

Дисклеймер
Данная статья не содержит материал, который стоит применять в реальных проектах. Это просто расширение границ, в которых воспринимается язык программирования.
Прежде, чем приступить к повествованию, настоятельно рекомендую ознакомиться с первым постом про StructLayout, т.к. там разобран пример, который будет использоваться в этой статье (Впрочем, как и всегда).
Предыстория
Начиная писать код к этой статье, я хотел сделать что-нибудь интересное с помощью языка ассемблера. Хотелось как-то нарушить стандартную модель выполнения и получить действительно необычный результат. И вспомнив, с какой частотой люди говорят, что ссылочный тип отличается от значимого тем, что первый располагается в куче, а второй на стеке, я решил использовать ассемблер, чтоб показать, что ссылочный тип может жить и на стеке. Однако я начал сталкиваться с разного рода проблемами, например, возврат нужного адреса и его представление в качестве управляемой ссылки (до сих пор работаю над этим). Так я начал хитрить и делать то, что не получается на ассемблере, на C#. И в конечном итоге ассемблера не осталось вообще.
Также рекомендация по прочтению — если вы хорошо знакомы с устройством ссылочных типов, рекомендую пропустить теорию про них (будут приведены только основы, ничего интересного).
Немного о внутреннем устройстве типов
Хочется напомнить, что разделение памяти на стек и кучу происходит на уровне .NET, причем это деление является чисто логическим, физически никакой разницы между областями памяти под кучу и под стек нет. Разницу в производительнсти обеспечивает уже конкретно работа с этими областями.
Как же тогда выделить память на стеке? Для начала давайте разберемся, как же устроен этот загадочный ссылочный тип и что есть в нем, чего нет в значимом.
Итак, рассмотрим простейший пример с классом Employee.
public class Employee
{
private int _id;
private string _name;
public virtual void Work()
{
Console.WriteLine(“Zzzz...”);
}
public void TakeVacation(int days)
{
Console.WriteLine(“Zzzz...”);
}
public static void SetCompanyPolicy(CompanyPolicy policy)
{
Console.WriteLine("Zzzz...");
}
}
И взглянем на то, как он представлен в памяти.
UPD: Рассматривается этот класс на примере 32-битной системы.

Таким образом, кроме памяти под поля, мы имеем еще два скрытых поля — индекс блока синхронизации (слово заголовка объекта на картинке) и адрес таблицы методов.
Первое поле, оно же индекс блока синхронизации, нас не особо интересует. При размещении типа я решил его опустить. Сделал я это по двум причинам:
- Я очень ленивый (я не говорил, что причины будут разумные)
- Для базового функционирования объекта это поле не обязательно
Но коль мы уже заговорили, считаю правильным сказать пару слов об этом поле. Используется оно для разных целей (хеш-код, синхронизация). Верней само поле является просто индексом одного из блоков синхронизации, относящихся с данному объекту. Сами блоки расположены в таблице блоков синхронизации(а-ля глобальный массив). Создание такого блока — операция довольно большая, так что он не создается, если он не нужен. Более того, при использовании тонких блокировкок туда будет записан идентификатор потока, получившего блокировку (вместо индекса).
Второе поле для нас намного важнее. Благодаря таблице методов типа возможен такой мощнейший инструмент, как полиморфизм (которым, кстати, не обладают структуры, короли стека). Допустим, что класс Employee дополнительно реализует три интерфейса: IComparable, IDisposable и ICloneable.
Тогда таблица методов будет выглядеть как-то так
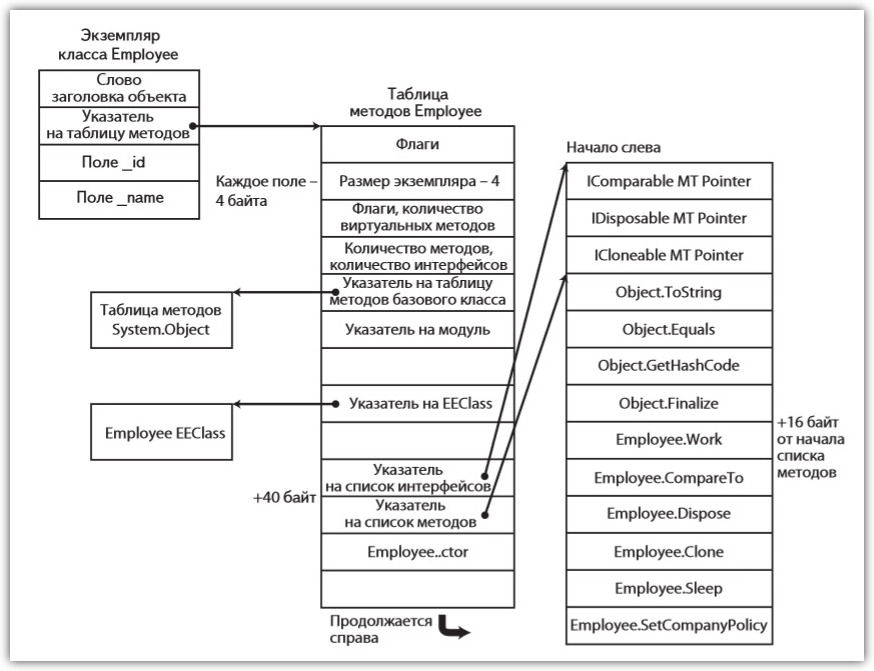
Картинка очень крутая, там в принципе все расписано и понятно. Если на пальцах и коротко, то вызов виртуального метода происходит не напрямую по адресу, а по смещению в таблице методов. В иерархии одни и те же виртуальные методы будут располагаться по одинаковому смещению в таблице методов. То есть мы на базовом классе вызываем метод по смещению, не зная, таблица методов какого именно типа будет использована, но зная, что по этому смещению будет самый актуальный метод для типа времени выполнения.
Также стоит помнить, что ссылка на объект указывает как раз на таблицу методов.
Долгожданный пример
Начнем с классов, которые помогут нам в нашей цели. С помощью StructLayout (я правда пытался без него, но не вышло) я написал простейшие мапперы указателей в управляемые типы и обратно. Получить указатель из управляемой ссылки довольно легко, а вот обратное преобразование вызвало у меня трудности и я, недолго думая, применил свой любимый атрибут. Чтоб держать код в одном ключе, сделал в 2 стороны одним способом.
// Предоставляет нужные нам сигнатуры
public class PointerCasterFacade
{
public virtual unsafe T GetManagedReferenceByPointer<T>(int* pointer) => default(T);
public virtual unsafe int* GetPointerByManagedReference<T>(T managedReference) => (int*)0;
}
// Предоставляет нужную нам логику
public class PointerCasterUnderground
{
public virtual T GetManagedReferenceByPointer<T>(T reference) => reference;
public virtual unsafe int* GetPointerByManagedReference<T>(int* pointer) => pointer;
}
[StructLayout(LayoutKind.Explicit)]
public class PointerCaster
{
public PointerCaster()
{
pointerCaster= new PointerCasterUnderground();
}
[FieldOffset(0)]
private PointerCasterUnderground pointerCaster;
[FieldOffset(0)]
public PointerCasterFacade Caster;
}
Для начала напишем метод, который принимает указатель на некоторую память(не обязательно на стеке, кстати) и конфигурирует тип.
Для простоты нахождения адреса таблицы методов я создаю тип в куче. Уверен, что таблицу методов можно найти и другими способами, но я не ставил себе целью оптимизировать этот код, мне интереснее было сделать его понятным. Далее, с помощью ранее описанных преобразователей, получаем указатель на созданный тип.
Этот указатель указывает ровно на таблицу методов. Поэтому достаточно просто получить содержимое по памяти, на которую он указывает. Это и будет адрес таблицы методов.
И так как переданный нам указатель является своего рода ссылкой на объект, то мы должны записать адрес таблицы методов также ровно туда, куда он указывает.
Собственно, это все. Неожиданно, правда? Теперь наш тип готов. Буратино, выделивший нам память, сам позаботится о инициализации полей.
Остается только воспользоваться грандкастером, чтоб преобразовать указатель в управляемую ссылку.
public class StackInitializer
{
public static unsafe T InitializeOnStack<T>(int* pointer) where T : new()
{
T r = new T();
var caster = new PointerCaster().Caster;
int* ptr = caster.GetPointerByManagedReference(r);
pointer[0] = ptr[0];
T reference = caster.GetManagedReferenceByPointer<T>(pointer);
return reference;
}
}
Теперь мы имеем на стеке ссылку, которая указывает на этот же стек, где по всем законам ссылочных типов(ну почти) лежит сконструированный из чернозема и палок объект. Полиморфизм доступен.
Следует понимать, что если передать эту ссылку за пределы метода, то после возврата из него, мы получим нечто неясное. О вызовах виртуальных методов и речи быть не может, полетим по исключению. Обычные методы вызываются напрямую, в коде будут просто адреса на реальные методы, так что они будут работать. А на месте полей будет… а никто и не знает, что там будет.
Так как для инициализации на стеке невозможно использовать отдельный метод (так как кадр стека будет затерт после возвращения из метода), память выделять должен метод, желающий применить тип на стеке. Строго говоря, есть не один спосооб сделать это. Но самый подходящий нам — stackalloc. Просто идеальное ключевое слово для наших целей. К сожалению, именно оно внесло неуправляемость в код. До этого была идея воспользоваться Span для этих целей и обойтись без небезопасного кода. В небезопасном коде нет ничего плохого, но как и везде, он не является серебряной пулей и имеет свои зоны применения.
Далее после получения указателя на память на текущем стеке передаем это указатель методу, составляющему тип по частям. Вот и все, кто слушал — молодец.
unsafe class Program
{
public static void Main()
{
int* pointer = stackalloc int[2];
var a = StackInitializer.InitializeOnStack<StackReferenceType>(pointer);
a.StubMethod();
Console.WriteLine(a.Field);
Console.WriteLine(a);
Console.Read();
}
}
Не стоит использовать это в реальных проектах, метод, выделяющий память на стеке использует new T(), что в свою очередь использует рефлекцию для создания типа в куче! Так что данный метод будет медленнее обычного создания типа раз ну этак в 40-50.
Здесь можно посмотреть весь проект.
Источник: в теоретическом экскурсе были использованы примеры из книги Sasha Goldstein — Pro .NET Performace
Комментарии (10)

ukhegg
05.11.2018 11:54А что если на стеке завести структуру соответствующего размера, взять ее адрес(возможно ли?) и проинициализировать там класс? Тогджа можно без stackalloc. Может я чего не понимаю-я из тех кто стреляет из дробовика++ в ногу)
ZloyChert Автор
05.11.2018 12:18Обдумывал и такой вариант. Теоретически, можно даже просто переменных нужное количество завести, но это не динамически. Тут, конечно, мой косяк, поленился написать нормальный метод main. Просто суть в том, что так я могу выделить на стеке память под любой размер класса (то бишь для любого класса). А в варианте со структурами (или кучей переменных) придется заводить их на каждый случай жизни, никакой динамики.
А так да, если подобрать нужную структуру, то должно получиться!
Nagg
05.11.2018 18:01Скоро в рантайм и так завезут авто аллоцирование реф-тайпов на стеке ;-) (escape analysis)
shai_hulud
Интересный опыт. Но зачем?
троллейбус_из_буханки.jpg
ZloyChert Автор
Как я написал в самом начале: «Это просто расширение границ, в которых воспринимается язык программирования». То есть интересный пример, показывающий некоторые аспекты внутреннего устройства
IRainman
Вот это «зачем?» мне напомнило конфу по Python в Яндексе лет 5 назад когда на вопрос докладчика «кто знает устройство памяти у языка?» ответ знали только два человека сам докладчик и я, а знали потому что оба пишем суровое высокопроизводительное… и на C++.
P.S. очень точно написано название книги «Pro .NET Performance» ибо до Senior в .NET без этих знаний не добраться ;)
shai_hulud
Это конечно круто, и я про это уже давно видел на докладе того же Голдштейна. Но это implementation details, неприменимые на практике. Тем более знания про таблицы методов, GC handles итд уже давно не тайна недоступная для изучения и «pro-only» тема.
IRainman
Разработчики языка специально ввели unsafe как раз для случаев где implementation details имеет значение и влияет на производительность, так что про неприменимость на практике всё таки не соглашусь.