

Здесь я расскажу об устройстве одного из многих инструментов, которые помогают в разработке различных сервисов для проекта Одноклассники. Внутри компании мы называем его «Hot Code Replace» (HCR), и предназначен данный инструмент для исправления критических и несложных багов в работающих продакшн сервисах без их остановки. Это чрезвычайно важная особенность, так как позволяет избежать достаточно занудного и трудоёмкого процесса выкладывания новой – исправленной версии барахлящего сервиса, избежать сопутствующей этому достаточно продолжительной паузы в доступности каждого хоста, избежать сброса кешей.
В общем, экономит массу времени и уменьшает интервал от момента обнаружения ошибки до исправления с часов до минут. Чаще всего, как и было задумано, исправляют мелкие ошибки в коде, например, программист забыл проверить на null и у некоторых пользователей определённые действия на сайте приводят к ошибке. То есть когда исправление осуществляется изменением нескольких строчек внутри метода. И ради таких мелких изменений больше не нужно отвлекать коллег и ждать часами выкладки на продакшн.
Например:
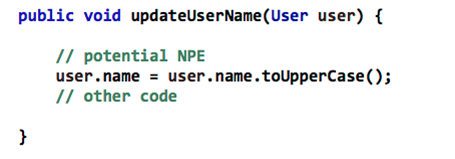
Можно легко исправить на:
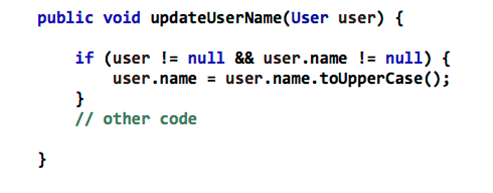
Конечно же можно внести гораздо больше изменений, заодно и добавить новые классы, быстренько внести правки, которые параллельно просит менеджер, не дожидаясь следующего апдейта. Но это уже, если месье знает толк в извращениях.
Далее, можно ставить «патчи» друг на друга и до бесконечности.
Но инструмент этот не всесилен и основан на стандартном функционале, который предлагает Java класс: java.lang.instrument.Instrumentation и его метод void redefineClasses(ClassDefinition… definitions).
Instrumentation.redefineClasses заменяет ранее загруженные классы на новый байт код. Одновременно можно перегружать несколько классов с разными зависимостями. Перегрузка не меняет существующие инстансы классов, не меняет наследования, не трогает поля инстанса или класса. Менять можно только тело метода, пул констант и атрибуты. Можно добавлять новые классы или подклассы. Сигнатуры методов, поля инстансов и поля классов менять нельзя. Если вы попробуете внести несовместимые изменения redefineClasses в принципе не сработает и выкинет ошибку. Нужно помнить, что при перегрузке классов выполнение перегружаемого участка кода не прерывается, новый байткод будет использован уже при следующем вызове этого же метода. И потому, если вы попытаетесь исправить код метода, который имеет внутри бесконечно долгий цикл, то фактическая замена случится только после того, как этот самый цикл завершится.
Если совсем по-простому: вы можете менять код только внутри методов и точка.
И вот пример цикла while, который пока не завершится метод не исправится.

Главной сложностью было сделать инструмент, работающей в экосистеме Одноклассников, инструмент, который вписывается во все установленные процессы работы. Который будет стабильно и прозрачно взаимодействовать со всеми сервисами на сотнях хостов, а так же будет гибок и прост в работе. Инструмент этот должен справиться с десятками экспериментов, работ и апдейтов, что непрерывно происходят на продакшане.
Как выглядит процесс установки патча с позиции разработчика/админа, пытающегося исправить баг на продакшане, но так, чтобы это можно было сделать при помощи некой стандартной и надёжной процедуры на десятках серверов. Опустим процесс поиска и исправления ошибки в коде.
1. Создаётся отдельный бранч в GIT для исправлений кода. Использование версионирования очень важно не только по причине удобства, но и для последующих возможных расследований.
2. В TeamCity запускается процесс сборки патча. Сначала создаётся сборка проекта из указанного бранча и далее новая сборка сравнивается с той, что установлена на продакшане. Для этого я написал плагин для инструмента сборки, который достаёт все файлы из архивов, сравнивает расхождения и выбирает только те файлы, которые изменились или добавились. При этом версия Java компилятора в обоих сборках должна быть одинаковой, т.к. другая версия компилятора создаст отличающиеся файлы и в патч попадут почти все файлы проекта. Это очень важно — создать именно небольшой по размерам архив, в который попадут только нужные файлы, т.к. это значительно ускорит процесс доставки патча на десятки серверов. Процесс билда подходит не только для патча кода проекта, также можно подменять в проекте пропатченную библиотечку. Во время сравнения содержания двух сборок, будут найдены в том числе и отличия в библиотеках (jar-файлах).
3. В случае удачной сборки, патч отправляется в специальный репозиторий, а в окне результата выдаётся ключ (или хэш), который нужен для однозначной идентификации патча и некой гарантии того, что на продакшн попадёт именно этот код.
Ну и опять же – патчить можно неограниченное количество раз и сборки с одним и тем же номером версии будут отличаться именно хэшем.
4. Далее вся деятельность перемещается в конфигурационный сервис, где в привычном UI можно указать для какого сервиса, на каких хостах и какие версии приложений нужно пропатчить.
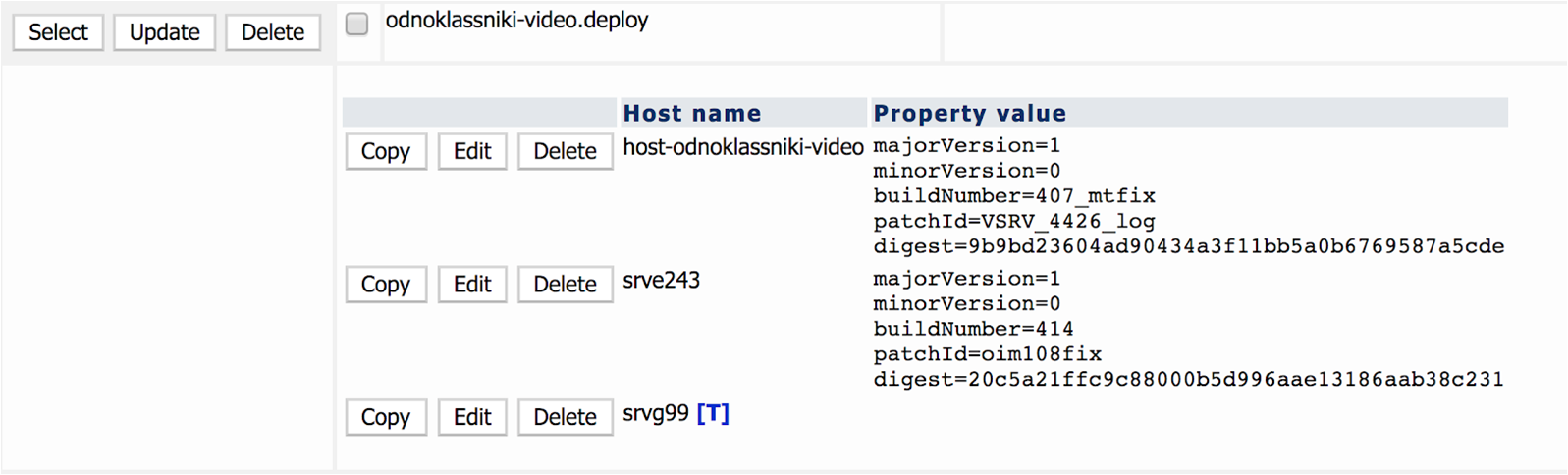
Подобное обилие параметров даёт необходимый уровень гибкости настроек, что очень важно в большом зоопарке из множества серверов. Скажем, на какой-то части серверов номер версии приложения отличается, и патчить этот код совсем не нужно. Или, для проверки, сначала запускается Hot Code Rreplace на одном сервере, или на группе серверов, а затем распространяется по всем инстансам приложения.
5. Через изменение конфигурации выбранные сервисы получают информацию о том, что за патч нужно установить, его версию и проверочный хэш. Идея такова, что все сервисы получают команду «установить патч» и дальше действуют самостоятельно. Самостоятельно сравнивают собственную версию и только если версия совпадает и хэш патча отсутствует или отличается, самостоятельно скачивают сборку патча из репозитория. Сам процесс скачивания происходит по HTTP, причём оперативно можно изменить адрес репозитория, количество попыток скачивания и период ожидания между повторениями попыток.
6. Каждое приложение локально проверяет хэш сборки и распаковывает её. При этом проверяется каждый файл на наличие его в массиве среди того, что возвращает Instrumentation.getAllLoadedClasses(), все новые классы и файлы записываются в новый — временный classpath и этот classpath добавляется через Instrumentation.appendToSystemClassLoaderSearch(), а существующие классы считываются в память и проходят через метод redefineClasses.
7. Весь процесс: приход сигнала о необходимости пропатчить приложение, его скачивание, проверка, распаковка и применение подробно логируется, как в общий с приложением лог, так и в собственный, чтобы можно было быстро и без лишних телодвижений проследить за процессом.
8. После удачного применения патча, процесс завершается изменением версии приложения на пропатченную путём прибавления специально составленной строки, включающей хеш патча. В случае, если у какого-то хоста версия не изменилась на ожидаемую, мы идём в лог Hot Code Replace для этого хоста и смотрим, что же там произошло. Если это были проблемы со связью, то можно смело повторить команду патча и нужный хост сам повторит попытку.
Какие возможные проблемы могут помешать пропатчить приложение? Таковых довольно много и среди них функционал класса Instrumentation я бы поставил на последнее место. До сих пор кривой код, не соответствующий строгим условиям redefineClasses всегда отшивался JVM без каких либо последствий для работы приложения. При применении метода redefineClasses JVM полностью останавливает работу приложения, но этот процесс занимает доли секунды. Потому совсем не страшно.
Самым рискованным моментом является доставка патча на сервер, которую решили дополнительными ретраями. Но если и ретраи не помогут, то можно повторить команду вызова патча и каждый из хостов попытается повторить процесс, но установит патч только в том случае, если это нужно, т.е. патч не был ранее установлен или если хэш ключ изменился.
Ещё одна потенциальная проблема, когда исправление устраняет одну ошибку и добавляет новую. Для сведения к минимуму подобного риска, мы сначала выкладываем патч на ограниченное количество серверов, смотрим логи, графики, следим за результатом. И только потом раскатываем исправления на остальные хосты.
Как быть с рестартом приложения или сервера? Это уже заложено в логику всех приложений одноклассников: одним из первых в любом приложении инициируется модуль HCR. И если во время инициализации будет замечена информация о необходимости пропатчить приложение, то патч применится в первую очередь.
А теперь немного о том из чего состоит Hot Code Replace.
- Наш JavaAgent. JavaAgent, если кто забыл, это отдельный специальным образом сформированный *.jar архив, который подхватывается JVM при запуске приложения при помощи дополнительного параметра, например: -javaagent:/path/to/lib/my-agent.jar Именно благодаря дополнительным возможностям Javaagent-а возможно использовать магию замены кода. Именно в агенте доступен класс java.lang.instrument.Instrumentation. Но, я не стал его (агента) засорять лишним кодом, т.к. апдейт агента задача нетривиальная, а просто вынес инстанс класса Instrumentation в статическое поле утилитного класса. Таким образом, все манипуляции можно инициировать из любого места приложения.
- Configuration service – отвечает за конфигурацию любого нашего приложения и поэтому в каждом приложении инициализируется первым. Именно там и спрятан основной функционал Hot Code Replace. При старте приложения или при изменении конфигурации HCR для конкретного приложения проверяется совместимость версии и производятся все вышеописанные манипуляции.
- TeamCity и скрипты для сборки – чтобы удобно создавать «патчи» и сохранять в них только изменённые или добавленные классы и ресурсы.
Какие же плюсы мы имеем от этого инструмента? Первое – это оперативность исправления критических ошибок в проде. По логам я вижу, что коллеги постепенно стали чаще и чаще пользоваться HCR, вместо ожидания релизов. Далее – это скорость применения. Приложение не нужно останавливать, JVM лишь замирает на долю секунды и все ваши объекты остаются на своих местах и продолжают работать.
И зажили наши разработчики свободно и счастливо и исправляли свои ошибки сразу и самостоятельно прямо в продакшане без оглядки на количество серверов и нагрузки.
Комментарии (20)

werklop
08.11.2018 12:57-11) Это вы типа переизобрели JRebel?
2) «программист забыл проверить на null» — а вы не пробовали код покрывать тестами? Слышал, это помогает
3) «достаточно занудного и трудоёмкого процесса выкладывания новой» — может стоит упростить процесс? Уверен, что можно разбить части на кусочки и релизить «атомарно», либо другим способом упростить
А вообще, данный подход из разряда «ху....-ху… и в продакшен». Печально слышать о его использовании в такой компании
kibb
08.11.2018 13:14zeroturnaround.com столько денег ввалили в рекламу своего jrebel, а вы без него обошлись.
izebit
10.11.2018 15:46Стандартная замена классов в java очень ограничена, в частности, в статье описываются случаи когда она не работает. JRebel использует несколько другой подход, поэтому он позволяет добавлять новые поля и изменять сигнатуру методов, т.е. очевидно более гибче
antonarhipov
11.11.2018 00:08JRebel, где может, использует HCR для экономии. Но это все но лишь одно маленькое изменение, которое возможно с HCR — изменение тела метода. Для запатки ок, и разумно когда критично сохранить состояние.
Throwable
08.11.2018 13:37Вопрос такой: а если патчуемый код уже заинструменчен каким-нибудь фреймворком в рантайме? Будет ли повторно вызываться инструментация фреймворка или нет?
Другой вопрос: а как вы тестируете сам процесс патчинга? HCR очень деликатная и ограниченная штука, и успешно пропатчить код может лишь в некоторых случаях. И вот у вас зафейлился патч на продакше. Что делать дальше?
Вообще, я нахожу использование такого подхода более чем странным особенно для Одноклассников. Как я себе представляю подобные системы, перезагрузка одного сервиса никак не должна влиять на общую работу: микросервисы, распределенность и все такое… Если же система монолитная или ее рестарт занимает значительное время, то можно попытаться разделить всю логику на контексты внутри приложения при помощи класслоадеров и рестартать их вбелую по мере необходимости. Или например использовать OSGi, где все это уже реализовано из коробки ввиде модулей. Но патчить на продакшне через интерфейс, предназначенный для дебага — это странное решение.
apangin
08.11.2018 16:38+2а если патчуемый код уже заинструменчен каким-нибудь фреймворком в рантайме? Будет ли повторно вызываться инструментация фреймворка или нет?
Смотря как фреймворк работает. Если он регистрирует инструментацию через Instrumentation.addTransformer, то после патчинга трансформация будет выполнена повторно.
а как вы тестируете сам процесс патчинга?
Зависит от сложности патча. В общем случае применяем сначала на тестовом сервере, потом на одном продакшн сервере, проверяем функциональность руками и/или автотестами, затем применяем на группе хостов, смотрим графики, и, наконец, на всём продакшне. Если патч сломался, его можно отменить применением обратного патча, либо уже традиционной процедурой апдейта. На практике до откатывания патча ни разу дело не доходило.
перезагрузка одного сервиса никак не должна влиять на общую работу
Перезагрузка одного сервера — да. А если надо рестартануть кластер из 600 инстансов? Это надо делать частями, с выводом трафика и плавным заводом, при этом старт и прогрев приложения может занимать десятки минут. Именно так и делается при плановых апдейтах, но это занимает время. Патчинг не заменяет апдейты. Он для простых, но срочных фиксов.
apangin
08.11.2018 19:31+1патчить на продакшне через интерфейс, предназначенный для дебага — это странное решение
Это необычно, согласен. Поэтому и удостоилось статьи. Ключевая особенность фиксов через HCR — что это происходит без даунтайма и без потери состояния. Все текущие соединения, запросы, накопленные данные, кеши, значения переменных — всё остаётся. Не требуется никакой активации/деактивации модулей и никакой миграции со старой версии на новую. OSGi в данном случае не поможет.culvert
09.11.2018 20:40подход вполне понятен, и имеет смысл. Но не лучше ли такое делать архитектурно? Т.е. делать resilient architecture, а не патчинг прода.
К примеру на Load Balancer перевести трафик на чистый сервер, потом спокойно рестартануть сервис. Такой подход добавляет большую надежность общей системы, и убирает приседания с байт кодом. что-то типа netflix style.apangin
10.11.2018 02:34Комментарием выше я как раз на это ответил. Мы ровно так и делаем при плановых релизах. А патчинг мы используем не для выкладки новой версии, а для небольших оперативных исправлений. Перевести трафик на один «чистый» сервер — не проблема. А когда сервис работает на 600 хостах — процедура сложнее и, главное, дольше.
stp008
08.11.2018 16:29Для особенно нетерпеливых и ленивых еще можно поставлять с каждым приложением простую UI висящую на 8080, например, куда в текстовую форму просто копипастится целиком класс и все на лету тоже меняется (если сможет конечно, потому что редефайн сигнатур не переживет и придется рестартовать приложение). Отсутствие адекватного трекинга изменений и версионирования плюс сюрпризы наподобие "почему вижу в коде одно, а на сервере ничего не работает" во время параллельной разработки гарантированы, но для фикс мастера уровень бог такие вещи помехой никогда не были)
Maccimo
08.11.2018 23:00Зачем какой-то 8080? Прошлый век!
Оформить центр управления в виде игры в самих Одноклассниках, как всякие «весёлые фермы» там сделаны. Желающий пропатчить production-сервер разработчик покупает ОК-и и заливает фикс.

Berkof
09.11.2018 09:30Интересная технология для наложения пластыря на разорванную артерию… но имхо, лучше научиться быстро и просто обновлять версии… Ну чтобы старт приложения не занимал больше десятка секунд, кэш при этом не умирал (желательно), а траффик… ну пусть LoadBalancer с этим живёт, переспросит у соседнего инстанса… Итого, если 600 серверов и апдейтить сразу по 10, то нужно 60 апдейтов, по 10 секунд — это 10 минут обновлений… имхо — это моментально.
ggo
09.11.2018 10:56+110 сек — это хорошо, но есть сервисы где 10 мин стартует, и чтобы радикально ускориться нужно очень сильно поиздержаться. И стартует 10 мин не потому что руки кривые…
Жизнь же разнообразна. Иногда нужно уметь и пластырь на артерию. И после того как научился необязательно артерии резать направо и налево, показывая всем свой навык.

tuxi
09.11.2018 13:05+1Ну чтобы старт приложения не занимал больше десятка секунд
Со временем, реальная жизнь цинично ломает такие мечты своей суровой реальностью :) Даже вынос всяких расплодившихся кешей наружу и поддержка их в «горячем» состоянии, не всегда позволяет выйти на «десятки секунд»
a_e_tsvetkov
Я бы без анестезии ничего в продакшене патчить бы не решился. Как минимум 0.5 нужно.