
Вы замечали, как любая рыночная ниша, став популярной, привлекает маркетологов от информационной безопасности, торгующих страхом? Они убеждают вас, что, случись кибератака, компания не сможет самостоятельно справиться ни с одной из задач по реагированию на инцидент. И тут, конечно, появляется добрый волшебник – сервис-провайдер, который за определенную сумму готов избавить заказчика от любых хлопот и необходимости принимать какие-либо решения. Рассказываем, почему такой подход может быть опасен не только для кошелька, но и для уровня защищенности компании, какую практическую пользу может принести вовлечение сервис-провайдера и какие решения должны всегда оставаться в зоне ответственности заказчика.

Прежде всего, разберемся с терминологией. Когда речь идет об управлении инцидентами, чаще всего приходится слышать две аббревиатуры, SOC и CSIRT, значение которых важно понимать, чтобы избежать маркетинговых манипуляций.
Несмотря на то, что в своей деятельности CSIRT чаще всего руководствуется стандартом NIST, включающем полный цикл управления инцидентами, на текущий момент акценты в маркетинговом пространстве чаще ставятся на деятельность по реагированию, отказывая в этой функции SOC и противопоставляя эти два термина.
Шире ли понятие SOC относительно CSIRT? На мой взгляд, да. В своей деятельности SOC не ограничен инцидентами, он может полагаться на данные киберразведки, прогнозы и анализ уровня защищенности организации и включать более широкие задачи по обеспечению безопасности.
Но вернемся к стандарту NIST, как одному из наиболее популярных подходов, описывающих процедуру и фазы управления инцидентами. Общая процедура стандарта NIST SP 800-61 выглядит следующим образом:
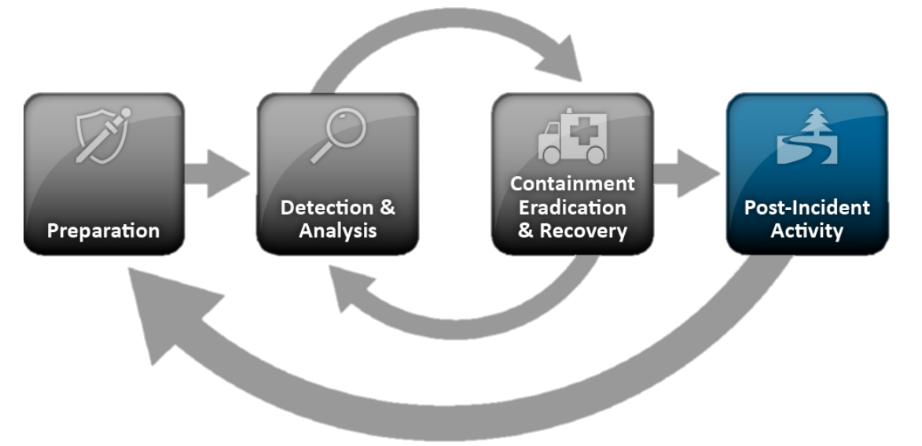
Несмотря на то, что стандарт NIST посвящен Incident Response, значительную часть реагирования занимает раздел «Выявление и анализ инцидентов», в котором фактически описаны классические задачи мониторинга и обработки инцидентов. Почему им уделено такое внимание? чтобы ответить на вопрос, давайте подробнее разберем каждый из этих блоков.
Задача выявления инцидентов начинается с создания и «приземления» модели угроз и модели нарушителя на правила выявления инцидентов. Детектировать инциденты можно, анализируя события информационной безопасности (логи) с различных средств защиты информации, компонентов ИТ-инфраструктуры, прикладных систем, элементов технологических систем (АСУ) и прочих информационных ресурсов. Конечно, можно делать это вручную, скриптами, репортами, но для эффективного real-time выявления инцидентов ИБ все же необходимы специализированные решения.
Здесь на помощь приходят SIEM-системы, но их эксплуатация — не меньший квест, чем анализ «сырых» логов, причем на каждом этапе, начиная с подключения источников и заканчивая созданием инцидентных правил. Трудности связаны с тем, что события, поступающие с различных источников, должны иметь единообразный вид, а ключевые параметры событий должны мапиться в одни и те же поля событий в SIEM вне зависимости от класса /производителя системы или железа.
Правила детектирования инцидентов, списки индикаторов компрометации, тренды киберугроз формируют так называемый «контент» SIEM. Он должен выполнять задачи по сбору профилей сетевой и пользовательской активности, накоплению статистики по событиям различных типов, выявлению типовых инцидентов информационной безопасности. Логика срабатывания правил детектирования инцидентов должна учитывать особенности инфраструктуры и бизнес-процессов конкретной компании. Как нет стандартной инфраструктуры компании и бизнес-процессов, протекающих в ней, так не может быть и унифицированного контента SIEM-системы. Поэтому все изменения ИТ-инфраструктуры компании должны своевременно находить отражение как в настройках и тюнинге средств защиты, так и в SIEM. Если система была настроена только один раз, на старте оказания сервисов, или обновляется раз в год, это снижает шансы на выявление боевых инцидентов и успешную фильтрацию ложных срабатываний в несколько раз.
Таким образом, настройка средств защиты, подключение источников к SIEM-системе и адаптация контента SIEM – это первостепенные задачи в рамках реагирования на инциденты, база, без которой невозможно двигаться дальше. Ведь если инцидент не был своевременно зафиксирован и не прошел через фазы выявления и анализа, о каком-либо реагировании речь уже не идет, мы можем работать лишь с его последствиями.
Служба мониторинга должна работать с инцидентами в real-time режиме круглосуточно и без выходных. Это правило, как азы техники безопасности, написано кровью: примерно половина критичных кибератак начинается ночью, очень часто – в пятницу (так было, например, с вирусом-шифровальщиком WannaCry). Если не принять защитные меры в течение первого часа, дальше уже банально может быть слишком поздно. При этом просто передавать все зафиксированные инциденты на следующий шаг, описанный в стандарте NIST, т.е. на этап локализации, нецелесообразно, и вот почему:
Обычно в службе мониторинга в режиме 24/7 работает первая линия инженеров, которые занимаются непосредственно обработкой потенциальных инцидентов, зафиксированных SIEM-системой. Количество таких инцидентов может достигать нескольких тысяч в сутки (опять-таки – все дальше на этап локализации передавать?), но, к счастью, большинство из них укладываются в известные паттерны. Поэтому чтобы повысить скорость их обработки, можно использовать скрипты и инструкции, пошагово описывающие необходимые действия.
Это проверенная практика, которая позволяет снизить нагрузку на 2 и 3 линию аналитиков – им будут передаваться только те инциденты, которые не укладываются ни в один из имеющихся скриптов. В противном случае либо эскалация инцидентов на вторую и третью линию мониторинга будет достигать 80%, либо на первую линию придется сажать дорогостоящих специалистов с высокой экспертизой и долгим сроком обучения.
Таким образом, помимо сотрудников первой линии необходимы аналитики и архитекторы, которые будут создавать скрипты и инструкции, обучать специалистов первой линии, создавать контент в SIEM, подключать источники, поддерживать работоспособность и интегрировать SIEM с системами классов IRP, CMDB и прочее.
Важной задачей мониторинга является поиск, обработка и имплементация в SIEM-систему различных репутационных баз, APT-репортов, информационных бюллетеней и подписок, которые в конечном счете превращаются в индикаторы компрометации (IoC). Именно они позволяют выявить скрытные атаки злоумышленников на инфраструктуру, вредоносы, не детектируемые антивирусными вендорами, и многое другое. Однако, как и подключение источников событий к SIEM-системе, добавление всей этой информации об угрозах предварительно требует решения ряда задач:
Выше я коснулся лишь части аспектов процесса мониторинга и анализа инцидентов, с которыми придется столкнуться любой компании, выстраивающей процесс реагирования на инциденты. На мой взгляд – это важнейшая задача во всем процессе, но давайте двигаться дальше, и перейдем к блоку работы с уже зафиксированными и проанализированными инцидентами информационной безопасности.
Данный блок, по мнению некоторых специалистов по информационной безопасности, является определяющим в различии между командой мониторинга и командой реагирования на инциденты. Давайте разберем подробнее, что в него вкладывает NIST.
Согласно NIST, главной задачей в процессе локализации инцидента является проработка стратегии, то есть определение мер по недопущению распространения инцидента в пределах инфраструктуры компании. Комплекс этих мер может включать в себя различные действия – изоляцию вовлеченных в инцидент хостов на сетевом уровне, переключение режимов работы средств защиты информации и даже остановку бизнес-процессов компании для минимизации ущерба от инцидента. Фактически, стратегия является playbook`ом, состоящим из матрицы действий в зависимости от типа инцидента.
Выполнение этих действий может относиться к зоне ответственности дежурной смены ИТ-техподдержки, владельцев и администраторов систем (в том числе бизнес-систем), сторонней компании-подрядчика, службы информационной безопасности. Действия могут выполняться вручную, компонентами EDR и даже самописными скриптами, применяемыми по команде.
Поскольку принимаемые на этом этапе решения могут напрямую повлиять на бизнесы-процессы компании, принятие решения о применении конкретной стратегии в абсолютном большинстве случаев остается задачей внутреннего менеджера по информационной безопасности (зачастую с вовлечением владельцев бизнес-систем), и эта задача не может быть передана сторонней компании. Роль провайдера сервисов информационной безопасности в локализации инцидента сводится к оперативному применению выбранной заказчиком стратегии.
После того, как приняты оперативные меры по локализации инцидента, необходимо провести тщательное расследование, собрав всю информацию для оценки масштабов. Эта задача разделяется на две подзадачи:
Также должен быть назначен человек, координирующий действия всех подразделений в рамках расследования инцидента. Этот специалист должен обладать полномочиями и контактами всех задействованных в расследовании сотрудников. Может ли эту роль выполнять сотрудник подрядной организации? Скорее нет, чем да. Логичнее поручить эту роль специалисту или руководителю службы информационной безопасности заказчика.
Получив полную картину инцидента из различных подразделений, координатор вырабатывает меры по устранению последствий инцидента. Эта процедура может включать в себя:
При выработке мер мы рекомендуем координатору консультироваться с профильными подразделениями, ответственными за конкретные системы, администраторами СЗИ, группой форенсики и службой мониторинга инцидентов ИБ. Но, опять-таки, финальное решение о применении тех или иных мер берет на себя координатор группы разбора инцидента.
В этом разделе NIST фактически говорит о задачах ИТ-департамента и службы эксплуатации бизнес-систем. Все работы сводятся к восстановлению и проверке работоспособности ИТ-систем и бизнес-процессов компании. Останавливаться на этом пункте не имеет смысла, так как большинство компаний сталкиваются с решением данных задач если не в результате инцидентов информационной безопасности, то, как минимум, после сбоев, периодически возникающих даже в самых стабильных и отказоустойчивых инсталляциях систем.
Четвертый раздел методики Incident Response посвящен работе над ошибками и совершенствованию технологий защищенности компании.
За подготовку отчета по инциденту, наполнение базы знаний и TI, как правило, отвечает группа форенсики совместно со службой мониторинга. Если по данному инциденту в свое время не была выработана стратегии локализации, ее написание включается в этот блок.
Ну, и очевидно, что очень важным моментом в работе над ошибками является разработка стратегии по недопущению аналогичных инцидентов в будущем:
Таким образом, возможное участие сервис-провайдера в тех или иных этапах реагирования на инциденты можно представить в виде матрицы:
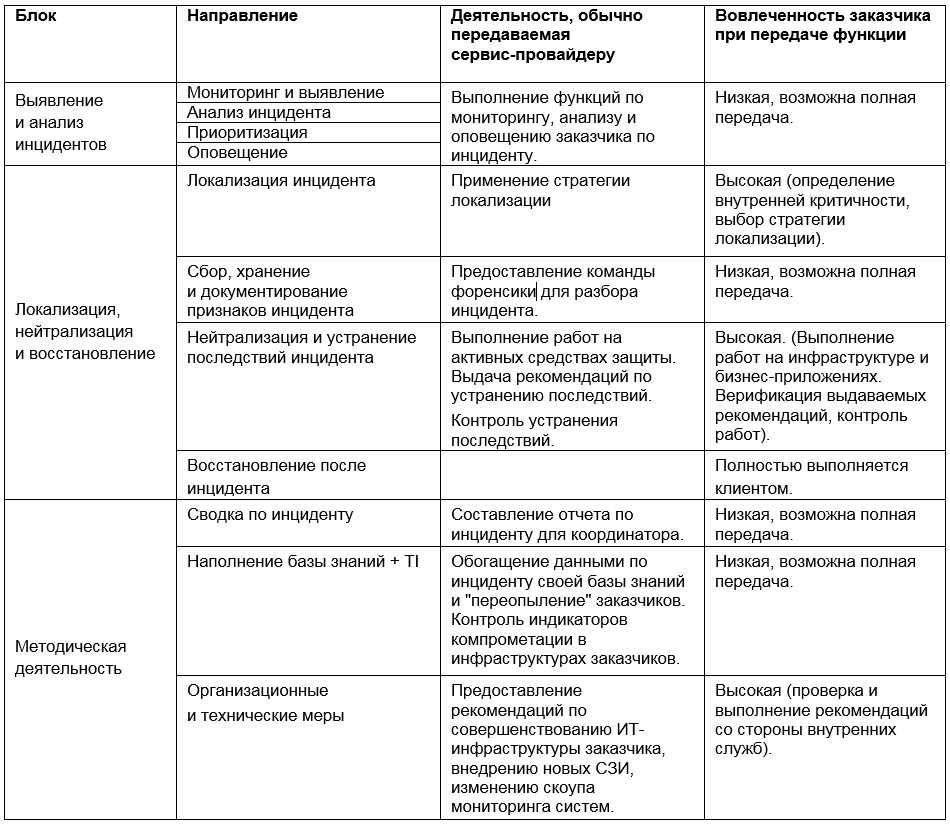
Выбор инструментов и подходов к управлению инцидентами — одна из сложнейших задач информационной безопасности. Соблазн довериться обещаниям сервис-провадера и отдать ему все функции может быть велик, но мы советуем здраво оценивать ситуацию и соблюдать баланс между использованием внутренних и внешних ресурсов — в интересах как экономической, так и процессной эффективности.
Прежде всего, разберемся с терминологией. Когда речь идет об управлении инцидентами, чаще всего приходится слышать две аббревиатуры, SOC и CSIRT, значение которых важно понимать, чтобы избежать маркетинговых манипуляций.
SOC (security operations center) — подразделение, занимающееся операционными задачами информационной безопасности. Чаще всего, говоря о функциях SOC, люди подразумевают мониторинг и выявление инцидентов. Однако обычно в сферу ответственности SOC входят любые задачи, связанные с процессами информационной безопасности, в том числе реагирование и ликвидация последствий инцидентов, методическая деятельность по совершенствованию ИТ-инфраструктуры и повышениею уровня защищенности компании. При этом SOC довольно часто является независимой штатной единицей, включающей специалистов различных профилей.
CSIRT (cybersecurity incident response team) — группа/временно формируемая команда или подразделение, отвечающее за реагирование на возникающие инциденты. CSIRT обычно имеет постоянный костяк, состоящий из ИБ-специалистов, администраторов СЗИ и группы форенсики. Однако итоговый состав команды в каждом случае определяется вектором угрозы и может быть дополнен службой ИТ, владельцами бизнес-систем и даже руководством компании с PR-службой (для нивелирования негативного фона в СМИ).
Несмотря на то, что в своей деятельности CSIRT чаще всего руководствуется стандартом NIST, включающем полный цикл управления инцидентами, на текущий момент акценты в маркетинговом пространстве чаще ставятся на деятельность по реагированию, отказывая в этой функции SOC и противопоставляя эти два термина.
Шире ли понятие SOC относительно CSIRT? На мой взгляд, да. В своей деятельности SOC не ограничен инцидентами, он может полагаться на данные киберразведки, прогнозы и анализ уровня защищенности организации и включать более широкие задачи по обеспечению безопасности.
Но вернемся к стандарту NIST, как одному из наиболее популярных подходов, описывающих процедуру и фазы управления инцидентами. Общая процедура стандарта NIST SP 800-61 выглядит следующим образом:
- Подготовка:
- Создание технической инфраструктуры, необходимой для работы с инцидентами
- Создание правил выявления инцидентов
- Выявление и анализ инцидентов:
- Мониторинг и выявление
- Анализ инцидента
- Приоритизация
- Оповещение
- Локализация, нейтрализация и восстановление:
- Локализация инцидента
- Сбор, хранение, и документирование признаков инцидента
- Нейтрализация и устранение последствий инцидента
- Восстановление после инцидента
- Методическая деятельность:
- Сводка по инциденту
- Наполнение базы знаний + Threat Intelligence
- Организационные и технические меры
Несмотря на то, что стандарт NIST посвящен Incident Response, значительную часть реагирования занимает раздел «Выявление и анализ инцидентов», в котором фактически описаны классические задачи мониторинга и обработки инцидентов. Почему им уделено такое внимание? чтобы ответить на вопрос, давайте подробнее разберем каждый из этих блоков.
Подготовка
Задача выявления инцидентов начинается с создания и «приземления» модели угроз и модели нарушителя на правила выявления инцидентов. Детектировать инциденты можно, анализируя события информационной безопасности (логи) с различных средств защиты информации, компонентов ИТ-инфраструктуры, прикладных систем, элементов технологических систем (АСУ) и прочих информационных ресурсов. Конечно, можно делать это вручную, скриптами, репортами, но для эффективного real-time выявления инцидентов ИБ все же необходимы специализированные решения.
Здесь на помощь приходят SIEM-системы, но их эксплуатация — не меньший квест, чем анализ «сырых» логов, причем на каждом этапе, начиная с подключения источников и заканчивая созданием инцидентных правил. Трудности связаны с тем, что события, поступающие с различных источников, должны иметь единообразный вид, а ключевые параметры событий должны мапиться в одни и те же поля событий в SIEM вне зависимости от класса /производителя системы или железа.
Правила детектирования инцидентов, списки индикаторов компрометации, тренды киберугроз формируют так называемый «контент» SIEM. Он должен выполнять задачи по сбору профилей сетевой и пользовательской активности, накоплению статистики по событиям различных типов, выявлению типовых инцидентов информационной безопасности. Логика срабатывания правил детектирования инцидентов должна учитывать особенности инфраструктуры и бизнес-процессов конкретной компании. Как нет стандартной инфраструктуры компании и бизнес-процессов, протекающих в ней, так не может быть и унифицированного контента SIEM-системы. Поэтому все изменения ИТ-инфраструктуры компании должны своевременно находить отражение как в настройках и тюнинге средств защиты, так и в SIEM. Если система была настроена только один раз, на старте оказания сервисов, или обновляется раз в год, это снижает шансы на выявление боевых инцидентов и успешную фильтрацию ложных срабатываний в несколько раз.
Таким образом, настройка средств защиты, подключение источников к SIEM-системе и адаптация контента SIEM – это первостепенные задачи в рамках реагирования на инциденты, база, без которой невозможно двигаться дальше. Ведь если инцидент не был своевременно зафиксирован и не прошел через фазы выявления и анализа, о каком-либо реагировании речь уже не идет, мы можем работать лишь с его последствиями.
Выявление и анализ инцидентов
Служба мониторинга должна работать с инцидентами в real-time режиме круглосуточно и без выходных. Это правило, как азы техники безопасности, написано кровью: примерно половина критичных кибератак начинается ночью, очень часто – в пятницу (так было, например, с вирусом-шифровальщиком WannaCry). Если не принять защитные меры в течение первого часа, дальше уже банально может быть слишком поздно. При этом просто передавать все зафиксированные инциденты на следующий шаг, описанный в стандарте NIST, т.е. на этап локализации, нецелесообразно, и вот почему:
- Получить дополнительную информацию о происходящем или отфильтровать ложное срабатывание проще и правильнее на этапе анализа, а не локализации инцидента. Это позволяет свести к минимуму количество инцидентов, переданных на следующие этапы процесса Incident Response, где к их рассмотрению должны подключаться более высокоуровневые специалисты – менеджеры по управлению инцидентами, команды реагирования, администраторов ИТ-систем и СЗИ. Логичнее выстраивать процесс таким образом, чтобы не эскалировать каждый пустяк, включая ложные срабатывания, на уровень CISO.
- Деятельность по реагированию и «подавлению» инцидента всегда несет с собой бизнес-риски. Реагирование на инцидент может включать в себя работы по блокированию подозрительных доступов, изоляции хоста, эскалации на уровень руководства. В случае ложноположительного срабатывания каждый из этих шагов напрямую повлияет на доступность элементов инфраструктуры и заставит команду управления инцидентами долго «гасить» собственную эскалацию многостраничными отчетами и служебными записками.
Обычно в службе мониторинга в режиме 24/7 работает первая линия инженеров, которые занимаются непосредственно обработкой потенциальных инцидентов, зафиксированных SIEM-системой. Количество таких инцидентов может достигать нескольких тысяч в сутки (опять-таки – все дальше на этап локализации передавать?), но, к счастью, большинство из них укладываются в известные паттерны. Поэтому чтобы повысить скорость их обработки, можно использовать скрипты и инструкции, пошагово описывающие необходимые действия.
Это проверенная практика, которая позволяет снизить нагрузку на 2 и 3 линию аналитиков – им будут передаваться только те инциденты, которые не укладываются ни в один из имеющихся скриптов. В противном случае либо эскалация инцидентов на вторую и третью линию мониторинга будет достигать 80%, либо на первую линию придется сажать дорогостоящих специалистов с высокой экспертизой и долгим сроком обучения.
Таким образом, помимо сотрудников первой линии необходимы аналитики и архитекторы, которые будут создавать скрипты и инструкции, обучать специалистов первой линии, создавать контент в SIEM, подключать источники, поддерживать работоспособность и интегрировать SIEM с системами классов IRP, CMDB и прочее.
Важной задачей мониторинга является поиск, обработка и имплементация в SIEM-систему различных репутационных баз, APT-репортов, информационных бюллетеней и подписок, которые в конечном счете превращаются в индикаторы компрометации (IoC). Именно они позволяют выявить скрытные атаки злоумышленников на инфраструктуру, вредоносы, не детектируемые антивирусными вендорами, и многое другое. Однако, как и подключение источников событий к SIEM-системе, добавление всей этой информации об угрозах предварительно требует решения ряда задач:
- Автоматизация добавления индикаторов
- Оценка их применимости и релевантности
- Приоритизация и учет устаревания информации
- И самое главное – понимание, с каких средств защиты можно получить информацию для проверки данных индикаторов. Если с сетевыми все довольно просто – проверка на межсетевых экранах и прокси, то с хостовыми сложнее – с чем сравнивать хэши, как на всех хостах проверить запускаемые процессы, ветки реестра и файлы, записывающиеся на жесткий диск?
Выше я коснулся лишь части аспектов процесса мониторинга и анализа инцидентов, с которыми придется столкнуться любой компании, выстраивающей процесс реагирования на инциденты. На мой взгляд – это важнейшая задача во всем процессе, но давайте двигаться дальше, и перейдем к блоку работы с уже зафиксированными и проанализированными инцидентами информационной безопасности.
Локализация, нейтрализация и восстановление
Данный блок, по мнению некоторых специалистов по информационной безопасности, является определяющим в различии между командой мониторинга и командой реагирования на инциденты. Давайте разберем подробнее, что в него вкладывает NIST.
Локализация инцидента
Согласно NIST, главной задачей в процессе локализации инцидента является проработка стратегии, то есть определение мер по недопущению распространения инцидента в пределах инфраструктуры компании. Комплекс этих мер может включать в себя различные действия – изоляцию вовлеченных в инцидент хостов на сетевом уровне, переключение режимов работы средств защиты информации и даже остановку бизнес-процессов компании для минимизации ущерба от инцидента. Фактически, стратегия является playbook`ом, состоящим из матрицы действий в зависимости от типа инцидента.
Выполнение этих действий может относиться к зоне ответственности дежурной смены ИТ-техподдержки, владельцев и администраторов систем (в том числе бизнес-систем), сторонней компании-подрядчика, службы информационной безопасности. Действия могут выполняться вручную, компонентами EDR и даже самописными скриптами, применяемыми по команде.
Поскольку принимаемые на этом этапе решения могут напрямую повлиять на бизнесы-процессы компании, принятие решения о применении конкретной стратегии в абсолютном большинстве случаев остается задачей внутреннего менеджера по информационной безопасности (зачастую с вовлечением владельцев бизнес-систем), и эта задача не может быть передана сторонней компании. Роль провайдера сервисов информационной безопасности в локализации инцидента сводится к оперативному применению выбранной заказчиком стратегии.
Сбор, хранение и документирование признаков инцидента
После того, как приняты оперативные меры по локализации инцидента, необходимо провести тщательное расследование, собрав всю информацию для оценки масштабов. Эта задача разделяется на две подзадачи:
- Передача дополнительных вводных команде мониторинга, подключение дополнительных источников событий информационной безопасности, вовлеченных в инцидент, к системе сбора и анализа событий.
- Подключение команды форенсики для анализа образов жестких дисков, анализа дампов памяти, образцов вредоносного ПО и инструментов, использованных злоумышленниками, в данном инциденте.
Также должен быть назначен человек, координирующий действия всех подразделений в рамках расследования инцидента. Этот специалист должен обладать полномочиями и контактами всех задействованных в расследовании сотрудников. Может ли эту роль выполнять сотрудник подрядной организации? Скорее нет, чем да. Логичнее поручить эту роль специалисту или руководителю службы информационной безопасности заказчика.
Нейтрализация и устранение последствий инцидента
Получив полную картину инцидента из различных подразделений, координатор вырабатывает меры по устранению последствий инцидента. Эта процедура может включать в себя:
- Удаление выявленных индикаторов компрометации и следов присутствия вредоносного ПО / злоумышленников.
- «Перезаливку» зараженных хостов и смену паролей пользователей.
- Установку последних обновлений и выработку компенсационных мер для устранения критических уязвимостей, использованных при атаке.
- Изменение профилей защиты СЗИ.
- Контроль за полнотой выполнения действий со стороны вовлеченных подразделений и отсутствием повторной компрометации систем злоумышленниками.
При выработке мер мы рекомендуем координатору консультироваться с профильными подразделениями, ответственными за конкретные системы, администраторами СЗИ, группой форенсики и службой мониторинга инцидентов ИБ. Но, опять-таки, финальное решение о применении тех или иных мер берет на себя координатор группы разбора инцидента.
Восстановление после инцидента
В этом разделе NIST фактически говорит о задачах ИТ-департамента и службы эксплуатации бизнес-систем. Все работы сводятся к восстановлению и проверке работоспособности ИТ-систем и бизнес-процессов компании. Останавливаться на этом пункте не имеет смысла, так как большинство компаний сталкиваются с решением данных задач если не в результате инцидентов информационной безопасности, то, как минимум, после сбоев, периодически возникающих даже в самых стабильных и отказоустойчивых инсталляциях систем.
Методическая деятельность
Четвертый раздел методики Incident Response посвящен работе над ошибками и совершенствованию технологий защищенности компании.
За подготовку отчета по инциденту, наполнение базы знаний и TI, как правило, отвечает группа форенсики совместно со службой мониторинга. Если по данному инциденту в свое время не была выработана стратегии локализации, ее написание включается в этот блок.
Ну, и очевидно, что очень важным моментом в работе над ошибками является разработка стратегии по недопущению аналогичных инцидентов в будущем:
- Изменение архитектуры ИТ-инфраструктуры и существующих СЗИ.
- Внедрение новых средств защиты информации.
- Введение процесса патч-менеджмента и мониторинга инцидентов информационной безопасности (если отсутствовало).
- Корректировка бизнес-процессов компании.
- Доукомплектование штата специалистов в департаменте ИБ.
- Изменение полномочий сотрудников информационной безопасности.
Роль сервис-провайдера
Таким образом, возможное участие сервис-провайдера в тех или иных этапах реагирования на инциденты можно представить в виде матрицы:
Выбор инструментов и подходов к управлению инцидентами — одна из сложнейших задач информационной безопасности. Соблазн довериться обещаниям сервис-провадера и отдать ему все функции может быть велик, но мы советуем здраво оценивать ситуацию и соблюдать баланс между использованием внутренних и внешних ресурсов — в интересах как экономической, так и процессной эффективности.
saipr
Еще как замечали! Более того страхом торгуют люди как правило ничего несмыслящие в информационной безопасности. Но как правило они и рулят этой рыночной нишей. Рыночной я бы взял в кавычки, так как она со всех сторон обложена законами, нормативными актами и т.д. Спасибо.