
Когда речь заходить о тестировании производительности — в первую очередь все думают о JMeter’е — он бесспорно остается самым известным инструментом с самым большим количеством плагинов. Мне же JMeter никогда не нравился из-за неочевидного интерфейса и высокого порога вхождения, как только возникает необходимость протестировать не Hello World приложение.
И вот, окрыленный успехом проведения тестирования в двух различных проектах, решил поделится информацией об относительно простом и удобном софте — Locust
Для тех, кому лень идти под кат, записал видео:
Что это?
Опенсорс тул, позволяющий задать сценарии нагрузки Python кодом, поддерживающий распределенную нагрузку и, как уверяют авторы, использовался для нагрузочного тестирования Battlelog для серии игр Battlefild (сразу подкупает)
Из плюсов:
- простая документация, включая copy-paste пример. Можно начать тестить, даже почти не умея программировать
- “Под капотом” использует библиотеку requests (HTTP для людей). Ее документацию можно использовать как расширенную шпаргалку и дебажить тесты
- поддержка Python — мне просто нравится язык
- Предыдущий пункт дает кроссплатформенность для запуска тестов
- Собственный веб сервер на Flask для отображения результатов тестирования
Из минусов:
- Никаких Capture & Replay — все руками
- Результат предыдущего пункта — нужен мозг. Как и в случае с использованием Postman, необходимо понимание работы HTTP
- Нужны минимальные навыки программирования
- Линейная модель нагрузки — что сразу расстраивает любителей генерировать пользователей “по Гауссу”
Процесс тестирования
Любое тестирование — комплексная задача, требующая планирования, подготовки, контроля выполнения и анализа результатов. При нагрузочном тестировании, если есть возможность, можно и нужно собирать все возможные данные, которые могут повлиять на результат:
- Hardware сервера (CPU, RAM, ROM)
- Software сервера (OS, версии сервера, JAVA, .NET, и пр., база данных и количество самих данных, логи сервера и тестируемого приложения)
- Пропускная способность сети
- Наличие прокси серверов, балансировщиков нагрузки и DDOS защиты
- Данные нагрузочного тестирования (количество пользователей, среднее время отклика, количество запросов в секунду)
Описанные далее примеры можно классифицировать как black-box функциональное нагрузочное тестирование. Даже не зная ничего о тестируемом приложении и не доступа к логам, мы можем измерить его производительность.
Перед началом
Для того, чтобы на практике проверять нагрузочные тесты, я развернул локально простой веб сервер https://github.com/typicode/json-server. Почти все следующие примеры я буду приводить для него. Данные для сервера я взял из развернутого онлайн примера — https://jsonplaceholder.typicode.com/
Для его запуска необходим nodeJS.
Очевидный спойлер: как и с тестированием безопасности — эксперименты с нагрузочным тестированием лучше проводить на кошках локально, не нагружая онлайн сервисы, чтобы вас не забанили
Для того, чтобы начать, также необходим Python — во всех примерах я буду использовать версию 3.6, а также сам locust (на момент написания статьи — версия 0.9.0). Его можно установить командой
python -m pip install locustioПодробности установки можно подсмотреть в официальной документации.
Разбор примера
Далее нам нужен файл теста. Я взял пример из документации, так как он очень прост и понятен:
from locust import HttpLocust, TaskSet
def login(l):
l.client.post("/login", {"username":"ellen_key", "password":"education"})
def logout(l):
l.client.post("/logout", {"username":"ellen_key", "password":"education"})
def index(l):
l.client.get("/")
def profile(l):
l.client.get("/profile")
class UserBehavior(TaskSet):
tasks = {index: 2, profile: 1}
def on_start(self):
login(self)
def on_stop(self):
logout(self)
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000Все! Этого реально достаточно, чтобы начать тест! Давайте разберем пример, прежде чем перейдем к запуску.
Пропуская импорты, в самом начале мы видим 2 почти одинаковые функции логина и логаута, состоящие из одной строчки. l.client — объект HTTP сессии, с помощью которой мы будем создавать нагрузку. Мы используем метод POST, почти идентичный такому же в библиотеке requests. Почти — потому что в данном примере мы передаем в качестве первого аргумента не полный URL, а только его часть — конкретный сервис.
Вторым аргументом передаются данные — и не могу не заметить, что очень удобно использовать словари Python, которые автоматически конвертируются в json
Также можно обратить внимание, что мы никак не обрабатываем результат запроса — если он будет успешен, результаты (например cookie), будут сохранены в этой сессии. Если произойдет ошибка — она будет записана и добавлена в статистику о нагрузке
Если нам захочется узнать, правильно ли мы написали запрос, можно всегда проверить его следующим образом:
import requests as r
response=r.post(base_url+"/login",{"username":"ellen_key","password":"education"})
print(response.status_code)Я добавил только переменную base_url, которая должна содержать полный адрес тестируемого ресурса.
Следующее несколько функций — запросы, за счет которых будет создаваться нагрузка. Опять же, нам не нужно обрабатывать ответ сервера — результаты пойдут сразу в статистику.
Дальше — класс UserBehavior (название класса может быть любое). Как видно из названия, в нем будет описано поведение сферического пользователя в вакууме тестируемого приложения. Свойству tasks мы передаем словарь методов, которые будет вызывать пользователь и их частоту вызовов. Теперь, несмотря на то, что мы не знаем, какую функцию и в каком порядке будет вызывать каждый пользователь — они выбираются случайно, мы гарантируем, что функция index вызовется в среднем в 2 раза чаще, чем функция profile.
Кроме поведения, родительский класс TaskSet позволяет задать 4 функции, которые можно выполнить до и после тестов. Порядок вызовов будет следующим:
- setup — вызывается 1 раз при старте UserBehavior(TaskSet) — его нет в примере
- on_start — вызывается 1 раз каждым новым пользователем нагрузки при старте работы
- tasks — выполнение самих задач
- on_stop — вызывается 1 раз каждым пользователем, когда тест заканчивает работу
- teardown — вызывается 1 раз, когда TaskSet завершает работу — его тоже нет в примере
Здесь же стоит упомянуть, что есть 2 способа объявления поведения пользователя: первый уже указан в примере выше — функции объявлены заранее. Второй способ — объявления методов прямо внутри класса UserBehavior:
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
self.client.post("/login", {"username":"ellen_key", "password":"education"})
def on_stop(self):
self.client.post("/logout", {"username":"ellen_key", "password":"education"})
@task(2)
def index(self):
self.client.get("/")
@task(1)
def profile(self):
self.client.get("/profile")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000В этом примере функции пользователя и частота их вызова задана с помощью аннотации task. Функционально же ничего не изменилось
Последний класс из примера — WebsiteUser (название класса может быть любое). В этом классе мы задаем модель поведений пользователя UserBehavior***+, а также минимальное и максимальное время ожидания между вызовами отдельных task каждым пользователем. Чтобы было понятнее, вот как это можно визуализировать:
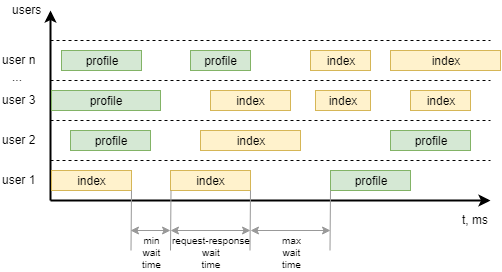
Начало работы
Запустим сервер, производительность которого мы будем тестировать:
json-server --watch sample_server/db.jsonТак же модифицируем файл примера, чтобы он соответствовал мог тестировать сервис, уберем логин и логаут, зададим поведение пользователя:
- Открыть главную страницу 1 раз при начале работы
- Получить список всех постов х2
- Написать комментарий к первому посту х1
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
self.client.get("/")
@task(2)
def posts(self):
self.client.get("/posts")
@task(1)
def comment(self):
data = {
"postId": 1,
"name": "my comment",
"email": "test@user.habr",
"body": "Author is cool. Some text. Hello world!"
}
self.client.post("/comments", data)
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
Для запуска в командной строке надо выполнить команду
locust -f my_locust_file.py --host=http://localhost:3000где host — адрес тестируемого ресурса. Именно к нему будут добавлены адреса сервисов, указанные в тесте.
Если никаких ошибок в тесте нет, нагрузочный сервер запустится и будет доступен по адресу http://localhost:8089/
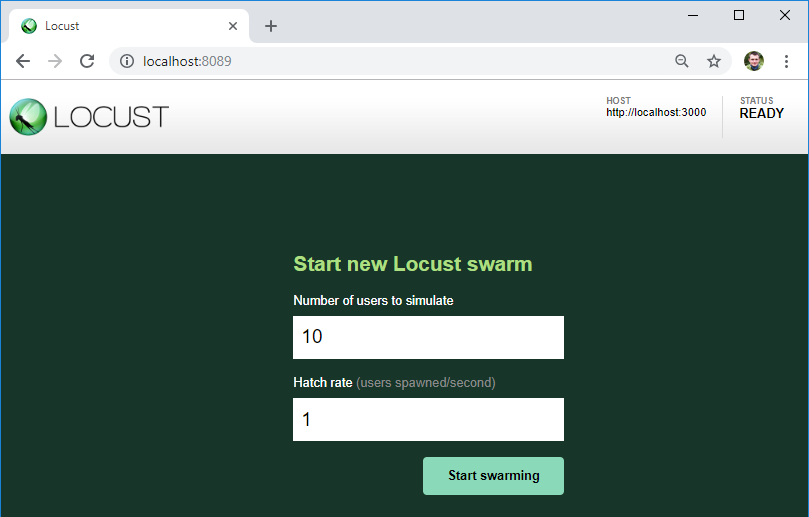
Как видим, здесь указан сервер, который мы будем тестировать — именно к этому URL будут добавлятся адреса сервисов из файла теста.
Также здесь мы можем указать количество пользователей для нагрузки и их прирост в секунду.
По кнопке начинаем нагрузку!
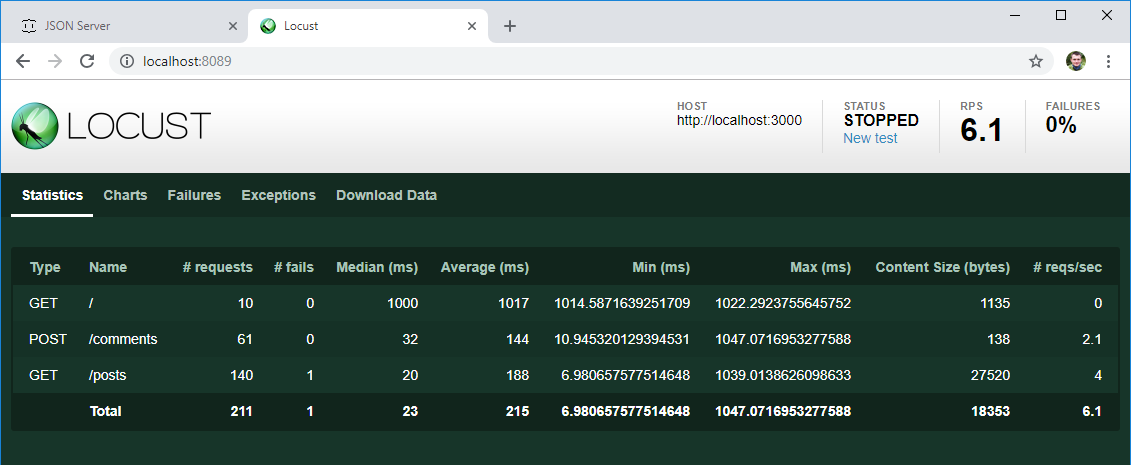
Результаты
Через определенное время остановим тест и взглянем на первые результаты:
- Как и ожидалось, каждый из 10 созданных пользователей при старте зашел на главную страницу
- Список постов в среднем открывался в 2 раза чаще, чем писался комментарий
- Есть среднее и медианное время отклика для каждой операции, количество операций в секунду — это уже полезные данные, хоть сейчас бери и сравнивай их с ожидаемым результатом из требований
На второй вкладке можно посмотреть графики нагрузки в режиме реального времени. В случае, если сервер падает при определенной нагрузке или его поведение меняется, на графике это будет сразу видно.
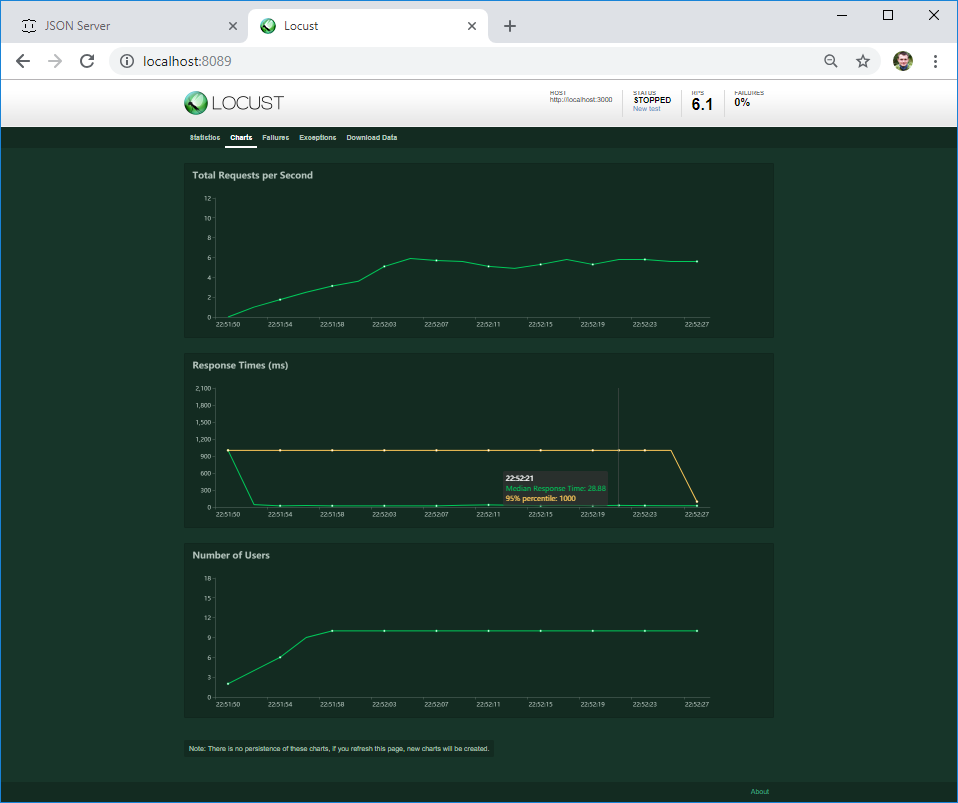
На третей вкладке можно посмотреть ошибки — в моем случае это ошибка клиента. Но если сервер вернет 4ХХ или 5ХХ ошибку — ее текст будет записан именно здесь
Если ошибка случится в коде вашего текста — она попадет во вкладку Exceptions. Пока что у меня самая частая ошибка связана с использованием команды print() в коде — это не лучший способ логирования :)
На последней вкладке можно загрузить все результаты теста в формате csv
Эти результаты релевантны? Давайте разберемся. Чаще всего требования к производительности (если такие вообще заявляются) звучат примерно так: среднее время загрузки страницы (ответа сервера) должно быть меньше N секунд при нагрузке M пользователей. Не особо уточняя, что должны делать пользователи. И этим мне нравится locust — он создает активность конкретного числа пользователей, которые в случайном порядке выполняют предполагаемые действия, которые ожидают от пользователей.
Если нам нужно провести benchmark — измерить поведение системы при разной нагрузке, мы может создать несколько классов поведения и провести несколько тестов при разных нагрузках.
Для начала этого достаточно. Если вам понравилась статья, я в ближайшее время планирую написать о:
- сложных сценариях тестирования, в которых результаты одного шага используются в следующих
- обработке ответа сервера, т.к. он может быть неправильным, даже если пришел HTTP 200 OK
- неочевидных сложностях, с которыми можно столкнутся и как их обойти
- тестировании без использования UI
- распределенном нагрузочном тестировании
Комментарии (15)

saw_tooth
20.11.2018 16:52Мне же JMeter никогда не нравился из-за неочевидного интерфейса и высокого порога вхождения, как только возникает необходимость протестировать не Hello World приложение.
У меня двоякое чувство от этого предложения.
С одной стороны Вы пишете, что интерфейс неочевиден, хотя куда что очевиднее GUI может быть, с другой стороны Locast ничего другого, кроме Hello World, по видимому и не может, но он Вас устроил, почему?
— только поддержка только http
— нет средств серверного мониторинга. Время отклика страницы без CPU/RAM это мягко говоря цифра совершенно бесполезная.
— нет расширенных инструментов, для управления данными (да, jm тоже не богат, но сделать быстрый data in/out там можно несколькими способами)
— нет db коннектора, базу например не отпрофилируешь, не посмотришь опять таки метрики (память/calls/QPS и другое)
— отсутствие системы плагинов, возможно ошибаюсь, но то что есть в локасте — это мало, и оно для приложений как раз больше HW, мало чем подходит. (да, std поставка jm тоже не самая кошерная, но ее можно легко изменить под нужны)
— jm имеет кучу встроенных листенеров/обработчиков, которые просто работают. Распарсить html, запустить js и прочее. Это все есть, было и будет, в отличии от python библиотек, с которыми в первую очередь нужно разобраться, а во вторую — они имеют привычку протухать особенно для всяких не-RFC стандартов, по типу socketIO от js комьюнити (как же я его ненавижу)
Итог получается какой то интересный: jm мне не нравится и плохой, потому что я его «ниосилил», и потому что он может больше, чем мне нужно.
Мне кажется locust и jm — это как notepad и visual studio, да и там и там можно писать текст в редакторе, но сравнивать их совершенно не корректно.
atomheart
20.11.2018 17:02Я хоть и не знаком пока непосредственно с locust, но с вами не соглашусь немного. Т.к. скрипты пишутся на Python, то это значит что:
- Нет отграничений только в рамках http (это скорее нативный код заточен под http, но фактически можно написать все что угодно).
- Про мониторинг я сам спрашивал выше, но предполагаю, что можно создать просто отдельного пользователя, который будет эти метрики собирать (в том числе и из БД). В крайнем случае для сбора метрик можно использовать сторонние инструменты. Да, это неудобно, но это не ограничение.
- Профилирование БД так же вероятно возможно (см. п.2).
saw_tooth
20.11.2018 17:16Ну вот видите, все вытекает из слов:
но фактически можно написать все что угодно
когда в jm это есть — просто используй.
Хотя, положа руку на сердце, в jm тоже есть бесячие моменты (кучерявые графики например), я не отрицаю, но приведенная неочевидность — явно не про него.atomheart
20.11.2018 17:59Ну это как минимум то, чего мне не хватает в JM — возможность скриптовать сценарии.
А тут как бы и любимый Python, и относительная свобода.
А по поводу недостатков, так никто не ограничивает нас только этим инструментом, те же метрики можно собирать JMeter-ом, параллельно с тестом, и вызывать его с коммандной строки при старте теста, останавливать при остановке теста.
Не холивара ради, но как минимум выглядит такое сочетание любопытно. И locust вполне может играть роль связующего звена для всего этого комбайна.
vmm86
20.11.2018 21:56Как раз сейчас по рабочей задаче пишу сервис нагрузочного тестирования на основе Locust. Он показался единственным заслуживающим внимания сервисом нагрузочного тестирования на Python: с одной стороны, из-за большого числа упоминаний в сети и активной разработке на GitHub, с другой стороны, в документации была указана возможность кастомизировать его работу под собственные бизнес-задачи, что и требовалось сделать. Работа пока в процессе, впечатления об инструменте положительные. По завершении проекта попробую подготовить статью на Хабр.-)

tuxi
21.11.2018 00:59В свое время аналогичную проблему (стресс-тест веб-приложения), я решил созданием небольшого распределенного приложения (на java, тогда еще 1.4, потом 5-я теперь 7я). На вход которого подавался файл с ссылками, полученный от Яндекс.вебмастера. Раньше у Я.Вебмастера не было ограничения на кол-во выгружаемых в файл записей, поэтому легко получались реальные тест-кейсы по 2..3..4 млн ссылок (включая «ошибочные» и т.п.).
На нескольких VPS в разных дата-центрах, запускаются пулы этаких «реквестеров», каждому из которых централизованно передается какая то часть ссылок из файла с данными. Также, передаются настройки, сколько потоков запускать, с каким периодом ожидания, нужно ли «парсить» получаемый html (например для проверки наличия тега H1 или соответствия его содержимого некоему шаблону).
Реквестеры, в процессе работы, отсылают на управляющий сервер свою текущую статистику (сколько запросов выполнил каждый их поток, какое среднее время ответа, % ошибок и тому подобное)
Далее подключаем к тестовому аппликейшен серверу jprofiler и наслаждаемся :) ну или в срочном порядке решаем проблему если сразу «все плохо». Нагрузка которую выдерживает тестовый стенд (ну например с метрикой полное «время генерации не больше 1000мс»), практически на 98% совпадает потом с реальной нагрузкой которую приносят на продакшен сервер живые посетители и поисковые боты.
Сейчас Я.Вебмастер дает только 500тыщ ссылок, поэтому дополняем входные данные из файлов access логов.


otchgol
21.11.2018 13:18Искренне считаю, что людям комфортно себя чувтсвующим с любым языком программирования эта штука и не нужна совсем. Усилий на освоение нужно моного, а оттдача сомнительна. JMeter безумно коряв и нестабилен, но два запроса на нем руками сделать быстрее, чем в любом коде. Запись опять же. Я в недоумении.
atomheart
Очень интересно, обязательно пишите еще!
Из вопросов (или я где-то чего-то не понял):
vmm86
Тестовые таски (методы) собираются в таск-сеты (классы). Таски могут быть как выполняемыми по порядку следования в классе, так и случайно вызываемыми. Возможность вызова того или ного таска (как и таск-сета в целом) можно указать целым числом, обозначающим условный «вес» как вероятность выполнения (чем больше число, тем чаще будет выполнение). Также на вход подаются классы, имитирующие «пользователей», отправляющих запросы на основе того или иного таск-сета. При этом наряду с несколькими рабочими тасками можно создать таск, прекращающий работу конкретного «пользователя» (возможность пока недокументированная, но проверенная). Поэтому после небольшой кастомизации можно получить весьма широкие возможности для тестирования:
а) таск-сеты со случайно или последовательно выполняемыми тасками,
б) таск-сеты прерываемые или работающие постоянно (до отключения всего прогона по таймауту или вручную),
в) каждый отдельный таск, как и таск-сет в целом могут иметь кастомную развесовку вероятности своего запуска или не иметь таковой.
Не говоря о том, что клиент, отправляющий запросы, как и отправку событий, определяющих успешность/неуспешность выполнения каждого отдельного запроса могут быть кастомизированы под свои нужды (можно не ограничиваться стандартной обёрткой над requests).
Гарантированно выполнить n раз за m единиц времени сходу не получится, нужно определить оптимальные параметры подбором исходя из числа пользователей и, опять же, распределения вероятностных «весов», если они будут нужны в конкретном случае.
Ypurek Автор