разыменование нулевого указателя editor. Стоит добавить дополнительную проверку.
Предупреждение PVS-Studio: V6007 Expression is always false. RefResolveServiceImpl.java:814
@Override
public boolean contains(@NotNull VirtualFile file) {
....
return false & !myProjectFileIndex.isUnderSourceRootOfType(....);
}Мне сложно сказать, что имел в виду автор, но такой код выглядит весьма подозрительно. Даже если вдруг ошибки здесь нет, думаю, стоит переписать это место так, чтобы не смущать анализатор и других программистов.
Предупреждение PVS-Studio: V6007 Expression 'result[0]' is always false. CopyClassesHandler.java:298
final boolean[] result = new boolean[] {false}; // <=
Runnable command = () -> {
PsiDirectory target;
if (targetDirectory instanceof PsiDirectory) {
target = (PsiDirectory)targetDirectory;
} else {
target = WriteAction.compute(() ->
((MoveDestination)targetDirectory).getTargetDirectory(
defaultTargetDirectory));
}
try {
Collection<PsiFile> files =
doCopyClasses(classes, map, copyClassName, target, project);
if (files != null) {
if (openInEditor) {
for (PsiFile file : files) {
CopyHandler.updateSelectionInActiveProjectView(
file,
project,
selectInActivePanel);
}
EditorHelper.openFilesInEditor(
files.toArray(PsiFile.EMPTY_ARRAY));
}
}
}
catch (IncorrectOperationException ex) {
Messages.showMessageDialog(project,
ex.getMessage(),
RefactoringBundle.message("error.title"),
Messages.getErrorIcon());
}
};
CommandProcessor processor = CommandProcessor.getInstance();
processor.executeCommand(project, command, commandName, null);
if (result[0]) { // <=
ToolWindowManager.getInstance(project).invokeLater(() ->
ToolWindowManager.getInstance(project)
.activateEditorComponent());
}Подозреваю, что здесь забыли как-либо изменить значение в result. Из-за этого анализатор сообщает о том, что проверка if (result[0]) является бессмысленной.
Заключение
Java направление является весьма разносторонним – это и desktop, и android, и web, и многое другое, поэтому у нас есть большой простор для деятельности. В первую очередь, конечно, будем развивать те направления, что будут наиболее востребованы.
Вот наши планы на ближайшее будущее:
- Вывод аннотаций на основе байт-кода;
- Интеграция в проекты на Ant (кто-то его еще использует в 2018?);
- Плагин для Eclipse (в процессе разработки);
- Еще больше диагностик и аннотаций;
- Совершенствование механизма Data Flow.
Также предлагаю желающим поучаствовать в тестировании альфа-версии нашего Java анализатора, когда она станет доступной. Для этого напишите нам в поддержку. Мы внесем ваш контакт в список и напишем вам, когда подготовим первую альфа-версию.

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Egor Bredikhin. Development of a new static analyzer:
Комментарии (84)

time2rfc
20.06.2018 15:05+7Спасибо что вы наконец пришли в java мир, как всегда приятно читать ваши статьи.
vektory79
20.06.2018 15:44Вы на проект SonarQube смотрели? Там только для Java больше 1700 инспекций...
Ну а если вы таки сможете придумать что-то дополнительно к уже имеющемуся там, то имеет смысл написать плагин для SonarQube, т.к. он является стандартом де-факто в корпоративной среде. Уж коли вы на корпоративный рынок целитесь...
Andrey2008
20.06.2018 15:52+1SonarQube мы смотрели внимательно и уверены, что сможем реализовать более качественные диагностики для поиска ошибок в Java коде. Да, в SonarQube много диагностик на тему «плохого запаха кода». Мы же ориентированы на поиск именно ошибок. Поэтому, мы скорее дополняем его, а не конкурируем с ним. Java анализатор будет встраиваться в SonarQube, как мы уже делаем это для C++ и C#. Некоторые наши клиенты как раз используют PVS-Studio как плагин к SonarQube.
SvyatoslavMC
20.06.2018 16:06Там только для Java больше 1700 инспекций...
Смотрите мой ответ на первый комментарий. И независимо от наличия собственных инструментов анализа, мы рекомендуем использовать совместно разные инструменты контроля качества кода для получения хорошего программного продукта.vektory79
20.06.2018 16:10+1Это-то понятно. Но так же нужно понимать и то, что вы вступаете на рынок, на котором тема статического анализа прорабатывается давно и плотно. И далеко не любителями...
Так что мне будет очень любопытно понаблюдать за развитием событий :-)
Больше статик анализа большого и разного :-)
SvyatoslavMC
20.06.2018 16:16+1вы вступаете на рынок, на котором тема статического анализа прорабатывается давно и плотно.
Ну хоть в какой-то сфере интересна эта тема :D А то сейчас дописываю статью про один игровой движок (С++). Там такое качество кода, что статья получилась крайне эмоциональной.
Andrey2008
20.06.2018 16:07Кстати, непонятно откуда взялось 1700 инспекций для Java. В SonarJava реализовано 440 Rules, из которых 315 это Code Smells.
vektory79
20.06.2018 16:13Не могу сказать куда вы смотрите, но вот прям сейчас у нас в боевом профиле светится цифра 1255. Это при том, что нам не все правила нужны/подходят и очень многое выключено.
vektory79
20.06.2018 16:15+1А… Там не только собственные правила от SonarQube, но и от FindBugs, Checkstyle и PMD. Так что похоже тут наши цифры и разошлись :-)
EgorBredikhin Автор
20.06.2018 16:24+4К слову, пример вполне реальной ошибки, которую нашел наш анализатор в самом проекте SonarQube:
V6029 Possible incorrect order of arguments passed to method: 'parent', 'profile'. InheritanceActionTest.java 254:
private void setParent(QProfileDto profile, QProfileDto parent) { ruleActivator.setParentAndCommit(dbSession, parent, profile); }
RuleActivator.java
public List<ActiveRuleChange> setParentAndCommit( DbSession dbSession, QProfileDto profile, @Nullable QProfileDto parent) { .... }EgorBredikhin Автор
20.06.2018 16:35+4Или вот еще например:
private void setUpdatedAtFromDefinition(@Nullable Long updatedAt) { if (updatedAt != null && updatedAt > definition.getUpdatedAt()) { setUpdatedAt(updatedAt); } } private void setUpdatedAtFromMetadata(@Nullable Long updatedAt) { if (updatedAt != null && updatedAt > definition.getUpdatedAt()) { setUpdatedAt(updatedAt); } }
Что-то мне подсказывает, что здесь скопипастили и забыли во втором случае поменять definition на metadata.
staticlab
20.06.2018 17:59Смотрите по именам переменных и аргументов? Учитывается строгое соответствие, или покажет ошибку даже в каком-нибудь варианте типа (parent, profile) => (profileDto, parentDto)?
EgorBredikhin Автор
20.06.2018 18:38+2На таком варианте тоже будет срабатывание. Мы используем эвристику для определения «похожести».
alexover
20.06.2018 16:43Подозреваю будет верещать возможными NPE в проекте со спрингом видя чтото вроде
@Autowired
private SomeService someService;EgorBredikhin Автор
20.06.2018 16:49+1Сталкивались с подобным, когда разрабатывали maven-плагин:
@Parameter(defaultValue = "${reactorProjects}", readonly = true) private List<MavenProject> reactorProjects;
Так что стараемся учитывать подобный код.
ExplosiveZ
20.06.2018 17:03А для простых смертных будет доступно? А то я слышал, что вам нужно куда-то на почту писать, чтобы получить цены / бесплатную копию.
SvyatoslavMC
20.06.2018 17:10+1Возможности пробного запуска, триальный и бесплатный режимы будут перенесены из C++/C# анализаторов. Если Вы с ними не знакомы, то вкратце: попробовать полноценную версию анализатора сможет любой желающий.
springimport
20.06.2018 17:14Вы не планируете прийти в мир php? Тем более что он в некоторым смысле родственник java.
guai
20.06.2018 21:31-2php… в некоторым смысле родственник java
Позвольте полюбопытствовать, в каком?
У меня только одна версия: php — такое же г… но, как javascript, который в своём названии содержит искомое «java» — бинго :)lovespy
21.06.2018 02:04По моему php для бэкэнда и javascript для фронтэнда — просто удобная связка например для того кто делает все сам. На одной волне.
TheIseAse
21.06.2018 08:59Не хочу поднимать холивар, но почему тогда уж не fullstack javascript, если все равно делать и то, и то?
lovespy
21.06.2018 14:58Тоже не хочу холиваров. Не совсем ясно я выразился. Бекэндом сейчас не занимаюсь, но именно работа на PHP заставила меня пересмотреть мое отношение к javascript. В некоторых моментах дисциплинировало и открыло некоторые возможности о которых я не подозревал. Сорри что не по теме.
imbasoft
20.06.2018 17:54Добрый день.
Есть ли идеи использования нейронных сетей для поиска ошибок в коде?Andrey2008
20.06.2018 17:56+1Нет. И не понятно, где собрать столько ошибок по каждому виду дефекта, чтобы её обучить.
TheIseAse
21.06.2018 09:00reinforcement learning. Пускай нейросеть меняет маленькие кусочки кода и пытается компилировать проект.
extempl
21.06.2018 09:56Так можно ненароком скомпилировать нечто такое, что человек никогда бы не написал (голос ИИ за кадром: МУАХАХАХАХАХА)
SvyatoslavMC
21.06.2018 12:01+1А когда ИИ закончит с улучшением кода, начнёт брать таски из баг-трекера…
Deosis
21.06.2018 12:10В таком случае НС максимум повторит компилятор.
Ошибки в логике компилятор не ищет.
lany
20.06.2018 19:06+4Молодцы, что статью написали! И жалко, что вас на конференцию не взяли (я рекомендовал брать, но не послушали).
Да, FABA — это был проект в JetBrains, и он интегрирован в Идейку. Чистоту методов тоже иногда умеем выводить. И контракты вида null->false. И по сорцам умеем иногда, не только по байткоду. Причём по сорцам на лету в процессе редактирования.
Вопрос: при сравнении строк вы различаете равенство по ссылке и по контенту?
str1.equals(str2) && str1 != str2вы подсветите (ошибочно) как всегда ложное или нет?EgorBredikhin Автор
20.06.2018 20:19+4Да такое мы различаем, благодаря тому, что dataflow взяли из C++. Там ведь возможна аналогичная ситуация:
int *ptr1 = ....; int *ptr2 = ....; if (*ptr1 == *ptr2 && ptr1 != ptr2) { .... }
Если в двух словах, то виртуальные значения для ссылок в Java, это наши виртуальные значения для указателей из C++. А виртуальное значение для указателя может, в свою очередь, содержать «boxed» значение (например целого числа, строки, и т.п.).
Ну и соответственно, в одном случае сравниваются виртуальные значения строк, а в другомуказателейссылок.
esavin
20.06.2018 20:56+1В Enterprise вам придется конкурировать не с SonarQube а с HP Fortify и Veracode. Мне приходилось сталкиваться с обоими системами. По ощущениям — HP Fortify более продвинутый. К примеру, если создается из кусков строк SQL выражение и выполняется просто через statement, то Veracode укажет это как SQL injection (и это может оказаться false positive), а Fortify проанализирует откуда берутся эти куски и, если там нет user input (в любом виде), то SQL injection не будет обнаружен. Если вы будете escap'ить сами user input чтобы избежать SQL injection, то Fortify это может понять, а Veracode — нет.
Далее — Veracod сканирует jar/war/ear файлы и ему не нужны исходники. Fortify встраивается в билд процесс (у нас был maven). Из этого можно сделать выводы, что Veracode просто разбирает Java bytecode, а Fortify получает AST (abstract syntax tree) и уже работает с ним. То есть обе системы не работают напрямую с исходниками и нет необходимости осуществлять синтаксический анализ исходников. По моему мнению это правильный подход, тем более что Java bytecode хорошо описан в спецификации. Я писал программу, которая его разбирает и дошел до команд виртуальной машины. По ощущениям, структура скомпилированного Java class файла достаточно логичная и понятная.
По поводу того, как используется сканер — приложение обязательно должно сканироваться перед релизом и релизить можно только приложения без critical и very height уязвимостей (это идеал, на практике, конечно, бывает по разному). К упомянутым типам уязвимостей относятся XSS, SQL injection, hardcoded passwords. На code smells всем наплевать при сканировании. То есть сканирование — это выявление уязвимостей, которые могут повлиять на безопасность системы. Качество кода не является сколь-нибудь важным на данном этапе.
И еще одно — не знаю как сейчас устроено у HP Fortify, но Veracode предоставляет сервис: вы закачиваете артифакты, Veracode их сканирует, вы получаете отчет (в web системе), в котором указаны найденные проблемы. У вас есть возможность связаться с сотрудниками Veracode, чтобы обсудить найденные уязвимости и пометить их как false positive (при необходимости). То есть это целая инфраструктура, которая не заканчивается на сканере.lany
21.06.2018 03:27+1На уровне байткода анализировать джаву — довольно тупиковый путь. Я писал свой анализатор на байткоде. Некоторые проблемы в принципе не увидишь. Надо быть как можно ближе к исходникам.
Я вот даже не уверен, что автоматическое удаление скобок в Spoon — это хорошая идея. Например,
a << 16 + bпохоже на ошибку: приоритет сложения выше, чем сдвига, а выглядит так будто автор забыл про это. С другой стороны,a << (16 + b)уже выглядит сознательным решением, и тут предупреждать не надо. Если есть дерево без скобок, эту разницу не увидишь. Даже комментарии в коде и отступы очень важны для статического анализа.EgorBredikhin Автор
21.06.2018 09:02Мы в таких отдельных случаях смотрим оригинальный код (spoon запоминает позиции для элементов).
KvanTTT
21.06.2018 10:14+1Я думаю это просто разные модели представления исходного кода. Дейсвтительно, комментарии, отступы, скобки важны для детектирования недостатков, нарушений стиля кода. В то же время они только мешаются во время анализа потоков данных или при использовании еще более глубоких типов анализа (абстрактная интерпретация). Для последних байт-код будет очень кстати.
Как вариант, можно анализировать на разных уровнях. В компиляторном мире, как правило, даже разделяют понятия: дерево разбора (Parse Tree) и абстрактное синтаксическое дерево (AST). Первое вообще может быть преобразовано обратно в код символ-в-символ (full fidelity). Второе не содержит незначимые узлы.lany
21.06.2018 10:29+1У нас в Идейке parse tree с full fidelity, конечно, но это не сильно усложняет потоковый анализ. Конечно, у нас и вычисление типов, и резолв ссылок сделан. В байткоде с этим проще, но и свои минусы есть — erasure. Восстановить generic-сигнатуру бывает очень сложно (эту задачу решают декомпиляторы). С байткодом, кстати, ещё большой минус — привязать предупреждение к конкретному элементу исходника. Там только номера строк есть, если отладочную инфу генерировали. Иногда это сильно усложняет понимание, где же ошибка.
esavin
20.06.2018 21:01И еще одно — в Java есть куча Web framework'ов с которыми Veracode умеет работать. И если для JSP еще можно как-то выкрутиться, скомпилировав в Java код, а дальше анализировать как pure java, то все остальное нужно реализовывать специфичным для данного framework'а образом.
alan008
20.06.2018 21:08+1У вас изначально очень крутой анализатор C++. Потом вы прикрутили C#. Верно ли, что анализатор С# гораздо более слабый по сравнению с С++ анализатором? И это направление вы, похоже, решили не развивать? Как при этом планируется позиционировать Java-анализатор по сравнению с С#: хотите ли проработать направление Java лучше, чем С#?
Andrey2008
20.06.2018 21:29C# анализатор слабее, чем C++. Со временем мы мечтаем улучшить C# анализатор, начав использовать в нём ядро C++, как это мы сразу делаем в Java-анализаторе. Плюс планируем (когда освободятся силу после Java) подобавлять в C# анализатор новые диагностики.
alan008
20.06.2018 22:06А можете еще раз в двух словах (для идиотов) пояснить, что означает использовать С++ ядро для java-анализатора? В статье это как-то очень замысловато описано. И почему не получилось это сделать для С# анализатора?
Andrey2008
20.06.2018 22:15А можете еще раз в двух словах (для идиотов) пояснить, что означает использовать С++ ядро для java-анализатора? В статье это как-то очень замысловато описано.
Как-же в двух словах то объяснить… Целая статья для этого понадобилась. :)
И почему не получилось это сделать для С# анализатора?
Мы были неопытные и решили просто разработать новый анализатор. Про использование одного из другого мы не думали, да и возможно не осилили такое сделать тогда просто в силу трудоёмкости.alan008
20.06.2018 23:21+1Спасибо, так понятнее. Ну, видимо, набив шишек на С#, вы теперь нормально реализуете Java, а потом может и С# переработаете под общую схему. Эксперимент с С# был интересный.
EgorBredikhin Автор
20.06.2018 22:23+2Если еще проще, то мы взяли dataflow анализатор и еще некоторый функционал из C++ анализатора и прикрутили его к Java анализатору (почти как библиотеку).
Про C# я не знаю наверняка, но думаю что на тот момент и инфраструктура C++ анализатора тоже не позволила бы так просто перенести что-либо в C#.

ChessMax
20.06.2018 21:46Плагин для IDEA разрабатывается с учетом Rider-а и C#?
SvyatoslavMC
21.06.2018 09:12Плагин для IDEA достаточно универсален. Возможность запуска PVS-Studio в CLion и Rider будет исследоваться в другой задаче.
ChessMax
21.06.2018 11:30Хотелось бы, что его можно было использовать и в CLion и в Rider. Надеюсь эта задача не уйдет в долгий ящик…
pjBooms
21.06.2018 06:57«В статическом анализе программ многие себе могилу нашли» — © Шелехов В.И., с.н.с. ИСИ СО РАН, занимался статическим анализом как наукой более 20 лет, пытался продавать статический анализатор для Java в начале нулевых :). Хотя конечно есть весьма успешные статические анализаторы.
alxt
21.06.2018 08:33+1Посмотрел несколько примеров- та же IDEA так же находит ошибки.
Вы приходите в мир, где статических анализаторов масса. Покажите примеры ошибок, которые не находят существующие популярные решения. До этого- мысль только «ещё одни решили сделать революцию, а вышел пшик».eliduvid
21.06.2018 09:03+1В посте пару ошибок из самого intellij.
alxt
21.06.2018 09:08Исходники PV просто недоступны для анализа :)
Вопрос именно в обнаружении ошибок. IDEA может это делать бесплатно, да и платно- у неё куча других плюсов. А PVC новый узкоспециализированный продукт- и вопрос, нужен ли он.
lany
21.06.2018 10:31Это ни о чём не говорит. Идейка в сорцах Идейки находит двести тысяч предупреждений. В том числе и те, которые в посте есть. Просто не всегда доходят руки их исправить.
Andrey2008
21.06.2018 10:38Вот именно поэтому, в своих анализаторах мы сосредотачиваемся на поиске ошибок, а не на code smells :). Подробнее я излагал эту мысль в заметке "Философия статического анализатора PVS-Studio".
lany
21.06.2018 10:43Это тут ни при чём. Там и реальных проблем полно, десятки тысяч, и можно сделать профиль инспекций, который только реальные проблемы будет показывать. Особенно с nullability много. Это механически не исправишь, там в каждом месте смотреть надо.
Andrey2008
21.06.2018 10:53+1Ой, тогда я просто не могу немножко не потроллить. Прошу прощение, я не со зла, но не могу удержаться. :)
Т.е. создан статический анализатор кода, которым невозможно пользоваться? Даже сами разработчики не могут настроить его, чтобы использовать результаты его работы в своём проекте?
Вот у нас вывод PVS-Studio на PVS-Studio чистый. И если где-то накосячили, то нам на почту приходит только одно-два предупреждения. :)lany
21.06.2018 10:58+5Почему невозможно? Возможно. Во-первых, у нас кода нереально больше, чем у вас. У нас не статический анализатор, а IDE, которая поддерживает уйму языков и миллион фич вроде интеграции с Git, Docker и чёрт знает что ещё. Во-вторых, я, например, никогда не коммичу жёлтый код. В новом коде от меня варнингов нет. Если я редактирую существующий код, я по возможности заодно исправляю варнинги в нём. Многие поступают так же.
Ну и вы же сами зачем-то поддерживаете режим «показать только свежие предупреждения». По вашей логике, если эта фича востребована, значит, вашим анализатором тоже невозможно пользоваться ;-)
lany
21.06.2018 10:48Ну и code smells — понятие растяжимое. Пример метода equals из Hive в этой статье — вполне себе code smell. Условие избыточно и всегда истинно, но не приводит ни к каким проблемам. Если его убрать, поведение метода не меняется ни при каких входных данных. Так что это не баг.
EgorBredikhin Автор
21.06.2018 11:01Вы точно про этот пример? Здесь перепутали && и ||.
String colOrScalar1 = tdesc[4]; .... if (colOrScalar1.equals("Col") && colOrScalar1.equals("Column")) { .... } else if (colOrScalar1.equals("Col") && colOrScalar1.equals("Scalar")) { .... } else if (colOrScalar1.equals("Scalar") && colOrScalar1.equals("Column")) { .... }
Такой паттерн это же явно баг.lany
21.06.2018 11:03+1Нет, я про другой пример. Нумеруйте их что ли, чтобы ссылаться можно было =)
public static boolean equal(byte[] arg1, final int start1, final int len1, byte[] arg2, final int start2, final int len2) { if (len1 != len2) { // <= return false; } if (len1 == 0) { return true; } .... if (len1 == len2) { // <= .... } }


yanisbiziuk
21.06.2018 10:24Так ждал от вас статический анализатор для Java, но уже перешел на Kotlin.
Буду ждать дальше :)vedenin1980
21.06.2018 11:00Но разве PVS анализирует не байткод? Есть ли разница получен байткод из Java, из Kotlin или Scala?
lany
21.06.2018 11:04+3В статье же всё сказано. Нет, не байткод.
И разница, кстати, большая. Вы огребёте большое количество ложных сработок на котлиновском байткоде, если возьмётесь его анализировать джавовским анализатором байткода. Я пробовал.
asamoilov
21.06.2018 17:30+1Не в тему статьи, но кто-то пользуется статическими анализаторами SQL & PL/SQL? Можете опытом поделиться?
igor_suhorukov
22.06.2018 00:43Использовал sqlcodeguard + sonar-tsql-plugin
Логика tsql была без тестов — проект легаси с человеко-годами техдолга. Масштабы бедствия менеджменту и команде показал, но адекватных действий так и не дождался. Разработчики хранимок так и не использовали этот подход в процессе разработке.
Для PL/SQL мой бывший коллега скрещивал статический анализатор Toad c Sonar, чтобы сэкономить деньги компании на платном плагине. На других проектах максимум что использовали DBA — это юнит тесты для хранимок в Oracle, без статического анализа кода.asamoilov
22.06.2018 14:30Спасибо, Игорь! Пока опыта тоже не густо — разработчикам это не интересно…
Хотя когда находишь что-то при случайном просмотре кодовой базы, некоторые интересуются, каким анализатором пользуюсь…
MzMz
Кроме явных ошибок при программировании есть еще плохие/запрещенные практики: посмотрите на инструменты checkstyle, PMD, findbugs. Ну и было бы очень хорошо, если это будет pure-java решением и не придется тащить платформо-зависимые бинарники.
SvyatoslavMC
Плохие практики и код-стайл не рассматриваются для реализации и в других наших анализаторах. Такое видение продукта: вменяемое кол-во предупреждений на проекте с максимальным процентом найденных реальных ошибок.
lany
Кстати, на коде Идеи у вас вменяемое количество предупреждений? :-)
EgorBredikhin Автор
Да, срабатываний мало, особенно относительно других проектов :)
lany
Ничего себе! У нас только dataflow выдаёт больше 10000 предупреждений, а все включённые инспекции на всём коде Идеи — около 200000. Что с ними делать — абсолютно непонятно :-D
rraderio
фиксить
Andrey2008
Предупреждение != ошибка. Как я понимаю, большинство из этих предупреждений шум (фиксить код смысла нет) и полезное тонет в них. Мы очень опасаемся такой ситуации и внимательно подходим к отбору диагностик.