
Под катом компоненты и особенности работы Headless Chrome, интересные сценарии использования Headless Chrome. Вторая часть про Puppeteer — удобную Node.js-библиотеку для управления Headless-режимом в Google Chrome и Chromium.
О спикере: Виталий Слободин — бывший разработчик PhantomJS — тот, кто закрыл его и похоронил. Иногда помогает Константину Токареву ( annulen) в «воскрешенной» версии QtWebKit — том самом QtWebKit, где есть поддержка ES6, Flexbox и многие других современных стандартов.
Виталий любит исследовать браузеры, в свободное время копаться в WebKit, Chrome и прочее, прочее. Про браузеры сегодня и поговорим, а именно про безголовые браузеры и всю их семейку призраков.
Что такое безголовый браузер?
Уже из названия понятно, что это нечто без головы. В контексте браузера это значит следующее.
- У него нет реальной отрисовки содержимого, то есть он все отрисовывает в памяти.
- За счет этого он потребляет меньше памяти, потому что не нужно отрисовывать картинки или гигабайтные PNG, которые люди пытаются при помощи бомбы положить в бэкенд.
- Он работает быстрее, потому что ему ничего не нужно отрисовывать на реальном экране.
- Имеет программный интерфейс для управления. Вы спросите — у него же нет интерфейса, кнопочек, окошек? Как же им управлять? Поэтому конечно же он имеет интерфейс для управления.
- Немаловажное свойство — возможность установки на «голый» Linux-сервер. Это нужно для того, что, если у вас есть свежеустановленная Ubuntu или Red Hat, вы можете просто туда закинуть бинарник или поставить пакет, и браузер будет работать из коробки. Никакого шаманства или вуду-магии не понадобится.
Так схематично выглядит обычной браузер на основе WebKit. Вы можете не вчитываться в компоненты — это просто наглядное изображение.

Нас интересует только верхний компонент Browser UI. Это тот самый интерфейс пользователя — окошки, меню, всплывающие уведомления и все остальное.

Так выглядит безголовый браузер. Заметили разницу? Мы полностью убираем интерфейс пользователя. Его больше нет. Остается только браузер.
Сегодня мы будем говорить именно про Headless Chrome (). В чем между ними разница? На самом деле, Chrome — это брендированная версия Chromium, у которой есть проприетарные кодеки, тот же самый H.264, интеграции с сервисами Google и все остальное. Chromium — это просто открытая реализация.

Дата рождения Headless Chrome: 2016 год. Если вы сталкивались с ним, то можете задать мне каверзный вопрос: «Как так, я помню новость 2017 года?» Дело в том, что команда инженеров из Google связывалась с разработчиками PhantomJS еще в 2016 году, когда они только-только начинали реализовывать Headless-режим в Chrome. Мы писали целые гуглдоки, как мы будем реализовывать интерфейс и прочее. Тогда Google хотели сделать интерфейс, полностью совместимый с PhantomJS. Это уже потом команда инженеров пришла к решению не делать таковую совместимость.
Об интерфейсе для управления (API), в качестве которого выступает Chrome DevTools protocol, поговорим позже и посмотрим, что с его помощью можно делать.
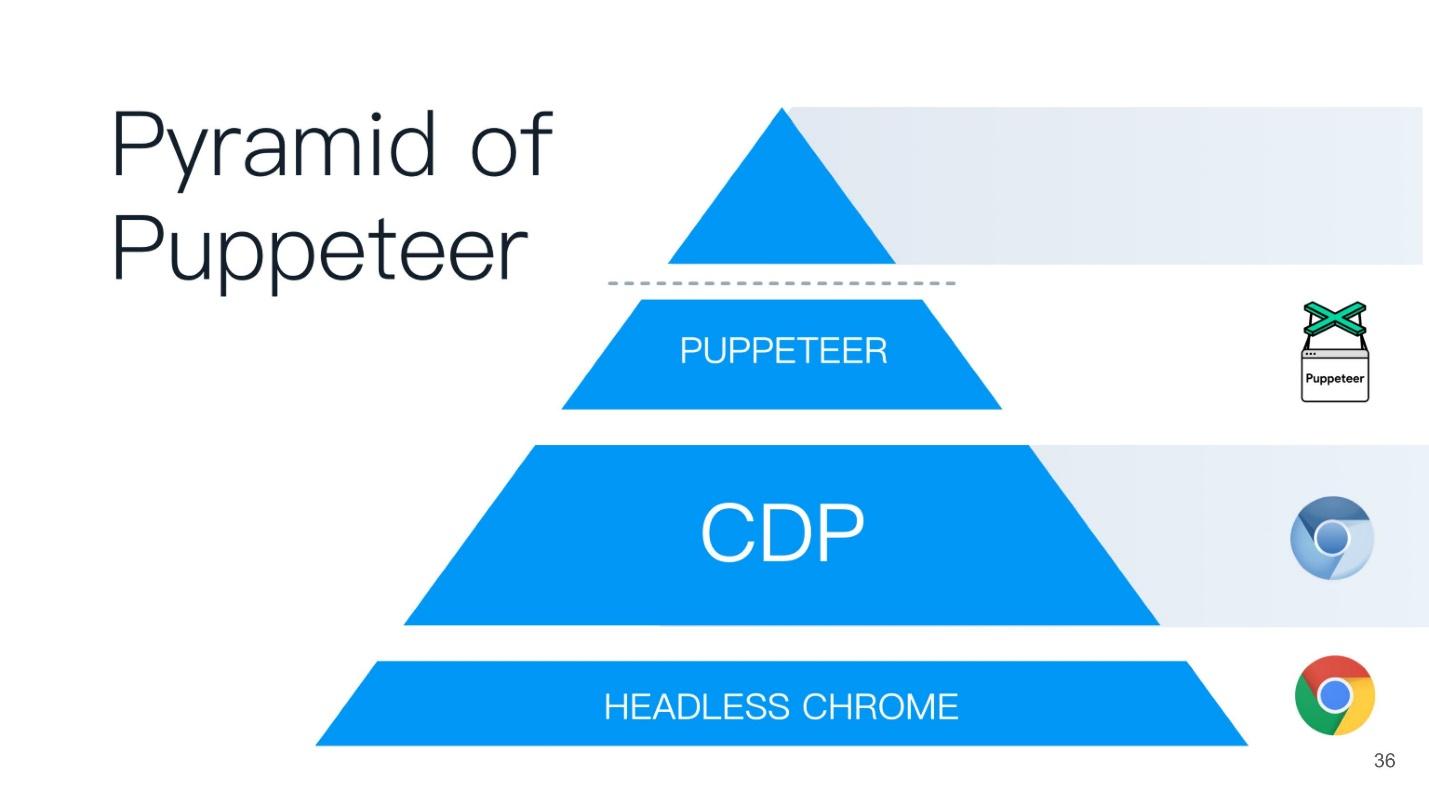
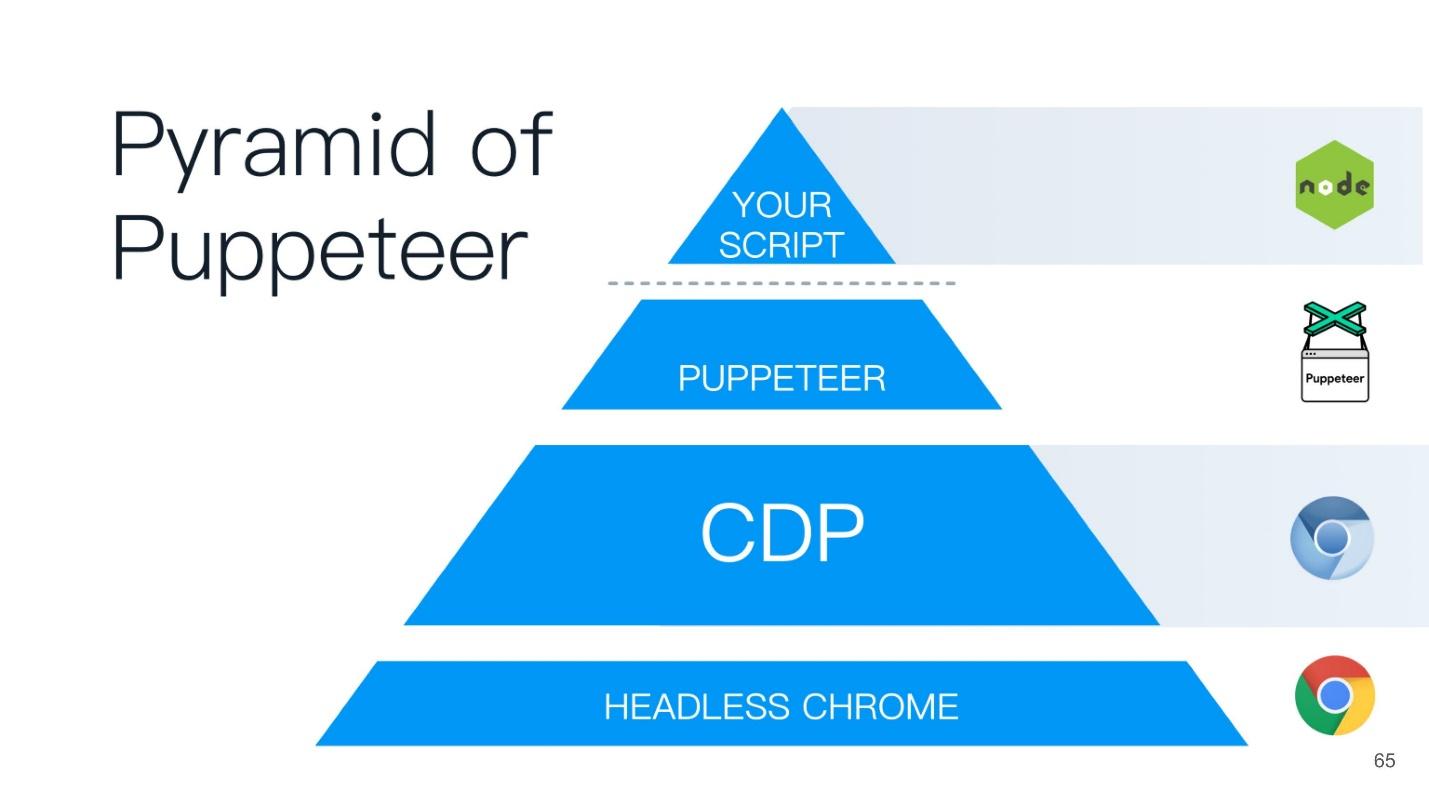
Эта статья будет строится по принципу пирамиды Puppeteer (с англ. кукловод). Хорошее название выбрано — кукловод — тот, кто управляет всеми остальными!
В основании пирамиды лежит Headless Chrome — безголовый Chrome — что это такое?
Headless Chrome
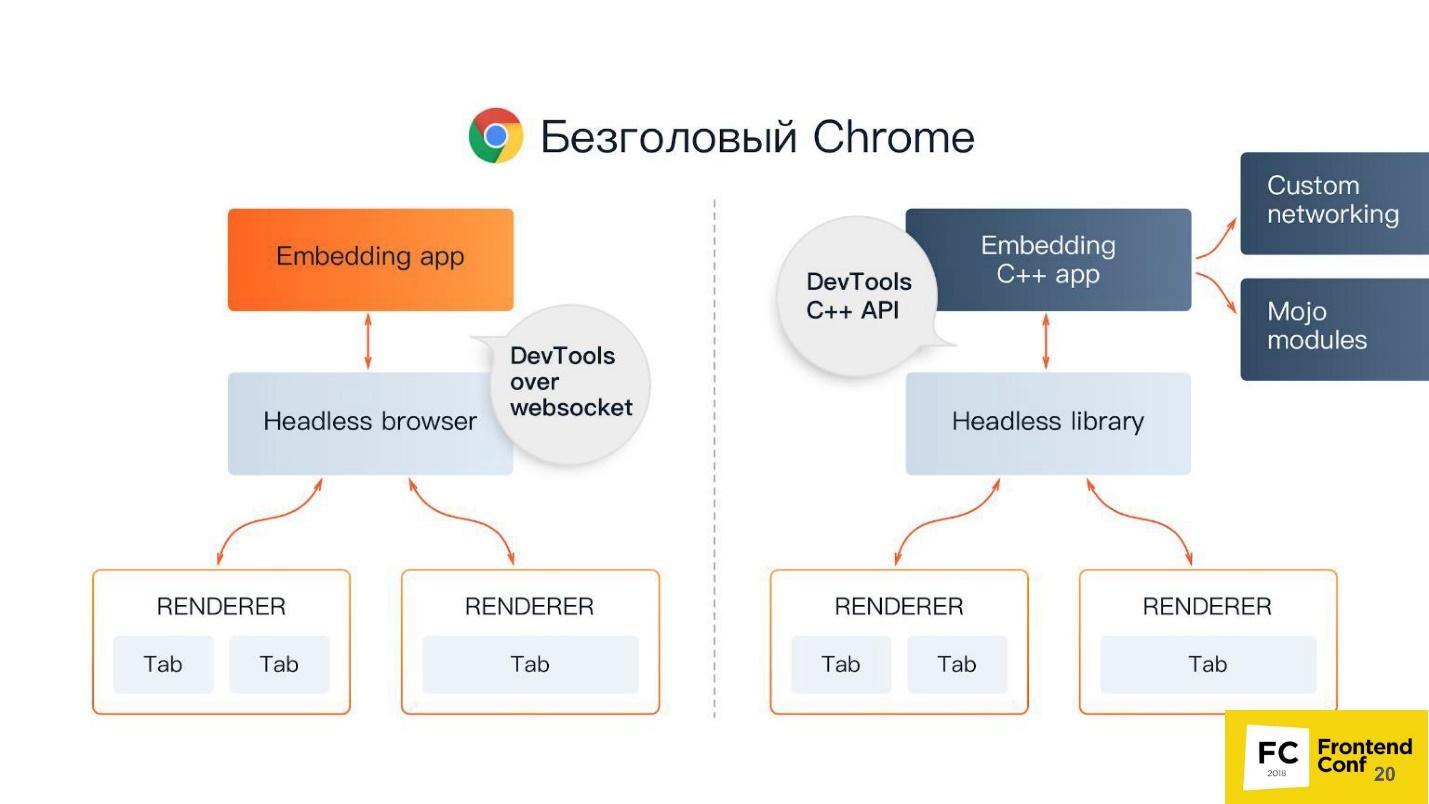
В центре — Headless browser — тот самый Chromium или Chrome (обычно Chromium). У него есть так называемые отрисовщики (RENDERER) — процессы, которые отрисовывают содержимое страницы (ваше окно). Причем, каждой вкладке нужен свой отрисовщик, поэтому, если открыть много вкладок, то Chrome запустит столько же процессов для отрисовки.
Поверх всего этого — ваше приложение. Если мы берем Chromium или Headless Chrome, то поверх него будет Chrome, либо какое-то приложение, в которое вы можете встроить его. Ближайшим аналогом можно назвать Steam. Все знают, что по сути Steam — это просто браузер к сайту Steam. Он, конечно, не headless, но похож на эту схему.
Есть 2 способа встраивать безголовый Chrome в ваше приложение (или его использовать):
- Стандартный, когда вы берете Puppeteer и используете Headless Chrome.
- Когда вы берете компонент Headless library, то есть библиотеку, которая реализует безголовый режим, и встраиваете в свое приложение, допустим, на языке C++.
Вы спросите, зачем C++ на фронтенде? Ответ — DevTools C++ API. Вы можете по-разному реализовывать и использовать возможности безголового Chrome. Если вы используете Puppeteer, общение с безголовым браузером будет осуществляться через веб-сокеты. Если вы встраиваете Headless library в десктопное приложение, то будете использовать нативный интерфейс, который написан на C++.
Но помимо всего этого у вас еще появляются дополнительные вещи, в том числе:
- Custom networking — кастомная реализация взаимодействия с сетью. Допустим, вы работаете в банке или в госструктуре, которая состоит из трех букв и начинается на «Ф», и используете очень хитрый протокол аутентификации или авторизации, который не поддерживается браузерами. Поэтому вам может понадобиться кастомный обработчик для вашей сети. Вы можете просто взять вашу уже реализованную библиотеку и использовать ее в Chrome.
- Mojo modules. Ближайшим аналогом Mojo являются нативные биндинги в Node.js к вашим нативным библиотекам, написанные в C++. Mojo делает то же самое — вы берете свою нативную библиотеку, пишите для нее Mojo-интерфейс, и потом можете в вашем браузере вызывать методы вашей нативной библиотеки.
Компоненты Chromium
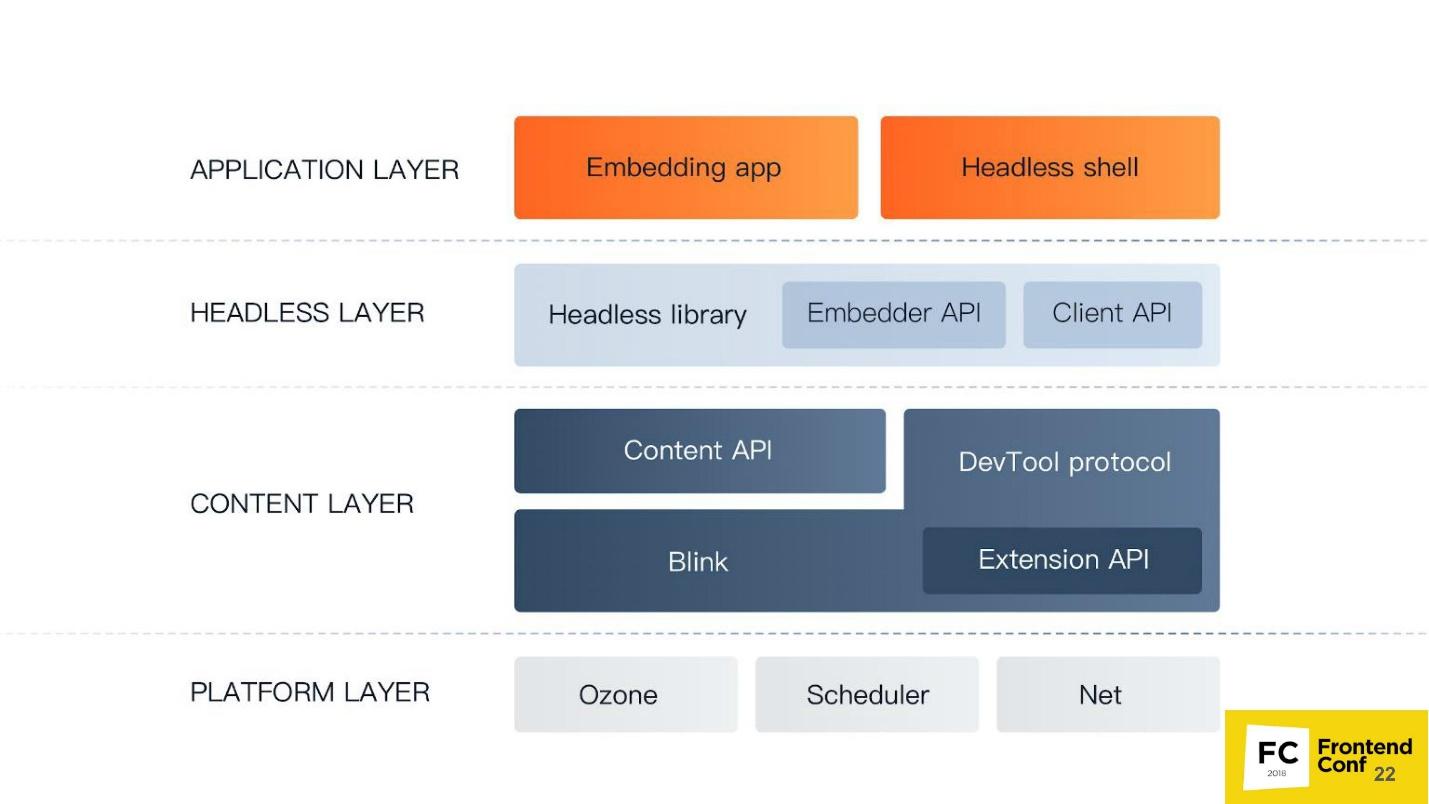
Опять слышу каверзный вопрос: «Зачем мне эта страшная схема? Я пишу под (вставьте название любимого фреймворка)».
Я считаю, что разработчик должен знать, как устроен его инструмент. Если вы пишите под React, вы должны знать, как работает React. Если вы пишите под Angular, вы должны знать, что у Angular под капотом.
Потому что в случае чего, допустим, фатальной ошибки или очень серьезного бага на продакшене, вам придется разбираться с «кишками», и вы просто можете потеряться там — где, что и как. Если вы, например, будете писать тесты или использовать Headless Chrome, вы тоже можете столкнуться с некоторыми его странностями поведения и багами. Поэтому я вам вкратце расскажу, какие у Chromium есть компоненты. Когда вы увидите большой stack trace, вы уже будете знать, в какую сторону копать и как вообще это можно поправить.
Самый низкий уровень Platform layer. Его компоненты:
- Ozone — абстрактный менеджер окон в Chrome — то, с чем взаимодействует оконный менеджер операционной системы. На Linux это либо X-server, либо Wayland. На Windows это менеджер окон Windows.
- Scheduler — тот самый планировщик, без которого мы никуда, потому что мы все знаем, что Chrome — это многопроцессное приложение, и нам нужно как-то разруливать все потоки, процессы и все остальное.
- Net — у браузера всегда должен быть компонент для работы с сетью, например, парсинг HTTP, создание заголовков, редактирование и т.д.
Уровень Content layer — самый большой компонент, который есть в Chrome. Он включает в себя:
- Blink — веб-движок на основе WebCore из WebKit. Он может взять HTML в виде строки, распарсить, выполнить JavaScript — и все. Больше он вообще ничего не умеет: ни работать с сетью, ни отрисовывать — все это происходит поверх Blink.
Blink в себя включает: сильно модифицированную версию WebCore — веб-движка для работы с HTML и CSS; V8 (JavaScript движок); а также API для всех расширений, которые мы используем в Chrome, например, блокировщик рекламы. Туда же входит DevTools protocol.
- Content API — это интерфейс, при помощи которого можно очень легко использовать все возможности веб-движка. Поскольку внутри Blink так много всего (наверное, больше миллиона интерфейсов), то, чтобы не потеряться во всех этих методах и функциях, нужен Content API. Вы вводите HTML, движок его автоматически обработает, разберет DOM, построит CSS OM, выполнит JavaScript, запустит таймеры, обработчики и все остальное.
Уровень Headless layer — уровень безголового браузера:
- Headless library.
- Embedder API интерфейс для встраивания Headless library в приложение.
- Client API — интерфейс, который использует Puppeteer.
Уровень приложения Application layer:
- Ваше приложение (Embedding app);
- Мини-приложения, например, Headless shell.
Теперь давайте поднимемся из глубин чуть выше, активизируемся — сейчас пойдет фронтенд.
Chrome DevTools protocol
Мы все сталкивались с Chrome DevTools protocol, поскольку пользуемся панелью разработчиков в Chrome или удаленным отладчиком — теми же самыми средствами разработки. Если вы запускаете средства разработчика в удаленном режиме, общение с браузером происходит при помощи именно DevTools protocol. Когда вы ставите debugger, смотрите code coverage, используете геолокацию или еще что-нибудь — все это управляется при помощи DevTools.
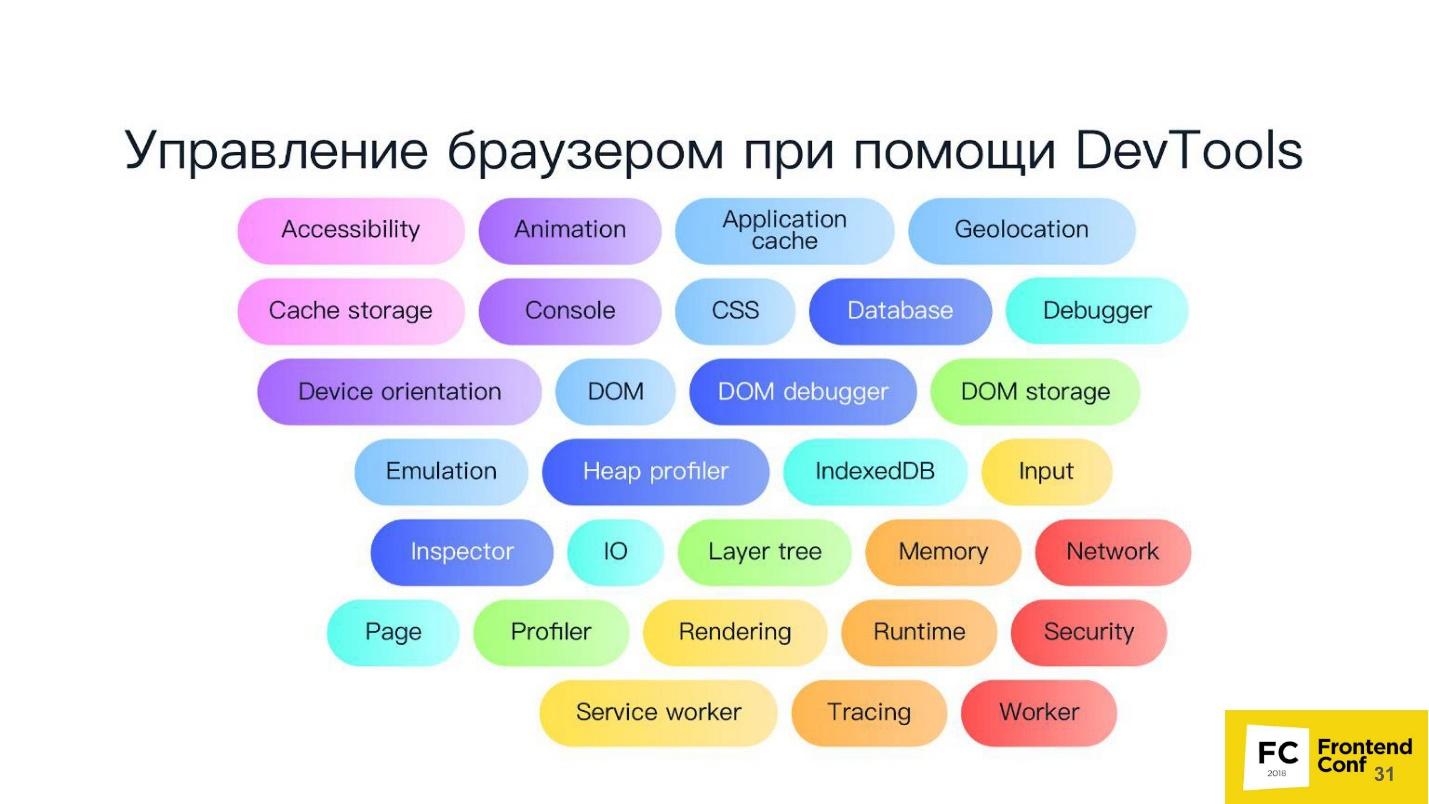
На самом деле сам DevTools protocol имеет огромное количество методов. Ваше средство разработчика не имеет доступа, наверное, к 80% из них. Реально там можно делать все!
Давайте разберем, что из себя представляет этот протокол. На самом деле он очень простой. В нем есть 2 компонента:
- DevTools target —вкладка, которую вы инспектируете;
- DevTools client — допустим, это панель разработчика, которая запущена в удаленном режиме.

Они общаются при помощи простого JSON:
- Есть идентификатор команды, название метода, который нужно выполнить, и некоторые параметры.
- Посылаем запрос и получаем ответ, который тоже выглядит очень просто: идентификатор, который нужен потому, что все команды, которые выполняются при помощи протокола, асинхронные. Для того, чтобы мы всегда могли сопоставить, какой ответ на какую команду нам пришел, нам и требуется идентификатор.
- Есть результат. В нашем случае он представляет собой объект result со следующими атрибутами: type: «number», value: 2, description: «2», исключение брошено не было: wasThrown: false.
Но помимо всего прочего ваша вкладка может слать события вам обратно. Допустим, когда произошло какое-то событие на странице, или было исключение на странице, вы получите уведомление через этот протокол.

Puppeteer
Установить Puppeteer можно при помощи любимого пакетного менеджера — будь то yarn, npm или любой другой.
Использовать его тоже легко — просто запрашиваете его в своем Node.js-скрипте, и уже, по сути, можете использовать.

По ссылке https://try-puppeteer.appspot.com вы можете прямо на сайте написать скрипт, выполнить его и получить результат прямо в браузере. Все это будет реализовано при помощи Headless Chrome.
Рассмотрим простейший скрипт под Node.js:
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch() ;
const page = await browser.newPage();
await page.goto('http://devconf.ru/') ;
await page.emulateMedia('screen') ;
await page.pdf({
path: './devconf.pdf,
printBackground: true
});
await browser.close() ;
})();
Здесь мы просто открываем страничку и печатаем ее в PDF. Посмотрим работу этого скрипта в режиме реального времени:
Все будет классно, но непонятно — что там внутри. Конечно, у нас же headless-браузер, мы же ничего не видим. Поэтому у Puppeteer есть специальный флаг, который называется headless: false:
const browser = await puppeteer.launch({
headless: false
});
Он нужен для запуска headless-браузера в режиме headful, когда вы сможете увидеть какое-то окно и посмотреть, что же происходит с вашей страницей в режиме реального времени, то есть как ваш скрипт взаимодействует с вашей страницей.
Так будет выглядеть тот же самый скрипт, когда мы добавим этот флаг. Слева появляется окно браузера — уже нагляднее.
Плюсы Puppeteer:
? + Это Node.js-библиотека для безголового Chrome.
? + Поддержка legacy-версий Node.js >= 6.
? + Легкая установка.
? + Высокоуровневый API для управления всей этой гигантской машиной.
Безголовый Chrome устанавливается легко и без вмешательства в систему. При первой установке Puppeteer скачивает версию Chromium и устанавливает ее прямо в папку node_modules именно под вашу архитектуру и ОС. Вам не нужно ничего скачивать дополнительно, он это делает автоматически. Вы также можете использовать и вашу любимую версию Chrome, которая установлена у вас в системе. Это тоже можно сделать — Puppeteer предоставляет вам такой API.
К сожалению, есть и минусы, если брать именно базовую инсталляцию.
Минусы Puppeteer:
? ? Нет top-level функций: синхронизации закладок и паролей; поддержки профилей; аппаратного ускорения и т.д.
? ? Программный рендеринг — наиболее весомый минус. Все вычисления и отрисовки происходят на вашем CPU. Но и тут инженеры Google нас скоро удивят — работы по реализации аппаратного ускорения уже ведутся. Уже сейчас можно попытаться его использовать, если вы смелы и отважны.
? ? До недавнего времени не было поддержки расширений — теперь ЕСТЬ! Если вы хитрый разработчик, можете взять ваш любимый AdBlock, указать, как Puppeteer’у его использовать, и вся реклама будет заблокирована.
? ? Нет поддержки аудио/видео. Потому что, ну зачем headless-браузеру аудио и видео.
Что может Puppeteer:
- Изоляция сессий.
- Виртуальные таймеры.
- Перехват сетевых запросов.
И еще пара клевых вещей, которые я покажу чуть дальше.
Изоляция сессий
Что это такое, с чем ее едят, и не подавимся ли мы? — Не подавимся!
Изоляция сессий — это отдельные «хранилища» для каждой вкладки. Когда вы запускаете Puppeteer, вы можете создать новую страницу, и у каждой новой страницы у вас может быть отдельное хранилище, в том числе:
- cookes;
- local storage;
- cache.
Все страницы будут жить независимо друг от друга. Это нужно, чтобы, например, поддерживать атомарность тестов.
Изоляция сессий позволяет сэкономить ресурсы и время при запуске параллельных сессий. Допустим, вы тестируете сайт, который собирается в development-режиме, то есть bundle не минимизированы, и весят 20 МБ. Если вы хотите просто его закэшировать, то можете указать Puppeteer использовать кэш общий для всех страниц, которые создаются, и этот bundle будет закэширован.
Можно сериализовать сессии для последующего использования. Вы пишите тест, который проверяет некое действие у вас на сайте. Но у вас есть проблема — сайт требует авторизацию. Вы же не будете в каждом тесте постоянно добавлять before для авторизации на сайте. Puppeteer позволяет залогиниться на сайте один раз, и потом переиспользовать эту сессию в дальнейшем.
Виртуальные таймеры
Возможно, вы уже используете виртуальные таймеры. Если вы двигали ползунок в средстве разработчика, который ускоряет или замедляет анимацию (и мыли после этого руки конечно же!), то в этот момент вы использовали виртуальные таймеры в браузере.
Браузер может использовать виртуальные таймеры вместо реальных, чтобы «прокрутить» время вперед для ускорения загрузки страницы или завершения анимации. Допустим, у вас тот же самый тест, вы заходите на главную страницу, а там анимация на 30 секунд. Никому не выгодно, чтобы тест ждал все это время. Поэтому вы можете просто ускорить анимацию, чтобы она была завершена мгновенно при загрузке страницы, и ваш тест продолжил работу.
Можно остановить время, пока выполняется сетевой запрос. Например, вы тестируете реакцию вашего приложения на то, когда запрос, ушедший на бэкенд, очень долго выполняется, либо возвращается с ошибкой. Вы можете остановить время — Puppeteer это позволяет.
На слайде ниже есть еще один вариант: остановить и продолжить работу отрисовщика (renderer). В экспериментальном режиме была возможность сказать браузеру не заниматься отрисовкой, а позже, если понадобится, запросить скриншот. Тогда бы безголовый Chrome все бы быстро отрисовал, выдал скриншот, и снова перестал бы отрисовывать что-либо. К сожалению, разработчики уже успели поменять принцип работы этого API и такой функции больше нет.
Схематичный вид виртуальных таймеров ниже.
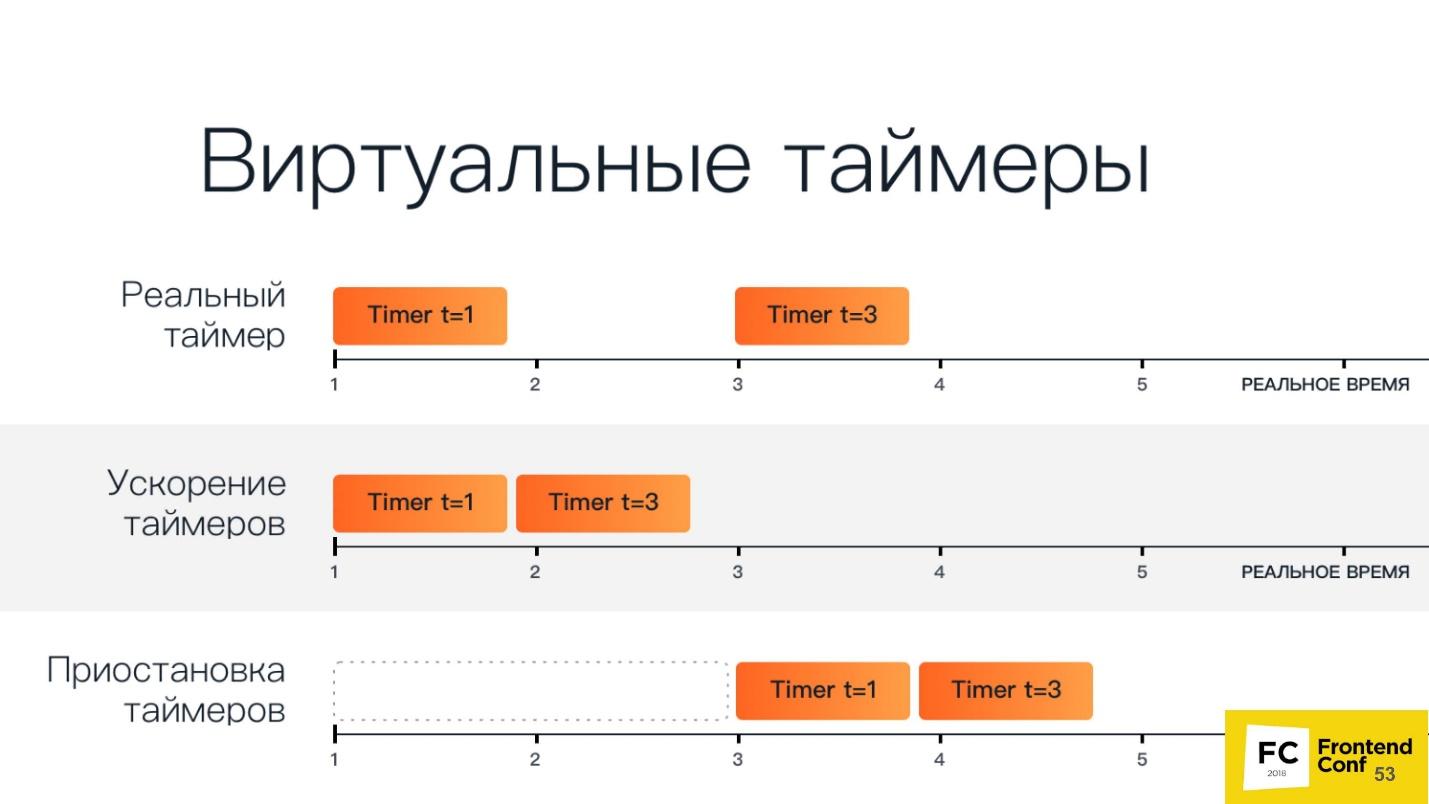
В верхней строке два обычных таймера: первый стартует в первую единицу времени и выполняется за одну единицу времени, второй стартует в третью единицу времени и выполняется за три единицы времени.
Ускорение таймеров — они запускаются друг за другом. Когда мы их приостанавливаем, у нас появляется промежуток времени, после которого все таймеры стартанут.
Рассмотрим это на примере. Ниже обрезанный кусок кода, который по сути просто загружает страницу с анимацией с codepen.io и ждет:
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
const url = ‘https ://codepen.o/ajerez/full/EaEEOW/'; // # 1
await page.goto(url, { waitUnitl: 'load' }); // # 2
})();
Это демонстрация выполнения в ходе доклада — просто анимация.
Теперь при помощи Chrome DevTools protocol отправим метод, который называется Animation.setPlaybackRate, передадим в качестве параметров ему playbackRate с значением 12:
const url = 'https://codepen.o/ajerez/full/EaEEOW/'; // # 1
await page._client.send('Animation.setPlaybackRate', { playbackRate: 12 }); // # 3
await page.goto(url, { waitUntil: 'load' }); // # 2
Загружаем ту же самую ссылку, и анимашка стала работать гораздо быстрее. Это происходит за счет того, что мы использовали виртуальный таймер и ускорили проигрывание анимации в 12 раз.
Давайте теперь проведем эксперимент — передадим playbackRate: 0 — и посмотрим, что же будет. А будет вот что: анимации вообще нет, она не проигрывается. Нулевое и отрицательные значения просто приостанавливают полностью всю анимацию.
Работа с сетевыми запросами
Вы можете перехватывать сетевые запросы путем установки следующего флага:
await page.setRequestlnterception(true);В таком режиме появляется дополнительное событие, которое срабатывает, когда отправляется или приходит какой-то сетевой запрос.
Вы можете менять запрос на лету. Это значит, что вы можете полностью менять все его содержимое (body) и его заголовки, инспектировать, даже отменять запрос.
Это нужно для того, чтобы обрабатывать авторизацию или аутентификацию, в том числе базовую аутентификацию по HTTP.
Еще вы можете сделать покрытие кода (JS/CSS). При помощи Puppeteer можно все это автоматизировать. Все мы знаем утилиты, которые могут загрузить страничку, показать, какие классы в ней используются и т.д. Но довольны ли мы ими? Думаю, нет.
Браузер знает лучше, какие селекторы и классы используются — он же браузер! Он всегда знает, какой JavaScript выполнился, какой нет, какой CSS используется, какой нет.
Опять на помощь приходит Chrome DevTools protocol:
await Promise.all ( [
page.coverage.startJSCoverage(),
page.coverage.startCSSCoverage()
]);
await page.goto(’https://example.com’);
const [jsCoverage, cssCoverage] = await Promise,all([
page.coverage.stopJSCoverage(), page.coverage.stopCSSCoverage()
]):
В первых двух строчках запускаем сравнительно новую фичу, которая позволяет узнать покрытие кода. Запускаем JS и CSS, переходим на какую-то страничку, потом говорим — стоп — и можем посмотреть результаты. Причем это не какие-то мнимые результаты, а те, которые видит браузер именно за счет движка.
Помимо всего прочего, уже есть плагин, который для Puppeteer это все экспортирует в istanbul.
На вершине пирамиды Puppeteer находится скрипт, который вы написали на Node.js — он как крестный отец всем нижним пунктам.
Но… «не всё спокойно в датском королевстве...» — как писал Уильям Шекспир.
Что не так с безголовыми браузерами?
У безголовых браузеров есть проблемы несмотря на то, что все их крутые фичи могут так много.
Отличие в рендеринге страницы на разных платформах
Я очень люблю этот пункт и постоянно про это рассказываю. Давайте посмотрим на эту картинку.

Здесь обычная страничка с обычным текстом: справа — отрисовка в Chrome на Linux, слева — под Windows. Те, кто тестирует скриншотами, знают, что всегда устанавливается значение, называемое «порогом погрешности», которое определяет, когда скриншот считается идентичным, а когда нет.
На самом деле проблема в том, что как бы вы не старались установить этот порог, погрешность всегда будет выходить за эту грань, и вы все равно будете получать ложно позитивные результаты. Это связано с тем, что все страницы, и даже веб-шрифты рендерятся по-разному на всех трех платформах — на Windows по одному алгоритму, на MacOS по-другому, в Linux вообще зоопарк. Вы не можете просто взять и тестировать скриншотами.
Вы скажете: «Мне просто нужна эталонная машина, где я буду запускать все эти тесты и сравнивать скриншоты». Но на самом деле это дико неудобно, потому что вам придется ждать CI, а вы хотите здесь и сейчас локально на машине у себя проверить, не сломали ли вы что-нибудь. Если у вас эталонные скриншоты делаются на Linux-машине, а у вас Mac, то будут ложные результаты.
Поэтому я и говорю, что не тестируйте скриншотами вообще — забудьте это.
Кстати, если вы все-таки хотите тестировать скриншотами, есть замечательная статья Романа Дворнова "Unit-тестирование скриншотами: преодолеваем звуковой барьер". Это прямо детективное чтиво.
Блокировки
Многие крупные контент-провайдеры не любят, когда вы делаете scraping или получаете их контент нелегальным способом. Представим, что я крупный контент-провайдер, и хочу сыграть с вами в одну игру. Есть два GET-запроса в двух разных браузерах.
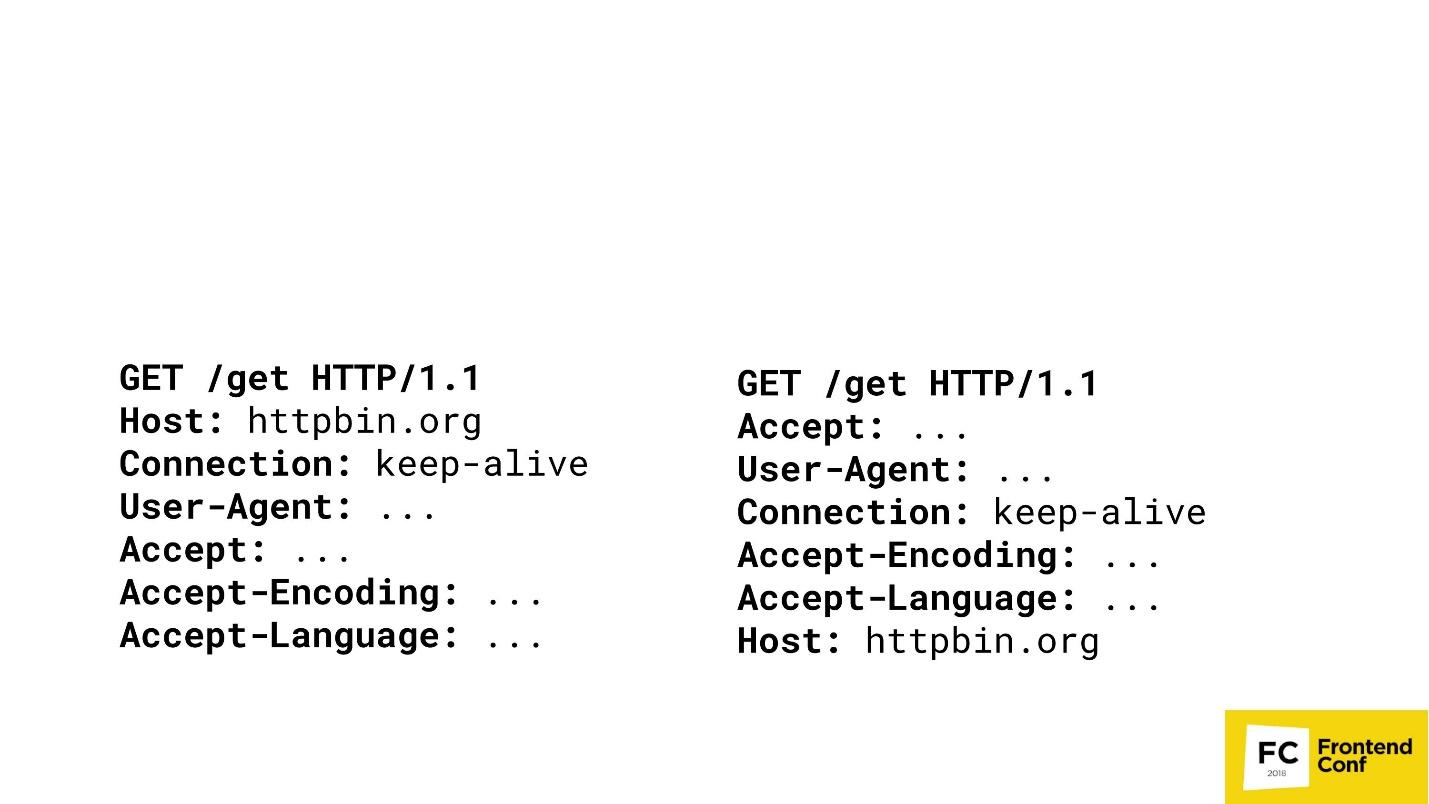
Сможете ли вы угадать, где здесь Chrome? Вариант «оба» не принимается — Chrome тут только один. Скорее всего, вы не сможете ответить на этот вопрос, а я, как крупный контент-провайдер, могу: справа — PhantomJS, а слева — Chrome.

Я могу дойти до такой степени, что буду обнаруживать ваши браузеры (что это именно — Chrome или FireFox) путем сопоставления порядка HTTP заголовков в ваших запросах. Если хост идет первым — я четко знаю — это Chrome. Дальше могу не сравнивать. Да, конечно, есть более сложные алгоритмы — мы проверяем не только порядок, но еще и значения, и т.д. и т.п. Но важен факт, что я могу слепками сравнивать ваши заголовки, проверять, кто вы есть, а потом просто блокировать вас или не блокировать.
Невозможно реализовать некоторые функции (Flash)
Вы когда-нибудь изучали углубленно, прямо хардкорно, Flash в браузерах? Как-то я заглянул — потом полгода не спал.
Все мы помним, как мы раньше смотрели YouTube, когда еще был Flash: ролик крутится, все хорошо. Но в тот момент, когда создается встраиваемый объект на странице типа Flash, он всегда запрашивает реальное окно у вашей ОС. То есть помимо окна вашего браузера, внутри YouTube-окошка Flash было еще одно окно вашей ОС. Flash не может работать, если вы не дадите ему реальное окно — причем не просто реальное окно, а окно, которое видно у вас на экране. Поэтому некоторые функции в безголовых браузерах реализовать невозможно, в том числе, Flash.
Полная автоматизация и боты
Как я уже сказал ранее, крупные контент-провайдеры очень боятся, когда вы пишите пауков или граббинги, которые просто крадут информацию, которая предоставляется платно.
В ход идут разные ухищрения. Есть статьи о том, как все-таки обнаруживать headless-браузеры. Могу сказать, что вы никак не сможете обнаружить headless-браузеры. Все методы, которые там описаны, обходятся. Например, там были способы обнаружения при помощи Canvas. Помню, даже был один скрипт, который смотрел, как движется мышка по экрану, и заполнял Canvas. Мы же люди и двигаем мышку довольно медленно, а Headless Chrome гораздо шустрее. Скрипт понимал, что слишком быстро заполняется Canvas — значит, это, скорее всего, безголовый Chrome. Мы это тоже обошли, просто замедлив браузер — не проблема.
Нет стандартного (единого) API
Если вы смотрели headless-реализации в других браузерах — будь это Safari или FireFox — там это все реализовано при помощи webdriver API. В Chrome есть Chrome DevTools protocol. В Edge вообще ничего не понятно — что там есть, чего нет.
WebGL?
Люди тоже просят WebGL в headless-режиме. По этой ссылке вы можете попасть на багтрекер Google Chrome. Там разработчики активно голосуют за реализацию headless-режима для WebGL, и уже он может что-то рисовать. Их сейчас просто сдерживает аппаратный рендеринг. Как только закончат реализацию аппаратного рендеринга, то и WebGL автоматически будет доступен, то есть что-то можно будет делать в фоне.
Но не все так плохо!
У нас появляется второй игрок на рынке — 11 мая 2018 была новость, что Microsoft в своем браузере Edge решил реализовать почти тот же самый протокол, который используется в Google Chrome. Они специально создали консорциум, где обсуждают протокол, который хотят довести до промышленного стандарта, чтобы вы могли взять свой скрипт и запустить его и под Edge, и под Chrome, и под FireFox.
Но есть одно «но» — у Microsoft Edge нет headless-режима, к сожалению. У них есть голосовалка, где люди пишут: «Дайте нам headless-режим!» — но они молчат. Наверное, что-то пилят втайне.
TODO (заключение)
Я рассказал это все для того, чтобы вы могли прийти к вашему менеджеру, или, если вы менеджер, к разработчику, и сказать: «Все! Мы не хотим больше Selenium — давайте нам Puppeteer! Будем в нем тестировать». Если это случится, я буду рад.
Но если вы сможете изучать, как и я, браузеры, используя Puppeteer, активно постить баги, или отправлять pull request, то я буду рад еще больше. Этот инструмент в OpenSource лежит на GitHub, написан на Node.js — вы можете просто в него брать и контрибьютить.
Случай с Puppeteer уникален тем, что в Google работает две команды: одна занимается именно Puppeteer, вторая — именно headless-режимом. Если пользователь находит баг, пишет о нем наа GitHub, то, если этот баг не в Puppeteer, а в Headless Chrome, баг переходит в команду Headless Chrome. Если они его там фиксят, то Puppeteer очень быстро обновляется. За счет этого получается единая экосистема, когда сообщество помогает улучшать браузер.
Поэтому я призываю вас помогать улучшать инструмент, который используете не только вы, но и другие разработчики и тестировщики.
Контакты:
- github.com/vitallium
- vk.com/vitallium
- twitter.com/vitalliumm
Frontend Conf Moscow — специализированная конференция фронтенд-разработчиков состоится 4 и 5 октября в Москве, в Инфопространстве. Список принятых докладов уже опубликован на сайте конференции.
В нашей рассылке мы регулярно делаем тематические обзоры выступлений, рассказываем о вышедших расшифровках и будущих мероприятиях — подписывайтесь, чтобы получать новости первым.
А это ссылка на наш Youtube-канал по фронтенду, там собраны все выступления, относящиеся к разработке клиентской части проектов.
Комментарии (11)

hdfan2
05.09.2018 20:17У него нет реальной отрисовки содержимого, то есть он все отрисовывает в памяти.
За счет этого он потребляет меньше памяти, потому что не нужно отрисовывать картинки или гигабайтные PNG
Я не понял — так он отрисовывает в память или нет? Если да, то к чему тут пассаж про PNG?skoder
05.09.2018 22:01Как я понимаю: он полностью размечает весь макет в памяти, размеры, шрифты. Все есть, все можно измерить. Но саму отрисовку всего этого он не делает, пока не запросишь метод скриншота
petuhov_k
06.09.2018 05:39И это утверждение тоже, мягко говоря, спорное:
Он работает быстрее, потому что ему ничего не нужно отрисовывать на реальном экране.
Отрисовка — копейки по сравнению с измерением текста и лэйаутом.
Sadler
06.09.2018 10:24+1Использую headless-режим через Selenium Python, переходить на Puppeteer не готов, т.к. не готов писать на языке, в котором количество async/await на строку > 0.5
bro-dev0
06.09.2018 17:33Можете колбэк хэлом писать по старинке, если я верно понял в питоне он и используется за неимением await.
qwez
06.09.2018 10:46Мы не хотим больше Selenium — давайте нам Puppeteer!
Вот сделали бы сравнение — чем Puppeteer, по-вашему, лучше.
Хотя, какие бы плюсы не нашлись, они вряд-ли перекроют эти два от Selenium: поддержка более одного браузера и громадное количество оберток для всех популярных ЯП.bro-dev0
06.09.2018 17:34Для меня плюс это стабильная поддержка проксей. Во всех других виртуальных браузерах для ноды или ни работают вообще, или только какой то один тип.
faiwer
06.09.2018 11:00Вопрос к тем, кто активно использует Puppeteer: насколько сложно\тривиально с ним организовать тест для drag-n-drop? Можно написать что-нибудь вроде:
mouse .mouseDown(...getNodeCoordinates(domNode)) .mouseMove(deltaX, deltaY) .mouseUp()
Ну и прочие хитрые штуки, вроде нативного drag-n-drop из ОС (типа перетаскивания файлов на панель). Есть ли поддержка zoom-а страницы? Удобно и вообще возможно работать с window.confirm, window.alert?
Iqorek
06.09.2018 16:44+1насколько сложно\тривиально с ним организовать тест для drag-n-drop?
// Do drag-and-drop mouse.down(..); mouse.move(..); mouse.up(..);
©
Ну и прочие хитрые штуки, вроде нативного drag-n-drop из ОС (типа перетаскивания файлов на панель).
Вряд ли, все что там есть, это то что можно делать в хромиум.
Есть ли поддержка zoom-а страницы?
Можно задать deviceScaleFactor через page.setViewport(viewport)
Удобно и вообще возможно работать с window.confirm, window.alert?
Возможно
x512