
Небольшой рассказ о преимуществах и недостатках микросервисов, концепции Service Mesh и инструментах Google, позволяющих запускать микросервисные приложения не засоряя голову бесконечными настройками политик, доступов и сертификатов и быстро находить ошибки, прячущиеся не в коде, а в микросервисной логике.

В основе статьи — доклад Крейга Бокса на нашей прошлогодней конференции DevOops 2017. Видео и перевод доклада — под катом.
Крейг Бокс (Craig Box, Твиттер) — DevRel из Google, отвечающий за направление микросервисов и инструменты Kubernetes и Istio. Его нынешний рассказ — про управление микросервисами на этих платформах.
Начнем с относительно новой концепции под названием Service Mesh. Этот термин используется для описания сети взаимодействующих между собой микросервисов, из которых состоит приложение.

На высоком уровне мы рассматриваем сеть как трубу, которая просто перемещает биты. Мы не хотим беспокоиться о них или, например, о MAC-адресах в приложениях, но стремимся думать о сервисах и связях, которые им необходимы. Если посмотреть с точки зрения OSI, то у нас есть сеть третьего уровня (с функциями определения маршрута и логической адресации), но мы-то хотим думать в терминах седьмого (с функцией доступа к сетевым службам).
Как должна выглядеть настоящая сеть седьмого уровня? Возможно, мы хотим видеть что-то вроде трассировки трафика вокруг проблемных сервисов. Чтобы можно было подключиться к сервису, и при этом уровень модели был поднят вверх с третьего уровня. Мы хотим получать представление о том, что происходит в кластере, находить непредусмотренные зависимости, выяснять корневые причины возникновения сбоев. Также нам необходимо избегать лишних накладных расходов, например, соединения с высокой задержкой или подключение к серверам с холодным или не до конца прогретым кешем.
Мы должны быть уверены, что трафик между службами защищен от тривиальных атак. Необходима взаимная TLS-аутентификация, но без встраивания соответствующих модулей в каждое приложение, которое мы пишем. Важно иметь возможность управления тем, что окружает наши приложения не только на уровне соединения, но и на более высоком уровне.
Service Mesh — это слой, который позволяет нам решать вышеуказанные проблемы в среде микрообслуживания.
Но сначала спросим себя, почему мы вообще должны решать эти проблемы? Как раньше мы занимались разработкой ПО? У нас было приложение, которое выглядит примерно вот так — как монолит.

Ведь здорово: весь код у нас на как ладони. Почему бы и дальше не использовать этот подход?
Да потому что у монолита есть свои проблемы. Главная трудность в том, что если мы захотим пересобрать это приложение, то должны повторно развернуть каждый модуль, даже если ничего не изменилось. Мы вынуждены создавать приложение на одном и том же языке или на совместимых языках, даже если над ним работают разные команды. Фактически отдельные части не могут быть протестированы независимо друг от друга. Пора это менять, пришло время микросервисов.

Итак, мы разделили монолит на части. Вы можете заметить, что в этом примере мы удалили некоторые из ненужных зависимостей и перестали использовать внутренние методы, вызываемые из других модулей. Мы создали сервисы из моделей, которые использовались ранее, создавая абстракции в тех случаях, когда нам нужно сохранять состояние. Например, каждый сервис должен иметь независимое состояние, чтобы при обращении к нему вы не беспокоились о том, что происходит в остальной части нашей среды.
Что получилось в итоге?

Мы ушли из мира гигантских приложений, получив то, что действительно отлично выглядит. Мы ускорили разработку, прекратили использовать внутренние методы, создали сервисы и теперь можем масштабировать их независимо, сделать сервис больше без необходимости укрупнять все остальное. Но какова цена изменений, что мы при этом потеряли?

У нас были надежные вызовы внутри приложений, потому что вы просто вызывали функцию или модуль. Мы заменили надежный вызов внутри модуля ненадежным удаленным вызовом процедуры. А ведь не всегда сервис на другой стороне доступен.
Мы были в безопасности, использовался один и тот же процесс внутри одной машины. Теперь мы подключаемся к сервисам, которые могут быть на разных машинах и в ненадежной сети.
В новом подходе в сети возможно присутствие других пользователей, которые пытаются подключиться к службам. Увеличились задержки, и одновременно сократились возможности их измерения. Теперь у нас есть пошаговые соединения во всех службах, которые создают один вызов модуля, и мы больше не можем просто посмотреть приложение в отладчике и узнать, что именно вызвало сбой. И эту проблему надо как-то решить. Очевидно, что нам необходим новый набор инструментов.

Есть несколько вариантов. Мы можем взять наше приложение и сказать, что если RPC не работает с первого раза, то следует попробовать еще раз, а затем еще и еще. Немного подождать и снова попробовать или добавить Jitter. Также мы можем добавить entry — exit traces чтобы сказать, что произошел запуск и завершение вызова, что для меня приравнивается к отладке. Можно добавить инфраструктуру для обеспечения проверки подлинности соединений и научить все наши приложения работать с TLS-шифрованием. Нам придется взять на себя бремя содержания отдельных команд и постоянно держать в голове различные проблемы, которые могут возникнуть в SSL-библиотеках.
Поддержание согласованности на различных платформах — это неблагодарная задача. Хотелось бы, чтобы пространство между приложениями стало разумным, чтобы появилась возможность отслеживания. Также нам нужна возможность изменения конфигурации во время выполнения, чтобы не перекомпилировать или не перезапускать приложения для перенастройки. Вот эти хотелки и реализует Service Mesh.
Поговорим о Istio.

Istio — это полноценный framework для подключения, управления и мониторинга микросервисной архитектуры. Istio создан для работы поверх Kubernetes. Сам он не развертывает программное обеспечение и не заботится о том, чтобы сделать его доступным на машинах, которые мы используем для этой цели с контейнерами в Kubernetes.

На рисунке мы видим три разных среза машин и блоки, которые составляют наши микросервисы. У нас есть способ сгруппировать их вместе с помощью механизмов, предоставляемых Kubernetes. Мы можем настроить таргетинг и сказать, что конкретная группа, которая может иметь автоматическое масштабирование, прикреплена к веб-сервису или может иметь другие методы развертывания, будет содержать наш веб-сервис. При этом нам не нужно думать о машинах, мы оперируем терминами уровня доступа к сетевым службам.

Данная ситуация может быть представлена в виде схемы. Рассмотрим пример, когда у нас есть механизм, который делает некоторую обработку изображений. Слева изображен пользователь, трафик от которого поступает к нам в микросервис.
Чтобы принимать оплату от пользователя, у нас есть отдельный платежный микросервис, вызывающий внешний API, который находится за пределами кластера.
Для обработки входа пользователей в систему у нас предусмотрен микросервис аутентификации, и у него есть состояния, сохраненные опять-таки за пределами нашего кластера в базе данных Cloud SQL.
Что делает Istio? Istio улучшает Kubernetes. Вы устанавливаете его с помощью альфа-функции в Kubernetes под названием Инициализатор. При развертывании программного обеспечения kubernetes заметит его и спросит, хотим ли мы изменить и добавить еще один контейнер внутри каждого kubernetes. Этот контейнер будет обрабатывать пути и маршрутизации, знать обо всех изменениях приложения.
Вот так схема выглядит с Istio.
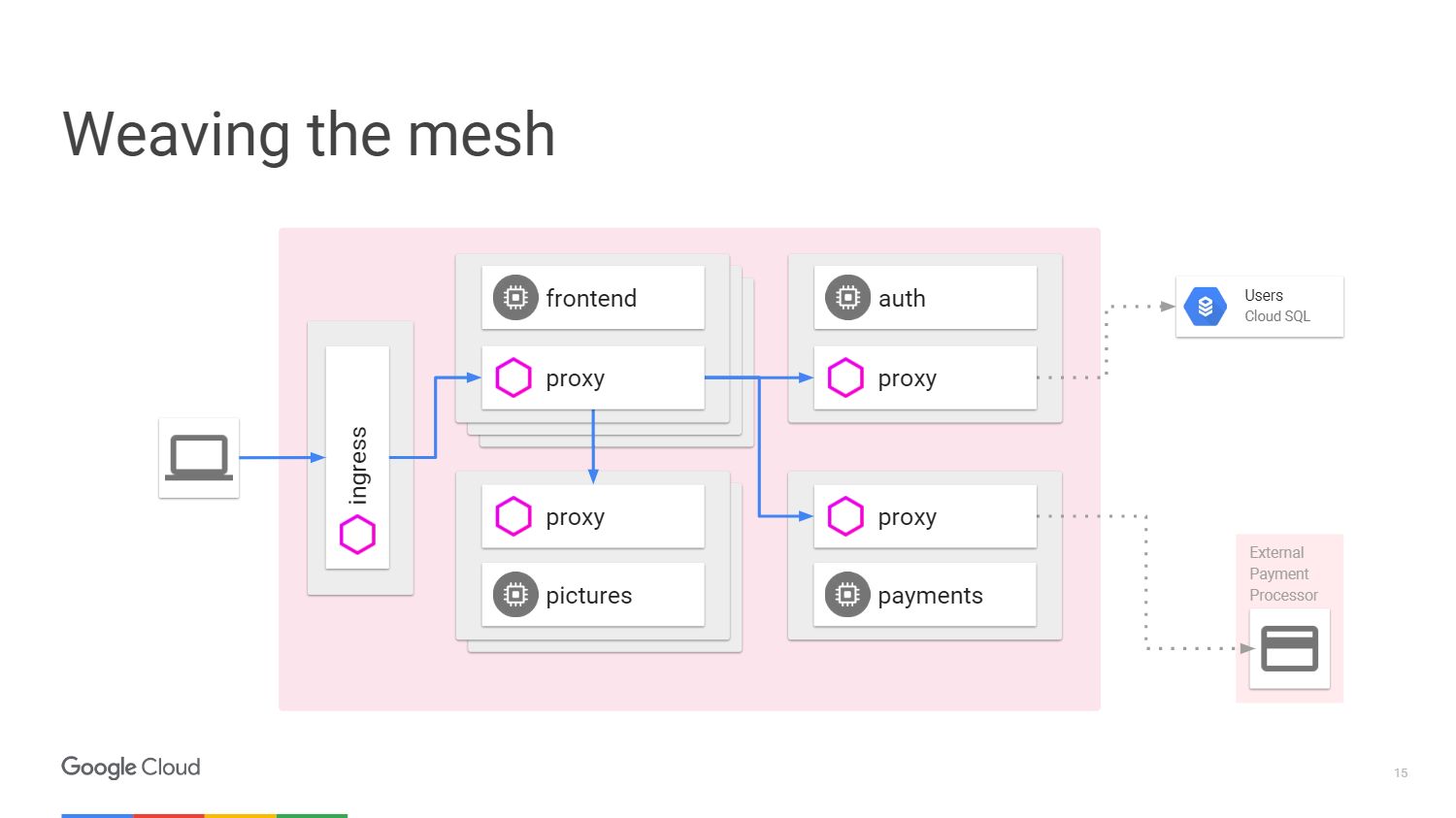
У нас есть внешние машины, которые обеспечивают входящий и исходящий прокси для трафика в конкретном сервисе. Мы можем разгрузить функции, о которых уже говорили. Нам не нужно учить приложение, как выполнять телеметрию или трассировку с помощью TLS. Зато можем добавить внутрь другие вещи: автоматическое прерывание, ограничение скорости, canary release.
Весь трафик теперь будет проходить через прокси-серверы на внешних машинах, а не напрямую к сервисам. Kubernetes делает все на том же IP-адресе. Мы сможем перехватить трафик, который пошел бы на front или end сервисы.
Внешний прокси, который использует Istio, называется Envoy.

Envoy на самом деле старше Istio, он был разработан в LYFT. Работает в продакшн более года, запуская всю инфраструктуру микросервисов. Мы выбрали Envoy для проекта Istio в сотрудничестве с сообществом. Таким образом, Google, IBM и LYFT — это три компании, которые до сих пор над ним работают.
Envoy написан на C++ версии 11. Был в продакшн более 18 месяцев, прежде чем стать проектом с открытым исходным кодом. Он не займет много ресурсов, когда вы подключите его к вашим сервисам.
Вот несколько вещей, которые умеет Envoy. Это создание прокси-сервера для HTTP, включая HTTP/2 и протоколов, основанных на нем, таких как gRPC. Он также может выполнять переадресацию другим протоколам на двоичном уровне. Envoy контролирует вашу зону инфраструктуры, так что вы можете сделать свою часть автономной. Он может обрабатывать большое количество сетевых соединений с повторами запросов и ожиданием. Вы можете установить определенное количество попыток подключения к серверу, прежде чем прекратить обращение и передать своим серверам информацию о том, что сервис не отвечает.
Не нужно беспокоиться о перезагрузке приложения, чтобы добавить в него конфигурацию. Вы просто подключаетесь к нему с помощью API, очень похожим на kubernetes, и меняете конфигурацию во время выполнения.
Команда Istio внесла большой вклад в платформу UpStream Envoy Platform. Например, оповещение об ошибке injection. Мы сделали так, чтобы можно было видеть, как приложение ведет себя в случае превышения количества запросов на объект, завершившихся неудачей. А также реализовали функции графического отображения и разделения трафика, чтобы обрабатывать случаи, когда используется canary-развертывание.
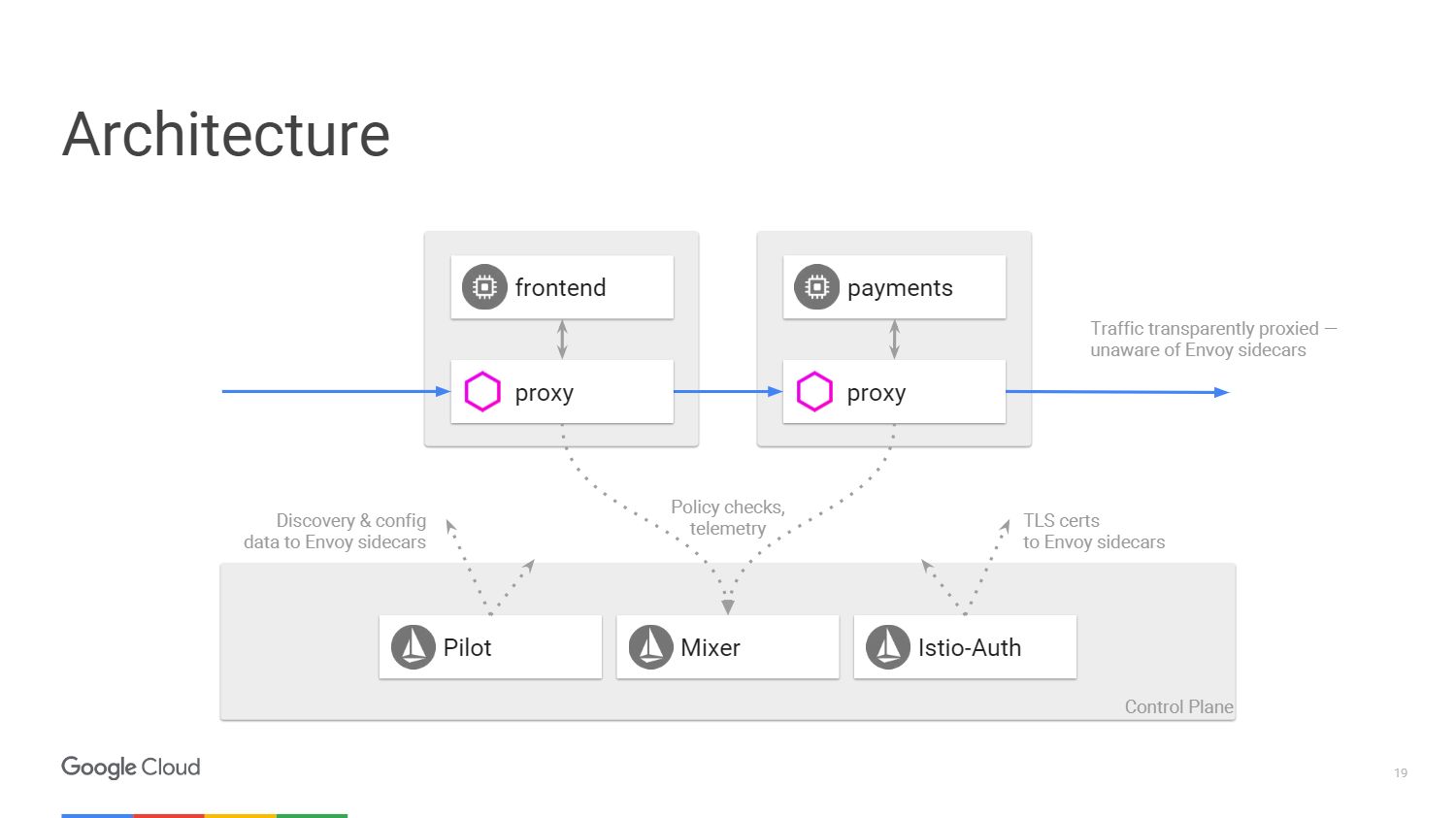
На рисунке показано, как выглядит архитектура системы Istio. Мы возьмем лишь два микросервиса, которые упоминали ранее. В конечном счете, на схеме все очень похоже на программно-определяемую сеть. Со стороны прокси-сервера Envoy, который мы развернули вместе с приложениями, происходит перенос трафика с помощью IP-таблиц в пространстве имен. Контрольная панель отвечает за управление консолью, но она не обрабатывает трафик сама.
У нас есть три компонента. Pilot, который создает конфигурацию, смотрит на правила, которые можно изменить с помощью API для контрольной панели Istio, и затем обновляет Envoy так, чтобы он вел себя как сервис обнаружения кластера. Istio-Auth служит центром сертификации и передает TLS сертификаты на прокси-серверы. Приложению не требуется наличие SSL, они могут соединяться по HTTP, и прокси будут обрабатывать все это за вас.
Mixer обрабатывает запросы, чтобы убедиться, что вы соответствуете политике безопасности, а затем передает телеметрическую информацию. Не внося никаких изменений в приложение, мы можем увидеть все, что происходит внутри нашего кластера.
Итак, давайте поговорим подробнее о пяти вещах, которые мы получим от Istio. В первую очередь рассмотрим управление трафиком. Мы можем отделить контроль трафика от масштабирования инфраструктуры, поэтому ранее мы могли бы сделать что-то вроде 20 экземпляров приложения и 19 из них будет на старой версии, а один на новой, то есть 5% трафика будет приходиться на новую версию. С Istio мы можем развернуть любое количество экземпляров, которое нам нужно, и при этом указать, какой процент трафика нужно отправить на новые версии. Простое правило разделения.
Все может быть запрограммировано «на лету» с помощью правил. Envoy будет периодически обновляться по мере изменения конфигурации, и это не приведет к сбоям в обслуживании. Так как мы работаем на уровне доступа к сетевым службам, то можем просмотреть пакеты, и в этом случае есть возможность залезть в пользовательский агент, который находится на третьем уровне сети.
Например, мы можем сказать, что любой траффик с iPhone подчиняется другому правилу, и мы собираемся направить определенную долю трафика на новую версию, которую хотим протестировать для определенного устройства. Внутренний вызывающий микросервис может определить, к какой конкретной версии ему нужно подключиться, а вы можете перевести его на другую версию, например, 2.0.
Второе преимущество — это прозрачность. Когда у вас есть представление внутри кластера, вы можете понять как оно сделано. Нам не нужно в процессе разработки создавать инструментарий для метрик. Метрики уже есть в каждом компоненте.
Некоторые считают, что для мониторинга вполне достаточно вести запись логов. Но по факту все, что нам нужно — это иметь такой универсальный набор показателей, который можно скормить любой службе мониторинга.

Так выглядит панель инструментов Istio, созданная с помощью сервиса Prometheus. Не забудьте его развернуть внутри кластера.
В примере на скриншоте показан ряд отслеживаемых параметров, характерных для всего кластера. Можно вывести и более интересные вещи, например, какой процент приложений дает более 500 ошибок, что подразумевает отказ. Время ответа агрегируется во всех вызывающих и отвечающих экземплярах сервисов внутри кластера, этот функционал не требует настроек. Istio знает, что поддерживает Prometheus, а тот в курсе, какие службы доступны в вашем кластере, поэтому Istio-Mixer может отправлять метрики в Prometheus без дополнительных настроек.
Давайте посмотрим, как это работает. Если вы вызываете конкретную службу, прокси сервис отправляет информацию об этом вызове в Mixer, который фиксирует такие параметры, как ожидание времени ответа, статус кода и IP. Он нормализует их и отправляет на любые серверы, которые вы сконфигурировали. Специально для вывода основных показателей есть сервис Prometheus и адаптеры FLUX DB, но вы также можете написать собственный адаптер и вывести данные в любом формате для любого другого приложения. И вам не придется ничего менять в инфраструктуре, если захотите добавить новую метрику.

Если вы хотите провести более глубокое исследование, то воспользуйтесь системой распределенной трассировки Zipkin. Информация обо всех вызовах, которые маршрутизируются через Istio-Mixer, может быть отправлена в Zipkin. Там вы увидите всю цепочку вызовов микросервисов при ответе пользователю и легко обнаружите службу, которая затягивает время обработки.

На уровне приложений беспокоиться о создании трассировки практически не нужно. Envoy сам передает всю необходимую информацию в Mixer, который отправляет ее в трассировку, например, в Zipkin, stackdriver trace от Google или любое другое пользовательское приложение.
Давайте поговорим об отказоустойчивости и эффективности.

Тайм-ауты между вызовами сервисов нужны для проверки работоспособности, в первую очередь, балансировщиков нагрузки. Введем ошибки в эту связь и посмотрим, что произойдет. Рассмотрим пример. Допустим, существует связь между сервисом A и сервисом B. Мы ждем ответ от сервиса видео 100 миллисекунд и даем всего 3 попытки, если результат не получен. По сути мы собираемся занять его на 300 миллисекунд, прежде чем он сообщит о неудачной попытке соединения.

Далее, например, наш сервис кино должен посмотреть рейтинг фильма через другой микросервис. У рейтинга таймаут составляет 200 миллисекунд и дается две попытки вызова. Вызов службы видео может привести к тому, что вы будете ждать 400 миллисекунд в случае, если рейтинг звездности вне доступа. Но, мы помним, по истечении 300 мс сервис кино сообщит, что он нерабочий, и мы никогда не узнаем реальную причину сбоя. Использование тайм-аутов и тестирование того, что происходит в этих случаях — отличный способ найти в вашей архитектуре микросервисов всякие хитроумные баги.
Посмотрим теперь, что с эффективностью. Сам балансировщик kubernetes действует всего лишь на уровне четвертого слоя. Мы изобрели конструктор входных данных для балансировки нагрузки со второго слоя по седьмой. Istio реализован в качестве балансировщика для уровня сети с доступом к сетевым службам.
Мы выполняем TLS-offloading, поэтому используем в Envoy современный хорошо допиленный SSL, с которым можно не волноваться о уязвимостях.
Еще одно преимущество Istio — безопасность.

Какие базовые средства безопасности есть в Istio? Сервис Istio-Auth работает в нескольких направлениях. Используется общедоступный фреймворк и набор стандартов идентификации для сервисов SPIFFE. Если мы говорим о потоке трафика, то у нас есть центр сертификации Istio, который выдает сертификаты для учетных записей служб, которые мы запускаем внутри кластера. Эти сертификаты соответствуют стандарту SPIFFE и распространяются Envoy, используя механизм защиты kubernetes. Envoy использует ключи для двусторонней аутентификации TLS. Таким образом, приложения бэкенда получают идентификаторы, на основе которых уже можно организовать политику.
Istio самостоятельно обслуживает корневые сертификаты, чтобы вы не волновались об аннулировании и истекающих сроках. Система будет реагировать на автоматическое масштабирование, поэтому вводя новую сущность, вы получаете новый сертификат. Никаких ручных настроек. Вам не надо настраивать firewall. Пользователи будут использовать сетевую политику и kubernetes, чтобы реализовать брандмауэры между контейнерами.
Наконец, применение политик. Mixer является точкой интеграции с инфраструктурными бэкэндами, которые вы можете расширить с помощью Service Mesh. Cервисы могут легко перемещаться внутри кластера, быть развернуты в нескольких средах, в облаке или локально. Все сконструировано для оперативного контроля вызовов, которые идут через Envoy. Мы можем разрешать и запрещать конкретные вызовы, ставить предварительные условия для пропуска вызовов, ограничивать их скорость и количество. Например, вы разрешаете к какой-то своей службе 20 бесплатных запросов в день. Если пользователь сделал 20 запросов, последующие не обрабатываются.
Предварительные условия могут включать в себя такие вещи, как, например, прохождение сервером проверки подлинности, ICL и его присутствие в белом списке. Управление квотами может использоваться в тех случаях, когда требуется, чтобы все, кто использует сервис, имели одинаковую скорость доступа. Наконец, Mixer собирает результаты обработки запросов и ответов, годные для телеметрии. Это позволяет производителям и пользователям смотреть на эту телеметрию с помощью сервисов.
Помните первый слайд с фотоприложением, с которого мы начали изучать Istio? Все вышеперечисленное скрыто под такой простой формой. На верхнем уровне все необходимое будет выполняться автоматически. Вы развернете приложение и не будете беспокоиться о том, как определить политику безопасности или настроить некоторые правила маршрутизации. Приложение будет работать именно так, как вы того ожидаете.
Istio поддерживает предыдущие версии kubernetes, но новая функция инициализатора, о которой я рассказывал, находится в версиях 1.7 и выше. Это альфа-функция в kubernetes. Я рекомендую использовать Google Container Engine Alpha clusters. У нас есть кластеры, которые вы можете включить на определенное количество дней и при этом использовать все продакшн возможности в них.
Прежде всего Istio — это проект с открытым исходным кодом на github. Мы только что выпустили версию 0.2. В версии 0.1 можно было управлять объектами в пределах одноименного пространства имен kubernetes. С версии 0.2 мы поддерживаем работу в собственном пространстве имен и кластере kubernetes. Еще мы добавили доступ для возможности управления сервисами, которые запускаются на виртуальных машинах. Вы можете развернуть Envoy на виртуальной машине и обезопасить сервисы, которые работают на ней. В дальнейшем Istio будет поддерживать другие платформы, такие как Cloud Foundry.
Краткое руководство по установке фреймворка находится здесь. Если у вас есть кластер под управлением Google Container Engine на 1.8 с включенными альфа-функциями, то установка Istio — это всего лишь одна команда.
В основе статьи — доклад Крейга Бокса на нашей прошлогодней конференции DevOops 2017. Видео и перевод доклада — под катом.
Крейг Бокс (Craig Box, Твиттер) — DevRel из Google, отвечающий за направление микросервисов и инструменты Kubernetes и Istio. Его нынешний рассказ — про управление микросервисами на этих платформах.
Начнем с относительно новой концепции под названием Service Mesh. Этот термин используется для описания сети взаимодействующих между собой микросервисов, из которых состоит приложение.
На высоком уровне мы рассматриваем сеть как трубу, которая просто перемещает биты. Мы не хотим беспокоиться о них или, например, о MAC-адресах в приложениях, но стремимся думать о сервисах и связях, которые им необходимы. Если посмотреть с точки зрения OSI, то у нас есть сеть третьего уровня (с функциями определения маршрута и логической адресации), но мы-то хотим думать в терминах седьмого (с функцией доступа к сетевым службам).
Как должна выглядеть настоящая сеть седьмого уровня? Возможно, мы хотим видеть что-то вроде трассировки трафика вокруг проблемных сервисов. Чтобы можно было подключиться к сервису, и при этом уровень модели был поднят вверх с третьего уровня. Мы хотим получать представление о том, что происходит в кластере, находить непредусмотренные зависимости, выяснять корневые причины возникновения сбоев. Также нам необходимо избегать лишних накладных расходов, например, соединения с высокой задержкой или подключение к серверам с холодным или не до конца прогретым кешем.
Мы должны быть уверены, что трафик между службами защищен от тривиальных атак. Необходима взаимная TLS-аутентификация, но без встраивания соответствующих модулей в каждое приложение, которое мы пишем. Важно иметь возможность управления тем, что окружает наши приложения не только на уровне соединения, но и на более высоком уровне.
Service Mesh — это слой, который позволяет нам решать вышеуказанные проблемы в среде микрообслуживания.
Монолит и микросервисы: плюсы и минусы
Но сначала спросим себя, почему мы вообще должны решать эти проблемы? Как раньше мы занимались разработкой ПО? У нас было приложение, которое выглядит примерно вот так — как монолит.
Ведь здорово: весь код у нас на как ладони. Почему бы и дальше не использовать этот подход?
Да потому что у монолита есть свои проблемы. Главная трудность в том, что если мы захотим пересобрать это приложение, то должны повторно развернуть каждый модуль, даже если ничего не изменилось. Мы вынуждены создавать приложение на одном и том же языке или на совместимых языках, даже если над ним работают разные команды. Фактически отдельные части не могут быть протестированы независимо друг от друга. Пора это менять, пришло время микросервисов.
Итак, мы разделили монолит на части. Вы можете заметить, что в этом примере мы удалили некоторые из ненужных зависимостей и перестали использовать внутренние методы, вызываемые из других модулей. Мы создали сервисы из моделей, которые использовались ранее, создавая абстракции в тех случаях, когда нам нужно сохранять состояние. Например, каждый сервис должен иметь независимое состояние, чтобы при обращении к нему вы не беспокоились о том, что происходит в остальной части нашей среды.
Что получилось в итоге?
Мы ушли из мира гигантских приложений, получив то, что действительно отлично выглядит. Мы ускорили разработку, прекратили использовать внутренние методы, создали сервисы и теперь можем масштабировать их независимо, сделать сервис больше без необходимости укрупнять все остальное. Но какова цена изменений, что мы при этом потеряли?
У нас были надежные вызовы внутри приложений, потому что вы просто вызывали функцию или модуль. Мы заменили надежный вызов внутри модуля ненадежным удаленным вызовом процедуры. А ведь не всегда сервис на другой стороне доступен.
Мы были в безопасности, использовался один и тот же процесс внутри одной машины. Теперь мы подключаемся к сервисам, которые могут быть на разных машинах и в ненадежной сети.
В новом подходе в сети возможно присутствие других пользователей, которые пытаются подключиться к службам. Увеличились задержки, и одновременно сократились возможности их измерения. Теперь у нас есть пошаговые соединения во всех службах, которые создают один вызов модуля, и мы больше не можем просто посмотреть приложение в отладчике и узнать, что именно вызвало сбой. И эту проблему надо как-то решить. Очевидно, что нам необходим новый набор инструментов.
Что можно предпринять?
Есть несколько вариантов. Мы можем взять наше приложение и сказать, что если RPC не работает с первого раза, то следует попробовать еще раз, а затем еще и еще. Немного подождать и снова попробовать или добавить Jitter. Также мы можем добавить entry — exit traces чтобы сказать, что произошел запуск и завершение вызова, что для меня приравнивается к отладке. Можно добавить инфраструктуру для обеспечения проверки подлинности соединений и научить все наши приложения работать с TLS-шифрованием. Нам придется взять на себя бремя содержания отдельных команд и постоянно держать в голове различные проблемы, которые могут возникнуть в SSL-библиотеках.
Поддержание согласованности на различных платформах — это неблагодарная задача. Хотелось бы, чтобы пространство между приложениями стало разумным, чтобы появилась возможность отслеживания. Также нам нужна возможность изменения конфигурации во время выполнения, чтобы не перекомпилировать или не перезапускать приложения для перенастройки. Вот эти хотелки и реализует Service Mesh.
Istio
Поговорим о Istio.
Istio — это полноценный framework для подключения, управления и мониторинга микросервисной архитектуры. Istio создан для работы поверх Kubernetes. Сам он не развертывает программное обеспечение и не заботится о том, чтобы сделать его доступным на машинах, которые мы используем для этой цели с контейнерами в Kubernetes.
На рисунке мы видим три разных среза машин и блоки, которые составляют наши микросервисы. У нас есть способ сгруппировать их вместе с помощью механизмов, предоставляемых Kubernetes. Мы можем настроить таргетинг и сказать, что конкретная группа, которая может иметь автоматическое масштабирование, прикреплена к веб-сервису или может иметь другие методы развертывания, будет содержать наш веб-сервис. При этом нам не нужно думать о машинах, мы оперируем терминами уровня доступа к сетевым службам.
Данная ситуация может быть представлена в виде схемы. Рассмотрим пример, когда у нас есть механизм, который делает некоторую обработку изображений. Слева изображен пользователь, трафик от которого поступает к нам в микросервис.
Чтобы принимать оплату от пользователя, у нас есть отдельный платежный микросервис, вызывающий внешний API, который находится за пределами кластера.
Для обработки входа пользователей в систему у нас предусмотрен микросервис аутентификации, и у него есть состояния, сохраненные опять-таки за пределами нашего кластера в базе данных Cloud SQL.
Что делает Istio? Istio улучшает Kubernetes. Вы устанавливаете его с помощью альфа-функции в Kubernetes под названием Инициализатор. При развертывании программного обеспечения kubernetes заметит его и спросит, хотим ли мы изменить и добавить еще один контейнер внутри каждого kubernetes. Этот контейнер будет обрабатывать пути и маршрутизации, знать обо всех изменениях приложения.
Вот так схема выглядит с Istio.
У нас есть внешние машины, которые обеспечивают входящий и исходящий прокси для трафика в конкретном сервисе. Мы можем разгрузить функции, о которых уже говорили. Нам не нужно учить приложение, как выполнять телеметрию или трассировку с помощью TLS. Зато можем добавить внутрь другие вещи: автоматическое прерывание, ограничение скорости, canary release.
Весь трафик теперь будет проходить через прокси-серверы на внешних машинах, а не напрямую к сервисам. Kubernetes делает все на том же IP-адресе. Мы сможем перехватить трафик, который пошел бы на front или end сервисы.
Внешний прокси, который использует Istio, называется Envoy.
Envoy на самом деле старше Istio, он был разработан в LYFT. Работает в продакшн более года, запуская всю инфраструктуру микросервисов. Мы выбрали Envoy для проекта Istio в сотрудничестве с сообществом. Таким образом, Google, IBM и LYFT — это три компании, которые до сих пор над ним работают.
Envoy написан на C++ версии 11. Был в продакшн более 18 месяцев, прежде чем стать проектом с открытым исходным кодом. Он не займет много ресурсов, когда вы подключите его к вашим сервисам.
Вот несколько вещей, которые умеет Envoy. Это создание прокси-сервера для HTTP, включая HTTP/2 и протоколов, основанных на нем, таких как gRPC. Он также может выполнять переадресацию другим протоколам на двоичном уровне. Envoy контролирует вашу зону инфраструктуры, так что вы можете сделать свою часть автономной. Он может обрабатывать большое количество сетевых соединений с повторами запросов и ожиданием. Вы можете установить определенное количество попыток подключения к серверу, прежде чем прекратить обращение и передать своим серверам информацию о том, что сервис не отвечает.
Не нужно беспокоиться о перезагрузке приложения, чтобы добавить в него конфигурацию. Вы просто подключаетесь к нему с помощью API, очень похожим на kubernetes, и меняете конфигурацию во время выполнения.
Команда Istio внесла большой вклад в платформу UpStream Envoy Platform. Например, оповещение об ошибке injection. Мы сделали так, чтобы можно было видеть, как приложение ведет себя в случае превышения количества запросов на объект, завершившихся неудачей. А также реализовали функции графического отображения и разделения трафика, чтобы обрабатывать случаи, когда используется canary-развертывание.
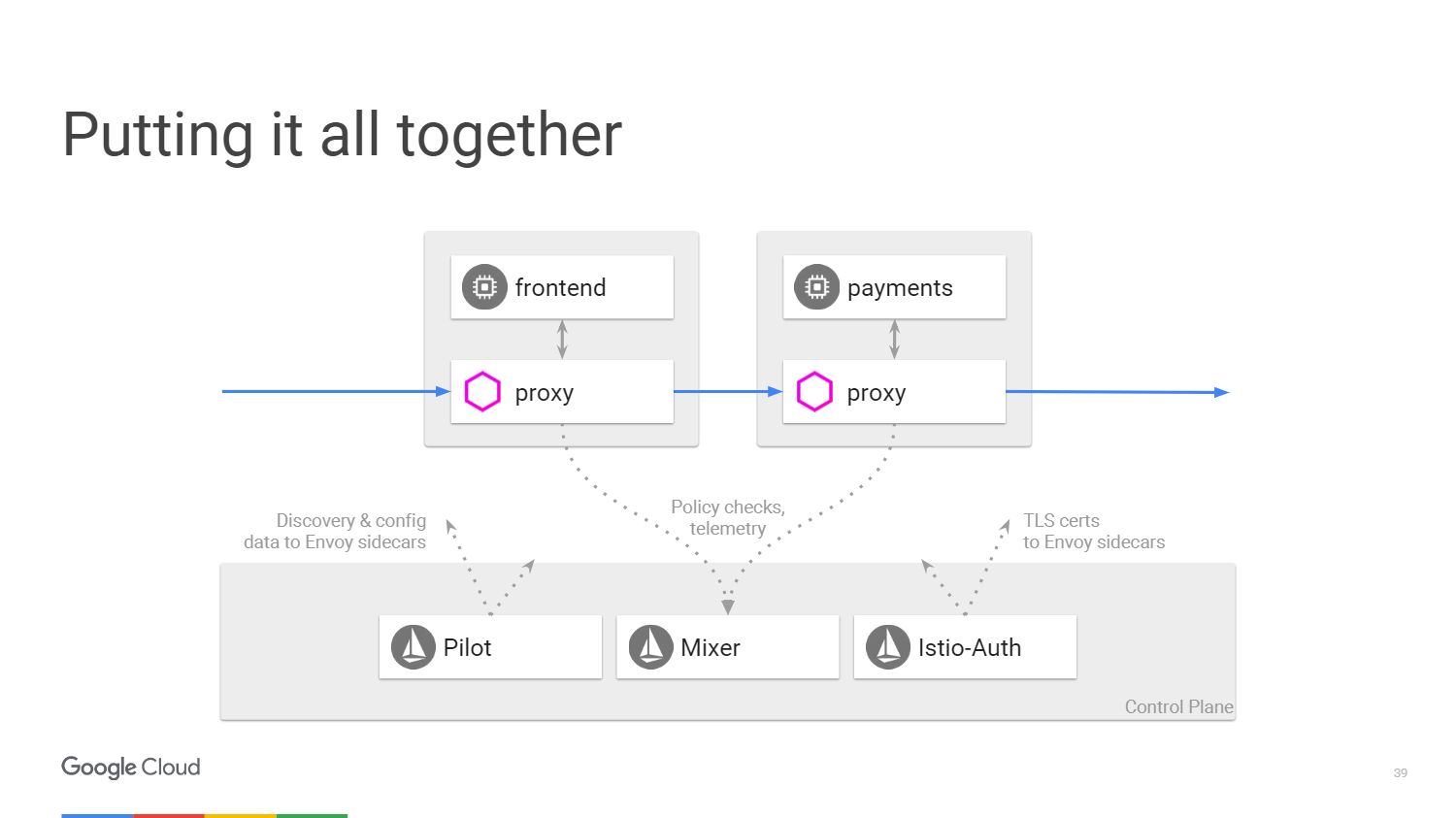
На рисунке показано, как выглядит архитектура системы Istio. Мы возьмем лишь два микросервиса, которые упоминали ранее. В конечном счете, на схеме все очень похоже на программно-определяемую сеть. Со стороны прокси-сервера Envoy, который мы развернули вместе с приложениями, происходит перенос трафика с помощью IP-таблиц в пространстве имен. Контрольная панель отвечает за управление консолью, но она не обрабатывает трафик сама.
У нас есть три компонента. Pilot, который создает конфигурацию, смотрит на правила, которые можно изменить с помощью API для контрольной панели Istio, и затем обновляет Envoy так, чтобы он вел себя как сервис обнаружения кластера. Istio-Auth служит центром сертификации и передает TLS сертификаты на прокси-серверы. Приложению не требуется наличие SSL, они могут соединяться по HTTP, и прокси будут обрабатывать все это за вас.
Mixer обрабатывает запросы, чтобы убедиться, что вы соответствуете политике безопасности, а затем передает телеметрическую информацию. Не внося никаких изменений в приложение, мы можем увидеть все, что происходит внутри нашего кластера.
Преимущества Istio
Итак, давайте поговорим подробнее о пяти вещах, которые мы получим от Istio. В первую очередь рассмотрим управление трафиком. Мы можем отделить контроль трафика от масштабирования инфраструктуры, поэтому ранее мы могли бы сделать что-то вроде 20 экземпляров приложения и 19 из них будет на старой версии, а один на новой, то есть 5% трафика будет приходиться на новую версию. С Istio мы можем развернуть любое количество экземпляров, которое нам нужно, и при этом указать, какой процент трафика нужно отправить на новые версии. Простое правило разделения.
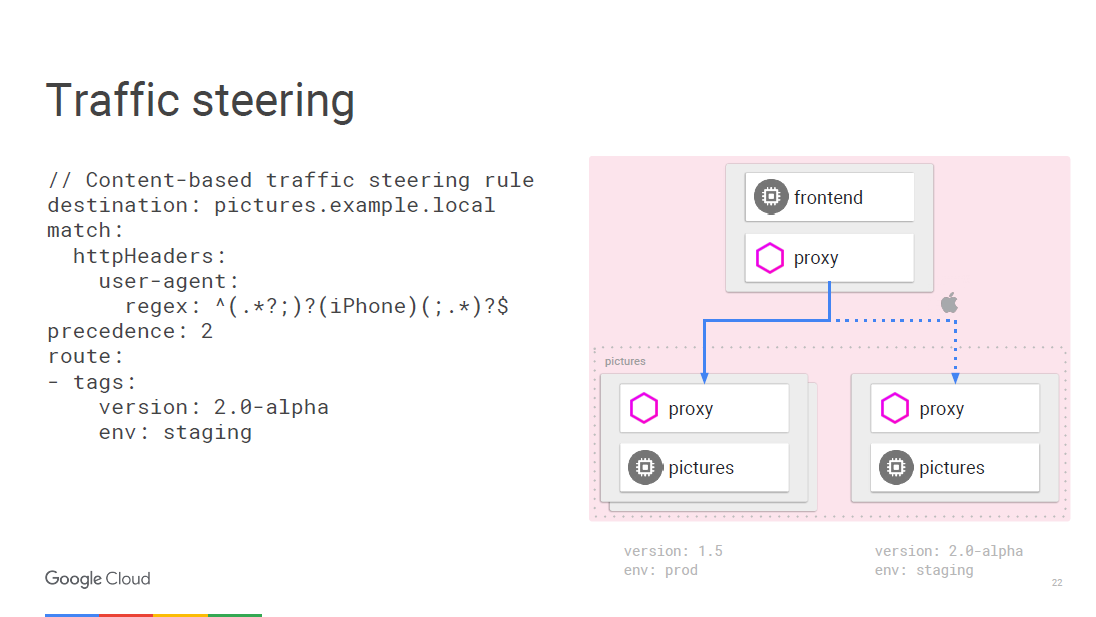
Все может быть запрограммировано «на лету» с помощью правил. Envoy будет периодически обновляться по мере изменения конфигурации, и это не приведет к сбоям в обслуживании. Так как мы работаем на уровне доступа к сетевым службам, то можем просмотреть пакеты, и в этом случае есть возможность залезть в пользовательский агент, который находится на третьем уровне сети.
Например, мы можем сказать, что любой траффик с iPhone подчиняется другому правилу, и мы собираемся направить определенную долю трафика на новую версию, которую хотим протестировать для определенного устройства. Внутренний вызывающий микросервис может определить, к какой конкретной версии ему нужно подключиться, а вы можете перевести его на другую версию, например, 2.0.
Второе преимущество — это прозрачность. Когда у вас есть представление внутри кластера, вы можете понять как оно сделано. Нам не нужно в процессе разработки создавать инструментарий для метрик. Метрики уже есть в каждом компоненте.
Некоторые считают, что для мониторинга вполне достаточно вести запись логов. Но по факту все, что нам нужно — это иметь такой универсальный набор показателей, который можно скормить любой службе мониторинга.
Так выглядит панель инструментов Istio, созданная с помощью сервиса Prometheus. Не забудьте его развернуть внутри кластера.
В примере на скриншоте показан ряд отслеживаемых параметров, характерных для всего кластера. Можно вывести и более интересные вещи, например, какой процент приложений дает более 500 ошибок, что подразумевает отказ. Время ответа агрегируется во всех вызывающих и отвечающих экземплярах сервисов внутри кластера, этот функционал не требует настроек. Istio знает, что поддерживает Prometheus, а тот в курсе, какие службы доступны в вашем кластере, поэтому Istio-Mixer может отправлять метрики в Prometheus без дополнительных настроек.
Давайте посмотрим, как это работает. Если вы вызываете конкретную службу, прокси сервис отправляет информацию об этом вызове в Mixer, который фиксирует такие параметры, как ожидание времени ответа, статус кода и IP. Он нормализует их и отправляет на любые серверы, которые вы сконфигурировали. Специально для вывода основных показателей есть сервис Prometheus и адаптеры FLUX DB, но вы также можете написать собственный адаптер и вывести данные в любом формате для любого другого приложения. И вам не придется ничего менять в инфраструктуре, если захотите добавить новую метрику.
Если вы хотите провести более глубокое исследование, то воспользуйтесь системой распределенной трассировки Zipkin. Информация обо всех вызовах, которые маршрутизируются через Istio-Mixer, может быть отправлена в Zipkin. Там вы увидите всю цепочку вызовов микросервисов при ответе пользователю и легко обнаружите службу, которая затягивает время обработки.
На уровне приложений беспокоиться о создании трассировки практически не нужно. Envoy сам передает всю необходимую информацию в Mixer, который отправляет ее в трассировку, например, в Zipkin, stackdriver trace от Google или любое другое пользовательское приложение.
Давайте поговорим об отказоустойчивости и эффективности.
Тайм-ауты между вызовами сервисов нужны для проверки работоспособности, в первую очередь, балансировщиков нагрузки. Введем ошибки в эту связь и посмотрим, что произойдет. Рассмотрим пример. Допустим, существует связь между сервисом A и сервисом B. Мы ждем ответ от сервиса видео 100 миллисекунд и даем всего 3 попытки, если результат не получен. По сути мы собираемся занять его на 300 миллисекунд, прежде чем он сообщит о неудачной попытке соединения.
Далее, например, наш сервис кино должен посмотреть рейтинг фильма через другой микросервис. У рейтинга таймаут составляет 200 миллисекунд и дается две попытки вызова. Вызов службы видео может привести к тому, что вы будете ждать 400 миллисекунд в случае, если рейтинг звездности вне доступа. Но, мы помним, по истечении 300 мс сервис кино сообщит, что он нерабочий, и мы никогда не узнаем реальную причину сбоя. Использование тайм-аутов и тестирование того, что происходит в этих случаях — отличный способ найти в вашей архитектуре микросервисов всякие хитроумные баги.
Посмотрим теперь, что с эффективностью. Сам балансировщик kubernetes действует всего лишь на уровне четвертого слоя. Мы изобрели конструктор входных данных для балансировки нагрузки со второго слоя по седьмой. Istio реализован в качестве балансировщика для уровня сети с доступом к сетевым службам.
Мы выполняем TLS-offloading, поэтому используем в Envoy современный хорошо допиленный SSL, с которым можно не волноваться о уязвимостях.
Еще одно преимущество Istio — безопасность.
Какие базовые средства безопасности есть в Istio? Сервис Istio-Auth работает в нескольких направлениях. Используется общедоступный фреймворк и набор стандартов идентификации для сервисов SPIFFE. Если мы говорим о потоке трафика, то у нас есть центр сертификации Istio, который выдает сертификаты для учетных записей служб, которые мы запускаем внутри кластера. Эти сертификаты соответствуют стандарту SPIFFE и распространяются Envoy, используя механизм защиты kubernetes. Envoy использует ключи для двусторонней аутентификации TLS. Таким образом, приложения бэкенда получают идентификаторы, на основе которых уже можно организовать политику.
Istio самостоятельно обслуживает корневые сертификаты, чтобы вы не волновались об аннулировании и истекающих сроках. Система будет реагировать на автоматическое масштабирование, поэтому вводя новую сущность, вы получаете новый сертификат. Никаких ручных настроек. Вам не надо настраивать firewall. Пользователи будут использовать сетевую политику и kubernetes, чтобы реализовать брандмауэры между контейнерами.
Наконец, применение политик. Mixer является точкой интеграции с инфраструктурными бэкэндами, которые вы можете расширить с помощью Service Mesh. Cервисы могут легко перемещаться внутри кластера, быть развернуты в нескольких средах, в облаке или локально. Все сконструировано для оперативного контроля вызовов, которые идут через Envoy. Мы можем разрешать и запрещать конкретные вызовы, ставить предварительные условия для пропуска вызовов, ограничивать их скорость и количество. Например, вы разрешаете к какой-то своей службе 20 бесплатных запросов в день. Если пользователь сделал 20 запросов, последующие не обрабатываются.
Предварительные условия могут включать в себя такие вещи, как, например, прохождение сервером проверки подлинности, ICL и его присутствие в белом списке. Управление квотами может использоваться в тех случаях, когда требуется, чтобы все, кто использует сервис, имели одинаковую скорость доступа. Наконец, Mixer собирает результаты обработки запросов и ответов, годные для телеметрии. Это позволяет производителям и пользователям смотреть на эту телеметрию с помощью сервисов.
Помните первый слайд с фотоприложением, с которого мы начали изучать Istio? Все вышеперечисленное скрыто под такой простой формой. На верхнем уровне все необходимое будет выполняться автоматически. Вы развернете приложение и не будете беспокоиться о том, как определить политику безопасности или настроить некоторые правила маршрутизации. Приложение будет работать именно так, как вы того ожидаете.
Как начать работать с Istio
Istio поддерживает предыдущие версии kubernetes, но новая функция инициализатора, о которой я рассказывал, находится в версиях 1.7 и выше. Это альфа-функция в kubernetes. Я рекомендую использовать Google Container Engine Alpha clusters. У нас есть кластеры, которые вы можете включить на определенное количество дней и при этом использовать все продакшн возможности в них.
Прежде всего Istio — это проект с открытым исходным кодом на github. Мы только что выпустили версию 0.2. В версии 0.1 можно было управлять объектами в пределах одноименного пространства имен kubernetes. С версии 0.2 мы поддерживаем работу в собственном пространстве имен и кластере kubernetes. Еще мы добавили доступ для возможности управления сервисами, которые запускаются на виртуальных машинах. Вы можете развернуть Envoy на виртуальной машине и обезопасить сервисы, которые работают на ней. В дальнейшем Istio будет поддерживать другие платформы, такие как Cloud Foundry.
Краткое руководство по установке фреймворка находится здесь. Если у вас есть кластер под управлением Google Container Engine на 1.8 с включенными альфа-функциями, то установка Istio — это всего лишь одна команда.
Если вам понравился этот доклад, приходите 14 октября на конференцию DevOops 2018 (Питер): там можно будет не только послушать доклады, но и пообщаться с любым докладчиком в дискуссионной зоне.
Комментарии (3)

lostinfuture
13.09.2018 10:00«… какой процент приложений дает более 500 ошибок, что подразумевает отказ...» Сомневаюсь, что там это имелось в виду
farcaller
1.0.2?
olegchir Автор
Да, сорян за косяк, я починил :)
Дело было 20 октября прошлого года, и конечно же там не было никакой версии 1.0. Однерка появилась только в этом июле. В докладе идет речь о версиях 0.1 и 0.2, конечно.