
Написал библиотеку для обучения нейронной сети. Кому интересно, прошу.
Давно хотел сделать себе инструмент такого уровня. C лета взялся за дело. Вот что получилось:
- библиотека написана с нуля на C++ (только STL + OpenBLAS для расчета), C-интерфейс, win/linux;
- cтруктура сети задается в JSON;
- базовые слои: полносвязный, сверточный, пулинг. Дополнительные: resize, crop..;
- базовые фишки: batchNorm, dropout, оптимизаторы весов — adam, adagrad..;
- для расчета на CPU используется OpenBLAS, для видеокарты — CUDA/cuDNN. Заложил еще реализацию на OpenCL, пока на будущее;
- для каждого слоя есть возможность отдельно задать на чем считать — CPU или GPU(и какая именно);
- размер входных данных жестко не задается, может меняться в процессе работы/обучения;
- сделал интерфейсы для C++ и Python. C# тоже будет позже.
Библиотеку назвал «SkyNet». (Сложно все с именами, другие были варианты, но что-то все не то..)
Cравнение с «PyTorch» на примере MNIST:
PyTorch: Accuracy: 98%, Time: 140 sec
SkyNet: Accuracy: 95%, Time: 150 sec
Машина: i5-2300, GF1060. Код теста.
Архитектура ПО
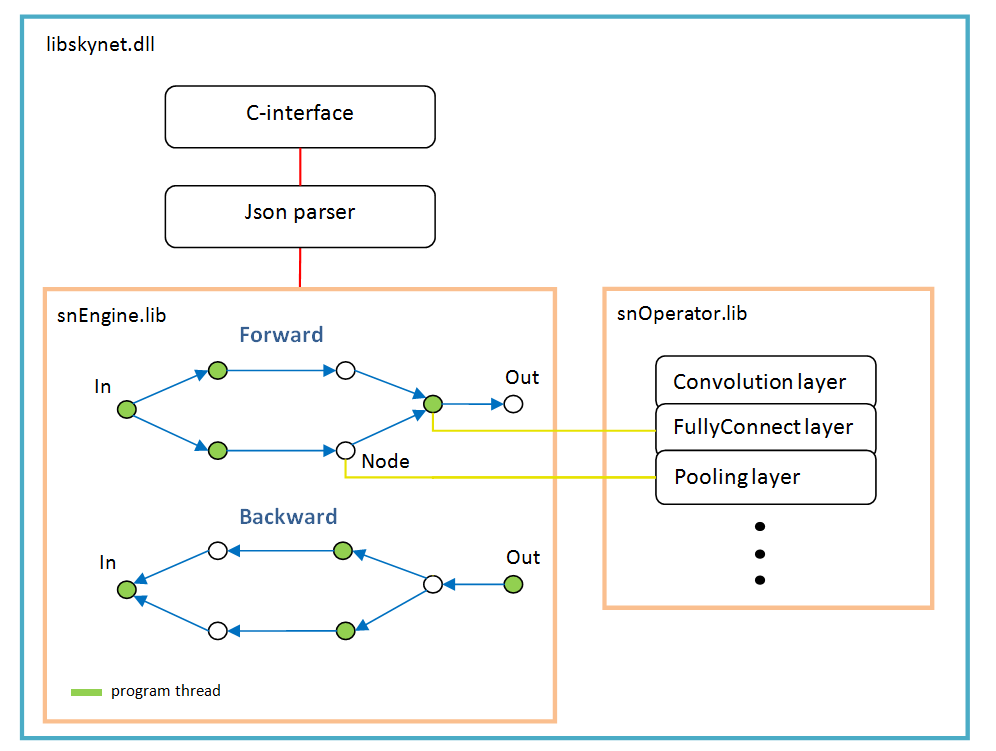
В основе лежит граф операций, создается динамически один раз после разбора структуры сети.
На каждое ветвление — новый поток. Каждый узел сети (Node) — это слой расчета.
Есть особенности работы:
- функция активации, нормализация по батчу, dropout — они все реализованы как параметры конкретных слоев, другими словами, эти функции не существуют как отдельные слои. Возможно batchNorm стоит выделить в отдельный слой, в будущем;
- функция softMax так же не является отдельным слоем, она принадлежит к специальному слою «LossFunction». В котором используется при выборе конкретного типа расчета ошибки;
- слой «LossFunction» используется для автоматического расчета ошибки, те явно можно не использовать шаги forward/backward (ниже пример работы с этим слоем);
- нет слоя «Flatten», он не нужен поскольку слой «FullyConnect» сам вытягивает входной массив;
- оптимизатор весов нужно задавать для каждого весового слоя, по умолчанию 'adam' используется у всех.
Примеры
MNIST

// создание сети
sn::Net snet;
snet.addNode("Input", sn::Input(), "C1")
.addNode("C1", sn::Convolution(15, 0, sn::calcMode::CUDA), "C2")
.addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA), "P1")
.addNode("P1", sn::Pooling(sn::calcMode::CUDA), "FC1")
.addNode("FC1", sn::FullyConnected(128, sn::calcMode::CUDA), "FC2")
.addNode("FC2", sn::FullyConnected(10, sn::calcMode::CUDA), "LS")
.addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy),
"Output");
............. // получение-подготовка изображений
// цикл обучения
for (int k = 0; k < 1000; ++k){
targetLayer.clear();
srand(clock());
// заполнение батча
for (int i = 0; i < batchSz; ++i){
.............
}
// вызов метода обучения сети
float accurat = 0;
snet.training(lr, inLayer, outLayer, targetLayer, accurat);
}
Полный код доступен здесь. Немного картинок добавил в репозиторий, находятся рядом с примером. Для чтения изображений использовал opencv, в комплект ее не включал.
Еще одна сеть того же плана, посложнее.

// создание сети
sn::Net snet;
snet.addNode("Input", sn::Input(), "C1 C2 C3")
.addNode("C1", sn::Convolution(15, 0, sn::calcMode::CUDA), "P1")
.addNode("P1", sn::Pooling(sn::calcMode::CUDA), "FC1")
.addNode("C2", sn::Convolution(12, 0, sn::calcMode::CUDA), "P2")
.addNode("P2", sn::Pooling(sn::calcMode::CUDA), "FC3")
.addNode("C3", sn::Convolution(12, 0, sn::calcMode::CUDA), "P3")
.addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC5")
.addNode("FC1", sn::FullyConnected(128, sn::calcMode::CUDA), "FC2")
.addNode("FC2", sn::FullyConnected(10, sn::calcMode::CUDA), "LS1")
.addNode("LS1", sn::LossFunction(sn::lossType::softMaxToCrossEntropy),
"Summ")
.addNode("FC3", sn::FullyConnected(128, sn::calcMode::CUDA), "FC4")
.addNode("FC4", sn::FullyConnected(10, sn::calcMode::CUDA), "LS2")
.addNode("LS2", sn::LossFunction(sn::lossType::softMaxToCrossEntropy),
"Summ")
.addNode("FC5", sn::FullyConnected(128, sn::calcMode::CUDA), "FC6")
.addNode("FC6", sn::FullyConnected(10, sn::calcMode::CUDA), "LS3")
.addNode("LS3", sn::LossFunction(sn::lossType::softMaxToCrossEntropy),
"Summ")
.addNode("Summ", sn::Summator(), "Output");
.............
В примерах ее нет, можете скопировать отсюда.
// создание сети
snet = snNet.Net()
snet.addNode("Input", Input(), "C1 C2 C3") .addNode("C1", Convolution(15, 0, calcMode.CUDA), "P1") .addNode("P1", Pooling(calcMode.CUDA), "FC1") .addNode("C2", Convolution(12, 0, calcMode.CUDA), "P2") .addNode("P2", Pooling(calcMode.CUDA), "FC3") .addNode("C3", Convolution(12, 0, calcMode.CUDA), "P3") .addNode("P3", Pooling(calcMode.CUDA), "FC5") .addNode("FC1", FullyConnected(128, calcMode.CUDA), "FC2") .addNode("FC2", FullyConnected(10, calcMode.CUDA), "LS1") .addNode("LS1", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \
.addNode("FC3", FullyConnected(128, calcMode.CUDA), "FC4") .addNode("FC4", FullyConnected(10, calcMode.CUDA), "LS2") .addNode("LS2", LossFunction(lossType.softMaxToCrossEntropy), "Summ") .addNode("FC5", FullyConnected(128, calcMode.CUDA), "FC6") .addNode("FC6", FullyConnected(10, calcMode.CUDA), "LS3") .addNode("LS3", LossFunction(lossType.softMaxToCrossEntropy), "Summ") \
.addNode("Summ", LossFunction(lossType.softMaxToCrossEntropy), "Output")
.............
CIFAR-10

Здесь уже пришлось включить batchNorm. Эта сетка учится до 50% точности в течении 1000 итераций, batch 100.
sn::Net snet;
snet.addNode("Input", sn::Input(), "C1")
.addNode("C1", sn::Convolution(15, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C2")
.addNode("C2", sn::Convolution(15, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P1")
.addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3")
.addNode("C3", sn::Convolution(25, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C4")
.addNode("C4", sn::Convolution(25, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P2")
.addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5")
.addNode("C5", sn::Convolution(40, -1, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "C6")
.addNode("C6", sn::Convolution(40, 0, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "P3")
.addNode("P3", sn::Pooling(sn::calcMode::CUDA), "FC1")
.addNode("FC1", sn::FullyConnected(2048, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC2")
.addNode("FC2", sn::FullyConnected(128, sn::calcMode::CUDA, sn::batchNormType::beforeActive), "FC3")
.addNode("FC3", sn::FullyConnected(10, sn::calcMode::CUDA), "LS")
.addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
Думаю, понятно, что можно подставить любые классы картинок.
U-Net tyni
Последний пример. Упростил нативную U-Net для демонстрации.

Чуть поясню: слои DC1… — обратная свертка, слои Concat1… — слои сложения каналов,
Rsz1… — используются для согласования числа каналов на обратном шаге, поскольку со слоя Concat обратно идет ошибка по сумме каналов.
sn::Net snet;
snet.addNode("In", sn::Input(), "C1")
.addNode("C1", sn::Convolution(10, -1, sn::calcMode::CUDA), "C2")
.addNode("C2", sn::Convolution(10, 0, sn::calcMode::CUDA), "P1 Crop1")
.addNode("Crop1", sn::Crop(sn::rect(0, 0, 487, 487)), "Rsz1")
.addNode("Rsz1", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc1")
.addNode("P1", sn::Pooling(sn::calcMode::CUDA), "C3")
.addNode("C3", sn::Convolution(10, -1, sn::calcMode::CUDA), "C4")
.addNode("C4", sn::Convolution(10, 0, sn::calcMode::CUDA), "P2 Crop2")
.addNode("Crop2", sn::Crop(sn::rect(0, 0, 247, 247)), "Rsz2")
.addNode("Rsz2", sn::Resize(sn::diap(0, 10), sn::diap(0, 10)), "Conc2")
.addNode("P2", sn::Pooling(sn::calcMode::CUDA), "C5")
.addNode("C5", sn::Convolution(10, 0, sn::calcMode::CUDA), "C6")
.addNode("C6", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC1")
.addNode("DC1", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz3")
.addNode("Rsz3", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc2")
.addNode("Conc2", sn::Concat("Rsz2 Rsz3"), "C7")
.addNode("C7", sn::Convolution(10, 0, sn::calcMode::CUDA), "C8")
.addNode("C8", sn::Convolution(10, 0, sn::calcMode::CUDA), "DC2")
.addNode("DC2", sn::Deconvolution(10, sn::calcMode::CUDA), "Rsz4")
.addNode("Rsz4", sn::Resize(sn::diap(0, 10), sn::diap(10, 20)), "Conc1")
.addNode("Conc1", sn::Concat("Rsz1 Rsz4"), "C9")
.addNode("C9", sn::Convolution(10, 0, sn::calcMode::CUDA), "C10");
sn::Convolution convOut(1, 0, sn::calcMode::CUDA);
convOut.act = sn::active::sigmoid;
snet.addNode("C10", convOut, "Output");
Полный код и изображения находятся здесь.
Математика из открытых источников типа этого.
Все слои тестировал на MNIST, эталоном оценки ошибки служил TF.
Что дальше
Библиотека в ширину расти не будет, то есть никаких opencv, сокетов и тп, чтобы не раздувать.
Интерфейс библиотеки изменяться/расширяться не будет, не скажу что вообще и никогда, но в последнюю очередь.
Только в глубину: сделаю расчет на OpenCL, интерфейс для C#, RNN сеть может быть…
MKL думаю нет смысла добавлять, потому что чуть глубже сеть — быстрее все равно на видеокарте, и карта средней производительности не дефицит совсем.
Импорт/экспорт весов с другими фреймворками — через Python (пока не реализован). Roadmap будет, если интерес возникнет у людей.
Кто может поддержать кодом, прошу. Но есть ограничения, чтобы текущую архитектуру не поломать.
Интерфейс для питона можете расширять до невозможности, так же доки и примеры нужны.
Для установки из Python:
* pip install libskynet — CPU
* pip install libskynet-cu — CPU + CUDA9.2
* pip install libskynet-cudnn — CPU + cuDNN7.3.1
Если сеть у вас не глубокая, используйте реализацию CPU + CUDA, памяти потребляет на порядки меньше по сравнению с cuDNN.
Руководство пользователя wiki.
ПО распространяется свободно, лицензия MIT.
Спасибо.
Комментарии (24)

Tantrido
14.10.2018 21:21Интересная библиотечка, нужно будет посмотреть, попробовать.
А сеть сам писал или это всё есть в openBLAS? Тот же вопрос по CUDA и т.п. — сам или всё есть openBLAS?
У меня тоже есть небольшая библиотечка — актуальна была, лет 10 назад, когда не было CUDA, был однопоток и т.п. Но мне она интересна наличием в ней быстрого CCG алгоритма и GA, в котором ошибка на тестовой выборке меньше, чем на обучающей. Как можно разпараллелить обучение, перевести на CUDA и т.д.? Можешь что-то посоветовать.tzps
14.10.2018 22:25OpenBLAS — это всего лишь BLAS. Несколько десятков операций линейной алгебры, для операций между векторами и матрицами.
CUDA — предоставляет свою имплементацию BLAS — cuBLAS, плюс предоставляет приличный набор примитивов для построения нейросетей — cuDNN.

Tyiler Автор
15.10.2018 05:59на CPU и CUDA алгоритмы свои, cuDNN дает готовую реализацию. Как ниже указали «OpenBLAS — это всего лишь BLAS».
Как можно разпараллелить обучен...
от задачи плясать надо. с мануала CUDA начать, дальше примеров в сети масса.
barabanus
14.10.2018 21:59+2Cравнение с «PyTorch» на примере MNIST:
PyTorch: Accuracy: 98%, Time: 140 sec
SkyNet: Accuracy: 95%, Time: 150 secТ.е. работает хуже и медленнее?
tzps
14.10.2018 22:27В коде указанном в статье не упоминается нигде важнейший аспект — изначальное распределение весов. А это — один из важнейших аспектов все-таки. Возможно разница в accuracy этим объясняется.
Tyiler Автор
15.10.2018 06:02Тест на адекватность расчета, не было цели догнать и перегнать. Математика везде та же самая, все дело в деталях — веса, слои, функция ошибки, аугментация данных и тд
Dark_Daiver
15.10.2018 09:18Неплохо было бы уменьшить разницу, чтобы убедиться что проблема была именно в аугментациях. 3% на MNIST это очень много.
roryorangepants
15.10.2018 09:22То есть вы сравнивали сети не с равными параметрами и настройками обучения?
Тогда это сравнение не даёт особой информации.
Попробуйте воспроизвести одну и ту же архитектуру один-в-один в PyTorch / TensorFlow и в вашей библиотеке. Вот такое сравнение было бы интересным.
divanus
14.10.2018 22:29-5Стою на траве я в лыжи обутый, то ли лето пришло, то ли я.
Точно, я.
А автору жирый лайкище!
greenkey
15.10.2018 05:57Интересная штука. Только недавно искал библиотеки по нейросетям, хоть и не для плюсов.
roryorangepants
15.10.2018 08:51+1Такое ощущение, что сейчас 2007 год, где библиотеки для глубокого обучения — редкость.
Сейчас есть десятки огромных библиотек, написанных на плюсах, у которых есть обертки под высокоуровневый язык программирования на ваш вкус.robert_ayrapetyan
15.10.2018 17:57Так в том-то и дело, что в оббертках куча логики, без которой плюсовые либы не юзабельны для современных практических задач, оттого и мнение такое сложилось.
Tyiler Автор
15.10.2018 19:53немного не в этом дело.
логику самому можно написать, которой не хватает (подготовка изображений, автокорр-ка lrate и тд).
Имхо, на самом деле, проблема в том, что у современных ML библиотек интерфейс проектировался(и реализовался) сразу с учетом использования на Python (или на другой скрипт язык). Поэтому, извиняюсь, кишки торчат наружу, те любая внутренняя структура имеет внешний handler, вся внутренняя кухня — engine, optimizer, lossfunc… все болтается в h-ках, которых тоже куча получается, для каждой внутренней сущности.
Соответственно пользоваться нативно таким винегретом, не разработчику, тяжело.
Приходится смотреть внутрь. Теперь о том что внутри.
Внутри С++ во всей красе, те не ограничен ничем — шаблоны в куче с наследованием, структуры магически выводящие описание и типы своих данных, портянки комментов, о том как работает код, авторы будто сами понимают, что без этого комментария вообще никак и т.д.
А теперь почему так (имхо все продолжается, если что). Потому что пишут люди близкие к науке, не программисты. По хорошему, им надо писать методики для программистов. Если бы был хороший понятный код, не только для питона, то мало кто стал бы писать велики.
ErmIg
15.10.2018 18:04Перспективы библиотеки конечно довольно туманны, ввиду огромного количества весьма достойных альтернатив. Однако она тоже полезна — лучший способ разобраться в методах машинного обучения — самому написать библиотечку для машинного обучения (проверено на себе). Так что удачи автору!
P.S. Сам достаточно длительное время посвятил оптимизациям прямого распространения сигнала в неросетях на CPU (проекты Simd и Synet). Если потребуется помощь — обращайтесь.
uncle_goga
Интересная вещь, не часто встретишь нейросеть на ++
robert_ayrapetyan
Да и еще и написано чисто и понятно. Тоже большая редкость для ++
tzps
Почти все современные библиотеки для DL написаны на C++. Но я вроде встречал и С однажды.
robert_ayrapetyan
А все ядро (линейная алгебра) — на фортране. И что? Там пирог слоев, и пользуют все питон почему-то…
roryorangepants
Я не согласен с вашей логикой.
То, что все используют питон, не отменяет того факта, что библиотека написана на плюсах, и ее можно использовать на плюсах. И более того, ее используют и в плюсовой версии тоже.
Другое дело, что на питоне ресерч вести куда проще.
robert_ayrapetyan
Не просто ресерч. Питон не просто оббертка, там много доп. логики реализовано. Так то можно и С назвать обберткой над фортрановской либой просто.
iroln
Вы просто не в теме.
Самый популярный tensorflow, внезапно, написан на C++
Следующий по популярности Caffe написан на C++
PyTorch, ой, внезапно тоже C++. Как же так?
И далее:
https://github.com/tiny-dnn/tiny-dnn
https://github.com/josephmisiti/awesome-machine-learning#general-purpose-machine-learning-2
А вы думали, всё на Python пишут? :) Нет, только интерфейсные обертки для удобного применения, прототипирования, визуализации и т. д.
robert_ayrapetyan
Из серии «а ядро все на фортране». Понятно что не на питоне, только вот человеческий облик только у питоновских обберток. И таки да, вы удивитесь, но все пользуют именно питоновские оббертки, а не фортран и С напрямую.