
Предисловие

В данной статье мы изучим несколько аспектов SVM:
- теоретическую составляющую SVM;
- как алгоритм работает на выборках, которые невозможно разбить на классылинейно;
- пример использования на Python и имплементация алгоритма в библиотеке SciKit Learn.
В следующих статьях, я постараюсь рассказать о математической составляющей этого алгоритма.
Как известно, задачи машинного обучения разделены на две основные категории — классификация и регрессия. В зависимости от того, какая из этих задач перед нами стоит, и какой у нас имеется датасет для этой задачи, мы выбираем какой именно алгоритм использовать.
Метод Опорных Векторов или SVM (от англ. Support Vector Machines) — это линейный алгоритм используемый в задачах классификации и регрессии. Данный алгоритм имеет широкое применение на практике и может решать как линейные так и нелинейные задачи. Суть работы “Машин” Опорных Векторов проста: алгоритм создает линию или гиперплоскость, которая разделяет данные на классы.
Теория
Основной задачей алгоритма является найти наиболее правильную линию, или гиперплоскость разделяющую данные на два класса. SVM это алгоритм, который получает на входе данные, и возвращает такую разделяющую линию.
Рассмотрим следующий пример. Допустим у нас есть набор данных, и мы хотим классифицировать и разделить красные квадраты от синих кругов (допустим позитивное и отрицательное). Основной целью в данной задаче будет найти “идеальную” линию которая разделит эти два класса.
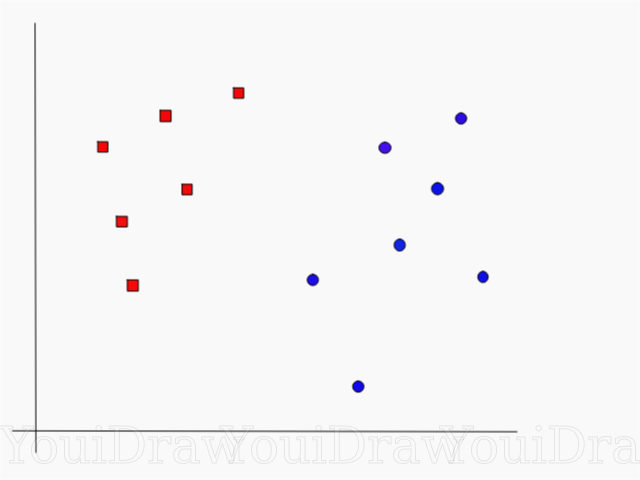
Найдите идеальную линию, или гиперплоскость, которая разделит набор данных на синий и красный классы.
На первый взгляд, не так уж и сложно, правда?
Но, как вы можете заметить, нет одной, уникальной, линии, которая бы решала такую задачу. Мы можем подобрать бесконечное множество таких линий, которые могут разделить эти два класса. Как же именно SVM находит “идеальную” линию, и что в его понимании “идеальная”?
Взгляните на пример ниже, и подумайте какая из двух линий (желтая или зеленая) лучше всего разделяет два класса, и подходит под описаниие “идеальной”?
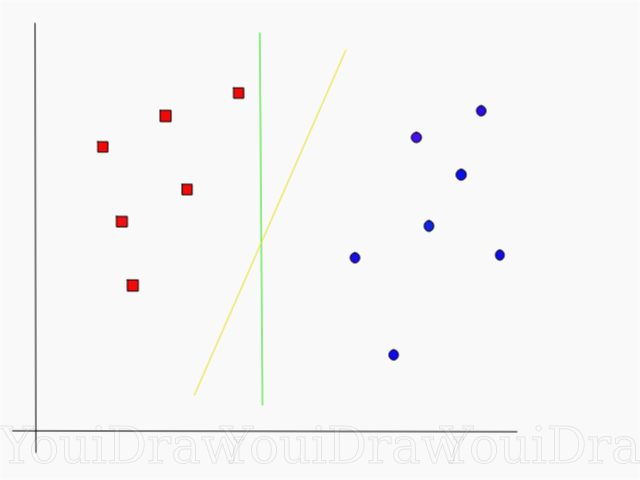
Какая линия лучше разделяет набор данных по вашему мнению?
Если вы выбрали желтую прямую, я вас поздравляю: это та самая линия, которую бы выбрал алгоритм. В данном примере мы можем интуитивно понять что желтая линия разделяет и соответственно классифицирует два класса лучше зеленой.
В случае с зеленой линией — она расположена слишком близко к красному классу. Несмотря на то, что она верно классифицировала все объекты текущего набора данных, такая линия не будет генерализованной — не будет так же хорошо вести себя с незнакомым набором данных. Задача нахождения генерализованной разделяющей двух классов является одной из основных задач в машинном обучении.
Как SVM находит лучшую линию
Алгоритм SVM устроен таким образом, что он ищет точки на графике, которые расположены непосредственно к линии разделения ближе всего. Эти точки называются опорными векторами. Затем, алгоритм вычисляет расстояние между опорными векторами и разделяющей плоскостью. Это расстояние которое называется зазором. Основная цель алгоритма — максимизировать расстояние зазора. Лучшей гиперплоскостью считается такая гиперплоскость, для которой этот зазор является максимально большим.

Довольно просто, не так ли? Рассмотрим следующий пример, с более сложным датасетом, который нельзя разделить линейно.
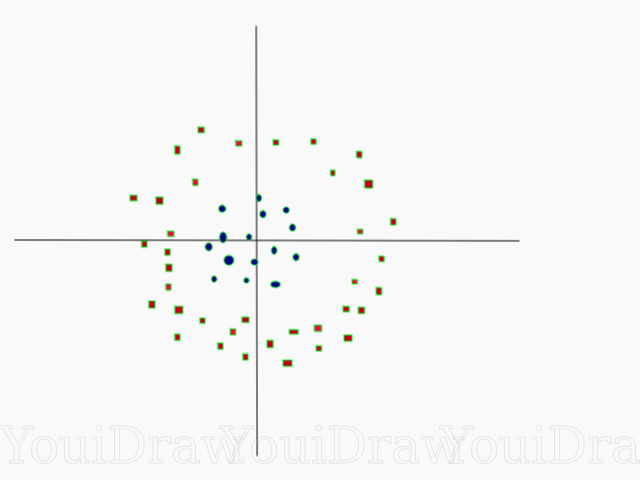
Очевидно, что этот набор данных нельзя разделить линейно. Мы не можем начертить прямую линию, которая бы классифицировала эти данные. Но, этот датасет можно разделить линейно, добавив дополнительное измерение, которое мы назовем осью Z. Представим, что координаты на оси Z регулируются следующим ограничением:
Таким образом, ордината Z представлена из квадрата расстояния точки до начала оси.
Ниже приведена визуализация того же набора данных, на оси Z.
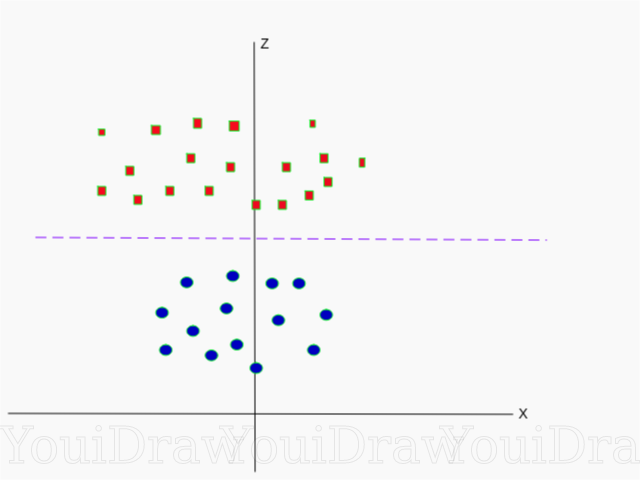
Теперь данные можно разделить линейно. Допустим пурпурная линия разделяющая данные z=k, где k константа. Если , то следовательно и — формула окружности. Таким образом, мы можем спроэцировать наш линейный разделитель, обратно к исходному количеству измерений выборки, используя эту трансформацию.
В результате, мы можем классифицировать нелинейный набор данных добавив к нему дополнительное измерение, а затем, привести обратно к исходному виду используя математическую трансформацию. Однако, не со всеми наборами данных можно с такой же легкостью провернуть такую трансформацию. К счастью, имплементация этого алгоритма в библиотеке sklearn решает эту задачу за нас.
Гиперплоскость
Теперь, когда мы ознакомились с логикой алгоритма, перейдем к формальному определению гиперплоскости
Гиперплоскость — это n-1 мерная подплоскость в n-мерном Евклидовом пространстве, которая разделяет пространство на две отдельные части.
Например, представим что наша линия представлена в виде одномерного Евклидова пространства (т.е. наш набор данных лежит на прямой). Выберите точку на этой линии. Эта точка разделит набор данных, в нашем случае линию, на две части. У линии есть одна мера, а у точки 0 мер. Следовательно, точка — это гиперплоскость линии.
Для двумерного датасета, с которым мы познакомились ранее, разделяющая прямая была той самой гиперплоскостью. Проще говоря, для n-мерного пространства существует n-1 мерная гиперплоскость, разделяющая это пространство на две части.
КОД
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])Точки представлены в виде массива X, а классы к которому они принадлежат в виде массива y.
Теперь мы обучим нашу модель этой выборкой. Для данного примера я задал линейный параметр “ядра” классификатора (kernel).
from sklearn.svm import SVC
clf = SVC(kernel='linear')
clf = SVC.fit(X, y)
Предсказание класса нового объекта
prediction = clf.predict([[0,6]])Настройка параметров
Параметры — это аргументы которые вы передаете при создании классификатора. Ниже я привел несколько самых важных настраиваемых параметров SVM:
“C”
Данный параметр помогает отрегулировать ту тонкую грань между “гладкостью” и точностью классификации объектов обучающей выборки. Чем больше значение “С” тем больше объектов обучающей выборки будут правильно классифицированы.

В данном примере есть несколько порогов принятия решений, которые мы можем определить для этой конкретной выборки. Обратите внимание на прямую (представлена на графике в виде зеленой линии) порога решений. Она довольно таки проста, и по этой причине, несколько объектов были классифицированы неверно. Эти точки, которые были классифицированы неправильно называются выбросами в данных.
Мы также можем настроить параметры таким образом, что в конечном итоге получим более изогнутую линию (светло-голубой порог решений), которая будет классфицировать асболютно все данные обучающей выборки правильно. Конечно, в таком случае, шансы того, что наша модель сможет генерализовать и показать столь же хорошие результаты на новых данных, катастрофически мала. Следовательно, если вы пытаетесь достигнуть точности при обучении модели, вам стоит нацелиться на что-то более ровное, прямое. Чем выше число “С” тем более запутанная гиперплоскость будет в вашей модели, но и выше число верно-классифицированных объектов обучающей выборки. Поэтому, важно “подкручивать” параметры модели под конкретный набор данных, чтобы избежать переобучения но, в то же время достигнуть высокой точности.
Гамма
В официальной документации библиотека SciKit Learn говорится, что гамма определяет насколько далеко каждый из элементов в наборе данных имеет влияние при определении “идеальной линии”. Чем ниже гамма, тем больше элементов, даже тех, которые достаточно далеки от разделяющей линии, принимают участие в процессе выбора этой самой линии. Если же, гамма высокая, тогда алгоритм будет “опираться” только на тех элементах, которые наиболее близки к самой линии.
Если задать уровень гаммы слишком высоким, тогда в процессе принятия решения о расположении линии будут учавствовать только самые близкие к линии элементы. Это поможет игнорировать выбросы в данных. Алгоритм SVM устроен таким образом, что точки расположенные наиболее близко относительно друг друга имеют больший вес при принятии решения. Однако при правильной настройке «C» и «gamma» можно добиться оптимального результата, который построит более линейную гиперплоскость игнорирующую выбросы, и следовательно, более генерализуемую.
Заключение
Я искренне надеюсь, что эта статья помогла вам разобраться в сути работы SVM или Метода Опорных Векторов. Я жду от вас любых комментариев и советов. В последующих публикациях я расскажу о математической составляющей SVM и о проблемах оптимизации.
Источники:
Официальная документация SVM в пакете SciKit Learn
Блог TowardsDataScience
Siraj Raval: Support Vector Machines
Видео курса Intro to Machine Learning Udacity об SVM: Gamma
Wikipedia: SVM
Комментарии (17)

roryorangepants
01.11.2018 17:28+3Краткий обзор SVM с каждым днем выглядит все более и более похоже на экскурсию в музей.
Sklott
02.11.2018 09:50+1Считать что нейронные сети лучше, чем SVM — это всё равно, что считать что переменный ток лучше постоянного. Была статейка на эту тему тут, но что-то никак не могу найти…
iworeushankaonce Автор
02.11.2018 10:14Согласен. Я никак не хотел устраивать холивар. Для каждого алгоритма есть определенная задача, которую он решает лучше всего. Есть задачи, для решения которых, лучше всего использовать SVM, ввиду ряда факторов, вроде вычислительной простоты SVM относительно нейронок, например. Проще говоря, нет абсолютно «идеального» алгоритма, как и идеального ЯП: каждый рассчитан на решение определенного ряда задач.
xgbaggins
03.11.2018 09:07+1>вроде вычислительной простоты SVM
Да там ей и не пахнет. С ядрам там же то ли квадрат, то ли куб будет, на скромных нынче выборках от 10-20k+ все быстро заглохнет. И еще, NN вы могли бы прям в статьей на голом numpy написать, а SVM?
roryorangepants
02.11.2018 10:31+1Во-первых, заметьте: в моем сообщении не было ни слова про нейронные сети, это вы сказали.
Во-вторых, прошу, покажите мне реальный датасет и задачу, где SVM был бы SotA-алгоритмом в данный момент.Sklott
02.11.2018 12:36+1Половина NLP сидит на SVM, и не собирается на сетки переползать для этих тех задач.
roryorangepants
02.11.2018 14:15+1Пруфы, пожалуйста.
SotA-пейперы по NLP идут или по пути deep learning подхода (скапитаню: это сети), или по пути генерации лингвистических фич, поверх которых и логрег даёт хорошие результаты.
Предполагаю, что вы говорите про второй кейс. Так вот, мой вопрос актуален. Покажите мне реальную задачу, где бустинг или сетка поверх ваших NLP-шных фич будут давать скор хуже, чем SVM.
xgbaggins
03.11.2018 09:59>Половина NLP сидит на SVM
Вы с таким же успехом могли бы сидеть и на логистической регрессии, фичи и данные важнее алгоритма в таких относительно простых линейных моделях. Вот у нас в конторе половина старого NLP как раз на LR, были бы данные, а алгоритм найдется
> и не собирается на сетки переползать для этих тех задач.
А зря, упускаете много новых клёвых штук, типа word embeddings и transfer learning, которые сейчас сильно рвут классический NLP на бенчмарках — ruder.io/nlp-imagenet. Профит причем скорее не от алгоритма отдельно, а потому что научились хорошо использовать неразмеченные данные для улучшения моделей
yellowmonster
02.11.2018 13:13+1можно чуть подробнее описать, для чего нужно манипулировать параметром гамма?
(понятно, что рандомным подбором можно повысить качество модели, но в чем теоретический смысл?)iworeushankaonce Автор
02.11.2018 17:35Вы правы, я исправил статью, добавив более детальное описание. Ответ на ваш вопрос приведен ниже.
Если задать уровень гаммы слишком высоким, тогда в процессе принятия решения о расположении линии будут учавствовать только самые близкие к линии элементы. Это поможет игнорировать выбросы в данных. Алгоритм SVM устроен таким образом, что точки расположенные наиболее близко относительно друг друга имеют больший вес при принятии решения. Однако при правильной настройке «C» и «gamma» можно добиться оптимального результата, который построит более линейную гиперплоскость игнорирующую выбросы, и следовательно, более генерализуемую.
Теоретический смысл в настройке степени «реагируемости» модели к выбросам. Но, этим он не ограничивается.
synedra
02.11.2018 18:13+1Самое обидное, что уже которую по счёту популярную статью читаю про SVM, и каждый раз «Строим такую гиперплоскость (гиперплоскость — это то-то), чтоб классы точек лежали от неё по разные стороны, а ежели такой гиперплоскости нет — то происходит магия, и классификатор всё равно нормально работает». Вот про эту магию бы чего-нибудь.
dmagin
А где тут «машинное обучение»? Вроде никто никого не обучает.
Почему тогда «метод опорных векторов», а не «метод опорных точек»?
iworeushankaonce Автор
«Машинное обучение» тут в том, что алгоритм обучаясь на обучающей выборке, строит такую гиперплоскость, которая бы в дальнейшем помогала классифицировать, если это задача классификации, ранее неизвестный объект по заданным признакам.
На второй вопрос детальный ответ здесь