
Мы делаем продукт под названием ALICE Platform и я сейчас расскажу, как решали проблему нагрузочного тестирования.

ALICE — это Jira для отелей. Мы делаем платформу, чтобы помочь им разобраться со своими внутренностями. Консьерж, фронтдеск-оператор, уборщики — им тоже нужны тикеты. Например: звонит гость > говорит, что нужно убраться в номере > сотрудник создает тикет > ребята, которые убираются, знают, на кого поставлен таск > выполняют > меняют статус.
У нас b2b, поэтому цифры могут не впечатлять — всего 1000 отелей, 5000 DAU. Для игр это немного, но для нас это очень круто, потому что есть целых 8 prod-серверов и они с трудом справляются с этими 5 тысячами активных пользователей. Так как под капотом происходят немного другие вещи — куча баз данных, транзакций и т.д.

Самое главное: за последний год мы выросли в 2 раза, теперь у нас инжиниринг-команда в районе 50 человек и мы планируем вдвое расширить пользовательскую базу в 2019 году. И это главный челендж, который стоит перед нами.
Пример из жизни. В пятницу вечером, отработав 60-часовую рабочую неделю, в 23:00 я закончил последний созвон, быстренько доделал презентацию, прыгнул в поезд и приехал сюда. А минут пять назад немного переделал свою презентацию. Так сейчас у нас всё и работает, потому что мы стартап и это круто. Пока я ехал, часть технической команды (мы это называем fire на продакшене) старались сделать так, чтобы система не легла и, одновременно, пользователи этого не заметили. У них всё получилось и мы спасены.
Как видите, пока что мы не очень хорошо спим по ночам. Мы точно знаем, что наша инфраструктура ляжет. Мы смотрим правде в глаза и понимаем это. Один вопрос: когда? Именно так мы поняли, что Load-тестирование — это ключ к спасению. Это то, чем нам нужно озаботиться.

Какие цели мы ставим перед собой. Во-первых, мы должны прямо сейчас точно понимать capacity и производительность нашей системы, как хорошо она работает у текущих пользователей. И это должно произойти до того, как пользователь разорвет с нами контракт (а это может быть клиент на 150 отелей и очень большие деньги) из-за того, что что-то не работает или очень тормозит. Кроме того, у отдела продаж есть план: двукратный рост в течение ближайшего года. А еще так получилось, что мы купили нашего главного конкурента и мигрируем их пользователей к себе.
И мы должны знать, что всё это выдержим. Знать заранее, до того, как придут эти пользователи и всё ляжет.
А еще мы делаем релизы. Каждую неделю. В понедельник. Конечно, не все релизы расширяют функционал, где-то maintenance, где-то исправление ошибок, но мы должны понимать, что пользователи этого не заметят и их экспириенс не станет хуже.
Но мы, как хорошие разработчики, люди ленивые и не любим работать. Поэтому спросили у сообщества и гугла, какие есть сервисы/решения для Load-тестирования. Их оказалось много. Есть простейшие вещи, вроде Apache Bench, который просто в сто потоков пинает какой-то сайт по урлу. Есть злой и странный вариант Bees with Machine Guns, где все тоже самое, но он стартует инстансы, которые летят и кладут ваши приложения. Есть JMeter, там можно написать какие-то скрипты, запустить в облаке.

Вроде бы все хорошо, но, подумав, мы поняли, что нам реально придется работать и сначала решить несколько задач.

Во-первых, нужно написать реальные сценарии, которые будут имитировать полноценную нагрузку. В некоторых системах достаточно сгенерировать рандомные вызовы API c рандомными данными. В нашем же случае — это длинные пользовательские сценарии: получил звонок, открыл экран, вбил все данные (кто позвонил, что он хочет), сохранил. Потом это появляется в мобильном приложении у другого человека, который будет исполнять запрос. Не самая тривиальная задача.
И, напомню, релизы каждую неделю. Функционал обновляется, сценарии должны быть реально актуальными. Сначала их нужно написать, а потом еще и поддерживать.
Но это была не самая большая проблема. Взять, например, flood.io. Классный инструмент, в нем можно запустить Selenium — это когда запускается Chrome, ты им можешь управлять, и он выполняет какие-то сценарии. В нем можно запустить JMeter-скрипты. Но если мы захотим запустить Selenium внутри JMeter-скриптов — внезапно все разваливается, потому что ребята, которые собирали это воедино, приняли ряд архитектурных решений. Или, например, какие-то сервисы могут запустить JUnit — он простой и понятный, но один из таких сервисов написал свой JUnit и он просто игнорирует некоторые вещи.

Остро стоит вопрос генерации нагрузки, потому что каждый инструмент просит по-своему ее сгенерировать. И даже когда ты справился с тем, чтобы сценарии были адекватные, возникает вопрос: а как запустить в 2-4 раза больше? Вроде бы: запусти и всё хорошо. Но нет. В этих запросах есть всякие ID — мы что-то создаем, получаем новый ID, изменяем по старому ID и тест, который грузит сущность по ID, меняет ее поле на другое. И 10 тестов, которые эту же сущность грузят 10 раз — это не очень интересно. Потому что 10 раз надо грузить разные сущности и правильно масштабировать эту нагрузку.
ОК, мы хотим решить проблему нагрузочного тестирования, чтобы точно понимать, сколько пользователей выдержит приложение, и что наши планы соотносятся с планами отдела продаж. Мы проанализировали решения, которые есть на рынке, и потом провели инвентаризацию наших макарон и палок.
Так как мы делаем релизы каждую неделю, естественно, мы автоматизировали некоторые тесты — интеграционные и еще что-то. Для этого мы используем Cucumber. Это BDD-фреймворк, на котором можно заниматься behavior-driven development. Т.е. мы задаем какие-то сценарии, которые состоят из шагов.

Наша инфраструктура позволяла запускать интеграционные и функциональные тесты в двух режимах: просто попинать бэкенд, подергать API или реально через Selenium запустить Chrome и управлять им.
Мы очень любим NewRelic. Он может по-простому мониторить сервера, основные показатели. Встраивается в JVM и перехватывает все вызовы контроллеров и API Endpoint. Eще у них есть решение для браузера, а так как у нас большая часть функционала находится именно там, то в браузере он тоже что-то делает и дает какие-то метрики.

Соответственно, нужно собрать это все воедино. Мы уже автоматизировали основные сценарии. Наши сценарии (т.к. как это BDD) имитируют реальных пользователей и нагрузка похожа на реальный продакшн. Заодно мы можем ее масштабировать. Так как это часть релиз-процесса, это всегда поддерживается в актуальном состоянии.

Теперь возьмем любой инструмент, который сейчас есть на рынке. Они оперируют теми же примитивами: http, вызовы API по http, JSON, JUnit, вот это всё. Но как только мы пытаемся засунуть наши тесты на Cucumber, они делают то же самое, оперируют теми же вещами, но ничего не работает. Мы начали думать, как справиться с этой задачей.
Небольшое отступление, потому что BDD не очень популярный термин в игровой разработке, это больше для enterprise-решений.

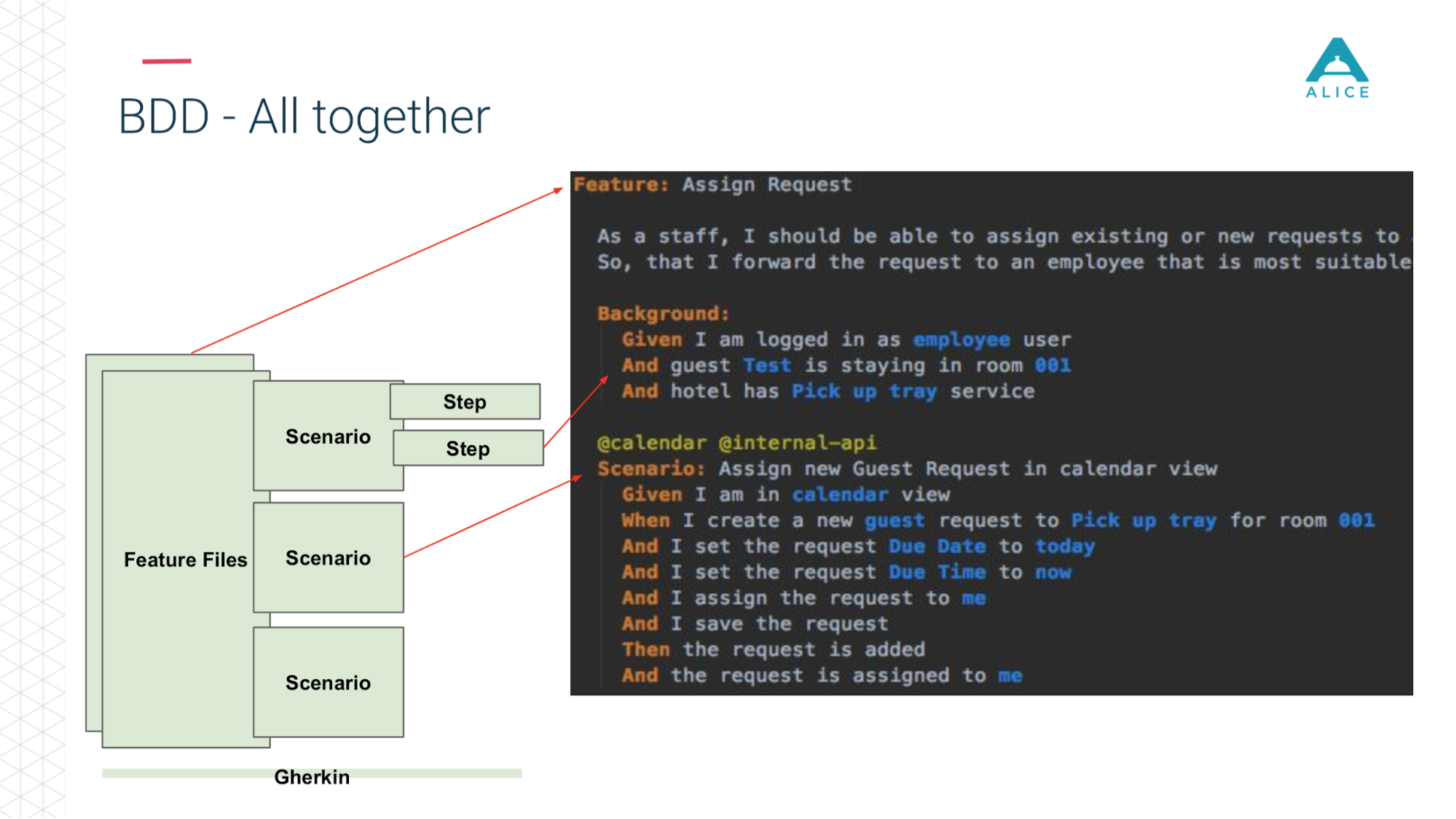
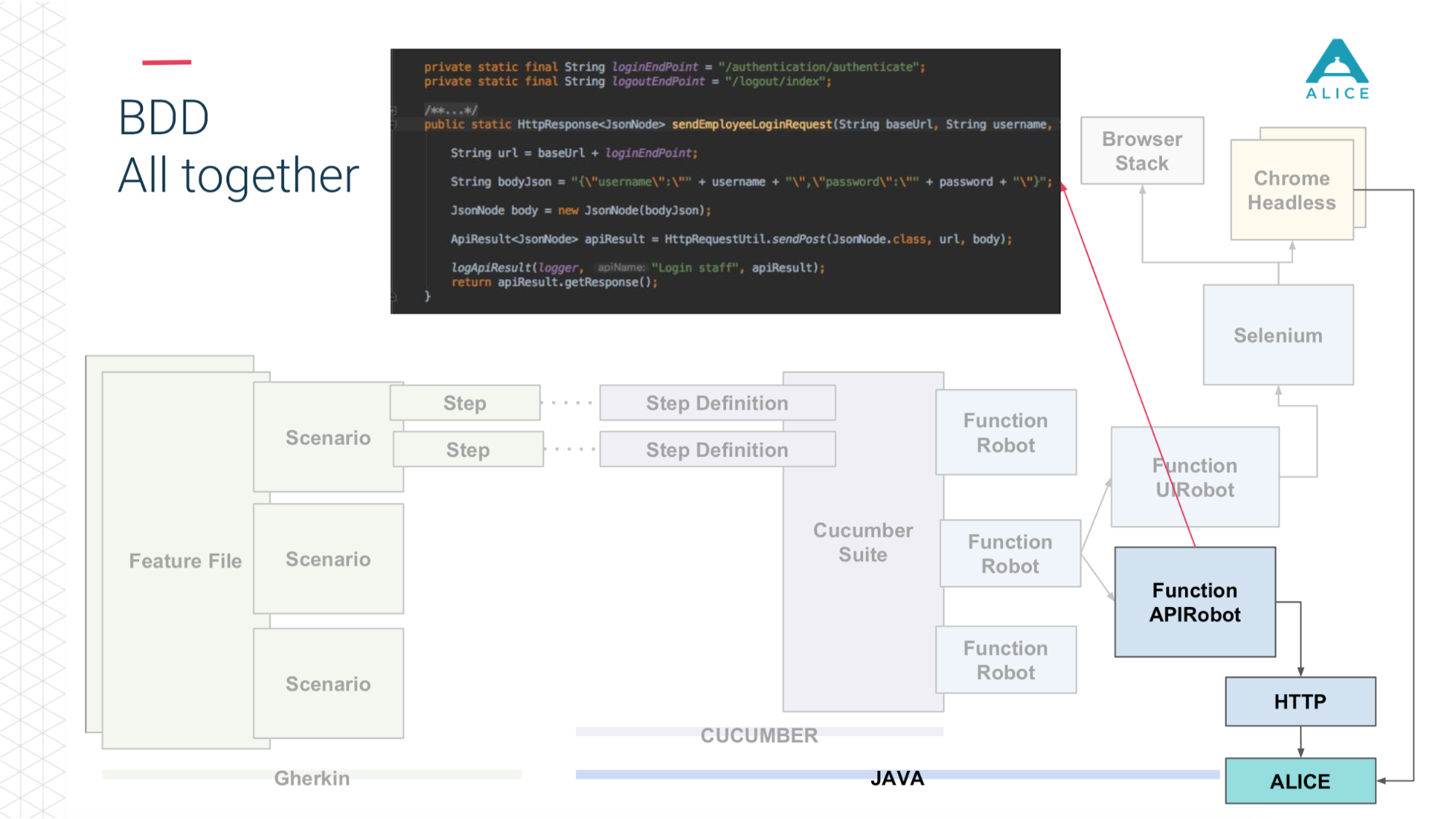
Все сценарии реально описывают какое-то поведение. Формат описания сценариев очень простой: Given, When, Then — в терминах BDD называется Gherkin. Cucumber за нас при помощи аннотаций и атрибутов отображает это на Java-код. Он занимается тем, что видит сценарий: надо дать человеку яблоко, давайте найдем метод, в котором это реализовано.
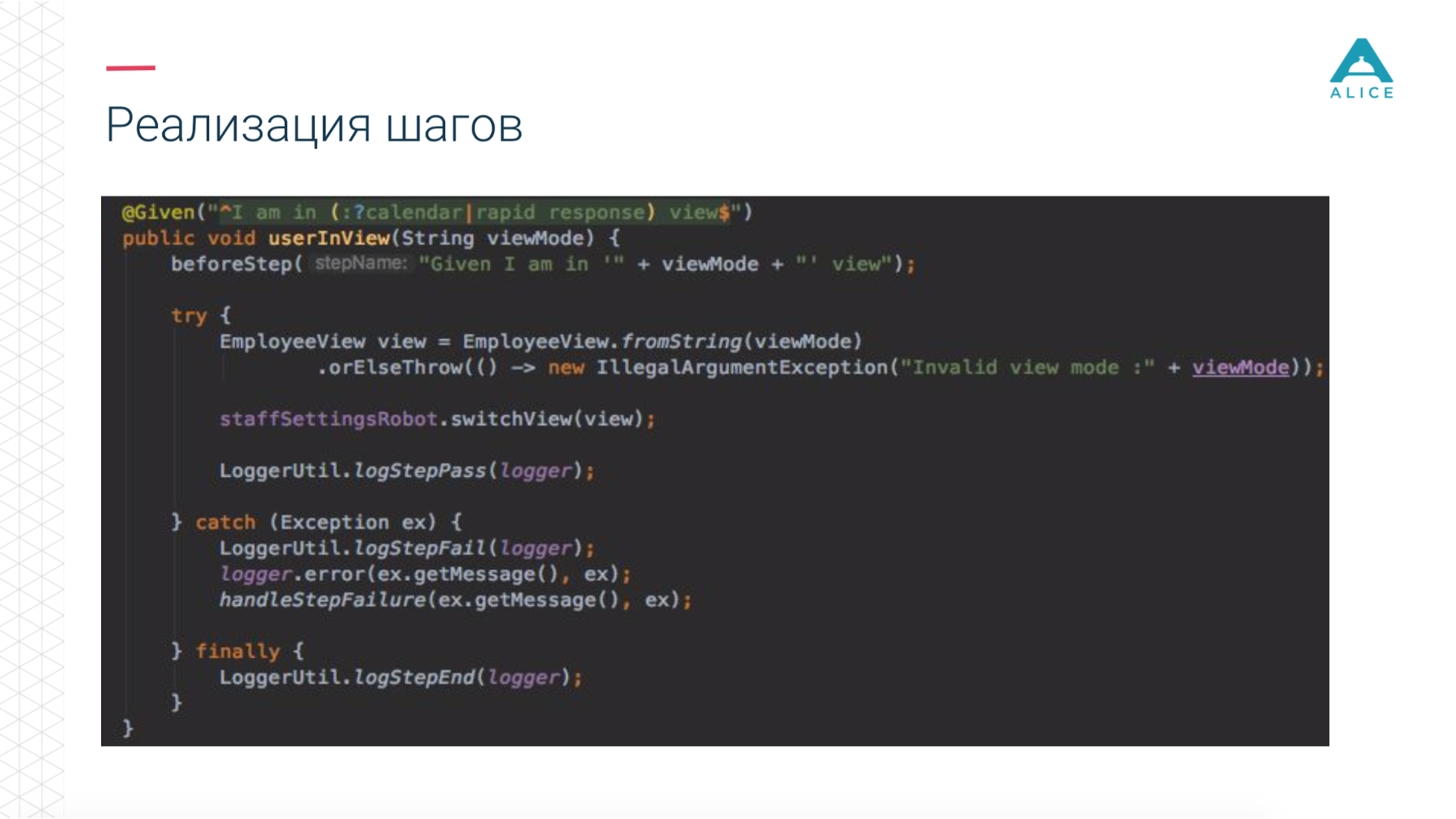
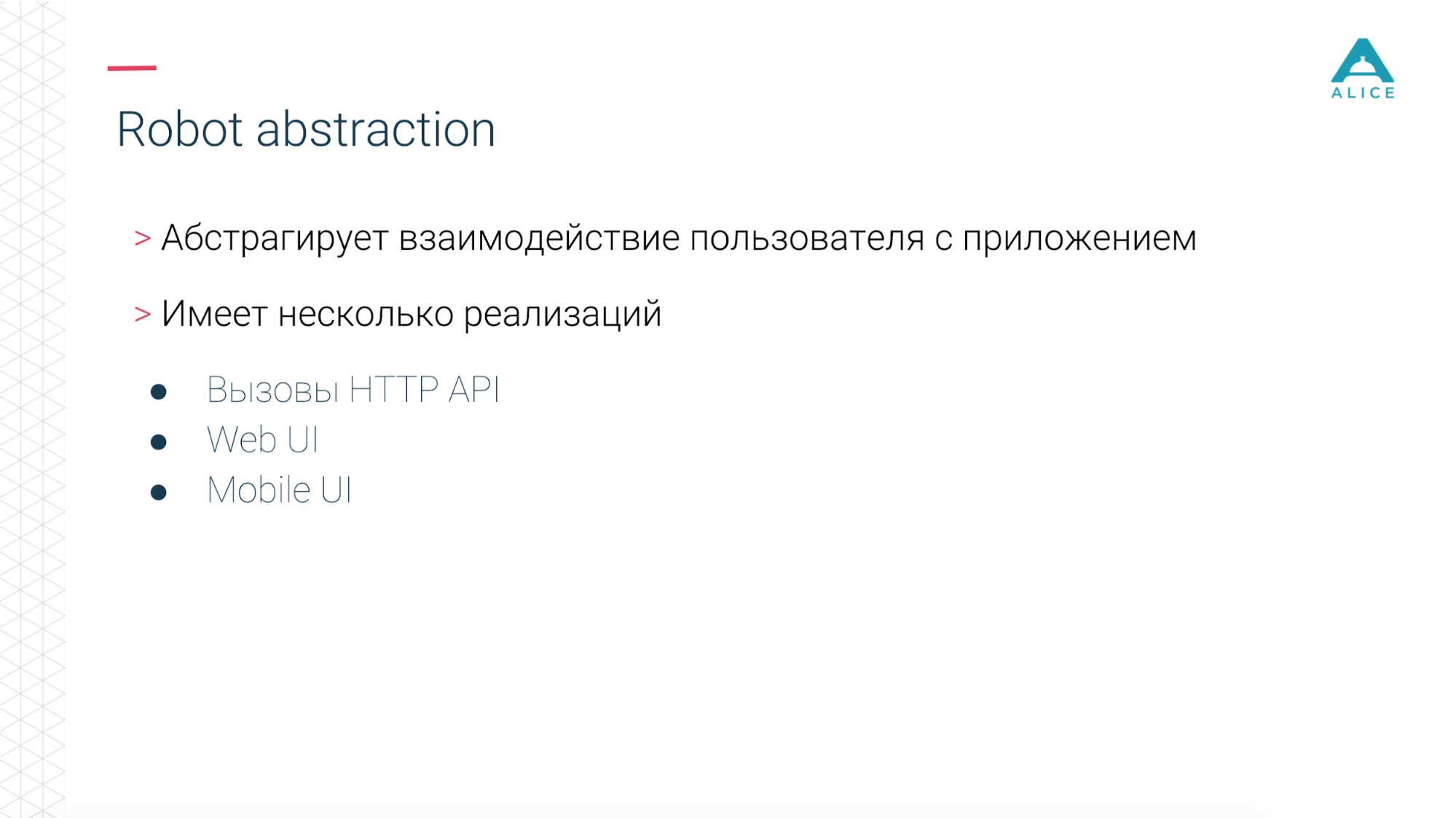
Затем мы ввели такое понятие, как Functional Robot. Это некий клиент для приложения, у него есть методы залогинить пользователя, разлогинить, создать тикет, посмотреть список тикетов и т.д. И он может работать в трех режимах: с мобильным приложением, web-приложением и просто делать API-вызовы.
Теперь в двух словах тоже самое на слайдах. Feature Files разбиты на сценарии, есть степы и все это пишется на английском языке.
Потом вступает в роль Cucumber, код на Java, он маппит эти сценарии на код, который уже реально исполняется.
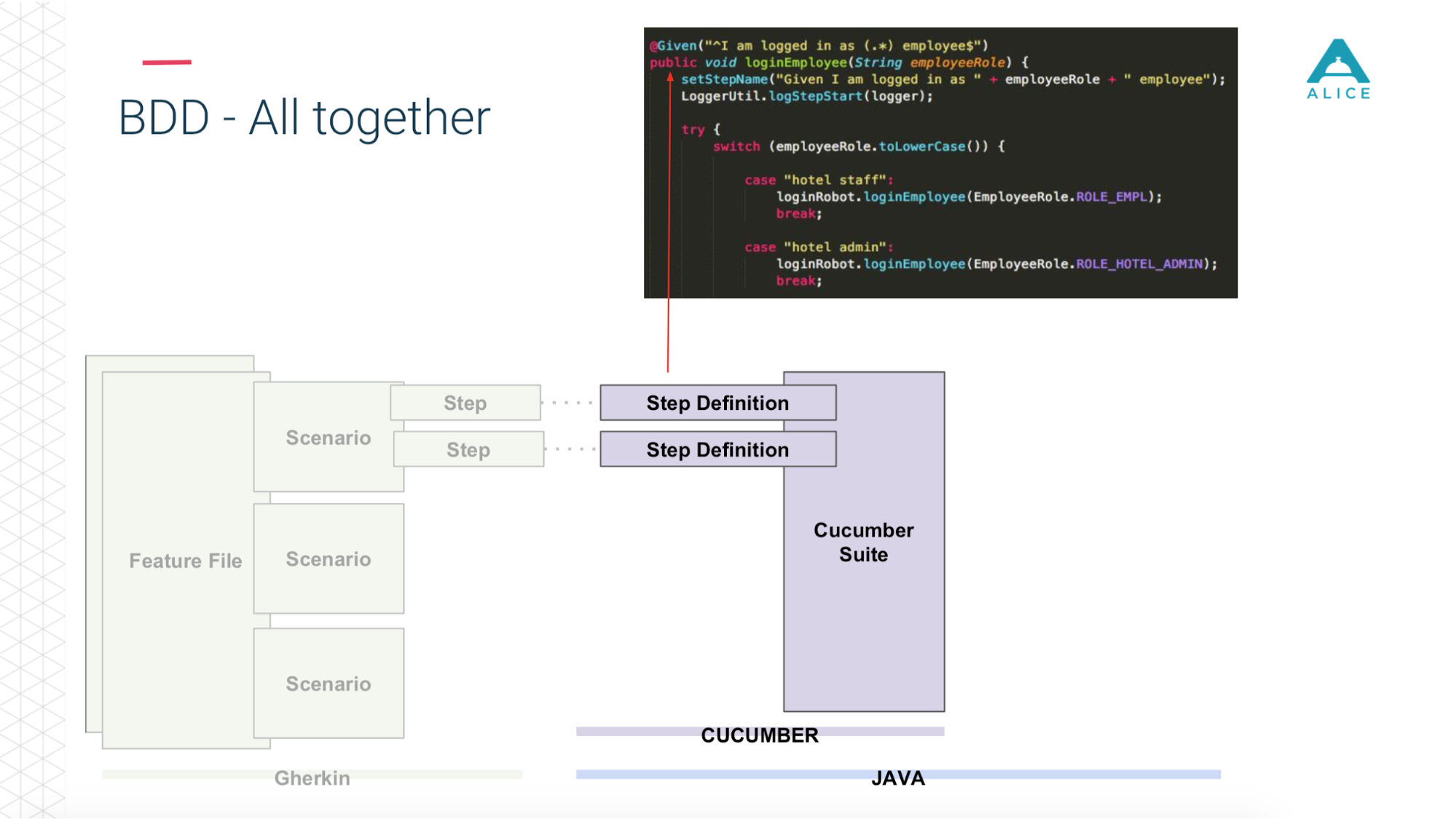
Этот код использует наше приложение.

И в зависимости от того, что мы выбрали: либо через Selenium Chrome идет в приложение ALICE.

Либо то же самое через API по http.
А затем (спасибо ребятам из Яндекса за Allure Reports) все это красиво показывается нам — как много времени заняло, какие тесты зафейлелись, на каком шаге и даже прикладывают скриншот, если что-то пошло не так.
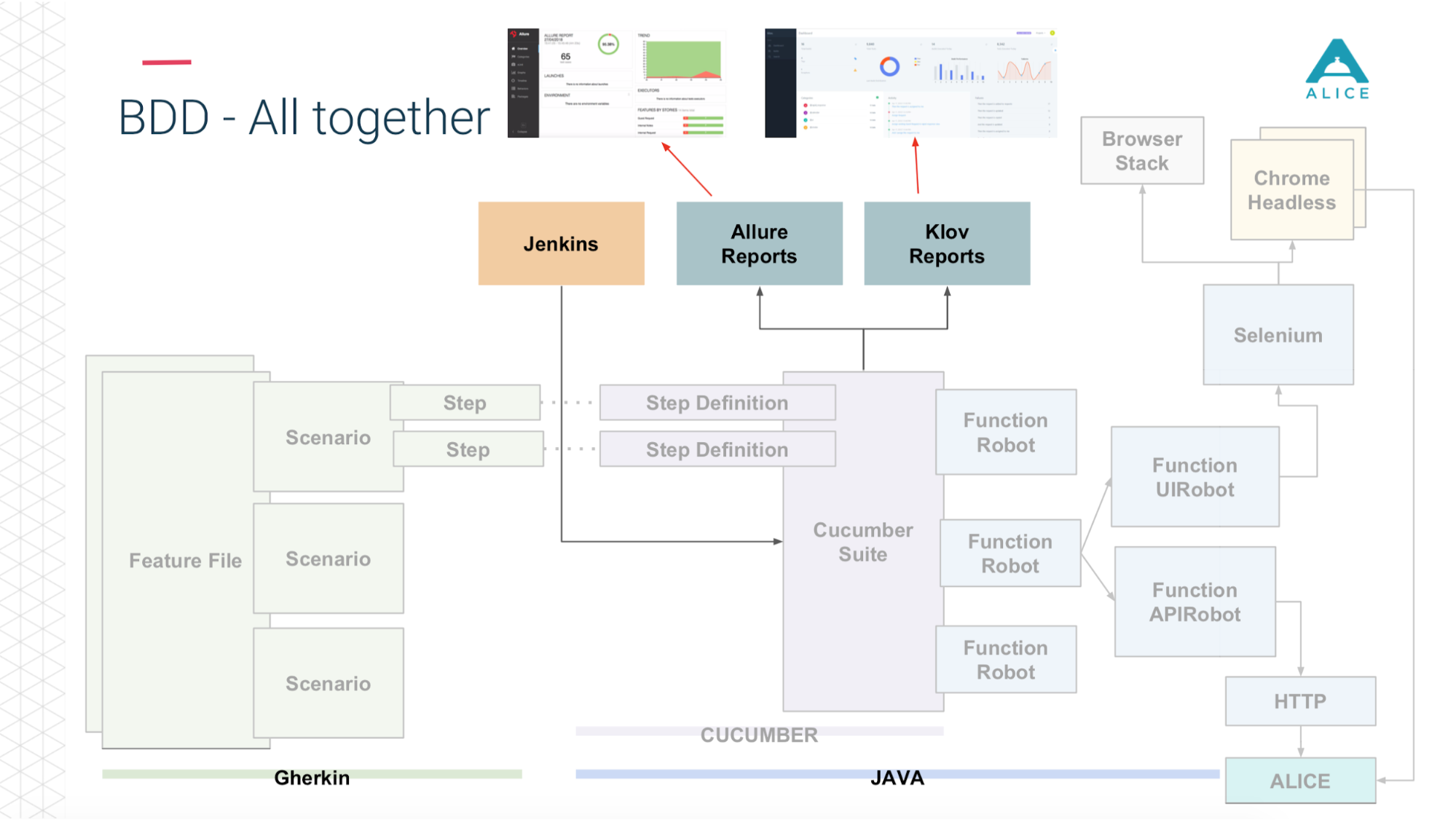
Вот вкратце то, что у нас уже было.
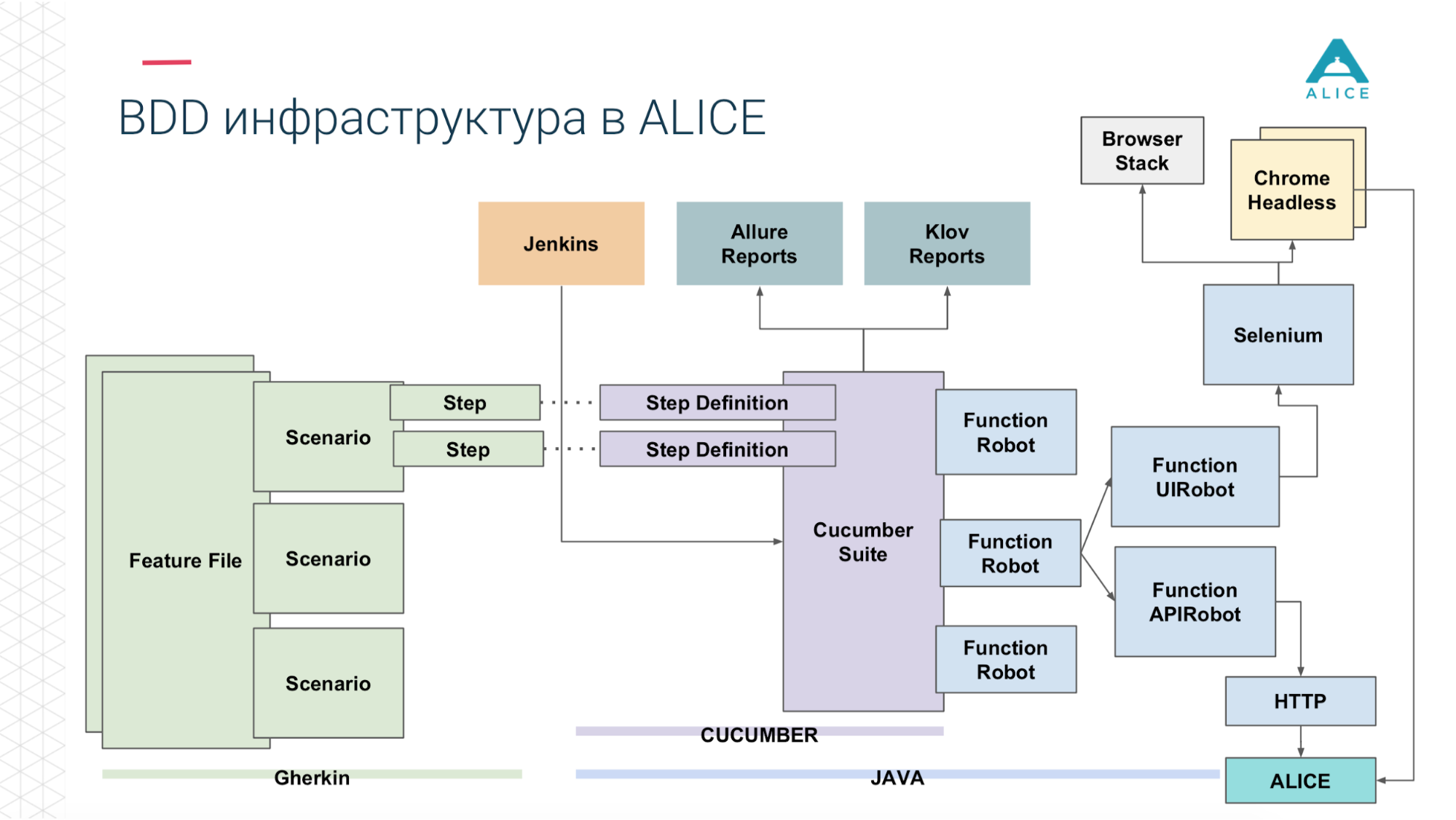
Как из этого собрать Load-тесты? У нас был Jenkins, который запускал Cucumber Suite. Это наши тесты и они шли в ALICE. В чем была главная проблема? Jenkins запускает тесты локально, он не может вечно масштабироваться. Да, мы хостимся в Амазоне, в облаке, мы можем попросить extra-large machine. Все равно в какой-то момент мы упремся, хотя бы, в сеть. Нужно как-то заоффлоудить эту нагрузку. Спасибо Амазон, он подумал за нас. Мы можем запаковать наш Cucumber Suite в Docker-контейнер и при помощи сервиса AWS (называется Fargate) сказать «а запусти нам их, пожалуйста». Проблема решена, мы можем запустить наши тесты уже в облаке.

Затем, так как мы в облаке, запустить 5-10-20 Cucumber Suite. Но есть нюанс: каждый запуск всех наших функциональных тестов генерирует репорт. Однажды мы запустили 400 тестов и сгенерировалось 400 репортов.
Спасибо в очередной раз ребятам из Яндекса за open source, мы почитали документацию, исходный код и поняли, что есть способы агрегировать все 400 отчетов в один. Чуть исправили данные, написали какие-то свои расширения и всё получилось.
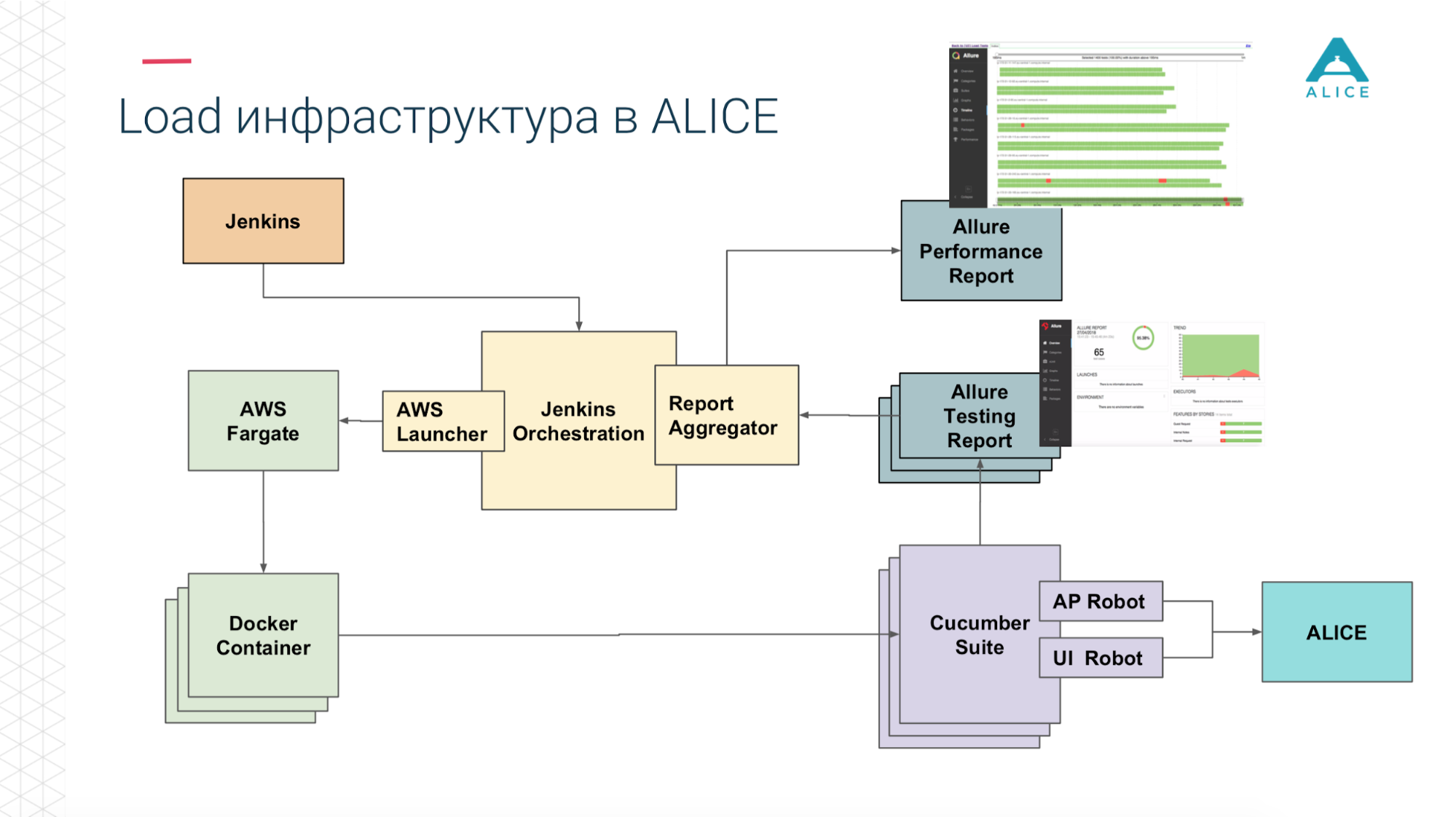
Теперь из Jenkins мы говорим «запусти нам 200 инстансов». Наш некий оркестрационный скрипт идет в Амазон, говорит «запусти 400 контейнеров». Каждый из них содержит наши интеграционные тесты, они генерируют отчет, отчет собирается через Aggregator в одну штуку, кладется в Jenkins, прикладывается к джобе, работает супер.
Но.
Я уверен, что многие из вас получали от тестировщиков странные вещи, типа «я играл в игру, 10 раз подпрыгнул, в это время люто нажимал на стрельбу и случайно задел кнопку выключения — персонаж начал мигать, зависать в воздухе, а потом компьютер выключился, разберись с этим». С человеком еще можно договориться и сказать, знаешь, это невозможно воспроизвести. Но у нас бездушные машины, они делают всё очень быстро и где-то не прогрузились данные, где-то не очень быстро отрендерилось, они пытаются нажать кнопку, а кнопки еще нет или она использует какие-то данные, которые еще не загрузились с сервера. Всё рушится и тест зафейлен. Хотя (я хочу сконцентрировать на этом внимание) у нас код на Java, который запускает Chrome, который через обертку на другой Java коннектится и что-то делает и все равно работает молниеносно.
Ну и очевидная проблема, вытекающая из этого: у нас 5 тыс. пользователей, а мы запустили всего 100 инстансов наших функциональных тестов и создали ту же самую нагрузку. Это не совсем то, что мы хотели, потому что мы планируем, что в следующем месяце у нас будет уже 6 тыс. пользователей. Такую нагрузку тяжело понять, понять сколько запустить потоков.
ОК, давайте «очеловечим» нашу систему. Так выглядит пользовательский интерфейс:

Кто-то звонит, консьерж хочет нажать кнопку «создать новый тикет», ему вылезает окно и он должен заполнить все поля.
Но это же не происходит мгновенно. Реальный человек пока доедет мышкой, пока начнет печатать, пока что-то выберет, пока нажмет Save. Поэтому давайте замедлять наши тесты.

Мы назвали это Human mode. Надо просто замерить, сколько длится шаг и чуть-чуть «поспать», если это было слишком быстро. Заодно мы можем замерить, сколько в принципе занял этот шаг — если 5 минут, то, наверное, user experience здесь поломан.
Так как у нас было довольно много тестов, переписывать каждый под эту штуку не стали. Взяли AspectJ, натянули на наш код, дописали еще 5 строчек кода, работает шикарно.
Короткое демо.


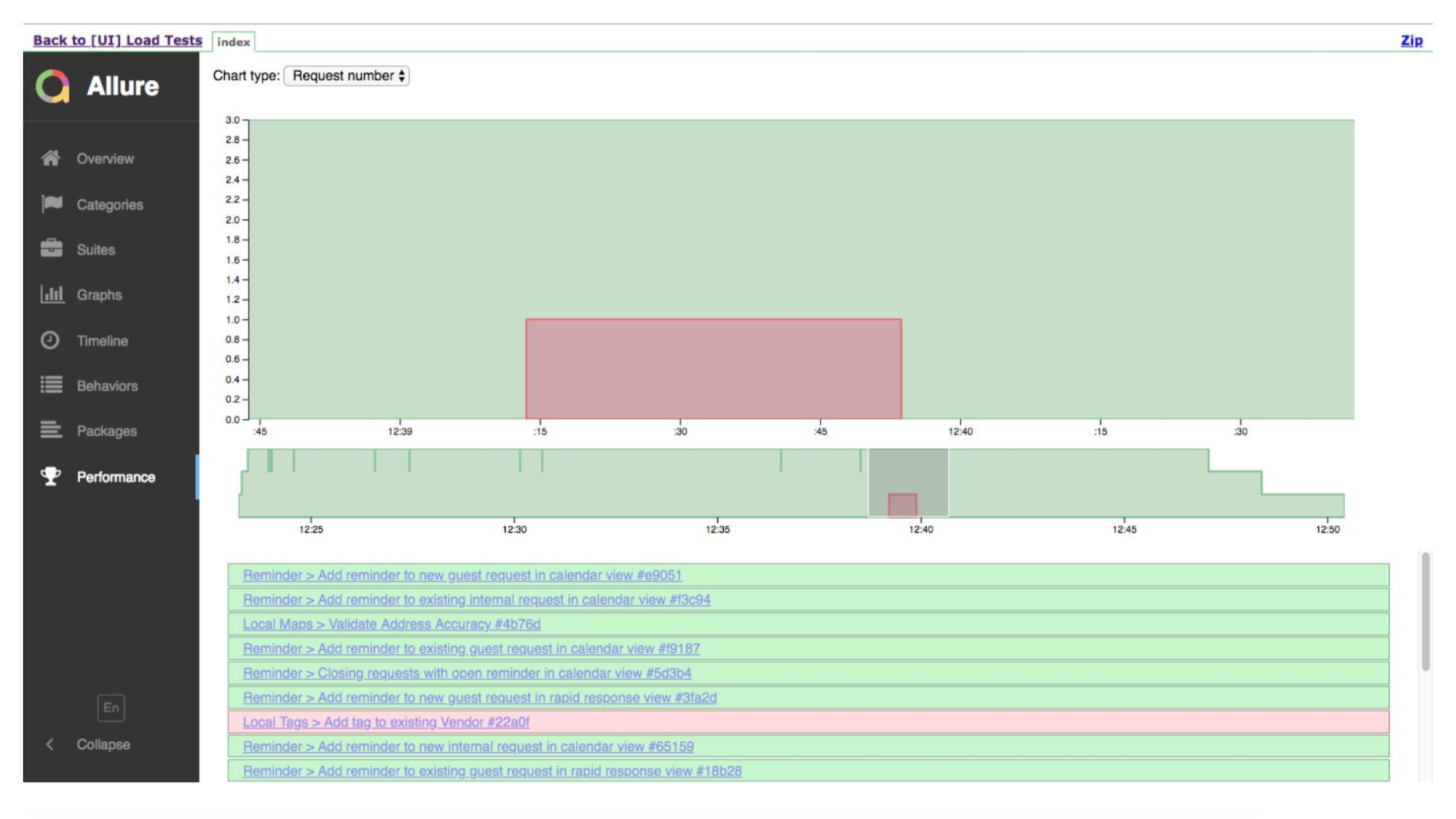
Это таймлайн запуска. Зеленые тесты — хорошо, где-то — плохо. Allure нам покажет детали, где зафейлилось.
А вот таймлайн, показывающий, что у нас было много инстансов. Они выполняли тест, где-то что-то упало.
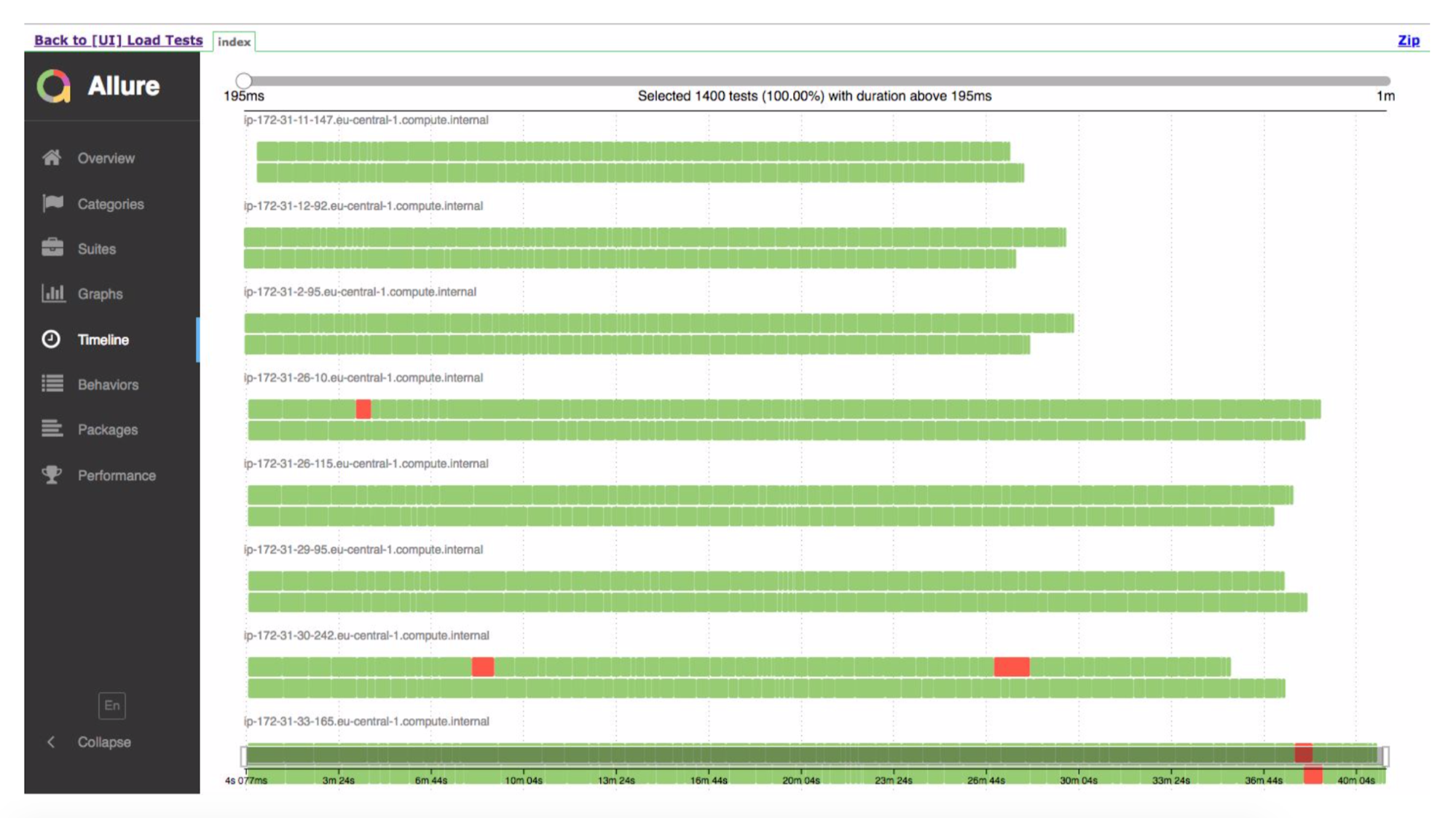
Система реально работает — на прошлой неделе сделали первые тесты на боевом продакшене.
Теперь о дальнейших шагах, как, мы считаем, это можно улучшить.

Самое главное, мы хотим, чтобы у людей был крутой user experience. Идея в том, что мы можем сгенерировать большую нагрузку на наше приложение и будто бы всё просто — банально померили производительность каждого запроса на сервер, продолжает ли он отвечать так же быстро или начались просадки по производительности (сервер стал медленнее обрабатывать входящие запросы). Но нет. В реальности, клиент/приложение может кидать на сервер сразу несколько запросов, кучей. И ждать, пока они все обработаются. И если один из запросов, самый долгий, как работал 5 секунд, так и продолжает работать 5 сек, то нам совершенно все равно, как работают все остальные — так же быстро или замедлились до 4 секунд. Ведь мы всё равно будем дожидаться самого долгого, пятисекундного. Или ты создал тикет, все отработало за одну миллисекунду, но тикет из-за внутренних кэшей индекса появился в системе слишком поздно. Обычный подход не решит эту проблему, поэтому мы хотим пробовать замерять все сценарии и смотреть, насколько реально стал хуже сценарий создания тикета.
Т.к. у нас все сценарии отталкиваются от юзкейсов, мы можем имитировать, запустив одного человека на ресепшене и 10 уборщиков. Потом 20 или 30 уборщиков. Но фронт людей все равно один. Т.е. мы можем генерировать реальную нагрузку по моделям поведения, очень близко к реалистичной нагрузке.
Также мульти-региональное тестирование. Нашей системой пользуются во всем мире (хотя все хостится в Америке) и поэтому мы можем сгенерировать нагрузку и из России и из Америки, чтобы посмотреть, у кого из них начнет быстрее тормозить.
Вопросы из зала
— Вы вынуждены писать большое количество логики и когда что-то чуть меняется, у вас ломается очень много всего в функциональных тестах. Получается, что у вас на поддержку тестов уходит времени едва ли не больше, чем на разработку?
— Да, но нет. Это BDD, это не совсем функциональные тесты, они ближе к интеграционным. И что бы мы не меняли, сценарий все равно остается один и тот же. Я нажимаю кнопку, вижу окно, в нем ввожу номер комнаты, с которой поступил запрос, имя человека и дату, на которую забронировать столик. Если изменилась разметка, поля поменялись местами, если в бэкенде что-то происходит по-другому — тест сохраняется, потому что мы на очень высоком уровне, мы нажимаем кнопки в браузере. Поэтому от большого количества изменений мы защищены. Есть моменты, когда все может разломаться. Поэтому в релиз-процедуре те ребята, которые пишут новую фичу — они отвечают за то, чтобы увидеть, что что-то сломалось и исправить. Но пока таких проблем в большом количестве не было.
— А у вас не было ситуации, что после одного изменения все тесты становятся красными.
— Не было. Теоретически, такое может случиться, если в сценарии не кнопка, а какой-то другой способ открыть окно для ввода данных про тикет. Но, как я ранее показывал, у нас все сценарии состоят из шагов. Шаги — это множество всего и, если у нас есть 100 сценариев, которые нажимают на одну и ту же кнопку, шаг все равно один. И если всё легло из-за этого конкретного шага, мы его исправляем, переписываем и все тесты сразу зеленеют.
Хотя один раз, когда мы случайно что-то сломали, у нас такое возникло. Осталось только 40% зеленого, хотя до этого было 99%. Это было одно маленькое изменение. Мы один шаг поправили (строчка кода) и все опять позеленело.
— У вас хоть и не интеграционные тесты, но и не совсем функциональные. Так или иначе это некий графический интерфейс, где нажимаются кнопки, происходит какое-то взаимодействие конкретно с внешней оболочкой. Я понимаю, что у вас в таком виде тесты, просто вы запускаете много потоков одновременно. А чем не устроили запросы, которые генерируются стандартными инструментами: JMeter, Gatling, которые никак не взаимодействуют с внешней оболочкой, а просто сыпят запросы на сервер?
— Все очень просто. Какова архитектура нашего приложения? У нас есть бэкенд, у нас есть фронтенд. Фронтенд — это веб. Есть мобильное приложение. И когда я создаю тикет, мой фронтенд подключен, например, еще и к ивент-серверам. Я создаю тикет на бэкенде и все люди, которые сидят в этом же отеле, смотрят тикеты в этом же отеле, им с ивент-серверов прилетит: ребята обновитесь, там данные изменились. И для того, чтобы все воедино собрать, у нас единая точка — это клиент. Он коннектится к большому количеству разнообразных компонент и либо нам программировать руками, что мы создали тикет в бэкенде и дальше мы подключаемся к ивент-серверу, зарегистрировались на нем и ждем от него каких-то событий. Либо просто запустили браузер, в котором уже все собрано воедино, этот код уже написан и мы все делаем как нам надо.
— Но это же разные подходы? Или мы работаем конкретно с сервером или с окошком. Можно же симулировать запросы сразу к нескольким серверам.
— Я поэтому рассказывал, что у нас функциональные роботы, которые вызываются из тестов. Есть те, которые поднимают Chrome и выполняют высокоуровневые нажимания. Есть те, которые не нажимают кнопку, ничего не происходит, но в момент создания тикета он отправляет запрос на сервер, и мы можем запускать то так, то так. Мы выбрали запуск через Chrome по одной простой причине — мы хотим имитировать реальных пользователей, то, как они реально пользуются. Пока у него прогрузилась страничка, пока у него все отрендерилось, пока отработали Java-скрипты и прочее. Мы хотим быть максимально близко к пользователю, а это реально веб.
— Но очень много вещей будет зависеть от того, какой у пользователя интернет, какое окружение. А вот конкретно работа приложения будет зависеть от вас уже и на вашей стороне. Вопрос, что мы тестируем: в принципе всё или какую-то часть отдельно?
— Хороший вопрос, поэтому я рассказывал про мульти-региональное тестирование. Мы можем попытаться сгенерировать трафик из Мексики, где, возможно, не очень хорошо с интернетом. Мы можем сгенерировать трафик из Америки, которая очень близко к региону Амазона, на котором все хостится. Но если человек на фоне открыл YouTube или начал майнить биткоины, то мы уже это воспроизвести не можем. Тут придется ждать звонка от реальных клиентов и выезжать к ним, разбираться что происходит. Это не серебряная пуля, да.
— Вы деплоите тесты. А у вас какой-то Selenium Grid поднимается или как? Вы же еще их мульти-региональными делаете.
— Просто много Cucumber’ов: все компилится в JAR, JAR запаковываем в Docker image и Fargate’у говорим, запусти этот image в контейнере. А flood.io запускал grid из Selenium и к нему не было доступа, поэтому наши тесты не работали.
— Насколько у вас широкая область тестирования? Ты упоминал, что у вас Chrome, что есть приложение на телефоне. А если я запущу Internet Explorer 4 (если где-нибудь откопаю), то оно может упасть? Или под какой-то очень специфической версией Android или еще что-нибудь.
— К счастью, это enterprise. А enterprise обладает одной очень интересной штукой, а именно requirements. Плюс мы естественно считерили — у нас мобилка это гибридное приложение, оно тоже идет на бэкенд, просто web view. Поэтому если Android может запустить web view и он нормального функционала, с этим особо проблем нет.
— Я прослушал, где вы тестируете, куда вы долбите Load-нагрузкой? Прямо на продакшн?
— Открываем слайд.
Там Environment и выпадающий список. И мы оттуда исключили продакшн. Там была интересная история, когда это еще не был Load, а просто была автоматизация. Там ты вводил кастомный 4-буквенный урл, по которому идти, он дальше клеил aliceapp.com. Потом мы сделали Load-тесты и это оттуда убрали, потому что мы случайно положили препродакшн. Не так, что он просто ушел в 504, а вообще обратно не встал, потому что развалилась репликация MySQL и развалилась синхронизация с ElasticSearch.
— Если вы долбите не продакшн (что хорошо), как вы потом понимаете, что на продакшн ровно также все произойдет? Вы же явно не поднимаете ровно тот же объем инстансов.
— Наше Load-окружение настроено идентично продакшену и у нас есть процедура, каждый день дамп с продакшена базы загружать на окружение. Т.е. мы имитируем копию.
— А вы его держите все время, не поднимаете на время тестов?
— Нет, мы не держим. Мы стартап, у нас в пятницу выключается всё, кроме продакшна, в понедельник по запросу включается обратно.
— Правильно ли я понял, что ваши тесты имитируют поведение пользователей и заполняют поля, т.е. непосредственно в html кликают кнопки или делают запросы методом API?
— Открывается браузер и Selenium позволяет получить прямой доступ к DOM-модели этого браузера: дергать любые ивенты, можно на поле ввода сказать, вот тут key down событие прошло, а вот на это — клик. И мы именно этими терминами оперируем.
— Кто пишет тесты? Разработчики, тестировщики?
— В данный момент есть специально команда. Сначала не было ничего, мы страдали. Затем появился QC, мы стали страдать меньше, страдал QC. Они сделали список Smoke-тестов и некий чек-лист. Затем мы пришли к ним и сказали «дайте свой чек-лист, мы его автоматизируем». Дальнейший шаг — это заставить разработчиков при разработке нового функционала писать эти тесты, потому что инфраструктура есть, все фреймворки есть, им нужно просто реализовать нажимание на кнопочки и прочие такие штуки.
Еще доклады с Pixonic DevGAMM Talks
- Использование Consul для масштабирования stateful-сервисов (Иван Бубнов, DevOps в компании BIT.GAMES);
- CICD: бесшовный деплой на распределенные кластерные системы без даунтаймов (Егор Панов, системный администратор Pixonic);
- Практика использования модели акторов в бэкэнд-платформе игры Quake Champions (Роман Рогозин, backend-разработчик Saber Interactive);
- Архитектура мета-сервера мобильного онлайн-шутера Tacticool (Павел Платто, Lead Software Engineer в PanzerDog);
- Как ECS, C# Job System и SRP меняют подход к архитектуре (Валентин Симонов, Field Engineer в Unity).
Комментарии (8)

polarnik
01.11.2018 19:23Здравствуйте. Интересная статья. Коллеги на одном из проектов пробовали сделать такое. Cucumber для нагрузки. Доступность облаков будила фантазию. Но не сделали — это не для всех задач подходит.
На другом проекте также использовали функциональные тесты, уже успешно и регулярно. Но не для нагрузки в широком смысле понимания, а как индикатор появления узких мест после внесения небольшой изменений в проект. Думаю, как и у Антона Косякина. Подход такой:
- запуск тестов + сбор метрик производительности (длительность выполнения, память, процессор, количество error/warn/info/debug в логе)
- изменение системы
- запуск тех же тестов + сбор метрик производительности
- сравнение метрик от теста 1 и 2 на одном графике — и так от сборки к сборке
Такой вариант хорошо работает. Если показатели производительности ухудшились, то причина скорее всего в функциональности и изменениях, которые были между запусками тестов. То есть — причина более-менее локализована. Это плюс. И очень быстрая обратная связь разработчикам — это самый главный плюс. Они не боятся вносить изменения в код.
Из минусов — нет точного понимания, какие будут показатели RPS (запросов в сек), TPS (операций в сек). Ведь функциональный тест может зависнуть, и если вчера за минуту выполнялось 60 тестов (1 TPS), то сегодня выполняется только 1 тест в минуту (1/60 TPS) — то есть нагрузка на систему подаётся в 10 раз меньшая, и результаты запусков не сравнимы. Предположу, что в данном подходе такое может случиться. Это открытая модель нагрузки. В JMeter/Gatling/Yandex.Tank контроль TPS/RPS — решаемая задача, с понятными ограничениями.
Также, достаточно дорого поддерживать много генераторов нагрузки, если она подаётся браузером — браузер требует очень много оперативной памяти, JMeter требует сильно меньше, а Gatling, так как гораздо меньше потоков, требует ещё меньше памяти. Для реализации нагрузки 100 операций в минуту через браузер (много)/http-api-robot (только аутентификация), может понадобится 20 станций. С ростом потребностей (1000 операций в минуту), доля http-api-robot будет расти, а доля браузера снижаться. А потом (10 000 операций в минуту) и вовсе решите перейти на модель, когда всю нагрузку подаёт 4 станции с Gatling/JMeter, и ещё на одной параллельно выполняется функциональный тест в BDD-формате — для оценки отзывчивости интерфейса под высокой нагрузкой.
insomnia77
01.11.2018 21:13Привет. Спасибо за статью.
1. В Allure 2 нет вкладки perfomance. Вы что-то самостоятельно кастомизировали? Можете поделиться кастомизацией Allure?
2.Eще у них есть решение для браузера, а так как у нас большая часть функционала находится именно там, то в браузере он тоже что-то делает и дает какие-то метрики.
Я правильно понимаю это что-то типа плагина, который настраивается на агенте с которого происходит запуск? Вы его настраивали? Какие метрики можно получить кроме скорости загрузки страниц?
igor_suhorukov
02.11.2018 11:53Мои коллеги и товарищи делали очень полезный фреймворк для нагрузочных тестов на JVM nonocloud https://m.habr.com/company/jugru/blog/275883/
g6uru
Основная проблем gherkin это отсутвтие блоков, что делает его крайне не удобным языком для тестов. Взять те же отели, нам нужно посмотреть что у нас создалась бронь.
Чтобы проверить, на то что боннирование создалось. Нам надо убедится что создалась 1 запись в бд. Но посравнению с чем?
или нам очищать все бронирования перед началом теста:
Т.е. мы или каждый раз чистим базу, или перед тестом сохраняем количество бронирований в глобальной переменной. Что в любом случае дает знатный костыль.
Было удобнее если бы в функционале gherkin появилось что-то вроде:
Без подобных вещей все тесты написанные для gherkin-спецификаций, подверженны огромной энтропии. Приэтом сами спецификации выглядят прекрасно.
insomnia77
Привет. Ты сам задаешь реализации для Gherkin шагов — их можно модифицировать как угодно. Начиная с 3 версии cucumber поддерживаются пост-действия и можно не только делать приведение к начальному состоянию в предыстории, но и после выполнения сценариев.
Никакой проблемы реализовать подобный сценарий нет:
Дано незарегистрированный пользователь
Создается 1 бронирование в системе:
Когда пользователь заходит на сайт
И делает бронирование
Не понял в чем проблема с Gherkin.
lxsmkv
Думаю как-то так это решается:
Дано незарегистрированный пользователь
Дано в системе 0 бронирований от пользователя.
Когда пользователь заходит на сайт
И делает бронирование
То в системе 1 бронирование от пользователя
g6uru
Да, это можно так решить. Но тест на степ
Дано в системе 0 бронирований от пользователяэто по факту,DELETE FROM booking WHERE user_id = ?. Или 'TRUNCATEusers', что на самом деле не совсем корректный тест, так как мы искуственно подчищаем базу.Мы проверяем увеличене на единицу.
Хотелось бы иметь что-то вроде
lxsmkv
Не вижу, честно говоря, в этом ничего искуственного. Ну а как еще подготовить эксперимент проверяющий добавление данных в базу? Представьте себе такой эксперимент: мы хотим убедиться, что если налить в чашку 200 мл воды, то вода не перельется через край. (Допустим мы должны проверит вместительность чашки)
Не опустошая чашку перед экспериментом у нас может получиться ложноотрицательный результат. Вы естественно подготовите чашку вылив из нее все содержимое и вытерев ее. Это не кажется вам ничем искуственным? Так и с базой, ничего искуственного в этом нет. Эксперимент всегда упрощает все до необходимого минимума. Мы также не льем в чашку кофе(хотя это будущий пользовательский сценарий), а льем воду, потому что это дешево, удобно и доступно в ходе эксперимента.