

Сегодня, наконец, началась основная программа конференции. Acceptance rate в этом году составила всего 8 %, т.е. выступать должны лучшие из лучших из лучших. Явно разделены прикладные и исследовательские потоки, плюс идет несколько отдельных сопутствующих мероприятий. Прикладные потоки выглядят более интересно, там доклады, в основном, от мэйджоров (Google, Amazon, Alibaba и т.д.). Расскажу о тех выступлениях, на которых удалось побывать.
Data For Good
Начался день с достаточно пространного выступления о том, что данные должны приносить пользу и использоваться во благо. Выступает професор Калифорнийского университета (стоит отметить, что на KDD очень много женщин, как среди слушателей, так и среди докладчиков). Всё это выражается в аббревиатуре FATES:
- Faireness — никаких биасов в прогнозах моделей, всё гендерно-нейтрально и толерантно.
- Acountability — должен быть кто-то или что-то, несущее ответственность за принятые машиной решения.
- Transparency — прозрачность и объяснимость принимаемых решений.
- Ethic — при работе с данными особый акцент должен быть на этичности и приватности.
- Safety and security — система должна быть безопасной (не наносить вреда) и защищенной (устойчивой к манипуляционным воздействиям извне)
Этот манифест, к сожалению, скорее выражает желание и слабо соотносится с реальностью. Политкорректной модель будет, только если убрать из неё все признаки; ответственность перенести на кого-то конкретного всегда очень сложно; чем дальше развивается ДС, тем сложнее интерпретировать, что-же там внутри модели происходит; по этике и приватности несколько хороших примеров было в первый день, но в остальном, к данным часто относятся достаточно вольно.
Ну и нельзя не признать, что современные модели часто не безопасны (автопилот может и угробить машину с водителем) и не защищены (можно подобрать примеры, ломающие работу нейросетки, даже не зная, как сеть устроена). Интересная недавняя работа DeepExplore: система для поиска уязвимостей в нейросетях генерирует, в том числе, картинки, заставляющие автопилот рулить не туда.

Далее дается yet another определение Data Science как «DS is the study of extracting value form data». В принципе, достаточно неплохо. В начале выступления докладчица специально оговорилась о том, что ДС часто смотрят на данные только с момента анализа, тогда как полный жизненный цикл гораздо шире, и это, в том числе, нашло отражение в определении.
Ну и не обошлось без нескольких примеров работ лаборатории.
Снова разберём задачу оценки влияния многих причин на результат, но уже не с позиции рекламы, а в целом. Есть ещё не опубликованная статья. Рассмотрим, например, вопрос о том, каких актеров выбрать для фильма, чтобы собрать хорошую кассу. Анализируем актерские списки самых кассовых фильмов и пытаемся предсказать вклад каждого из актеров. Но! Есть так называемые confounders, которые влияют на то, насколько эффективен будет актер (например, Сталлоне неплохо зайдет в трешовом боевике, но не в романтической комедии). Чтобы выбрать правильно, нужно найти всех confounders и оценить их, но мы никогда не будем уверены, что нашли всех. Собственно, в статье предлагается новый подход — deconfounder. Вместо выделения confounders явно вводим латентные переменные и оцениваем их в unsupervised-режиме, а затем учим модель с их учетом. Звучит всё это достаточно странно, потому как похоже на простой вариант эмбедингов, в чем новизна, не понятно.
Было показано еще несколько красивых картинок-примеров, как в их университете двигают вперед AI и т.д.
E-commerce and Profiling
Пошел на прикладную секцию по коммерции. В начале было несколько весьма интересных докладов, в конце некоторое количество каши, но обо всем по порядку.
New User Modeling and Churn prediction
Интересная работа Snapchat о предсказании оттока. Ребята используют идею, которую мы тоже с успехом обкатывали еще 4 года назад: прежде чем предсказывать отток, надо пользователей поделить на кластеры по типу поведения. При этом векторное пространство по типам действий у них получилось достаточно бедным, всего из нескольких типов взаимодействий (нам, в свое время, пришлось делать отбор признаков, чтобы от трех сотен перейти к полутора), но они обогащают пространство дополнительными статистиками и рассматривают как временной ряд, в итоге кластеры получаются не столько про то, что делают пользователи, сколько про то, как часто они это делают.
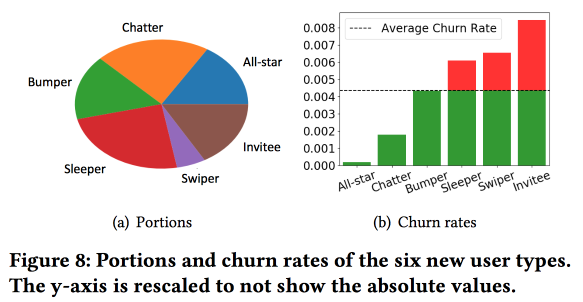
Важное наблюдение: в сети есть «ядро» наиболее плотно связанных и активных пользователей размером в 1,7 млн человек. При этом поведение и удержание пользователя сильно зависит от того, сможет ли он связаться с кем-то из «ядра».
Дальше начинаем строить модель. Возьмем новичков за полмесяца (511 тыс.), простые фичи и эго-нетворки (размер и плотность), и посмотрим, связываются ли они с «ядром» и т.д. Поведение пользователей скормим LSTM и получим точность прогноза оттока немного выше, чем у logreg (на 7-8 %). А вот дальше начинается интересное. Чтобы учесть специфику отдельных кластеров, будем тренировать несколько LSTM параллельно, а сверху навесим attention-слой. В результате такая схема начинает работать и на кластеризацию (какой из LSTM-ов получил attention), и на прогноз оттока. Дает еще +5-7 % прироста по качеству, и logreg уже выглядит бледно. Но! На самом деле, по-честному надо было бы сравнить с сегментированным logreg-ом, натренированным отдельно для кластеров (которые можно получить и более простыми способами).
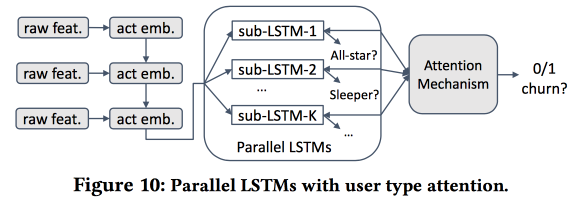
Я спросил про интерпретируемость: ведь отток часто предсказывают не для того, чтобы получить прогноз, а чтобы понять, какие факторы на него влияют. Докладчик явно был готов к этому вопросу: для этого используют выделенные кластера и анализируют, чем те из них, где прогнозы оттока выше, отличают от других.
Universal User Representation
Ребята из Alibaba рассказывают о том, как строить эмбединги пользователей. Оказывается, иметь много представлений пользователей плохо: многие не доработаны, силы тратятся зря. У них получилось сделать универсальное представление и показать: что оно работает лучше. Естественно на нейросетках. Архитектура достаточно стандартная, уже в том или ином виде не раз описывалась на конференции. На вход подаются факты из поведения пользователя, по ним строим эмбединг, отдаём это всё в LSTM, сверху вешаем attention-слой, а рядом с ним дополнительно сетку по статичным фичам, венчаем multitask-ом (по сути, несколькими маленькими сетками под конкретную задачу). Обучаем всё это вместе, выход с attention и будет эмбедингом пользователя.
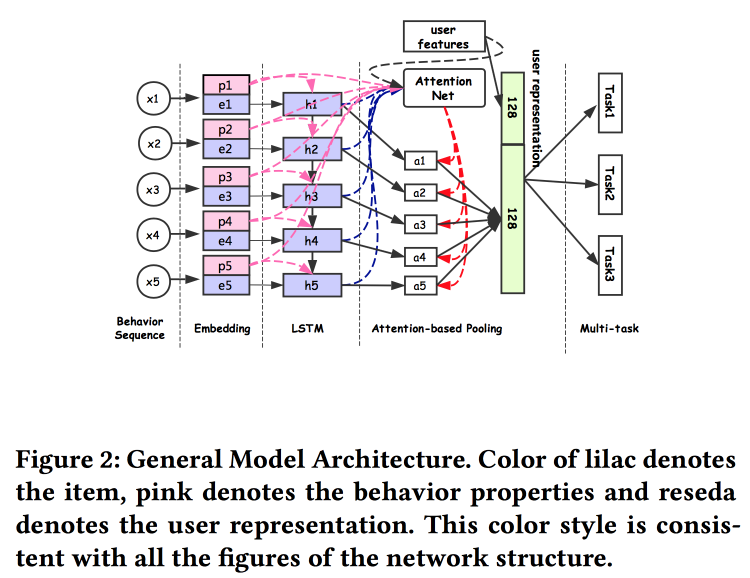
Есть и несколько более сложных добавлений: помимо простого attention добавляют «углубленный» attention net, а также используют модифицированный вариант LSTM — property gated LSTM
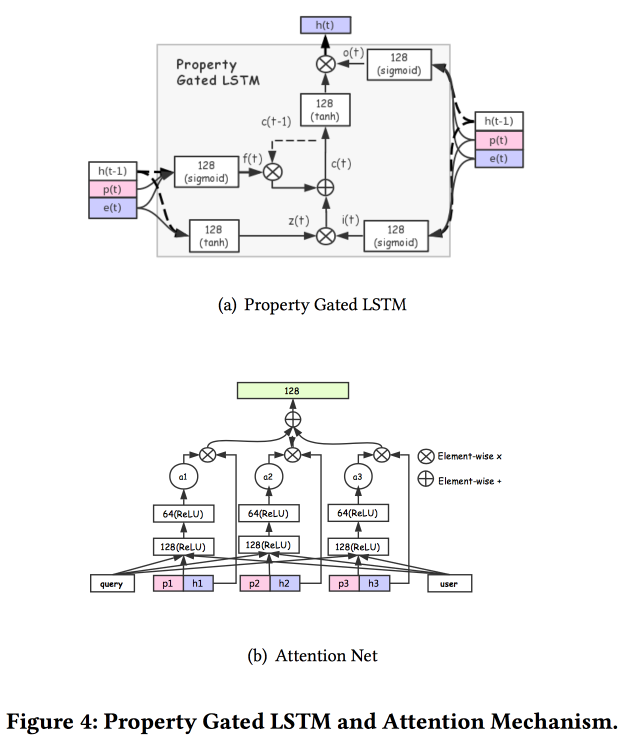
Задачи, на которых всё это обкатывают: CTR prediction, Price preference prediction, learning to rank, fashion following prediction, shop preference prediction. Датасет за 10 дней включает в себя 6*109 примеров для обучения.
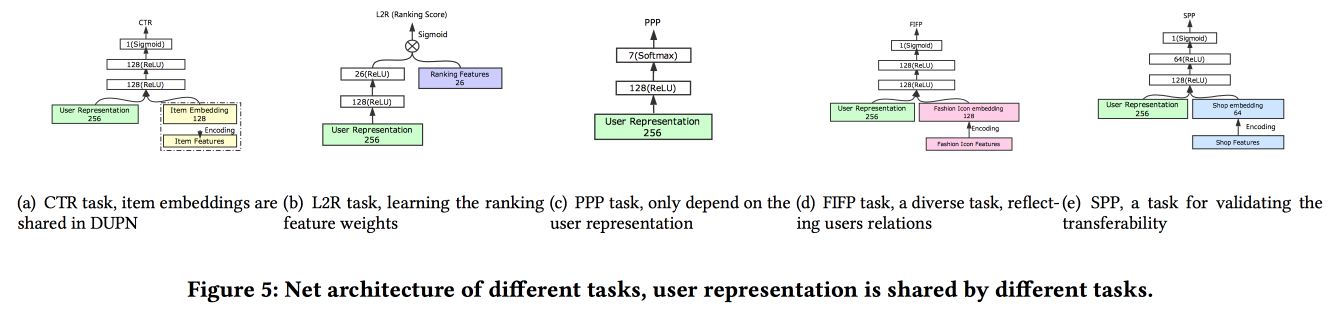
Дальше был нежданчик: тренируют всё это на TensorFlow, на CPU-кластере из 2000 машин по 15 ядер, уходит 4 дня на то, чтобы окучить данные за 10 дней. Поэтому далее дообучают день за днем (10 часов на этом кластере). Про ГПУ/ПЛИС не успел спросить :(. Добавление новой задачи делают либо через переобучение целиком, либо через дообучение неглубокой сетки (netwrok fine tuning). В runtime для инференса хранят представления (выход с attention для конкретных пользователей) и вычисляют только головы сеток под конкретные задачи. А/Б-тест показал прирост 2-3 % по разным показателям.
E-Tail product return prediction
Предсказывают возврат товара пользователем после покупки, работу презентует IBM. К сожалению, пока в открытом доступе текста нет. Возврат товаров — это серьезная проблема стоимостью 200 миллиардов долларов в год. Для построения прогноза возврата использует модель гиперграфа, связывающего продукты и корзины, по данной корзине пытаются найти ближайших по гиперграфу, после чего оценивают вероятность возврата. Чтобы предотвратить возврат у интернет-магазина есть много возможностей, например, предлагать скидку за удаление определенных товаров из корзины.
Сразу отметили, что есть существенное различие между корзинами с дубликатами (например, две одинаковые футболки разного размера) и без, поэтому сразу надо строить разные модели для этих двух случаев.
Общий алгоритм называется HyperGo:
- Строим гиперграф для представления покупок и возвратов с информацией от пользователя, продукта, корзины.
- Далее используем local graph cut на базе random walk, чтобы получить локальную информацию для прогноза.
- Отдельно рассматриваем корзины с дублями и без дублей.
- Используем байесовские методы для оценки влияния отдельного продукта в корзине.
Сравнивают качество прогноза возврата с кНН по корзинам, взвешенный по Жаккарду кНН, нормирование по количеству дубликатов, получаем прирост по результату. На слайдах мелькала ссылка на GitHub, но найти их исходники не удалось, и в статье ссылки нет.
OpenTag: Open Attribute Value Extraction from Product Profiles
Достаточно интересная работа от Amazon. Задача: намайнить для Alexa разных фактов, чтобы она лучше отвечала на вопросы. Рассказывают, как всё сложно, старые системы не умеют работать с новыми словами, часто требуют большого количества рукописных правил и эвристик, результаты при этом так себе. Порешать все проблемы помогут, конечно же, нейросетки с уже примелькавшейся архитектурой embednig-LSTM-attention, но LSTM сделаем двойным, а сверху еще накинем Conditional Random Field.

Будем решать задачу тегирования последовательности слов. Тэги будут показывать, где у нас начинаются и заканчиваются последовательности определенных атрибутов (например, вкуса и состава собачьего корма), их и будет пытаться предсказывать LSTM. В качестве плюшки и реверанса в сторону Mechanical Turk используют активное обучение модели. Для выбора примеров, которые нужно послать на доразметку, используют эвристику «брать те примеры, где чаще всего между эпохами свопались теги».
Learning and Transferring IDs Representation in E-commerce
В своей работе коллеги из Alibaba снова возвращаются к вопросу построения эмбедингов, в этот раз смотрят не просто на пользователей, а на ИД в принципе: для продуктов, брендов, категорий, пользователей и т.д. В качестве источника данных используют сессии взаимодействия, учитывают и дополнительные атрибуты. В качестве основного алгоритма используют скипграммы.
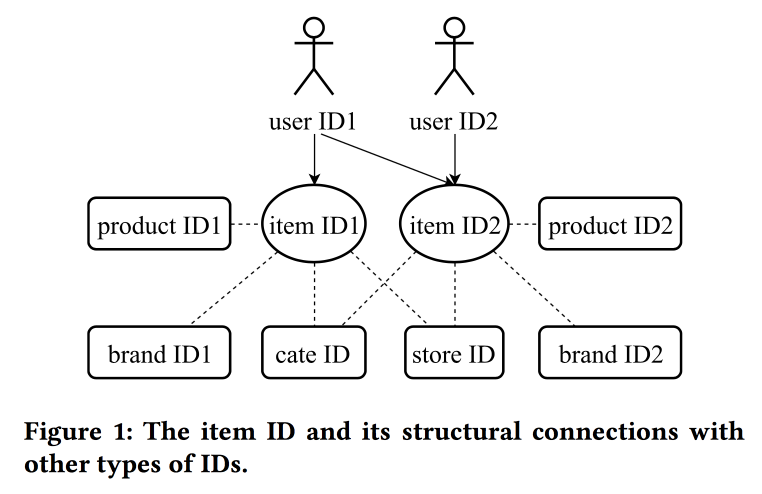
У докладчика очень тяжелое произношение с сильным китайским акцентом, понять, что происходит, почти не реально. Одна из «фишек» работы заключается в механиках переноса представлений при недостатке информации, например, с item-ов на пользователя через усреднение (быстро, не надо учить модель целиком). Со старых item-ов можно инициализировать новые (видимо, по контентной похожести), а также перенести представление пользователя из одного домена (электроника) в другой (одежда).
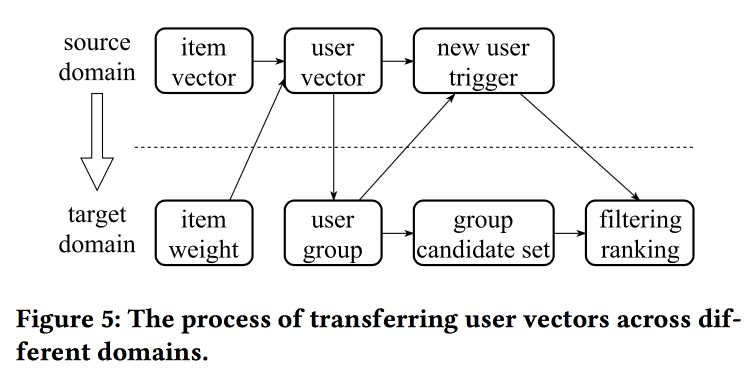
В целом не совсем понятно, где тут новизна, видимо, надо копнуть подробности; кроме того, не ясно, как это соотносится с предыдущим рассказом про унифицированные представления пользователей.
Online Parameter Selection for Web-based Ranking Problems
Очень интересная работа от товарищей из LinkedIn. Суть работы в том, чтобы в онлайне выбирать оптимальные параметры работы алгоритма с учетом нескольких конкурирующих целей. В качестве области применения рассматривают ленту и пытаются увеличить количество сессий некоторых типов:
- Сессию с некоторым виральным действием (VA).
- Сессия с отправкой резюме (JA).
- Сессия с взаимодействием с контентом в ленте (EFS).
Функция ранжирование в алгоритме — взвешенное среднее по прогнозам конверсии в эти три цели. Собственно, веса и есть те параметры, которые будем пробовать оптимизировать в онлайне. Изначально формулируют бизнес-задачу как «максимизировать количество вирусных сессий при сохранении двух других типов не ниже некоторого уровня», но затем немного трансформируют для простоты оптимизации.
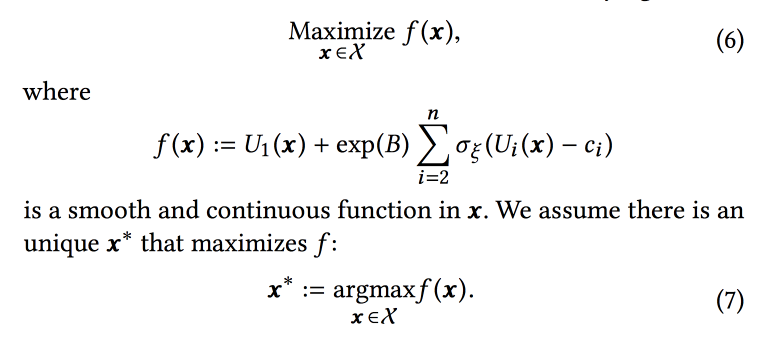
Моделируем данные набором биномиальных распределений (сконвертится пользователь в нужную цель или нет, увидев ленту с определенными параметрами), где вероятность успеха при заданных параметрах Гауссовский процесс (свой для каждого типа конверсии). Далее используем сэмлпер Томпсона с «бесконечнорукими» бандитами для подбора оптимальных параметров (не в онлайне, а в офлайне на исторических данных, поэтому долго). Дают несколько советов: использовать bold points для построения начальной сетки и обязательно добавить epsilon-greedy-сэмплирование (с вероятностью эпсилон пробовать случайную точку в пространстве), иначе можно проглядеть глобальный максимум.
Симулируют взятие образцов в офлайне раз в час (надо много сэмплов), итогом становится некое распределение оптимальных параметров. Далее при заходе пользователя из этого распределения берут конкретные параметры для построения ленты (важно это делать консистентно с seed-ом из ID пользователя для инициализации, чтобы лента пользователя не менялась радикально).
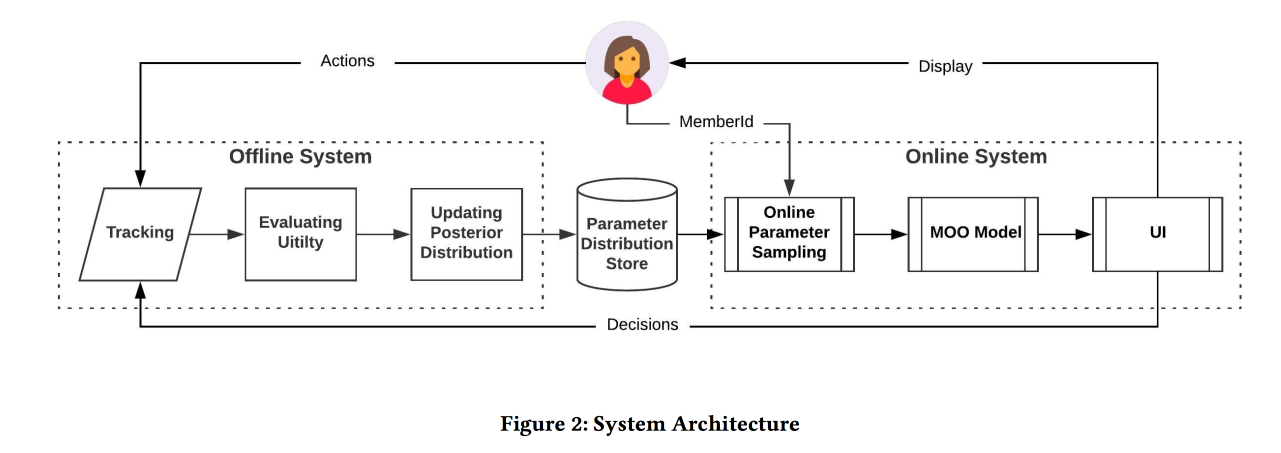
По результатам А/Б-эксперимента получили прирост отправки резюме на 12 % и лайков на 3 %. Делятся некоторыми наблюдениями:
- Проще участить сэмплирование, чем пытаться внести больше информации в модель (например, о дне недели/часе).
- Предполагаем в этом подходе независимость целей, но непонятно, есть ли она (скорее, нет). Однако подход работает.
- Бизнес должен ставить цели и пороги.
- Важно исключить человека из процесса и дать ему заняться чем-то полезным.
Near Real-time Optimization of Activity based notification
Еще одна работа от LinkedIn, на этот раз про управление уведомлениями. У нас есть люди, события, каналы доставки и долговременные цели по увеличении вовлеченности пользователей без значимого негатива в виде жалоб и отписок от пушей. Задача важная и сложная, и нужно всё делать правильно: правильным людям в правильное время отправить правильный контент по правильному каналу и в правильном объеме.
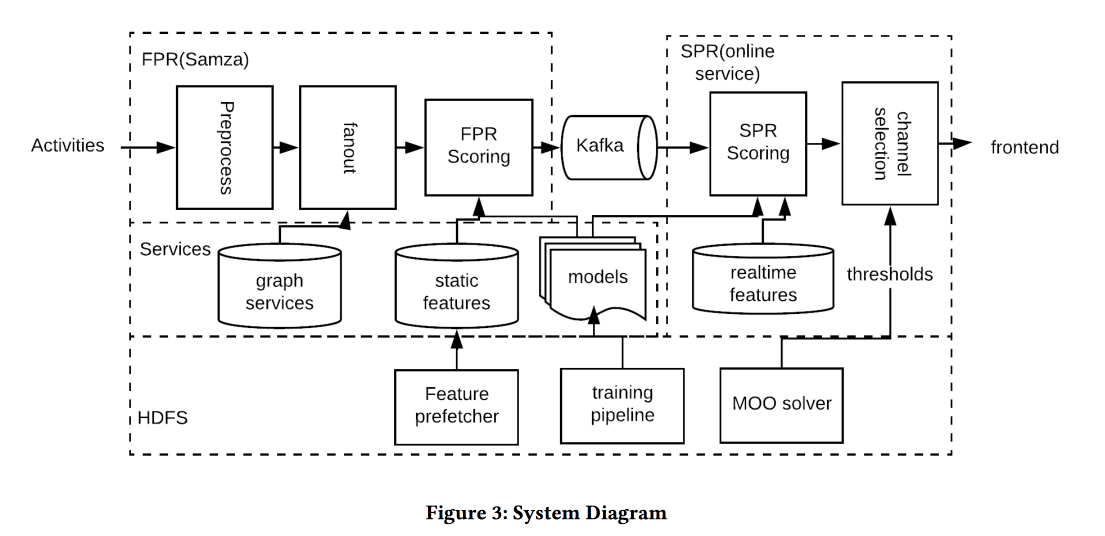
Архитектура системы на картинке выше, суть происходящего примерно следующая:
- Фильтруем всякий спам на входе.
- Правильные люди: шлем всем, кто достаточно сильно связан с автором/контентом, балансируя порог на силу связи, управляем покрытием и релевантностью.
- Правильное время: сразу шлем контент, для которого важно время (события друзей), остальное можно придержать для менее динамичных каналов.
- Правильный контент: используют logreg! Строят модель прогноза клика на куче признаков, отдельно для случая, когда человек в приложении и когда нет.
- Правильный канал: ставим разные пороги на релевантность, самый строгий для пуша, пониже — если пользователь сейчас в приложении, еще ниже — для почты (в ней же всякие дайджесты/рекламы).
- Правильный объем: модель обрезания по объему стоит на выходе, она же смотрит на релевантность, рекомендуют делать индивидуально (хорошая эвристика порога — минимум score отправленных объектов за последние несколько дней)
На А/Б-тесте получили несколько процентов роста количества сессий.
Real-time Personalization using Embeddings for Search Ranking at Airbnb
А это был best application paper от AirBnB. Задача: оптимизировать выдачу похожих размещений и поисковую выдачу. Решаем через построение эмбедингов размещений и пользователей в одном пространстве, чтобы дальше оценивать похожесть. Важно помнить, что есть долговременная история (предпочтения пользователя) и кратковременная (текущий интент пользователя/сессии).
Не мудрствуя лукаво, используем для построения эмбедингов мест word2vec на последовательностях кликов в поисковых сессиях (одна сессия — один документ). Но некоторые модификации всё-таки делаем (КДД, как никак):
- Берем сессии, в течение которых было бронирование.
- То, что в итоге забронировано, держим как глобальный контекст для всех элементов сессии при w2v-обновлении.
- Негативы в обучении сэмплируем в том же городе.

Результативность такой модели проверяем тремя стандартными способами:
- Проверка в офлайне: насколько быстро сможем поднять правильный отель наверх в поисковой сессии.
- Проверка ассесорами: построили специальный инструмент для визуализации похожих.
- А/Б-тестом: спойлер, CTR вырос значительно, бронирования не прибавились, но теперь происходят раньше
Результаты поисковой выдачи стараемся ранжировать не только загодя, но и переранжировать (поэтому real-time) при поступлении отклика — клика на одно предложение и игнора другого. Подход заключается в том, чтобы собрать прокликаные и заигноренные места в две группы, найти в каждой центроид по эмбедингам (есть спецформула), а дальше в ранжировании поднимаем похожее на клики, опускаем похожее на скипы.
На А/Б-тесте получили прирост бронирований, подход выдержал проверку временем: придуман полтора года назад и до сих пор крутится в production.
А если надо искать в другом городе? По кликам заранее отранжировать не получится, нет информации об отношении пользователям к местам в этом населённом пункте. Для обхода этой проблемы введем «контентые эмбединги». Сначала заведем простое дискретное пространство признаков (дешевый/дорогой, в центре/на отшибе и т.д.) размером порядка 500 тыс. типов (и для мест, и для людей). Дальше строим эмбединги по типам. При обучении не забываем добавить явный негатив по отказам (когда хозяин места не подтвердил бронь).
Graph Convolutional Neural Networks for Web-Scale Recommender Systems
Работа от Pinterest по рекомендации пинов. Рассматриваем двудольный граф пины-пользователи и добавляем в рекомендации сетевые фичи. Граф очень большой — 3 миллиарда пинов, 16 миллиардов взаимодействий, классические графовые эмбединги завести не удалось. В итоге, отталкиваясь от системы GraphSAGE, строящей эмбединги по локальной структуре (смотрим на эмбединги соседей и обновляем свой, обновление передаем соседям по модели message passing), строят PinSAGE. После того, как эмбединги построены, рекомендуют через поиск ближайших соседей в пространстве эмбедингов.
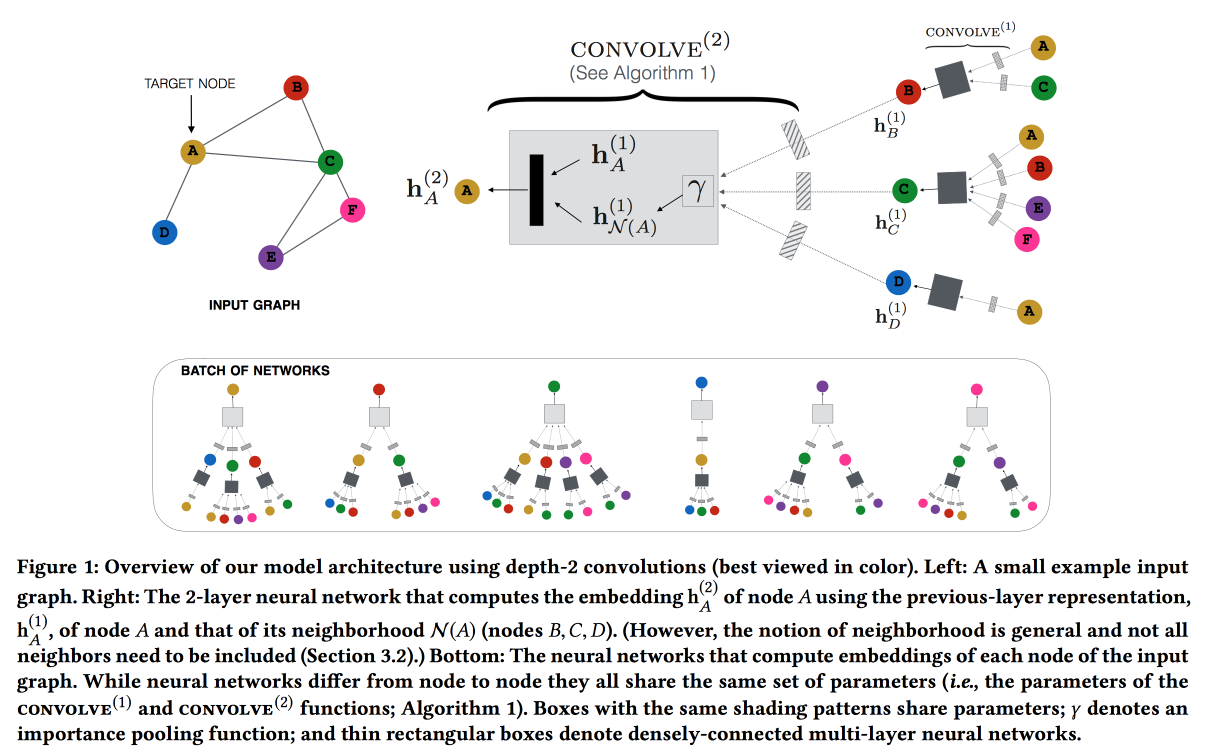
Дальше начинаются «кровавые подробности»:
- Советуют использовать max margin loss.
- Обучение идет совместно на CPU/GPU: CPU сэмплирует пакет подграфов одинаковой структуры (чтобы GPU мог эффективно запаралелить) и шлет GPU. Ответа не ждет, сразу начинает готовить следующий пакет.
- Для вершин с большой степенью берут не всех соседей, а сэмплируют random walk-ом.
- Используют подход Curriculum Learning: постепенно добавляют все больше hard negative-примеров. на которых модель в прошлые эпохи часто ошибалась.
- Сверху Map reduce, чтобы применить натренированную свертку и получить эмбединги для всех вершин.
В итоге наглядно показали, что схема работает лучше визуальной похожести, по аннотациям и текущей коллаборивке. Внедрили, проявила себя хорошо на А/Б-тесте.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
«А что будет, если дать возможность рекомендателю спросить пользователя, чего же тот хочет?» — таким вопросом задались ребята из YouTube в своей работе. Вопросы рассматривали только одного формата: «на какую тему хотели бы посмотреть видео?». и использовали результат для оптимизации «онбординга» (есть, оказывается, в YouTube место, где можно задать свои интересы).
Сейчас в YouTube рекомендации строятся с помощью Video-RNN, которая предсказывает ID видео. Ребята решили взять ту же архитектуру, но предсказывать ID некой темы, а также добавить информацию о теме поверх старой сетки (post fusion). Ниже показан результат (наконец-то где-то применили GRU, а то всё LSTM и LSTM).

Тренируем это счастье на 7 днях данных, тестируем на 8-м, берем пользователей с достаточным количеством просмотров. Интересно, что на прогнозирование темы работает на 8 % лучше, чем многоклассовая классификация по последовательности в форме баг-оф-вордс. В А/Б-тесте interleaving-ом +0,7 % к времени просмотра на главной странице, +1,23 % к открытию уведомлений.
После чего перешли к онбордингу: при использовании персонифицированной подборки тем пользователь заполняет онбординг на 18 % чаще, что в итоге выливается в +4 % прироста времени просмотра.
Graph and social nets
После обеда решил послушать исследовательские выступления, благо тема, что называется, близка к сердцу.
Graph Classification using Structural Attention
Достаточно интересная работа по классификации графов, ориентированная на графы «большого размера». В качестве примеров в основном смотрел на разные молекулы, например, лекарства. Раньше в этой области использовались графлеты, но на больших графах с ними сложно, поэтому будем тренировать сетку.
По сути, делаем LSTM по последовательности блужданий по графу, но добавляем своеобразный attention-слой, который по типу текущей вершины выдает вероятности того, в какие типы вершин надо двигаться дальше. Этот слой фокусирует наше блуждание в нужном направлении. В качестве типов рассматривал химический элемент, в кулуарах подкинул автору идею перейти от типов вершин к некоторым простым эмбедингам, сказала, что попробует.
Тренируется сеть по модели РЛ: даем ей побродить по графу ограниченное количество шагов, если после этого классификация не удалась, даем пенальти. Помимо attention, ведущего прогулку, поверх LSTM добавляют self-attention, который смотрит на всю историю прогулки (уже примелькавшаяся схема). При пересечении заводим несколько «агентов», которые будут делать прогулки, и аггрегируем их ответы.
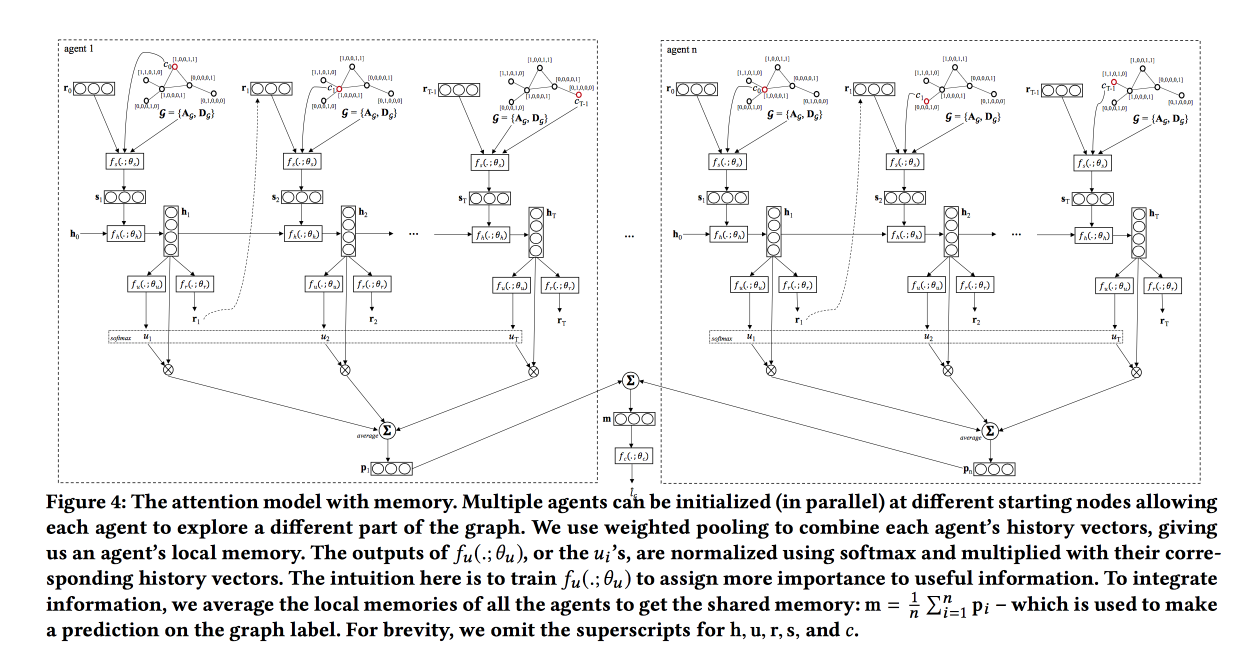
Тестировали на данных по структуре лекарств, сравнивали только с простыми baseline с мотивацией — мы же не видим весь граф. Прогулки не всегда работают, хотят попробовать TreeLSTM.
SpotLight: Detecting Anomalies in Streaming Graphs
Авторы пытаются находить аномалии в графах взаимодействий, например, спам-прозвон, сканирование портов, выпадение коммутатора. Определяют аномалию как «неожиданное появление или исчезновение крупного плотного подграфа». Задача усложняется тем, что определять аномалии надо поточно, имея ограниченные память и время.
Основная идея заключается в использовании «хешировния» графов в некоторое метрическое пространство и сравнении последовательности снепшотов хешей. Если в какой-то момент снепшот прыгнет куда-то далеко, то у нас аномалия.
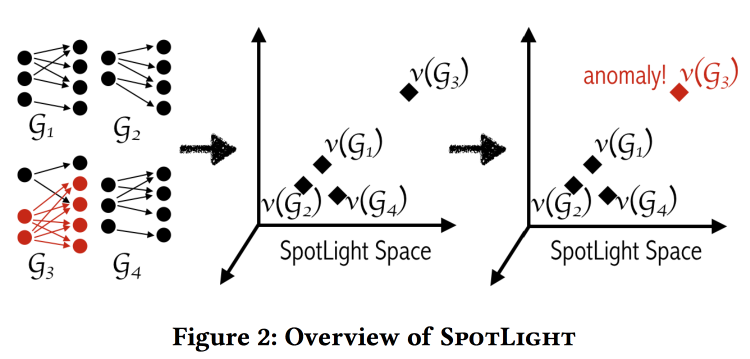
Алгоритм хеширования подкупает своей простотой: возьмем два случайных региона графа и посчитаем, сколько между ними связей. Результат будет одной размерностью хеша. Повторим процедуру для остальных размерностей. Для подсчета хеша не обязательно видеть весь граф, хеш можно считать на потоке событий о добавлении/удалении связей.
Несмотря на кажущуюся наивность, авторы приводят некоторые теоретические гарантии по разделимости ситуаций с аномалиями и без. Проверяли на labeled DARPA dataset. Вроде работают хорошо, при этом по сравнению с baseline-ами пропускают разные типы атак (т.е. есть потенциал для ансамбля).
Adversarial Attacks on Graph Networks
А теперь лучшая исследовательская работа. Adversary очень популярны в интернете, особенно в рекомендациях, поиске и т.д.: злоумышленники пытаются поднять свой сайт/контент повыше. Сейчас всё чаще в индустрии внедряются сети, работающие с графами — являются ли они устойчивыми к атакам (спойлер — нет)? В качестве примера рассмотрим задачу восстановления класса узлов графа при неполной разметке.
В принципе, у атакующего есть много возможностей:
- Менять атрибуты на «своем» узле.
- Менять связи «своего» узла.
- Попробовать «подкинуть» связи чужому узлу.
- Атака может быть направлена не только на процесс пересечения, но и на процесс обучения (poisoning).
Предлагают два подхода ко взлому. При открытой информации о сети, которую надо взломать, делают контрсеть, при закрытой — используют генетический алгоритм. В итоге все популярные графовые сетки оказались взломаны и классифицировали нужный узел неправильно. Я не удивлен.
В отличие от картинок, с графами всё сложно с точки зрения unnoticeability: как убедиться, что внесенные изменения не будут замечены?
Multi-Round Influence maximization
В работе решают задачу нахождения небольшого подмножества узлов в соцсети для обеспечения максимального распространения контента. Ранее проблема была изучена в случае одного раунда воздействия, теперь посмотрим случай, когда раундов несколько.
При моделировании распространения воздействий используют схему с независимыми каскадами, но есть и другая схема с линейным порогом (разобрана в статье, но не на слайдах).
Используют Монте-Карло-симуляцию и предлагают несколько схем:
- С учетом результатов предыдущих раундов: работает лучше, но в реальности далеко не всегда эта информация есть.
- Без учета результатов предыдущих раундов: по сути, просто повторение процедуры.
- Кросс-раунд схему: пытаются оценивать маргинальный вклад inffluencer-ов относительно ранее выбранных. Работает хорошо, но долго.
Для ускорения процесса расчетов предлагают подход Reverse-Reachable sets: если ходить не от inffluencer-а, а к нему, то получается быстрее.
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
В академии не хватает больших графов. Раньше генерировали синтетические, теперь будем расширять существующие, сохраняя распределение основных свойств.
Предложенный метод прост, но работает только с графами, где степень вершин распределена по power law. Идея в том, что мы берем оригинальный граф, «клонируем» его вершины, а затем сэмплируем дуги и для каждой кидаем монетку: прорисовать «клон» этой дуги в и из оригинала в клон оригинала вершины на той стороне.

Далее приводят сравнение с некоторыми другими механизмами и показывают, что новый сильно лучше, распределения свойств сохраняются. Есть код на гитхабе.
Кейноут
Пожилой британский профессор рассказывает о data science в финансах. На самом деле. не только в финансах, а за жизнь. Приведу пару интересных цитат.
All models are wrong, but some are useful — модели в data science, по сути, не отражают природу, но могут до определенного предела давать хорошие прогнозы. «Предел» же может наступить неожиданно и об этом надо помнить (дрейф признаков, резкие изменения в среде, adversarial и т.д.)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — помнить о многих типичных ошибках (overfitting, selection bias, обратная связь, подглядывание в будущее и т.д.)
Первые специалисты по анализу данных появились в 1762 году с открытием The Equitable Life Assurance Society, выдававшей страховки на базе анализа атрибутов пользователя.
Сейчас же страховым компаниям приходится трудно: в 2011-м окончательно запретили дискриминацию по половому признаку, теперь нельзя учитывать пол при страховании (что чертовски сложно — даже если явно спрятать фичу «пол», модель с большой вероятностью апроксимирует её по другим признакам). Это привело к интересному эффекту в UK:
- Женщины водят аккуратнее и реже попадают в аварии, поэтому страховки для них были дешевле.
- После уравниловки стоимость страховки для женщин поднялась, а для мужчин опустилась.
- Рынок работает: в результате на дорогах стало больше мужчин и меньше женщин.
- Поскольку средняя «аккуратность» водителей на дорогах снизилась, аварий стало больше.
- После чего страховки, естественно, стали дорожать.
- Дорожающие страховки стали еще сильнее вымывать аккуратных водителей.
В итоге получили «спираль смерти».
Эта тема перекликается с открывавшим день выступлением. F — Fairness, это некий недостижимый облачный замок. Модели ML учатся разделять примеры (в том числе людей) в пространстве признаков, поэтому не могут быть «справедливыми» по определению.
Sadler
dmitrybugaychenko Автор
В том-то и дело что сначала для мужчин подешевели, а для женщин подорожали (но стали равными между собой). А дальнейшее увеличение в первую очередь тоже чувствовали женщины, так как повышение для них шло с более высокого уровня.