While working on the annual report this year we have decided to avoid retelling the news headlines of the previous year and, though it is almost impossible to ignore memories absolutely, we want to share with you the result of a clear thought and a strategic view to the point where we all are going to arrive in the nearest time?—?the present.
Leaving introduction words behind, here are our key findings:
- Average DDoS attack duration dropped to 2.5 hours;
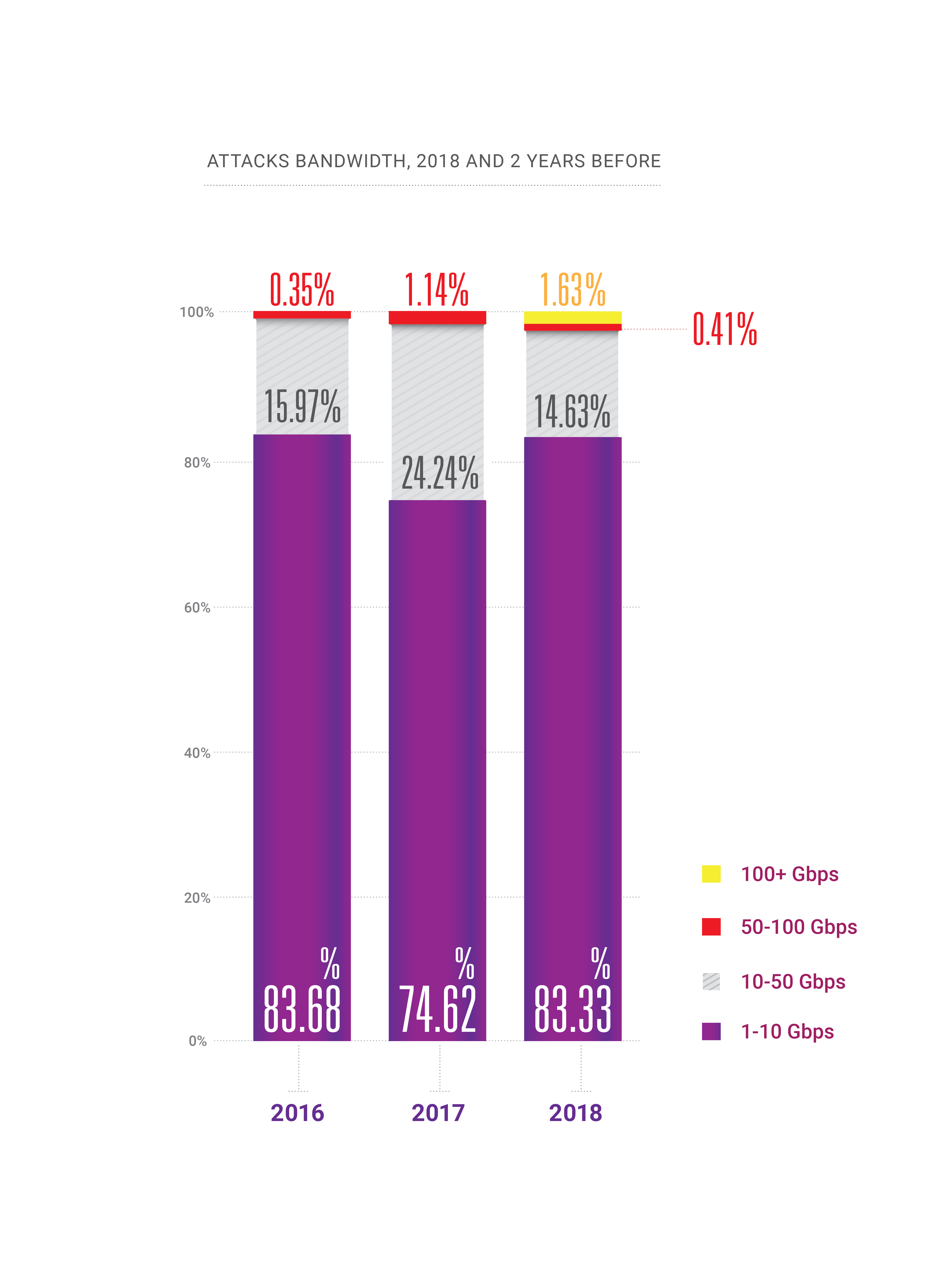
- During 2018, the capability appeared for attacks at hundreds of gigabits-per-second within a country or region, bringing us to the verge of “quantum theory of bandwidth relativity”;
- The frequency of DDoS attacks continues to grow;
- The continuing growth of HTTPS-enabled (SSL) attacks;
- PC is dead: most of the legitimate traffic today comes from smartphones, which is a challenge for DDoS actors today and would be the next challenge for DDoS mitigation companies;
- BGP finally became an attack vector, 2 years later than we expected;
- DNS manipulation has become the most damaging attack vector;
- Other new amplification vectors are possible, like memcached & CoAP;
- There are no more “safe industries” that are invulnerable to cyberattacks of any kind.
In this article we have tried to cherry-pick all the most interesting parts of our report, though if you would like read the full version in English, the PDF is available.
Retrospective
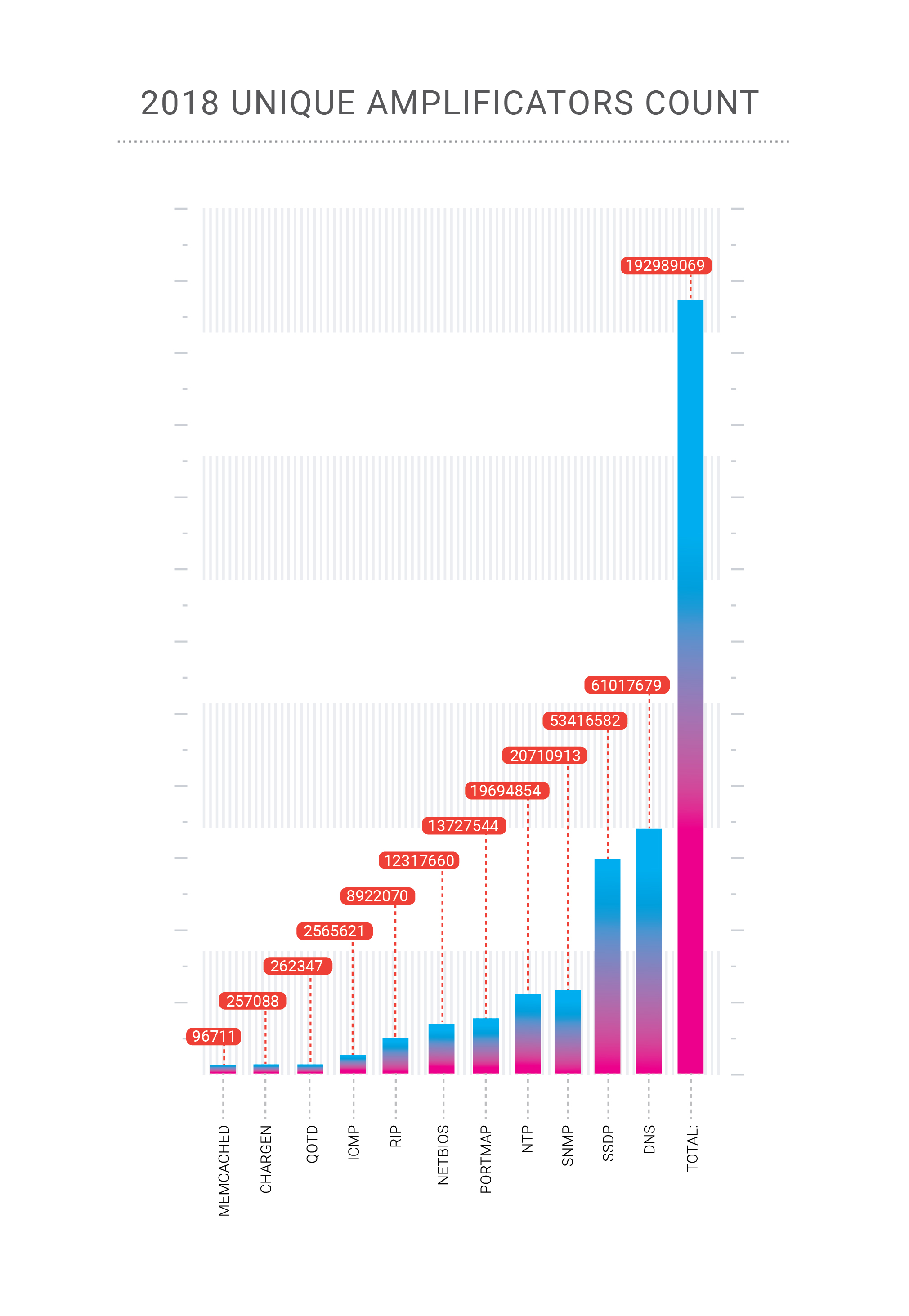
In 2018, our company “celebrated” two record-breaking attacks on its network. The Memcached amplification attacks, which we described in detail during late February 2018, reached 500 Gbps in the case of the Qiwi payment platform, a customer of Qrator Labs. Then, in late October, we received a highly concentrated DNS amplification attack on one of our customers within the Russian Federation.
DNS amplification is an old and well-known DDoS attack vector which is primarily volumetric and raises two problems, In the event of a hundreds of gigabits-per-second attack, there is a high chance of overloading our upstream channel. How to fight this? Obviously, we have to spread such load among many channels, which leads to the second issue?—?added latency that results from changing the traffic flow to our processing point. Fortunately, we successfully mitigated that particular attack with only load-balancing.
This is where flexible load-balancing demonstrates its true value, and since Qrator Labs manages an anycast BGP network, Radar is modeling the spread of traffic across our network after we adjust the load balance. BGP is a distance-vector protocol, and we know those states because the distance graph remains static. Analyzing those distances and considering LCPs and Equal-Cost Multipath, we can estimate the AS_path from point A to point B with high confidence.
This is not to say that amplification is the most dangerous threat?—?no, application layer attacks remain the most effective, edgy and invisible since most of them are low-bandwidth.
This is the main reason Qrator Labs upgrades connections with operators based on points-of-presence, while widening the areas of presence too. That is a natural step for any network operator these days, assuming its numbers are growing. However, from the attackers’ perspective, we believe it is common to collect a mediocre botnet and only afterwards focus on looking for the richest array of available amplificators to strike from all guns possible, at the highest possible reload rate. Hybrid attacks are here, growing in bandwidth, packet rate, and frequency.
Botnets evolved significantly in 2018 and their masters found a new job for them?—?click fraud. With the rise of machine learning and headless browser engines, click fraud became much easier to accomplish than just a couple of years ago.
A today’s average website receives around 50% to 65% of its traffic from mobile devices, smartphone browsers, and applications. For some Web services, this figure is close to 90% or 100%, while a desktop-only website today is a rare thing being encountered mostly in enterprise environments or some borderline cases.
PC is basically dead in 2019, which renders some of the used-to-be-neat approaches, like mouse movement tracking, utterly useless for bot tracking and filtering. In fact, not only PC (with all the shiny laptops and all-in-one desktop machines) is rarely a source of a major traffic share with certain websites, but it’s frequently becoming more of just an offender. At times, just denying access to whatever is not a proper smartphone browser is enough to mitigate a botnet attack completely causing at the same time about zero negative impact on key business performance indicators.
Botnet authors are used to implement or imitate the behavior of desktop browsers in their malicious code, just as the website owners are used to believe that PC browsers really matter. The latter has changed recently, so within a few years, there should also happen a change in the former.
We already stated that nothing changed significantly during 2018, but change and progress maintained a steady pace. One of the most significant examples is Machine Learning, where improvements were especially evident, particularly in the area of Generative Adversarial Networks. Slowly, but steadily, ML is reaching the mass market. The machine learning world has become more accessible and, by the end of the year it is no longer restricted to academics.
We expected to see the first ML-based (or otherwise related) DDoS attacks by the beginning of 2019 but it still has not happened. We expect such a development because of the low cost of ML-generated data right now, but apparently it is not low enough.
If you think of the current state of “automated human” industry, putting the neuro-network on top of that is not a bad idea. Such a network would learn real human behavior in the context of managing web page contents. That is something that everybody would call “AI user experience” and, of course, such a network equipped with a browser engine could produce a very interesting arsenal for both sides, offense and defense.
Sure, teaching the network is expensive, but distributing and outsourcing such a system could be very affordable and, possibly, free, especially if malware, hacked applications and so on are considered. Potentially, such a change could affect the entire industry, the same way GANs transformed what we think of “visual reality” and “trustworthiness.”
Since this is also a race between search engines with Google in first place and everyone else trying to reverse-engineer the algorithms, it could reach a situation where a bot would imitate not a random human being, but a specific person, like the one usually sitting behind a selected vulnerable computer. Versions of Captcha and Recaptcha could serve as examples of how attackers improve their tools and attack techniques.
After memcached, there was much talk about the possibility of a new class of DDoS attack weapon?—?a vulnerability, bot, compromised service, something that could eternally send particular data to a specific address chosen by the attacker. One command from the attacker could release a perpetual continuous flow of traffic, like syslog or a massive flood. That is only a theory. We can’t say if such servers, or devices, actually exist, but if they do, it would be an understatement to say that they could represent an extremely dangerous weapon in the wrong hands.
In 2018, we also saw increased interest in governance of the internet and associated services from all kinds of governments and nonprofits around the world. We view this as a neutral development up to the point where fundamental freedoms could be suppressed, which we hope won’t happen, especially in developed nations.
After years of collecting and analyzing attacking traffic globally, Qrator Labs is now implementing the first request block. The models we use to predict malicious behavior enable us to determine with high confidence whether or not a user is legitimate. We adhere to our central philosophy of uninterrupted user experience, without JavaScript challenges or captchas and in 2019, we hope to achieve the capability to block the first malicious request from breaching our defenses.
Mellanox
We chose 100G Mellanox switches as a result of our internal tests in previous years. We still select equipment that fulfills our needs in specific situations. First of all, switches should not drop any small packets while working at line rate?—?there cannot be any degradation at all. Second, we liked the price. However, that’s not all. Cost is always justified by how the vendor reacts to your specifications.
Mellanox switches work under Switchdev, turning their ports into ordinary Linux interfaces. Being a part of the mainstream Linux kernel, Switchdev is described in documentation as “an in-kernel driver model for switch devices which offload the forwarding data plane from the kernel“. This approach is very convenient, as all the tools we’ve used to are available under one API that’s extremely natural for every modern programmer, developer and network engineer. Any program, that uses standard Linux networking API, can be run on the switch. All the network monitoring and control tools built for Linux servers, including homemade ones, are available. For example, implementing changes to the route table is much more comfortable compared to how it’s been done before Switchdev. Up to the level of the network chip, all code is visible and transparent, making it possible to learn and make modifications, until the specific moment when you have to know exactly how the chip is built, or at least the external interface.
A Mellanox device under Switchdev control is the combination that we found most suitable for our needs, as the company provides full support for the already robust open source operating system out of the box.
While testing the equipment before running it in production, we found out that some forwarded traffic was dropped. Our investigation showed that it was caused by traffic on one interface was routed via the control processor, which of course could not handle high volumes of it. We did not know the exact cause of such behavior, but we supposed it was bound to the handling of ICMP redirects. Mellanox confirmed the cause of the problem, and we asked them to do something about that. Mellanox reacted rapidly, providing us with a working solution in the short term.
Great job, Mellanox!
Protocols and open source
DNS-over-HTTPS is a more complex technology than the DNS-over-TLS. We see the former blooming and the latter being slowly forgotten. It is a clear example where “more complex” means “more efficient,” as DoH traffic is indistinguishable from any other HTTPS. We already saw this with the RPKI data integration, when it was initially positioned as an anti-hijack solution and didn’t end up well, but then reappeared as a powerful weapon against mistakes like static leaks and incorrect routing setups. Noise transformed into signal and now RPKI is supported on the biggest IX’s, which is terrific news.
TLS 1.3 has arrived. Qrator Labs, as well as the IT industry overall, watched the development process closely from initial draft through every stage within IETF to become an understandable and manageable protocol that we are ready to support in 2019. The support is already evident among the market, and we want to keep pace in implementing this robust, proven security protocol. We don’t know how DDoS mitigation hardware producers will adapt to the TLS 1.3 realities, but, due to the technical complexity of protocol support, it could take them some time.
We are following HTTP/2 too. For now, Qrator Labs does not support the newer version of the HTTP protocol, due to the existing code base around this protocol. Bugs and vulnerabilities are still found rather frequently in the new code; as a security service provider, we are not yet ready to support such a protocol under the SLA we agree with our consumers.
The real question of 2018 for Qrator Labs was: “Why do people want HTTP/2 so much? And it was the subject of hot debate throughout the year. People still tend to think of the “2” digit as the “faster, stronger, better” version, which is not necessarily the case in every aspect of that particular protocol. However, DoH recommends HTTP/2 and this is where both protocols might get a lot of momentum.
One concern about the development of the next generation protocol suites and features is that it usually depends heavily on academic research, and the state of that for the DDoS mitigation industry is quite poor. Section 4.4 of the IETF draft “QUIC manageability”, which is a part of the future QUIC protocol suite, could be seen as a perfect example of that: it states that “current practices in detection and mitigation of [DDoS attacks] generally involve passive measurement using network flow data”, the latter being in fact very rarely a case in real life enterprise environments (and only partly so for ISP setups)?—?and in any way hardly a “general case” in practice?—?but definitely a general case in academic research papers which, most of the time, aren’t backed by proper implementations and real world testing against the whole range of potential DDoS attacks, including application layer ones (which, due to the progress in the worldwide TLS deployment, could obviously never be handled with any kind of passive measurement). Setting proper academic research trend is another challenge for the DDoS mitigation operators in 2019.
Switchdev fully met the expectations we expressed a year ago. We hope the continuous work on making Switchdev even better will strengthen in the coming years, as the community is strong and growing.
Qrator Labs is following through with enabling Linux XDP to help further increase packet processing efficiency. Offloading some patterns of malicious traffic filtration from CPU to NIC, and even to the network switch, appears quite promising, and we look forward to continuing our research and development in this area.
Deep dive with bots
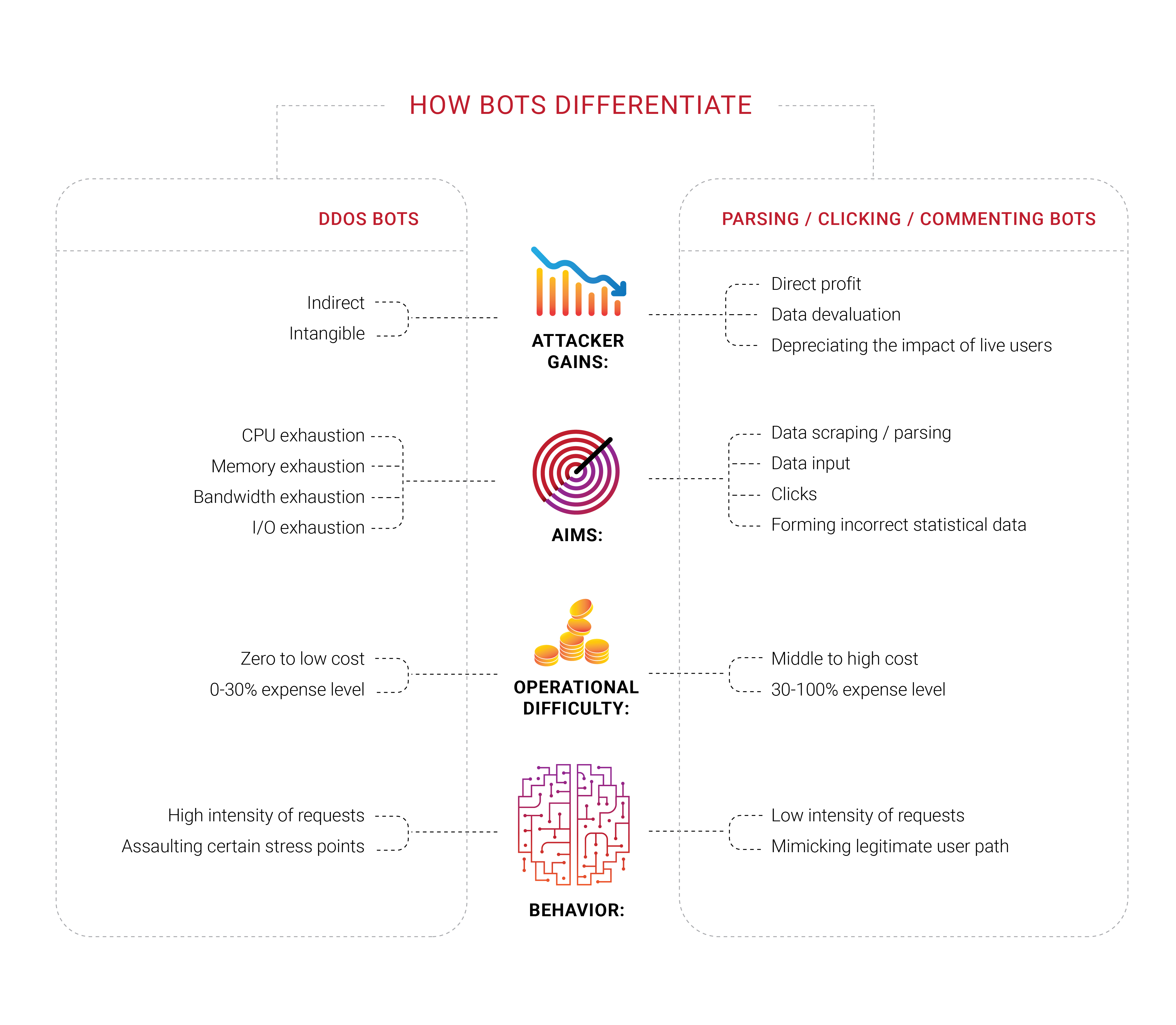
Many companies seek bot protection, and it is no surprise that we saw groups working in different areas of that field in 2018. What we found interesting is that a large portion of these companies never experienced a targeted DDoS attack, at least a typical denial of service attempt to drain finite resources like bandwidth or CPU capacity. They feel threatened by the bots but cannot distinguish them from actual users or determine what they’re actually doing. They just know they want to get rid of the perceived bots.
The problems with bots and scrapers also have an important economic component. If 30% of traffic is illegitimate and machine-originated, then 30% of the costs of supporting that traffic are wasted. Today, this can be seen as an additional inevitable tax on Internet businesses. It’s hard to decrease the number exactly to zero, but business owners would prefer to see it as low as possible.
Identification becomes a significant issue in today’s internet since the best bots don’t have to mimic human beings anymore?—?they occupy the same space, like parasites. We have been repeating for some time that any information available publicly, without authorization or authentication, is and would end as common property?—?nobody could prevent that.
In 2018 we concentrated on identity and bot management issues. However, the broader scope here is different; we live in an era when there is no exact way to know the reason a client requests the server’s response. You read it right: ultimately every business wants a customer to buy something, that’s the reason for existing and the goal, so some companies want to look deeper into who requests what from the server?—?if there’s a real person behind.
It’s no wonder that business owners often learn from the technicians that a significant portion of their website traffic is originated by bots, not customers.
Automated humans we mentioned earlier could also be targeting some specific network resource with a browser add-on installed?—?and we believe that most of those extensions are installed purposely, to pursue a specific aim, known only to the creators of those networks. Click fraud, ad manipulation, parsing?—?such tasks are efficiently accomplished with the help of real human beings at the point where automation fails. Just imagine how the situation would change if machine learning were applied to the right link in the chain.
Parsers and scrapers, which are a part of the broader bot problem, became an issue we dived into during 2018, firstly thanks to our customers, who approached us with their experiences and provided the option to investigate further what was happening with their resources. Such bots might not even register on typical metrics, like the bandwidth or the server CPU load. We are currently testing a variety of approaches, but ultimately it is clear what customers need?—?to block such intruders on their first request.
During the scraping epidemic we saw in Russia & CIS, it became clear that the bots involved are capable of encryption. One request per minute is a rate that could easily go unnoticed without request analysis of incoming traffic. In our humble opinion, the customer should decide the next step after getting our analysis and markup. Whether to block them, let them through or spoof (mislead) them?—?it is not for us to decide.

However, certain problems exist with pure automations, or “bots,” as we are used to calling them. If you are certain that the malicious bot generated a specific request, the first thing most decide to do is block it, sending no response from the server. We have reached the conclusion that this as senseless because such actions only give more feedback to the automation, enabling it to adapt and find a workaround. Unless the bots are attempting a denial of service attack, we recommend not blocking such automations right away since the outcome of such cat and mouse games could be nothing more than a great waste of time and effort.
This is the primary reason Qrator Labs chooses to mark suspicious and/or malicious traffic and leave the decision about next steps to the resource owner taking into consideration their audience, service and business goals. One such example is the ad-blocking browser extension. Most ads are scripts and by blocking scripts you’re not necessarily blocking ads and you could block something else, like a javascript challenge. It is easy to imagine how this could escalate, resulting in lost income for a major group of internet businesses.
When attackers are blocked and receive the feedback they need, they can swiftly adapt, learn and attack again. Qrator Labs’ technologies are built upon the simple philosophy that the automation cannot be given any feedback they can use: you should neither block them nor pass them through, just mark them. After such marks are made you should consider their real goal?—?What they want? and Why are they visiting that specific resource or webpage? Maybe you could slightly alter the webpage’s content in a way no human would feel the difference, but the bot reality would turn upside down? If they are parsers, they could get misleading parsing info in the form of incorrect data.
While discussing those problems throughout 2018 we labeled such attacks as the straightforward business metrics attack. Your website and servers might seem fine, with no user complaints, but you feel something changing… like the CPA price of an ad you take from some programmatic platform slowly, but steadily steering advertisers elsewhere.
Killing attackers’ incentive is the only way of counteracting that. Trying to stop bots results only in wasted time and money. If they click something you benefit from, render those clicks inefficient; if they parse you, provide unreliable information they won’t distinguish from legitimate, trustworthy data.
Clickhouse
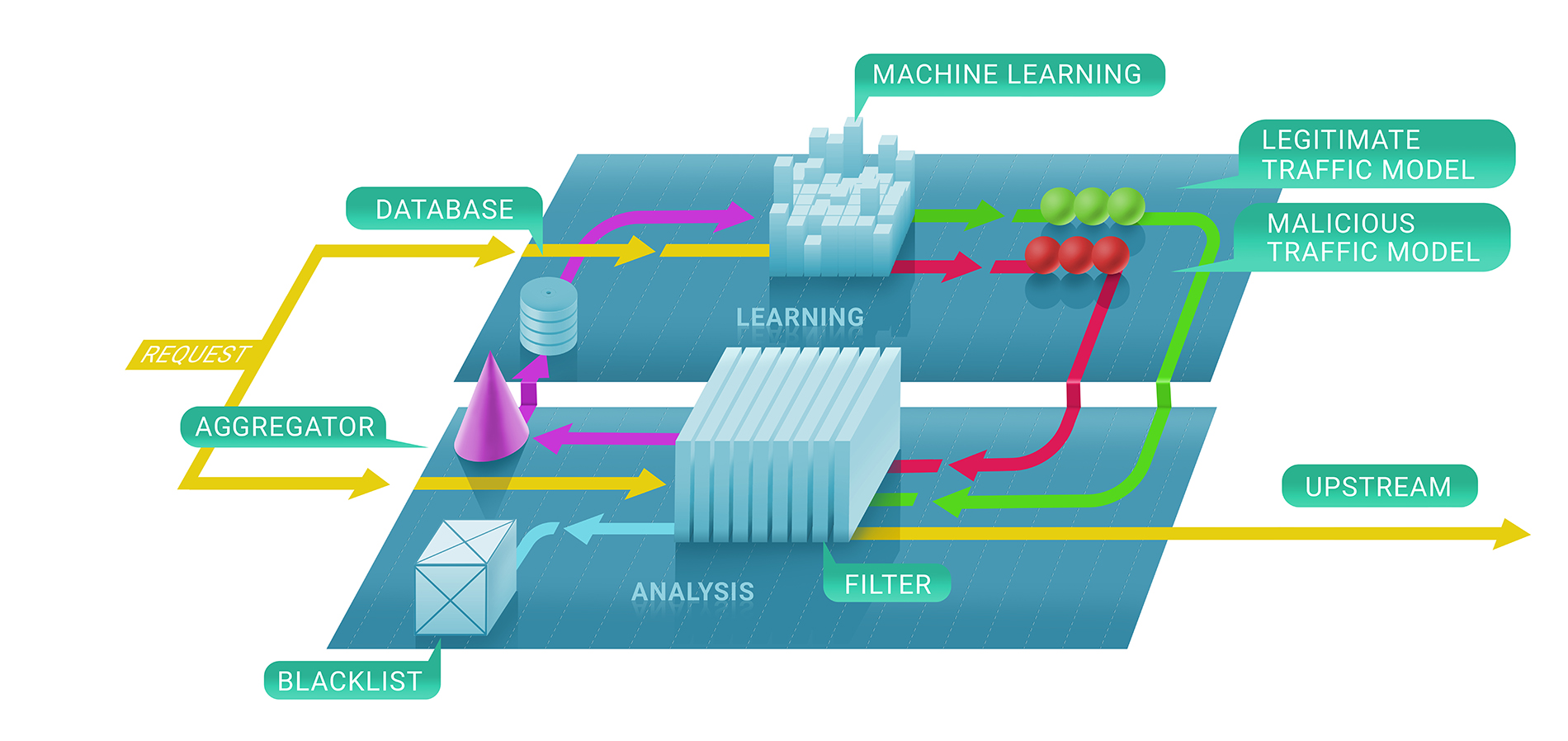
In general, Qrator Labs filtering service involves two stages: first, we immediately evaluate whether a request is malicious with the help of stateless and stateful checks, and, secondly, we decide whether or not to keep the source blacklisted and for how long. The resulting blacklist could be represented as the list of unique IP-addresses.
In the first stage of this process, we enlist machine learning techniques to better understand the natural flow of traffic for a given resource, since we parametrize the service for each customer individually based on the data we collect.
That is where Clickhouse comes in. To understand precisely why an IP-address was banned from communicating with a resource, we have to follow the machine learning model to Clickhouse DB. It works very fast with big chunks of data (consider a 500 Gbps DDoS attack, continuing for a few hours between pauses), and stores them in a way that’s naturally compatible with the machine learning frameworks we use at Qrator Labs. More logs and more attack traffic leads to better and more robust results from our models to use in further refining the service in real time, under the most dangerous attacks.
We use the Clickhouse DB to store all the attack (illegitimate) traffic logs and bot behavior patterns. We implemented this specific solution because it promised an impressive capacity for processing massive datasets in a database style, fast. We use this data for analysis and to build the patterns we use in DDoS filtering and to, apply machine learning to improve the filtering algorithms.
A significant Clickhouse advantage, compared to other DBs, is that it doesn’t read the entire string of data?—?it could take only the needed, much smaller, segment, if you’re storing everything by the guidelines.
Conclusion

For quite some time, we have been living with multifactor attacks that explore multiple attacking protocols to render a target unavailable.
Digital hygiene and up-to-date security measures should and actually could cover 99% of the actual risks an individual entity is likely to encounter, except for extreme or purposefully targeted cases, and keep an “average” internet service from experiencing problems.
On the other hand, DDoS attacks are capable of cutting the internet connection of any country in the world, though only few could be effectively targeted externally. That’s not the case in the BGP, where it is possible to only shut down a number of dots on any map you would like to draw.
Knowledge of network security continues to grow, which is excellent. Nevertheless, once you look at the numbers tied to amplificators in networks or options to spoof someone else?—?they aren’t going down! This is because each year the amount of time students spend in internet security school, i.e. the people starting to care about how they write code and build their applications, does not match the amount of time needed to ensure they’re not making vulnerabilities that will allow someone to use such resources for organizing a successful DDoS attack, or worse.
One of the most significant findings of 2018 was that most people still expect substantially more from technology than can be delivered currently. This was not always that the case, but right now we see a strong tendency to ask too much, regardless of the software or hardware features. People keep expecting more, which probably won’t change because of the promises made in marketing campaigns. However, people are buying those promises, and the companies feel, that they should work on fulfilling them.
Maybe, that’s the nature of progress and evolution. These days, people feel frustrated and disappointed for not having what they were “guaranteed,” and what they paid for. So, this is where the current problems originate, where we can’t “fully” buy a device and all its software that will do what we want, or where “free of charge” services come at a high price in terms of personal data.
Consumerism tells us that we want something, and we should pay for it with our lives. Do we need the kinds of products or services that upgrade themselves to sell us better deals in the future based on data they gathered on us in ways we may not like? We could anticipate that in 2019, after the Equifax and Cambridge Analytica cases, we may see a final explosion of personal data acquisition and abuse.
After ten years, we have not changed our core beliefs about the architecture of the interconnected network. That is the reason we continue to stand behind the most fundamental principles of Qrator Labs filtering network?—?BGP-anycast, the ability to process encrypted traffic, avoidance of captchas and other obstacles, more visibility for legitimate users compared to attacking bots.
Looking at what continues to happen with cybersecurity experts and companies in the field we want to stress another issue: when it comes to security, no naive, simple or fast approach is applicable.
This is the main reason Qrator Labs doesn’t have hundreds or even dozens of points-of-presence, compared to the CDNs. By maintaining a smaller number of scrubbing centers all connected to the Tier-1 class ISPs, we achieve true traffic decentralization. That is also the reason why we do not try to build firewalls, which are entirely different from what Qrator Labs does?—?connectivity.
We have been telling stories about captchas and javascript tests and checks for some time and here we are?—?neural networks are getting extremely useful in solving the former, and the latter were never an issue for the skilled and persistent attacker.
This year we also felt a rather exciting shift: for years DDoS was a problem for only a limited number of business areas, usually, the ones where money is above the water level: e-commerce, trading/stocks, banking/payment systems. However, with the continuous growth of the Internet, we observe DDoS attacks now being applied to all the other available internet services. The DDoS era started with increases in bandwidth and the number of personal computers in use around the world; it is no surprise that in 2018, with silicon microchips in every device around us, the attack landscape is evolving so fast.
If anyone expects this tendency to ever change, they are probably mistaken. Just as we, perhaps, are too. No one can tell how the internet will actually evolve and spread its impact and power in the coming years, but according to what we saw in 2018 and continue to observe in 2019, everything is going to multiply. By 2020 the number of connected devices on the internet is expected to exceed 30 billion, besides the fact that we’re already passed the point at which humanity generated more traffic than the automation it created. So, soon, we will have to decide how to manage all this “intelligence,” artificial or not, since we are still living in the world where only a human being can be responsible for something being right, as well as wrong.
2018 was a year of opportunities for those on the dark side. We see growth in attacks and hacks in terms of complexity, volume and frequency. Crooks obtained some powerful tools and learned how to use them. The good guys did little more than just watch these developments. We hope to see that change this year, at least on the most painful questions.