
Задача
Полный текст задачи доступен по > ссылке. Вкратце: есть 10 гб данных, где каждая строка содержит три json'а вида «ключ: счетчик», некая категория, некая временная метка и идентификатор пользователя. Одному пользователю может соответствовать множество записей. Требуется определить к какому классу относится пользователь, первому или второму. Метрикой качества для модели является ROC-AUC, о ней отлично написано в блоге Александра Дьяконова[1].
Пример записи в файле
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1}
{"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
Решение
Первая идея, которая возникает у data scientist'а, успешно скачавшего датасет — превратить json-колонки в разреженную матрицу. На этом месте многие участники испытали проблемы с недостатком оперативной памяти. При разворачивании даже одной колонки в питоне потребление памяти было выше, чем это доступно в среднем ноутбуке.
Немного сухой статистики. Количество уникальных ключей в каждой колонке: 2053602, 20275, 1057788. При этом и в трейн-части и в тест части всего лишь: 493866, 20268, 141931. 427994 уникальных пользователей в трейн и 181024 в тест части. Примерно 4% класса 1 в тренировочной части.
Как видим, признаков у нас очень много, использовать их все это явный путь к оверфиту на трейн, потому что, например, решающие деревья используют сочетания признаков, а уникальных сочетаний такого большого количества признаков еще больше и практически все из них существуют только в тренировочной части данных или в тестовых. Тем не менее, одной из базовых моделей у меня был lightgbm с colsample ~0.1 и очень жесткой регуляризацией. Однако, даже не смотря на огромные параметры регуляризации, оно показывало нестабильный результат на публичной и приватной части, как выяснилось после окончания соревнования.
Второй мыслью человека, который решил участвовать в этом соревновании наверняка было бы собрать трейн и тест, агрегируя информацию по идентификаторам. Например, суммой. Или максимумом. И тут выясняется две очень интересные вещи, которые придумал для нас Mail.ru. Во-первых, тест можно классифицировать с очень высокой точностью. Даже по статистикам о количестве записей для cuid и количестве уникальных ключей в json тест значительно превосходит трейн. Базовый классификатор давал 0.9+ roc-auc в распознавании теста. Во-вторых, счетчики не имеют никакого смысла, практически все модели становились лучше от перехода от счетчиков к бинарным признакам вида: есть/нет ключ. Даже деревья, которым по идее не должно быть хуже от того, что вместо единицы стоит какое-то число, похоже переобучались на счетчики.
Результаты на публичном лидерборде сильно превосходил таковые на кросс-валидации. Это было связано, видимо, с тем, что модели было проще построить ранжирование двух записей в тесте, чем в трейне, потому что большее число признаков давало больше слагаемых для ранжирования.
На этом этапе стало окончательно ясно, что валидация в этом соревновании вещь совершенно не простая и ни паблик, ни информация о CV других участников, которую можно было хитростью выманить в официальном чате[2]. Отчего так вышло? Похоже, что трейн и тест разделены по времени, что позже подтвердили организаторы.
Любой опытный участник kaggle сразу посоветует Adversarial validation[3], но все не так просто. Несмотря на то, что точность классификатора на трейн и тест близка к 1 по метрике roc-auc, но похожих на тест записей в трейне не так много. Я пробовал суммировать агрегированные по cuid семплы с одинаковым таргетом, чтобы увеличить количество записей c большим числом уникальных ключей в json, но это давало просадки и на кросс-валидации, и на паблике, и я побоялся использовать такие модели.
Есть два пути: искать вечные ценности с помощью unsupervised learning или пробовать брать более важные именно для теста фичи. Я пошел обоими путями, используя TruncatedSVD для unsupervised и отбор фич по частоте в тесте.
Первым шагом, впрочем, я сделал глубокий autoencoder, но ошибся, взяв два раза одну и ту же матрицу, исправить ошибку и использовать полный набор признаков не удалось: входной тензор не вмещался в память GPU ни при каком размере dense-слоя. Ошибку я нашел и в дальнейшем уже не пробовал кодировать фичи.
SVD я генерировал всеми способами на которые хватало фантазии: на оригинальном датасете с cat_feature и последующим суммированием по cuid. По каждой колонке отдельно. По tf-idf на json как bag-of-words[4] (не помогало).
Для большего разнообразия я пробовал отбирать небольшое число фич в трейне, использую A-NOVA по трейн части каждого фолда на кросс-валидации.
Модели
Основные базовые модели: lightgbm, vowpal wabbit, xgboost, SGD. Кроме этого я использовал несколько архитектур нейронных сетей. Находившийся на первом месте публичного лидерборда участник Дмитрий Никитко советовал использовать HashEmbeddings, эта модель после некоторого подбора параметров показала неплохой результат и улучшила ансамбль.
Еще одна модель нейронной сети с поиском интеракций (factorization machine style) между 3-4-5 колонками данных (три левых входа), численными статистиками (4 вход), SVD матрицы (5 вход).
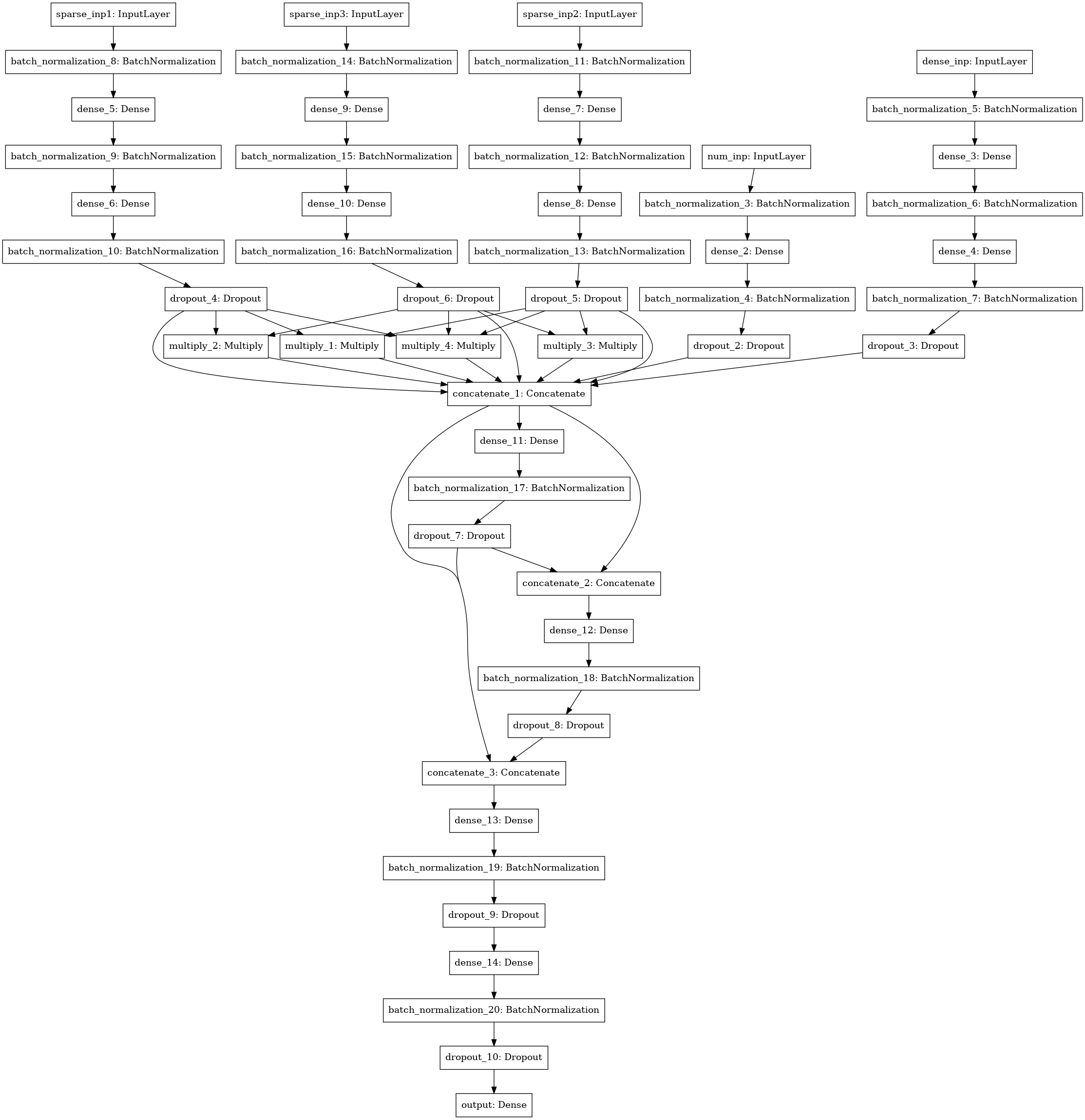
Ансамбль
Все модели я считал по фолдам, усредняя предсказания теста от моделей, тренированных на различных фолдах. Предсказания трейна использовались для стекинга. Лучший результат показал стек 1 уровня с помощью xgboost на предсказаниях базовых моделей и по 250 признаков из каждой json-колонки, отобранные по частоте, с которой встречался признак в тесте.
На решение я потратил ~30 часов своего времени, считал на сервере с 4 ядрами core-i7, 64 гигабайтами оперативной памяти, и одним GTX 1080. В итоге мое решение оказалось довольно стабильным и я поднялся с третьего места публичного лидерборда на первое приватного.
Существенная часть кода доступна на битбакете в виде ноутбуков[5].
Хочу поблагодарить Mail.ru за интересные контесты и других участников за интересное общение в группе!
[1] ROC-AUC в блоге Александрова Дьяконова
[2] Официальный чат ML BootCamp official
[3] Adversarial validation
[4] bag-of-words
[5] исходный код большинства моделей
Комментарии (11)

CrazyElf
31.07.2018 14:10+21) Я пробовал разреженные матрицы. Нет никакой проблемы с памятью, если не переводить матрицы из разреженного формата в обычные матрицы. В scikit-learn есть несколько (штуки четыре) алгоритмов, которые работают прямо с разреженными матрицами, не разворачивая их в памяти. Другое дело, что качество этих алгоритмов оставляло желать лучшего, я попробовал их и выкинул эту идею. В дело шли прямо все возможные «буквы», а качества это не давало. Возможно, надо было попробовать ещё со «словами», но до меня это тогда не дошло.
2) В итоге брал всякие статистики по «буквам», «словам» и «фразам» каждого пользователя, плюс делал суммарный bag of chars и bag of words для каждого cuid. Естественно, пришлось брать только самые частые «символы» и «слова», чтобы влезть в память. В итоге тоже где-то под 300 фич получилось.
3) Дальше я стал стэкать out of fold, но, к сожалению, уже не хватило времени — уехал в отпуск за несколько дней до окончания конкурса, как-раз когда наконец-то какой-то прогресс начал намечаться. А так то хорошо было бы NN ещё попробовать. Ну и постэкать ещё больше вариантов. А так только 92 место, позор какой-то, хотя вроде и «угадал все буквы». %)
Athlon II X4 640, 12Гб озу впритык хватало на 300 фич, один проход по фолдам занимал полчаса. Засабмитил всего что ли три прохода LightGBM по oof с разными сидами, хотел сделать десяток, но из-за глупой ошибки в скрипте уже не успел.

bulnv
31.07.2018 14:12-6Странно видеть, как в 2018, прекрасно мыслящие люди, имеют дела с мэйлру.
roryorangepants
31.07.2018 14:24+1Казалось бы, в чем проблема? Это же просто конкурс по машинному обучению, и какая разница, кто его организует, если, конечно, задача на конкурсе — это не определение оппозиционеров по профилям в соцсетях, например.
bulnv
31.07.2018 15:16Не хотел разводить политический шитпостинг. Проблема для меня, очевидно в том, как результаты работы участников буткэмпа будут использованы. Может быть и таким способом, как вы указали.
Femistoklov
01.08.2018 08:33Ну вот, например, https://habr.com/company/mailru/blog/354456/. Правда, не политика:
Нам предоставили почтовые письма от магазинов с подтверждением сделанных заказов или рассылкой рекламных акций.
sannikovdmitry
31.07.2018 14:54+1В Mail.Ru много классных проектов и людей. Зря вы так, даже с точки зрения троллинга.
bulnv
31.07.2018 15:09Наверняка это так. К людям никаких претензий. Дело в том, как компания использует свои наработки. В данном случае алгоритмы, разработанные участниками буткэмпа. По совести, или нет. В хабрасообществе ценится поддержка коллег (и поэтому меня заминусят), но не стоит путать эту поддержки и совесть.
sergeif Автор
31.07.2018 15:28Я не думаю, что компания использует эти наработки каким-либо образом. Задача учебная, конкурс носит такое название потому что выполняет в основном образовательную функцию и это несомненно благое дело.
bulnv
31.07.2018 15:39+1Требуется определить к какому классу относится пользователь, первому или второму
Вполне реальная задача, с ML в руках MR выглядит пугающе. Я много лет читаю Хабр в режиме ридонли, выполз из тени и не пожалел кармы, чтобы выразить мнение. Считаю, что буквально, только Хабр способен влиять на таких гигантов. Но, раз меня минусят, видимо всех все устраивает. Ну хотя-бы высказался =)roryorangepants
31.07.2018 15:42+2Одно дело — если вам не нравится, как Mail.ru применяет машинное обучение. Тогда так и пишите.
Другое дело — если вам не нравятся вполне конкретные конкурсы от Mail.ru, которые, кстати, весьма ламповые и полезные образовательно, а мейлу в лучшем случае приносят профит в виде рекламы среди потенциальных сотрудников.
decomeron
Поздравляю!
Кто хочет — тот добьется,
Кто ищет — тот всегда найдет!