
Будучи инфраструктурным инженером в команде разработки облачной платформы, мне довелось поработать со многими распределенными системами хранения данных, в том числе и с теми, что указаны в заголовке. Кажется, что есть понимание их сильных и слабых сторон, и я попробую поделиться с вами своими мыслями на этот счет. Так сказать, посмотрим у кого хеш-функция длиннее.

Дисклеймер: Ранее в этом блоге вы могли видеть статьи, посвященные GlusterFS. Я не имею к этим статьям никакого отношения. Это авторский блог проектной команды нашего облака и каждый ее участник может рассказать свою историю. Автор тех статей — инженер нашей группы эксплуатации и у него свои задачи и свой опыт, которым он поделился. Прошу это учитывать, если вдруг вы увидите расхождение во мнениях. Пользуясь случаем, передаю автору тех статей большой привет!
О чем пойдет речь
Поговорим о файловых системах, которые можно построить на базе GlusterFS и CephFS. Обсудим архитектуру этих двух систем, посмотрим на них под различными углами и в конце я даже рискну сделать какие-то выводы. Другие возможности Ceph, такие как RBD и RGW, затронуты не будут.
Терминология
Чтобы статья была полноценной и понятной каждому, давайте разберемся с базовой терминологией обеих систем:
Терминология Ceph:
RADOS (Reliable Autonomic Distributed Object Store) — самодостаточное объектное хранилище, которое является основой проекта Ceph.
CephFS, RBD (RADOS Block Device), RGW (RADOS Gateway) — высокоуровневые примочки к RADOS, которые предоставляют конечным пользователям различные интерфейсы к RADOS.
Конкретно CephFS предоставляет интерфейс POSIX-совместимой файловой системы. Фактически данные CephFS хранятся в RADOS.
OSD (Object Storage Daemon) — процесс, обслуживающий отдельный диск/хранилище объектов в RADOS-кластере.
RADOS Pool (пул) — несколько OSD, объединенных общим набором правил, таких как, например, политика репликации. С точки зрения иерархии данных, пул — это каталог или отдельное (плоское, нет подкаталогов) пространство имен для объектов.
PG (Placement Group) — понятие PG я введу чуть позже, в контексте, для лучшего понимания.
Так как RADOS — это фундамент, на котором построен CephFS, я часто буду говорить именно о нем и это автоматически будет относиться к CephFS.
Терминология GlusterFS (далее gl):
Brick — процесс, обслуживающий отдельный диск, аналог OSD в терминологии RADOS.
Volume — том, в который объединяются brick'и. Том — это аналог пула в RADOS, он также имеет определенную топологию репликации между brick'ами.
Распределение данных
Чтобы было понятнее, рассмотрим простой пример, который может быть реализован обеими системами.
Сетап, который будет использоваться в качестве примера:
- 2 сервера (S1, S2) по 3 диска равного объема (sda, sdb, sdc) в каждом;
- том/пул с репликацией 2.
И той и другой системе для нормальной работы нужно минимум 3 сервера. Но мы закрываем на это глаза, поскольку это просто пример для статьи.
В случае с gl это будет Distributed-Replicated том, состоящий из 3 групп репликации:

Каждая группа репликации — это два brick'а на разных серверах.
По сути, получается том, который объединяет в себе три RAID-1.
Когда вы смонтируете его, получите желанную файловую систему и начнете записывать на нее файлы, то обнаружите, что каждый записываемый вами файл ложится в одну из этих групп репликации целиком.
Распределением файлов по этим Distributed-группам занимается DHT (Distributed Hash Tables), который по сути является хеш-функцией (позже мы еще вернемся к нему).
На "схеме" это будет выглядеть так:
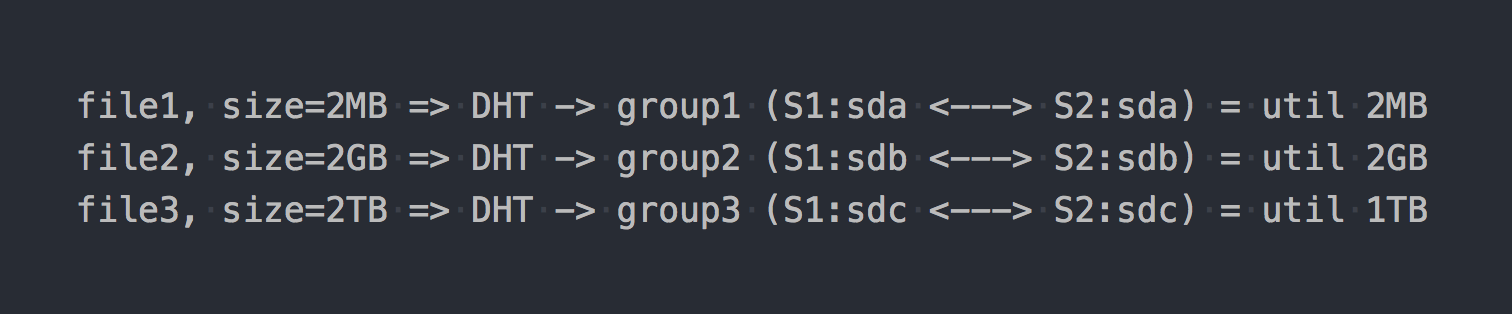
Как бы уже проявляются первые архитектурные особенности:
- место в группах утилизируется неравномерно, это зависит от размеров файлов;
- при записи одного файла IO идет только на одну группу, остальные простаивают;
- нельзя получить IO всего тома при записи одного файла;
- если в группе недостаточно места для записи файла — вы получите ошибку, файл не будет записан и не будет перераспределен в другую группу.
Если использовать другие типы томов, например, Distributed-Striped-Replicated или даже Dispersed (Erasure Coding), то принципиально изменится только механика распределения данных внутри одной группы. DHT так же будет раскладывать файлы целиком по этим группам, и в итоге мы получим все те же проблемы. Да, если том будет состоять только из одной группы или, если у вас все файлы примерно одного размера, то и проблемы не будет. Но мы же говорим о нормальных системах, под сотни терабайт данных, в том числе и файлов разного размера, поэтому считаем, что проблема есть.
Теперь давайте рассмотрим CephFS. На сцену выходит RADOS, упомянутый выше. В RADOS каждый диск обслуживается отдельным процессом — OSD. Исходя из нашего сетапа, у нас таких получится всего 6, по 3 на каждом сервере. Далее нам нужно создать пул для данных и задать число PG и фактор репликации данных в этом пуле — в нашем случае 2.
Допустим, мы создали пул с 8 PG. Эти PG будут примерно равномерно распределены по OSD:
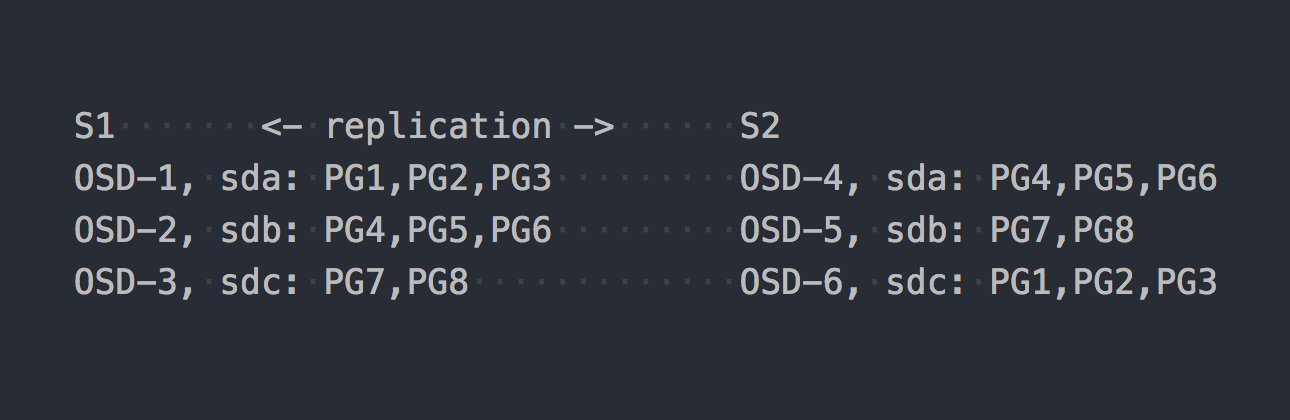
Самое время пояснить, что PG — это логическая группа, которая объединяет в себе какое-то число объектов. Так как мы задали факт репликации 2, то каждая PG имеет реплику на какой-то другой OSD на другом сервере (по умолчанию). Например, у PG1, которая на OSD-1 на сервере S1, есть близняшка на S2 на OSD-6. В каждой паре PG (или тройке, если репликация 3) есть PRIMARY PG, в которую идет запись. Например, PRIMARY для PG4 находится на S1, а вот PRIMARY для PG3 на S2.
Теперь, когда вы знаете, как работает RADOS, мы можем перейти к записи файлов в наш новенький пул. Хотя RADOS — это полноценное хранилище, смонтировать его как файловую систему или использовать как блочное устройство не представляется возможным. Для записи данных в него напрямую нужно использовать специальную утилиту или библиотеку.
Запишем те же три файла, что и в примере выше:
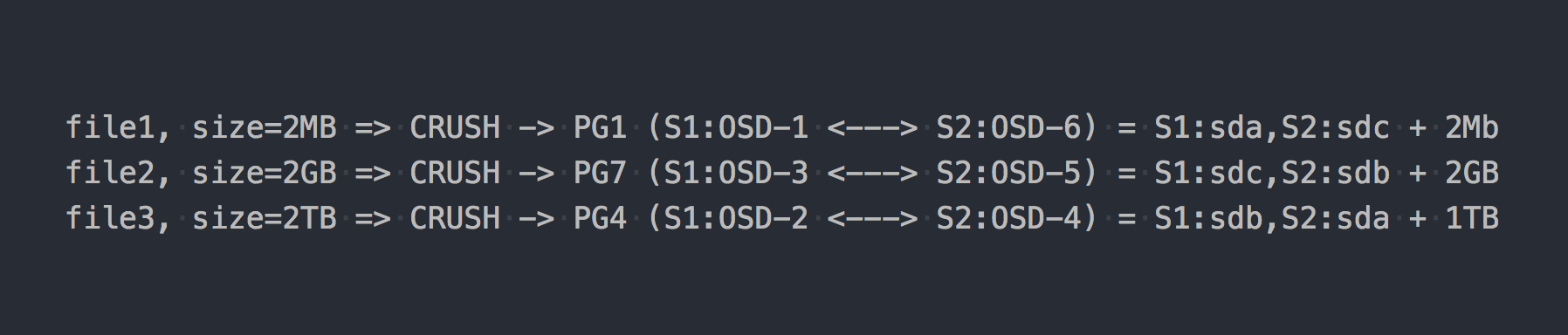
В случае с RADOS все стало как-то сложнее, согласитесь.
Тут в цепочке появился CRUSH (Controlled Replication Under Scalable Hashing). CRUSH — это алгоритм, на котором держится RADOS (мы еще вернемся к нему позже). В данном конкретном случае с помощью этого алгоритма определяется, куда должен быть записан файл, в какую именно PG. Тут CRUSH выполняет ту же функцию, что и DHT в gl. В результате этого псевдослучайного распределения фалов по PG мы получили все те же проблемы, что у gl, только на более сложной схеме.
Но я сознательно умолчал об одном важном моменте. RADOS в чистом виде практически никто не использует. Для удобной работы с RADOS были разработаны прослойки: RBD, CephFS, RGW, о которых я уже упоминал.
Все эти трансляторы (RADOS-клиенты) предоставляют разный клиентский интерфейс, но они схожи в своей работе с RADOS. Наиболее важное сходство в том, что все данные, проходящие через них, режутся на кусочки и кладутся в RADOS как отдельные RADOS-объекты. По умолчанию официальные клиенты режут входной поток на куски по 4MB. Для RBD размер страйпа можно задать при создании тома. В случае с CephFS это атрибут (xattr) файла и им можно управлять на уровне отдельных файлов или целиком для всех файлов каталога. Ну и у RGW также есть соответствующий параметр.
Теперь предположим, что мы взгромоздили CephFS поверх RADOS-пула, который фигурировал в прошлом примере. Сейчас рассматриваемые системы полностью в равных условиях и предоставляют идентичный интерфейс файлового доступа.
Если мы снова запишем наши тестовые файлы на новенькую CephFS, то обнаружим совершенно другое, почти равномерное распределение данных по OSD. Например, file2 размером 2GB будет разделен на 512 кусочков, которые будут распределены по разным PG и, как следствие, по разным OSD почти равномерно, и это практически решает описанные выше проблемы с распределением данных.
В нашем примере используется всего 8 PG, хотя рекомендуется иметь на одной OSD ~100 PG. И пулов для работы CephFS нужно 2. Также еще нужно несколько служебных демонов для работы RADOS в принципе. Не думайте, что все так просто, я специально многое опускаю, дабы не отходить от сути.
Итак, теперь CephFS кажется более интересной, не так ли? Но я умолчал еще один важный момент, на этот раз про gl. У gl тоже есть механизм разрезания файлов на куски и прогона уже этих кусков через DHT. Так называемый шардинг (Sharding).
Пятиминутка истории
On April 21, 2016, the Ceph development team released "Jewel", the first Ceph release in which CephFS is considered stable.
Это сейчас все налево и направо кричат про CephFS! А 3-4 года назад использовать ее было бы по меньшей мере сомнительным решением. Мы искали другие решения, и gl с описанной выше архитектурой никуда не годился. Но мы верили в него больше, чем в CephFS, и ждали шардинг, который готовили к выходу.
И вот он день икс:
June 4, 2015 — The Gluster Community today announced the general availability of GlusterFS 3.7 open software-defined storage software.
3.7 — первая версия gl, в которой анонсировали шардирнг как экспериментальную возможность. У них был почти год до стабильного релиза CephFS, чтобы закрепиться на пьедестале...
Так вот, шардинг, значит. Как и все в gl, это реализовано в отдельном трансляторе (translator), который стоял выше DHT (тоже translator) по стеку. Так как он выше, чем DHT, на вход DHT получает уже готовые шарды и распределяет их по группам репликации как регулярные файлы. Шардирование включается на уровне отдельного тома. Размер шарда можно задать, по умолчанию — 4MB, как и у примочек Ceph.
Когда я провел первые тесты я был в восторге! Я всем рассказывал, что gl — это теперь топовая штука и сейчас-то заживем! С включенным шардированием запись одного файла идет в параллель на разные группы репликации. Следующая за "On-Write" компрессией декомпрессия может быть инкрементальной до уровня шарда. При наличии кеш-тира тут тоже все становится хорошо и в кеш перемещаются отдельные шарды, а не файлы целиком. В общем, я ликовал, т.к. казалось, что получил в свои руки очень крутой инструмент.
Оставалось подождать первых багфиксов и статуса "ready for production". Но все оказалось не так радужно… Дабы не растягивать статью списком критичных багов, связанных с шардингом, то и дело возникавших в следующих версиях, скажу лишь, что последний "major issue" со следующим описанием:
Expanding a gluster volume that is sharded may cause file corruption. Sharded volumes are typically used for VM images, if such volumes are expanded or possibly contracted (i.e add/remove bricks and rebalance) there are reports of VM images getting corrupted.
был закрыт в релизе 3.13.2, 20 января 2018 года…а может это не последний?
Коммент к одной из наших статей про это, так сказать, из первых уст.
RedHat в своей документации к актуальному RedHat Gluster Storage 3.4 отмечает, что единственный поддерживаемый ими кейс для шардинга — это хранилище для дисков ВМ.
Sharding has one supported use case: in the context of providing Red Hat Gluster Storage as a storage domain for Red Hat Enterprise Virtualization, to provide storage for live virtual machine images. Note that sharding is also a requirement for this use case, as it provides significant performance improvements over previous implementations.
Я не знаю, почему такое ограничение, но согласитесь, это настораживает.
Сейчас я тебе тут все захеширую
Обе системы используют хеш-функцию для псевдослучайного распределения данных по дискам.
У RADOS это выглядит примерно так:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun
# e.g. pool id=5 => pg = 5.1f
OSD = crush_hash_based_on_jenkins(PG)
# e.g. pg=5.1f => OSD = 12 Gl использует так называемый consistent hashing. Каждый brick получает "range within a 32-bit hash space". То есть все brick'и делят между собой все линейное адресное хеш-пространство без пересечений диапазонов или дыр. Клиент прогоняет имя файла через хеш-функцию, а затем определяет в какой хеш-диапазон попадает полученный хеш. Таким образом выбирается brick. Если в группе репликации несколько brick'ов, то все они имеют одинаковый хеш-диапазон. Примерно так:
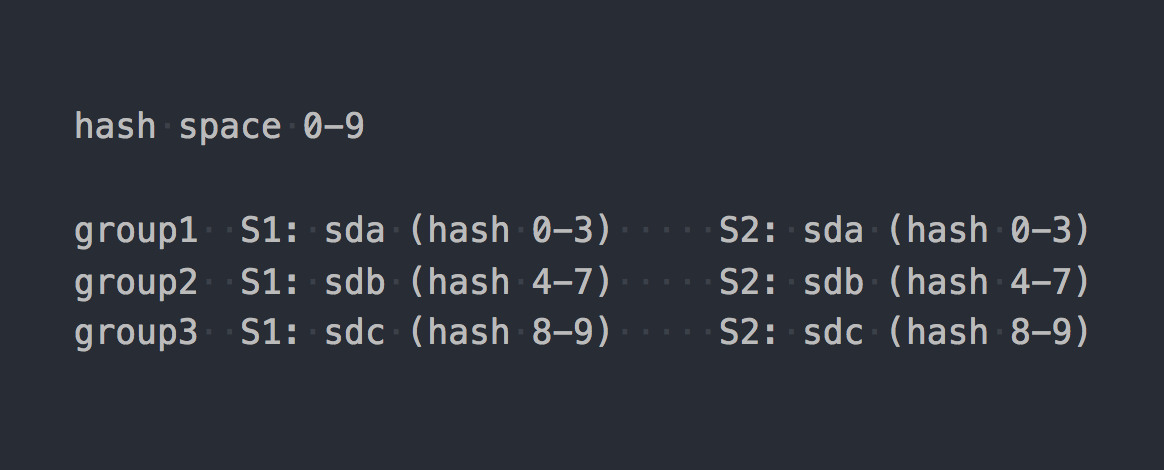
Если привести к некоему единому логическому виду работу двух систем, то получится как-то так:
file -> HASH -> placement_unitгде placement_unit в случае RADOS — это PG, а в случае gl — это группа репликации из нескольких brick'ов.
Так вот, хеш-функция, значит, такая распределяет, распределяет файлики и вдруг оказывается, что один placement_unit утилизирован сильнее другого. Такая вот фундаментальная особенность систем с распределением по хешу. И перед нами встает вполне обычная задача — разбалансировать данные.
Gl умеет в ребеланс, но из-за описанной выше архитектуры с хеш-диапазонами, вы можете сколько угодно запускать ребеланс, но никакой хеш-диапазон (и, как следствие, данные) с места не сдвинутся. Единственный критерий для перераспределения хеш-диапазонов — это изменение емкости тома. И у вас остается одна опция — добавить brick'и. А если мы говорим о томе с репликацией, то мы должны добавить целую группу репликации, то есть два новых brick'а в нашем сетапе. После расширения тома можно запустить ребеланс — хеш-диапазоны будут перераспределены с учетом новой группы и данные распределятся. При удалении группы репликации хеш-диапазоны распределяются автоматически.
У RADOS тут целый вагон возможностей. В статье, посвященной Ceph, я много жаловался на концепцию PG, но тут, сравнивая с gl, конечно, RADOS на коне. Каждая OSD имеет свой вес, обычно он задается на основе размера диска. В свою очередь, PG распределяются по OSD в зависимости от веса последних. Все, далее мы просто меняем вес OSD вверх или вниз и PG (вместе с данными) начинают перемещаться на другие OSD. Также у каждой OSD есть дополнительный корректировочный вес, который позволяет балансировать данные между дисками одного сервера. Все это заложено в CRUSH. Основной профит в том, что не обязательно расширять емкость пула, чтобы разбалансировать лучше данные. И не обязательно добавлять диски группами, можно добавить всего одну OSD и на нее перенесется часть PG.
Да, возможна ситуация, когда при создании пула не создали достаточно PG и вышло так, что каждая из PG довольно большая по объему, и куда бы они не перемещались, дисбаланс будет сохраняться. В таком случае можно увеличить число PG, и они расщепятся на более мелкие. Да, если кластер забит данными, то это больно, но главное в нашем сравнении то, что такая возможность есть. Сейчас допускается только увеличение числа PG и с этим нужно быть аккуратнее, но в ближайшей версии Ceph — Nautilus появится поддержка уменьшения числа PG (pg merging).
Репликация данных
Наши тестовые пул и том имеют фактор репликации 2. Интересно, что в рассматриваемых системах используются разные подходы к достижению этого числа реплик.
В случае с RADOS схема записи выглядит примерно так:
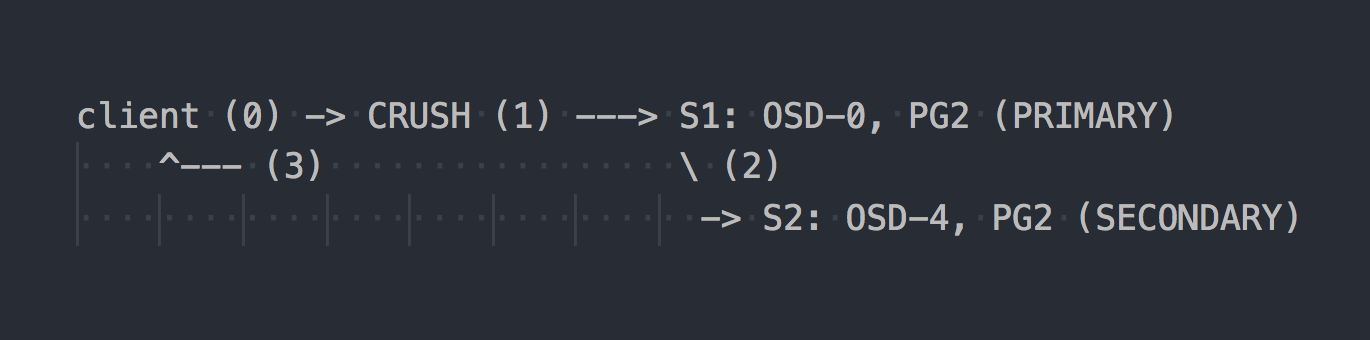
Клиент знает топологию всего кластера, использует CRUSH (шаг 0) для выбора конкретной PG для записи, пишет в PRIMARY PG на OSD-0 (шаг 1), затем OSD-0 синхронно реплицирует данные на SECONDARY PG (шаг 2), и только после успешного/неуспешного шага 2, OSD подтверждает/не подтверждает операцию клиенту (шаг 3). Репликация данных между двумя OSD прозрачна для клиента. OSD вообще могут использовать отдельную "кластерную", более быструю сеть для репликации данных.
Если настроена тройная репликация, то она также выполняется синхронно c PRIMARY OSD на две SECONDARY, прозрачно для клиента… ну, только, что летенси выше.
Gl работает иначе:
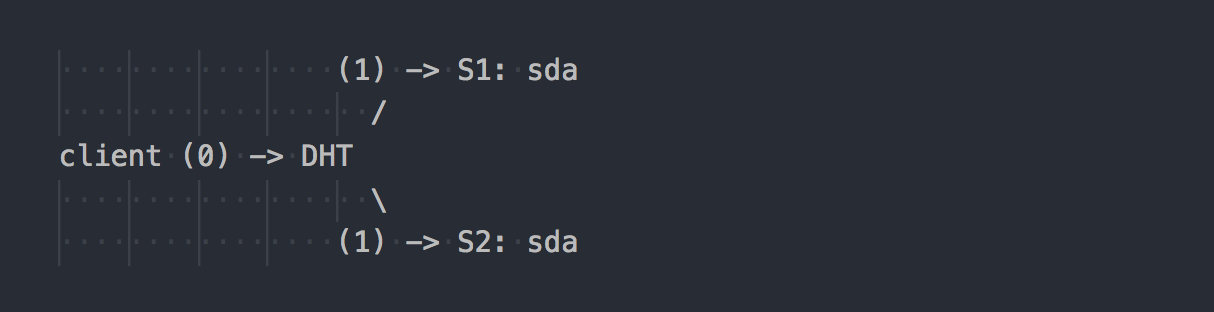
Клиент знает топологию тома, использует DHT (шаг 0), чтобы определить нужный brick, затем выполняет на него запись (шаг 1). Все просто и понятно. Но тут мы вспоминаем, что все brick'и в группе репликации имеют одинаковый хеш-диапазон. И вот эта незначительная особенность делает весь праздник. Клиент пишет параллельно на все brick'и, которые имеют подходящий хеш-диапазон.
В нашем случае при двойной репликации клиент выполняет параллельно двойную запись на два разных brick'а. При тройной репликации будет выполнена тройная запись соответственно, и 1MB данных превратится грубо в 3MB сетевого траффика от клиента в сторону gl-серверов. Согласитесь, концепции у систем перпендикулярные.
В такой схеме на клиента gl возложено больше работы, и, как следствие, ему нужно больше CPU, ну и про сеть я уже сказал.
Репликацией занимается AFP-транслятор (Automatic File Replication) — A client-side xlator that performs synchronous replication. Replicates writes to all bricks of the replica > Uses a transaction model.
При необходимости синхронизировать реплики в группе (healing), например, после временной недоступности одного brick'а, демоны gl делают это самостоятельно средствами встроенного в них AFP, прозрачно для клиентов и без их участия.
Интересно, что если работать не через нативный клиент gl, а писать через встроенный NFS сервер в gl, то получим такое же поведение как у RADOS. В таком случае будет использоваться AFP в демонах gl для репликации данных без участия клиента. Но встроенный NFS задеприкейчен в gl v4 и, если хочется такого поведения, то рекомендуется использовать NFS-Ganesha.
Кстати, из-за настолько разного поведения при использовании NFS и нативного клиента вы можете видеть совершенно разные показатели производительности.
А у вас есть такой же кластер, только "на коленке"?
Я часто вижу в интернете обсуждения всяких наколеночных сетапов, где кластер под данные строится из того, что есть под рукой. В таком случае решение на базе RADOS может дать вам больше свободы при выборе дисков. В RADOS вы можете добавлять диски практически любого размера. Каждый диск будет иметь вес, соответствующий его размеру (обычно), и данные распределятся по дискам почти пропорционально их весу. В случае с gl в томах с репликацией нет понятия "отдельные диски". Диски добавляются парами при двойной репликации или тройками при тройной. Если в одной группе репликации будут диски разного размера, то вы упретесь в место на самом маленьком диске в группе и недоутилизируете емкость больших дисков. В такой схеме gl будет считать, что емкость одной группы репликации равна емкости наименьшего диска в группе, что логично. При этом допускается иметь группы репликации, состоящие из дисков разного объема — разные по объему группы. Группы большего объема могут получить больший относительно других групп хеш-диапазон и, как следствие, принять больше данных.
Мы живем с Ceph уже пятый год. Начинали с дисков одного объема, сейчас вводим более емкие. С Ceph можно удалить диск и поставить вместо него другой большего размера или несколько поменьше без каких-то архитектурных затруднений. С gl все сложнее — вынул диск на 2 TB — такой же и поставь, будь добр. Ну или выводи всю группу целиком, что не оч, согласитесь.
Обработка отказов
Мы уже познакомились немного с архитектурой двух решений и теперь можем поговорить о том, как с этим жить и какие есть особенности при обслуживании.
Предположим, у нас отказал sda на S1 — обычное дело.
В случае с gl:
- копия данных на оставшемся в группе живом диске не перераспределяется автоматически на другие группы;
- пока диск не будет заменен, останется только одна копия данных;
- при замене сбойного диска на новый репликация выполняется с исправного диска на новый (1 на 1).
Это похоже на обслуживание полки с несколькими RAID-1. Да, с тройной репликацией, при отказе одного диска останется не одна копия, а две, но все равно у такого подхода есть серьезные недостатки, и я покажу их на хорошем примере с RADOS.
Предположим, у нас отказал sda на S1 (OSD-0) — обычное дело:
- PG, которые находились на OSD-0, будут автоматически перемаплены на другие OSD через 10 минут (по умолчанию). В нашем примере на OSD 1 и 2. Если бы серверов было больше, то на большее число OSD.
- PG, которые хранят вторую, уцелевшую копию данных, начнут автоматически реплицировать их на те OSD, куда перенесены восстанавливаемые PG. Получается репликация "многие-ко-многим", а не "один-к-одному" как у gl.
- При введении нового диска взамен сломанного на новую OSD будут намаплены какие-то PG в соответствии с ее весом и постепенно перераспределены данные с других OSD.
Думаю, архитектурные преимущества RADOS пояснять нет смысла. Вы можете не дергаться при получении письма о том, что отказал диск. А придя утром на работу обнаружите, что все недостающие копии уже восстановлены на десятках других OSD или в процессе этого. На больших кластерах, где сотни PG размазаны по куче дисков, восстановление данных одной OSD может проходить на скоростях сильно больших скорости одного диска за счет того, что вовлечены (читают и пишут) десятки OSD. Ну и про распределение нагрузки тоже забывать не стоит.
Масштабирование
В этом контексте я, пожалуй, отдам пьедестал gl. В статье, посвященной Ceph, я уже писал о некоторых сложностях масштабирования RADOS, связанных с концепцией PG. Если увеличение PG по мере роста кластера еще можно пережить, то как быть с Ceph MDS — непонятно. CephFS бежит поверх RADOS и использует отдельный пул для метаданных и специальный процесс — Сeph metadata server (MDS) для обслуживания метаданных файловой системы и координирования всех операций с ФС. Я не говорю, что наличие MDS ставит крест на масштабируемости CephFS, нет, тем более что допускается запускать несколько MDS в active-active режиме. Я лишь хочу отметить, что gl архитектурно лишен всего этого. У него нет аналога PG, нет ничего наподобие MDS. Gl действительно прекрасно масштабируется простым добавлением групп репликации, практически линейно.
Еще во времена "до CephFS" мы проектировали решение под петабайты данных и рассматривали gl. Тогда у нас были сомнения насчет масштабируемости gl и мы выясняли это через рассылку. Вот один из ответов (Q: мой вопрос):
I am using 60 servers each has 26x8TB disks total 1560 disk 16+4 EC volume with 9PB of usable space.
Q: Do you use libgfapi or FUSE or NFS on client side?
I use FUSE and I have nearly 1000 clients.
Q: How many files are you have in your volume?
Q: Files are more big or small?
I have over 1M files and %13 of cluster is used which makes average file size 1GB.
Minimum/Maximum file size is 100MB/2GB. Every day 10-20TB new data enters the volume.
Q: How fast does "ls" work)?
Metadata operations are slow as you expect. I try not to put more than 2-3K files in a directory. My use case is for backup/archive so I rarely do metadata operations.
Переименование файлов
Снова возвращаемся к хеш-функциям. Мы разобрались с тем, как конкретные файлы роутятся на конкретные диски, и теперь уместным становится вопрос, а что же будет при переименовании файлов?
Ведь если мы меняем имя файла, то хеш от его имени тоже поменяется, а значит, и место этому файлу на другом диске (в другом хеш-диапазоне) или на другой PG/OSD в случае RADOS. Да, мы мыслим правильно, и тут у двух систем снова все перпендикулярно.
В случае с gl при переименовании файла новое имя прогоняется через хеш-функцию, определяется новый brick и на нем создается специальная ссылка на старый brick, где файл остается лежать по-прежнему. Топчик, правда? Чтобы данные реально переместились на новое место, и клиент не делал лишнего перехода по ссылке, нужно сделать ребеланс.
А вот у RADOS вообще нет метода для переименования объектов как раз из-за необходимости в последующем их перемещении. Для переименования предлагается использовать честное копирование, что приводит к синхронному перемещению объекта. А CephFS, которая работает поверх RADOS, имеет козырь в рукаве в виде пула с метаданными и MDS. Изменение имени файла не затрагивает содержимое файла в data-пуле.
Репликация 2.5
У gl есть одна очень прикольная возможность, которую я хотел бы отметить отдельно. Все понимают, что репликация 2 — это недостаточно надежная конфигурация, но тем не менее она периодически имеет место быть и вполне обоснованно. Для защиты от split-brain в таких схемах и для обеспечения согласованности данных gl позволяет строить тома с репликой 2 и дополнительным арбитром. Арбитр применим при репликации 3 и более. Это такой же brick в группе, как и остальные два, только на нем фактически создается только файловая структура из файлов и директорий. Файлы на таком brick'е имеют нулевой размер, но их расширенные атрибуты файловой системы (extended attributes) поддерживаются в синхронизированном состоянии с полноразмерными файлами в этой же реплике. Думаю, идея понятна. Мне кажется это крутой возможностью.
Единственный момент… размер места в группе репликации определяется размером самого маленького brick'а и это значит, что арбитру нужно подсунуть диск, как минимум такого же размера, как и у остальных в группе. Для этого рекомендуют создавать тонкие (thin) LV фиктивного, большого размера, дабы не использовать реальный диск.
А че по клиентам?
Нативный API двух систем реализован в виде библиотек libgfapi (gl) и libcephfs (CephFS). Биндинги для популярных языков тоже есть. В целом, с библиотеками все примерно одинаково хорошо. Вездесущая NFS-Ganesha поддерживает в качестве FSAL обе библиотеки, что тоже норм. Qemu также поддерживает нативный API gl через libgfapi.
А вот fio (Flexible I/O Tester) давно и успешно поддерживает libgfapi, но поддержки libcephfs в нем нет. Это плюс gl, т.к. с помощью fio очень приятно тестировать gl "напрямую". Только работая из userspace через libgfapi вы получите от gl все, что она может.
Но если мы говорим о POSIX файловой системе и о способах ее монтирования, то тут gl может предложить только FUSE-клиент, а CephFS реализацию в апстримном ядре. Понятно, что в модуле ядра можно такого наворотить, что FUSE будет показывать лучшую производительность. Но на практике FUSE — это всегда оверхед на контекстных переключениях. Я лично не раз видел, как FUSE нагибал двухсокетный сервер одними CS.
Как-то на этот счет Линус сказал:
Userspace filesystem? The problem is right there. Always has been. People who think that userspace filesystems are realistic for anything but toys are just misguided.
Разработчики gl наоборот считают, что FUSE это круто. Говорят, что это дает больше гибкости и отвязывает от версий ядра. Как по мне, они используют FUSE, потому что gl это не про скорость. Как-то пишется — ну и нормально, и заморачиваться с реализацией в ядре действительно странно.
Производительность
Никаких сравнений не будет).
Это слишком сложно. Даже на идентичном сетапе слишком сложно провести объективное тестирование. По-любому найдется кто-то в комментариях, кто приведет 100500 параметров, которые "ускоряют" одну из систем и скажет, что тесты — фуфло. Поэтому, если интересно, тестируйте сами, пожалуйста.
Заключение
RADOS и CephFS, в частности, более сложное решение и в понимании, и в настройке, и в сопровождении.
Но лично мне архитектура RADOS и работающей поверх CephFS нравятся больше, чем у GlusterFS. Большее число ручек (PG, вес OSD, иерархия CRUSH и прочее), метаданные у CephFS повышают сложность, но дают больше гибкости и делают это решение более эффективным, по моему мнению.
Ceph гораздо лучше подходит под современные критерии SDS и кажется мне более перспективным. Но это мое мнение, а как думаете вы?
Комментарии (6)

FATruden Автор
20.11.2018 12:57И… я пропустил, или в статье ничего про Гео-репликацию не сказано?
(Тоесть вопросы безопасности передачи данных, проблеммы, связанные с высоким пингом, малой скоростью и т.п.)
Нет, вы не пропустили, тема гео-репликации и гео-распределенных кластеров не затронута в этой статье в силу отсутствия у нас подобного опыта и необходимости в подобных сетапах.
FATruden Автор
20.11.2018 13:01И… я пропустил, или в статье ничего про Гео-репликацию не сказано?
(Тоесть вопросы безопасности передачи данных, проблеммы, связанные с высоким пингом, малой скоростью и т.п.)
Если у вас есть подобный опыт, было бы интересно почитать о нем, хотя бы в двух словах.
arheops
20.11.2018 16:49+1Glusterfs требует постоянного слежения за ним. Оставленная без присмотра теряет файлы/делает split brain и даже не сообщает об этом, узнаешь только по факту отказа диска.
Короче, для систем где не нужно супер большие обьемы проще старый добрый rsync.
celebrate
21.11.2018 19:08Не, ну когда файлы от 200 метров до двух гигов, то операции с метадатой сравнительно недорогие. Но когда постоянная запись кучи мелких файлов, то ни Гластер, ни Цеф не подходят. И вообще непонятно, какая кластерная ФС подходит в этом случае…
Fox_exe
Тесты всё равно надо было привести, но только в «дефолтной» конфигурации, дабы показать на что способны системы с «Рекомендуемыми разработчиком» настройками.
И… я пропустил, или в статье ничего про Гео-репликацию не сказано?
(Тоесть вопросы безопасности передачи данных, проблеммы, связанные с высоким пингом, малой скоростью и т.п.)
gecube
У меня цеф был сильно быстрее в дефолте. Никаких ручек не крутил. Но тут еще вопрос в том, что вероятно, что тест был не совсем честен, т.к. как соотнести количество PG и brick'и? Или вообще не стоит на это заморачиваться и пускай вообще все по дефолту будет?
Возможно, что были какие-то особенности с подключением glusterfs (там есть нюансы — nfs/fuse и т.п.)