
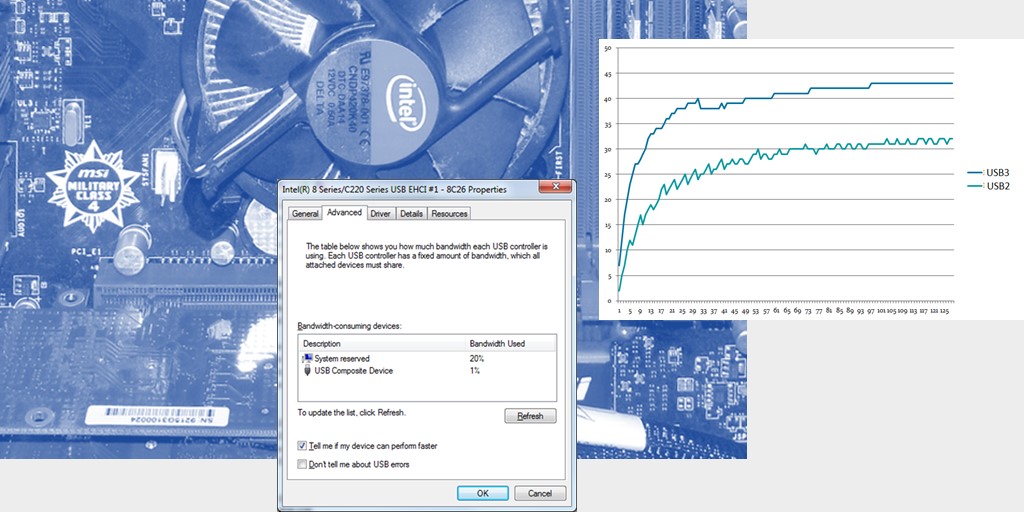
А получается удивительная вещь. Если USB 2.0 устройство воткнуто в «голубенький» разъём (это который USB 3.0), то скорость получается одна. Если в «чёрненький» — другая. Вот мой график зависимости скорости записи в USB от длины передаваемых данных. USB3 и USB2 — это тип разъёма, устройство всегда USB 2.0 HS.
Я пробовал в разных машинах. Результат — близок. Никто не мог объяснить мне этот феномен. Уже потом я нашёл наиболее вероятную причину. А причина очень проста. Вот свойства контроллера USB 2.0:

У контроллеров, управляющих «голубеньким» разъёмом такого нет. А разница — как раз примерно процентов 20.
Из этого мы делаем вывод, что не всегда ограничения пропускной способности определяются физическими свойствами шины. Иногда накладываются ещё какие-то вещи. Переходим с этими знаниями в наши дни.
Первичный эксперимент
Итак. Всё начиналось весьма буднично. Шла проверка одной программы. Проверялся процесс записи данных одновременно на несколько дисков. Аппаратура простая: имеется материнская плата с четырьмя PCIe-слотами. Во все слоты воткнуты совершенно одинаковые карточки с AHCI-контроллерами, каждый из которых поддерживает исключительно PCIe x1.

Каждая карта обслуживает 4 накопителя.
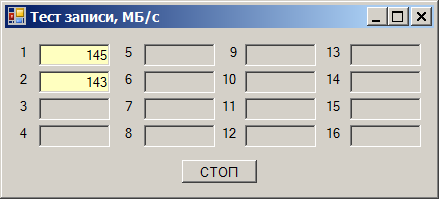
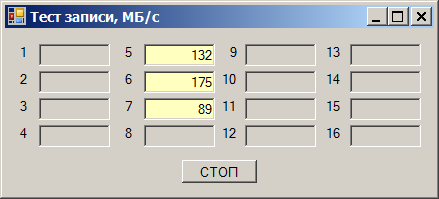
И вот выясняется следующий эффект. Берём один диск и начинаем записывать на него данные. Получаем скорость от 180 до 220 мегабайт в секунду (здесь и далее, мегабайт — это 1024*1024 байт):

Берём второй накопитель. Скорость записи на него — от 170 до 190 МБ/с:

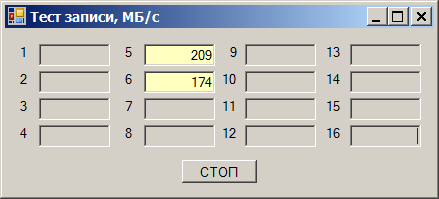
Пишем сразу на оба — получаем просадку скорости:
Суммарная скорость получается в районе 290 МБ/с. Но удивительность состоит в том, что отлаживали (так получилось) эту программу мы на тех же накопителях, но на других каналах. И там всё было хорошо. Быстро перетыкаем в те каналы (они будут идти через другую карту), получаем прекрасную работу:
Куплю слот в хорошем районе
Сразу скажу, что винить во всём какие-то чужие компоненты не стоит. Здесь всё написано нами, начиная от самой программы, заканчивая драйверами. Так что весь путь прохождения данных может быть проконтролирован. Неизвестность наступает только когда запрос ушёл в аппаратуру.
После первичного разбора выяснилось, что скорость не ограничивается в «длинных» слотах PCIe и ограничивается в «коротких». Длинные — это куда можно вставить карты x16 (правда, один из них работает в режиме не выше x4), а короткие — только для карт x1.

Всё бы ничего, но контроллеры в текущих картах в принципе не могут работать в режиме, отличном от PCIex1. То есть, все контроллеры должны быть в абсолютно идентичных условиях, независимо от длины слота! Ан нет. Кто живёт в «длинном» — работает быстро, кто в «коротком» — медленно. Хорошо. А быстро — насколько быстро? Добавляем третий накопитель, пишем на все три.
В «коротких» слотах ограничение всё ещё в районе 290 МБ/с:

В «длинных» — в районе 400 МБ/с:

Я перерыл весь Интернет. Во-первых, через некоторое время я уже смеялся со статей, где говорится о том, что пропускная способность PCIe gen 1 и gen 2 для x1 составляет 250 и 500 МБ/с. Это «сырые» мегабайты. За счёт оверхеда (я использую это нерусское слово, чтобы обозначить служебный обмен, идущий по тем же линиям, что и основные данные) для gen 2 получается именно 400 мегабайт в секунду полезного потока. Во-вторых, я упорно не мог найти ничего про магическую цифру 290 (забегая вперёд — до сих пор не нашёл).
Отлично. Пытаемся глянуть на топологию включения наших контроллеров. Вот она (013-015 — это суффиксы имён устройств, по которым я сопоставил их, чтобы как-то различать). Зелёные —быстрые, красные — медленные.
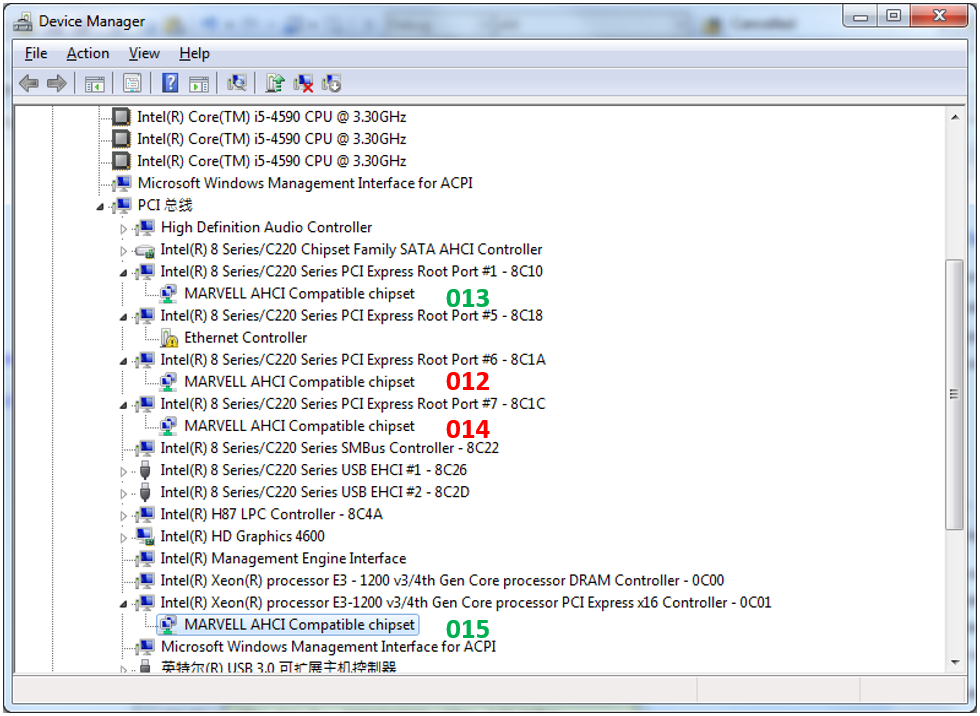
Контроллер «015» мы даже не рассматриваем. Он живёт в привилегированном слоте, предназначенном для видеокарты. Но 013-й подключён к тому же коммутатору, что и 012-й с 014-м. Чем он отличается?
Отдельные статьи говорят, что разные карты могут отличаться параметрами Max Payload. Я изучил конфигурационное пространство всех карт — этот параметр стоит у всех в одном и том же, минимально возможном значении. Мало того, в документации на чипсет этой материнки сказано, что иного значения и быть не может.

В общем, я перерыл всё в конфигурационном пространстве — всё настроено идентично. А скорость разная! Многократно перечитал документацию на чипсет — никаких настроек пропускной способности. Приоритеты — да, что-то про них написано, но тесты же ведутся при полном отсутствии нагрузки по другим каналам! То есть дело не в них.
На всякий случай, я даже отключил работу программы по прерываниям. Нагрузка на процессор возросла до безумных величин, ведь теперь он постоянно тупо читает бит готовности, но показания скорости не изменились. Так что обвинить в проблемах эту подсистему тоже нельзя.
А что там у других плат?
Попробовали поменять материнскую плату на точно такую же. Никаких изменений. Попробовали заменить процессор (были основания считать, что он барахлит). Тоже никаких изменений скорости (но старый процессор и правда барахлил). Поставили материнскую плату более нового поколения — всё просто летает на всех слотах. Причём предельная скорость уже не 400, а 418 мегабайт в секунду, хоть в «длинных», хоть в «коротких» слотах:

Но здесь — никаких чудес. Привычным движением руки (за эти дни уже привык) считываем конфигурационное пространство и видим, что параметр Max Payload установлен не на 128, а на 256 байт.
Больше размер пакета — меньше количество пакетов. Меньше оверхед на их пересылку — больше полезных данных успевает пробежать за то же время. Всё верно.
Так кто же виноват?
Точного ответа на вопрос из заголовка, со ссылкой на документы, я не дам. Но мысль моя пошла по следующему пути: допустим, что ограничение потока задано внутри чипсета. Его нельзя программировать, оно задано намертво, но оно есть. Например, оно равно 290 мегабайт в секунду на каждую дифф. пару. Больше — режется уже где-то внутри чипсета на его внутренних механизмах. Поэтому в «длинном» слоте (куда можно воткнуть карты вплоть до x4) внутри чипсета для нашей карты ничего не режется, а мы упираемся в физический предел шины x1. В «коротком» же разъёме мы упираемся в это ограничение.
На самом деле, проверить это не просто, а очень просто. Втыкаем в 013-й слот не AHCI, а SAS-контроллер, который обслуживает сразу 8 накопителей и может работать в режимах PCIe вплоть до x4. Подключаем ему 4 шустрых SSD накопителя. Смотрим скорость записи — аж душа радуется:

Теперь добавляем те 4 диска, которые фигурировали в первых тестах. Скорость работы SSD предсказуемо просела:

Вычисляем суммарную скорость, проходящую через SAS-контроллер, получаем 1175 мегабайт в секунду. Делим на 4 (столько линий идёт в «длинный» слот), получаем… Барабанная дробь… 293 мегабайта в секунду. Где-то я это число уже видел!
Итак, в рамках данного проекта было доказано, что дело не в нашей программе или драйвере, а в странных ограничениях чипсета, которые наверняка «зашиты» намертво. Была выведена методика подбора материнских плат, которые могут быть использованы в проекте. А в целом, выводы делаем следующие.
Заключение
- Зачастую в реальной жизни аппаратура имеет меньшую производительность, чем теоретически возможная. Ограничения могут накладываться даже драйверами, как показано в случае USB. Иногда удаётся подобрать такую аппаратуру, которая (или драйверы которой) не имеет таких ограничений.
- Ограничения могут быть даже недокументированными, но чётко выраженными.
- Масса статей, в которых говорится, что одна дифференциальная пара PCIe gen. 1 и gen 2 даёт примерно 250 и 500 мегабайт в секунду, ошибочны. Они копируют друг у друга одну и ту же ошибку — мегабайт «сырых» данных в секунду. Оверхед накапливается на нескольких уровнях интерфейса. При Max Payload 128 байт, на PCIe gen2 реально получается около 400 мегабайт в секунду. В более новых поколениях PCIe всё должно быть чуть лучше, так как там физическое кодирование не 8b/10b, а более экономичное, но пока не найдено ни одного контроллера дисков, на которых можно было бы проверить это на практике.
Комментарии (70)

Bedal
22.06.2018 09:31Вот вроде мне и не надо — а понравилось. И стиль изложения, и суть материала познавательная. Спасиб.
imbasoft
22.06.2018 09:33По всей видимости дело реально в чипсетах или их настройках.
Пробовали ли использовать материнки других платформ Intel <-> AMD?EasyLy Автор
22.06.2018 09:55Так взяли другую Intel материнку (более новую) — всё заработало на предельной скорости для 1x. Дальше уже чисто из спортивного интереса собрал снова старую и проверил на восьмиканальном контроллере, работающем в режиме 4x.
HiMem-74
22.06.2018 09:38Вот Вы сейчас одной статьей всколыхнули огромную аудиторию, возможно даже не подозревая об этом.

ShamanR
22.06.2018 09:44Так проблема майнинга не в скорости передачи данных, а в алгоритмах. От/к видеокарт(ам) идёт не такой и большой поток информации.
HiMem-74
22.06.2018 10:05Действительно, это так. Но на тематических форумах идут бурные дискуссии, почему одна и та же видеокарта выдает разную производительность в разных конфигурациях. В частности, (без приведения доказательств и исследований) постулируется, что в х16 слоте скорости на 4-7% выше из-за неких «лагов» в передаче данных. А за такой прирост производительности люди уже готовы биться в кровь.
Ну вот, это исследование уже указывает некоторый путь к оптимизации.BaLaMuTt
22.06.2018 10:31Лаги возможно связаны с тем что в современных ПК линии PCI-E которые идут на слот для ВК обычно идут от самого процессора, а остальные уже через чипсет организованы из-за чего соответственно могут быть и лаги и просадки скорости как у ТС.
yuklimov
22.06.2018 09:46Не удалось найти размеры аппаратных буферов и количества запросов (posted/non-posted/completion), которые может отправить устройство или в устройство до получения подтверждения о их выполнении?
Аппаратные ресурсы ограничены, а протокол PCIe — надежный, поэтому данные должны сохраняться в буфере до тех пор, пока получатель не подтвердит их получение. Размеры буферов для x4 порта должны быть больше, чем для x1, что может дать большую скорость на каких-то шаблонах работы и/или на небольшом payload'е. Кроме размера буфера еще должно влиять его распределение между запросами разного типа. Вы контроллер готовый использовали или как для USB на ПЛИС делали? В ПЛИС можно эти параметры покрутить и посмотреть, к чему это приведет.EasyLy Автор
22.06.2018 09:58Готовый четырёхканальный AHCI контроллер фирмы Marvell. Фирма — известная. Модель чипа — 9215, чип — тоже известный и популярный.
Данные гонял по 8192 сектора на команду. То есть, по 4 мегабайта в блоке.yuklimov
22.06.2018 15:27Я немного про другое. По PCIe ходят пакеты (TLP-пакеты), максимальный размер (вернее, полезный размер) которых и есть payload size. Но уходят пакеты быстро, а подтверждения, что пакет правильно получен и обработан приходят с задержкой. Чтобы это не сказывалось на пропускной способности используется кредитный механизм: когда отправитель может отправить без получения подтверждения только ограниченных объем данных. Это ограничение определяется и суммарным объемом пакетов каждого типа, так и просто количеством. Т.е. при инициализации принимающая сторона сообщает передающей свои ограничения (размер буферов и количества пакетов), а отправляющая гарантированно не посылает больше этого числа, не получив подтверждение.
Раз при перестановке карты в другую мать становится лучше, то значит в самом контроллере Mavell на его приемной стороне буфера нормальные. А вот в чипсете на его приемной стороне для порта x1 буфера недостаточные для получения максимальной скорости. А на порте x4 буфера побольше, что приводит к разумной скорости на x1.
Надо у Интела выбивать информацию, чтобы он рассказал размеры буферов и другие ограничения у своих портов.
В общем, не думаю, что что-то специально режет пропускную способность просто так. Есть вполне осмысленные физические ограничения (размеры буферов), которые с одной стороны дают возможность приемной стороне регулировать скорость поступления пакетов (т.к. не всегда приемная сторона способна работать на полной скорости), а с другой приводят к таким странным замедлениям, когда на этих буферах экономят.
yuklimov
22.06.2018 15:36Если будет время, то посмотрите значение Maximum Read Request Size в PCIe Capabilities. Устройства такого типа обычно работают в режиме DMA — когда устройство само запрашивает данные из памяти. Тогда размер пакета ограничен не Max Payload (это максимальный размер пакета, который процессор может послать в устройство), а Maximum Read Request Size (максимальный размер запроса на чтение из устройства).
EasyLy Автор
22.06.2018 16:27-1Именно чтобы откинуть этот вариант, производились только тесты записи. Данные писались в карты.
yuklimov
22.06.2018 16:34+2Вряд ли процессор сам записывал данные на диск (режим PIO). Это медленно и процессор загружен. Обычно (я дисками не занимаюсь, но это легко проверить: загрузка процессора должна быть минимальна) Marvell сам читал данные из памяти (режим DMA) и сам записывал их на диск (а процессор простаивал).
EasyLy Автор
22.06.2018 19:07Наконец-то до Зоркого Глаза дошло, что от него хотят. Зоркий Глаз — это я.
В документации на чипсет сказано:
Max Read Request Size (MRRS)—RO. Hardwired to 0.
В конфигурационном пространстве там действительно нули у всех портов. У всех — идентично.
Теперь смотрим этот же регистр у Марвеллов.
Там 0x2000. Это 0010000000000000
Интересующие нас биты 010 => 512 байт
Это значение у всех четырёх карт идентично. Короткий слот, длинный… Значения идентичны. Не найдём мы наверняка ничего тут. Я уже пытался… Всё идентично, а поведение — разное.
vzhicharra
22.06.2018 10:02А как определили что процессор барахлит?
Что вызвало подозрения?EasyLy Автор
22.06.2018 10:06Запускаем машину. Нагрузка 13%. Ничего не запущено. Причём это одно ядро почти на 50% нагружено.
Дальше — я деталей не помню. Я зимой разбирался. Нашёл на форумах ссылку на какой-то WDK инструмент (забыл имя), который собирает статистику, кто грузит процессор.
Запустил, пособирал. Выяснил, что драйвер USB постоянно в прерывание входит-выходит. Тогда успокоились, так как машина — стенд, который используется не так часто.
Озаботились только сейчас, разбираясь с причинами просадки скорости. После замены материнки, ничего не изменилось. После замены процессора, сразу после загрузки нагрузка на процессор 0%. Ни программные ни аппаратные вещи иные — не менялись.fedorro
22.06.2018 13:25Может просто процессор слабый. У меня неттоп на атоме начинал тормозить при активном использовании Wi-Fi т.к. прерывания отъедали большую часть процессора. Собственно, пропускная способность Wi-Fi упиралась на нем в процессор.
EasyLy Автор
22.06.2018 13:55Который барахлил — i5. Сейчас в этой материнке стоит i3 (других под рукой в нужном корпусе не было)
Машину под это дело специально выбирали помощнее. Не экономили. Собственно, сейчас взяли ещё более крутую, чтобы вопрос закрыть.port443
22.06.2018 19:20Чудеса какие-то. При этом ОС работает и ничего не виснет?
Может быть, что микрокод в процессоре старый?
А точно такой же i5 для теста в той же материнской плате — нельзя попробовать?EasyLy Автор
22.06.2018 19:33При установке ОС — синие экраны. Ранее установленная — работала и не висла.
Я тут в командировке, так что возможности по добыванию железа ограничены тем, что есть у Заказчика. Был i3 — поставили. А так — Заказчика наука вообще не интересует. Нашли решение, плюс доказали повторяемость проблемы на старом железе — мне вообще перестали железки на пробу давать.port443
22.06.2018 19:39+2Понятно. Просто мне, например, «барахлящий» процессор в этой статье не менее интересен, чем сама суть статьи; никогда о таком не слышал. Ошибки — да, но подобных симптомов я ни разу не наблюдал и не слышал.
osipov_dv
22.06.2018 10:29А операционную систему менять не пробовали? Что будет если запустить вашу программу под Wine на линуксе?
EasyLy Автор
22.06.2018 10:32Целевые программа и драйвер жёстко завязаны на Windows. Причём (Заказчику виднее) на WIN7 x64. А подгонялась скорость именно под этот комплект «программа + драйвер». Первична была сдача комплекса…
Karpion
22.06.2018 18:09+1Если Вы хотите выяснить причину тормозов — пробуйте альтернативную операционку (в идеале — FreeDOS). Если же хотите сдать комплекс и забыть — то оставайтесь на Windows.
EasyLy Автор
24.06.2018 08:42Если уж переходить, то на ОСРВ МАКС, так как я являюсь автором статей по работе под ней. Разумеется, под PC она ещё не сделана (и даже не планируется), но в каждой шутке есть доля правды.
Пока — пусть будет Windows, всё же работает. Возникла конкретная проблема под конкретным железом. Она решилась. Разбираясь с причинами, я не нашёл никаких публикаций, которые бы подталкивали к выходу, поэтому потерял много времени придумывая эксперименты. Решил опубликовать это дело для тех, кто будет искать в будущем, чтобы они знали какие вещи перебирать в первую очередь.
EasyLy Автор
22.06.2018 10:40Там ещё такое дело. ОС в работе почти не используется. Проекция регистров на память основной программы, дальше — программа сама всем рулит. ОС рулит прерываниями, но я отметил, что пробовал исключать их из работы. Скорости не изменились.
KorDen32
22.06.2018 11:04Знакомая проблема.
Вначале я наткнулся на ограничения по портам SATA (чипсет Z97) — при одновременном чтении-записи на разные порты SATA суммарная скорость упиралась в этак 300 МБ/с, хотя в один порт бенчмарки выдавали 400. На SAS-контроллере, поддерживающем x8, но установленном в слот x4, уперся в схожий с вашим предел.
Самое интересное, что M.2 SSD, упирающийся в лимит PCIe 2.0 x2 на этой материнке, выдает скорости под 800 МБайт/с. Приоритеты? Сейчас хочу взять плату PCIe-M2, чтобы проверить скорость SSD на разъеме x4 на той же материнке.
DMI2 — фактически 4 линии PCIe 2.0 (2ГБайт/с)
На вашей материнке распаяно 6 чипсетных линий… 290*6=1740, т.е. как раз приблизительно лимит DMI2. Таким образом легко предположить, что чипсет ставит пропорциональный общий лимит на каждый разъем PCIe. Остается только вопрос, этот лимит статичный, или динамически изменяется от количества использованных слотов? Из текста не увидел, вы пробовали измерять скорость, когда к материнке подключен только один контроллер, а не 4?EasyLy Автор
22.06.2018 11:16Сейчас уже проверить не смогу, втыкая платы в отдельные слоты. Командировка подходит к концу, нет возможности спокойно вести опыты. Но по крайней мере, когда я вёл проверку — остальные слоты не были нагружены. Кто на скриншотах жёлтый — там идёт обмен. Остальные — пассивны, хоть контроллеры и воткнуты.
Lofer
22.06.2018 12:19Возможно, при больших скоростях/объемах передаваемых данных просто возрастают взимные наводки между электрическими проводниками шины и возрастает количество ошибок при передаче, требуется больше попыток повторной передачи.
Были подобраны параметры чипов и разводки плат так, что бы вероятность этого была минимальна и не приводила к фатальным последствиям.
Опять же, есть некоторые зависимости от потока данных (последовательность 101, 1100 и т.д.) на взаимные наводки. Полагаю, что люди проектировавшие такие решение, знали об этом и заложили некоторые защитные механизмы.
Вот и получились такие результаты.EasyLy Автор
22.06.2018 12:31Ну, собственно, статья — предостережение программистам. Чтобы имели это дело в виду. Я — несколько дней врага искал. Кто прочёл — меньше времени потратит.
Собственно, что делать — тоже теперь ясно. Надеюсь, кому-то сэкономит время.khim
23.06.2018 03:03+1Не очень только понятно — кому. Все эти эффекты наблюдались всегда: то, что у вас есть какой-нибудь Ultra-ATA-66 вовсе не значило, что вы получите вдвое больше, чем у тех, у кого на чипсете только Ultra-ATA-33. И то же самое — с передачей данных на VGA-карту. Разные ISA-карты по скорости легко вдвое могли отличаться. Более того — есть куча сайтов, где разные чипсеты и матерински по этому параметру сравшиваются!
Так что за подход к изучению эффекта можно только похвалить, но за то, что вы о нём не знаете… Тут я просто не понимаю — как так могло получится…
А конкретных табличек со списками «хороших» и плохих чипсетов у вас нет (да и вряд ли удастся есть ресурсы, чтобы их создать), так что неясно как экономия времени-то получится…
EasyLy Автор
22.06.2018 12:29+1Улучил минутку, проверил.
Три слота свободны. В «коротком» слоте торчит одинокая карта.
Лимит — всё те же 290.
quartz64
22.06.2018 12:43>>Масса статей, в которых говорится, что одна дифференциальная пара PCIe gen. 1 и gen 2 даёт примерно 500 мегабайт в секунду, ошибочны.
Не читайте за столом советских газет. Есть же первоисточник — PCI-SIG. С учётом кодирования теоретический потолок получается 250, 500, 984.6 МиБ/с на линию для 1.0, 2.0, 3.0 соответственно.
Дальше в дело вступают другие факторы:
Размер пакета. Если он ограничен 128 байтами, то всё плохо — в пакет добавляется 20–30 байт служебных данных. Во-вторых — DLL-пакеты. В общем, средняя температура по больнице получается на уровне 200/400/800 МиБ/с на линию в идеальных условиях. По крайней мере, с PCIe 3.0 я это регулярно наблюдаю на практике: современные (производительность которых упирается не в ядро, а в PCIe) SAS HBA или RAID, подключаемые к PCEe 3.0 ?8, при достаточном количестве быстрых накопителей упираются в 6 с небольшим ГиБ/с (примеры: HBA Broadcom 9300, 9400, RAID Broadcom многопортовые 9361 и 9460, Adaptec 8-й серии и 3100). Современные NVMe с PCEe 3.0 ?8 (HGST SN260) тоже упираются в 6 с небольшим ГиБ/с с последовательным доступом на больших блоках в теории и на практике.
В-третьих — с чтением всё ещё интереснее. Например, можно покурить вот этот документ от Xilinx.
В-четвёртых — в данном конкретном случае тут присутствуют чипсетные PCIe 2.0 (между процессором и PCH находится DMI 2.0 со своими особенностями и на PCH ещё много чего висит) и процессорные PCIe, которых, ЕМНИП, 16 линий максимум.
В-пятых — для многопроцессорных систем и быстрых накопителей (NVMe) приходится ещё и топологию NUMA учитывать, так же как с памятью.
Inanity
22.06.2018 13:06+1… пропускная способность PCIe gen 1 и gen 2 для x1 составляет 500 МБ/с
Почему вы пишите, что у gen1 и gen2 скорости одинаковые?
PCIe gen1 x1 — 2.5Gb/s (на физ.уровне), т.е. 250MB/s (после 8b/10b)
PCIe gen2 x1 — 5.0Gb/s (на физ.уровне), т.е. 500MB/s (после 8b/10b)EasyLy Автор
22.06.2018 13:07+1Ой, опечатка. Спасибо. Я как-то задумался про 8b/10b, но совсем забыл про скорость. Сейчас буду править.
amarao
22.06.2018 13:31Загрузите линукс и посмотрите на вывод lspci -vvvvvv — там куча служебной информации про используемые протоколы на PCI шине, типы кодирования, количество линий и т.д.
EasyLy Автор
22.06.2018 13:35Да вроде, и под Windows всё видно, если правильными программами пользоваться.
Беда в том, что цифра 290 — не документирована нигде.amarao
22.06.2018 17:08+1Просто интересно было бы посмотреть на вывод. Потому что я там много странного вижу. Вот пример:
09:00.0 USB controller: ASMedia Technology Inc. ASM1042A USB 3.0 Host Controller (prog-if 30 [XHCI]) Subsystem: Dell ASM1042A USB 3.0 Host Controller Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 128 bytes Interrupt: pin A routed to IRQ 18 Region 0: Memory at c4000000 (64-bit, non-prefetchable) [size=32K] Capabilities: <access denied> Kernel driver in use: xhci_hcd 3a:00.0 Network controller: Qualcomm Atheros QCA6174 802.11ac Wireless Network Adapter (rev 32) Subsystem: Bigfoot Networks, Inc. QCA6174 802.11ac Wireless Network Adapter Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0 Interrupt: pin A routed to IRQ 164 Region 0: Memory at dc000000 (64-bit, non-prefetchable) [size=2M] Capabilities: <access denied> Kernel driver in use: ath10k_pci Kernel modules: ath10k_pci
Например, поля Latency и Control…
electronus
22.06.2018 13:52Так всё-же, какая(ие) платы лучшие?
Берите LSI/Avago, там будет 3й Express.EasyLy Автор
22.06.2018 14:00Мы пока не нашли контроллеры, которые бы работали в режиме третьего Express (и были бы приемлемыми по цене: AHCI — это всё-таки не топовая вещь, для топовой — есть на примете очень мощный SAS контроллер).
На какой материнской плате всё работает без тормозов во всех слотах — сейчас не скажу, её утащили. Но точно помню, что память у неё DDR4.
Главная цель написания статьи — просто предупредить программистов. Чтобы прикидывали реальные вещи, не надеясь на цифры из обзорных статей или из теории. Чтобы не пугались ограничений, не искали баги в коде, а проверяли бы то же, что у меня. В общем, цель — проинформировать. А чтобы таблицы составлять — это надо отдельную работу проводить. Может, кто заинтересуется и сделает.electronus
22.06.2018 14:05И не найдете. Некоторые люди, которым нужно было много дисков — заказывают спец материнки со встроенными тремя LSI-ями.
quartz64
22.06.2018 15:44Во все слоты воткнуты совершенно одинаковые карточки с AHCI-контроллерами, каждый из которых поддерживает исключительно PCIe x1.
…и были бы приемлемыми по цене…
Насколько приемлемыми? Какой-нибудь 9305-16i (16-портовый SAS3 HBA, PCIe 3.0 ?8) заменит 4 Ваших контроллера, при этом стоить будет около $100 в пересчёте на каждую «четверть». Конечно, те Марвелы стоят раза в три дешевле, но иногда просто нет выбора.
Магические 290 МиБ/с на линию, которые существенно меньше средних практических 400 МиБ/с для PCIe 2.0 (и тем более 500 МиБ/с теоретических) связаны, как уже упоминали выше, с а) ограничением MPS в 128 байт (в теории может быть до 4096 байт, но ограничен возможностями устройств на данном рут-комплексе) б) это чипсетный PCIe 2.0 (8 линий), до процессора там идёт DMI 2.0, т.е. 2 ГиБ/c на всё, включая набортные SATA и USB. Наверное, под них резервируется полоса.EasyLy Автор
22.06.2018 18:32-1Критерий приемлемости, собственно, выходит за рамки темы. Статья создана, так как я отхватил проблемы, полез искать причины — а их нет нигде. Масса статей с ошибками, а путная — ну разве что тот AppNote от Xilinx. И тот — не по моей теме.
Вот, решил создать хотя бы что-то для тех, кто такое же огребёт. Чтобы знали, что это не у них ошибки, а вот такие приколы. Чтобы пробовали другие слоты. Чтобы пробовали другие материнки. А уж с комментариями — вообще много чего понять можно теперь. Намного больше, чем просто из статьи.
А так — для текущего этапа задачи всё решилось сменой материнки. А приемлемость чипа определяется наличием понятности его программирования напрямую через регистры. AHCI — открытый стандарт. Для SAS — там отдельная тема, но тоже ясно, куда двигаться. Просто не в рамках этой статьи.
Огромное спасибо за раскрытие физических деталей, которые могут влиять на это дело. Пусть все выкладки лежат вместе.
KorDen32
22.06.2018 18:41+1А зачем вам PCIe3.0, если он обычно только в одном слоте GPU? Или вам в принципе нужен 1 контроллер на один ПК в слот GPU?
ktod
22.06.2018 19:04Не увидел ни слова о мостах. А нужно понимать, что в отличии от прародителя, каждый слот PCIe подключен к системной шине через свой собственный мост, ибо, топология у PCIe — точка-точка. А на этих мостах каких только чудес не бывает. Имхо, именно с исследования конфигурационного пространства этих мостов и следует начинать поиск причины подобного рода непоняток.
EasyLy Автор
22.06.2018 19:10Слов нет. Есть скриншот с иерархией подключения. Конфигурационное пространство — полностью идентично в рамках настроек. Собственно, в ответе на самый первый комментарий есть ссылка, где можно все дампы увидеть.
Мало того, три карты подключены к портам одного и того же моста. А поведение — разное.ktod
22.06.2018 19:43Не могут быть все 3 карты подключены к портам одного и того же моста. Еще раз повторяю, что в силу того, что pcie имеет топологию типа точка-точка, каждый слот подключен на свой мост. Этот факт совершенно не виден на приведенном скриншоте. А настройки у этих мостов могут быть совершенно разные, по тем или иным причинам.
EasyLy Автор
22.06.2018 19:56+2А как надо писать?
Да, я понимаю в PCIe только чуточку. Вот SATA и SAS — делал ядра под Альтеру. Так что как идёт гигабитный сигнал — представляю.
Но касаемо портов моста… Вот у нас Intel® 8 Series/C220 Series Chipset Family Platform Controller Hub (PCH). Три карты подключены к линиям, выходящим из него.
Вот в нём имеются устройства, которые в документации называются D28:F0/F1/F2/F3/F4/F5/F6/F7. На иерархии в основной статье видно, что платы воткнуты непосредственно туда. Никаких мостов между ними нет. У меня есть плата, где имеется промежуточный мост, но это — не тот случай.
Ещё там сказано The PCH provides up to 8 PCI Express Root Ports, supporting the PCI Express Base Specification, Revision 2.0. Each Root Port x1 lane supports up to 5 Gb/s bandwidth in each direction (10 Gb/s concurrent). PCI Express Root Ports 1–4 or Ports 5–8 can independently be configured to support multiple port width configurations.
и потом идёт масса таблиц с возможными конфигурациями. Можно пускать линии на разъёмы. Можно — на USB 3.0 контроллеры. Можно — на сетевухи. Можно — менять ширину на разъёмах. Таблиц много, сюда приводить не буду. Но никаких внешних мостов — не требуется. Всё живёт в чипсете. И три разъёма идут — в него. Четвёртый — на скриншоте видно, что идёт мимо. Но три — в него.
Собственно, если я брежу — так разъясните детали. Делов-то. Пока я не вижу бреда. Но на то он и бред, чтобы несущий его, не видел ничего такого.ktod
22.06.2018 20:29+1Линии выходят из чипсета — да. Но(!), в самом чипсете имеется для каждого слота мост. Именно pci-pci bridge, классический. И как их там производитель МП конфигурирует в efi — не угадаешь. Именно поэтому важно, получить всю (!) информацию по топологии шины (sudo lspci -tv) и по конфигурации отдельных устройств, в том числе всех мостов (sudo lspci -vvv). Тогда можно будет, не ковыряясь в дампах, попытаться делать какие либо выводы по ситуации. Повторюсь, имхо, с этого нужно начинать поиск всяких непоняток.
И да, извините, если был где то резок.EasyLy Автор
22.06.2018 21:42Чип — на то и чип, чтобы в нём всё бегало по старым, не добрым параллельным шинам. В моей любимой Альтере сразу после приёмников стоит десериалайзер (с эластичным буфером и ловлей примитива ALIGN). Ну, и перед передатчиками тоже сериалайзер стоит непосредственно. До того — всё в параллельном коде. Я видел наработки знакомых на Xilinx — тоже всё в параллельных шинах реализовано в чипе. Последовательная — только наружу выходит. Рисунок Figure 2-1. PCH Interface Signals Block Diagram (not all signals are on all SKUs) из документации на чипсет также подразумевает общую внутреннюю шину.
Так что всё на иерархии верно. Когда появляются дополнительные мосты — они там видны, просто я сейчас не могу скриншот снять. А с утра — вообще на самолёт. Так что если Вам надо картинку со сложной иерархией мостов — могу постараться в воскресенье снять. А так — поверьте на слово, что тут всё просто идёт. Когда ещё мосты влезают — они там видны. Тем удивительнее тот факт, что три слота включены идентично, а поведение — разное. Но, собственно, причина — наверняка выявлена.
ktod
22.06.2018 19:54+1Ну и да, ковыряться в дампах — это такое себе. Крайне желателен вывод lspci -tv и lspci -vvv для разных случаев.
igor_suhorukov
22.06.2018 19:22Linux пробовали? Так по крайней мере и в исходниках драйвера можно порыться.
EasyLy Автор
22.06.2018 19:26Я же написал в основном текста, что драйвер — наш. Так что тоже можно порыться.
igor_suhorukov
22.06.2018 21:07Так ещё есть драйвера чипсета, pci, iommu, буферизация ОС и тп В windows до таких глубин не добраться, не протрассировать.
EasyLy Автор
22.06.2018 21:45+3Настройки чипсета видны прекрасно. Буферизация ОС отсутствует. Я использую режим Common Buffer DMA. Всё управление железом — с уровня User Mode (кроме прерываний, но я их пробовал отключать и работать по опросу). Всё там прекрасно разбирается. Но увы, три порта настроены полностью идентично, а ведут себя — по-разному. Четвёртый — он стоит особняком, так как воткнут в слот, предназначенный для видеокарты. А три — идентичны.
Solexid
23.06.2018 00:45+2Вполне можно добраться, если знать куда тыкать. Просто многие линуксоиды знают винду не сильно больше обычного юзера. Тот же кернеллог — о его существовании знают единицы.
Jeditobe
23.06.2018 13:58Бывают платы у которых длинные разьемы PCIe — ревизии 2.0 или 3.0, а маленькие почему-то работают по стандарту ревизии 1.0. Очень хорошо коррелирует с полученными вами результатами.
Jeditobe
23.06.2018 14:39Мат.Плата H87M-G43 (MS-7823)
PCI Express Gen 3: World's 1st PCI Express Gen 3 Motherboard Brand
— говорят, что первая в своем роде с третьей версией ревизии. Возможны велосипеды и детские болезни внутри.
www.msi.com/Motherboard/H87M-G43/Specification
Slots
• 1 x PCIe 3.0 x16 slot
• 1 x PCIe 2.0 x16 slot
— PCI_E4 supports up to PCIe 2.0 x4 speed
• 2 x PCIe 2.0 x1 slots
BD9
24.06.2018 02:511. Какая задача-то решалась этим железом?
2. Зачем подключать 16 дисков к плате microATX? Какой корпус будет использоваться?
3. Взяли устаревший ширпотреб и удивляетесь возникшими сложностями?
4. Какой смысл ставить 4 порта SATA на плату с PCI-E 2.0 1x? На камне ASMedia 106x на плате с разъёмом PCI-E 2.0 1x паяют 2 SATA 6 Гбит/с, и даже двух SATA будет много при подключении SSD.
5. Стоит обновить прошивку МП и контроллеров SATA до новейших, и поотключать функции энергосбережения.
6. Как используются 6 каналов SATA 6Гб/с от чипсета? Они дб быстрее, чем с дочерних плат.
7. Что там насчёт RAID? Что там с надёжностью?
8. «Главная цель написания статьи — просто предупредить программистов.» — такое нужно железячникам, не программистам.
9. MSI часто экономят и выпускают изделия низкого инженерного качества. Пробуйте других производителей.
10. Зачем чипсет Intel H87, если Intel Z87 позволяет расщепить процессорные PCI-E 3.0 16x на 8+8 или 8+4+4?
11. Flexible I/O www.intel.com/content/dam/www/public/us/en/documents/datasheets/8-series-chipset-pch-datasheet.pdf#M3.9.42549.02Level.21.Flexible.IO
Возможно понавесили слишком много. Что-то лучше отключить (USB) и пользоваться встроенными портами SATA.
12. Ставьте SAS контроллер. Для SAS есть разветвители и преходники на SATA.EasyLy Автор
24.06.2018 08:14Отвечаю в произвольном порядке, так как в пунтах я запутаюсь.
Это нужно программистам. Во всём виноваты программисты. Пока те не докажут, что сбои не у них. Поэтому не нужно искать, где не оптимальна программа, когда виновата не она. Именно на этом будет сэкономлено время. Программа виновата не всегда оказывается.
Зачем H87 — железо было спущено сверху. Не прокатило — спустили другое. Даташит изучен вдоль и поперёк. Но, собственно, вопрос решился сменой мамки.
Корпус — самодельный. Фото публиковать нельзя. Это ремонтный комплекс. По этой же причине все остальные ограничения на выбор железа. Оно должно быть однородно, оно должно быть хорошо известно. Оно не должно быть ASMedia, так как у неё имеется хорошо изученный баг во время посылки некоторых нестандартных команд.
Antinomy
25.06.2018 06:22Статья очень интересная!
В вашем случае вряд ли помогут прошивки и прочее, скорее всего какая-то особенность конфигурации PCIe. Интересно, что длинный PCIe, сидящий на южном мосту показывает нормальный результат. Возможно, его режим отличается от PCIe 1x, например, дуплекс или сжатие. По нюансам скорости работы PCIe (для подключения внешнего видео) есть неплохой FAQ здесь: forum.notebookreview.com/threads/diy-egpu-experiences.418851
но вашего случая нет.
Раз с процессорными портами проблемы нет, стоит завести это на платформе Intel HEDT (либо AMD), там гораздо больше линий PCI-E и портов, напрямую подключённых к процессору. Либо же поискать PCI-E 3.0 x16 HBA, такие тоже есть. У LSI точно были такие.
autuna
Любопытно стало. Автор, можете снять с материнок информацию при помощи CPU-Z и выложить куда-нибудь?
EasyLy Автор
Добрый день, поделюсь с вами.
yadi.sk/i/jm2TrWJ53YEgGy
1nd1g0
Возможно, на кристалле хаба есть ограничения по суммарной пропускной способности из-за того, что все каналы PCI-Ex зависимы друг от друга и по очереди используют одни и те же не модули кристалла. Если это так, то возможна ситуация, когда слоты свободны, и один из них может работать как 4x, а стоит занять все, выше 1x он подняться не сможет. Для окончательных выводов интересно было бы найти на точно таком же чипсете плату с такой же конфигурацией слотов, но без таких проблем.
EasyLy Автор
Используемые платы — все 1x. Беда в том, что в «коротких» слотах скорость ещё ниже, чем 1x. А в «длинных» — как раз соответствует ожидаемой от 1x.
1nd1g0
Так о том и речь, что полноценных модулей на чипе может быть меньше, чем виртуально предоставляемых процессору линий. Тогда при загрузке нескольких слотов одновременно с работой накопителей и периферии самой платы на таком же интерфейсе возникают просадки даже на 1x.
Кстати, если карты Ваши собственные, и каждой из них доступен полный DMA, не пробовали организовать их общение между собой в обход CPU? Если память быстрая, то можно выяснить практический максимум самой матплаты, максимально исключая издержки на ПО и интерфейсы к CPU.
EasyLy Автор
Карты на Марвелловских чипах.
Запись данных — в режиме DMA, с использованием механизма Common Buffer (который выделяется при старте ОС). Во время теста, записи в этот Common Buffer сейчас не производится. Исходно — производилась (что несколько повышало нагрузку на процессор). Сейчас во время теста процессор показывает единицы процентов загрузки.
Программа при старте проецирует все регистры на свою память, затем — просто работает с оборудованием. Так что все программные нагрузки — минимальны. Прыжков в ядро и обратно — нет. Подготовили команду, заполнили указатель на Common Buffer, поехали гнать 4 мегабайта средствами контроллера. Закончили — делаем то же самое, но для следующего блока LBA…
Из того, что может мешать — драйвер ловит прерывания. Но я пробовал исключать их из работы. На поток — не повлияло.