
Нижегородский офис компании Intel, помимо прочего, занимается разработкой алгоритмов компьютерного зрения на основе глубоких нейронных сетей. Многие наши алгоритмы публикуются в репозитории Open Model Zoo. Для обучения моделей требуется большое число размеченных данных. Теоретически, существует много способов подготовить их, однако наличие специализированного программного обеспечения многократно ускоряет этот процесс. Так, в целях повышения эффективности и качества разметки, мы разработали собственный инструмент – Computer Vision Annotation Tool (CVAT).
Конечно, на просторах Интернета можно найти немало аннотированных данных, но здесь существуют некоторые проблемы. Например, постоянно возникают новые задачи, для которых таких данных просто нет. Другой вопрос заключается в том, что не все данные пригодны для использования при разработке коммерческих продуктов, по причине их лицензионных соглашений. Таким образом, кроме разработки и тренировки алгоритмов, наша деятельность включает и разметку данных. Это достаточно длительный и трудоемкий процесс, который неразумно было бы возлагать на плечи разработчиков. Например, для обучения одного из наших алгоритмов было размечено около 769 000 объектов за более, чем 3100 человеко-часов.
Существует два варианта решения проблемы:
Изначально Computer Vision Annotation Tool разрабатывался именно для нашей аннотационной команды.

Конечно, у нас не стояло цели создать “15-ый стандарт”. Первое время мы использовали готовое решение – Vatic, но в процессе работы аннотационная и алгоритмические команды предъявляли к нему все новые и новые требования, реализация которых в итоге привела к полному переписыванию программного кода.
Далее в статье:
Computer Vision Annotation Tool (CVAT) – это инструмент с открытым исходным кодом для разметки цифровых изображений и видео. Основной его задачей является предоставление пользователю удобных и эффективных средств разметки наборов данных. Мы создаем CVAT как универсальный сервис, поддерживающий разные типы и форматы разметки.
Для конечных пользователей CVAT – это web-приложение, работающее в браузере. Он поддерживает разные сценарии работы и может быть использован как для персональной, так и для командной работы. Основные задачи машинного обучения с учителем в области обработки изображений можно разбить на три группы:
CVAT пригоден во всех этих сценариях.
Преимущества:
Недостатки:
Конечно, эти списки не исчерпывающие, но содержат основные положения.
Как было сказано ранее, CVAT поддерживает ряд дополнительных компонентов. Среди них:
Deep Learning Deployment Toolkit в составе OpenVINO Toolkit – применяется для ускоренного запуска TF OD API модели при отсутствии GPU. Мы работаем над парой других полезных применений этого компонента.
Tensorflow Object Detection API – используется для автоматической разметки объектов. По умолчанию мы используем модель Faster RCNN Inception Resnet V2, обученную на COCO (80 классов), но не должно возникнуть сложностей с подключением других моделей.
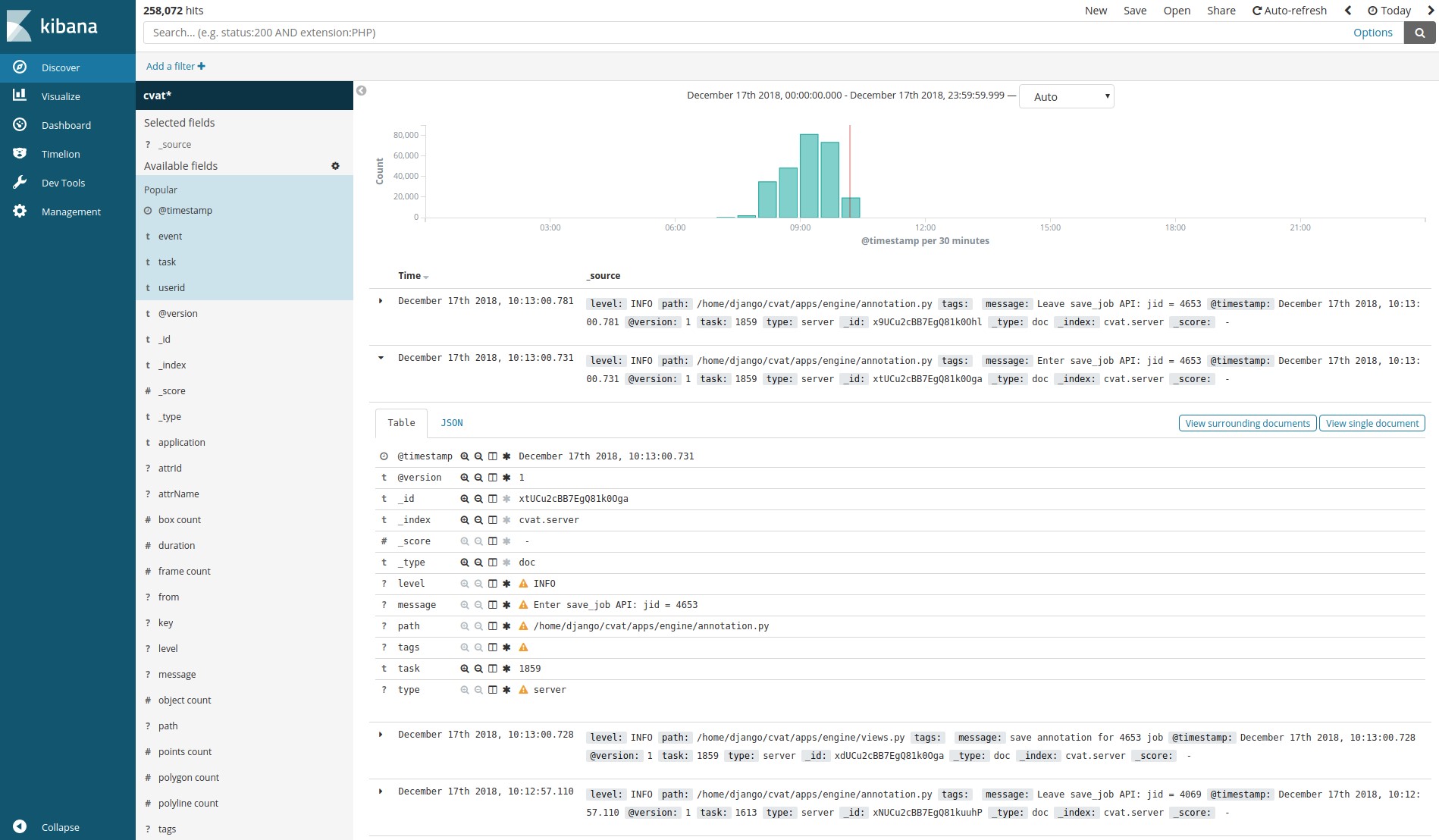
Logstash, Elasticsearch, Kibana – позволяют визуализировать и анализировать накопленные клиентами логи. Это может применяться, например, для мониторинга процесса разметки или поиска ошибок и причин их возникновения.
NVIDIA CUDA Toolkit – набор инструментов для выполнения вычислений на графическом процессоре (GPU). Может использоваться для ускорения автоматической разметки с TF OD API или в других пользовательских дополнениях.
Первое время у нас не было какой-либо унификации и каждая задача разметки выполнялась своими инструментами, в основном – написанными на С++ с использованием библиотеки OpenCV. Эти инструменты ставились локально на машины конечных пользователей, не было механизма разделения данных, общего конвейера постановки и разметки задач, многие вещи приходилось делать вручную.
Отправной точкой истории CVAT можно считать конец 2016 года, когда в качестве инструмента разметки был внедрен Vatic, интерфейс которого представлен ниже. Vatic имел открытый исходный код и вводил некоторые замечательные, общие идеи, как, например интерполяция разметки между ключевыми кадрами на видео или клиент-серверная архитектура приложения. Однако, в целом, он предоставлял довольно скромную функциональность разметки и многое мы дорабатывали сами.
Так, например, за первые полгода была реализована возможность аннотирования изображений, добавлены пользовательские атрибуты объектов, разработана страничка со списком существующих задач и возможностью добавления новых через web интерфейс.
В течение второй половины 2017 года мы внедрили Tensorflow Object Detection API в качестве метода получения предварительной разметки. Было и много мелких доработок клиента, но в конце концов мы столкнулись с тем, что клиентская часть стала работать очень медленно. Дело было в том, что размер задач возрастал, время их открытия увеличивалось пропорционально количеству кадров и размеченных данных, UI тормозил из-за неэффективного представления размечаемых объектов, часто терялся прогресс за часы работы. Производительность в основном проседала на задачах с изображениями, поскольку фундамент тогдашней архитектуры изначально был спроектирован для работы с видео. Проявилась необходимость полного изменения клиентской архитектуры, с чем мы успешно справились. Большинство проблем с производительностью на тот момент ушло. Web интерфейс стал работать намного шустрее и стабильнее. Стала возможной разметка бoльших задач. В тот же период была попытка внедрить unit-тестирование, для обеспечения, в какой-то мере, автоматизации проверок при изменениях. Эта задача уже не была решена столь успешно. Мы настроили QUnit, Karma, Headless Chrome в Docker-контейнере, написали какие-то тесты, запустили все это на CI. Тем не менее, огромная часть кода оставалась, и до сих пор остается не покрытой тестами. Еще одно нововведение представляло из себя систему логирования действий пользователей с последующими поиском и визуализацией на основе ELK Stack. Она позволяет мониторить процесс работы аннотаторов и искать сценарии действий, приводящие к программным исключениям.
В первом половине 2018 года мы расширили клиентскую функциональность. Был добавлен Attribute Annotation Mode, реализующий эффективный сценарий разметки атрибутов, идею которого мы позаимствовали у коллег и обобщили; появились возможности фильтрации объектов по целому ряду признаков, подключения общего хранилища для загрузки данных при постановке задач с просмотром его через браузер и многие другие. Задачи становились объемнее и снова стали возникать проблемы с производительностью, но на этот раз узким местом оказалась уже серверная часть. Проблема Vatic была в том, что он содержал много самописного кода для задач, которые можно было проще и эффективнее решить с помощью готовых решений. Так мы решили переделать серверную часть. В качестве серверного фреймворка мы выбрали Django, во многом из-за его популярности и доступности многих вещей, что называется, “из коробки”. После переделки серверной части, когда от Vatic ничего не осталось, мы решили, что сделали уже достаточно объемную работу, которой можно поделиться с сообществом. Так было принято решение идти в open source. Получить разрешение на это внутри большой компании – достаточно тернистый процесс. Для этого существует большой список требований. В том числе, нужно было придумать имя. Мы набросали варианты и провели серию опросов среди коллег. В итоге, наш внутренний инструмент получил имя CVAT, а 29 июня 2018 года исходный код был опубликован на GitHub в организации OpenCV под лицензией MIT и с начальной версией 0.1.0. Дальнейшая разработка проходила в публичном репозитории.
В конце сентября 2018 года вышла мажорная версия 0.2.0. Здесь было достаточно много мелких изменений и фиксов, однако основной фокус был на поддержке новых видов аннотации. Так появился ряд инструментов для разметки и валидации сегментации, а также возможность аннотации полилиниями или точками.
Следующий релиз, прямо как новогодний подарок, запланирован на 31 декабря 2018 года. Наиболее существенные моменты здесь – опциональная интеграция Deep Learning Deployment Toolkit в составе OpenVINO, который используется для ускоренного запуска TF OD API в случае отсутствия видеокарты NVIDIA; система аналитики логов пользователей, которая ранее не была доступна в публичной версии; многие улучшения в клиентской части.
Мы подвели краткий обзор истории CVAT до настоящего времени (декабрь 2018 года) и рассмотрели наиболее существенные события. Более подробно об истории изменений всегда можно почитать в changelog.
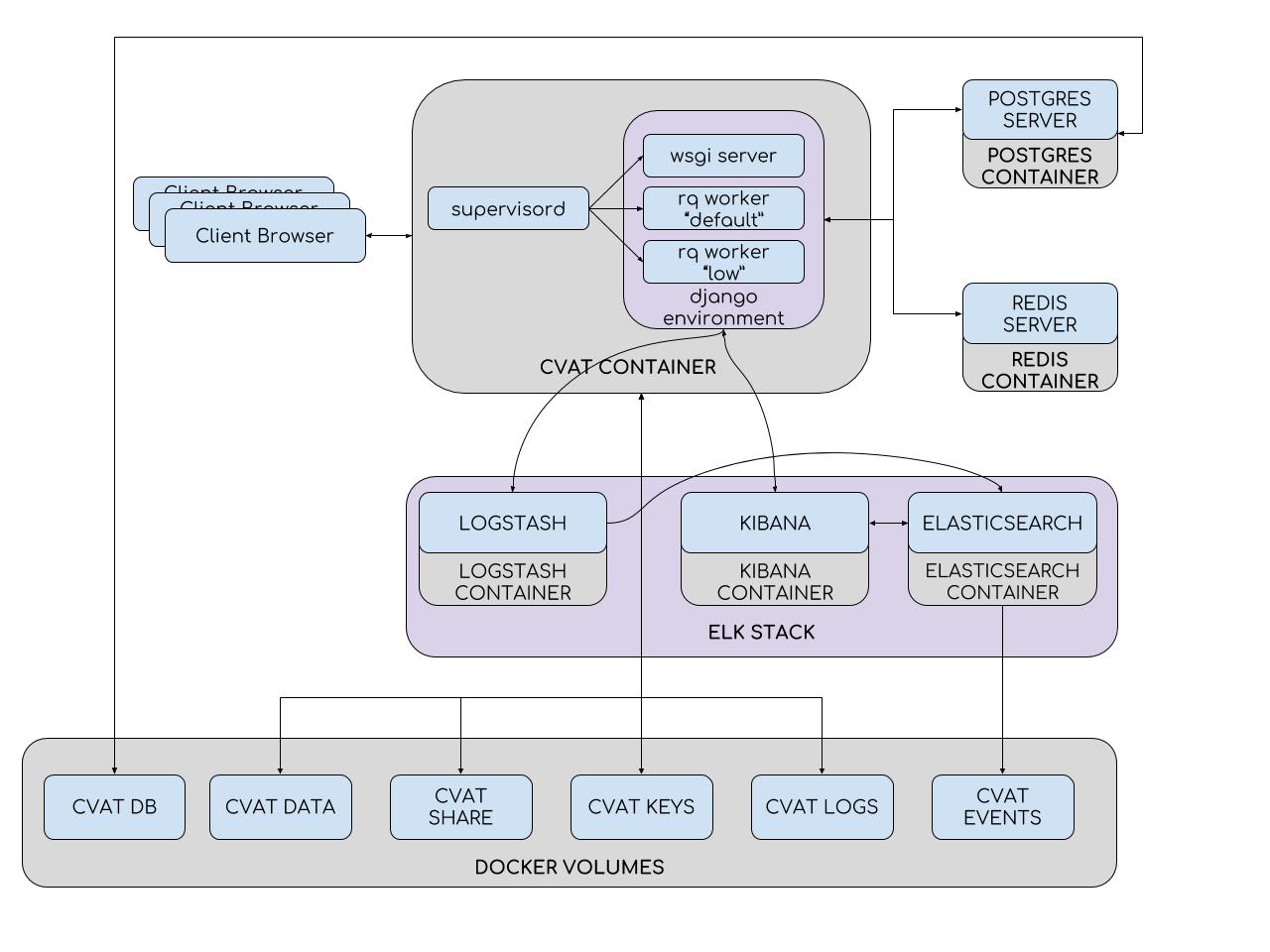
Для упрощения установки и развертывания CVAT использует контейнеры Docker. Система состоит из нескольких контейнеров. В контейнере CVAT выполняется процесс supervisord, который порождает несколько процессов Python в среде Django. Один из них – wsgi server, который занимается обработкой клиентских запросов. Другие процессы – rq workers, служат для обработки «долгих» задач из очередей Redis: default и low. К таким задачам относятся те, что не могут быть обработаны в течение одного пользовательского запроса (постановка задачи, подготовка аннотационного файла, разметка с TF OD API и другие). Количество workers может быть настроено в файле конфигурации supervisord.
Среда Django взаимодействует с двумя серверами баз данных. Сервер Redis хранит состояния очередей задач, а база данных CVAT содержит всю информацию о задачах, пользователях, аннотации и т.д. В качестве СУБД для CVAT используется PostgreSQL (и SQLite 3 при разработке). Все данные хранятся на подключаемом разделе (cvat db volume). Разделы используются там, где необходимо избежать потери данных при обновлении контейнера. Таким образом, в контейнер CVAT монтируются:
Система аналитики состоит из Elasticsearch, Logstash и Kibana, обернутых контейнерами Docker. При сохранении работы на клиенте все данные, включая логи, передаются на сервер. Сервер, в свою очередь, отдает их в Logstash для фильтрации. Кроме того, здесь есть возможность автоматической рассылки уведомлений на почту при возникновении каких-либо ошибок. Далее, логи попадают в Elasticsearch. Последний сохраняет их на подключаемом разделе (cvat events volume). Затем, пользователь может использовать интерфейс Kibana для просмотра статистики и логов. При этом, Kibana будет активно взаимодействовать с Elasticsearch.
На уровне исходного кода CVAT состоит из множества приложений Django:
Мы стремимся создать проект с гибкой структурой. По этой причине опциональные приложения не имеют жесткого (hardcode) встраивания. К сожалению, пока у нас нет идеального прототипа системы плагинов, но постепенно, с разработкой новых приложений, положение дел здесь улучшается.
Клиентская часть реализована на JavaScript и шаблонах Django. При написании кода JavaScript мы используем, в основном, объектно-ориентированную парадигму программирования (насколько позволяет сам язык) и архитектуру model-view-controller. Так, каждому высокоуровневому объекту в клиенте (плеер, фигура, история) соответствует свой файл исходного кода, в котором описано поведение самого объекта. Файл может содержать как один класс (если объект не имеет какого-либо отображения в UI), так и целое множество (как, например, в случае с фигурами: имеем множество разных типов фигур и, следовательно, множество классов models, views и controllers).
Придя в open source, мы получили достаточно много позитивных отзывов от пользователей. Оказалось, что работа востребована сообществом. Возникло множество запросов на новую функциональность. И это прекрасно, потому как теперь не только внутренние потребности определяют направления развития CVAT. Направлений этих, в действительности, немало. Вот некоторые из них:
Существует и множество других запросов на функциональность, которая не относится к вышеперечисленному. К сожалению, запросов всегда больше, чем возможностей для их реализации. По этой причине мы призываем сообщество подключаться и активно участвовать в open source разработке. Это не обязательно должны быть крупные вложения – мы будем рады и небольшим, простым изменениям. Мы подготовили инструкцию в которой описана настройка среды разработки, процесс создания ваших PR и многое другое. Как было сказано ранее, пока нет документации для разработчиков, но вы всегда можете обратиться за помощью к нам в чат в Gitter. Поэтому спрашивайте, включайтесь и творите! Всем удачи!
Конечно, на просторах Интернета можно найти немало аннотированных данных, но здесь существуют некоторые проблемы. Например, постоянно возникают новые задачи, для которых таких данных просто нет. Другой вопрос заключается в том, что не все данные пригодны для использования при разработке коммерческих продуктов, по причине их лицензионных соглашений. Таким образом, кроме разработки и тренировки алгоритмов, наша деятельность включает и разметку данных. Это достаточно длительный и трудоемкий процесс, который неразумно было бы возлагать на плечи разработчиков. Например, для обучения одного из наших алгоритмов было размечено около 769 000 объектов за более, чем 3100 человеко-часов.
Существует два варианта решения проблемы:
- Первый – передать данные на разметку сторонним компаниям, с соответствующей специализацией. Мы имели подобный опыт. Здесь стоит отметить усложненный процесс валидации и переразметки данных, а также наличие бюрократии.
- Второй, более удобный для нас – создание и поддержка собственной аннотационной команды. Удобство заключается в возможности быстро ставить новые задачи, управлять ходом их выполнения и облегченной балансировке между ценой и качеством. Кроме того, есть возможность внедрять собственные алгоритмы автоматизации и повышения качества разметки.
Изначально Computer Vision Annotation Tool разрабатывался именно для нашей аннотационной команды.
Конечно, у нас не стояло цели создать “15-ый стандарт”. Первое время мы использовали готовое решение – Vatic, но в процессе работы аннотационная и алгоритмические команды предъявляли к нему все новые и новые требования, реализация которых в итоге привела к полному переписыванию программного кода.
Далее в статье:
- Общие сведения (функциональность, области применения, преимущества и недостатки инструмента)
- История и эволюция (краткое повествование о том, как CVAT жил и развивался)
- Внутреннее устройство (высокоуровневое описание архитектуры)
- Направления развития (немного о целях, которых хотелось бы достичь, и возможных путях к ним)
Общие сведения
Computer Vision Annotation Tool (CVAT) – это инструмент с открытым исходным кодом для разметки цифровых изображений и видео. Основной его задачей является предоставление пользователю удобных и эффективных средств разметки наборов данных. Мы создаем CVAT как универсальный сервис, поддерживающий разные типы и форматы разметки.
Для конечных пользователей CVAT – это web-приложение, работающее в браузере. Он поддерживает разные сценарии работы и может быть использован как для персональной, так и для командной работы. Основные задачи машинного обучения с учителем в области обработки изображений можно разбить на три группы:
- Детектирование объектов
- Классификация изображений
- Сегментация изображений
CVAT пригоден во всех этих сценариях.
Преимущества:
- Отсутствие установки у конечных пользователей. Для создания задачи или разметки данных достаточно открыть определенную ссылку в браузере.
- Возможность совместной работы. Существует возможность сделать задачу общедоступной для пользователей и распараллелить работу над ней.
- Простота развертывания. Установка CVAT в локальной сети осуществляется парой команд за счет применения Docker.
- Автоматизация процесса разметки. Интерполяция, к примеру, позволяет получить разметку на множестве кадров, при реальной работе лишь над некоторыми ключевыми.
- Опыт профессионалов. Инструмент разрабатывался с участием аннотационной и нескольких алгоритмических команд.
- Возможность интеграции. CVAT пригоден для встраивания в платформы более широкого назначения. Например Onepanel.
- Опциональная поддержка различных инструментов:
- Deep Learning Deployment Toolkit (компонент в составе OpenVINO)
- Tensorflow Object Detection API (TF OD API)
- ELK (Elasticsearch + Logstash + Kibana) система аналитики
- NVIDIA CUDA Toolkit
- Поддержка разных аннотационных сценариев.
- Открытый исходный код под простой и свободной лицензией MIT.
Недостатки:
- Ограниченная поддержка браузеров. Работоспособность клиентской части гарантируется только в браузере Google Chrome. Мы не тестируем CVAT в других браузерах, но теоретически инструмент может заработать в Opera, Yandex Browser и других с движком Chromium.
- Не проработана система автоматических тестов. Все проверки работоспособности проводятся вручную, что существенно замедляет разработку. Однако, мы уже работаем над решением этой проблемы совместно со студентами ННГУ им. Лобачевского в рамках проекта IT Lab.
- Отсутствует документация по исходному коду. Включиться в разработку может быть достаточно трудно.
- Ограничения по производительности. С увеличением требований по объемам разметки мы столкнулись с разными проблемами, как например, ограничение Chrome Sandbox по использованию оперативной памяти.
Конечно, эти списки не исчерпывающие, но содержат основные положения.
Как было сказано ранее, CVAT поддерживает ряд дополнительных компонентов. Среди них:
Deep Learning Deployment Toolkit в составе OpenVINO Toolkit – применяется для ускоренного запуска TF OD API модели при отсутствии GPU. Мы работаем над парой других полезных применений этого компонента.
Tensorflow Object Detection API – используется для автоматической разметки объектов. По умолчанию мы используем модель Faster RCNN Inception Resnet V2, обученную на COCO (80 классов), но не должно возникнуть сложностей с подключением других моделей.
Logstash, Elasticsearch, Kibana – позволяют визуализировать и анализировать накопленные клиентами логи. Это может применяться, например, для мониторинга процесса разметки или поиска ошибок и причин их возникновения.
NVIDIA CUDA Toolkit – набор инструментов для выполнения вычислений на графическом процессоре (GPU). Может использоваться для ускорения автоматической разметки с TF OD API или в других пользовательских дополнениях.
Разметка данных
- Процесс начинается с постановки задачи для разметки. Постановка включает в себя:
- Указание названия задачи
- Перечисление классов, подлежащих разметке и их атрибутов
- Указание файлов на загрузку
- Данные загружаются с локальной файловой системы, либо с распределенной, смонтированной в контейнере файловой системы
- Задача может содержать один архив с изображениями, одно видео, набор изображений и даже структуру каталогов с изображениями при загрузке через распределенное хранилище
- Опционально задаются:
- Ссылка на подробную спецификацию разметки, а также любую другую дополнительную информацию (Bug Tracker)
- Ссылка на удаленный Git-репозиторий для хранения аннотации (Dataset Repository)
- Поворот всех изображений на 180 градусов (Flip Images)
- Поддержка слоев для задач сегментации (Z-Order)
- Размер сегмента (Segment Size). Загружаемая задача может быть разбита на несколько подзадач для параллельной работы
- Область пересечения сегментов (Overlap). Используется в видео для слияния аннотации в разных сегментах
- Уровень качества при конвертации изображений (Image Quality)
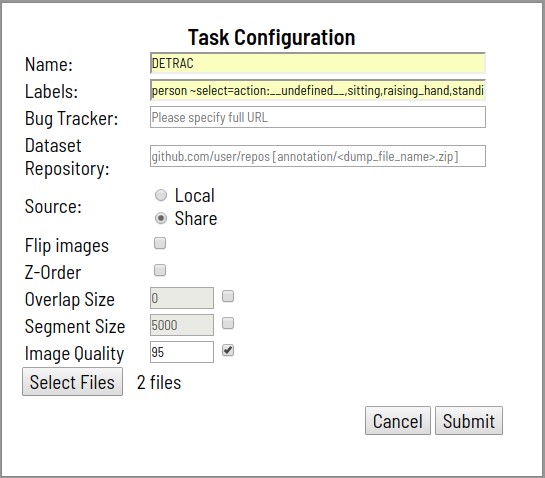
- После обработки запроса, созданная задача появится в списке задач.

- Каждая из ссылок в разделе «Jobs» соответствует одному сегменту. В данном случае, задача предварительно не разбивалась на сегменты. При нажатии на любую из ссылок открывается страница разметки.

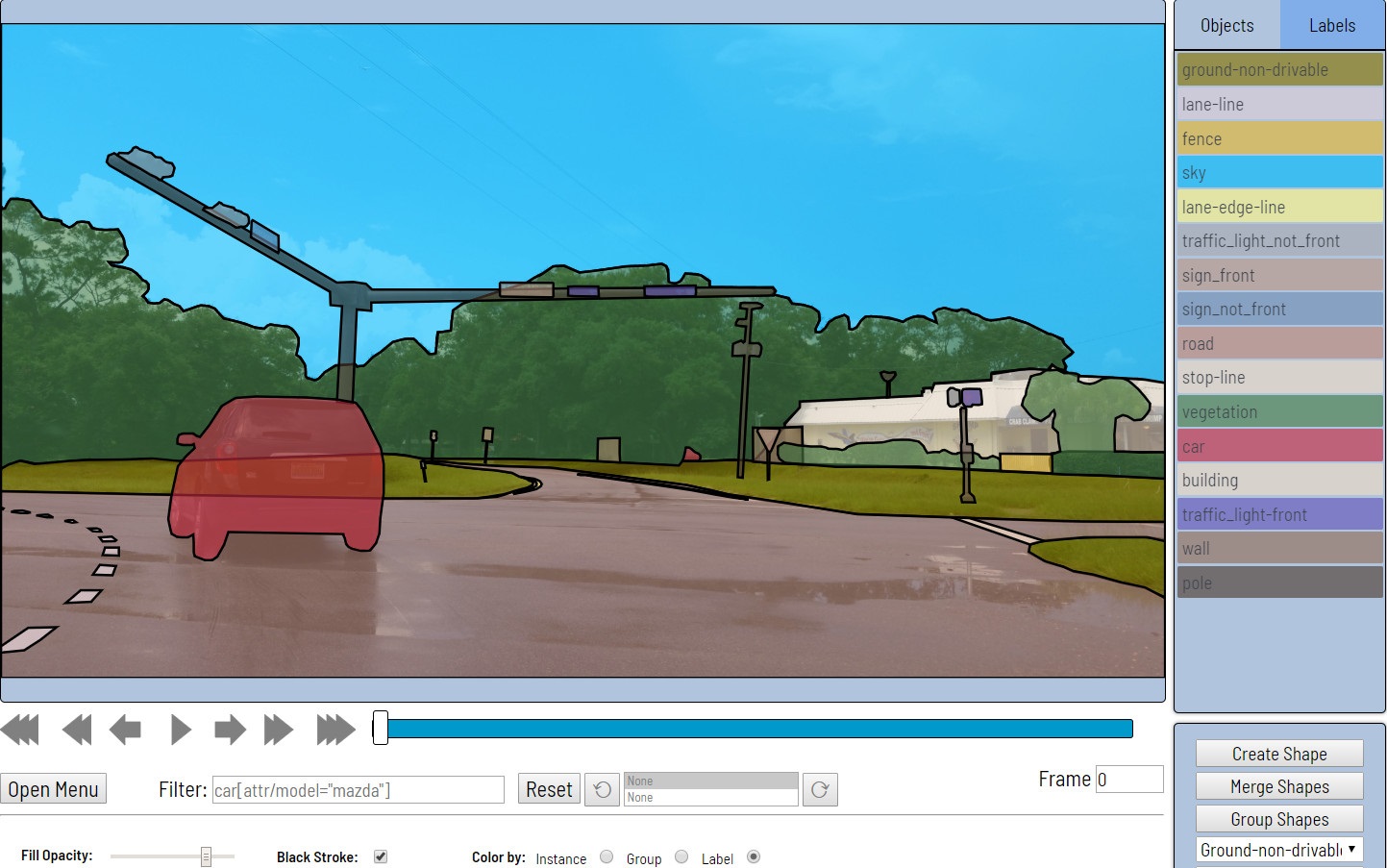
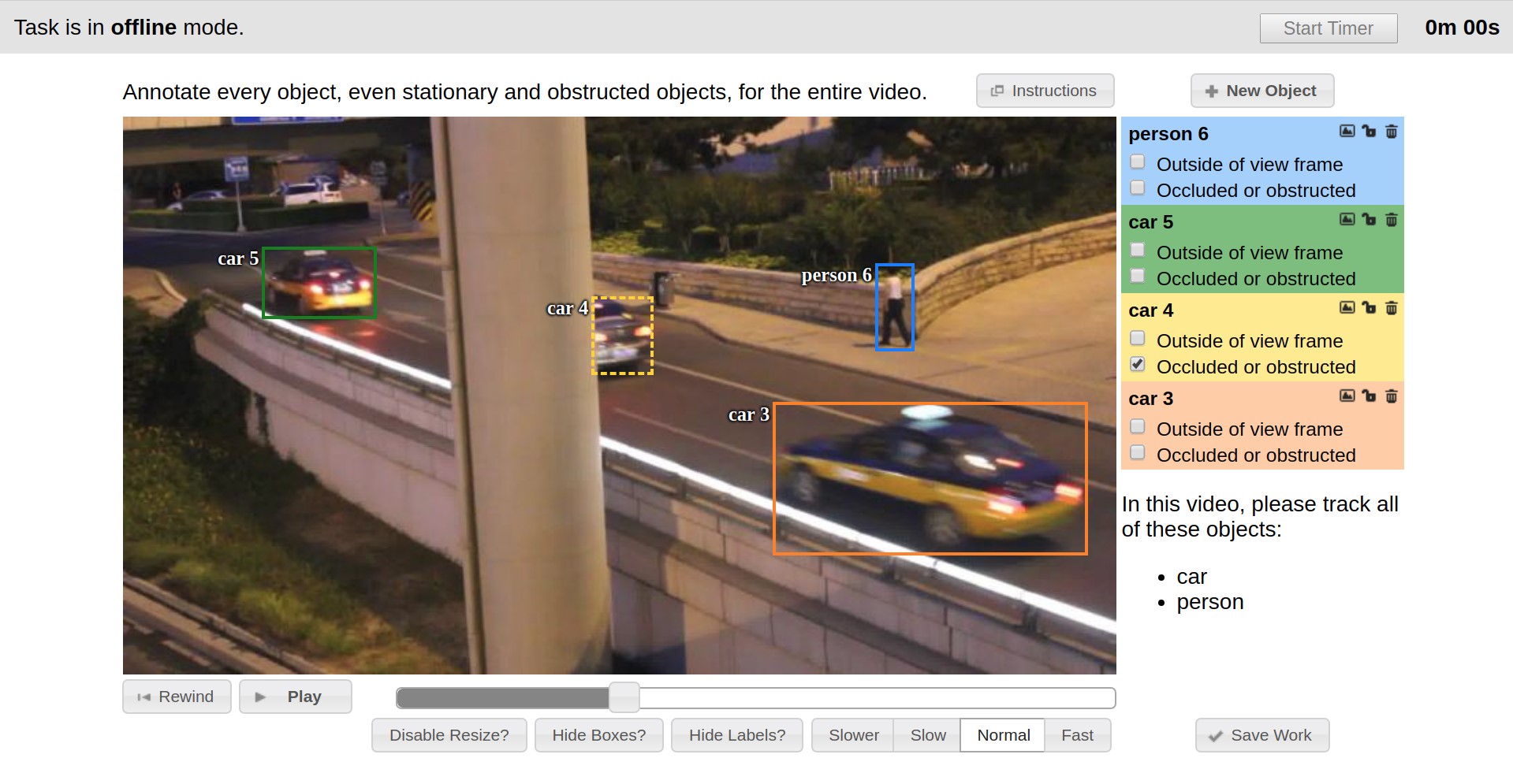
- Далее происходит непосредственно разметка данных. В качестве примитивов предоставляются прямоугольники, полигоны (в основном для задач сегментации), полилинии (могут быть полезны, например, для дорожной разметки) и множества точек (например, разметка face landmarks или pose estimation).
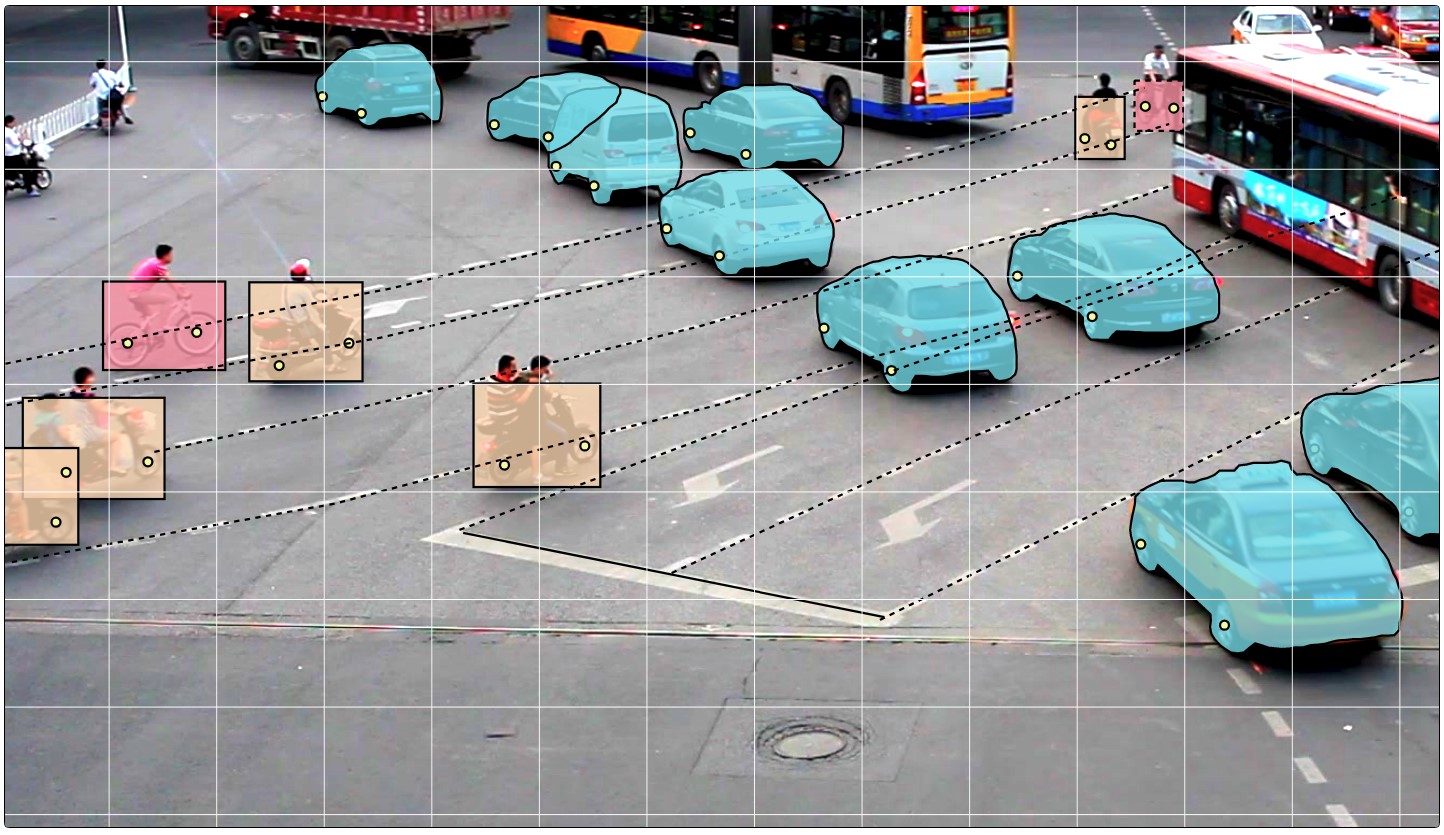
Доступны также разные инструменты автоматизации (копирование, размножение на другие кадры, интерполяция, предварительная разметка с TF OD API), визуальные настройки, множество горячих клавиш, поиск, фильтрация и другая полезная функциональность. В окне настроек можно изменять ряд параметров для более комфортной работы.
Диалоговое окно помощи содержит множество поддерживаемых сочетаний горячих клавиш и некоторые другие подсказки.

Процесс разметки можно увидеть в примерах ниже.
CVAT может выполнять линейную интерполяцию прямоугольников и атрибутов между ключевыми кадрами видео. За счет этого аннотация на множестве кадров выводится автоматически.
Для сценария классификации был разработан Attribute Annotation Mode, который позволяет ускоренно аннотировать атрибуты за счет концентрации внимания разметчика на одном определенном свойстве. Кроме того, разметка здесь происходит за счет использования «горячих клавиш».
С помощью полигонов поддерживаются сценарии semantic segmentation и instance segmentation. Разные визуальные настройки облегчают процесс валидации.
- Получение аннотации
Нажатие кнопки «Dump Annotation» инициирует процесс подготовки и загрузки результатов разметки в виде одного файла. Файл аннотации – это специфицированный .xml файл, который содержит некоторые метаданные задачи и всю аннотацию. Разметку можно загрузить прямо в Git-репозиторий, если последний был подключен на этапе создания задачи.
История и эволюция
Первое время у нас не было какой-либо унификации и каждая задача разметки выполнялась своими инструментами, в основном – написанными на С++ с использованием библиотеки OpenCV. Эти инструменты ставились локально на машины конечных пользователей, не было механизма разделения данных, общего конвейера постановки и разметки задач, многие вещи приходилось делать вручную.
Отправной точкой истории CVAT можно считать конец 2016 года, когда в качестве инструмента разметки был внедрен Vatic, интерфейс которого представлен ниже. Vatic имел открытый исходный код и вводил некоторые замечательные, общие идеи, как, например интерполяция разметки между ключевыми кадрами на видео или клиент-серверная архитектура приложения. Однако, в целом, он предоставлял довольно скромную функциональность разметки и многое мы дорабатывали сами.
Так, например, за первые полгода была реализована возможность аннотирования изображений, добавлены пользовательские атрибуты объектов, разработана страничка со списком существующих задач и возможностью добавления новых через web интерфейс.
В течение второй половины 2017 года мы внедрили Tensorflow Object Detection API в качестве метода получения предварительной разметки. Было и много мелких доработок клиента, но в конце концов мы столкнулись с тем, что клиентская часть стала работать очень медленно. Дело было в том, что размер задач возрастал, время их открытия увеличивалось пропорционально количеству кадров и размеченных данных, UI тормозил из-за неэффективного представления размечаемых объектов, часто терялся прогресс за часы работы. Производительность в основном проседала на задачах с изображениями, поскольку фундамент тогдашней архитектуры изначально был спроектирован для работы с видео. Проявилась необходимость полного изменения клиентской архитектуры, с чем мы успешно справились. Большинство проблем с производительностью на тот момент ушло. Web интерфейс стал работать намного шустрее и стабильнее. Стала возможной разметка бoльших задач. В тот же период была попытка внедрить unit-тестирование, для обеспечения, в какой-то мере, автоматизации проверок при изменениях. Эта задача уже не была решена столь успешно. Мы настроили QUnit, Karma, Headless Chrome в Docker-контейнере, написали какие-то тесты, запустили все это на CI. Тем не менее, огромная часть кода оставалась, и до сих пор остается не покрытой тестами. Еще одно нововведение представляло из себя систему логирования действий пользователей с последующими поиском и визуализацией на основе ELK Stack. Она позволяет мониторить процесс работы аннотаторов и искать сценарии действий, приводящие к программным исключениям.
В первом половине 2018 года мы расширили клиентскую функциональность. Был добавлен Attribute Annotation Mode, реализующий эффективный сценарий разметки атрибутов, идею которого мы позаимствовали у коллег и обобщили; появились возможности фильтрации объектов по целому ряду признаков, подключения общего хранилища для загрузки данных при постановке задач с просмотром его через браузер и многие другие. Задачи становились объемнее и снова стали возникать проблемы с производительностью, но на этот раз узким местом оказалась уже серверная часть. Проблема Vatic была в том, что он содержал много самописного кода для задач, которые можно было проще и эффективнее решить с помощью готовых решений. Так мы решили переделать серверную часть. В качестве серверного фреймворка мы выбрали Django, во многом из-за его популярности и доступности многих вещей, что называется, “из коробки”. После переделки серверной части, когда от Vatic ничего не осталось, мы решили, что сделали уже достаточно объемную работу, которой можно поделиться с сообществом. Так было принято решение идти в open source. Получить разрешение на это внутри большой компании – достаточно тернистый процесс. Для этого существует большой список требований. В том числе, нужно было придумать имя. Мы набросали варианты и провели серию опросов среди коллег. В итоге, наш внутренний инструмент получил имя CVAT, а 29 июня 2018 года исходный код был опубликован на GitHub в организации OpenCV под лицензией MIT и с начальной версией 0.1.0. Дальнейшая разработка проходила в публичном репозитории.
В конце сентября 2018 года вышла мажорная версия 0.2.0. Здесь было достаточно много мелких изменений и фиксов, однако основной фокус был на поддержке новых видов аннотации. Так появился ряд инструментов для разметки и валидации сегментации, а также возможность аннотации полилиниями или точками.
Следующий релиз, прямо как новогодний подарок, запланирован на 31 декабря 2018 года. Наиболее существенные моменты здесь – опциональная интеграция Deep Learning Deployment Toolkit в составе OpenVINO, который используется для ускоренного запуска TF OD API в случае отсутствия видеокарты NVIDIA; система аналитики логов пользователей, которая ранее не была доступна в публичной версии; многие улучшения в клиентской части.
Мы подвели краткий обзор истории CVAT до настоящего времени (декабрь 2018 года) и рассмотрели наиболее существенные события. Более подробно об истории изменений всегда можно почитать в changelog.
Внутреннее устройство
Для упрощения установки и развертывания CVAT использует контейнеры Docker. Система состоит из нескольких контейнеров. В контейнере CVAT выполняется процесс supervisord, который порождает несколько процессов Python в среде Django. Один из них – wsgi server, который занимается обработкой клиентских запросов. Другие процессы – rq workers, служат для обработки «долгих» задач из очередей Redis: default и low. К таким задачам относятся те, что не могут быть обработаны в течение одного пользовательского запроса (постановка задачи, подготовка аннотационного файла, разметка с TF OD API и другие). Количество workers может быть настроено в файле конфигурации supervisord.
Среда Django взаимодействует с двумя серверами баз данных. Сервер Redis хранит состояния очередей задач, а база данных CVAT содержит всю информацию о задачах, пользователях, аннотации и т.д. В качестве СУБД для CVAT используется PostgreSQL (и SQLite 3 при разработке). Все данные хранятся на подключаемом разделе (cvat db volume). Разделы используются там, где необходимо избежать потери данных при обновлении контейнера. Таким образом, в контейнер CVAT монтируются:
- Раздел с видео и изображениями (cvat data volume)
- Раздел с ключами (cvat keys volume)
- Раздел с логами (cvat logs volume)
- Общее файловое хранилище (cvat shared volume)
Система аналитики состоит из Elasticsearch, Logstash и Kibana, обернутых контейнерами Docker. При сохранении работы на клиенте все данные, включая логи, передаются на сервер. Сервер, в свою очередь, отдает их в Logstash для фильтрации. Кроме того, здесь есть возможность автоматической рассылки уведомлений на почту при возникновении каких-либо ошибок. Далее, логи попадают в Elasticsearch. Последний сохраняет их на подключаемом разделе (cvat events volume). Затем, пользователь может использовать интерфейс Kibana для просмотра статистики и логов. При этом, Kibana будет активно взаимодействовать с Elasticsearch.
На уровне исходного кода CVAT состоит из множества приложений Django:
- authentication – аутентификация пользователей в системе (базовая и LDAP)
- engine – ключевое приложение (основные модели базы данных; загрузка и сохранение задач; загрузка и выгрузка аннотации; клиентский интерфейс разметки; интерфейс сервера для создания, изменения и удаления задач)
- dashboard – интерфейс клиента для создания, редактирования, поиска и удаления задач
- documentation – отображение пользовательской документации в интерфейсе клиента
- tf_annotation – автоматическая аннотация с Tensorflow Object Detection API
- log_viewer – отправка логов с клиента в Logstash при сохранении задачи
- log_proxy – прокси соединение CVAT > Kibana
- git – интеграция Git-репозиториев для хранения готовой аннотации
Мы стремимся создать проект с гибкой структурой. По этой причине опциональные приложения не имеют жесткого (hardcode) встраивания. К сожалению, пока у нас нет идеального прототипа системы плагинов, но постепенно, с разработкой новых приложений, положение дел здесь улучшается.
Клиентская часть реализована на JavaScript и шаблонах Django. При написании кода JavaScript мы используем, в основном, объектно-ориентированную парадигму программирования (насколько позволяет сам язык) и архитектуру model-view-controller. Так, каждому высокоуровневому объекту в клиенте (плеер, фигура, история) соответствует свой файл исходного кода, в котором описано поведение самого объекта. Файл может содержать как один класс (если объект не имеет какого-либо отображения в UI), так и целое множество (как, например, в случае с фигурами: имеем множество разных типов фигур и, следовательно, множество классов models, views и controllers).
Направления развития
Придя в open source, мы получили достаточно много позитивных отзывов от пользователей. Оказалось, что работа востребована сообществом. Возникло множество запросов на новую функциональность. И это прекрасно, потому как теперь не только внутренние потребности определяют направления развития CVAT. Направлений этих, в действительности, немало. Вот некоторые из них:
- Сделать CVAT более удобным, интуитивно понятным, максимально быстрым и, наконец, просто красивым. Для этого необходимо во многом переработать UI с привлечением профессиональных дизайнеров и с внедрением современных подходов.
- Охватить больший круг аннотационных сценариев. Например, добавить разметку кубоидами или сортировку изображений по определенному признаку.
- Повысить надежность и стабильность инструмента, упростить разработку. Здесь стоит вопрос переработки системы автоматического тестирования до состояния, когда она оказалась бы действительно эффективной и полезной.
- Расширить возможности по автоматической разметке. Внедрить больше deep learning моделей, автоматизирующих разметку. В частности, с Deep Learning Deployment Toolkit есть возможность подключить большое количество разнообразных моделей из OpenVINO без каких-либо дополнительных зависимостей. У нас уже есть несколько полезных фишек, но по ряду причин они пока не вошли в публичный репозиторий. Кроме того, хотелось бы поддержать загрузку пользовательских моделей.
- Разработать demo-сервер CVAT, для того, чтобы любой желающий мог зайти туда и опробовать инструмент в действии, не тратя время на установку. Существует сторонний demo-сервер от Onepanel, однако CVAT в нем претерпел существенные модификации и мы не можем отвечать за стабильность его работы.
- Интегрировать платформу Amazon Mechanical Turk в CVAT для разметки данных с помощью краудсорсинга. Эта платформа предоставляет готовый SDK для этих целей.
Существует и множество других запросов на функциональность, которая не относится к вышеперечисленному. К сожалению, запросов всегда больше, чем возможностей для их реализации. По этой причине мы призываем сообщество подключаться и активно участвовать в open source разработке. Это не обязательно должны быть крупные вложения – мы будем рады и небольшим, простым изменениям. Мы подготовили инструкцию в которой описана настройка среды разработки, процесс создания ваших PR и многое другое. Как было сказано ранее, пока нет документации для разработчиков, но вы всегда можете обратиться за помощью к нам в чат в Gitter. Поэтому спрашивайте, включайтесь и творите! Всем удачи!
Ссылки
Комментарии (5)

anonymous
25.12.2018 16:20Вы к киношникам на постпродакшн обратитесь — те постоянно масками обводят объекты, и инструменты там еще более изощренные, такая точность вам и не снилась)
roryorangepants
Очень круто.
Думаю, многие компании имеют что-то подобное в качестве внутреннего инструмента (мне и самому приходилось писать утилиту такого плана для одного проекта), но обычно это так и остается в пределах компании.