

Друзья, всем привет!
Эта статья в первую очередь будет интересна фронтенд-разработчикам, особенно тем кому актуальна тема GraphQL, но в то же время я надеюсь, что она будет полезна и бэкенд-разработчикам и поможет им понять преимущества GraphQL глазами фронтендера.
Несколько слов о себе: Я являюсь VP of Technology компании 8base. Мы разрабатываем инструменты, которые позволяют фронтенд и мобильным разработчикам быстрее создавать качественные бизнес-приложения.
Мы предоставляем платформу, в которой достаточно определить модель данных через наш UI и получить готовый GraphQL API для взаимодействия с данными. Пользователь получает настроенный сервер с ролями, правами доступа, возможностью работать с файлами, деплоить serveless-функции, CI и многое другое. Также для ускорения разработки у нас есть SDK и готовые библиотеки компонентов для React. Бэкенд пишем на Node.js
И так как основными пользователями нашей системы являются фронтенд и мобильные разработчики, мы решили сделать ставку на GraphQL, который изначально показался нам более гибким, чем REST, и дающим больше возможностей на фронте. Ну а теперь, когда мы получили достаточно обратной связи от конечных пользователей, мы можем сказать, что в нашем случае он подходит идеально.
Почему же всё-таки GraphQL?
В отличие от REST, каждый API на GraphQL предоставляет схему (schema), которая содержит информацию о входных и выходных типах данных, их полях и взаимосвязях между типами. Это позволяет использовать в API модели данных со связями, а также совершать гибкие запросы (queries) и изменения в данных (mutations), которые не зависят от представления в конкретном клиентском приложении.
Кроме того, GraphQL API позволяет клиентским разработчикам явно определять возвращаемые данные, в том числе ссылаться на связанные объекты в каждом запросе, не допускать избытка и недостатка данных (over- and under-fetching) и сокращать количество запросов к API.
Сравним GraphQL и REST
Давайте сравним GraphQL и REST на простом примере — создании интернет-блога. При выводе на экран отдельной статьи в блоге нам надо показать содержимое статьи, аватар и имя автора, список комментариев, а также аватар и имя каждого комментатора.
Если использовать REST, нам понадобятся следующие запросы к API:
GET /articles/:id — получить содержание статьи;
GET /users/:id — получить URL аватара и имя автора;
GET /articles/:id/comments — получить список комментариев (а если бэкенд-разработчики не встроили в него имена и аватары комментаторов, придется выполнить еще и шаг 4);
GET /users/:id для каждого комментария — получить URL аватара и имя комментатора.
Обратите внимание на проблему under-fetching (когда один запрос не возвращает все что нужно) и over-fetching (когда, к примеру, запрос /users/:id возвращает больше данных, чем будет отображаться), а также на более сложный код во фронтэнде, необходимый для организации серии запросов к API.
В GraphQL вся информация может быть получена одним запросом, при условии что разработчики API указали взаимосвязи между статьями, пользователями и комментариями в схеме GraphQL API. Кроме того, ответ от API будет содержать только запрошенные поля, что уменьшит его объем.
Вот пример GraphQL-запроса, который возвратит нам сразу всю информацию в одном запросе:
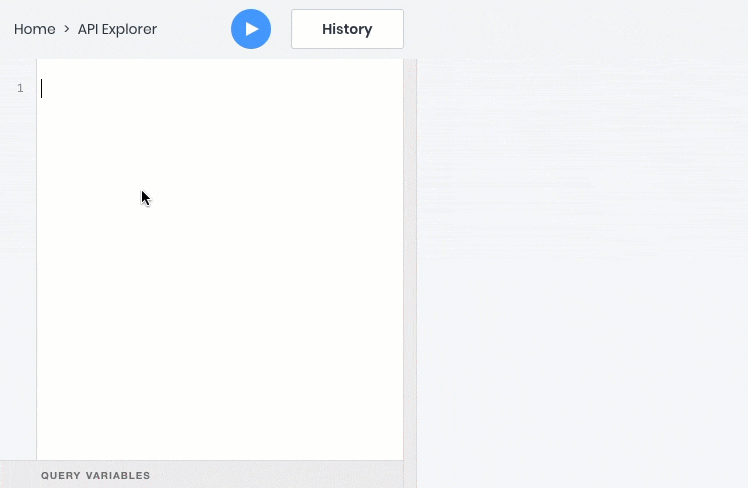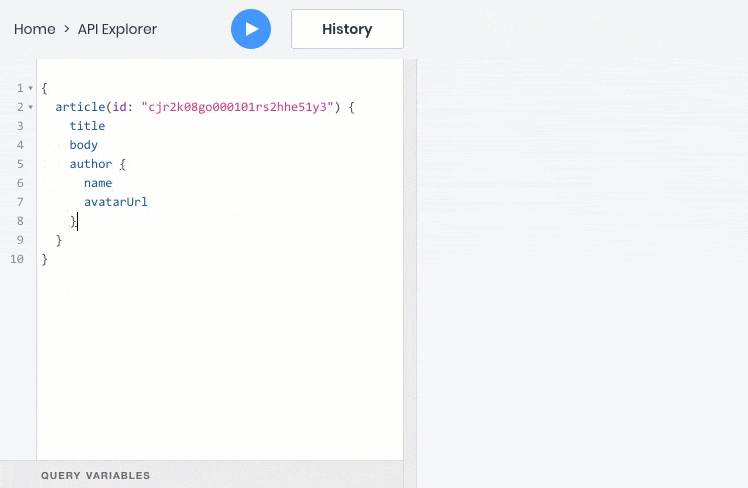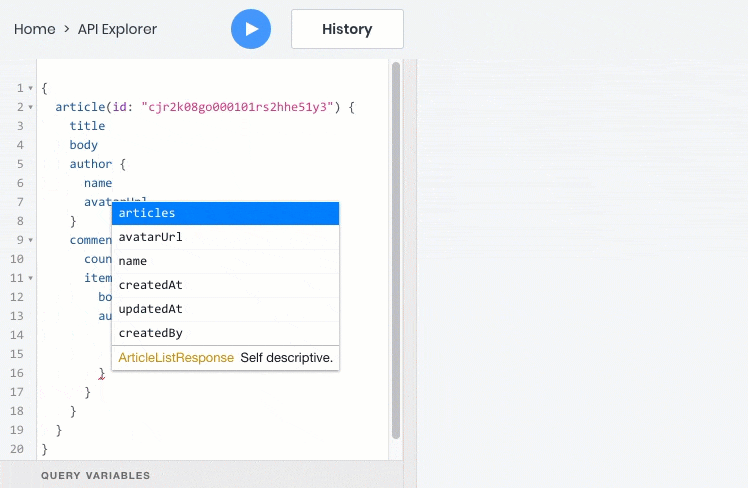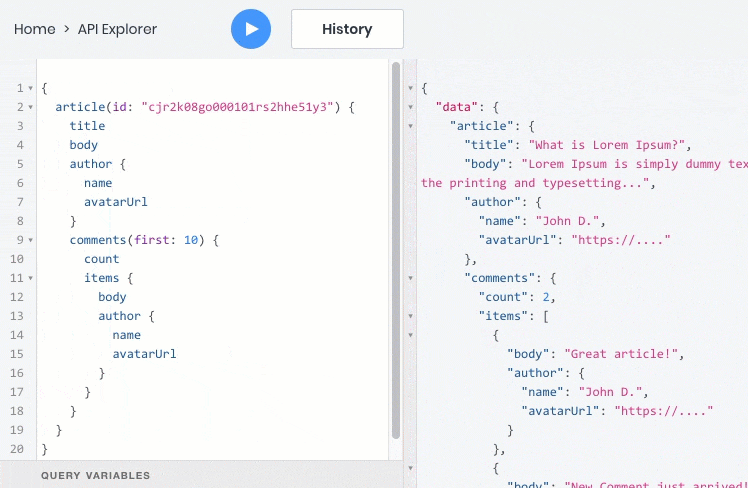
Чтобы реализовать такую возможность в REST, бэкенд-разработчикам потребовалось бы создать особый API endpoint, который возвращал бы эту информацию. Однако то же самое пришлось бы делать для каждого подобного случая с отображением данных из связанных таблиц, а заодно и обновлять API, как только фронтенду понадобятся дополнительные поля.
Этот пример показывает, как GraphQL выравнивает «баланс сил» в пользу фронтенд-разработчиков, позволяя им запрашивать любые необходимые данные, и дает бэкенд-разработчикам возможность реализовывать API так, чтобы охватить в нем всю предметную область, а не конкретное представление на клиенте.
Все это в сочетании с набором библиотек и инструментов выводит качество и удобство работы фронтенд-разработчика на новый уровень — именно поэтому популярность GraphQL среди команд разработки растет по всему миру.
Как это выглядит на практике
Один из недостатков GraphQL — более сложная реализация, чем у REST. Чтобы представить данные в удобном для самых разных клиентских приложений виде, необходим большой объем работы на бэкенде. Реализовывать CRUD-операции, связи, фильтры, сортировку и разбивку на страницы для каждого типа данных довольно утомительно. Организовать такие важные возможности, как права доступа к данным и прикрепление файлов к объектам данных, тоже не так-то просто.
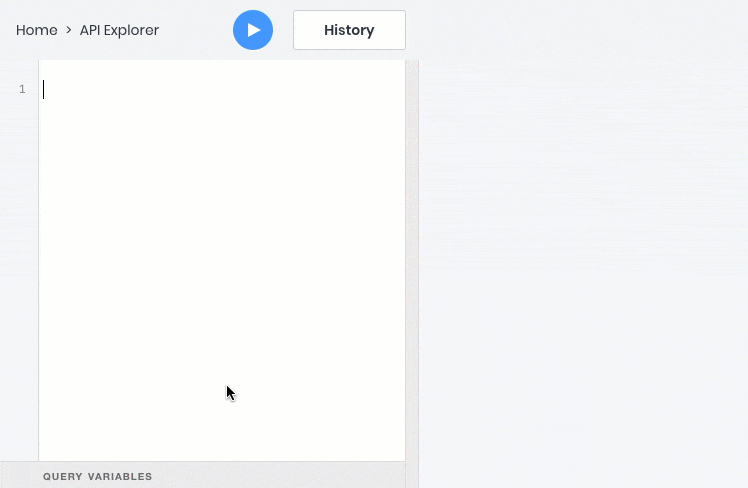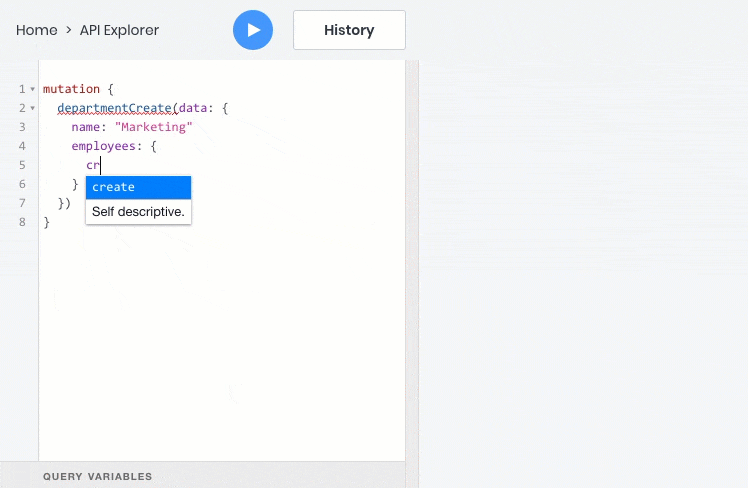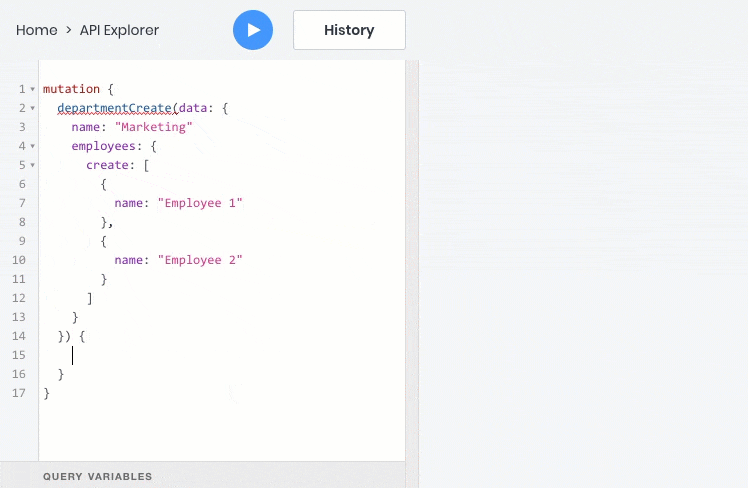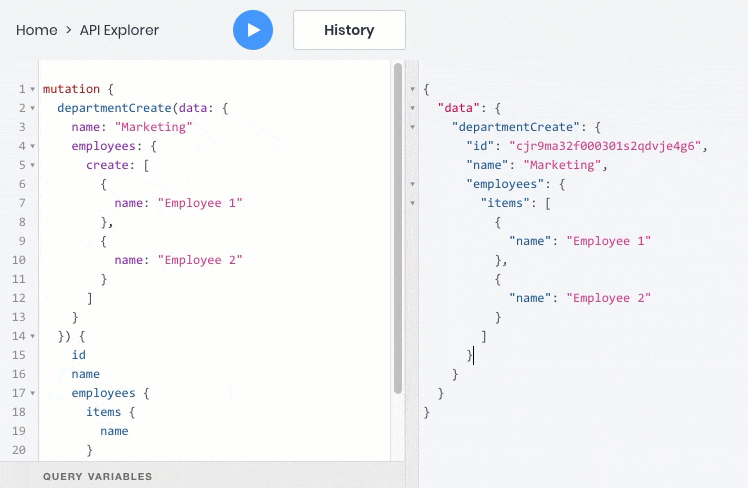
Сейчас я покажу какие возможности дает использование GraphQL на примере нашей реализации:
- получить один объект по идентификатору или любому уникальному полю
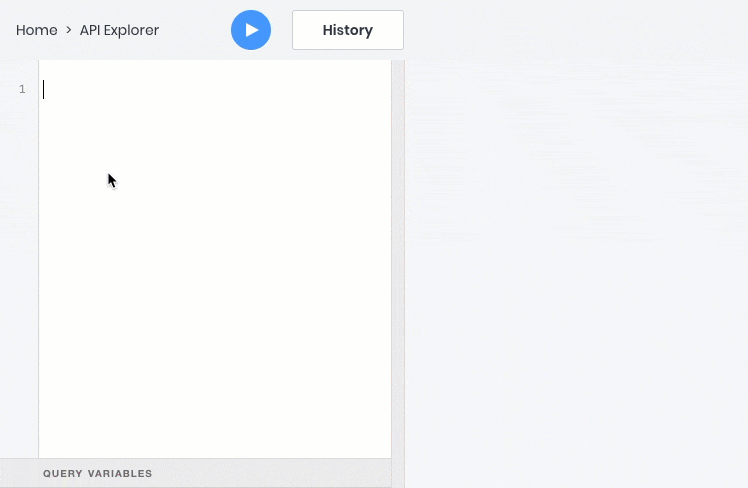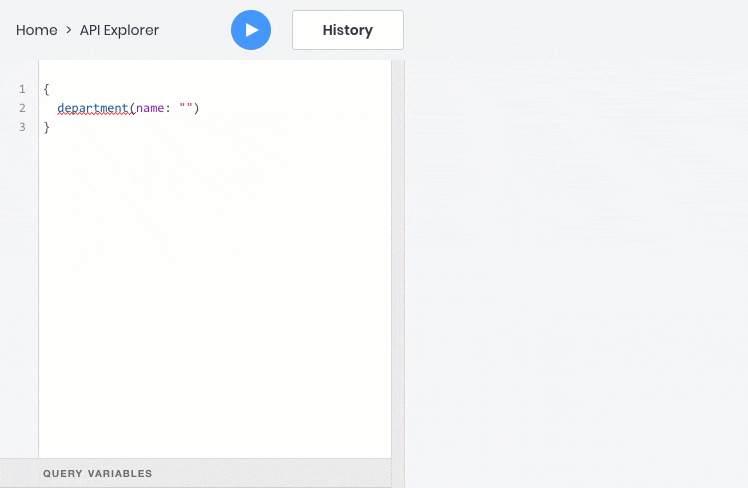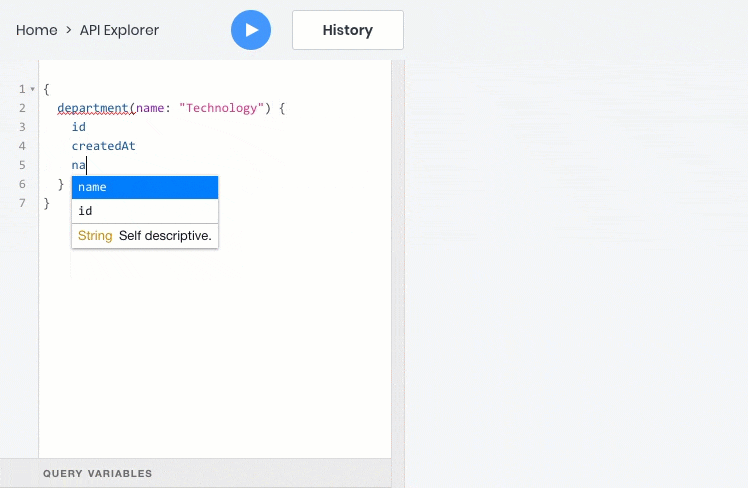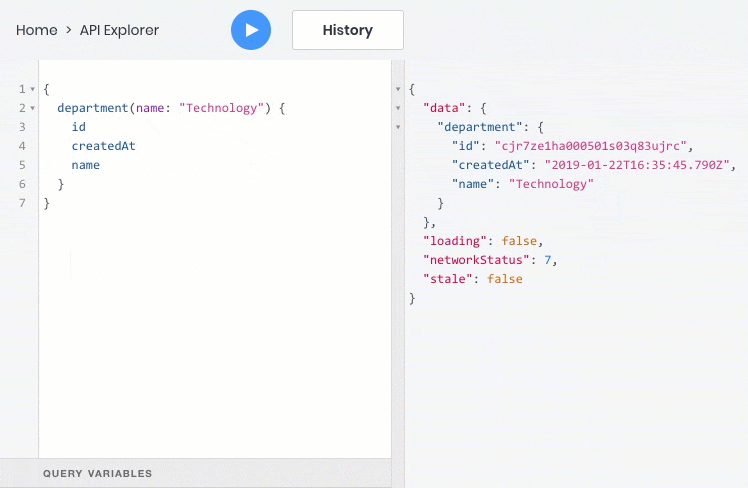
- получить список объектов на основе фильтров, сортировки, разбивки на страницы и критериев полнотекстового поиска

- создать, обновить или удалить объект

- подписаться на события данных в реальном времени через веб сокет
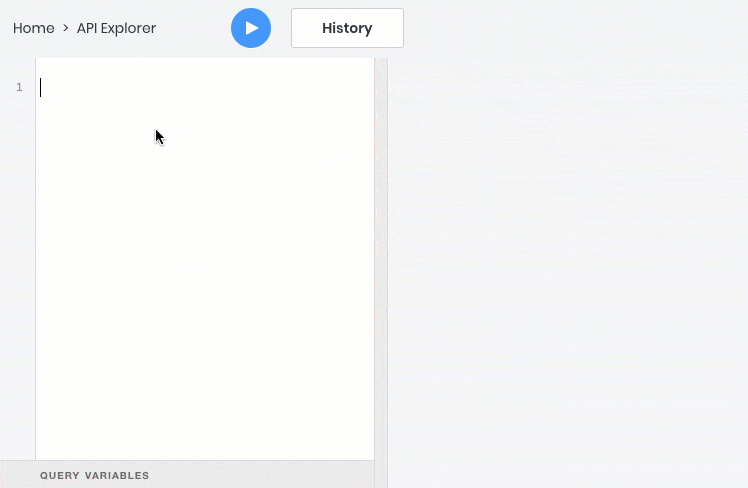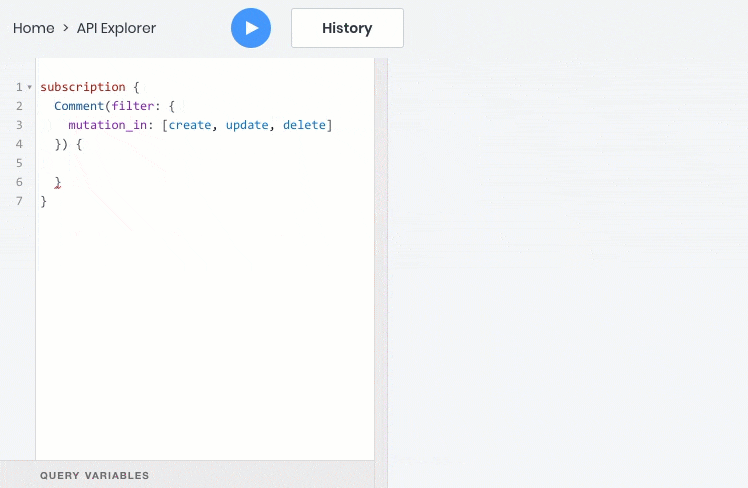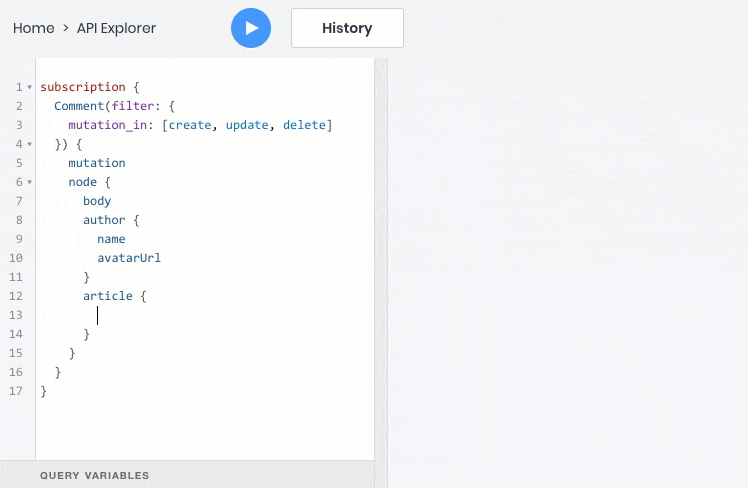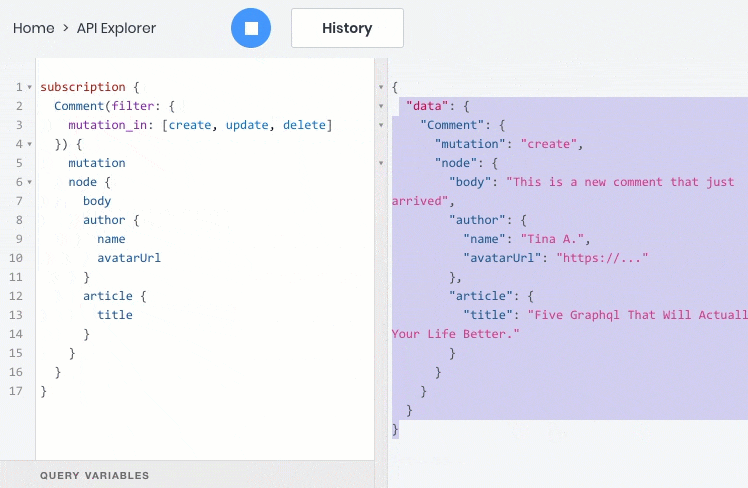
- все эти операции отлично работают со взаимосвязями между объектами, поэтому дочерние объекты можно запрашивать, создавать и обновлять вместе с родительскими:
Резюме
Спасибо за внимание! Очень хотелось бы услышать ваше мнение о GraphQL или о опыте его использования, его проблемах, а так же буду рад ответить на вопросы.
Также, друзья, возможно вам было бы интересно почитать серию технических статей о нашем стеке или может быть что-то ещё?
P.S. Чуть более подробно узнать о преимуществах GraphQL для фронтенд разработчиков и о том, как мы используем GraphQL, можно на видео с выступления нашего бэкенд-разработчика Андрея Горинова
Комментарии (20)

GHostly_FOX
18.02.2019 22:13Сейчас мы переходим на GraphQL (чуть позже будет статья).
Мы взяли GraphQL на вооружение для предоставление более гибкого интерфейса нашим REST API.
Дало конечно больше удобства и весьма сокращает количество запросов к API на получение необходимой информации. Мутации (изменение данных) мы не используем т.к. наши API предназначены только для того, чтобы делится информацией и в нашем случае GraphQL дает нам делать это более Красиво )))
andrei_anisimov Автор
19.02.2019 06:42Согласен, несмотря на то, что у бэкенд разработчиков много весьма валидных вопросов по поводу реализации, большинство клиентских разработчиков, как вы сказали, отмечают удобство работы с GraphQL. А в конечном счете, как говорится, клиент всегда прав))

powerman
19.02.2019 07:14Это говорилось вовсе не про тех клиентов. :)
И, кстати, лет 20 назад уже была технология, дающая клиентам почти то же самое, что GraphQL — называлась "клиент присылает серверу SQL-запрос (или отдельные элементы SQL-запроса)". Закончилось всё печально — несмотря на замечательную гибкость этого подхода для клиентов оказалось, что валидация на сервере не справляется с контролем безопасности, плюс некоторые запросы оказывались слишком "тяжёлыми", плюс изменение схемы БД требовало изменения клиентов. GraphQL, конечно, более продвинутый вариант, но не похоже, чтобы он решал все эти проблемы.
andrei_anisimov Автор
19.02.2019 08:02Согласен. Еще был/есть SOAP, у которого даже схема есть в спецификации. Но в этот раз все выглядит немного иначе. Основной фактор — общение на конференциях с разработчиками из таких компаний как Github, Airbnb, Jet.com, Atlassian и др, которые отмечают позитивный опыт в продакшене (у некоторых уже больше года) и повсеместные планы по расширению внедрения GraphQL. В конечном счете, с насыщением рынка API-продуктов, баланс сил смещается в сторону клиентских разработчиков, которые выбирают то API, которым им удобнее пользоваться, независимо от сложности реализации на бэке.
GHostly_FOX
20.02.2019 12:17Почему нет.
Он принимает не SQL запрос, а структурированный по его правилам запрос.
Шаг в лево, шаг в право — Ошибка.
Преимущества над RestAPI:
— он типизирован
— он сам может рассказать какая у него структура причем сразу с описанием и указанием типов данных
— он может рассказать какие поля получили флаг Deprecated
— он не примет ни каких подзапросов SQL или Injection т.к. все данные будут проходить через модели и валидироваться на входе
— он не раскрывает связей между объектами
и так можно продолжать дальше.
Принимать SQL — это не хорошо. Там слишком много лазеек которые можно использовать. GraphQL — уже лучше.
ktretyak
18.02.2019 22:18+1Есть ли понятие "версионности" в запросах на GraphQL, или эту надобность перекрывает указание нужной схемы от клиента? Тоесть, если клиент хочет некоторую версию данных от бекенда, то вместо номера версии он просто указывает нужную схему, или этого будет недостаточно?
andrei_anisimov Автор
19.02.2019 05:03GraphQL предлагает решение проблемы версионности путем добавления новых полей/запросов в схему. Поля, которые требуется исключить, сначала объявляются как @deprecated, давая клиентам знать что поле в будущем будет исключено из схемы. Подробнее об этом подходе: graphql.org/learn/best-practices/#versioning

prostofilya
19.02.2019 04:34А как там с кешированием?
andrei_anisimov Автор
19.02.2019 06:53В отличие от REST, где кэширование заложено на уровне протокола HTTP, в GraphQL оно остается на усмотрение разработчиков. Например Apollo Client имеет встроенный механизм кэширования запросов, который совмещен с управлением состоянием (state) приложения. На данном этапе мы не обнаружили серьезных недостатков связанных с кэшем, но не исключаем вероятность того что они возникнут в будущем и их прийдется решать.
tbicr
19.02.2019 13:55Вот если нятягивать graphql на реляционную базу:
как graphql помогает в решении делать join или подзапросы?
как позволяет избежать большого количества join или избегает бамбёжки самыми толстыми запросами?
как позволяет ограничить условие выборки и сортировки, чтобы попасть в индэкс?boblenin
19.02.2019 20:41Все делается в резолверах. Если сделаете тупой резолвер — будет плохо с join-ами. Но вы всегда можете иметь несколько. Или постепенно переводить тупые резолверы на умные.
По сути дела принятие решения перемещается из контроллера в резолвер. Вот и вся магия.
boblenin
19.02.2019 20:37+2GraphQL отлично подоходит для решения одной очень узкой задачи. Публикация API для большого количества независимых разработчиков, которых поддерживать у вас нет ни желания, ни обязательств, ни ресурсов; а им нужен доступ к очень небольшому количеству элементов данных из вашего дата-сета. Например вы facebook и под вашу платформу пишут десятки тысяч разработчиков для мобильных телефонов. И их приложения показывают одно-два текстовых поля и кнопочку. В таком случае гибкий контракт позволяет держать большую часть пользователей-разработчиков спокойными, а недовольным всегда будет меньшинство.
В случае же махрового ентерпрайза, когда ваш потребитель выгребает практически весь ваш датасет, во весь рост вылезают проблемы масштабирования, отсутствие версионности, невнятная модель безопасности, отсутствие поддержки кэширования на уровне протокола. И решенния на GraphQL получаются чем-то вроде припудренной и весьма дряхлой примадонны SOAP (которой многие все еще пользуются — зона комфорта все-таки).
И в общем дело не в том, что все что я перечислил не решаемо. Дело в том, что для решения всех этих проблем никогда нет ни времени, ни денег, ни управленческой воли. И в итоге применяя GraphQL мы усложняем жизнь клиентам (библиотеки все еще сырые, а в ручную писать все-таки труднее чем просто REST или RPC), а себе жизнь особо не облегчаем. Ну разве что даем разработчикам возможность еще один buzzword добавить в резюме.andrei_anisimov Автор
20.02.2019 06:29Эта проблема действительно актуальна в контексте энтерпрайса. В нашем случае мы не пытаемся решить все ситуации за счет GraphQL и готовим к выпуску набор фич позволяющих прямой доступ к БД. Таким образом во многих проектах 50%+ API будет предоставлено платформой, а остальное можно точечно кастомизировать под конкретный случай. В этом плане GraphQL не диктует что обязательно должны быть CRUD-операции на все сущности со связями. Просто за счет строгой типизации и набора open-source средств с таким API намного приятнее работать на клиенте. При этом контроль эффективности запросов не уменьшается по сравнению с REST.
SOAP действительно пытался решить многие подобные проблемы и в свое время звучал многообещающе, но XML, высокий порог вхождения, не такая развитая в то время open-source среда сделали работу с ним непривлекательной по сравнению с простым и элегантным REST+JSON. В случае с GraphQL работать с ним на наш взгляд действительно удобнее чем с REST, во многом именно за счет множества open-source средств. Такие вещи как статическая проверка типов, Apollo Client, автокомплит, средства типа GraphiQL и GraphQL Playground значительно ускоряют работу с данными на клиенте. После этого возвращение на REST вызывает негативные ощущения (субъективное мнение моe и команды, мы все делали REST/JSON RPC до 8base).
Thisnickname2019
20.02.2019 16:18Одним запросом всю базу, лихие ребята)) И да, у вас да и не только у вас, ни разу не Фейсбук.
powerman
Было бы любопытно услышать Ваше мнение по поводу моего старого комментария, ключевые моменты:
andrei_anisimov Автор
Да, действительно, все эти проблемы весьма актуальны. Реализация GraphQL бэкенда с гибким и секьюрным доступом к данным как-раз является одной из центральных проблем, которую мы решаем.
С другой стороны, эти проблемы характерны не только GraphQL. Если учесть, что API множества более сложных приложений из-за нужд клиентов со временем из RESTful превращаются в JSON RPC с доморощенным протоколом передачи данных и описанными выше проблемами, которые разработчики каждый раз решают по-своему. В этом смысле GraphQL дает некий стандарт вокруг которого со временем возникнут средства, упрощающие реализацию подобных бэкендов с гибким доступом к данным. Другими словами, GraphQL — это не совершенно новый подход, а скорее попытка формализации существующих по факту, но разрозненных практик.
На наш взгляд это того стоит, так как в конечном счете выиграют как клиент-разработчики, которым проще работать с данными в приложениях, так и платформы/организации, которые открывают гибкий доступ к своим данным как для внутренних, так и для внешних приложений.
powerman
Судя по описанию Вашего приложения — там нужен гибкий доступ к данным с запросами, которые заранее не предусмотришь, т.е. это вполне подходящий кейс для GraphQL.
Но в большинстве других приложений количество разных запросов к данным конечно и даже не очень велико, они известны заранее, и не составляет большой проблемы реализовать для каждого отдельный вызов JSON RPC 2.0 (это стандарт которому уже почти 10 лет, не совсем понял что Вы имели в виду под "доморощенным протоколом") с простым и явным контролем доступа (плюс с любыми ручными оптимизациями/кешами для тяжёлых запросов). И я вот совсем не уверен, что GraphQL для таких приложений является подходящим решением — больше похоже на то, что он несёт с собой больше проблем и сложностей, чем решает.
andrei_anisimov Автор
С учетом сложности реализации самописного GraphQL-бэкенда я согласен что многим приложениям GraphQL не требуется. С точки зрения бэкенда безусловно всегда проще реализовать жесткий набор эндпоинтов, особенно когда набор клиентов ограничен и заранее известен.
С другой стороны, если стоит цель максимально упростить работу с данными на клиенте, то GraphQL ее довольно хорошо решает. Мы делаем ставку на то, что важность удобства работы с данными на клиентах будет только расти. Также, появится больше средств позволяющих с легкостью развернуть GraphQL-бэкенд.
ogregor
У Microsoft есть аналог ODATA, та же самая проблема. Если настроить модели не правильно, то можно одним запросом всю базу выкачать. В случае если приложение большое, то спроектировать эти модели на все юзкейсы становится практически невозможным.
Поэтому как ODATA так и GraphQL можно рассматривать как дополнение а не замену.