

Второй день основной программы KDD. Под катом снова много интересного: от машинного обучения в Pinterest до разных способов прокопаться к водопроводным трубам. В том числе было выступление нобелевского лауреата по экономике — рассказ о том, как NASA работает с телеметрией, и много графовых эмбедингов :)
Market design and computerized marketplace
Неплохое выступление нобелевского лауреата, работавшего с Шэпли, посвященное рынкам. Рынок — это искусственная штука, устройство которой придумывают люди. Есть так называемые commodity markets, когда вы покупаете некий товар и вам всё равно, у кого, важно только, по какой цене (например, рынок акций). И есть matching markets, когда цена не является единственным фактором (а иногда её вообще нет).
Например, распределение детей по школам. Раньше в США схема работала так: родители выписывают список школ по приоритетам (1, 2, 3 и т.д.), школы сначала рассматривают тех, кто указал их как номер 1, сортируют по своим школьным критериям и берут столько, сколько могут взять. Для тех, кто не попал, берем вторую школу и повторяем процедуру. С точки зрения теории игр схема из рук вон плохая: родителям приходится вести себя «стратегически», нецелесообразно честно говорить свои предпочтения — если ты не попадаешь в школу 1, ко второму раунду школа 2 может быть уже заполнена и ты и в неё не попадешь, даже если если твои характеристики выше, чем у тех, кто был принят в первом раунде. На практике неуважение к теории игр выливается в коррупцию и внутренние договорняки между родителями и школами. Математики предложили другой алгоритм — «отложенное принятие». Основная идея в том, что школа не дает согласие сразу, а просто держит «в памяти» ранжированный список кандидатов, и если кто-то выходит за границу хвоста, то сразу получает отказ. В этом случае для родителей есть доминантная стратегия: сначала идем в школу 1, если в какой-то момент получаем отказ, то переходим в школу 2 и ничего не боимся потерять — шансы попасть в школу 2 такие же, как если бы мы пошли в неё сразу. Эту схему внедрили «в production», правда. о результатах А/Б-теста не рассказали.
Другой пример — трансплантация почек. В отличие от многих других органов, жить можно и с одной почкой, поэтому часто возникает ситуация, что кто-то готов отдать почку другому человеку, но не абстрактному, а конкретному (ввиду личных отношений). Однако вероятность того, что донор и реципиент совместимы, очень мала, и приходится ждать другой орган. Есть и альтернатива — обмен почками. Если две пары донор-реципиент и несовместимы внутри, но совместимы между парами, то можно провести обмен: 4 одновременных операции по извлечению/имплантации. Для этого уже работает система. А если найдется «свободный» орган, не привязанный к конкретной паре, то он может дать начало целой цепочке обменов (в практике были цепочки до 30 трансплантаций).
Подобных matching markets сейчас очень много: от Uber до рынка онлайн-рекламы, и всё меняется очень быстро за счет компьютеризации. Помимо прочего, сильно меняется «приватность»: в качестве примера докладчик привел исследование одного студента, показавшего, что в США после выборов количество поездок в гости на День благодарения снизилось из-за поездок между штатами с разными политическими взглядами. Исследование проводилось на анонимизированном датасете координат телефонов, но автор достаточно легко вычленил «дом» хозяина телефона, т.е. деанонимизировал датасет.
Отдельно докладчик прошелся по технологической безработице. Да, беспилотные авто лишат работы многих (в США 6 % рабочих мест под угрозой), но они и создадут новые места (для автомехаников). Конечно, пожилой водитель уже не сможет переквалифицироваться и для него это будет сильный удар. В такие моменты нужно концентрироваться не на том, как предотвратить изменения (не получится), а на том, как помочь людям максимально безболезненно их пройти. В середине прошлого века при механизации сельского хозяйства очень много людей лишились работы, но мы ведь рады тому, что сейчас не приходится половине населения отправляться работать в поле? К сожалению, это только разговоры, реализуемых вариантов смягчения удара для тех, по кому катится технологическая безработица, докладчик не предложил…
И да, снова про faireness. Нельзя сделать так, чтобы распределение прогноза модели было одинаковым во всех группах, модель потеряет смысл. Что можно сделать, в теории, чтобы распределение ОШИБОК первого и второго рода было одинаковым для всех групп? Это уже выглядит гораздо более здраво, но как этого добиться на практике, не ясно. Дал ссылку на интересную статью о юридической практике — в США решение отпускать ли под залог судья принимает на основании прогноза ML.
Recommenders I
Запутался в расписании и пришел не на то выступление, но всё равно в тему — первый блок по рекомендательным системам.
Leveraging Meta-path based Context for Top N recommendation with Co-attention mechanism
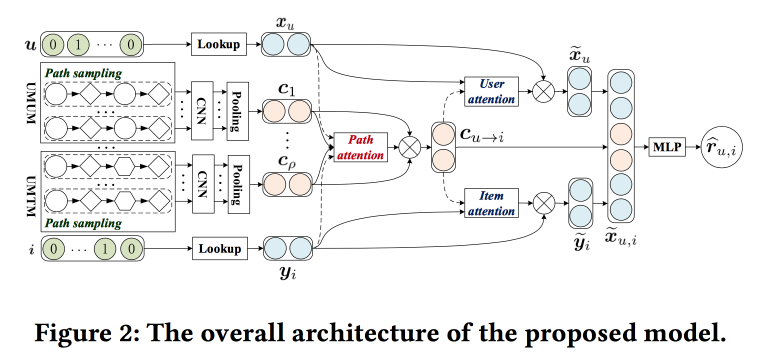
Ребята пытаются улучшить рекомендации с помощью анализа путей в графе. Идея достаточно простая. Есть «классический» нейросетевой рекомендатель с эмбедингами для объектов и пользователей и полносвязной частью сверху. Есть рекомендации по графу, в том числе с нейросетевыми накрутками. Давайте попробуем это всё совместить в одном механизме. Начнем с построения «мета-графа», объединяющего пользователей, фильмы и атрибуты (актер/режиссер/жанр и т.д.), на графе random walk-om засэмплируем некоторое количество путей, подадим на вход свёрточной сети, сбоку добавим эмбединги пользователя и объекта, а сверх навесим attention (тут немного мудреный, со своими особенностями для разных ветвей). Для получения итогового ответа сверху поставим перцептрон с двумя скрытыми слоями.
Consumer Internet Applications
В перерыве между докладами перемещаюсь на то выступление, куда хотел изначально: здесь выступают приглашенные докладчики из LinkedIn, Pinterest и Amazon. Все девушки и все начальники DS-отделов.
Neraline Contextual Recommentations for Active Communities LinkedIn
Суть в том, чтобы стимулировать развитие сообществ и их активизацию в LinkedIn. Половину про развитие пропустил, последняя рекомендация: эксплуатировать локальные паттерны. Например, в Индии студенты часто после выпуска стараются связаться с выпускниками этого же ВУЗа с прошлых курсов с оформленной карьерой. В LinkedIn это учитывают и при построении, и при выдаче рекомендаций.
Но просто создать сообщество недостаточно, надо, чтобы там была активность: пользователи публиковали контент, получали и давали обратную связь. Показывают корреляцию полученной обратной связи с количеством публикаций в дальнейшем. Показывают, как информация каскадами распространяется по графу. Но что делать, если какой-то узел не вовлечен в каскад? Слать уведомление!
Дальше было достаточно много перекликаний со вчерашним рассказом про работу с уведомлениями и лентой. Здесь они тоже используют подход многоцелевой оптимизации «максимизируем одну из метрик, удерживая другие в определенных пределах». Чтобы контролировать нагрузку, ввели свою систему «Air Trafic Control», которая лимитирует нагрузку по уведомлениям на пользователя (смогли снизить отписки и жалобы на 20 %, не уронив вовлеченность). ATC решает, можно ли слать пользователю push или нет, а готовит этот push другая система под названием Concourse, работающая в потоковом режиме (как и у нас, на Samza!). Именно про неё много рассказывали вчера. У Concourse есть и оффлайн-напарник по имени Beehive, но постепенно всё больше уходит в стриминг.
Отметили еще несколько моментов:
- Важна дедупилкация, причем качественная, с учетом наличия многих каналов и контента.
- Важно иметь платформу. Причем у них команда платформы выделена, и там работают программисты.
Pinterest Approach to Machine learning
Теперь выступает представитель Pinterest и рассказывает про две большие задачи, где используется ML — лента (homefeed) и поиск. Докладчик сразу говорит, что итоговый продукт является результатом работы не только data scientist-ов, но и ML-инженеров, и программистов — на всё у них выделены люди.
Лента (ситуация, когда пользовательского намерения нет) строится по следующей модели:
- Понимаем пользователя — используем информацию из профиля, графа, взаимодействие с пинами (что видел, что пинил), строим эмбединги по поведению и атрибутам.
- Понимаем контент — смотрим на него во всех аспектах: визуальном, текстовом, кто автор, на какие доски попадает, кто реагирует. Очень важно помнить, что люди в одной картинке часто видят разные вещи: кто-то голубой акцент в дизайне, кто-то камин, а кто-то кухню.
- Собираем всё вместе — процедура из трех шагов: генерируем кандидатов (рекомендации + подписки), персонализируем (используя модель ранжирования), блендим с учетом политик и бизнес-правил.
Для рекомендаций пользуются random walk-ом по графу пользователь-доска-пин, внедряют PinSage, про который говорили вчера. Персонализация эволюционировала от сортировки по времени, через линейную модель и GBDT к нейросетке (с 2017 года). При сборе итогового списка важно не забывать про бизнес-правила: свежесть, разнообразие, дополнительные фильтры. Начали с эвристик, сейчас двигаются в сторону модели оптимизации контекста в целом относительно целей.
В ситуации с поиском (когда намерение есть) двигаются немного по-другому: пытаются лучше понять намерение. Для этого используют техники query understanding и query expansion, причем расширение сделано не просто автодополнением, а через красивую визуальную навигацию. Используют разные методики по работе с картинками и текстами. Начинали в 2014 еще без deep learning, запустили Visual Search с deep learning в 2015-м, в 2016-м добавили object detection с семантическим анализом и поиском, недавно запустили сервис Lens — наводишь камеру смартфона на предмет и получаешь пины. В deep learning активно пользуются multi task: есть общий блок, строящий эмбединг картинки. и сверху другие сети для решения разных задач.
Помимо этих задач ML используют еще много где: уведомления/реклама/спам/прогнозирование и т.д.
Немного про извлеченные уроки:
- Надо помнить про биасы, один из самых опасных «rich get richer» (тенденция машинного обучения переливать трафик в и без того популярные объекты).
- Обязательно тестировать и мониторить: внедрение сетки сначала сильно обвалило все показатели, потом выяснилось, что из-за бага уже давно дрейфовали распределения фич и появлялись пустоты в онлайне.
- Инфраструктура и платформа очень важны, особый акцент на удобстве и распараллеливании экспериментов, но надо и уметь отсекать эксперименты в офлайне.
- Метрики и понимание: офлайн не гарантирует онлайн, а для интерпретации моделей делаем инструменты.
- Строим устойчивую экосистему: о фильтре мусора и кликбэйта, обязательно добавляйте негативную обратную связь в УИ и модель.
- Не забывайте, чтобы был слой для встраивания бизнес-правил.
Broad Knowledge Graph by Amazon
Теперь выступает девушка из Amazon.
Есть графы знаний — узлы-сущности, ребра-атрибуты и т.д., — которые строятся автоматически, например, по Википедии. Они помогают решать многие задачи. Хотели бы получить похожую штуку для продуктов, но с этим куча проблем: нет структурированных данных на входе, продукты динамичны, есть много всяких аспектов, которые не ложатся на модель графа знаний (спорно, на мой взгляд, скорее «не ложатся без серьезного усложнения структуры»), очень много вертикалей и «не именованные сущности». Когда концепт «продали» руководству и получили добро, разработчики сказали, что это «проект на сотню лет», в итоге справились за 15 человеко-месяцев.
Начали с извлечения сущностей из каталога Amazon: здесь есть какая-никакая структура, хотя он краудсорсинговый и грязный. Далее подключили OpenTag (подробнее рассказал вчера) для обработки текстов. И третьим компонентом стал Ceres — инструмент для парсинга из веба с учетом DOM-дерева. Идея в том, что аннотируя одну из страниц сайта можно легко парсить остальные — ведь все сгенерированы по шаблону (но есть много нюансов). Чтобы это провернуть, использовали систему разметки Vertex (куплена Amazon в 2011) — в ней делают разметку, на её основе создан набор xpath для вычленения атрибутов, а логистической регрессией определяют, какие применимы в конкретной странице. Чтобы слить информацию с разных сайтов, используют random forest. Также используют активное обучение, сложные страницы отправляют на ручную доразметку. В конце делают supervised knowledge cleaning — простой классификатор, например, бренд/не бренд.
Далее немного за жизнь. Они у себя выделяют два типа целей. Roofshots — краткосрочные цели, достигая которые мы двигаем продукт, и Moonshots — достигая которые мы расширяем границы и удерживаем глобальное лидерство.
Embeddings and Representations
После обеда пошел на секцию о том, как строить эмбединги, в основном для графов.
Finding Similar Exercises with a Unified Semantic Representation
Ребята решают задачу по поиску похожих заданий в некой китайской онлайн-системе обучения. Задания описываются текстом, картинками и набором связанных концпетов. Вклад разработчиков — сблендить информацию из этих источников. Для картинок делают свёртку, для концептов тренируют эмбединги, для слов — тоже. Эмбединги слов передают в Attention-based LSTM вместе с информацией о концептах и картинках. Получают некоторую репрезентацию задания.

Описанный выше блок превращают в сиамскую сеть, в которой также добавлено attention и на выходе similarity score.
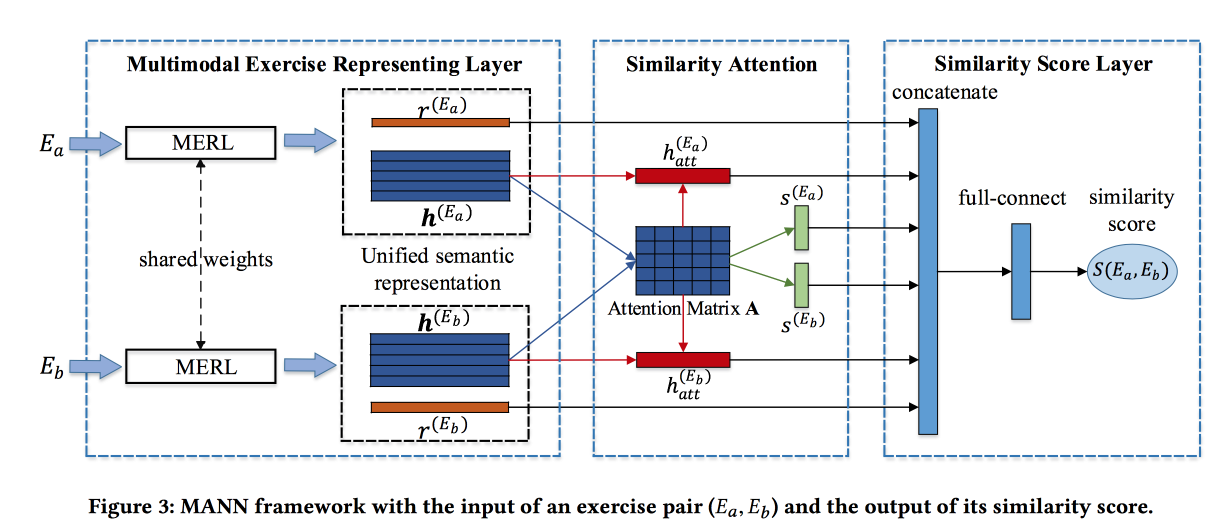
Обучают на размеченном датасете из 100 тыс. упражнений и 400 тыс. пар (всего 1,5 млн упражнений). Добавляют hard negative, сэмплируя упражнения с теми же концептами. Матрицы attention-а затем можно использовать для интерпретации похожести.
Arbitrary-Order Proximity Preserved Network Embedding
Ребята строят очень интересный вариант эмбедингов для графов. Сначала критикуют методы на основе прогулок и на основе соседей за то, что они акцентируются на «близости» определенного уровня (соответствующей длине прогулки). Они же предлагают метод, учитывающий близость нужного порядка, причем с контролируемыми весами.
Идея очень простая. Давайте возьмём полиномиальную функцию и применим к матрице смежности графа, а результат факторизуем по СВД. В данном случае степень конкретного члена полинома это уровень близости, а вес этого члена — влияние этого уровня на результат. Естественно, эта дикая идея не реализуема: после возведения матрицы смежности в степень она уплотниться, не влезет в память и фиг такую факторизуешь.
Без математики дело дрянь, ведь если полиномиальную функцию применить к результату ПОСЛЕ разложения, то получим ровно то же самое, как если бы применили разложение к большой матрице. На самом деле не совсем. Мы считаем SVD приблизительно и оставляем только самые верхние собственные числа, но после применения полинома порядок собственных чисел может поменяться, поэтому надо брать числа с запасом.

Алгоритм подкупает своей простотой и показывает сногсшибательные результаты в задаче link prediction.

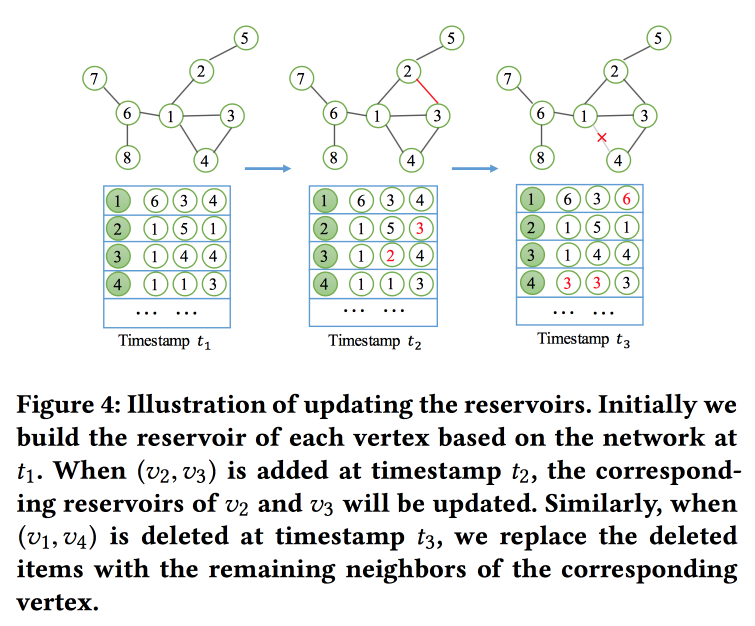
NetWalk: A Flexible Deep Embedding Approach for Anomaly Detection in Dynamic Networks
Как понятно из названия, будем строить эмбединги графа на основании прогулок. Но не просто, а в потоковом режиме, так как решаем задачу поиска аномалий в динамических сетях (работа на эту тему была и вчера). Чтобы быстро считать и обновлять эмбединги, используют концепцию «резервуара», в котором лежит сэмпл графа и стохастически обновляется при поступлении изменений.
Для обучения формулируют достаточно сложную задачу с несколькими целями, основные — близость эмбедингов для узлов в одном пути и минимум ошибки при восстановлении сети автоэнкодером.
Hierarchical Taxonomy Aware Network Embedding
Еще один вариант построения эмбедингов для графа, в этот раз на основе вероятностной генерирующей модели. Качество эмбедингов улучшают за счет использования информации из иерархической таксономии (например, области знания для сетей цитирования или категории товаров для продуктов в e-tail). Процесс генерирования строим по некоторым «топикам», часть из которых привязана к узлам в таксономии, а часть — к конкретной ноде.
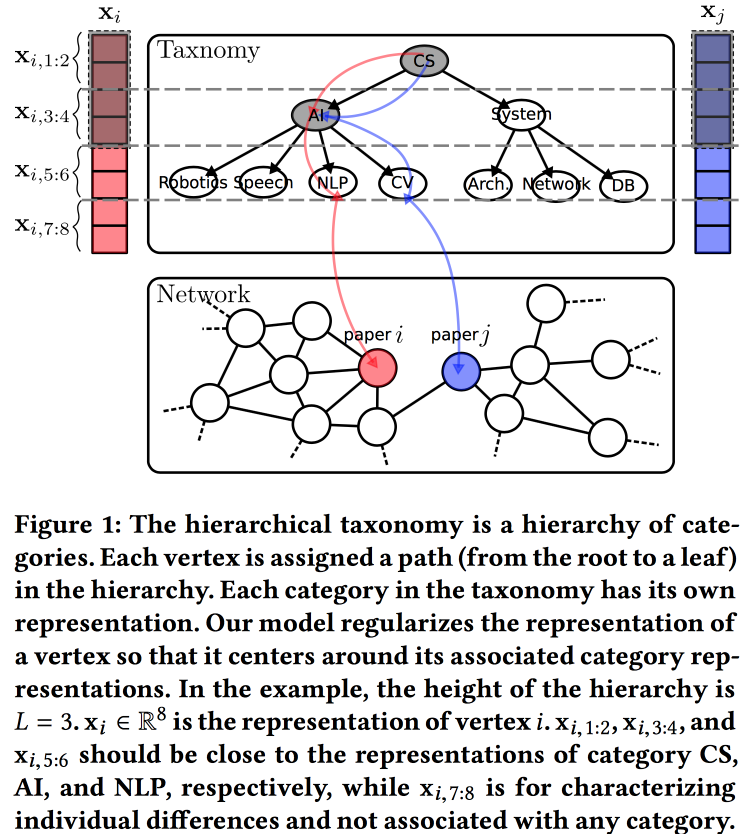
С параметрами таксономии связываем априорное нормальное распределение с нулевым средним, параметры конкретной вершины в таксономии — нормальное распределение со средним, равным параметру таксономии, а на свободные параметры вершины — нормальное распределение с нулевым средним и бесконечной дисперсией. Окружение вершины генерируем с помощью распределения Бернулли, где вероятность успеха пропорциональна близости параметров узлов. Всю эту махину оптимизируем EM-алгоритмом.
Deep Recursive Network Embedding with Regular Equivalence
Распространенные методы построения эмбедингов работают не для всех задач. Например, рассмотрим задачу «роль ноды». Для определения роли важны не конкретные соседи (на которых обычно смотрят), а структура графа в окрестности вершины и некоторые паттерны в ней. При этом искать эти паттерны (regular equivalence) напрямую алгоритмически очень сложно, а для крупных графов — нереально.
Поэтому пойдем другим путем. Для каждой ноды посчитаем параметры, связанные с её графом: степень, плотность, разные центральности и т.д. На них одних эмбединги не построить, но можно воспользоваться рекурсией, ведь наличие одинакового паттерна подразумевает, что атрибуты соседей двух нод с одинаковой ролью должны быть схожи. А значит, можно stack more layers.
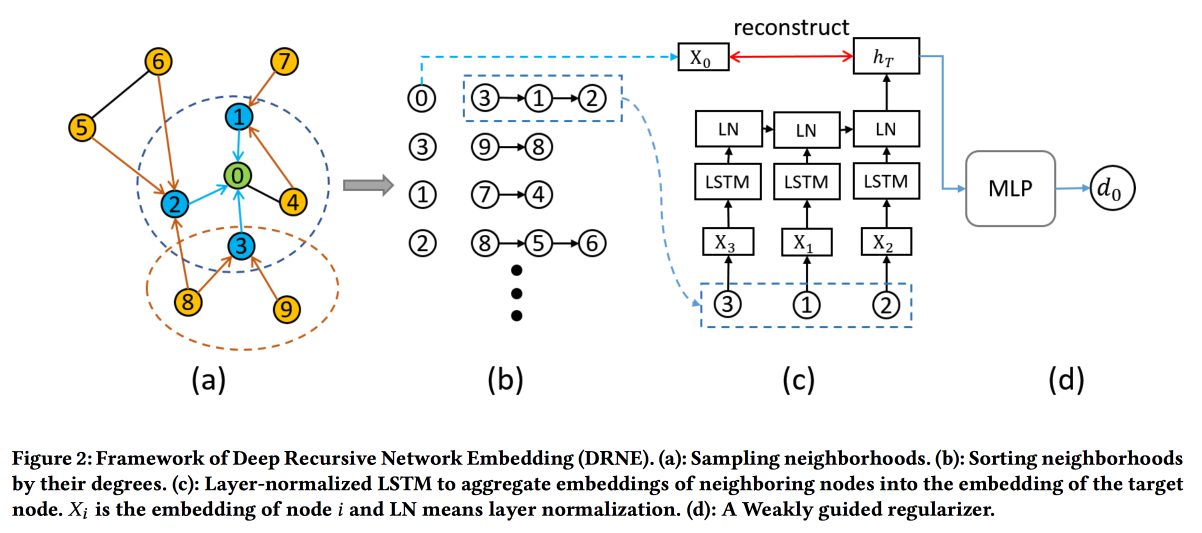
На валидации показывают, что обходят стандартные base line-ы DeepWalk и node2wek на многих задачах.
Embedding Temporal Network via Neighborhood Formation
Последняя работа по графовым эмбедингам на сегодня. В этот раз посмотрим на динамику: будем оценивать и момент возникновения связи, и все факты взаимодействия во времени. В качестве примера берем сеть цитирования, где взаимодействие — совместная публикация.
Используем Hawkes Process для моделирования того, как прошлые взаимодействия вершин влияют на их будущие взаимодействия. Функции интенсивности и влияние исторических событий для HP определяем через евклидово расстояние между эмбедингами. Для улучшения результата добавляем матрицу attention для корректировки влияния истории. Оптимизируют log likelihood с помощью градиентного спуска. Результаты выглядят неплохо.
Safety
В вечерней сессии сложно было выбрать. куда пойти, но в итоге остался очень доволен. В разборе вопросов о том, как ML может помочь обезопасить жизнь в реальных проектах, сложного МЛ почти не было, зато практические кейсы очень интересные.
Using Machine Learning to Assess the Risk of and Prevent Water Main Breaks
В американском городе Сиракузы проблемы: население уменьшается, собираемость налогов тоже, инфраструктура стареет — некоторые водопроводные трубы были проложены еще в девятнадцатом веке. Естественно, трубы регулярно прорывает и устранение последствий обходится очень дорого. Трубы надо менять, но денег мало (в том числе из-за того, что их много уходит на устранение аварий), и можно поменять только 1-2 % труб в год. Надо выбрать, где менять трубы в первую очередь.
И тут решила попробовать помочь команда data miner-ов из чикагского проекта Data Science for Social Good. Правда, ребята сразу столкнулись с проблемами, так как самые важные данные выглядели вот так:

Рукописные схемы труб и акты приемки работ, некоторым из которых более сотни лет. Но ребята неплохо справились: вручную оцифровали этот датасет и заблендили много чего еще, а затем натренировали GBDT. При этом делали достаточно необычную оптимизацию гиперпараметров на точность на Топ-1 % ответа.
Сравнили точность прогноза с base line-ами: эвристика «менять самые старые трубы» работает почти так же плохо, как случайный выбор, а вот эвристика «менять там, где за последнее время было больше всего аварий» работает очень неплохо. Но ML, конечно, лучше.

27 из 32-х спрогнозированных аварий уже случились, оставшиеся, скорее всего, не за горами (в авариях есть сезонность, зимой их больше — трубы замерзают). Ожидают, что использование модели сэкономит порядка $1,2 млн в следующем году.
На вопрос о том, удалось ли найти интересные и не очевидные закономерности, рассказали, что в 1940-е, похоже, металл для труб был плохого качества (всё шло на фронт) и модель на это обратила внимание.
Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding
Ребята из NASA представили работу по анализу телеметрии от космических аппаратов (спутников и роверов). Задача — поиск аномалий. Сейчас система работает по порогам и некоторые типы аномалий не засекает, пока не произойдет катастрофа. Эксперты периодически просматривают графики глазами, но данных очень много.
ML достаточно простой. Заправляем временной ряд в LSTM и предсказываем, что будет в будущем. Строим по модели на каждый канал телеметрии для интерпретируемости результата (чтобы эксперт понял, куда смотреть). Затем сравниваем реальные значения с прогнозом, и если различие выше порога, то зажигаем сигнал. С порогом не всё так просто, подбирают его тоже на данных. Моделирование ошибки Гауссианой не заработало, там другое распределение.
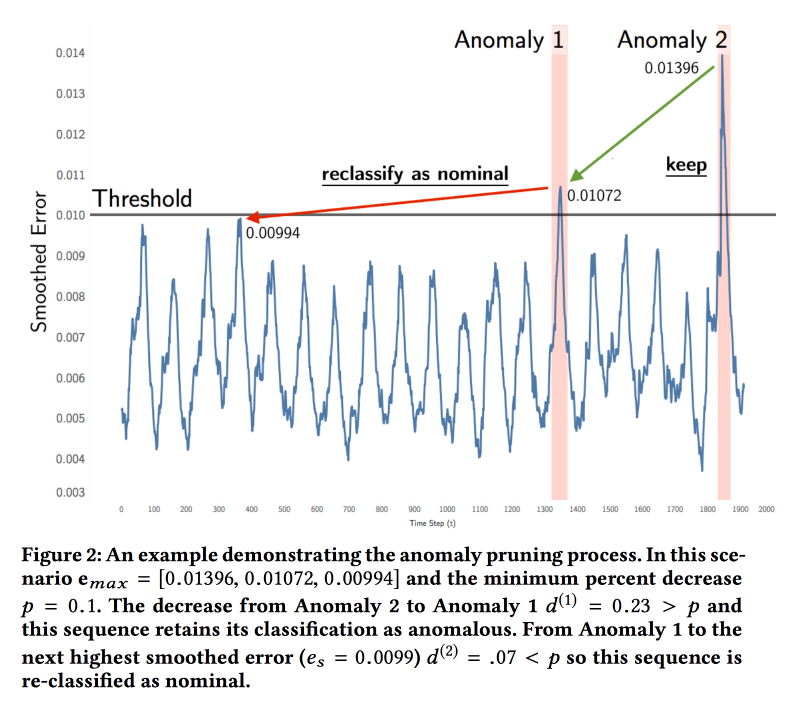
Проверили модель на данных двух миссий: soil moisture active passive на орбите и Curiosity c Mars Science Laboratory. Экспертами было отмечено 122 аномалии, точность и полнота модели получилось порядка 80 %. Запустили пилот, нашли аномалии в работе радара, который через два месяца сломался. Есть проблема с командами, некоторые показатели меняются ожидаемо при выполнении команд, но сами команды в модель не попадают.
Explaining Aviation Safety Incidents Using Deep Temporal Multiple Instance Learning
Еще одна работа, посвященная телеметрии, на этот раз от обычных самолетов. Иногда с самолетами случаются Safety Incidents, например, при заходе на посадку в определенный момент скорость становится выше норматива. Некоторые из таких инцидентов заканчиваются трагедией, но о подавляющем большинстве пассажиры даже не узнают. При этом любой инцидент тщательно разбирается на земле.
С самолета собирается очень много показателей, и человек-эксперт садится изучать их в периоде, предшествующем инциденту. Его задача найти «прекурсоры», т.е. те факторы, которые привели к возникновению инцидента. Работа эта очень тяжелая, потому что данных много, а анализируют вручную. Значит, надо сделать систему, которая помогла бы искать проблемные места.
Суть предложенной в работе модели заключается в рекуррентной нейросети на базе GRU, обучаемой с использованием подхода Multiple Instances Learning. Подход заключается в том, что вместо индивидуальных размеченных обучающих примеров нам дают «мешки» — наборы примеров, где метка ассоциирована с мешком в целом. При прогнозировании мы тоже оцениваем мешки по принципу «если есть хоть один позитив, то весь мешок позитивен, если нет — то негативен» (в нашем случае позитив = аномалия). Эта схема очень просто добавляется в сеть с помощью слоя max pooling поверх выходов рекуррентных блоков.

Обучали всё это с помощью cross entropy loss на размеченном датасете от проанализированных человеком инцидентов. В качестве base line использовали варианты MI-SVM и свою же прошлую работу ADOPT.
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
Тех, кто дочитал, ждет замечательная история.
Есть в США небольшой городок Флинт. Находится в ста километрах от Детройта и проживает там порядка 120 тысяч человек. К несчастью, сосед Детройт объявил о банкротстве в 2013 году, что создало для Флинта определенные проблемы: система водоснабжения была завязана на Детройт. Но рядом протекала одноименная река, поэтому воду решили брать оттуда и переключились на собственно водоснабжение в 2014-м. Однако уже в 2015-м педиатры забили тревогу — количество детей с аномально высоким количеством свинца в крови резко увеличилось. Проверка воды в домах показала наличие свинца, хотя в реке его не находили. Срочно переключились обратно на снабжение от Детройта, но свинец в воде никуда не делся…
После разборок ситуация прояснилась — вода в реке была чистая, но обладала другой жесткостью и своими примесями. Тогда как при строительстве водопровода мнооого лет назад использовали свинцовые трубы с изоляцией, рассчитанной на детройтскую воду. Вода из Флинта эту изоляцию растворила и свинец труб стал контактировать с водой.
В итоге система водоснабжения города нуждается практически в полной замене. «Практически», потому что часть труб сделана из меди. Но тут всплыли новые сложности: записи о том, где и какие трубы лежат, вели крайне небрежно, часть данных утеряли. В итоге, где свинец, а где медь — неизвестно, и надо менять всё…
За несколько лет заменили порядка 6 тысяч участков трубопровода. Сначала находили только свинец, но дальше процент ложных вскрытий и зря потраченных денег стал расти и достиг 20 %. Тут и решили позвать на помощь data scientist-ов.
Те, увидев данные в книгах и карточках 19 века, слегка ошалели, руками разребать не стали и отправили в контору, занимающуюся оцифровкой. Там смогли распознать только часть, а остальное вернули с пометкой «распознать невозможно». Добавили дополнительные источники, в том числе карту, и натравили на это XGBoost и иерархического Байеса для моделирования гео-пространственных зависимостей. Получили неплохую точность прогноза (на 7 % лучше, чем у логистической регрессии).
Копать по результатам прогноза модели власти не решились, но дали ребятам машину-грязесос, которая могла докопаться до труб с относительно небольшим ущербом, чтобы проверить, что же там — медь или свинец. С этой машиной ребята стали практиковать «активное обучение» и убедились в эффективности модели.

Проанализировав данные ретроспективно, посчитали, что использование модели в формате активного обучения позволило бы сократить перерасход средств с 16 % до 3 %. Кроме того, отметили, что в процессе взаимодействия с учёными власти значительно улучшили свое отношение к данным — вместо листочков и разрозненных табличек в Excel появился нормальный портал для отслеживание процесса замены водопровода.
A Dynamic Pipeline for Spatio-Temporal Fire Risk Prediction
В заключение еще одна больная тема — пожарные инспекции. О том, что бывает, если их не проводить, мы узнали в марте 2018-го. В США тоже такие случае не редки. При этом ресурсы на проведение инспекций у пожарных ограничены, надо направить их туда, где больше всего риска.
Существуют открытые модели оценки риска от пожаров, но они предназначены для лесных пожаров и для города не годятся. Есть какая-то система в Нью-Йорке, но она закрытая. Значит, надо попробовать сделать свою.
В сотрудничестве с пожарными Питсбурга ребята собрали данные о пожарах за несколько лет, добавили к ним информацию о демографии, доходах, формах бизнесов и т.д., а также о других обращениях в пожарную службу, не связанных с пожарами. И попробовали оценить риск пожара на основании этих данных.
Обучают две разные модели XGBoost-а: для домохозяйств и для коммерческой недвижимости. Качество работы оценивали, в первую очередь, по Каппе в виду сильного дисбаланса классов.
Добавление динамических факторов (звонки в пожарную охрану, срабатывание детекторов/сигнализаций) в модель заметно улучшило качество, но чтобы их использовать, модель надо было пересчитывать каждую неделю. На базе прогноза модели сделали приятную вебморду для пожарных инспекторов, показывающую, где находятся объекты с наибольшим риском.
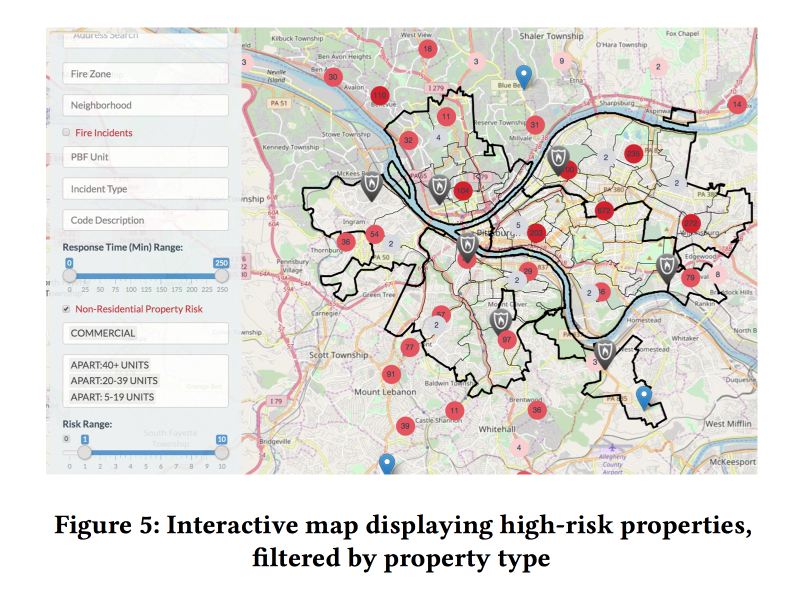
Проанализировали важность признаков. Среди важных фич для коммерции оказались связанные с ложными срабатываниями сигнализации (видимо, дальше идет отключка). А вот для домохозяйств — количество уплаченных налогов (привет Fairness, пожарные проверки в бедные районы будут ходить чаще).