
В новой версии unity 2018 года наконец официально добавили новую систему Entity component system или сокращенно ECS которая позволяет вместо привычной работы с компонентами объекта работать только с их данными.
Дополнительная же система задач предлагает вам использовать параллельные вычислительные мощности, чтобы улучшить производительность вашего кода.
Вместе эти две новые системы (ECS и Job System) предлагают новый уровень обработки данных.
Конкретно в этой статье я не буду разбирать всю систему ECS, которая пока что доступна в виде отдельно скачиваемого набора инструментов в unity, а рассмотрю только систему задач и как ее можно использовать вне пакета ECS.
Изначально в unity и раньше можно было использовать многопоточные вычисления, но всё это нужно было создавать разработчику самостоятельно, самому решать возникающие проблемы и обходить подводные камни. И если раньше необходимо было работать на прямую с такими вещами как создание потоков, закрытие потоков, пулы, синхронизация, то теперь же вся эта работа легла на плечи движка, а от самого разработчика требуется только создание задач и их выполнение.
Чтобы выполнить какие-либо вычисления в новой системе необходимо использовать задачи которые представляют из себя объекты состоящие из методов и данных для вычисления.
Как и любые другие данные в системе ECS, задачи в Job System также представлены в виде структур которые наследует один из трех интерфейсов.
Самый простой интерфейс задачи содержащий в себе один метод Execute который ничего не принимает в виде параметров и ничего не возвращает.
Сама задача выглядит так:
В методе Execute можно выполнять необходимые вычисления.
Еще один интерфейс с таким же методом Execute который уже в свою очередь принимает числовой параметр index.
Этот интерфейс IJobParallelFor, в отличие от интерфейса IJob, предлагает выполнить задачу несколько раз и не просто выполнить, а разбить это выполнение на блоки которые будут распределены между потоками.
Непонятно? Не переживайте об этом я еще расскажу.
И последний, особый интерфейс, который, как понятно из названия предназначен для работы с данными транформом объекта. Также содержит в себе метод Execute, с числовым параметром index и параметром TransformAccess где находятся позиция, размер и вращение трансформа.
Из-за того что напрямую в задаче нельзя работать с unity объектами, этот интерфейс может обрабатывать данные трансформа только в виде отдельной структуры TransformAccess.
Готово, теперь вы знаете как создаются структуры задач, можно переходить к практике.
Давайте создадим простую задачу унаследованную от интерфейса IJob и выполним ее. Для этого нам понадобится любой простой MonoBehaviour скрипт и сама структура задачи.
Теперь закиньте это скрипт на какой нибудь объект на сцене. В этом же скрипте (TestJob) ниже напишем структуру задачи и не забывайте импортировать нужные библиотеки.
В методе Execute, для примера, выведем простую строку в консоль.
Теперь перейдем в метод Start скрипта TestJob, где создадим экземпляр задачи после чего выполним его.
Если вы проделали всё как в примере, то после запуска игры получите простое сообщение в консоль как на картинке.

Что здесь происходит: после вызова метода Schedule, планировщик помещает задачу в хэндл и теперь ее можно выполнить вызвав метод Complete.
Это был пример задачи которая просто выводила текст в консоль. Чтобы задача выполняла какие-либо параллельные вычисления нужно наполнить ее данными.
Как и в системе ECS в задачах нет доступа к объектам unity, у вас не получиться передать в задачу GameObject и изменить его имя там. Все что вы можете сделать это передать в задачу какие-то отдельные параметры объекта, изменить эти параметры, и после выполнения задачи применить эти изменения обратно объекту.
К самим данным в задаче также есть несколько ограничений: во-первых, это должны быть структуры, во-вторых, это должны быть не преобразуемые типы данных то есть тот же boolean или string вы передать в задачу уже не сможете.
И главное условие: данные не заключенные в контейнер могут быть доступны только внутри задачи!
При работе с многопоточными вычислениями возникает необходимость как то обмениваться данными между потоками. Чтобы можно было передавать в них данные и считывать их обратно в системе задач для этих целей существуют контейнеры. Эти контейнеры представлены в виде обычных структур и работаю по принципу моста по которому элементарные данные синхронизируются между потоками.
Есть несколько видов контейнеров:
NativeArray. Самый простой и самый часто используемый тип контейнера представлен в виде простого массива с фиксированным размером.
NativeSlice. Еще один контейнер — массив, как понятно из перевода, предназначен для нарезания NativeArray на части.
Это два основных контейнера доступных без подключения системы ECS. В более расширенном варианте существует еще несколько видов контейнеров.
NativeList. Представляет собой обычный список данных.
NativeHashMap. Аналог словаря с ключом и значением.
NativeMultiHashMap. Тот же NativeHashMap только с несколькими значениями под одним ключом.
NativeQueue. Список очереди данных.
Так как мы работает без подключения системы ECS то нам доступны только NativeArray и NativeSlice.
Перед тем как перейти к практической части необходимо разобрать самый главный момент — создание экземпляров.
Как я говорил раньше, эти контейнеры представляют собой мост по которым данные синхронизируются между потоками. Система задач открывает этот мост перед началом работы и закрывает после ее завершения. Процесс открытия называется “аллокация” (Allocation) или еще “выделением памяти”, процесс закрытия — “высвобождением ресурсов”(Dispose).
Именно аллокация определяет то как долго задача сможет использовать данные в контейнере — иначе говоря как долго будет открыт мост.
Для того чтобы лучше понять эти два процесса давайте взглянем на картинку ниже.
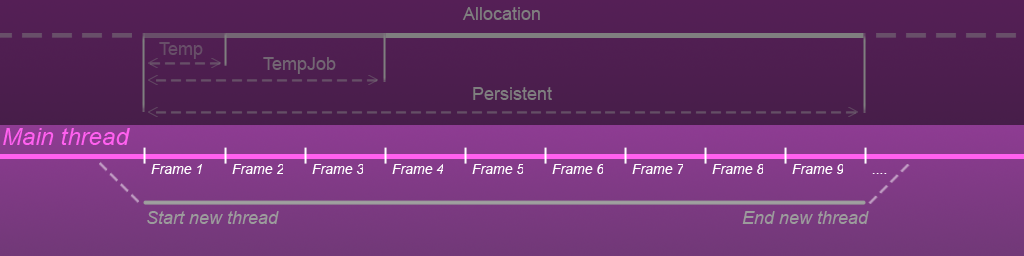
Нижняя ее часть показывает жизненный цикл главного потока(Main thread), который исчисляется в кол-ве кадров, в первом кадре мы создаем еще один параллельный поток(New thread) который существует определенное кол-во кадров и потом благополучно закрывается.
В этот же New thread и поступает задача с контейнером.
Теперь взглянем на верхнюю часть картинки.

Белая полоса Allocation показывает время существования контейнера. В первом кадре происходит аллокация контейнера — открытие моста, до этого момента контейнер не существовал, после выполнения всех расчетов в задаче, контейнер высвобождается из памяти и в 9’ом кадре мост закрывается.
Также на этой полоске (Allocation) есть временные отрезки(Temp, TempJob и Presistent), каждый этот отрезок показывает предположительное время существования контейнера.
Для чего эти отрезки нужны!? Дело в том что выполнение задачи по продолжительности могут быть разные, мы можем выполнять их прямо в том же методе где и создали, или же можем растянуть время выполнения задачи если она достаточно сложная, а эти отрезки показывают как срочно и как долго задача сможет использовать данные в контейнере.
Если все еще не понятно, я разберу каждый тип аллокации на примере.
Теперь можно перейти к практической части создания контейнеров, для этого вернемся в метод Start скрипта TestJob и создадим новый экземпляр контейнера NativeArray и не забывайте подключать нужные библиотеки.
Для создания нового экземпляра контейнера необходимо указать в его конструкторе размер, и тип аллокации. В этом примере используется тип Temp, так как задача будет выполняться только в методе Start.
Теперь инициализируем точно такую же переменную array в самой структуре задачи SimpleJob.
Готово. Теперь можно создать саму задачу и передать в нее экземпляр массива.
Для запуска задачи в этот раз будем использовать ее хэндл JobHandle, чтобы получить его вызовем тот же метод Schedule.
Теперь можно вызывать метод Complete у ее хэндла и проверить выполнена ли задача, чтобы вывести текст в консоль.
Если запустить задачу в таком виде то после запуска игры вы получите жирную красную ошибку о том что не высвободили контейнер array из ресурсов после выполнения задачи.
Примерно такую.

Чтобы этого избежать вызовем метод Dispose у контейнера после выполнения задачи.
После чего можно спокойно запускать заново.
Но задача же ничего не выполняет! — тогда добавим в нее пару действий.
В методе Execute я умножаю индекс каждого элемента массива на самого себя и записываю обратно в массив array, чтобы вывести результат в консоль в методе Start.
Вот так можно создавать контейнеры, помещать их в задачи и выполнять действия над ними.
Это был пример c использованием типа аллокации Temp, который подразумевает выполнение задачи в течении одного кадра. Этот тип лучше использовать когда вам необходимо быстро выполнить вычисления не нагружая главный поток, но нужно быть осторожным если задача будет слишком сложная или если их будет очень много, то могут возникнуть провисания, в этом случае лучше использовать тип TempJob который я разберу далее.
В этом примере я немного изменю структуру задачи SimpleJob и унаследую ее от другого интерфейса IJobParallelFor.
Также раз задача будет выполняться дольше чем один кадр то будем выполнять и собирать результаты задачи в разных методах Awake и Start представленный в виде корутины. Для этого изменим немного внешний вид класса TestJob.
В методе Awake будем создавать задачу и контейнер векторов, а в методе Start выводить полученные данные и высвобождать ресурсы.
Здесь опять создается контейнер array с типом аллокации TempJob, после чего создаем задачу и получаем ее хэндл вызвав метод Schedule с небольшими изменениями.
Первый параметр в методе Schedule указывает сколько раз выполнится задача, здесь то же число что и размер массива array.
Второй параметр указывает на сколько блоков поделить выполнение задачи.
Какие еще блоки?
Раньше для того чтобы выполнить задачу поток просто один раз вызывал метод Execute, теперь же вызвать этот метод нужно 100 раз, поэтому планировщик, чтобы не нагружать какой то отдельный поток, разбивает эти 100 раз повторений на блоки которые распределяет между потоками. В примере сотня повторений будет поделена на 5 блоков по 20 повторений в каждом, то есть предположительно планировщик распределит эти 5 блоков в 5 потоков, где каждый поток вызовит метод Execute 20 раз. На практике конечно не факт что планировщик именно так и поступит, все зависит от загруженности системы, так что может и все 100 повторений произойдут в одном потоке.
Теперь можно вызвать метод Complete у хэндла задачи.
В корутине Start будем проверять выполнение задачи после чего произведем очистку контейнера.
Теперь перейдем к действиям в самой задаче.
После выполнения задачи в методе Start выведем все элементы массива в консоль.
Готово, можно запустить и посмотреть на результат.
Чтобы понять в чем заключается разница между IJob и IJobParallelFor взглянем на изображения ниже.
Для примера можно и в IJob использовать простой цикл for для выполнения вычислений несколько раз, но в любом случае поток сможет только один раз вызвать метод Execute за все время работы задачи — это как заставить одного человека выполнить сотню одних и тех же действий подряд.

IJobParallelFor предлагает не просто выполнить задачу в одном потоке несколько раз, а еще и распределить эти повторения между другими потоками.

В целом тип аллокации TempJob отлично подходит для большинства задач которые выполняются в течении нескольких кадров.
Но что если вам нужно хранить данные даже после выполнения задачи, что если после получения результата их не нужно сразу же уничтожать. Для этого необходимо использовать тип аллокации Persistent, который подразумевает высвобождение ресурсов тогда “когда нужно будет!”.
Опять вернемся в класс TestJob и изменим его. Теперь будем создавать задачи в методе OnEnable, проверять их выполнение в методе Update и зачищать ресурсы в методе OnDisable.
В примере будем двигать объект в методе Update, для расчета траектории будем использовать два векторных контейнера — inputArray в который будем помещать текущее положение и outputArray откуда будем принимать полученные результаты.
Структуру задачи SimpleJob также немного изменим унаследовав ее от интерфейса IJob чтобы выполнить ее один раз.
В саму задачу мы также будем предавать два векторных контейнера, один вектор позиции и числовую дельту, которая будет смещать объект к цели.
Атрибут ReadOnly и WriteOnly показывают потоку ограничения в действиях связанных с данными внутри контейнеров. ReadOnly предлагает потоку только читать данные из контейнера, атрибут WriteOnly наоборот — дает возможность потоку только записывать данные в контейнер. Если вам нужно выполнять сразу два этих действия с одним контейнером тогда не нужно помечать его атрибутом вообще.
Перейдем в метод OnEnable класса TestJob где будут инициализироваться контейнеры.
Размеры контейнеров будут единичными так как нужно передавать и принимать параметры только один раз. Тип аллокации будет Persistent.
В методе OnDisable будем высвобождать ресурсы контейнеров.
Создадим отдельный метод CreateJob где будем создавать задачу с ее хэндлом и там же будем заполнять ее данными.
На самом деле inputArray здесь не особо то и нужен так как можно передавать в задачу и просто вектор направления, но так я думаю будет лучше понятно зачем вообще нужны эти атрибуты ReadOnly и WriteOnly.
В методе Update будем проверять выполнена ли задача, после чего применим полученный результат транформу объекта и снова ее запустим.
Перед запуском немного подправим метод OnEnable так чтобы задача создавалась сразу после инициализации контейнеров.
Готово, теперь можно перейти к самой задаче и выполнить нужные вычисления в методе Execute.
Чтобы увидеть результат работы можно кинуть скрипт TestJob на какой то объект и запустить игру.
Например у меня спрайт просто понемногу смещается вправо.
В общем тип аллокации Persistent отлично подходит для повторно используемых контейнеров, которые нет необходимости каждый раз уничтожать и создавать заново.
Так какой же тип использовать!?
Тип Temp лучше использовать для быстрого выполнения вычислений, но если задача будет слишком сложной и большой могут возникнуть провисания.
Тип TempJob отлично подходит для работы с объектами unity, так можно изменять параметры объектов и применять их, к примеру, в следующем кадре.
Тип Persistent можно использовать тогда когда вам не важна скорость, а просто необходимо постоянно вычислять какие-то данные на стороне, к примеру обрабатывать данные по сети, или работу ИИ.
Отдельно стоит все же разобрать возможности хэндла задачи, ведь кроме как проверять процесс выполнения задачи, этот маленький хэндл еще может создавать целые сети задач через зависимости(хотя я больше предпочитаю называть их очередями).
К примеру если вам нужно выполнить две задачи в определенной последовательности то для этого нужно просто вложить хэндл одной задачи в хэндл другой.
Выглядит это примерно так.

Каждый отдельный хэндл изначально содержит свою задачу, а вот уже при комбинировании получаем новый хэндл с двумя задачами.
Или так.
Последовательность выполнения сохраняется и планировщик не начнет выполнять следующую задачу пока не убедится в выполнении предыдущей, но важно помнить, что свойство хэндла IsCompleted будет ожидать выполнения всех задач находящихся в нем.
Статические данные.
Не пытайтесь использовать статические данные в задаче(Random и другие), любое обращение к статическим данным нарушит безопасность системы. На самом деле в данный момент можно обращаться к статическим данным, но только если вы уверены что они не изменяются в процессе работы — то есть полностью статичны и доступны только для чтения.
Когда использовать систему задач?
Все эти примеры что приведены здесь в статье лишь условные, и показывают как нужно работать с этой системой, а не когда нужно ее использовать. Систему задач можно использовать и без ECS, нужно понимать что система также потребляет ресурсы при работе и, что по любому поводу сразу писать задачи, создавать кучи контейнеров просто бессмысленно — все станет еще хуже. К примеру пересчитать массив размером 10 тысяч элементов будет не правильно — у вас больше времени уйдет на работу планировщика, а вот пересчитать все полигоны огромного террейна или вообще сгенерировать его — правильное решение, можно разбить террейн на задачи и обрабатывать каждую в отдельном потоке.
В общем если вы постоянно занимаетесь сложными вычислениями в проектах и постоянно ищите новые возможности как сделать этот процесс менее ресурсоемким, то Job System это именно то что вам нужно. Если вы постоянно работает со сложными вычислениями неотделимо от объектов и хотите чтобы ваш код работал быстрее и поддерживался на большинстве платформ, то ECS вам точно в этом поможет. Если вы создаете проекты только под WebGL тогда это не для вас, на данный момент Job System не поддерживает работу в браузерах, хотя это уже проблема не юнитеков, а самих разработчиков браузеров.
Исходник со всеми примерами
Дополнительная же система задач предлагает вам использовать параллельные вычислительные мощности, чтобы улучшить производительность вашего кода.
Вместе эти две новые системы (ECS и Job System) предлагают новый уровень обработки данных.
Конкретно в этой статье я не буду разбирать всю систему ECS, которая пока что доступна в виде отдельно скачиваемого набора инструментов в unity, а рассмотрю только систему задач и как ее можно использовать вне пакета ECS.
Новая система
Изначально в unity и раньше можно было использовать многопоточные вычисления, но всё это нужно было создавать разработчику самостоятельно, самому решать возникающие проблемы и обходить подводные камни. И если раньше необходимо было работать на прямую с такими вещами как создание потоков, закрытие потоков, пулы, синхронизация, то теперь же вся эта работа легла на плечи движка, а от самого разработчика требуется только создание задач и их выполнение.
Задачи
Чтобы выполнить какие-либо вычисления в новой системе необходимо использовать задачи которые представляют из себя объекты состоящие из методов и данных для вычисления.
Как и любые другие данные в системе ECS, задачи в Job System также представлены в виде структур которые наследует один из трех интерфейсов.
IJob
Самый простой интерфейс задачи содержащий в себе один метод Execute который ничего не принимает в виде параметров и ничего не возвращает.
Сама задача выглядит так:
IJob
public struct JobStruct : IJob {
public void Execute() {}
}В методе Execute можно выполнять необходимые вычисления.
IJobParallelFor
Еще один интерфейс с таким же методом Execute который уже в свою очередь принимает числовой параметр index.
IJobParallelFor
public struct JobStruct : IJobParallelFor {
public void Execute(int index) {}
}Этот интерфейс IJobParallelFor, в отличие от интерфейса IJob, предлагает выполнить задачу несколько раз и не просто выполнить, а разбить это выполнение на блоки которые будут распределены между потоками.
Непонятно? Не переживайте об этом я еще расскажу.
IJobParallelForTransform
И последний, особый интерфейс, который, как понятно из названия предназначен для работы с данными транформом объекта. Также содержит в себе метод Execute, с числовым параметром index и параметром TransformAccess где находятся позиция, размер и вращение трансформа.
IJobParallelForTransform
public struct JobStruct : IJobParallelForTransform {
public void Execute(int index, TransformAccess transform) {}
}Из-за того что напрямую в задаче нельзя работать с unity объектами, этот интерфейс может обрабатывать данные трансформа только в виде отдельной структуры TransformAccess.
Готово, теперь вы знаете как создаются структуры задач, можно переходить к практике.
Выполнение задачи
Давайте создадим простую задачу унаследованную от интерфейса IJob и выполним ее. Для этого нам понадобится любой простой MonoBehaviour скрипт и сама структура задачи.
TestJob
public class TestJob : MonoBehaviour {
void Start() {}
}Теперь закиньте это скрипт на какой нибудь объект на сцене. В этом же скрипте (TestJob) ниже напишем структуру задачи и не забывайте импортировать нужные библиотеки.
SimpleJob
using Unity.Jobs;
public struct SimpleJob : IJob {
public void Execute() {
Debug.Log("Hello parallel world!");
}
}В методе Execute, для примера, выведем простую строку в консоль.
Теперь перейдем в метод Start скрипта TestJob, где создадим экземпляр задачи после чего выполним его.
TestJob
public class TestJob : MonoBehaviour {
void Start() {
SimpleJob job = new SimpleJob();
job.Schedule().Complete();
}
}Если вы проделали всё как в примере, то после запуска игры получите простое сообщение в консоль как на картинке.
Что здесь происходит: после вызова метода Schedule, планировщик помещает задачу в хэндл и теперь ее можно выполнить вызвав метод Complete.
Это был пример задачи которая просто выводила текст в консоль. Чтобы задача выполняла какие-либо параллельные вычисления нужно наполнить ее данными.
Данные в задаче
Как и в системе ECS в задачах нет доступа к объектам unity, у вас не получиться передать в задачу GameObject и изменить его имя там. Все что вы можете сделать это передать в задачу какие-то отдельные параметры объекта, изменить эти параметры, и после выполнения задачи применить эти изменения обратно объекту.
К самим данным в задаче также есть несколько ограничений: во-первых, это должны быть структуры, во-вторых, это должны быть не преобразуемые типы данных то есть тот же boolean или string вы передать в задачу уже не сможете.
SimpleJob
public struct SimpleJob : IJob {
public float a, b;
public void Execute() {
float result = a + b;
Debug.Log(result);
}
}И главное условие: данные не заключенные в контейнер могут быть доступны только внутри задачи!
Контейнеры
При работе с многопоточными вычислениями возникает необходимость как то обмениваться данными между потоками. Чтобы можно было передавать в них данные и считывать их обратно в системе задач для этих целей существуют контейнеры. Эти контейнеры представлены в виде обычных структур и работаю по принципу моста по которому элементарные данные синхронизируются между потоками.
Есть несколько видов контейнеров:
NativeArray. Самый простой и самый часто используемый тип контейнера представлен в виде простого массива с фиксированным размером.
NativeSlice. Еще один контейнер — массив, как понятно из перевода, предназначен для нарезания NativeArray на части.
Это два основных контейнера доступных без подключения системы ECS. В более расширенном варианте существует еще несколько видов контейнеров.
NativeList. Представляет собой обычный список данных.
NativeHashMap. Аналог словаря с ключом и значением.
NativeMultiHashMap. Тот же NativeHashMap только с несколькими значениями под одним ключом.
NativeQueue. Список очереди данных.
Так как мы работает без подключения системы ECS то нам доступны только NativeArray и NativeSlice.
Перед тем как перейти к практической части необходимо разобрать самый главный момент — создание экземпляров.
Создание контейнеров
Как я говорил раньше, эти контейнеры представляют собой мост по которым данные синхронизируются между потоками. Система задач открывает этот мост перед началом работы и закрывает после ее завершения. Процесс открытия называется “аллокация” (Allocation) или еще “выделением памяти”, процесс закрытия — “высвобождением ресурсов”(Dispose).
Именно аллокация определяет то как долго задача сможет использовать данные в контейнере — иначе говоря как долго будет открыт мост.
Для того чтобы лучше понять эти два процесса давайте взглянем на картинку ниже.
Нижняя ее часть показывает жизненный цикл главного потока(Main thread), который исчисляется в кол-ве кадров, в первом кадре мы создаем еще один параллельный поток(New thread) который существует определенное кол-во кадров и потом благополучно закрывается.
В этот же New thread и поступает задача с контейнером.
Теперь взглянем на верхнюю часть картинки.
Белая полоса Allocation показывает время существования контейнера. В первом кадре происходит аллокация контейнера — открытие моста, до этого момента контейнер не существовал, после выполнения всех расчетов в задаче, контейнер высвобождается из памяти и в 9’ом кадре мост закрывается.
Также на этой полоске (Allocation) есть временные отрезки(Temp, TempJob и Presistent), каждый этот отрезок показывает предположительное время существования контейнера.
Для чего эти отрезки нужны!? Дело в том что выполнение задачи по продолжительности могут быть разные, мы можем выполнять их прямо в том же методе где и создали, или же можем растянуть время выполнения задачи если она достаточно сложная, а эти отрезки показывают как срочно и как долго задача сможет использовать данные в контейнере.
Если все еще не понятно, я разберу каждый тип аллокации на примере.
Теперь можно перейти к практической части создания контейнеров, для этого вернемся в метод Start скрипта TestJob и создадим новый экземпляр контейнера NativeArray и не забывайте подключать нужные библиотеки.
Temp
TestJob
using Unity.Jobs;
using Unity.Collections;
public class TestJob : MonoBehaviour {
void Start() {
NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp);
}
}Для создания нового экземпляра контейнера необходимо указать в его конструкторе размер, и тип аллокации. В этом примере используется тип Temp, так как задача будет выполняться только в методе Start.
Теперь инициализируем точно такую же переменную array в самой структуре задачи SimpleJob.
SimpleJob
public struct SimpleJob : IJob {
public NativeArray<int> array;
public void Execute() {}
}Готово. Теперь можно создать саму задачу и передать в нее экземпляр массива.
Start
void Start() {
NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp);
SimpleJob job = new SimpleJob();
job.array = array;
}Для запуска задачи в этот раз будем использовать ее хэндл JobHandle, чтобы получить его вызовем тот же метод Schedule.
Start
void Start() {
NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp);
SimpleJob job = new SimpleJob();
job.array = array;
JobHandle handle = job.Schedule();
}Теперь можно вызывать метод Complete у ее хэндла и проверить выполнена ли задача, чтобы вывести текст в консоль.
Start
void Start() {
NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp);
SimpleJob job = new SimpleJob();
job.array = array;
JobHandle handle = job.Schedule();
handle.Complete();
if (handle.IsCompleted) print("Задача выполнена");
}Если запустить задачу в таком виде то после запуска игры вы получите жирную красную ошибку о том что не высвободили контейнер array из ресурсов после выполнения задачи.
Примерно такую.
Чтобы этого избежать вызовем метод Dispose у контейнера после выполнения задачи.
Start
void Start() {
NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp);
SimpleJob job = new SimpleJob();
job.array = array;
JobHandle handle = job.Schedule();
handle.Complete();
if (handle.IsCompleted) print("Complete");
array.Dispose();
}После чего можно спокойно запускать заново.
Но задача же ничего не выполняет! — тогда добавим в нее пару действий.
SimpleJob
public struct SimpleJob : IJob {
public NativeArray<int> array;
public void Execute() {
for(int i = 0; i < array.Length; i++) {
array[i] = i * i;
}
}
}В методе Execute я умножаю индекс каждого элемента массива на самого себя и записываю обратно в массив array, чтобы вывести результат в консоль в методе Start.
Start
void Start() {
NativeArray<int> array = new NativeArray<int>(10, Allocator.Temp);
SimpleJob job = new SimpleJob();
job.array = array;
JobHandle handle = job.Schedule();
handle.Complete();
if (handle.IsCompleted) print(job.array[job.array.Length - 1]);
array.Dispose();
}Какой будет результат в консоли если выведем последний элемент массива возведенный в квадрат?
Вот так можно создавать контейнеры, помещать их в задачи и выполнять действия над ними.
Это был пример c использованием типа аллокации Temp, который подразумевает выполнение задачи в течении одного кадра. Этот тип лучше использовать когда вам необходимо быстро выполнить вычисления не нагружая главный поток, но нужно быть осторожным если задача будет слишком сложная или если их будет очень много, то могут возникнуть провисания, в этом случае лучше использовать тип TempJob который я разберу далее.
TempJob
В этом примере я немного изменю структуру задачи SimpleJob и унаследую ее от другого интерфейса IJobParallelFor.
SimpleJob
public struct SimpleJob : IJobParallelFor {
public NativeArray<Vector2> array;
public void Execute(int index) {}
}Также раз задача будет выполняться дольше чем один кадр то будем выполнять и собирать результаты задачи в разных методах Awake и Start представленный в виде корутины. Для этого изменим немного внешний вид класса TestJob.
TestJob
public class TestJob : MonoBehaviour {
private NativeArray<Vector2> array;
private JobHandle handle;
void Awake() {}
IEnumerator Start() {}
}В методе Awake будем создавать задачу и контейнер векторов, а в методе Start выводить полученные данные и высвобождать ресурсы.
Awake
void Awake() {
this.array = new NativeArray<Vector2>(100, Allocator.TempJob);
SimpleJob job = new SimpleJob();
job.array = this.array;
}Здесь опять создается контейнер array с типом аллокации TempJob, после чего создаем задачу и получаем ее хэндл вызвав метод Schedule с небольшими изменениями.
Awake
void Awake() {
this.array = new NativeArray<Vector2>(100, Allocator.TempJob);
SimpleJob job = new SimpleJob();
job.array = this.array;
this.handle = job.Schedule(100, 5)
}Первый параметр в методе Schedule указывает сколько раз выполнится задача, здесь то же число что и размер массива array.
Второй параметр указывает на сколько блоков поделить выполнение задачи.
Какие еще блоки?
Раньше для того чтобы выполнить задачу поток просто один раз вызывал метод Execute, теперь же вызвать этот метод нужно 100 раз, поэтому планировщик, чтобы не нагружать какой то отдельный поток, разбивает эти 100 раз повторений на блоки которые распределяет между потоками. В примере сотня повторений будет поделена на 5 блоков по 20 повторений в каждом, то есть предположительно планировщик распределит эти 5 блоков в 5 потоков, где каждый поток вызовит метод Execute 20 раз. На практике конечно не факт что планировщик именно так и поступит, все зависит от загруженности системы, так что может и все 100 повторений произойдут в одном потоке.
Теперь можно вызвать метод Complete у хэндла задачи.
Awake
void Awake() {
this.array = new NativeArray<Vector2>(100, Allocator.TempJob);
SimpleJob job = new SimpleJob();
job.array = this.array;
this.handle = job.Schedule(100, 5);
this.handle.Complete();
}В корутине Start будем проверять выполнение задачи после чего произведем очистку контейнера.
Start
IEnumerator Start() {
while(this.handle.isCompleted == false){
yield return new WaitForEndOfFrame();
}
this.array.Dispose();
}Теперь перейдем к действиям в самой задаче.
SimpleJob
public struct SimpleJob : IJobParallelFor {
public NativeArray<Vector2> array;
public void Execute(int index) {
float x = index;
float y = index;
Vector2 vector = new Vector2(x * x, y * y / (y * 2));
this.array[index] = vector;
}
}После выполнения задачи в методе Start выведем все элементы массива в консоль.
Start
IEnumerator Start() {
while(this.handle.IsCompleted == false){
yield return new WaitForEndOfFrame();
}
foreach(Vector2 vector in this.array) {
print(vector);
}
this.array.Dispose();
}Готово, можно запустить и посмотреть на результат.
Чтобы понять в чем заключается разница между IJob и IJobParallelFor взглянем на изображения ниже.
Для примера можно и в IJob использовать простой цикл for для выполнения вычислений несколько раз, но в любом случае поток сможет только один раз вызвать метод Execute за все время работы задачи — это как заставить одного человека выполнить сотню одних и тех же действий подряд.
IJobParallelFor предлагает не просто выполнить задачу в одном потоке несколько раз, а еще и распределить эти повторения между другими потоками.
В целом тип аллокации TempJob отлично подходит для большинства задач которые выполняются в течении нескольких кадров.
Но что если вам нужно хранить данные даже после выполнения задачи, что если после получения результата их не нужно сразу же уничтожать. Для этого необходимо использовать тип аллокации Persistent, который подразумевает высвобождение ресурсов тогда “когда нужно будет!”.
Persistent
Опять вернемся в класс TestJob и изменим его. Теперь будем создавать задачи в методе OnEnable, проверять их выполнение в методе Update и зачищать ресурсы в методе OnDisable.
В примере будем двигать объект в методе Update, для расчета траектории будем использовать два векторных контейнера — inputArray в который будем помещать текущее положение и outputArray откуда будем принимать полученные результаты.
TestJob
public class TestJob : MonoBehaviour {
private NativeArray<Vector2> inputArray;
private NativeArray<Vector2> outputArray;
private JobHandle handle;
void OnEnable() {}
void Update() {}
void OnDisable() {}
}Структуру задачи SimpleJob также немного изменим унаследовав ее от интерфейса IJob чтобы выполнить ее один раз.
SimpleJob
public struct SimpleJob : IJob {
public void Execute() {}
}В саму задачу мы также будем предавать два векторных контейнера, один вектор позиции и числовую дельту, которая будет смещать объект к цели.
SimpleJob
public struct SimpleJob : IJob {
[ReadOnly]
public NativeArray<Vector2> inputArray;
[WriteOnly]
public NativeArray<Vector2> outputArray;
public Vector2 position;
public float delta;
public void Execute() {}
}Атрибут ReadOnly и WriteOnly показывают потоку ограничения в действиях связанных с данными внутри контейнеров. ReadOnly предлагает потоку только читать данные из контейнера, атрибут WriteOnly наоборот — дает возможность потоку только записывать данные в контейнер. Если вам нужно выполнять сразу два этих действия с одним контейнером тогда не нужно помечать его атрибутом вообще.
Перейдем в метод OnEnable класса TestJob где будут инициализироваться контейнеры.
OnEnable
void OnEnable() {
this.inputArray = new NativeArray<Vector2>(1, Allocator.Persistent);
this.outputArray = new NativeArray<Vector2>(1, Allocator.Persistent);
}Размеры контейнеров будут единичными так как нужно передавать и принимать параметры только один раз. Тип аллокации будет Persistent.
В методе OnDisable будем высвобождать ресурсы контейнеров.
OnDisable
void OnDisable() {
this.inputArray.Dispose();
this.outputArray.Dispose();
}Создадим отдельный метод CreateJob где будем создавать задачу с ее хэндлом и там же будем заполнять ее данными.
CreateJob
void CreateJob() {
SimpleJob job = new SimpleJob();
job.delta = Time.deltaTime;
Vector2 position = this.transform.position;
job.position = position;
Vector2 newPosition = position + Vector2.right;
this.inputArray[0] = newPosition;
job.inputArray = this.inputArray;
job.outputArray = this.outputArray;
this.handle = job.Schedule();
this.handle.Complete();
}На самом деле inputArray здесь не особо то и нужен так как можно передавать в задачу и просто вектор направления, но так я думаю будет лучше понятно зачем вообще нужны эти атрибуты ReadOnly и WriteOnly.
В методе Update будем проверять выполнена ли задача, после чего применим полученный результат транформу объекта и снова ее запустим.
Update
void Update() {
if (this.handle.IsCompleted) {
Vector2 newPosition = this.outputArray[0];
this.transform.position = newPosition;
CreateJob();
}
}Перед запуском немного подправим метод OnEnable так чтобы задача создавалась сразу после инициализации контейнеров.
OnEnable
void OnEnable() {
this.inputArray = new NativeArray<Vector2>(1, Allocator.Persistent);
this.outputArray = new NativeArray<Vector2>(1, Allocator.Persistent);
CreateJob();
}Готово, теперь можно перейти к самой задаче и выполнить нужные вычисления в методе Execute.
Execute
public void Execute() {
Vector2 newPosition = this.inputArray[0];
newPosition = Vector2.Lerp(this.position, newPosition, this.delta);
this.outputArray[0] = newPosition;
}Чтобы увидеть результат работы можно кинуть скрипт TestJob на какой то объект и запустить игру.
Например у меня спрайт просто понемногу смещается вправо.
Анимация
В общем тип аллокации Persistent отлично подходит для повторно используемых контейнеров, которые нет необходимости каждый раз уничтожать и создавать заново.
Так какой же тип использовать!?
Тип Temp лучше использовать для быстрого выполнения вычислений, но если задача будет слишком сложной и большой могут возникнуть провисания.
Тип TempJob отлично подходит для работы с объектами unity, так можно изменять параметры объектов и применять их, к примеру, в следующем кадре.
Тип Persistent можно использовать тогда когда вам не важна скорость, а просто необходимо постоянно вычислять какие-то данные на стороне, к примеру обрабатывать данные по сети, или работу ИИ.
Invalid и None
Существует еще два типа аллокации Invalid и None, но они нужны больше для отладки, и в работе участия не принимают.
JobHandle
Отдельно стоит все же разобрать возможности хэндла задачи, ведь кроме как проверять процесс выполнения задачи, этот маленький хэндл еще может создавать целые сети задач через зависимости(хотя я больше предпочитаю называть их очередями).
К примеру если вам нужно выполнить две задачи в определенной последовательности то для этого нужно просто вложить хэндл одной задачи в хэндл другой.
Выглядит это примерно так.
Каждый отдельный хэндл изначально содержит свою задачу, а вот уже при комбинировании получаем новый хэндл с двумя задачами.
Start
void Start() {
Job jobA = new Job();
JobHandle handleA = jobA.Schedule();
Job jobB = new Job();
JobHandle handleB = jobB.Schedule();
JobHandle result = JobHandle.CombineDependecies(handleA, handleB);
result.Complete();
}Или так.
Start
void Start() {
JobHandle handle;
for(int i = 0; i < 10; i++) {
Job job = new Job();
handle = job.Schedule(handle);
}
handle.Complete();
}Последовательность выполнения сохраняется и планировщик не начнет выполнять следующую задачу пока не убедится в выполнении предыдущей, но важно помнить, что свойство хэндла IsCompleted будет ожидать выполнения всех задач находящихся в нем.
Заключение
Контейнеры
- При работе с данными в контейнерах не забывайте что это структуры, так что любая перезапись данных в контейнере не изменяет их, а создает заново.
- Что будет если задать тип аллокации Temp и не очистить ресурсы после завершения задачи? Ошибка.
- Можно ли создавать свои контейнеры? Можно, юнитеки подробно расписали здесь процесс создания кастомных контейнеров, но лучше несколько раз подумать: а стоит ли, может и обычных контейнеров хватит!?
Безопасность!
Статические данные.
Не пытайтесь использовать статические данные в задаче(Random и другие), любое обращение к статическим данным нарушит безопасность системы. На самом деле в данный момент можно обращаться к статическим данным, но только если вы уверены что они не изменяются в процессе работы — то есть полностью статичны и доступны только для чтения.
Когда использовать систему задач?
Все эти примеры что приведены здесь в статье лишь условные, и показывают как нужно работать с этой системой, а не когда нужно ее использовать. Систему задач можно использовать и без ECS, нужно понимать что система также потребляет ресурсы при работе и, что по любому поводу сразу писать задачи, создавать кучи контейнеров просто бессмысленно — все станет еще хуже. К примеру пересчитать массив размером 10 тысяч элементов будет не правильно — у вас больше времени уйдет на работу планировщика, а вот пересчитать все полигоны огромного террейна или вообще сгенерировать его — правильное решение, можно разбить террейн на задачи и обрабатывать каждую в отдельном потоке.
В общем если вы постоянно занимаетесь сложными вычислениями в проектах и постоянно ищите новые возможности как сделать этот процесс менее ресурсоемким, то Job System это именно то что вам нужно. Если вы постоянно работает со сложными вычислениями неотделимо от объектов и хотите чтобы ваш код работал быстрее и поддерживался на большинстве платформ, то ECS вам точно в этом поможет. Если вы создаете проекты только под WebGL тогда это не для вас, на данный момент Job System не поддерживает работу в браузерах, хотя это уже проблема не юнитеков, а самих разработчиков браузеров.
Исходник со всеми примерами