

Причём, похоже, для этого даже не обязательно самому пользователю открывать и читать полученное сообщение. Если включены уведомления и символы появятся в превью, то приставка также отключится.
Пример сообщения для «выбивания» пользователя:
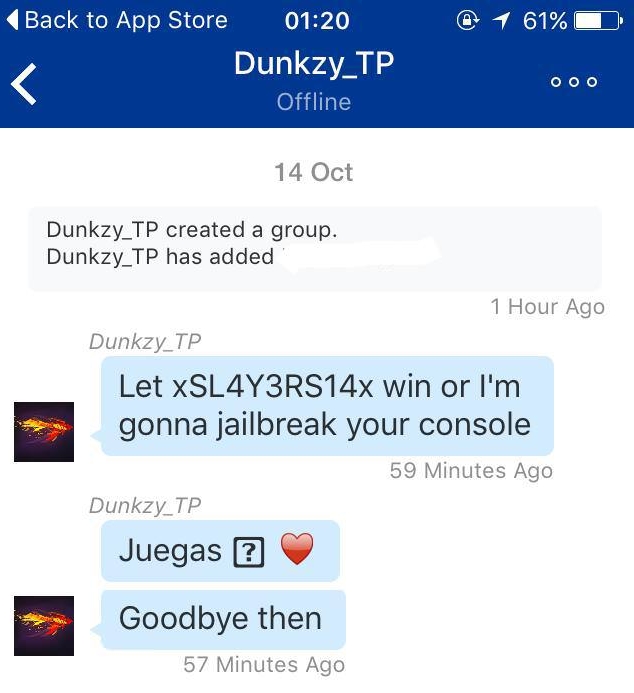
Уязвимость производителем на данный момент не исправлена и используется достаточно широко, особенно против игроков в сетевых играх, судя по скриншотам и веткам обсуждений с форумов по PS4.
Ссылка на обсуждение проблемы.
Update 15/10/18:
A PS4 exploit appeared during the weekend, in which a viral PSN message could render your machine unusable until you followed a workaround.
Sony says it is aware of the issue and is working on a fix. “We are aware of the situation and are planning a system software update to resolve this problem,” Sony told VG247 in an email.
В компании Sony заявили, что знают о проблеме и работают над исправлением. «Мы знаем о ситуации и планируем обновление системного программного обеспечения для решения этой проблемы»
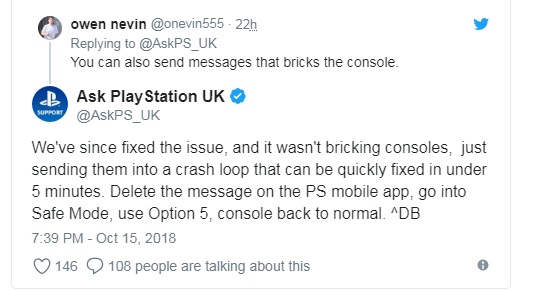
Рекомендуется выполнить изменение настроек консоли для противодействия уязвимости:
— на приставке PS4: Управление учётной записью -> Настройки конфиденциальности -> Личная информация -> Сообщения -> Никто (или Друзья, если доверяете им);
— в мобильном приложении PlayStation Messages: Изменить профиль -> Настройки конфиденциальности -> Личная информация -> Сообщения -> Никто (или Друзья, если доверяете им).
Если неприятность все же произошла и консоль отключилась после получения сообщения, то решить проблему возможно — нужно удалить данное сообщение с мобильного приложения PlayStation Messages, которое доступно на iOS или Android. Желательно ещё и реконструировать базу данных PS4 через безопасный режим.
Если эти действия не помогли, то только Factory Reset.
Еще пример сообщений:
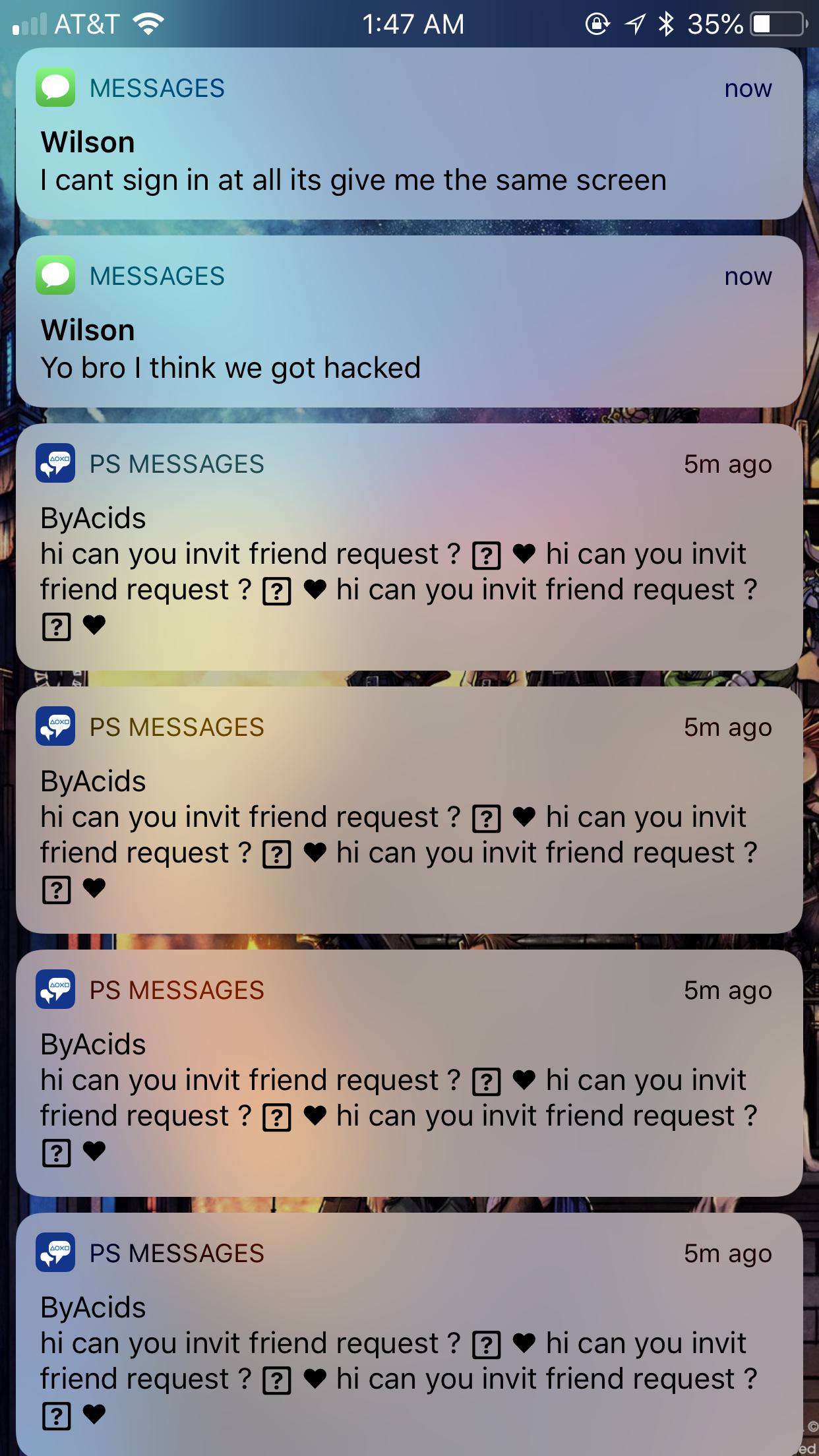
Emogi что ли используют в сообщении таком.
Комментарии (51)

dopusteam
14.10.2018 19:28+5Было бы интересно причину узнать, что именно там происходит
vassabi
14.10.2018 19:45+5как обычно — неправильная обработка строк и протекание абстракций.
tormozedison
14.10.2018 22:08Интереснее другое: как эксплойт найти удалось. Кто-то чисто случайно кому-то это эмоджи отправил?
JerleShannara
14.10.2018 23:09+2Ну или повторили стандартные варианты, которые уже были открыты для яблочных девайсов и прочих.
darksshvein
15.10.2018 10:19слава отличному коду и продвинутым языкам, которые умеют целиться в ногу!
JerleShannara
14.10.2018 19:48+2Скорее всего вечный прикол с добавлением всяких склеек символов и алфавитов с прочтением наоборот.
vmchaz
14.10.2018 20:15+8utf8, говорили они.
Самая «совершенная» кодировка, говорили они.JerleShannara
14.10.2018 23:08После статей вида «как вычислить длину строки utf8» я очень прифигел
ivan386
15.10.2018 09:02Можно пару ссылочек? Никак не найду похожих статей.
mkshma
15.10.2018 13:57Можно глянуть, например, алгоритм кодирования на вики. Полагаю нормального способа узнать длину нет (если языком не предусмотрена библиотечная функция именно под utf-8) и придется играться с битовыми операциями.

evgepet
16.10.2018 05:13www.cyberforum.ru/c-beginners/thread1195447.html
Достаточно понятно объяснено.
Комментарий с объяснением взят отсюда: tools.ietf.org/html/rfc3629
balexa
15.10.2018 00:14Так дело ведь не в кодировке. Скорее всего в том, что кто-то вместо стандартной библиотеки строк решил писать свой велосипед.
mynameco
15.10.2018 01:43utf8 это не кодировка а один из "контейнеров" для кодировки юникод. Чтобы в utf8 накосячить нужно уж очень постараться.
ivan386
15.10.2018 09:30-2Очень даже легко накосячить. Стоит только выйти за значения байта > 127 и тут начинается магия не правильных последовательностей байт. А какой сюрприз мне сделали суррогатные пары в нём которые превращают два кодпойнта в один. А потом оказывается что его ещё и ограничили из за utf16 в котором как раз и используются эти соррогатные пары.
0serg
15.10.2018 10:12+1В UTF-8 нет суррогатных пар
ivan386
15.10.2018 10:51Они есть в Unicode (диапазон 0xD800 — 0xDBFF) и как следствие могут быть во всех контейнерах.
D800;<Non Private Use High Surrogate, First>;Cs;0;L;;;;;N;;;;; DB7F;<Non Private Use High Surrogate, Last>;Cs;0;L;;;;;N;;;;; DB80;<Private Use High Surrogate, First>;Cs;0;L;;;;;N;;;;; DBFF;<Private Use High Surrogate, Last>;Cs;0;L;;;;;N;;;;;0serg
15.10.2018 13:41Они есть в UTF-16 но это не валидные символы Unicode (в таблице Unicode этот диапазон специально из-за UTF-16 зарезервирован чтобы туда никто символов не добавлял). Кроме того у UTF-8 технически нет вообще никаких проблем с тем чтобы их кодировать хотя многие compliant readers откажуется это делать вполне справедливо интерпретировав получение зарезервированного символа как ошибку декодирования. Все же кодировать с помощью UTF-8 не саму строку а ее бинарное представление записанное с помощью UTF-16 — это определенный бред. Но никакую «склейку двух кодпоинтов в один» они в UTF-8 в любом случае не порождают.
ivan386
15.10.2018 14:21Notepad++

- HEX в UTF-8 (EDA0B4EDB480)
- Копируем полученную строку
- UTF-8 в HEX (F09D8480)
Мне этот символ аж комментарий порезал ))
mayorovp
15.10.2018 14:34+1Тут прикол в том, что на этапе «Копируем полученную строку» вы копируете ее в кодировке utf-16, где эти самые суррогатные пары как раз и используются. Поэтому ваш Notepad++ делает преобразование utf-8 — utf-16 — utf-8.

forever_live
16.10.2018 17:42А можно поподробнее? Не могу воспроизвести в относительно свежем N++. HEX-ASCII, ASCII-HEX — нашёл (Plugins/Converter), а HEX-UTF8 — нет.
ivan386
16.10.2018 18:24HEX-ASCII, ASCII-HEX это оно. Надо это делать в режиме UTF-8.
Может уже поправили. У меня он старый. У меня всё старое ибо XP 64.forever_live
16.10.2018 20:43Разобрался. У меня была отключена анимация гифок после обновления FF, поэтому не было очевидно что происходит.
Вообще, это классический случай неожиданного поведения в случае некорректных данных.
Этот поток байт не является корректным UTF-8 потоком, и с ним нельзя делать то, что оптимистично сделал N++. У меня он работает почти так же, только показывает один квадратик вместо двух.
На всякий случай декодировал поток вручную, чтобы не зависеть от багов какого-либо перекодировщика.
В общем, олдскульным программистам, видевшим DOS 3.x и однобайтные кодировки, придётся запомнить, что в нынешнем мире массив байт — это одно, а строка символов — совсем другое. Такова нынешняя реальность.
namikiri
15.10.2018 08:51Так проблема-то в рендерере шрифтов. Что-то не видел я, чтобы таким способом положили устройство на Windows, Linux или Android. В основном этим страдали устройства Apple, ибо кодовая база для рендерера шрифтов у них одна. Как видим, Sony подсмотрела лучшие технологии у коллег.
vsb
15.10.2018 10:40Шрифты часто рисуют где-то рядом с драйвером, любой баг в отрисовке шрифта может быть фатален, тут только улучшать качество кода рендерера. Бывает, что и просто хитрый CSS с какими-то замудрёными фильтрами роняет драйвер, в венде я это наблюдал, просто там это не фатально, как ни странно, но венда это самая продвинутая ОС в этом плане, после бага драйвер графического режима рестартует и даже заменяется VGA-драйвером, чтобы можно было нормально сохраниться и перезагрузить, прямо микроядерная ОС. Ну и безумное число сочетаний всех комбинаций версий драйверов, железа и тд тоже усложняет подбор такого эксплоита, в отличие от того же Apple, где всё довольно одинаковое.
namikiri
15.10.2018 11:49Да-да, то самое «видеодрайвер перестал отвечать и был восстановлен». Очень радует меня эта восстанавливаемость, порой спасало данные от полной потери.
mayorovp
15.10.2018 12:11Хм, у меня обычно после «восстановления» видеодрайвера компьютер сразу же зависает в бесконечном цикле вылетов и восстановлений…
namikiri
15.10.2018 13:15+1Видел такое «восстановление» видел только один раз в жизни. Что-то подсказывает что тут уже проблемы с железом.
vorphalack
15.10.2018 18:49у меня вообще было восстановление из голубого экрана на десятке один раз, выглядело как хренова магия. но у меня и правда видяха с при… дурью, скажем так.
QtRoS
14.10.2018 22:23Я недавно в Qt репортил похожий баг — цветной эмоджи на кнопке вызывал рандомный segfault. Если интересно, могу поискать, мне кажется плюс минус похожая проблема.
UberSchlag
15.10.2018 13:11Это интересно было бы посмотреть!
QtRoS
15.10.2018 20:51+1Мой баг: https://bugreports.qt.io/browse/QTBUG-64439
Исправление было сделано в: https://bugreports.qt.io/browse/QTBUG-64239
willmore
14.10.2018 21:31+3Emogi что ли используют в сообщении таком.
Язык этот знакомым кажется мне.

Iwanowsky
14.10.2018 23:16Это как в былые времена SMS смерти для телефонов Siemens и некоторых др.
Igor_O
15.10.2018 00:36Парадоксальным образом, такие баги встречались и до эмодзи и хитрых кодировок. Сейчас уже простым образом не находится, что именно там глючило и почему, но в стародавние времена при наличии определенной последовательности символов в тексте происходило глухое зависание компьютера при попытке просмотреть файл по F3 в Нортон Коммандере под старым добрым ДОСом. Причем, нарваться на эту последовательность можно было и в совершенно безобидных файлах.
ABATAPA
15.10.2018 09:44Это Вы ещё не знаете о "залипании" бит (не данных) при некоторых последовательностях на печатных машинках. И переход в командный режим модема при наличии "+++" в сжатых данных…
И многое, многое иное.
skptricks
15.10.2018 08:48Check out this example: www.skptricks.com/2018/10/create-custom-snackbar-component-in-react-native.html
einhander
15.10.2018 09:22+1Если не ошибаюсь, то несколько лет назад у apple была схожая бага, окирпичивающая аппарат.

denis-19 Автор
15.10.2018 09:24Berkof
15.10.2018 10:55Я не понял, производитель решил полностью забить на пользователей или ему так сложно экстренно добавить в движок обработки сообщений (в движок чата, на этапе приёма сообщения) фильтр на эту последовательность? А потом уже спокойно чинить багу «как надо».
Vindicar
15.10.2018 11:07Скорее всего, там целый класс последовательностей. Захардкодишь в заплатке одну — начнут использовать другую.
А что бы определить возможные варианты («как надо»), требуется время.OnYourLips
15.10.2018 13:13Временно запретить все последовательности, возможно пожертвовав парой языков на время появления правильной заплатки.
mayorovp
15.10.2018 14:38Проще забанить всех кто их отправляет, и приостановить регистрацию новых пользователей…
springimport
15.10.2018 16:32+2Там такой производитель который в 2018 анонсировал смену ников и скоро начнется бета-тест… ну вы поняли.
А когда все заработает то в некоторых играх новый ник может не работать. Ну вы…
Такой вот производитель.beeruser
16.10.2018 01:26А когда все заработает то в некоторых играх новый ник может не работать.
А как вы себе это представляете? Они все игры должны поправить?
Изменился API. Нужно переписать код, который с ним работает.springimport
16.10.2018 16:02+1Я представляю это себе так: при закладке системы разработчики спустили на тормозах функцию изменения ника. И было это примерно эдак в 2007 а не в 1995 когда еще можно было бы списать это.
Silvatis
кажется, разработчики немного не так поняли рвение менеджеров ровняться на apple…