
Одна крупная добывающая компания пришла с интересной задачей: есть множество площадок с ИТ-системами. Они расположены как в городах, так и на месторождениях. Это несколько десятков региональных офисов плюс добывающие предприятия. На 500 километров в тайге без дороги — легко! На каждом объекте есть оборудование, которое нужно «сложить» в общую инфраструктуру и определить, что и в каком состоянии работает.
Здесь нужна была не просто техническая инвентаризация всех устройств в сети (серийники, версии ПО и пр.), а полноценная система мониторинга. Зачем? Для того чтобы выявлять корневые причины аварий и оперативно об этом предупреждать, строить карты сети, отрисовывать связи между оборудованием, мониторить состояние железа и каналов связи, делать предупреждения по сходу с поддержки или включению нового неучтённого оборудования и т. п. Помимо этого, потребовалась интеграция с CMDB (учётом конфигурационных единиц), чтобы всё железо, которое «нашла» система мониторинга, сравнивалось с тем, что стоит на учёте в конкретном филиале, т. е. по факту находится в сети.
Ещё систему мониторинга нужно было «подружить» с телефонией Астериск, чтобы последняя
в случае каких-то серьёзных нештатных ситуаций типа отключения питания на площадке в Красноярске могла автоматически оперативно дозваниваться ответственным людям. Также была задача разграничить видимость объектов мониторинга и полномочия групп пользователей. Операторы смотрят за оборудованием, Москва — Москву, инженеры на месторождении — только своё месторождение.
Заказчик выбирал между несколькими системами мониторинга: 1) условно-бесплатным продуктом; 2) одним из коммерческих решений; 3) системой Infosim StableNet. В результате тестирования для заказчика стали ясны минусы условно-бесплатного продукта: его долго и сложно настраивать, плюс в нём не было того объёма функционала, который требовался (в части той же, например, отрисовки связей между устройствами в сети). Из коробки он это делать не умеет, а с плагинами получается так себе. У коммерческого продукта не оказалось распределённых агентов мониторинга — это которые устанавливаются на конкретной площадке и контролируют только свой «куст». Соответственно, остановились на Инфосиме — он закрыл все хотелки. И вот благодаря чему.
Вот так выглядит основной экран администратора InfoSim StableNet (это не проект с полезными ископаемыми, а тестовая инфраструктура).
Основной экран, на котором отображается текущее состояние сети:

Слева видна панель управления, в которой мы можем настраивать систему и выводить нужную нам статистику. Например, кнопка Analyzer позволяет вывести статистику по любому параметру, который мы собираем, — в частности, round-trip time за часовой период для конкретной железки.

Кнопка Inventory выводит нам инвентарные данные объектов мониторинга, соседей, MAC-таблицу по каждому устройству, которое есть в системе. Невероятно удобно: облегчается процесс поиска любого параметра оборудования в сети по серийникам, типам оборудования, версиям операционных систем и т. д.

Когда где-то далеко в тайге местные сотрудники, например, поставили новый свитч и никому об этом не сказали, в системе это сразу же стало видно. Это оборудование попадает в специальную ветку в дереве устройств «Новые устройства» и автоматически — в CMDB.

Объекты мониторинга опрашиваются не только на предмет серийников и моделей, но и на загрузку памяти, интерфейсов и т. д. Есть поддержка множества вендоров — в частности, по серверам, СХД, телеком-оборудованию, машинам конечных пользователей. Если чего-то не хватает, заказчик пишет нам или вендору напрямую и новые железки добавляются. Всё просто.

Система интегрируется с MS Active Directory и RADIUS-серверами для общей авторизации и применения групповых политик. Вот так выглядит архитектура системы:
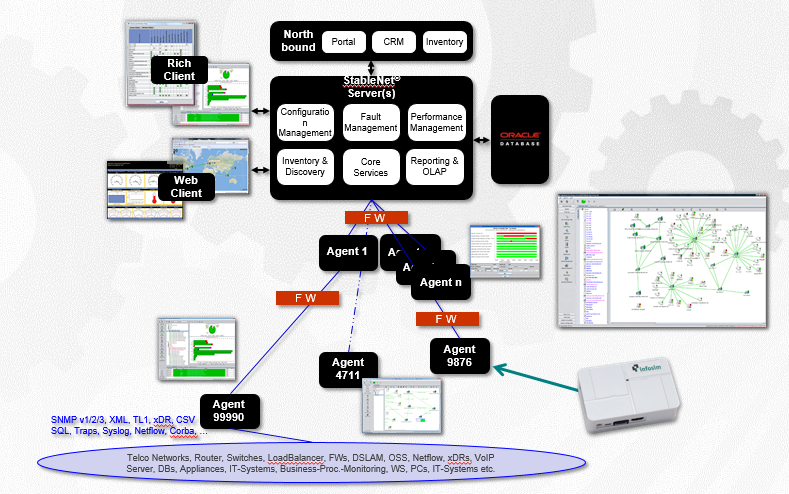
Центральный сервер отвечает за обработку и вывод статистики, собранной с железа.
Второй важный компонент — это агент, отвечающий за опрос оборудования и проверку доступности железа. Агентов (удалённое ПО) может быть несколько, у нас это геораспределённая тема, по агенту на каждую площадку. Нужно это для того, чтобы не гонять сырой трафик телеметрии в головную организацию — у заказчика большое количество площадок подключено по дорогим спутниковым каналам, поэтому отправляется только результат замеров. И база данных для хранения всего того, что собрали.
В случае недоступности удалённой площадки сотрудники на месте могут подключаться напрямую к агенту и видеть состояние своего «куста» сети даже без доступа к центральному серверу.
Агентом может выступать сервер x64/x86 с ОС RedHat, CentOS, Ubuntu, Windows Server (для крупных площадок) или же микроагент на базе маленьких ARM-компьютеров вроде Raspberry PI (для маленьких площадок). Мы не грузим канал пингами железа, это делает агент, и он уже агрегирует пакеты со статистикой.

Ещё мы можем снимать задержку, джиттер, вариации джиттера для оборудования Cisco (IP SLA) и Хуавей (NQA). Поэтому, если в будущем заказчик добавит какое-то другое железо, проблем у компании не возникнет — мы также сможем помочь измерить показатели качества каналов, провести синтетические тесты, нагрузочное тестирование каналов связи между агентами.
Система мониторинга умеет принимать сислог сообщения, SNMP-трапы с железа, фильтровать их и генерировать аварийные сообщения. Она автоматически строит топологию на уровнях L2 и L3, и на основе этого автоматически настраиваются зависимости аварийных ситуаций (root cause analyze). Это очень круто, так как позволяет сообщать администраторам о корневой причине аварии, тем самым снижая время, требуемое для её решения. Например, если в цепочке из пяти свитчей один в середине отвалился, мы получим сообщение, что отвалился третий свитч (root cause), а четвёртый и пятый недоступны из-за этого.

Решение работает из коробки, но процесс можно кастомизировать. Так, например, для облегчения работы нашей техподдержки мы «добавили» статусы состояния бесперебойников и электропитания: если выключается питание на сайте, то вместо 30 тревог мы получаем одну по питанию. Корреляция происходит по топологии, пользователям и правилам.
Есть групповая конфигурация оборудования, можно не просто пассивно опрашивать железо, а раскатывать конфиги типа настроек на коммутаторах. Прописать влан или ntp на 40 коммутаторах? Легко!
А ещё очень круто, что система позволяет заказчику бекапить конфигурацию оборудования по расписанию: раз в сутки собирать конфиги или при событии (например, приходит сислог об изменении конфигурации — можно настроить задание, которое будет отрабатывать момент наступления события и собирать изменённый конфиг). То же самое есть по трапам, по аварийным событиям. Это очень сильно поможет при «разборе полётов» и поиске основных виновников изменения конфигураций. Плюс, по сути, создаётся актуальная база всех конфигураций устройств в сети.
Есть API для интеграции. В нашем проекте была сделана интеграция мониторинга с CMDB 1C:ITIL Управление информационными технологиями предприятия для хранения всей информации об оборудовании (материальных активах). Информация опроса сравнивается с тем, что есть в активах, при обнаружении неучтённого оборудования система говорит: «Вот тут непонятный коммутатор». Выясняют, что это, забивают все необходимые поля — место установки, имя и др. Серийный номер, имя, партийный номер, версия прошивки получается от железа. Далее отправляется задача в мониторинг — изменяется имя железки в системе, выставляется на правильную позицию в дереве локаций, применяются настройки мониторинга в зависимости от типа железки (например, граничное оборудование должно опрашиваться чаще, чем остальное), изменяется хост-нейм на самом устройстве и т. д.
Первым делом мы настроили интеграцию с AD. Это облегчило нам жизнь во время внедрения, а также в последующей эксплуатации. Не надо создавать и удалять учётки для юзеров каждый раз. Система автоматически получит все активные учётки из AD. Если вдруг кто-то уволился, то система сама деактивирует эту учётку у себя и по ней больше никто не сможет зайти.
Для админов и среднего менеджмента очень актуальной задачей было получение множества отчётов. За время запуска были настроены отчёты по утилизации и доступности каналов, по доступности железок на площадках, топ аварийных ситуаций, отчёты по конкретным типам аварий, версии ОС, отчёты по изменениям конфигурации оборудования и др.
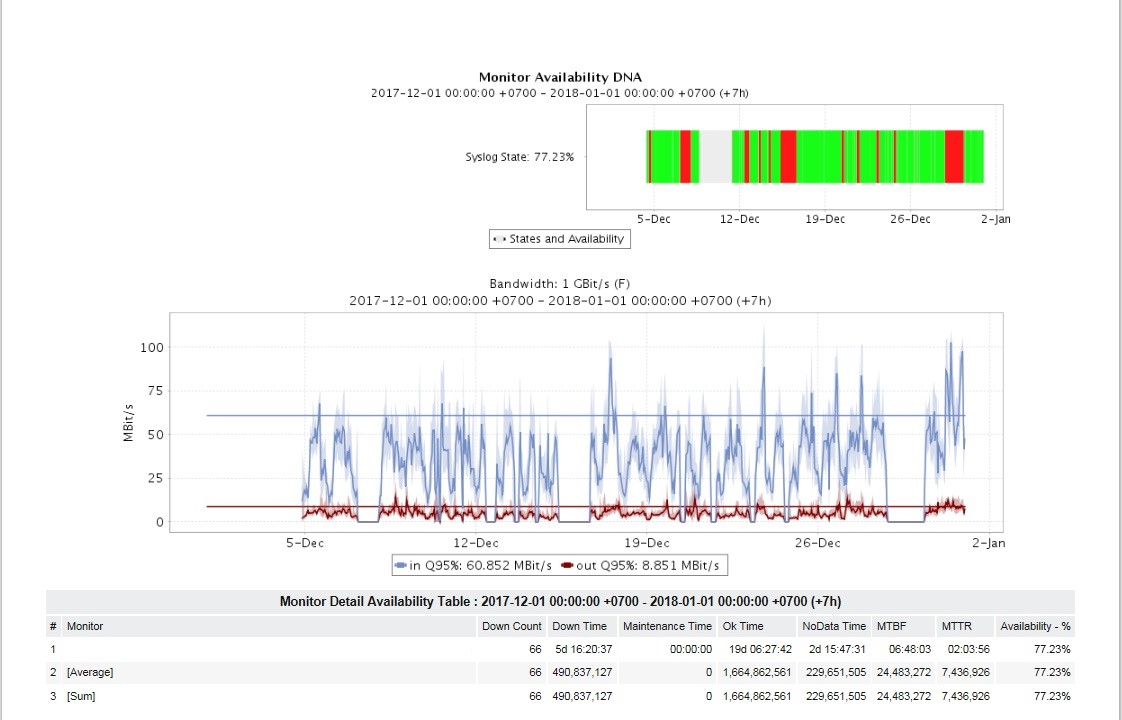
Отчёты можно увидеть в формате HTML, получать их по почте в формате PDF и XLSX с нужной периодичностью (раз в сутки, неделю, месяц и т. п.). Для разных отчётов была настроена своя периодичность и персональная адресность потребителя отчёта.
Система также имеет гибкие возможности по оповещению и выполнению кастомных действий при возникновении аварийных ситуаций, стандартно может отправлять e-mail-сообщения, эсэмэски (используя внешний СМС-шлюз), плюс писать свои скрипты, которые будут запускаться. Например, мы в нашей облачной услуге мониторинга сделали Telegram-бота, который оповещает ответственных сотрудников в нашей службе эксплуатации об аварийных ситуациях. Также его можно опрашивать на предмет разных параметров: «ЦПУ, 10.1.1.100» возвращает «95%», но с учётом поддержки мобильного приложения это может показаться немного избыточным, хотя и удобно.
Далее мы написали скрипт интеграции с телефонной станцией. Теперь при возникновении мегакритичной ситуации (отключении питания на критичных площадках или ЦОД) система названивает ответственным людям на мобильные телефоны и голосом, как у Сири, говорит: «Напряжение на таком-то объекте ниже критической отметки». Делается довольно просто: авария дублируется в определённую папку на телефонной станции, где обрабатывается сервисом телефонии — надо только указать заранее номера, кому звонить автоматом. По сути, мы автоматизировали процесс оповещения ответственных администраторов или руководства при возникновении аварии. Другими словами, заменили человека, который должен позвонить и доложить об аварии.
Очень удобная функция поиска пользователей и железок. Звонит юзер, говорит: «У меня не работает сеть». По его IP-адресу можно сразу увидеть, куда он подключён (какой коммутатор, какой порт, какой мак) и куда он подключён раньше:

Можно строить разного вида графические топологии, которые облегчают жизнь инженерам. Нужно, например, посмотреть, где у нас стоит какой-нибудь коммутатор. Всё просто: нашли его в нужной ветке (или воспользовались поиском) и открыли его соседей. Поддерживается несколько уровней соседства (первый — непосредственные соседи, второй — соседи соседей и т. п.). И сразу видно, где в топологии стоит наш коммутатор, какими портами и куда он подключён, какие мак-адреса у портов. Или же посмотреть карту протоколов OSPF, BGP, EIGRP, STP, PIM, MPLS — система всё это сама обработает и нарисует.

Или же наглядно посмотреть, как себя «чувствует» сеть на одной из площадок. Для удобства мы разделили части WAN и LAN площадок и отрисовываем их отдельными картами. Все индикаторы и линки интерактивны. При наведении на них можно увидеть текущий статус и провалиться в какое-нибудь конкретное устройство. Отдельно хочется обратить внимание, что в качестве подложки такого отчёта используется схема из Microsoft Visio, которую рисовал сам инженер. Он эту схему много раз видел как статичную картинку на бумаге или экране. Теперь она «оживает» и даёт обратную связь в реальном времени. Очень удобно.

В соответствии с требованием заказчика были разграничены права доступа пользователей. Ролей стало много, но они гибко настраиваются. Учитывая разницу часовых поясов между объектами, очень пригодилась фишка рабочих часов в ролях: в какое время, по каким авариям, кому SMS и так далее.
InfoSim StableNet собирает статистику инцидентов. По нашему опыту в таких случаях бывают проблемы с плановыми работами — они портят отчёты и вызывают лишние тревоги. Здесь же можно отметить, что вот тут и тут будут работы: тогда тревоги пойдут в silent-режиме, а в отчёте будет отмечено другим цветом, что данный даунтайм — это план. Да, плановые работы задним числом не объявляются.

Если не хватает возможностей из коробки, можно создавать самописные шаблоны. Например, на проекте были точки доступа Моторолы. Готовых шаблонов под них не было. С помощью встроенного «визарда» мы создали шаблоны и мониторили параметры, которые хотел видеть заказчик (уровень сигнала, соотношение сигнал/шум).
Был и другой случай, когда система «не понимала» одного российского производителя и показывала код производителя вместо имени. На этот случай в системе есть функционал, который позволяет добавить новых вендоров и модели железок за считаные секунды.
Вот тот перечень возможностей, которые заказчику на данный момент позволяет выполнять система мониторинга:
— Байки первой линии поддержки.
— Каналы связи для месторождений полезных ископаемых.
— Моя почта: DDrozhzhin@croc.ru
Здесь нужна была не просто техническая инвентаризация всех устройств в сети (серийники, версии ПО и пр.), а полноценная система мониторинга. Зачем? Для того чтобы выявлять корневые причины аварий и оперативно об этом предупреждать, строить карты сети, отрисовывать связи между оборудованием, мониторить состояние железа и каналов связи, делать предупреждения по сходу с поддержки или включению нового неучтённого оборудования и т. п. Помимо этого, потребовалась интеграция с CMDB (учётом конфигурационных единиц), чтобы всё железо, которое «нашла» система мониторинга, сравнивалось с тем, что стоит на учёте в конкретном филиале, т. е. по факту находится в сети.
Ещё систему мониторинга нужно было «подружить» с телефонией Астериск, чтобы последняя
в случае каких-то серьёзных нештатных ситуаций типа отключения питания на площадке в Красноярске могла автоматически оперативно дозваниваться ответственным людям. Также была задача разграничить видимость объектов мониторинга и полномочия групп пользователей. Операторы смотрят за оборудованием, Москва — Москву, инженеры на месторождении — только своё месторождение.
Заказчик выбирал между несколькими системами мониторинга: 1) условно-бесплатным продуктом; 2) одним из коммерческих решений; 3) системой Infosim StableNet. В результате тестирования для заказчика стали ясны минусы условно-бесплатного продукта: его долго и сложно настраивать, плюс в нём не было того объёма функционала, который требовался (в части той же, например, отрисовки связей между устройствами в сети). Из коробки он это делать не умеет, а с плагинами получается так себе. У коммерческого продукта не оказалось распределённых агентов мониторинга — это которые устанавливаются на конкретной площадке и контролируют только свой «куст». Соответственно, остановились на Инфосиме — он закрыл все хотелки. И вот благодаря чему.
Вот так выглядит основной экран администратора InfoSim StableNet (это не проект с полезными ископаемыми, а тестовая инфраструктура).
Основной экран, на котором отображается текущее состояние сети:
Слева видна панель управления, в которой мы можем настраивать систему и выводить нужную нам статистику. Например, кнопка Analyzer позволяет вывести статистику по любому параметру, который мы собираем, — в частности, round-trip time за часовой период для конкретной железки.
Кнопка Inventory выводит нам инвентарные данные объектов мониторинга, соседей, MAC-таблицу по каждому устройству, которое есть в системе. Невероятно удобно: облегчается процесс поиска любого параметра оборудования в сети по серийникам, типам оборудования, версиям операционных систем и т. д.
Когда где-то далеко в тайге местные сотрудники, например, поставили новый свитч и никому об этом не сказали, в системе это сразу же стало видно. Это оборудование попадает в специальную ветку в дереве устройств «Новые устройства» и автоматически — в CMDB.
Объекты мониторинга опрашиваются не только на предмет серийников и моделей, но и на загрузку памяти, интерфейсов и т. д. Есть поддержка множества вендоров — в частности, по серверам, СХД, телеком-оборудованию, машинам конечных пользователей. Если чего-то не хватает, заказчик пишет нам или вендору напрямую и новые железки добавляются. Всё просто.
Система интегрируется с MS Active Directory и RADIUS-серверами для общей авторизации и применения групповых политик. Вот так выглядит архитектура системы:
Центральный сервер отвечает за обработку и вывод статистики, собранной с железа.
Второй важный компонент — это агент, отвечающий за опрос оборудования и проверку доступности железа. Агентов (удалённое ПО) может быть несколько, у нас это геораспределённая тема, по агенту на каждую площадку. Нужно это для того, чтобы не гонять сырой трафик телеметрии в головную организацию — у заказчика большое количество площадок подключено по дорогим спутниковым каналам, поэтому отправляется только результат замеров. И база данных для хранения всего того, что собрали.
В случае недоступности удалённой площадки сотрудники на месте могут подключаться напрямую к агенту и видеть состояние своего «куста» сети даже без доступа к центральному серверу.
Агентом может выступать сервер x64/x86 с ОС RedHat, CentOS, Ubuntu, Windows Server (для крупных площадок) или же микроагент на базе маленьких ARM-компьютеров вроде Raspberry PI (для маленьких площадок). Мы не грузим канал пингами железа, это делает агент, и он уже агрегирует пакеты со статистикой.
Ещё мы можем снимать задержку, джиттер, вариации джиттера для оборудования Cisco (IP SLA) и Хуавей (NQA). Поэтому, если в будущем заказчик добавит какое-то другое железо, проблем у компании не возникнет — мы также сможем помочь измерить показатели качества каналов, провести синтетические тесты, нагрузочное тестирование каналов связи между агентами.
Система мониторинга умеет принимать сислог сообщения, SNMP-трапы с железа, фильтровать их и генерировать аварийные сообщения. Она автоматически строит топологию на уровнях L2 и L3, и на основе этого автоматически настраиваются зависимости аварийных ситуаций (root cause analyze). Это очень круто, так как позволяет сообщать администраторам о корневой причине аварии, тем самым снижая время, требуемое для её решения. Например, если в цепочке из пяти свитчей один в середине отвалился, мы получим сообщение, что отвалился третий свитч (root cause), а четвёртый и пятый недоступны из-за этого.
Решение работает из коробки, но процесс можно кастомизировать. Так, например, для облегчения работы нашей техподдержки мы «добавили» статусы состояния бесперебойников и электропитания: если выключается питание на сайте, то вместо 30 тревог мы получаем одну по питанию. Корреляция происходит по топологии, пользователям и правилам.
Есть групповая конфигурация оборудования, можно не просто пассивно опрашивать железо, а раскатывать конфиги типа настроек на коммутаторах. Прописать влан или ntp на 40 коммутаторах? Легко!
А ещё очень круто, что система позволяет заказчику бекапить конфигурацию оборудования по расписанию: раз в сутки собирать конфиги или при событии (например, приходит сислог об изменении конфигурации — можно настроить задание, которое будет отрабатывать момент наступления события и собирать изменённый конфиг). То же самое есть по трапам, по аварийным событиям. Это очень сильно поможет при «разборе полётов» и поиске основных виновников изменения конфигураций. Плюс, по сути, создаётся актуальная база всех конфигураций устройств в сети.
Есть API для интеграции. В нашем проекте была сделана интеграция мониторинга с CMDB 1C:ITIL Управление информационными технологиями предприятия для хранения всей информации об оборудовании (материальных активах). Информация опроса сравнивается с тем, что есть в активах, при обнаружении неучтённого оборудования система говорит: «Вот тут непонятный коммутатор». Выясняют, что это, забивают все необходимые поля — место установки, имя и др. Серийный номер, имя, партийный номер, версия прошивки получается от железа. Далее отправляется задача в мониторинг — изменяется имя железки в системе, выставляется на правильную позицию в дереве локаций, применяются настройки мониторинга в зависимости от типа железки (например, граничное оборудование должно опрашиваться чаще, чем остальное), изменяется хост-нейм на самом устройстве и т. д.
Процесс на местах
Первым делом мы настроили интеграцию с AD. Это облегчило нам жизнь во время внедрения, а также в последующей эксплуатации. Не надо создавать и удалять учётки для юзеров каждый раз. Система автоматически получит все активные учётки из AD. Если вдруг кто-то уволился, то система сама деактивирует эту учётку у себя и по ней больше никто не сможет зайти.
Для админов и среднего менеджмента очень актуальной задачей было получение множества отчётов. За время запуска были настроены отчёты по утилизации и доступности каналов, по доступности железок на площадках, топ аварийных ситуаций, отчёты по конкретным типам аварий, версии ОС, отчёты по изменениям конфигурации оборудования и др.
Отчёты можно увидеть в формате HTML, получать их по почте в формате PDF и XLSX с нужной периодичностью (раз в сутки, неделю, месяц и т. п.). Для разных отчётов была настроена своя периодичность и персональная адресность потребителя отчёта.
Система также имеет гибкие возможности по оповещению и выполнению кастомных действий при возникновении аварийных ситуаций, стандартно может отправлять e-mail-сообщения, эсэмэски (используя внешний СМС-шлюз), плюс писать свои скрипты, которые будут запускаться. Например, мы в нашей облачной услуге мониторинга сделали Telegram-бота, который оповещает ответственных сотрудников в нашей службе эксплуатации об аварийных ситуациях. Также его можно опрашивать на предмет разных параметров: «ЦПУ, 10.1.1.100» возвращает «95%», но с учётом поддержки мобильного приложения это может показаться немного избыточным, хотя и удобно.
Далее мы написали скрипт интеграции с телефонной станцией. Теперь при возникновении мегакритичной ситуации (отключении питания на критичных площадках или ЦОД) система названивает ответственным людям на мобильные телефоны и голосом, как у Сири, говорит: «Напряжение на таком-то объекте ниже критической отметки». Делается довольно просто: авария дублируется в определённую папку на телефонной станции, где обрабатывается сервисом телефонии — надо только указать заранее номера, кому звонить автоматом. По сути, мы автоматизировали процесс оповещения ответственных администраторов или руководства при возникновении аварии. Другими словами, заменили человека, который должен позвонить и доложить об аварии.
Очень удобная функция поиска пользователей и железок. Звонит юзер, говорит: «У меня не работает сеть». По его IP-адресу можно сразу увидеть, куда он подключён (какой коммутатор, какой порт, какой мак) и куда он подключён раньше:
Можно строить разного вида графические топологии, которые облегчают жизнь инженерам. Нужно, например, посмотреть, где у нас стоит какой-нибудь коммутатор. Всё просто: нашли его в нужной ветке (или воспользовались поиском) и открыли его соседей. Поддерживается несколько уровней соседства (первый — непосредственные соседи, второй — соседи соседей и т. п.). И сразу видно, где в топологии стоит наш коммутатор, какими портами и куда он подключён, какие мак-адреса у портов. Или же посмотреть карту протоколов OSPF, BGP, EIGRP, STP, PIM, MPLS — система всё это сама обработает и нарисует.
Или же наглядно посмотреть, как себя «чувствует» сеть на одной из площадок. Для удобства мы разделили части WAN и LAN площадок и отрисовываем их отдельными картами. Все индикаторы и линки интерактивны. При наведении на них можно увидеть текущий статус и провалиться в какое-нибудь конкретное устройство. Отдельно хочется обратить внимание, что в качестве подложки такого отчёта используется схема из Microsoft Visio, которую рисовал сам инженер. Он эту схему много раз видел как статичную картинку на бумаге или экране. Теперь она «оживает» и даёт обратную связь в реальном времени. Очень удобно.
В соответствии с требованием заказчика были разграничены права доступа пользователей. Ролей стало много, но они гибко настраиваются. Учитывая разницу часовых поясов между объектами, очень пригодилась фишка рабочих часов в ролях: в какое время, по каким авариям, кому SMS и так далее.
InfoSim StableNet собирает статистику инцидентов. По нашему опыту в таких случаях бывают проблемы с плановыми работами — они портят отчёты и вызывают лишние тревоги. Здесь же можно отметить, что вот тут и тут будут работы: тогда тревоги пойдут в silent-режиме, а в отчёте будет отмечено другим цветом, что данный даунтайм — это план. Да, плановые работы задним числом не объявляются.
Если не хватает возможностей из коробки, можно создавать самописные шаблоны. Например, на проекте были точки доступа Моторолы. Готовых шаблонов под них не было. С помощью встроенного «визарда» мы создали шаблоны и мониторили параметры, которые хотел видеть заказчик (уровень сигнала, соотношение сигнал/шум).
Был и другой случай, когда система «не понимала» одного российского производителя и показывала код производителя вместо имени. На этот случай в системе есть функционал, который позволяет добавить новых вендоров и модели железок за считаные секунды.
Вот тот перечень возможностей, которые заказчику на данный момент позволяет выполнять система мониторинга:
- Мониторить доступность с помощью ICMP-пингов.
- Собирать инфу с помощью SNMP.
- Сканировать подсети на предмет появления нового оборудования.
- Рассылать отчёты по периодам.
- Осуществлять бекапы конфигураций.
- Анализировать доступности.
- «Бить тревогу» по недоступности оборудования или выходу показателей за пределы нормы.
- Выполнять скриптование по SNMP traps как триггерам, данным syslog’а и любым входным данным.
- Интегрироваться с AD.
- Автоматически определять связность устройств (CDP, LLDP, L3 соседство) и на основе этого автоматически рисовать карту сети.
- Создавать «погодные карты» для визуализации состояния сети с возможностью использования графических подложек.
- Создавать рабочие экраны (dashboards) для вывода оперативной информации о состоянии сети и устройств.
- Проводить инвентаризацию оборудования (тип оборудования, производитель, модель, версия ПО, когда настанет дата EoS/EoL и т. д.)
- Есть REST API для глубокой интеграции с CMDB 1C и другими внешними системами.
- Выполнять групповую настройку оборудования из системы мониторинга.
- Проверять конфигурацию устройств на соответствие политикам компании
Ссылки
— Байки первой линии поддержки.
— Каналы связи для месторождений полезных ископаемых.
— Моя почта: DDrozhzhin@croc.ru
Комментарии (6)

multiadmin
29.06.2018 12:03Агентом может выступать… микроагент на базе маленьких ARM-компьютеров вроде Raspberry PI
А можете поподробнее что-то написать про эти микроагенты, по оборудованию? Какие есть возможности, какая ОС, стоимость?
Как оборудование в сравнении с таким продуктом: 3G роутер TELEOFIS RTU968 V2? Это штука на базе OpenWRT, для диапазона температур от -40 до +70, имеет 4 универсальных входа и стоит примерно от 12 тыс. руб. в зависимости от комплектации (опциональны WiFi, GPS и т.п.)DDrozhzhin Автор
02.07.2018 12:02Микроагент создан на базе микро-пк Banana Pro.
OS – Linux Debian Jessy
CRU — ARM Cortex-A7 Dual Core CPU
RAM — 1 GB DDR3 RAM
Storage — 8 GB SD или внешний HDD
1 Gigabit Ethernet Interface
Краткие возможности:
Автономный мониторинг объектов на площадке
Могут выполнять более 1000 тестов на одной «коробке»
Проверка канала на соблюдение SLA (скорость, потери, jitter и т.д.)
Опциональный GSM-модем, для возможности мониторинга при обрыве основных каналов связи.
Этот микроагент не выполняет функций маршрутизации, он включается в КСПД и проводит мониторинг оборудования.
Если нужно подробнее, пишите в личку
dmsav
DDrozhzhin Автор
Проводили сравнение с CA Spectrum. Infosim является полноценной системой мониторинга, включающей fault management, configuration management, инвентаризацию.
Сравнивать можно с многими продуктами.
Касаемо opensource, то тут могу сказать следующее. Заказчик понял, что поддерживать эту систему ему придется самому, постоянно донастраивать, обновлять и разбираться в коде, а у них на это не было ни времени, ни желания. Да и программирование не все знают. Кроме того, недавно нашли серьезные бреши безопасности в одной из популярных бесплатных систем, поэтому как-то больше доверия было к промышленной системе, которая стоит в том числе у операторов связи, для которых сеть — это основной бизнес
dmsav
Понял, спасибо за ответы