
Время течет и скоро от этой разработки почти ничего не останется, а у меня все никак не находилось времени ее описать.
Речь пойдет о компании федерального уровня с большим числом филиалов и подфилиалов. Но, как обычно, все началось давным-давно с одного маленького магазина. С течением лет шло достаточно быстрое и стихийное развитие, появлялись филиалы, подразделения и прочие офисы, а ИТ-инфраструктуре не уделялось в те времена должного внимания, и это тоже частое явление. Конечно же, везде использовалась 1С77, без задела на какие-либо репликации и масштабирование, поэтому, сами понимаете, в конце пришли к тому, что был порожден спрут-франкенштейн с примотанными изолентой щупальцами — в каждом филиале автономный мутант, который с центральной базой обменивался в «наколеночном» режиме лишь несколькими справочниками, без которых ну вообще никак было нельзя, а остальное автономно. Какое-то время довольствовались копиями (десятки их!) филиальных баз в центральном офисе, но данные в них отставали на несколько дней.
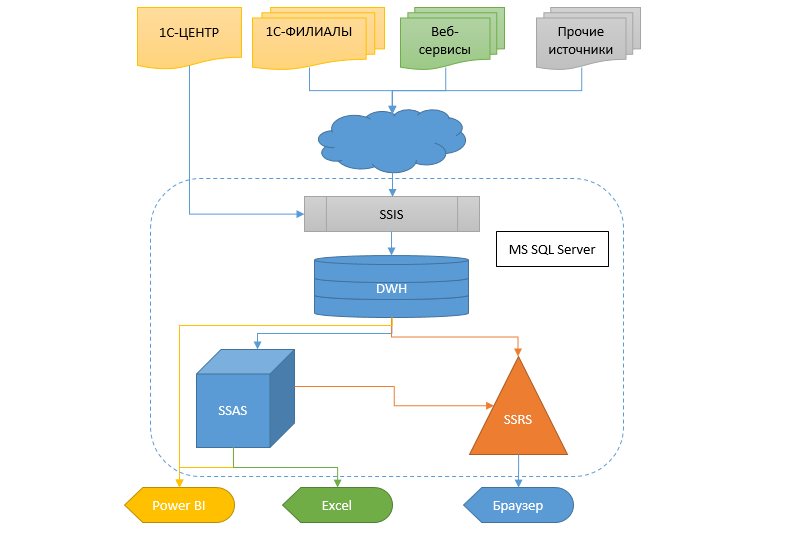
Реальность же требует получать информацию более оперативно и гибко, а еще надо что-то с этим делать. Пересесть с одной учетной системы на другую при таких масштабах — то еще болото. Поэтому было решено сделать хранилище данных (ДХ), в которое стекалась бы информация из разных баз, чтобы впоследствии из этого ХД могли получать данные другие сервисы и аналитическая система в виде кубов, SSRS отчетов и протча.
Забегая вперед скажу, что переход на новую учетную систему почти уже случился и бОльшая часть проекта, описываемого здесь, будет выпилена в ближайшее время за ненадобностью. Жаль, конечно, но ничего не поделаешь.
Далее следует длинная статья, но прежде чем начнете читать, позвольте заметить, что ни в коем случае не выдаю это решение за эталон, однако может кто-то найдет для себя в ней что-то полезное.
Начну с общего подхода к проекту, для которого в качестве среды разработки был выбран SSDT, с последующей публикацией проекта в Git. Думаю, на сегодняшний день существует достаточно всевозможных статей и туториалов, описывающих сильные стороны этого инструмента. Но есть несколько моментов, проблема которых лежит за пределами данной среды.
Касаемо версий и перечислений требования к проекту подразумевали:
Т.к. перечисления часто хранят в себе логику и являются базовыми значениями, без которых добавление записей в другие таблицы становится невозможным (из-за внешних ключей FK), то по сути они являются частью структуры БД, наряду с метаданными. Поэтому изменение любого элемента перечисления ведет к инкременту версии БД и вместе с этой версией должны гарантированно обновиться записи при развертывании.
Думаю, все плюсы блокировки развертывания без инкремента версии очевидны, одним из которых которых является невозможность повторного запуска скрипта публикации, если он уже был выполнен успешно ранее.
Хотя в сети для баз данных часто предлагается использовать только мажорную версию (без дробей), мы решили использовать версии в формате X.Y, где Y — патч, когда была исправлена опечатка в описании таблицы, столбца, наименовании элемента перечисления или еще что-то мелкое, типа добавления комментария в хранимую процедуру и т.д. Во всех остальных случаях наращивается мажорная версия.
Быть может, для кого-то в этом нет ничего такого и все очевидно. Но у меня, в свое время, ушло не мало нервов и сил на внутренние споры о том, как хранить перечисления в проекте базы данных, чтобы это было по феншую (в соответствии с моим представлением о нём) и чтобы удобно было работать с ними, одновременно минимизировав вероятность ошибок.
С перечислениями, в целом, все просто — создаем в проекте файлик PostDeploy и пишем в нем код для заполнения таблиц. С мерджами или транкейтами — это кому как нравится. Мы предпочли мерджить, предварительно проверяя, не превышает ли число записей в целевой таблице то число записей, что находится в источнике (проекте). Если превышает, то вызывается исключение, чтобы обратить на это внимание, ибо странно. Почему в источнике меньше записей? Потому что одна лишняя? С чего вдруг? А если в БД уже есть ссылки на нее? Хоть у нас и используются внешние ключи (FK), которые не позволят удалить запись, если на нее есть ссылки, все же предпочли оставить такой вариант. В результате PostDeploy превратился в нечитаемую простыню, ибо для каждой заполняемой таблицы, помимо самих значений, есть еще и проверочный код, мердж и прочее.
Однако если использовать PostDeploy в режиме SQLCMD, то появляется возможность вынести блоки кода в отдельные файлы, в результате для заполнения перечислений в PostDeploy остался только структурированный список имен файлов.
С версиями БД есть нюансы. В интернетах давно ведутся споры по поводу того, где хранить версию базы данных, как она должна выглядеть, и вообще, нужно ли ее где-то хранить? Допустим, мы решили, что она нам нужна, в каком месте проекта ее хранить? Где-то в дебрях скрипта PostDeploy или вынести ее в переменную, которая объявлена в первой строке скрипта?
На мой взгляд, — ни то, ни другое. Удобнее, когда она хранится в отдельном файле и больше там ничего нет.
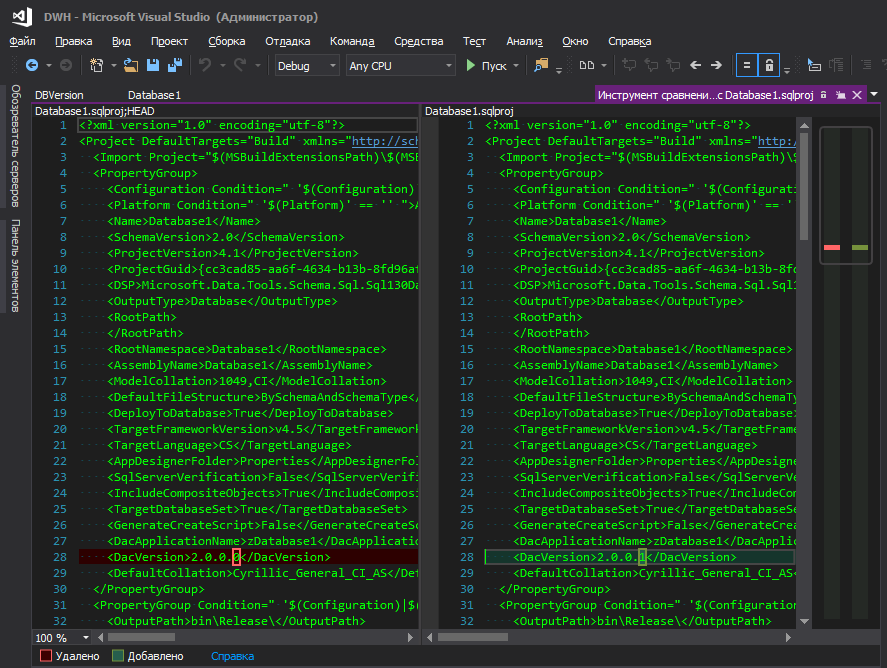
Кто-то скажет — в свойствах проекта есть же dacpac и в нем можно задать версию. Безусловно, можно даже подтягивать эту версию в свой скрипт, как описано здесь, но это неудобно — чтобы изменить версию БД, нужно пойти куда-то далеко, нажать кучу кнопок. Не понимаю логику микрасофта — они спрятали это в далекий угол наряду с такими параметрами БД, как сортировка, уровень совместимости и прочее, ведь версия базы данных меняется так же «часто», как и параметры сортировки, правда? Когда идет постоянная разработка, версия наращивается с каждым новым деплоем, ну и удобство отслеживания изменений тоже играет немаловажную роль, ведь когда светится измененный файл с понятным именем — это одно, а когда светится файл проекта .sqlproj, в котором множество строк в XML-формате, и среди них где-то в центре строки выделена одна измененная циферка, то как-то не очень.
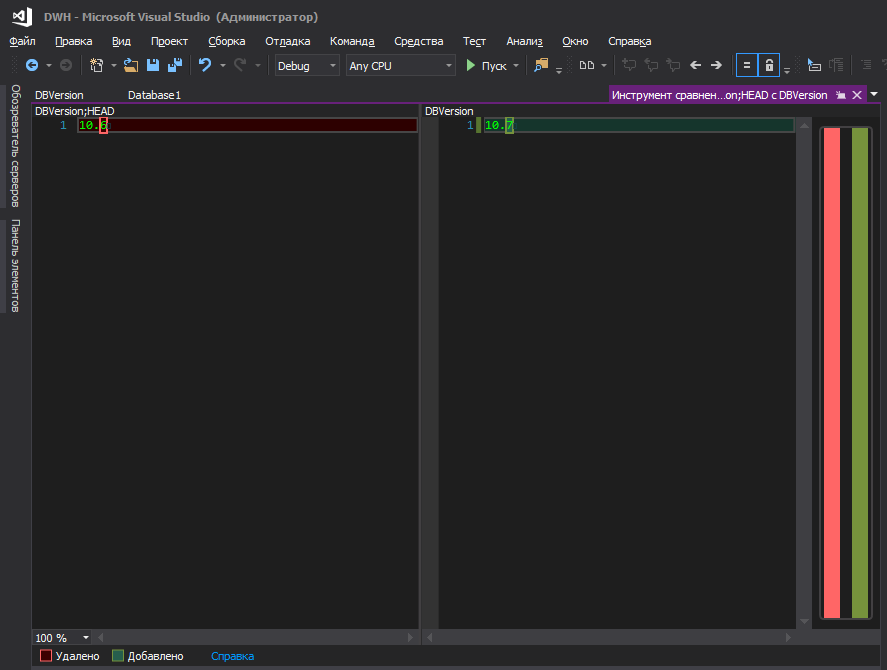
Так лучше
Впрочем, возможно, это только мои тараканы и не стоит обращать на них внимания.
Теперь вопрос: где хранить эту версию уже в развернутой БД. Опять же, вроде бы dacpac делает это красиво — пишет всё в системные таблички, но чтобы посмотреть версию, нужно выполнить запрос (или можно иначе, а я просто не умею их готовить? кажется, в старых версиях SSMS был интерфейс для этого, а сейчас нет)
для администратора (и не только) это не очень удобно. Куда логичнее, чтобы версия отображалась бы прямо в свойствах самой БД.

Или нет?
Для этого в проект нужно добавить файл, включенный в построение, описывающий расширенные свойства
Да, они пустые, и это некрасиво смотрится в скрипте публикации, но без них нельзя. Если их не описать в проекте, а в БД они будут, то студия каждый раз при развертывании будет пытаться их удалить. (Было немало попыток обойти это лаконично и без лишних опций при развертывании, но безрезультатно)
Значения для них будем устанавливать в скрипте PostDeploy.
Выполняем
Ну, и историю было бы неплохо хранить, на предмет кто и когда разворачивал БД.
Развертывание изменений метаданных можно выполнять в транзакции штатными средствами, установив флажок Включить скрипты транзакций в окне Дополнительные параметры публикации. Но этот флажок не влияет на скрипты (Pre/Post)deploy и они продолжают выполняться без транзакции. Конечно, ничто не мешает в начале скрипта PostDeploy запустить транзакцию, однако это будет отдельная от метаданных транзакция, а у нас задача откатить изменения метаданных, если в PostDeploy произошло исключение.
Решение простое — начать транзакцию в PreDeploy, а зафиксировать в PostDeploy, и не использовать для этих целей никаких галочек в параметрах публикации.
Чтобы версию БД было удобно хранить в проекте и чтобы она прописывалась в желаемые места при развертывании, можно прибегнуть к переменным SQLCMD. Однако не хочется хранить версию где-то в дебрях кода, хочется чтобы она была на поверхности.
Чтобы на уровне проекта поместить версию базы в отдельный файл и управлять версией оттуда, добавим в .sqlproj следующий блок:
Это инструкция для MSBuild перед построением считать строку из файла и создать временный файл на основе считанных данных. MSBuild создаст временный файл
После таких манипуляций можно ссылаться на этот временный файл из скрипта PreDeploy и в нем же начнем глобальную транзакцию:
Файлы
При развертывании
В идеале, конечно, хотелось бы, чтобы версия отображалась в момент публикации

Но не получается подтянуть в это окно значение из файла, хотя MSBuild его считывает и помещает в свойство ExtDBVersion с помощью дополнительных инструкций в файле .sqlproj, как в примере выше, но конструкция
не прокатывает.
Разработчики сиквела в своем вэбдневничке пишут, как это делается. По их версии, магия заключается в инструкции
и готово. Хорошая попытка, но нет. Быть может, когда была опубликована эта запись в блог, все работало, но с тех пор в этих ваших америках успели трижды пройти выборы президента и никто не знает, какая инструкция может перестать работать завтра.

А здесь один товарищ перепробовал все варианты, но ни один из них не взлетел.
Поэтому либо брать версию из dacpac, либо хранить ее в PostDeploy, либо в отдельном файле, либо _________ (вписать свой вариант).
Первая проблема заключалась в том, что у 1С77 нет никакого сервера приложений или другого дЕмона, позволяющего взаимодействовать с ней без запуска платформы. Кто работал с 1С77 -знает, что у нее нет полноценного консольного режима. Можно запустить платформу с параметрами и даже что-то выполнить на их основе, но консольных параметров очень мало и цель их была в другом. Но даже с их помощью можно наколхозить целый комбайн. Однако она может непредсказуемо вылететь, может вывести модальное окно и ждать, пока кто-то нажмет ОК и прочие прелести. И, пожалуй, самая большая проблема — скорость работы платформы оставляет желать… Поэтому решение тут только одно — прямые запросы в БД 1С. Учитывая структуру, нельзя просто так взять и написать эти запросы, но благо — есть целое сообщество, которое в свое время разработало прекрасный инструмент — 1C++ (1cpp.dll), невероятное им за это СПАСИБО! Библиотека позволяет писать запросы в терминах 1С, которые далее превращаются в реальные имена таблиц и полей. Если кто не знает, то запрос можно написать с использованием псевдоимен и выглядеть он будет так
Такой запрос понятен человеку, но на сервере нет такой таблицы и поля, там другие имена, поэтому 1С++ превратит его в
и такой запрос уже понятен серверу. Все довольны, никто не ругается — ни человек, ни сервер. Тут вроде бы вопрос решен.
Вторая проблема лежала в плоскости конфигураций: в филиалах использовалась одна конфигурация, в центральном офисе другая, а в подфилиалах — третья! Класс?!!1 Я тоже так думаю. Причем все они не типовые и даже не наследие типовых, а полностью написанные с нуля во времена викингов и, к сожалению, фундамент этих конф закладывали не самые лучшие архитекторы… Документ Реализация, например, в каждой конфигурации имеет разный набор реквизитов. Но отличаются не только названия некоторых полей, куда веселее, когда названия реквизитов одинаковые, но смысл хранящихся в них данных — РАЗНЫЙ.

В конфигурациях почти не используются регистры, всё построено на хитросплетениях документов. Поэтому иной раз приходилось писать целую простыню на чистом транзакте, с кучей кейсов и джойнов, чтобы повторить логику какой-то процедуры из конфигурации, выводящей в текстовое поле на форме некую информацию.
Надо отдать должное команде разработчиков, которые все эти годы поддерживали то, что им досталось в наследство от «внедренцев», это огромный труд — поддерживать такое и даже что-то оптимизировать. Пока не увидишь — не поймешь, я сам сначала не верил, что все может быть настолько сложно. Спросите — почему бы не переписать с нуля? Банальная нехватка ресурсов. Компания развивалась так быстро, что, несмотря на большую команду программистов, они просто не успевали за потребностями бизнеса, не говоря уже о переписывании всей концепции.
Продолжим повесть о запросах. Очевидно, что все блоки по извлечению данных оборачивались в хранимки, чтобы впоследствии их можно было запускать на стороне сервера минуя платформу 1С. Правило было такое: одна хранимка отвечает за извлечение одной сущности. Т.к. хотелок на этапе старта накопилось уже много, ибо наболело за годы, то хранимок получилось несколько десятков.
Третья проблема — как повысить скорость и качество разработки, и как всё это чудовище потом поддерживать? Писать запрос на 1С++ и копипастить результат его конвертации в хранимку? Очень неудобно и нудно, к тому же велика вероятность ошибок — скопировать не то и не туда или не выделить последнюю строчку запроса и скопировать без нее. Это особенно актуально, когда речь идет о прямых запросах 1С, ведь там не видно псевдоимен типа Справочник.Номенклатура.Артикул, только реальные имена SC2235.SP5278 и поэтому закопипастить запрос из под справочника товаров в хранимку, извлекающую клиентов, очень просто. Конечно, запрос, скорее всего, свалится, из-за несоответствия типов и количества полей в таблице-приемнике, но есть и идентичные таблички, типа перечислений, где только две колонки — ИД и Наименование. В общем, тут остается только применять какую-то автоматизацию. Ну, хватит лирики, давайте к делу!
Хотелось, чтобы процесс разработки хранимок сводился к примерно таким действиям:
Для решения третьей проблемы была написана внешняя обработка (.ert). В обработке есть ряд процедур, каждая из которых содержит текст запроса для извлечения одной сущности с использованием псевдоимен, типа
На форме обработки есть поле для вывода результата работы той или иной процедуры, т.е. запроса, преобразованного в понятный для сервера вид, чтобы можно было его быстро испробовать в деле. Плюс к этому запросу всегда добавляется отладочный блок, с объявлением переменных, именами тестовых БД, серверов и прочее. Остается только скопипастить в SSMS и нажать F5. Можно, конечно, выполнить этот запрос и из самой обработки, но план запроса и все такое, ну вы поняли… В общем, так производится отладка. Т.к. конфигураций несколько, в обработке предусмотрена возможность конвертировать одни и те же тексты запросов с псевдоименами объектов в конечные запросы для разных конфигураций. Ведь в одной конфе справочник Номенклатура это SC123, а в другой — SC321. Но 1С++ позволяет в рантайме подгружать в себя разные конфы и для каждой из них генерировать индивидуальный вывод в соответствии со словарем.
Далее в обработку был добавлен режим пакетного запуска, когда она автоматически запускает каждую из процедур для каждой конфигурации, а вывод каждой из них записывает в файлы .sql (далее базовые файлы). Таким образом мы получаем кучу комбинаций базовых файлов, которые впоследствии должны автоматически превратиться в хранимые процедуры средствами VS. Стоит отметить, что базовые файлы включают в себя и блок отладки.
Казалось бы, почему не сделать вывод сразу в конечные файлы хранимых процедур и держать всё в этой обработке? Дело в том, что для некоторых тестов необходимо пакетно запускать именно отладочные версии запросов, в которых объявлены все переменные, плюс хотелось, чтобы именами хранимых процедур можно было управлять из VS, минуя запуск 1С, ведь это логично, не так ли?
Кстати, базовые файлы тоже хранятся в проекте, ну, и файлы готовых хранимых процедур, конечно же. В любой момент, не запуская 1С, можно открыть базовый файл в SSMS и выполнить его, не заморачиваясь с объявлением переменных.
В обработке все процедуры с запросами тоже шаблонные, имеющие одинаковый набор параметров, но в той или иной процедуре используются только необходимые параметры. В некоторых задействовано всё, а в некоторых достаточно и двух. Поэтому добавление новой процедуры сводится к копированию шаблона и заполнению параметров самими запросами.
Код одной из процедур обработки, которая после превратится в хранимую процедуру
Конечный запрос собирается примерно так:
Внешний вид обработки

При переключении конфигураций меняется и список доступных (необходимых) для выгрузки элементов в списке Данные. По возможности, код процедур в 1С максимально унифицировался. Если извлекаются контрагенты и в разных конфигурациях эти справочники имеют нестыковки, то внутри процедуры генерации есть разные кейсы, типа: этот блок фиксированный для всех, вот этот только для такой конфы добавляется в конечный запрос, а вон тот — для другой. Получается, что в хранимые процедуры для одной сущности но разных конфигураций могут отличаться не только именами таблиц, но целыми блоками джойнов, присутствующих в одной и отсутствующих в другой. Набор выходных полей, конечно же, одинаковый и соответствует таблице-приемнику или контейнеру SSIS пакета, какие-то поля забиваются заглушками для конфигураций, в которых этих реквизитов нет в принципе.
Волшебная кнопочка
В Visual Studio есть такие инструменты, как MSbuild и совершенно замечательные шаблоны T4. Поэтому в качестве волшебной кнопки был написан скрипт на C# для T4, который:
Перед созданием хранимок скрипт T4 извлекает из базовых файлов тексты запросов регуляркой, чтобы исключить отладочные куски (ориентируется на специальную метку, обозначающую конец отладочного блока) и оборачивает в единый унифицированный шаблон хранимой процедуры. Во всех хранимках одинаковый набор параметров, но в той или иной процедуре используются только необходимые параметры. Список сопоставления имен базовых файлов и имен хранимых процедур, в которые они должны превратиться, выполнены в проекте в виде отдельного файла, чтобы было удобно с этим работать, не разыскивая в портянке кода нужную строчку и опять-таки — минуя запуск 1С.
Также хотелось, чтобы разработчик, впервые присоединившийся к проекту, мог без проблем писать запросы и конвертировать их, не забивая себе голову необходимостью регистрации пустой конфигурации, развертывания пустой базы данных и прочих неприятных и нудных мелочей. Поэтому в проекте хранится всё — необходимые конфигурации 1С, скрипты для корректной работы 1С, сама обработка-конвертер и прочие файлы.
В результате сценарий действий разработчика такой: Нужна новая хранимка или нужно исправить существующую?
На выходе получаем измененный файл модуля и формы обработки, новый базовый файл и саму хранимку. Студия прекрасно подсвечивает все измененные строки. Много, конечно, ушло времени на все эти красоты, чтобы обработка не пересоздавала базовые файлы, если в коде обработки ничего не изменилось, а то они светились как измененные (потому что дата файла изменилась), но при построчном сравнении нет разницы. Кстати, в базовый файл (в ту его часть, которая впоследствии уйдет в хранимую процедуру) записывается комментарий, с информацией о дате и времени генерации файла, версии конфигурации, на основе которой он был создан и кто это выполнял. Поэтому в любой хранимой процедуре всегда можно увидеть кто генерировал код, находящийся в ней. Обработка, перед перезаписью существующего базового файла, сверяет его полезный текст с тем, который планируется в него записать, если отличий нет, то файл остается нетронутым (это все ради того, чтобы не было ложных подсвечиваний изменений при изменении конфигурации 1С, например, когда изменилась версия MD файла).
Еще пришлось помучиться с текстами запросов, потому что они выполняются к удаленным серверам через OPENQUERY, а имена баз данных 1С в филиалах отличаются, как отличаются и имена серверов, поэтому текст запроса собирается динамически из строки, с подстановкой этих значений из параметров хранимки, помещается в переменную и запускается в конце через EXEC. OPENQUERY изначально заточен выполнять строку, поэтому уже получается строка в строке, кавычка в кавычке, экранирование и прочее.
И 1С77 (в базовом исполнении) функционирует на SQL2000, а там varchar(max) не работает, максимум varchar(8000), а общий текст запроса 9к, например… Значит, надо определить уже две переменные и выполнить их в EXEC(@SQL1+@SQL2). Не смотря на то, что процедуры хранятся и выполняются на SQL2016, их части проверялись на SQL2000. Руками переменные определять не хотелось, хотелось минимизировать число ненужных телодвижений, чтобы все было автоматически.
Как видно из кода — хранимая процедура не имеет форматирования. При создании базового файла всё форматирование (пробелы, табуляции) слева и справа, которые были в оригинале запроса с псевдоименами, удаляется, ведь серверу плевать на форматирование, а для экономии имеет прямой смысл, ибо переменных можно наплодить сколько угодно, а у OPENQUERY лимит 8к символов.
.ert обработка определяет длину конечного запроса с учетом удаленного форматирования и вычисляет количество переменных, в которое все это должно разместиться и т.д. В общем, много крови выпила эта обработка.
Вручную никаких изменений в сами хранимые процедуры никогда не вносится, только через исправление обработки.
Пожалуй, в этой части нет ничего особенного (на мой взгляд). Классическая схема с промежуточной БД (Stage). Можно лишь отметить, что ETL реализована с помощью SSIS пакетов, которые, в свою очередь, выполняют те самые хранимые процедуры, о которых говорилось в предыдущем разделе. Есть основной пакет и несколько дочерних. Для возможности многопоточного выполнения основной пакет параллельно запускает несколько экземпляров одного и того же дочернего пакета с разными параметрами (для разных филиалов), в результате удается получить данные от связанных серверов за максимально короткий период.
Если в процессе получения данных один или несколько экземпляров дочернего пакета не смогли подключиться к удаленным серверам, то список таких серверов (с неудачной попыткой подключения) запоминается, а после того, как закончится выполнение всех потоков дочерних пакетов (т.е. через несколько минут), основной пакет вновь запускает потоки для серверов из списка с неудачной попыткой, пытаясь таки достучаться и ему это иногда удается.
Если не удалось получить данные из одного или нескольких филиалов, то это не критическая ошибка, система будет функционировать и без них. Разумеется, пакет уведомляет о таких ситуациях. В нашем случае через zabbix.
Все полученные данные сбрасываются в промежуточную БД из которой уже переливаются в основную.
Т.к. в используемых конфигурациях 1С нет никаких механизмов регистрации изменений, а о событийной интеграции и вспоминать не стоит, приходится каждый раз перезапрашивать данные из всех баз за несколько последних месяцев. Чтобы не тратить время на удаление, используется секционирование таблиц, позволяющее выполнять
Разумеется, со временем главный пакет стал увеличиваться (обрастая дочерними пакетами) и в него добавились взаимодействия с веб-сервисами, различными «не 1С-ными» базами данных и прочими источниками.
Поток управления одного из SSIS пакетов
Один из потоков данных пакета
Для повышения скорости вставки данных в БД через SSIS используйте компонент потока данных Назначение SQL Server (SQL Server Destination), он работает в разы быстрее, чем Назначение OLE DB (OLE DB Destination).
Для повышения скорости отката при сбоях, а вернее для отсутствия необходимости в нем, есть вариант с ротацией БД, когда рядом с основной БД создается копия и начинает пополняться без всяких транзакций. Если пополнение прошло успешно, то копия переименовывается в основную либо остается нетронутой, в случае ошибки. (Разумеется, если на сервере достаточно места)
Никогда не исправляйте вручную данные в БД. Только скриптами и обязательно сохраняйте каждый из них с адекватным именем, датой и комментариями внутри, из которых должно быть понятно кто, когда и на каком основании это делал (ошибка/служебка и прочее).
Делайте блокирующую проверку версии БД внутри таких скриптов и не допускайте выполнение в случае несоответствия версий в скрипте и в БД назначения.
И еще бы я рекомендовал завести в БД специальную таблицу, в которой будет храниться история запусков таких скриптов (из предыдущего абзаца). Т.е. скрипт не только вносит изменения в данные, но и регистрирует факт своего запуска в журнале. Есть смысл не только регистрировать запуск, но и блокировать его повторный запуск в случае, если в журнале уже есть информация о предыдущем выполнении. А если по какой-то причине нужно выполнить тот же скрипт повторно — сделайте его копию и присвойте ему новую дату и номер. Это существенно облегчит жизнь и избавит от лишних претензий при разборе полетов.
В качестве настроек по умолчанию для развертывания установите строки подключения и пути отличные от продуктивных путей и имен, чтобы для публикаций в продуктив нужно было целенаправленно (т.е. осознанно) выбрать конкретную настройку.
Не ленитесь делать всевозможные защиты от дурака, они лишними никогда не бывают, какой бы высокой квалификацией и уровнем ответственности не обладали разработчики.
Я не претендую на истину, каждый решает для себя сам, исходя из своего опыта и предпочтений, полезно ли все то, что было описано. Все примеры — это только примеры, сделанные на скорую руку. Статья писалась несколько месяцев с десятками подходов и большими интервалами из-за нехватки времени, поэтому могут быть некоторые нестыковки в тексте, уж не обижайтесь.
Речь пойдет о компании федерального уровня с большим числом филиалов и подфилиалов. Но, как обычно, все началось давным-давно с одного маленького магазина. С течением лет шло достаточно быстрое и стихийное развитие, появлялись филиалы, подразделения и прочие офисы, а ИТ-инфраструктуре не уделялось в те времена должного внимания, и это тоже частое явление. Конечно же, везде использовалась 1С77, без задела на какие-либо репликации и масштабирование, поэтому, сами понимаете, в конце пришли к тому, что был порожден спрут-франкенштейн с примотанными изолентой щупальцами — в каждом филиале автономный мутант, который с центральной базой обменивался в «наколеночном» режиме лишь несколькими справочниками, без которых ну вообще никак было нельзя, а остальное автономно. Какое-то время довольствовались копиями (десятки их!) филиальных баз в центральном офисе, но данные в них отставали на несколько дней.
Реальность же требует получать информацию более оперативно и гибко, а еще надо что-то с этим делать. Пересесть с одной учетной системы на другую при таких масштабах — то еще болото. Поэтому было решено сделать хранилище данных (ДХ), в которое стекалась бы информация из разных баз, чтобы впоследствии из этого ХД могли получать данные другие сервисы и аналитическая система в виде кубов, SSRS отчетов и протча.
Забегая вперед скажу, что переход на новую учетную систему почти уже случился и бОльшая часть проекта, описываемого здесь, будет выпилена в ближайшее время за ненадобностью. Жаль, конечно, но ничего не поделаешь.
Далее следует длинная статья, но прежде чем начнете читать, позвольте заметить, что ни в коем случае не выдаю это решение за эталон, однако может кто-то найдет для себя в ней что-то полезное.
Начну с общего подхода к проекту, для которого в качестве среды разработки был выбран SSDT, с последующей публикацией проекта в Git. Думаю, на сегодняшний день существует достаточно всевозможных статей и туториалов, описывающих сильные стороны этого инструмента. Но есть несколько моментов, проблема которых лежит за пределами данной среды.
Хранение перечислений и версии БД
Касаемо версий и перечислений требования к проекту подразумевали:
- Удобство редактирования и отслеживания изменений версии БД внутри проекта
- Удобство просмотра версии БД через SSMS для админов
- Сохранение истории изменений версий в самой БД (кто и когда выполнял развертывание)
- Хранение в проекте перечислений (enumerations)
- Удобство редактирования и отслеживания изменений в перечислениях
- Блокировка развертывания БД поверх существующей, если не было инкремента версии
- Установка новой версии, запись истории, перечислений и реструктуризация должны выполняться в одной транзакции и полностью откатываться в случае неудачи на любом из этапов
Т.к. перечисления часто хранят в себе логику и являются базовыми значениями, без которых добавление записей в другие таблицы становится невозможным (из-за внешних ключей FK), то по сути они являются частью структуры БД, наряду с метаданными. Поэтому изменение любого элемента перечисления ведет к инкременту версии БД и вместе с этой версией должны гарантированно обновиться записи при развертывании.
Думаю, все плюсы блокировки развертывания без инкремента версии очевидны, одним из которых которых является невозможность повторного запуска скрипта публикации, если он уже был выполнен успешно ранее.
Хотя в сети для баз данных часто предлагается использовать только мажорную версию (без дробей), мы решили использовать версии в формате X.Y, где Y — патч, когда была исправлена опечатка в описании таблицы, столбца, наименовании элемента перечисления или еще что-то мелкое, типа добавления комментария в хранимую процедуру и т.д. Во всех остальных случаях наращивается мажорная версия.
Быть может, для кого-то в этом нет ничего такого и все очевидно. Но у меня, в свое время, ушло не мало нервов и сил на внутренние споры о том, как хранить перечисления в проекте базы данных, чтобы это было по феншую (в соответствии с моим представлением о нём) и чтобы удобно было работать с ними, одновременно минимизировав вероятность ошибок.
С перечислениями, в целом, все просто — создаем в проекте файлик PostDeploy и пишем в нем код для заполнения таблиц. С мерджами или транкейтами — это кому как нравится. Мы предпочли мерджить, предварительно проверяя, не превышает ли число записей в целевой таблице то число записей, что находится в источнике (проекте). Если превышает, то вызывается исключение, чтобы обратить на это внимание, ибо странно. Почему в источнике меньше записей? Потому что одна лишняя? С чего вдруг? А если в БД уже есть ссылки на нее? Хоть у нас и используются внешние ключи (FK), которые не позволят удалить запись, если на нее есть ссылки, все же предпочли оставить такой вариант. В результате PostDeploy превратился в нечитаемую простыню, ибо для каждой заполняемой таблицы, помимо самих значений, есть еще и проверочный код, мердж и прочее.
Однако если использовать PostDeploy в режиме SQLCMD, то появляется возможность вынести блоки кода в отдельные файлы, в результате для заполнения перечислений в PostDeploy остался только структурированный список имен файлов.
С версиями БД есть нюансы. В интернетах давно ведутся споры по поводу того, где хранить версию базы данных, как она должна выглядеть, и вообще, нужно ли ее где-то хранить? Допустим, мы решили, что она нам нужна, в каком месте проекта ее хранить? Где-то в дебрях скрипта PostDeploy или вынести ее в переменную, которая объявлена в первой строке скрипта?
На мой взгляд, — ни то, ни другое. Удобнее, когда она хранится в отдельном файле и больше там ничего нет.
Кто-то скажет — в свойствах проекта есть же dacpac и в нем можно задать версию. Безусловно, можно даже подтягивать эту версию в свой скрипт, как описано здесь, но это неудобно — чтобы изменить версию БД, нужно пойти куда-то далеко, нажать кучу кнопок. Не понимаю логику микрасофта — они спрятали это в далекий угол наряду с такими параметрами БД, как сортировка, уровень совместимости и прочее, ведь версия базы данных меняется так же «часто», как и параметры сортировки, правда? Когда идет постоянная разработка, версия наращивается с каждым новым деплоем, ну и удобство отслеживания изменений тоже играет немаловажную роль, ведь когда светится измененный файл с понятным именем — это одно, а когда светится файл проекта .sqlproj, в котором множество строк в XML-формате, и среди них где-то в центре строки выделена одна измененная циферка, то как-то не очень.
Так лучше
Впрочем, возможно, это только мои тараканы и не стоит обращать на них внимания.
Теперь вопрос: где хранить эту версию уже в развернутой БД. Опять же, вроде бы dacpac делает это красиво — пишет всё в системные таблички, но чтобы посмотреть версию, нужно выполнить запрос (или можно иначе, а я просто не умею их готовить? кажется, в старых версиях SSMS был интерфейс для этого, а сейчас нет)
select * from msdb.dbo.sysdac_instances_internalдля администратора (и не только) это не очень удобно. Куда логичнее, чтобы версия отображалась бы прямо в свойствах самой БД.
Или нет?
Для этого в проект нужно добавить файл, включенный в построение, описывающий расширенные свойства
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = '';
GO
EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = '';
GO
EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = '';Да, они пустые, и это некрасиво смотрится в скрипте публикации, но без них нельзя. Если их не описать в проекте, а в БД они будут, то студия каждый раз при развертывании будет пытаться их удалить. (Было немало попыток обойти это лаконично и без лишних опций при развертывании, но безрезультатно)
Значения для них будем устанавливать в скрипте PostDeploy.
declare @username varchar(256) = suser_sname()
,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss')
EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username;
EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;Выполняем
sp_updateextendedproperty без всяких проверок, потмоу что к моменту запуска блока из PostDeploy все свойства уже созданы, если их не было.Ну, и историю было бы неплохо хранить, на предмет кто и когда разворачивал БД.
Развертывание изменений метаданных можно выполнять в транзакции штатными средствами, установив флажок Включить скрипты транзакций в окне Дополнительные параметры публикации. Но этот флажок не влияет на скрипты (Pre/Post)deploy и они продолжают выполняться без транзакции. Конечно, ничто не мешает в начале скрипта PostDeploy запустить транзакцию, однако это будет отдельная от метаданных транзакция, а у нас задача откатить изменения метаданных, если в PostDeploy произошло исключение.
Решение простое — начать транзакцию в PreDeploy, а зафиксировать в PostDeploy, и не использовать для этих целей никаких галочек в параметрах публикации.
Чтобы версию БД было удобно хранить в проекте и чтобы она прописывалась в желаемые места при развертывании, можно прибегнуть к переменным SQLCMD. Однако не хочется хранить версию где-то в дебрях кода, хочется чтобы она была на поверхности.
Чтобы на уровне проекта поместить версию базы в отдельный файл и управлять версией оттуда, добавим в .sqlproj следующий блок:
<Target Name="BeforeBuild">
<ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion">
<Output TaskParameter="Lines" PropertyName="ExtDBVersion" />
</ReadLinesFromFile>
<WriteLinesToFile File="$(ProjectDir)\Скрипты\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" />
</Target>
</Target>Это инструкция для MSBuild перед построением считать строку из файла и создать временный файл на основе считанных данных. MSBuild создаст временный файл
SetPreDepVarsTmp.sql, в который пропишет строчку :setvar DBVersion $(ExtDBVersion), где $(ExtDBVersion) — значение, считанное из нашего файла, хранящего версию БД.После таких манипуляций можно ссылаться на этот временный файл из скрипта PreDeploy и в нем же начнем глобальную транзакцию:
:r .\SetPreDepVarsTmp.sql
go
:r ".\BeginTransaction.sql"Промежуточная версия
Первоначально в файле ExtendedProperties.sql присваивались не пустые значения, а значения из переменных
Переменные, в свою очередь, прописывались в файле SetPreDepVarsTmp.sql автоматически MSBuild'ом вот так:
При таком подходе не нужно переустанавливать эти свойства в PostDeploy, но беда в том, что SetPreDepVarsTmp.sql содержал статические значения и если скрипт публикации был сгенерирован сейчас, а развернут через час, или, еще хуже, — на следующий день (разработчик его долго перепроверял визуально, например), то дата публикации, прописанная в свойства, будет отличаться от реальной даты публикации и не совпадать с датой в истории.
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)];
GO
EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)];
GO
EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];Переменные, в свою очередь, прописывались в файле SetPreDepVarsTmp.sql автоматически MSBuild'ом вот так:
<PropertyGroup>
<CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime>
</PropertyGroup>
<PropertyGroup>
<NewLine>
--
</NewLine>
</PropertyGroup>
<Target Name="BeforeBuild">
<ReadLinesFromFile File="$(ProjectDir)\DBVersion">
<Output TaskParameter="Lines" PropertyName="ExtDBVersion" />
</ReadLinesFromFile>
<WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" />
</Target>При таком подходе не нужно переустанавливать эти свойства в PostDeploy, но беда в том, что SetPreDepVarsTmp.sql содержал статические значения и если скрипт публикации был сгенерирован сейчас, а развернут через час, или, еще хуже, — на следующий день (разработчик его долго перепроверял визуально, например), то дата публикации, прописанная в свойства, будет отличаться от реальной даты публикации и не совпадать с датой в истории.
Содержимое файла BeginTransaction.sql
По сути это просто копипаста из стандартного блока запуска транзакции, который генерирует студия при установке флажка Включить скрипты транзакций, но мы используем его по-своему. В скрипте изменено только имя временной таблицы с
#tmpErrors на #tmpErrorsManual, чтобы не было конфликта имен, если кто-то включит флажок.IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE #tmpErrorsManual
GO
CREATE TABLE #tmpErrorsManual (Error int)
GO
SET XACT_ABORT ON
GO
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
GO
BEGIN TRANSACTION
GOСкрипт PostDeploy
Переменная SkipEnumDeploy, как уже стало ясно, позволяет пропустить этап обновления перечислений, это бывает полезно, при мелких косметических правках. Хотя, с точки зрения религии, это может быть и неверно, однако на этапе разработки точно пригождается.
declare @TableName VarChar(255) = null -- переменная содержит имя таблицы назначения для перечислений
if $(SkipEnumDeploy) = 0
begin
PRINT N'Обновление перечислений...'
:r ..\Перечисления\EnumTable1.sql
end
--обновим версию БД
PRINT N'Установка версии БД...';
declare @username varchar(256) = suser_sname()
, @curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss')
if $(DBVersion) > (select isnull( MAX( DBVersion),0) from zDBVersionHistory)
begin
insert into zDBVersionHistory( DBVersion, DeploymentDate, DeployerName) values ($(DBVersion),@curdatetime,@username)
EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username;
EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;
end
else
begin
RaisError ( N'ОШИБКА: База данных назначения имеет такую же или более высокую версию, чем разворачиваемая. Если в проект были внесены изменения, то необходимо увеличить версию БД в файле DBVersion в соответствии с правилами и повторно выполнить генерацию скрипта развертывания.'
, 16
, 1
) WITH SETERROR;
end
GO
:r ".\CaptureTransactionError.sql"
:r ".\CommitTransaction.sql"Переменная SkipEnumDeploy, как уже стало ясно, позволяет пропустить этап обновления перечислений, это бывает полезно, при мелких косметических правках. Хотя, с точки зрения религии, это может быть и неверно, однако на этапе разработки точно пригождается.
Файлы
CaptureTransactionError.sql и CommitTransaction.sql тоже копипасты (с небольшими правками) из стандартного алгоритма работы транзакции, который генерирует студия при установке вышеописанного флажка, и который мы теперь воспроизводим самостоятельно.Содержимое CaptureTransactionError.sql
IF @@ERROR <> 0
AND @@TRANCOUNT > 0
BEGIN
ROLLBACK;
END
IF @@TRANCOUNT = 0
BEGIN
INSERT INTO #tmpErrorsManual (Error)
VALUES (1);
BEGIN TRANSACTION;
ENDСодержимое CommitTransaction.sql
IF EXISTS (SELECT * FROM #tmpErrorsManual) ROLLBACK TRANSACTION
GO
DROP TABLE #tmpErrorsManual
GO
IF @@TRANCOUNT>0 BEGIN
PRINT N'Транзакции обновления базы данных успешно завершены.'
COMMIT TRANSACTION
END
ELSE
RaisError ( N'Сбой транзакций обновления базы данных.'
, 16
, 1
);Содержимое EnumTable1.sql
set @TableName = N'Table1'
PRINT N'Обработка таблицы '+@TableName+'...'
begin try
set nocount on
drop table if exists #tmpEnums;
select * into #tmpEnums from (values
( 0, 'Значение 1')
, ( 1, 'Значение 2')
, ( 2, 'Значение 3')
) as tmp
( Id
, Title )
set nocount off
-- Сверка количества строк в источнике и таблице назначения
If ((select count(*) from Table1) > (select count(*) from #tmpEnums))
begin
RaisError ( N'ОШИБКА: Количество записей в целевой таблице больше, чем в источнике.'
, 0
, 1
) WITH SETERROR;
end
set Identity_insert Table1 on
Merge Table1 as target
Using (
select * from #tmpEnums
except
select * from dbo.Table1
) as source
on target.Id = source.Id
when matched
then update set target.Title = source.Title
when not matched by target
then insert ( Id
, Title )
values ( source.Id
, source.Title );
set Identity_insert Table1 off
drop table if exists #tmpEnums;
END TRY
begin catch
IF @@trancount > 0 ROLLBACK TRANSACTION
set @Error_Message = Error_Message();
RaisError ( N'ОШИБКА: %s.'
, 0
, 1
, @Error_Message
) WITH SETERROR;
end catch
:r "..\Скрипты\CaptureTransactionError.sql"При развертывании
Publish скрипт будет иметь следующую структуру--блок PreDeploy
----:setvar DBVersion "10.6" --это уже вычисленная строчка, содержащая значение из файла DBVersion
----запуск глобальной транзакции
--инструкции по корректировке метаданных БД, которые генерирует студия в соответствии с внесенными в проект изменениями
--блок PostDeploy
----обновление перечислений
----установка версии БД
----фиксация глобальной транзакцииВ идеале, конечно, хотелось бы, чтобы версия отображалась в момент публикации
Но не получается подтянуть в это окно значение из файла, хотя MSBuild его считывает и помещает в свойство ExtDBVersion с помощью дополнительных инструкций в файле .sqlproj, как в примере выше, но конструкция
<SqlCmdVariable Include="DBVersion">
<DefaultValue>
</DefaultValue>
<Value>$(ExtDBVersion)</Value>
</SqlCmdVariable>не прокатывает.
Разработчики сиквела в своем вэбдневничке пишут, как это делается. По их версии, магия заключается в инструкции
SqlCommandVariableOverride, с которой все просто — добавляем в файл проекта .sqlproj пару строк<ItemGroup>
<SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" />
</ItemGroup>и готово. Хорошая попытка, но нет. Быть может, когда была опубликована эта запись в блог, все работало, но с тех пор в этих ваших америках успели трижды пройти выборы президента и никто не знает, какая инструкция может перестать работать завтра.
А здесь один товарищ перепробовал все варианты, но ни один из них не взлетел.
Поэтому либо брать версию из dacpac, либо хранить ее в PostDeploy, либо в отдельном файле, либо _________ (вписать свой вариант).
Интеграция с 1С
Первая проблема заключалась в том, что у 1С77 нет никакого сервера приложений или другого дЕмона, позволяющего взаимодействовать с ней без запуска платформы. Кто работал с 1С77 -знает, что у нее нет полноценного консольного режима. Можно запустить платформу с параметрами и даже что-то выполнить на их основе, но консольных параметров очень мало и цель их была в другом. Но даже с их помощью можно наколхозить целый комбайн. Однако она может непредсказуемо вылететь, может вывести модальное окно и ждать, пока кто-то нажмет ОК и прочие прелести. И, пожалуй, самая большая проблема — скорость работы платформы оставляет желать… Поэтому решение тут только одно — прямые запросы в БД 1С. Учитывая структуру, нельзя просто так взять и написать эти запросы, но благо — есть целое сообщество, которое в свое время разработало прекрасный инструмент — 1C++ (1cpp.dll), невероятное им за это СПАСИБО! Библиотека позволяет писать запросы в терминах 1С, которые далее превращаются в реальные имена таблиц и полей. Если кто не знает, то запрос можно написать с использованием псевдоимен и выглядеть он будет так
select
Артикул
from
$Справочник.НоменклатураТакой запрос понятен человеку, но на сервере нет такой таблицы и поля, там другие имена, поэтому 1С++ превратит его в
select
SP5278
from
SC2235и такой запрос уже понятен серверу. Все довольны, никто не ругается — ни человек, ни сервер. Тут вроде бы вопрос решен.
Вторая проблема лежала в плоскости конфигураций: в филиалах использовалась одна конфигурация, в центральном офисе другая, а в подфилиалах — третья! Класс?!!1 Я тоже так думаю. Причем все они не типовые и даже не наследие типовых, а полностью написанные с нуля во времена викингов и, к сожалению, фундамент этих конф закладывали не самые лучшие архитекторы… Документ Реализация, например, в каждой конфигурации имеет разный набор реквизитов. Но отличаются не только названия некоторых полей, куда веселее, когда названия реквизитов одинаковые, но смысл хранящихся в них данных — РАЗНЫЙ.
В конфигурациях почти не используются регистры, всё построено на хитросплетениях документов. Поэтому иной раз приходилось писать целую простыню на чистом транзакте, с кучей кейсов и джойнов, чтобы повторить логику какой-то процедуры из конфигурации, выводящей в текстовое поле на форме некую информацию.
Надо отдать должное команде разработчиков, которые все эти годы поддерживали то, что им досталось в наследство от «внедренцев», это огромный труд — поддерживать такое и даже что-то оптимизировать. Пока не увидишь — не поймешь, я сам сначала не верил, что все может быть настолько сложно. Спросите — почему бы не переписать с нуля? Банальная нехватка ресурсов. Компания развивалась так быстро, что, несмотря на большую команду программистов, они просто не успевали за потребностями бизнеса, не говоря уже о переписывании всей концепции.
Продолжим повесть о запросах. Очевидно, что все блоки по извлечению данных оборачивались в хранимки, чтобы впоследствии их можно было запускать на стороне сервера минуя платформу 1С. Правило было такое: одна хранимка отвечает за извлечение одной сущности. Т.к. хотелок на этапе старта накопилось уже много, ибо наболело за годы, то хранимок получилось несколько десятков.
Третья проблема — как повысить скорость и качество разработки, и как всё это чудовище потом поддерживать? Писать запрос на 1С++ и копипастить результат его конвертации в хранимку? Очень неудобно и нудно, к тому же велика вероятность ошибок — скопировать не то и не туда или не выделить последнюю строчку запроса и скопировать без нее. Это особенно актуально, когда речь идет о прямых запросах 1С, ведь там не видно псевдоимен типа Справочник.Номенклатура.Артикул, только реальные имена SC2235.SP5278 и поэтому закопипастить запрос из под справочника товаров в хранимку, извлекающую клиентов, очень просто. Конечно, запрос, скорее всего, свалится, из-за несоответствия типов и количества полей в таблице-приемнике, но есть и идентичные таблички, типа перечислений, где только две колонки — ИД и Наименование. В общем, тут остается только применять какую-то автоматизацию. Ну, хватит лирики, давайте к делу!
Хотелось, чтобы процесс разработки хранимок сводился к примерно таким действиям:
- Исправляем SQL-запрос с псевдоименами и сохраняем его
- Жмем волшебную кнопочку и получаем на выходе исправленную хранимую процедуру на преобразованном SQL, понятном серверу
Немного деталей
Для решения третьей проблемы была написана внешняя обработка (.ert). В обработке есть ряд процедур, каждая из которых содержит текст запроса для извлечения одной сущности с использованием псевдоимен, типа
select
*
from
$Справочник.НоменклатураНа форме обработки есть поле для вывода результата работы той или иной процедуры, т.е. запроса, преобразованного в понятный для сервера вид, чтобы можно было его быстро испробовать в деле. Плюс к этому запросу всегда добавляется отладочный блок, с объявлением переменных, именами тестовых БД, серверов и прочее. Остается только скопипастить в SSMS и нажать F5. Можно, конечно, выполнить этот запрос и из самой обработки, но план запроса и все такое, ну вы поняли… В общем, так производится отладка. Т.к. конфигураций несколько, в обработке предусмотрена возможность конвертировать одни и те же тексты запросов с псевдоименами объектов в конечные запросы для разных конфигураций. Ведь в одной конфе справочник Номенклатура это SC123, а в другой — SC321. Но 1С++ позволяет в рантайме подгружать в себя разные конфы и для каждой из них генерировать индивидуальный вывод в соответствии со словарем.
Далее в обработку был добавлен режим пакетного запуска, когда она автоматически запускает каждую из процедур для каждой конфигурации, а вывод каждой из них записывает в файлы .sql (далее базовые файлы). Таким образом мы получаем кучу комбинаций базовых файлов, которые впоследствии должны автоматически превратиться в хранимые процедуры средствами VS. Стоит отметить, что базовые файлы включают в себя и блок отладки.
Казалось бы, почему не сделать вывод сразу в конечные файлы хранимых процедур и держать всё в этой обработке? Дело в том, что для некоторых тестов необходимо пакетно запускать именно отладочные версии запросов, в которых объявлены все переменные, плюс хотелось, чтобы именами хранимых процедур можно было управлять из VS, минуя запуск 1С, ведь это логично, не так ли?
Кстати, базовые файлы тоже хранятся в проекте, ну, и файлы готовых хранимых процедур, конечно же. В любой момент, не запуская 1С, можно открыть базовый файл в SSMS и выполнить его, не заморачиваясь с объявлением переменных.
В обработке все процедуры с запросами тоже шаблонные, имеющие одинаковый набор параметров, но в той или иной процедуре используются только необходимые параметры. В некоторых задействовано всё, а в некоторых достаточно и двух. Поэтому добавление новой процедуры сводится к копированию шаблона и заполнению параметров самими запросами.
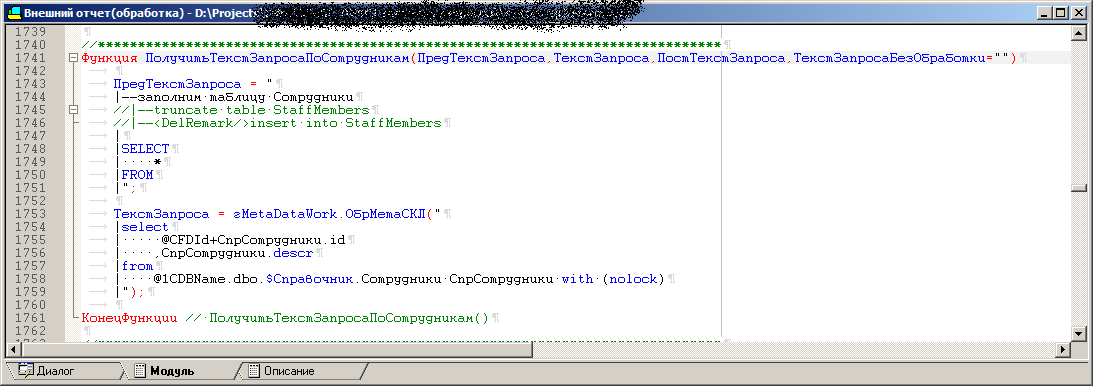
Код одной из процедур обработки, которая после превратится в хранимую процедуру
Конечный запрос собирается примерно так:
ТекстЗапросаБезОбработки+ПредТекстЗапроса+"("+OPENQUERY(ТекстЗапроса)+")"+ ПостТекстЗапросаВнешний вид обработки
При переключении конфигураций меняется и список доступных (необходимых) для выгрузки элементов в списке Данные. По возможности, код процедур в 1С максимально унифицировался. Если извлекаются контрагенты и в разных конфигурациях эти справочники имеют нестыковки, то внутри процедуры генерации есть разные кейсы, типа: этот блок фиксированный для всех, вот этот только для такой конфы добавляется в конечный запрос, а вон тот — для другой. Получается, что в хранимые процедуры для одной сущности но разных конфигураций могут отличаться не только именами таблиц, но целыми блоками джойнов, присутствующих в одной и отсутствующих в другой. Набор выходных полей, конечно же, одинаковый и соответствует таблице-приемнику или контейнеру SSIS пакета, какие-то поля забиваются заглушками для конфигураций, в которых этих реквизитов нет в принципе.
Волшебная кнопочка
В Visual Studio есть такие инструменты, как MSbuild и совершенно замечательные шаблоны T4. Поэтому в качестве волшебной кнопки был написан скрипт на C# для T4, который:
- Регистрирует пустую конфигурацию в реестре (иначе 1С выведет модальное окно с предложением регистрации конфы и ждет действий пользователя)
- Создает пустую базу данных для этой конфы на SQL сервере, ибо без нее 1С выдаст ошибку
- Запускает 1С и через OLE говорит ей выполнить обработку (ту самую .ert), так же передавая в 1С уникальный GUID
- На выходе получается ряд файлов с готовыми (переконвертированными) запросами и маркерный файл, в который пишется GUID, полученный при запуске
- Удаляется из реестра регистрация конфы и удаляется временная пустая БД с сервера
- Выполняется проверка содержимого маркерного файла. Если в маркерном файле лежит тот GUID, который мы передали в 1С при ее запуске, значит, она отработала до конца, не вылетела и т.д., тогда переходим к следующему шагу, либо выводим ошибку
- Создаем хранимки.
- Декомпилируем .ert файл с помощью gcomp, чтобы получить тексты модуля и формы обработки, ну, и в юникод преобразовываем, для последующей отправки в Git и корректного отображения там. Для тех, кто не работал с 1С: .ert файл — это бинарник и студия вместе с гитом трубят, что .ert файл изменен, но непонятно, что именно в нем изменилось, может просто кто-то кнопку сдвинул влево на один пиксель (что недопустимо без обоснования)
Перед созданием хранимок скрипт T4 извлекает из базовых файлов тексты запросов регуляркой, чтобы исключить отладочные куски (ориентируется на специальную метку, обозначающую конец отладочного блока) и оборачивает в единый унифицированный шаблон хранимой процедуры. Во всех хранимках одинаковый набор параметров, но в той или иной процедуре используются только необходимые параметры. Список сопоставления имен базовых файлов и имен хранимых процедур, в которые они должны превратиться, выполнены в проекте в виде отдельного файла, чтобы было удобно с этим работать, не разыскивая в портянке кода нужную строчку и опять-таки — минуя запуск 1С.
Также хотелось, чтобы разработчик, впервые присоединившийся к проекту, мог без проблем писать запросы и конвертировать их, не забивая себе голову необходимостью регистрации пустой конфигурации, развертывания пустой базы данных и прочих неприятных и нудных мелочей. Поэтому в проекте хранится всё — необходимые конфигурации 1С, скрипты для корректной работы 1С, сама обработка-конвертер и прочие файлы.
В результате сценарий действий разработчика такой: Нужна новая хранимка или нужно исправить существующую?
- Пишем в обработке новую процедуру/исправляем старую;
- Добавляем в проекте VS строчку в настроечный файл сопоставлений, если была добавлена новая процедура;
- Запускаем скрипт Т4;
Профит.Готово.
Хинт?
Т.к. базовые файлы выкладываются обработкой в определенную папку и проект о новых файлах ничего не знает, то чтобы они автоматически появлялись в проекте, нужно откорректировать файл .sqlproj, заменив
На
И забыть про такую операцию как «добавить новый базовый файл в проект». А то знаете, может случиться, что хранимка есть, а базового файла нет :)
А еще храните все настройки, разрешения, списки учетных записей (сервисных, разумеется) и прочие мелочи в проекте. Не меняйте никакие настройки и наборы прав в базе напрямую (минуя проект), чтобы не приходилось после чистого деплоя бегать высунув язык, из-за того что где-то что-то перестало работать и не тратить массу времени, перепроверяя все ли клиентские приложения и прочие сервисы имеют нужный доступ и функционал.
<ItemGroup>
<None Include="Базовые файлы\Файл1.sql">
<None Include="Базовые файлы\Файл2.sql">
<None Include="Базовые файлы\Файл3.sql">
</ItemGroup>На
<ItemGroup>
<Content Include="Базовые файлы\*.sql" />
</ItemGroup>И забыть про такую операцию как «добавить новый базовый файл в проект». А то знаете, может случиться, что хранимка есть, а базового файла нет :)
А еще храните все настройки, разрешения, списки учетных записей (сервисных, разумеется) и прочие мелочи в проекте. Не меняйте никакие настройки и наборы прав в базе напрямую (минуя проект), чтобы не приходилось после чистого деплоя бегать высунув язык, из-за того что где-то что-то перестало работать и не тратить массу времени, перепроверяя все ли клиентские приложения и прочие сервисы имеют нужный доступ и функционал.
На выходе получаем измененный файл модуля и формы обработки, новый базовый файл и саму хранимку. Студия прекрасно подсвечивает все измененные строки. Много, конечно, ушло времени на все эти красоты, чтобы обработка не пересоздавала базовые файлы, если в коде обработки ничего не изменилось, а то они светились как измененные (потому что дата файла изменилась), но при построчном сравнении нет разницы. Кстати, в базовый файл (в ту его часть, которая впоследствии уйдет в хранимую процедуру) записывается комментарий, с информацией о дате и времени генерации файла, версии конфигурации, на основе которой он был создан и кто это выполнял. Поэтому в любой хранимой процедуре всегда можно увидеть кто генерировал код, находящийся в ней. Обработка, перед перезаписью существующего базового файла, сверяет его полезный текст с тем, который планируется в него записать, если отличий нет, то файл остается нетронутым (это все ради того, чтобы не было ложных подсвечиваний изменений при изменении конфигурации 1С, например, когда изменилась версия MD файла).
Еще пришлось помучиться с текстами запросов, потому что они выполняются к удаленным серверам через OPENQUERY, а имена баз данных 1С в филиалах отличаются, как отличаются и имена серверов, поэтому текст запроса собирается динамически из строки, с подстановкой этих значений из параметров хранимки, помещается в переменную и запускается в конце через EXEC. OPENQUERY изначально заточен выполнять строку, поэтому уже получается строка в строке, кавычка в кавычке, экранирование и прочее.
И 1С77 (в базовом исполнении) функционирует на SQL2000, а там varchar(max) не работает, максимум varchar(8000), а общий текст запроса 9к, например… Значит, надо определить уже две переменные и выполнить их в EXEC(@SQL1+@SQL2). Не смотря на то, что процедуры хранятся и выполняются на SQL2016, их части проверялись на SQL2000. Руками переменные определять не хотелось, хотелось минимизировать число ненужных телодвижений, чтобы все было автоматически.
В обработке текст запроса выглядит примерно так
select
...
from (
select
...
from
@1CDBName.dbo.$Документ.ххх
join
@1CDBName.dbo.$Справочник.ууу
join
...
where
xxx = 'hello!'
^--на этой точке уже заканчивается лимит в 8к символов, значит, это слово целиком нужно перенести в следующую переменную, но анализировать слова и дополнительные экранирования сложно, проще переносить построчно. Если после добавления следующей строки запроса в переменную превышается лимит, то создается новая переменная и эта строка помещается уже в нее и т.д.
...
join
...
)
join
...А текст хранимки имеет следующий вид
CREATE PROCEDURE [dbo].[SP1]
@LinkedServerName varchar(24)
,@1CDBName varchar(24)
AS
BEGIN
Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000)
set @TSQL0='
select
...
from OPENQUERY('+@LinkedName+',''
select
...
from
'+@1CDBName+'.dbo.DH123.ххх
join
'+@1CDBName+'.SC123.ууу
...
where
';
set @TSQL1='
xxx = ''''hello!''''
join
...
join
...
)''
join
...
''';
set @TSQL2='
...
EXEC(@TSQL0+@TSQL1+@TSQL2)
ENDКак видно из кода — хранимая процедура не имеет форматирования. При создании базового файла всё форматирование (пробелы, табуляции) слева и справа, которые были в оригинале запроса с псевдоименами, удаляется, ведь серверу плевать на форматирование, а для экономии имеет прямой смысл, ибо переменных можно наплодить сколько угодно, а у OPENQUERY лимит 8к символов.
.ert обработка определяет длину конечного запроса с учетом удаленного форматирования и вычисляет количество переменных, в которое все это должно разместиться и т.д. В общем, много крови выпила эта обработка.
Вручную никаких изменений в сами хранимые процедуры никогда не вносится, только через исправление обработки.
ETL
Пожалуй, в этой части нет ничего особенного (на мой взгляд). Классическая схема с промежуточной БД (Stage). Можно лишь отметить, что ETL реализована с помощью SSIS пакетов, которые, в свою очередь, выполняют те самые хранимые процедуры, о которых говорилось в предыдущем разделе. Есть основной пакет и несколько дочерних. Для возможности многопоточного выполнения основной пакет параллельно запускает несколько экземпляров одного и того же дочернего пакета с разными параметрами (для разных филиалов), в результате удается получить данные от связанных серверов за максимально короткий период.
Если в процессе получения данных один или несколько экземпляров дочернего пакета не смогли подключиться к удаленным серверам, то список таких серверов (с неудачной попыткой подключения) запоминается, а после того, как закончится выполнение всех потоков дочерних пакетов (т.е. через несколько минут), основной пакет вновь запускает потоки для серверов из списка с неудачной попыткой, пытаясь таки достучаться и ему это иногда удается.
Если не удалось получить данные из одного или нескольких филиалов, то это не критическая ошибка, система будет функционировать и без них. Разумеется, пакет уведомляет о таких ситуациях. В нашем случае через zabbix.
Все полученные данные сбрасываются в промежуточную БД из которой уже переливаются в основную.
Т.к. в используемых конфигурациях 1С нет никаких механизмов регистрации изменений, а о событийной интеграции и вспоминать не стоит, приходится каждый раз перезапрашивать данные из всех баз за несколько последних месяцев. Чтобы не тратить время на удаление, используется секционирование таблиц, позволяющее выполнять
truncate для секции.Разумеется, со временем главный пакет стал увеличиваться (обрастая дочерними пакетами) и в него добавились взаимодействия с веб-сервисами, различными «не 1С-ными» базами данных и прочими источниками.
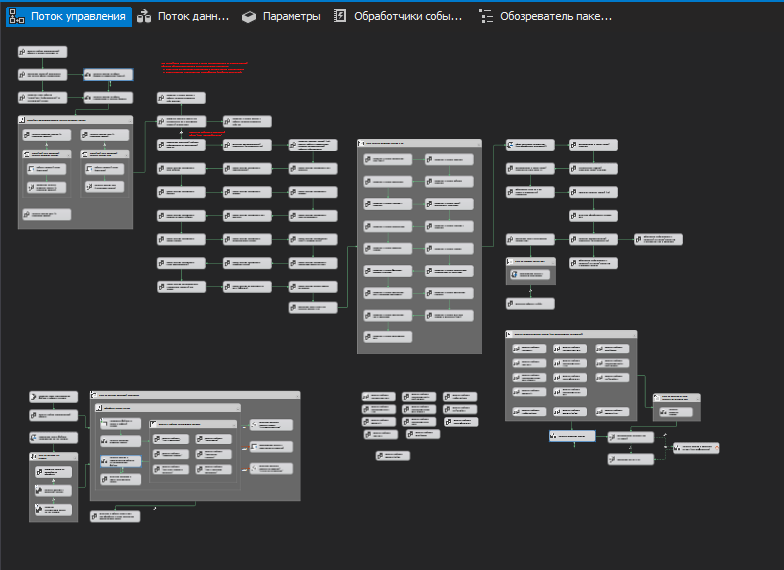
Поток управления одного из SSIS пакетов
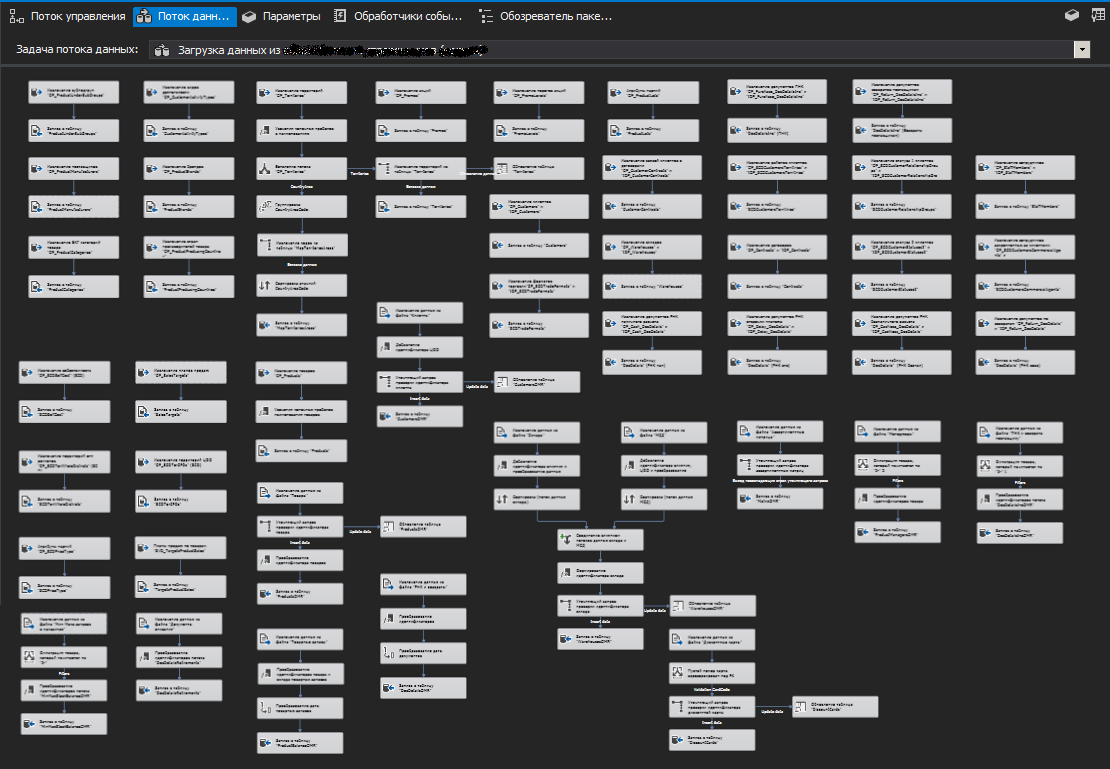
Один из потоков данных пакета
Несколько советов, если позволите
Для повышения скорости вставки данных в БД через SSIS используйте компонент потока данных Назначение SQL Server (SQL Server Destination), он работает в разы быстрее, чем Назначение OLE DB (OLE DB Destination).
Для повышения скорости отката при сбоях, а вернее для отсутствия необходимости в нем, есть вариант с ротацией БД, когда рядом с основной БД создается копия и начинает пополняться без всяких транзакций. Если пополнение прошло успешно, то копия переименовывается в основную либо остается нетронутой, в случае ошибки. (Разумеется, если на сервере достаточно места)
Никогда не исправляйте вручную данные в БД. Только скриптами и обязательно сохраняйте каждый из них с адекватным именем, датой и комментариями внутри, из которых должно быть понятно кто, когда и на каком основании это делал (ошибка/служебка и прочее).
Делайте блокирующую проверку версии БД внутри таких скриптов и не допускайте выполнение в случае несоответствия версий в скрипте и в БД назначения.
И еще бы я рекомендовал завести в БД специальную таблицу, в которой будет храниться история запусков таких скриптов (из предыдущего абзаца). Т.е. скрипт не только вносит изменения в данные, но и регистрирует факт своего запуска в журнале. Есть смысл не только регистрировать запуск, но и блокировать его повторный запуск в случае, если в журнале уже есть информация о предыдущем выполнении. А если по какой-то причине нужно выполнить тот же скрипт повторно — сделайте его копию и присвойте ему новую дату и номер. Это существенно облегчит жизнь и избавит от лишних претензий при разборе полетов.
В качестве настроек по умолчанию для развертывания установите строки подключения и пути отличные от продуктивных путей и имен, чтобы для публикаций в продуктив нужно было целенаправленно (т.е. осознанно) выбрать конкретную настройку.
Не ленитесь делать всевозможные защиты от дурака, они лишними никогда не бывают, какой бы высокой квалификацией и уровнем ответственности не обладали разработчики.
P.S.
Я не претендую на истину, каждый решает для себя сам, исходя из своего опыта и предпочтений, полезно ли все то, что было описано. Все примеры — это только примеры, сделанные на скорую руку. Статья писалась несколько месяцев с десятками подходов и большими интервалами из-за нехватки времени, поэтому могут быть некоторые нестыковки в тексте, уж не обижайтесь.
Комментарии (6)

uaggster
31.10.2018 15:10Просто из любопытства вопрос:
А почему было не реализовать средствами 1С (ну, или, скажем так — 1С + что-то) на филиале выгрузку в некую промежуточную структуру, например — xml файл, а на уровне хранилища — загрузку из типового xml файла? Ну хорошо, версионированного файла.
Да, для каждого филиала выгружалку придется писать и поддерживать индивидуально, но вы в любом случае это делали.
И никакого безобразия с монструозными SSIS пакетами с замудрённой логикой на уровне хранилища — нету. Каждый отдельный кусок замечательно тестируется и обкатывается (и загружается) — индивидуально.rt001 Автор
31.10.2018 17:46Может, я не понял вопроса… Но кажется причина была описана
Первая проблема заключалась в том, что у 1С77 нет никакого сервера приложений или другого дЕмона, позволяющего взаимодействовать с ней без запуска платформы. Кто работал с 1С77 -знает, что у нее нет полноценного консольного режима. Можно запустить платформу с параметрами и даже что-то выполнить на их основе, но консольных параметров очень мало и цель их была в другом. Но даже с их помощью можно наколхозить целый комбайн. Однако она может непредсказуемо вылететь, может вывести модальное окно и ждать, пока кто-то нажмет ОК и прочие прелести. И, пожалуй, самая большая проблема — скорость работы платформы оставляет желать… Поэтому решение тут только одно — прямые запросы в БД 1С.
Поэтому выгрузка из самой 1С даже не рассматривалась.
(ну, или, скажем так — 1С + что-то)
Если прямые запросы запускать на стороне филиала с помощью чего-то еще, то какая разница, будет этим «что-то» какой-то другой продукт или SSIS?
Монструозность можно было бы уменьшить (не избежать), если использовать те функции, что есть в конфигурации 1С, написанные на языке 1с, позволяющие добраться до документа основание или еще что-то, но это противоречит первому условию
Всё это множество переходов и условий в SSIS появились не из-за прямых запросов, а из-за большого числа сущностей, которые в хранилище нужно слить воедино. Для каждого XML файла пришлось бы делать то же самое — как минимум один компонент на файл, если файлов десятки, то и компонентов десятки, вот они уже и на экран не умещаются. Однако в случае с файлами нужно было бы обеспечить их транспорт, а это еще один сервис. Ну не в шару же их выкладывать.
Плюс логика обработки самих файлов — какой период в них лежит? А есть ли предыдущая версия файла рядом? В какой последовательности их загружать и что делать с соседним файлом в котором такой же или перекрывающий период? Религиозный вопрос — нужно ли хранить где-то историю этих файлов, т.е. уже загруженные/ошибочные/планируемые к загрузке копии…

epee
а снепшоты базы для этой цели не думали использовать?
правда у варианта со снепшотом есть минус — в случае неудачного деплоя, вам основную базу надо из снепшота восстанавливать, но если изменений немного — то восстановление из снепшота происходит быстро, создается снепшот очень быстро по сравнению с созданием копии. вариант снепшотов не подходит для если вы деплоитесь на базу которая работает 24\7, но если есть окно обслуживания, то вариант со снепшотом вполне себе рабочий
rt001 Автор
Вы обозначили обе причины, по которым мы не используем снимки )))