
Проблематика
Для больших и технически сложных проектов, над которыми как правило одновременно работают много распределенных команд, существует известная проблема версионности разрабатываемого ПО, которую разные компании решают по-разному.
В настоящее время ряд наших клиентов и партнеров делают поставку последних релизов (CI/CD) на Production вручную через установку последних/актуальных версий своего ПО, предварительно протестировав его с остальным окружением. Например, путем поставки сборок приложений iOS, Android и проч., если мы говорим про клиентском ПО, или через обновление docker-images в среде docker-окружения, если мы говорим о backend. Для больших и важных проектов, где решение о выходе новой версии в Production каждый раз принимается Project Manager, такое решение вполне оправданно и не слишком затратно, особенно если релизы выходят не часто. Однако для тестовой среды разработки (Dev/Stage environment) использование «ручных» инструментов приводит к запутанности проекта, возможным срывам показов Заказчику и проч. Причин тому может быть множество, в том числе и несогласованность версий различных контейнеров на middleware ПО или отсутствие детальной истории по релизам.
В этом нам пришлось убедиться лично и испытать много сложностей на большом проекте, в котором в день выпускалось по 6-8 новых версий ПО на backend и 2-3 версии ПО на frontend в системе CI, где инженеры по тестированию объективно не справлялись с нагрузкой и было постоянное непонимание какую же версию ПО на frontend/backend считать на текущий момент стабильной.
Наш опыт
Наша компания в своей работе использует различные системы CI/CD, выбор которых зачастую обусловлен требованиями со стороны Заказчика. Так, например, наши специалисты часто сталкиваются с такими системами CI/CD как Jenkins, TeamCity, Travis CI, Circle CI, Gitlab CI, Atlassian Bamboo, где порой мы работаем полностью на инфраструктуре Заказчика. Соответственно, при таком подходе вопрос с решением версионности полностью лежит на Заказчике.
При разработке решений для клиентов, когда у нас есть возможность делать это на собственной инфраструктуре, в качестве основой системы Continuous Integration / Continuous Delivery мы применяем TFS версии 2018. Это позволяет нам решать основную задачу формирования полного цикла разработки ПО, а именно:
- Постановка задач (Issues, Bugs, Tasks) на основе используемого в текущем проекте подхода к разработке ПО;
- Хранение исходного кода проекта;
- Разворачивание инфраструктуры build-агентов для сборок под разные ОС (Windows, Linux, MacOS);
- Сборки проектов в «ручном» режиме и CI;
- Разворачивание проектов в «ручном» режиме и CD;
- Тестирование проектов;
- Формирование данных в части затраченного сотрудниками времени на проект и ряд дополнительных функций, которые мы реализовали с помощью TFS Extensions собственной разработки и через добавление статики в WIT (в данном виде TFS заменил нашей компании Redmine и упростил сбор статистики, отчетов и проч. в разрезе проектов).
В этом случае решение проблемы версионности было бы логичным возложить на TFS, дорабатывая функционал TFS под наши задачи и пожелания Заказчика. В итоге задача построения системы версионности для проектов микросервисной архитектуры была нами решена средствами TFS путем кастомизации различных сценариев сборок и упорядочивания тестовых/релизных окружений.
Путь решения: использование TFS и сторонних инструментов
Итак, нам нужна система версионности для проектов микросервисной архитектуры для упорядочивания тестовых окружений и релизов.
В качестве исходных данных мы имеем:
- Оркестрация – используем docker swarm в основном для того, чтобы сократить использование других сторонних инструментов. При этом, существует конверторы по преобразованию конфигов – например, утилита Kompose, что позволит использовать Kubernetes при необходимости.
- Build-агентов – VM на базе Linux-серверов.
- Репозиторий исходников – Git на базе TFS.
- Хранения образов – docker registry на VM.
К вопросу о наименования билдов
- Логично будет использовать уже существующие нормы наименования, например, такие как Semantic Versioning Specification.
- Такому наименованию следуем при ручном запуске процесса билда релизной версии, поскольку иначе автоматически добиться правильного наименования не получится (если только вручную в коде не проставлять, что опять-таки мало относится к CI идеологии).
- В режиме CI для «отладочных» версий ПО применяем на разных проектах следующие наименования:
- Встроенные внутренние номера TFS;
- Нумерацию на основе текущей даты и номера билда в этот день;
- Номер коммита, по которому запустился билд.
Конкретное решение, например, можно посмотреть на базе примера сервиса Calculator, сделанного на Javascript, и нескольких общедоступных проектов.
Алгоритм решения
1. В TFS2018 создаем проект с названием SibEDGE Semver и импортируем репозиторий в локальный репозиторий
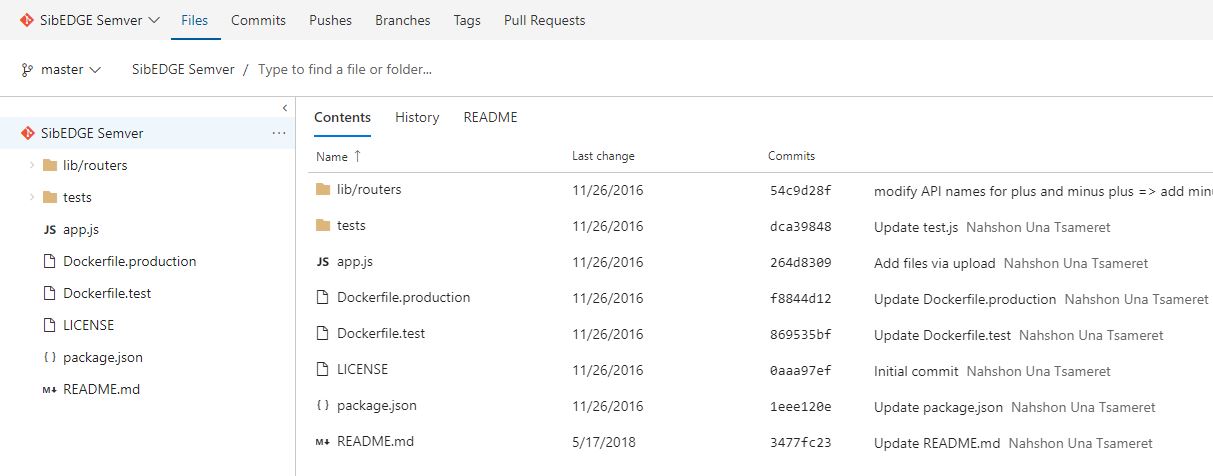
Рисунок 1 – Проект SibEDGE Semver в репозитории на TFS 2018
2. Создаем Dockerfile-файл с описанием сборки node.js под наши нужды (ссылка).
FROM node:7
WORKDIR /usr/src/app
COPY package.json app.js LICENSE /usr/src/app/
COPY lib /usr/src/app/lib/
LABEL license MIT
COPY tests tests
ENV NODE_ENV dev
RUN npm config set strict-ssl false
RUN npm update && npm install -g mocha
CMD ["mocha", "tests/test.js", "--reporter", "spec"]
Скрипт 1 – Dockerfile для сборки билда
3. На тестовом стенде (с установленным docker), куда планируем разворачивать наше окружение, создаем swarm-кластер. В нашем случае он будет состоять из одного сервера.
$ docker swarm init 4. Создаем yml-файл с описанием микросервисов под наши нужды (ссылка).
Заметим, что
vm-docker-registry.development.com:5000 – внутренний репозиторий для данного проекта, который мы заранее подготовили. Для того, чтобы тестовый стенд мог использовать данный репозиторий, необходимо на стенде прописать ssl-сертификат в папке /etc/docker/certs.d/<название репозитория>/ca.crtversion: '3.6'
services:
#---
# Portainer for manage Docker
#---
portainer:
image: portainer/portainer:1.15.3
command: --templates http://templates/templates.json -d /data -H unix:///var/run/docker.sock
networks:
- semver-network
ports:
- 9000:9000
volumes:
- /var/run/docker.sock:/var/run/docker.sock
#---
#----Service Calculator Test#
#---
semver-calc:
image: vm-docker-registry.development.com:5000/calculator:latest
networks:
- semver-network
#---
#----Pminder - Nginx#
#---
nginx:
image: nginx:1.9.6
depends_on:
- mysql
ports:
- "8888:80"
- "6443:443"
networks:
- semver-network
#
#-----------------------------
# START NoSQL - Redis.
#---
redis:
image: redis:4.0
networks:
- semver-network
ports:
- "8379:6379"
#
# END NoSQL - Redis.
#---
#----Pminder - DB#
#---
mysql:
image: mysql:5.7
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: 'ODdsX0xcN5A9a6q'
MYSQL_DATABASE: 'semver'
MYSQL_USER: 'user'
MYSQL_PASSWORD: 'uXcgTQS8XUm1RzR'
networks:
- semver-network
#---
#----PhpMyAdmin #
#---
phpmyadmin:
image: phpmyadmin/phpmyadmin
depends_on:
- mysql
environment:
PMA_HOST: 'mysql'
PMA_USER: 'user'
PMA_PASSWORD: 'uXcgTQS8XUm1RzR'
ports:
- "8500:80"
- "8600:9000"
networks:
- semver-network
#---
networks:
semver-network:
Скрипт 2 – содержание файла semver.yml, который является docker-compose файлом проекта.
5. Создаем описание сборки в TFS2018 (Build Definition).
6. Первым действием нашего скрипта является сборка образа docker-контейнера:
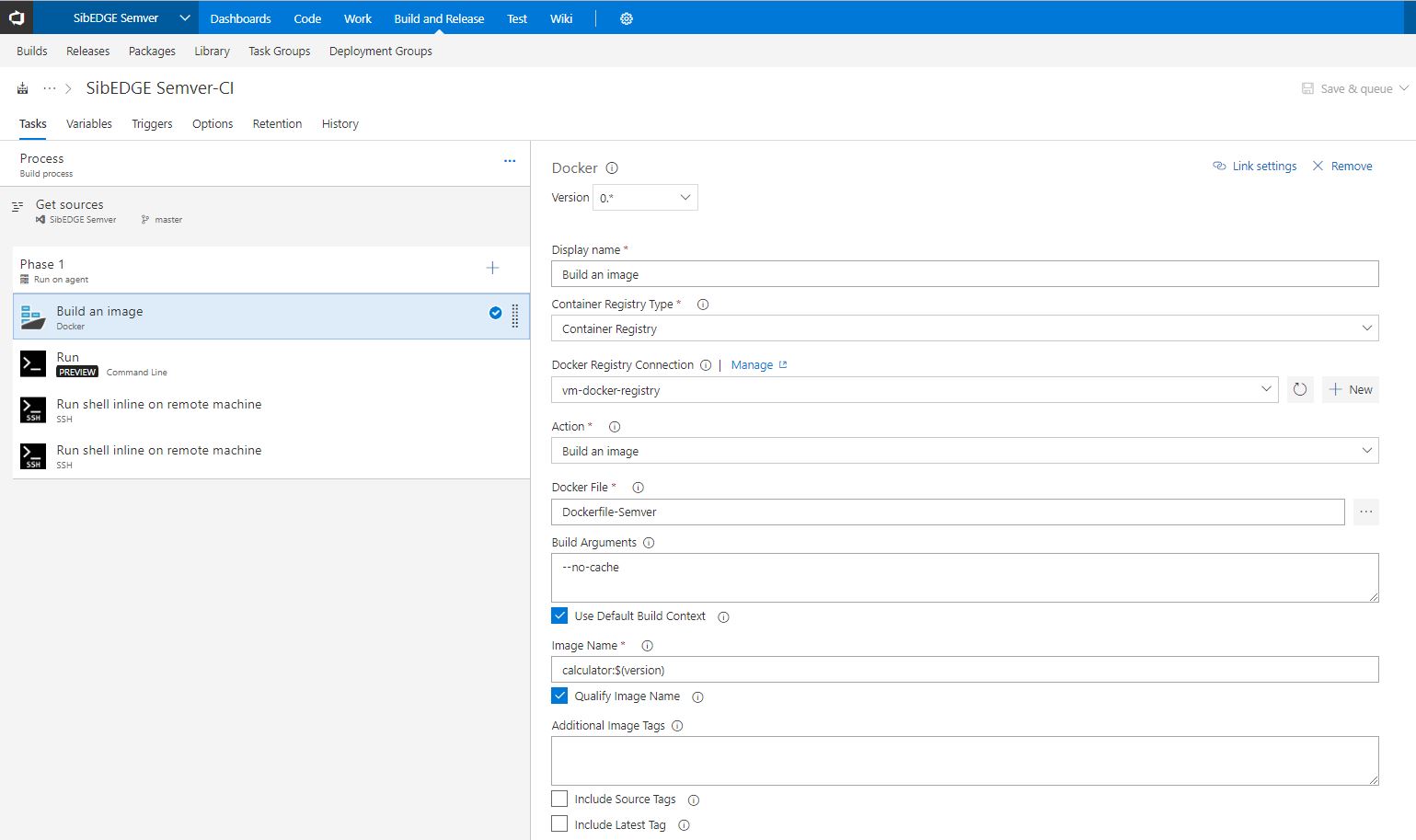
Рисунок 2 – Сборка образа для нашего билда в TFS 2018
7. Отправим созданный на build-машине образ docker-контейнера во внутренний репозиторий для данного проекта:

Рисунок 3 – Сохранение docker-image для нашей сборки в репозитории TFS 2018
8. Для всего окружения на тестовом стенде в файле описания микросервисов меняем имя образа на новое:

Рисунок 4 – Замена имени образа в скрипте сборки для нашего билда в TFS 2018
9. На тестовый стенд скопируем созданный образ docker-контейнера из внутреннего репозитория и обновим сервис в docker swarm:

Рисунок 5 – Разворачивание docker-контейнера со скриптом сборки нашего билда из образа в TFS 2018
В итоге на выходе в репозитории TFS мы имеем yml-файл с релизными версиями docker-образов, который в свою очередь имеет релизное название всего проекта.
10. Зайдем на тестовый стенд и проверим работу сервисов и убедимся, что сервис Calculator обновился и использует новую версию сборки.
$ docker service ls
Рисунок 6 – Обновление сервиса Calculator и проверка его текущей версии на нашем тестовом стенде
Таким образом, в нашем хранилище образов docker registry у нас есть набор образов различных версий микросервисов (в данном конкретном случае изменяется версия только одного микросервиса). Запустив отдельный процесс деплоя (через скрипт, меняющий yml-файл описания), в любой момент времени можно получить нужное окружение для тестирования на тестовом стенде и передать данную конфигурацию в QA подразделение. После проведения тестирования (регрессионного, нагрузочного etc.) мы получаем информацию о том, что микросервис такой-то версии работает стабильно на тестовом стенде с релизными версиями других микросервисов таких-то версий, и уже принимается итоговое решение о том, что можно или нет обновлять релизный стенд до новой версии.
Резюме – что получили на выходе
Благодаря внедрению версионности в проекты с микросерсивной архитектурой удалось достичь следующего результата:
- снизилось количество хаоса в версиях;
- увеличилась скорость разворачивания нового окружения в проектах;
- улучшилось качество сборок и понизился уровень ошибок в них;
- повысилась прозрачность разработки для Руководителей Проектов и Заказчика;
- улучшилось взаимодействие между отделами;
- появились новые направления в работе DevOps.
P.S Спасибо моему коллеге Кириллу Б. в помощи в написании статьи.
Tishka17
Смущает, что скрипты вы пишете прямо в интерфейсе TC. Они получаются за пределами системы контроля версии и не привязаны к коду, который собирают, с соответствующими последствиями.
Как в вашем случае выглядит конфигурирование сервисов для разных стендов?
Много раз слышал, что не стоит запускать БД в докере, что вы об этом думаете?
Seva_Morotskiy Автор
1. В разных системах CI по-разному, но в TFS именно так. В ней самой созданы описания сборок, которые имеют историю. Зачастую бывает, что код передается Заказчику или предполагается совместная работа с ним. Соответственно, переносить в репозиторий избыточные данные – не лучшая практика в таком ключе. Опять-таки, есть проекты, где скрипты написаны разработчиками (или для них) и пригодны для использования вне CI (сборки Sharepoint и проч.) и тогда комбинируем. В-общем, все индивидуально получается.
2. В рамках одного проекта создаем дополнительное описание сборки с добавлением особенностей (к примеру для dev/stage).
3. Есть проблемы с запуском MySQL-кластера (не рекомендуем для Заказчиков), PostgreSQL работает в кластере, но и с ним есть определенные нюансы. Если нет требования отказоустойчивости или некритична временная недоступность сервиса, то хорошее решение.
Tishka17
Хранение скриптов сборки в git решает следующие проблемы:
1) При изменении скрипта можно всегда найти старые версии
2) Можно делать рефакторинг процесса сборки в новой ветке без каких либо усилий по созданию и поддержке разных тасков для разных веток
Ну и все таки скрипт сборки — не избыточные данные, это тот же код, который запускается и который надо поддерживать