
Так вот, сообщество, прошу предоставить мне шанс удивить вас с третьего раза, в предыдущем решении я задействовал питон, думал вот тут привлеку внимание знатоков и мне сразу скажут, да зачем это делать, вообще есть же регулярные выражения — сделал и все там точно будет работать, этот наш питон может выдать и поболее скорости.
Следующая тема статьи должна быть другая задача по очереди, ан нет меня не оставила еще первая, что можно сделать, чтобы получить еще более быстрое решение, так как победа на сайте увенчалась еще одним соревнованием.
Я написал реализацию которая в среднем была вот такого вида скорости, значит есть еще 90 процентов решений, которых я не заметил, что кто-то знает как ее решить еще быстрее и он молчит, и посмотрев две предыдущие статьи не сказал: ах, если это вопрос производительности, тогда все понятно — тут пролог не подходит. Но с производительностью сейчас все нормально, представить себе программу, которая будет запущена на слабом железе не возможно, "в конце концов, зачем об этом думать?"
Вызов
Решить задачу еще быстрее, там был питон и было время, и есть на питоне более быстрое решение?
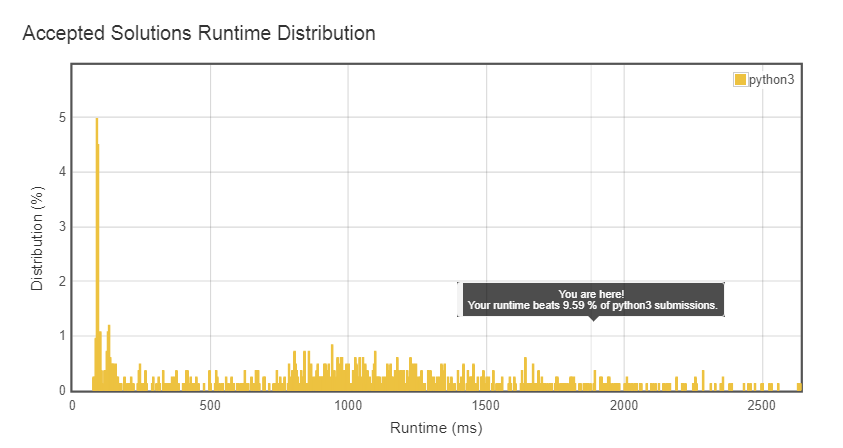
Мне сообщают "Runtime: 2504 ms, faster than 1.55% of Python3 online submissions for Wildcard Matching."
Предупреждаю, далее происходит поток мысли онлайн.
1 Регуляркой?
Может тут вариант написать более быструю программу просто воспользовавшись регулярным выражением.
Явно питон может создать объект регулярного выражения, который проверит входную строку и это получится запустить прямо там, в той песочнице, что на сайте для тестирования программ.
Всего лишь import re, смогу сделать импорт такого модуля, это интересно, надо попробовать.
Не просто это понимать, что создать быстрое решение не легко. Придется немного поискать, попробовать и создать реализация подобную такой:
1.сделать объект этой регулярки,
2.подсунуть ей шаблон подправленный по правилам регулярок выбранной библиотеки,
3.сравнить и ответ готов
Вуаля:
import re
def isMatch(s,p):
return re.match(s,pat_format(p))!=None
def pat_format(pat):
res=""
for ch in pat:
if ch=='*':res+="(.)*"
if ch=='?':res+="."
else:
res+=ch
return resвот очень короткое решение, как будто правильное.
Пробую запустить, но не тут то было, не совсем правильно, какой-то вариант не подходит, надо тестировать преобразование в шаблон.
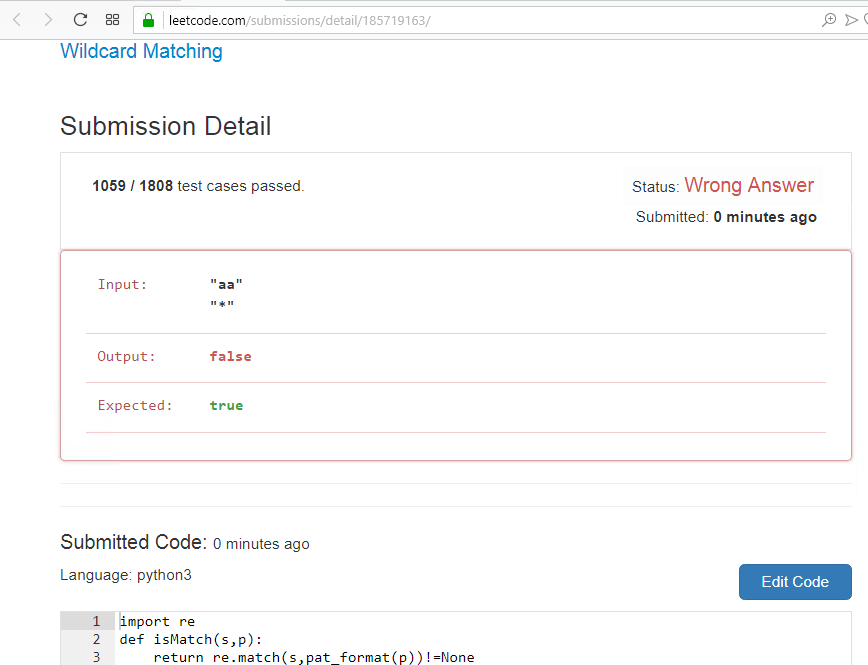
Правда забавно, я перепутал шаблон и строку, а решения сошлось, я прошел 1058 тестов и провалился, только тут.
Еще раз повторюсь, на этом сайте работают внимательно над тестами, как так получилось, все предыдущее хорошо, а тут перепутаны два основных параметра и это проявилось, вот вам преимущества TDD...
И на вот такой замечательный текст, я все равно получаю ошибку
import re
def isMatch(s,p):
return re.match(pat_format(p),s)==None
def pat_format(pat):
res=""
for ch in pat:
if ch=='*':res+="(.)*"
else:
if ch=='?':res+="."
else:res+=ch
return res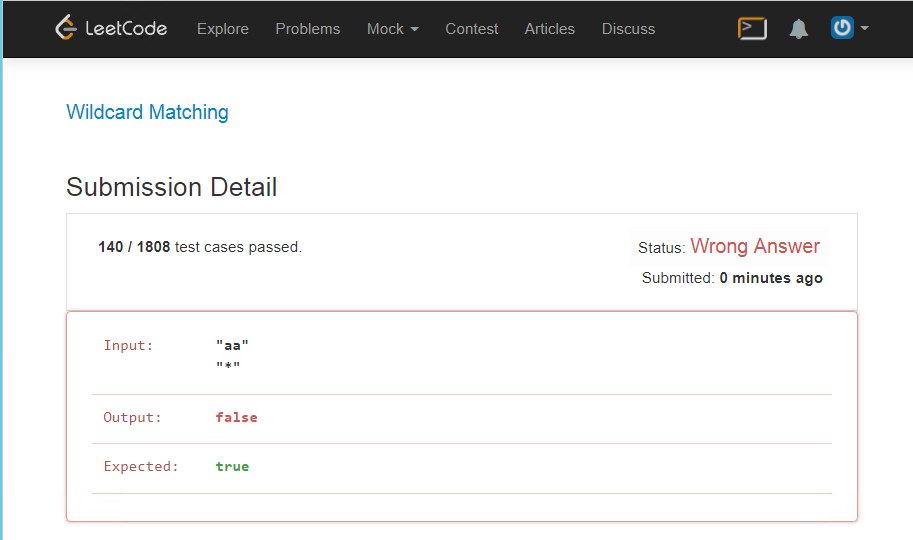
Сложно
Похоже это задание специально так обложили тестами, чтобы именно те кто захочет применять регулярные выражения получил побольше сложностей, у меня до этого решения, логических ошибок в программе не было, а тут надо учесть так много всего.
Значит так — регулярное выражение матчится и первый же результат должен равняться нашей строке.
Победа?
Не просто было заставить его использовать регулярное выражение, но попытка не удалась, не такое это и простое решение химичить регулярки. Решение поиском в ширину срабатывало быстрее.
Вот такая реализация,
import re
def isMatch(s,p):
res=re.match(pat_format(p),s)
if res is None: return False
else: return res.group(0)==s
def pat_format(pat):
res=""
for ch in pat:
if ch=='*':res+="(.)*"
else:
if ch=='?':res+="."
else:res+=ch
return resприводит к вот этому:
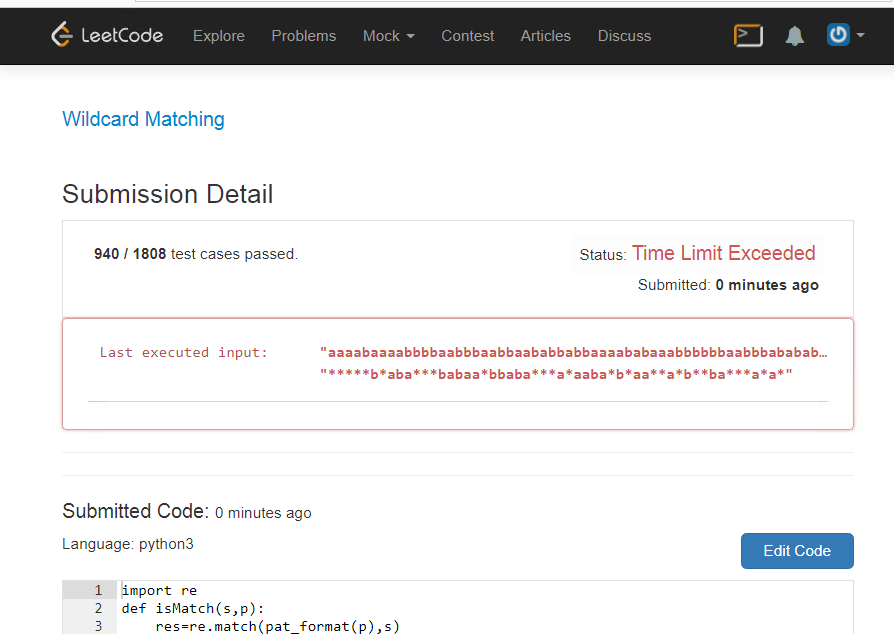
Обращение
Дорогие жители, попробуйте проверить вот это, и это делает питон три, он не может быстро выполнить вот такое задание:
import re
def isMatch(s,p):
res=re.match(pat_format(p),s)
if res is None: return False
else: return res[0]==s
def pat_format(pat):
res=""
for ch in pat:
if ch=='*':res+="(.)*"
else:
if ch=='?':res+="."
else:res+=ch
return res
##test 940
import time
pt=time.time()
print(isMatch("aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba","*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*"))
print(time.time()-pt)Можно попробовать дома. Чудеса, оно не просто долго решается, оно зависает, оооо.
Регулярные выражения как подмножество декларативного взгляда хромают производительностью?
Странно утверждение, они же присутствуют во всех модных языках, значит производительность должна быть ого, а тут совсем не реально, что в них там не конечный автомат?, что там за бесконечный цикл происходит??
Го
Я читал в одной книге, но это было давно… новейший язык Го работает очень быстро, а как там с регулярным выражением?
Испытаю-ка и его:
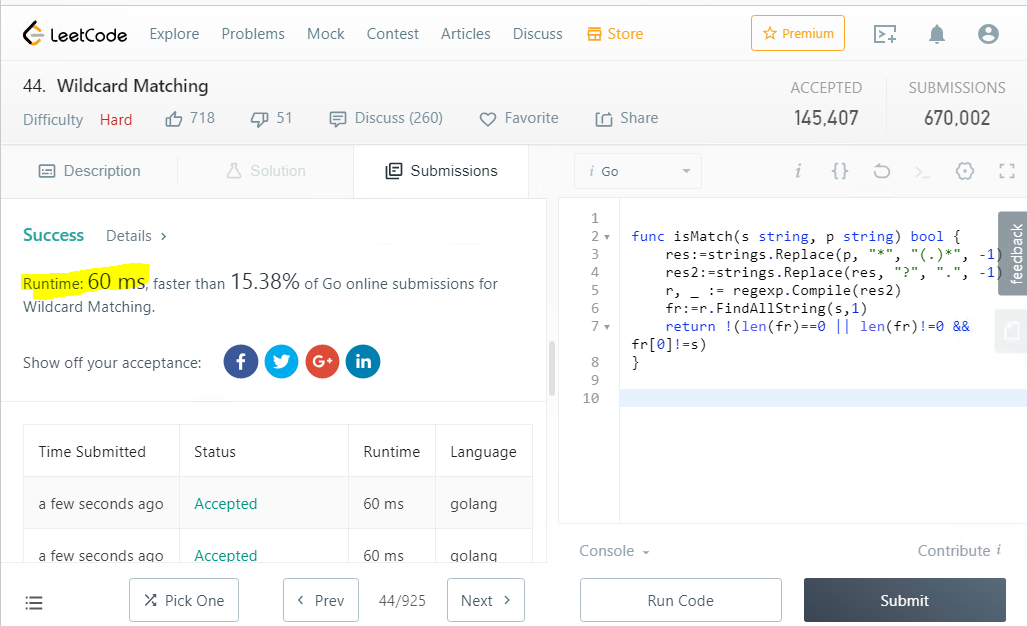
func isMatch(s string, p string) bool {
res:=strings.Replace(p, "*", "(.)*", -1)
res2:=strings.Replace(res, "?", ".", -1)
r, _ := regexp.Compile(res2)
fr:=r.FindAllString(s,1)
return !(len(fr)==0 || len(fr)!=0 && fr[0]!=s)
}Признаюсь, не просто было получить такой лаконичный текст, там синтаксис не тривиален, даже со знанием си, разобраться не просто...
Это замечательный результат, скорость действительно зашкаливает, итого ~60 милисек, но удивительно, что это решение быстрее только 15% ответов на этом же сайте.
А где Пролог
Найду, что нам предоставляет этот забытый язык для работы с регулярными выражениями, есть библиотека на базе Perl Compatible Regular Expression.
Вот так это можно реализовать, но предварительно обработать строку шаблона отдельным предикатом.
pat([],[]).
pat(['*'|T],['.*'|Tpat]):-pat(T,Tpat),!.
pat(['?'|T],['.'|Tpat]):-pat(T,Tpat),!.
pat([Ch|T],[Ch|Tpat]):-pat(T,Tpat).
isMatch(S,P):-
atom_chars(P,Pstr),pat(Pstr,PatStr),!,
atomics_to_string(PatStr,Pat),
term_string(S,Str),
re_matchsub(Pat, Str, re_match{0:Str},[bol(true),anchored(true)]).
И время выполнения отлично:
isMatch(aa,a)->ok:0.08794403076171875/sec
isMatch(aa,*)->ok:0.0/sec
isMatch(cb,?a)->ok:0.0/sec
isMatch(adceb,*a*b)->ok:0.0/sec
isMatch(acdcb,a*c?b)->ok:0.0/sec
isMatch(aab,c*a*b)->ok:0.0/sec
isMatch(mississippi,m??*ss*?i*pi)->ok:0.0/sec
isMatch(abefcdgiescdfimde,ab*cd?i*de)->ok:0.0/sec
isMatch(zacabz,*a?b*)->ok:0.0/sec
isMatch(leetcode,*e*t?d*)->ok:0.0009980201721191406/sec
isMatch(aaaa,***a)->ok:0.0/sec
isMatch(b,*?*?*)->ok:0.0/sec
isMatch(aaabababaaabaababbbaaaabbbbbbabbbbabbbabbaabbababab,*ab***ba**b*b*aaab*b)->ok:0.26383304595947266/sec
isMatch(abbbbbbbaabbabaabaa,*****a*ab)->ok:0.0009961128234863281/sec
isMatch(babaaababaabababbbbbbaabaabbabababbaababbaaabbbaaab,***bba**a*bbba**aab**b)->ok:0.20287489891052246/secНО, есть какие-то ограничения, очередной тест вывел:
Not enough resources: match_limit
Goal (directive) failed: user:assert_are_equal(isMatch(aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba,'*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*'),false)Как вывод
Итого остались только вопросы. Можно реализовать все, но скорость хромает.
Прозрачные решения не бывают эффективны?
Декларативные регулярные выражения кто-то реализовал, что там за механизмы?
И как вам такие вызовы, есть задача, которую можно решать, а где оно идеальное решение?
Комментарии (31)

Rast1234
29.10.2018 08:14+1Регулярные выражения только в самом простом варианте эквивалентны FSM, не помню где там грань проходит, но нежадные квантификаторы уже добавляют backtracking и это может привксти к очень долгой работе. Да и регулярные выражения это не декларативный подход, просто мини-язык.
gdt
29.10.2018 08:19Да, ничего не скажу про PCRE, но в регулярках .Net точно используются недетерминированные конечные автоматы в сложных случаях, может быть даже с магазином
go-prolog Автор
29.10.2018 12:16По моему, это язык, но не императивный, это не команды или инструкции,
это описание задачи, которую нужно решать, отсюда и производительность может хромать, посмотрите как пример с Го летает
AI-Vadim
29.10.2018 12:12import re import time def isMatch(s, p): m = re.match(pat_format(p), s) if not m: return False else: return m.group() == s def pat_format(pat): pat = re.sub("[*]{2,}", "*", pat) pat = re.sub("[?]", ".", pat) pat = re.sub("[*]", "(.)*", pat) return pat pt=time.time() print(isMatch("aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba","*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*")) print(time.time()-pt)go-prolog Автор
29.10.2018 12:13Спасибо, такой вариант уже опробовали,
Не проходит тест далее:
1708 / 1808 test cases passed.
Status: Time Limit Exceeded
Submitted: 0 minutes ago
Last executed input:
«abbabaaabbabbaababbabbbbbabbbabbbabaaaaababababbbabababaabbababaabbbbbbaaaabababbbaabbbbaabbbbababababbaabbaababaabbbababababbbbaaabbbbbabaaaabbababbbbaababaabbababbbbbababbbabaaaaaaaabbbbbaabaaababaaaabb»
"**aa*****ba*a*bb**aa*ab****a*aaaaaa***a*aaaa**bbabb*b*b**aaaaaaaaa*a********ba*bbb***a*ba*bb*bb**a*b*bb"AI-Vadim
29.10.2018 12:37Приведенная строка — это полный текст поиска?
В нем нет сочетания такого большого количества `aaaaaaaaa`.
Дополнительный вопрос: данные в группировках нужны? Они замедляют работу в ~2.5 раза.
Можно заменить:
def pat_format(pat): pat = re.sub("\*{2,}", "*", pat) pat = re.sub("\?", ".", pat) pat = re.sub("\*", ".*", pat) return patAI-Vadim
29.10.2018 13:17Поправка, нашел весь текст в исходном коде.
Просто не отображается вся строка в тексте комментария по длине.go-prolog Автор
29.10.2018 13:22Тестировать надо на самом сайте, вот тут leetcode.com/problems/wildcard-matching
AI-Vadim
29.10.2018 14:30+1
AI-Vadim
30.10.2018 10:29Нашел решение с использованием регулярных выражений, но в комбинации с разбиением исходного выражения по `*` и отсечением исходной строки по каждому из них.
class Solution: start_p = re.compile("\*+") q_p = re.compile("\?") def isMatch(self, s: str, p: str): test_s = s pattern_list = list(filter(None, self.pat_format(p).replace('.*?', '\n.*?').split('\n'))) pattern_len = len(pattern_list) last_index = pattern_len - 1 for index, pattern in enumerate(pattern_list): if index == last_index: pattern = pattern + '$' m = re.match(pattern, test_s) if not m: return False test_s = test_s[m.span()[1]:] return not bool(test_s) def pat_format(self, pat: str): pat = self.q_p.sub(".", pat) pat = self.start_p.sub(".*?", pat) return pat
Вроде получился неплохой результат, лучший прогон: 108 Runtime (ms), 0,11% Distribution.
parserpro
30.10.2018 19:23+1В Python версии проблема в катастрофическом откате. Надо бы паттерн "(.)*" заменить на ".*+" — сверхжадный квантификатор. Вот только пайтона у меня нет чтобы проверить, на перле это работает.
Если интересны подробности — habr.com/post/56765go-prolog Автор
30.10.2018 19:37можно поиграть вот тут, в онлайне leetcode.com/problems/wildcard-matching
datacompboy
30.10.2018 22:53«sre_constants.error: multiple repeat»
а если в скобки завернуть (.*)+ — «Time Limit Exceeded» еще раньше
re не поддерживает их (regex да, но он недоступен).
можно поиграться с negative lookahead's чтоб избавиться от отката назад.
AI-Vadim выше реализовал их отдельными запросами, что не совсем спортивно :D
datacompboy
вместо `(.)*` взять `(?:.)*?` — пробовали уже?
datacompboy
Не, даже если сколлапсить повторяющиеся звезды, всё равно таймаут:
datacompboy
А для Го эта оптимизация работает:
Хм. сперва нарисовало 40ms, потом 68ms, то есть времена нестабильны.
ZyXI
Мне интересно, а зачем вам вообще какая?либо группировка?
*применяется к предыдущему атому, точка — сама по себе атом. Поэтому.*должно нормально зайти. Если добавить?, то такое решение выдаёт превышение time limit (на моей системе — 8,7 секунд) значительно позже, на тесте 1614:datacompboy
Мм… у меня вне зависимости от скобочек вылетает на 1708 / 1808.
коллапс множества звездочек помогает (снижает бэктрэкинг).
go-prolog Автор
Спасибо, действительно убрать повторяющиеся звездочки и указать начало с конец строки это правильно.
ZyXI
Строго говоря, начало строки можно не указывать из?за
match. Вот конец указать нужно, если ответы как?то принимаются без него, то что?то с тестами не так.go-prolog Автор
Все правильно, я сверял первый матч с входной строкой, а указав строго начало конец это и не требуется
go-prolog Автор
Да, времена не повторяются, под виртуалкой, надо несколько раз пробовать,
как вывод — Питон неожиданно медленный…
datacompboy
А я не помню, разве re на питоне написан, это не C++ модуль?
ZyXI
Кстати, что с жадным, что с нежадным, и в обоих случаях максимально оптимизированном регулярным выражением Python виснет на тесте 1708, хотя тест 1614 уже на моей машине проходит за примерно 0,2 мс независимо от жадности. Вот, собственно, код:
(Для нежадной версии убейте второй вопросительный знак, их здесь всего два.) Я не думаю, что можно сделать что?то лучше на регулярных выражениях. Вот, кстати, что мой код генерирует для данного теста:
^.{0,}?aa.{0,}?ba.{0,}?a.{0,}?bb.{0,}?aa.{0,}?ab.{0,}?a.{0,}?aaaaaa.{0,}?a.{0,}?aaaa.{0,}?bbabb.{0,}?b.{0,}?b.{0,}?aaaaaaaaa.{0,}?a.{0,}?ba.{0,}?bbb.{0,}?a.{0,}?ba.{0,}?bb.{0,}?bb.{0,}?a.{0,}?b.{0,}?bb$datacompboy
Да, коллапс вопросов мало поможет в этом тесте, их тут нет :))
а чем `.{0,}?` лучше по сравнению с `.*?`?
ZyXI
Тем, что мне не нужно писать отдельный код для обработки случая
[MANY, 0](и[MANY, 1], которое.+?). Компилятор Python re всё равно должен скомпилировать оба варианта в один и тот же автомат.