
Но теперь мы спим лучше. Мы научились распознавать сценарии системного апокалипсиса и обрабатывать их. Ниже расскажу, как мы обеспечиваем стабильность системы.

Это первая статья из цикла про крушение системы, который я написал на основе своего выступления на DotNext 2018 в Москве:
1. День, когда Dodo IS остановилась. Синхронный сценарий.
2. Loading...
Dodo IS
Система — большое конкурентное преимущество нашей франшизы, потому что франчайзи получают готовую модель бизнеса. Это ERP, HRM и CRM, всё в одном.
Система появилась через пару месяцев после открытия первой пиццерии. Ей пользуются менеджеры, клиенты, кассиры, повара, тайные покупатели, сотрудники колл-центра — все. Условно Dodo IS делится на две части. Первая — для клиентов. Туда входят сайт, мобильное приложение, контакт-центр. Вторая для партнёров-франчайзи, она помогает управлять пиццериями. Через систему проходят накладные от поставщиков, управление персоналом, вывод людей на смены, автоматический расчёт зарплат, онлайн обучение для персонала, аттестация управляющих, система проверки качества и тайных покупателей.
Производительность системы
Производительность системы Dodo IS = Надёжность = Отказоустойчивость / Восстановление. Остановимся подробнее на каждом из пунктов.
Надёжность (Reliability)
У нас нет больших математических расчётов: нам нужно обслуживать определённое количество заказов, есть определённые зоны доставки. Количество клиентов особо не варьируется. Конечно мы обрадуемся, когда оно возрастёт, но это редко происходит большими всплесками. Для нас производительность сводится к тому, насколько мало отказов происходит, к надёжности системы.
Отказоустойчивость (Fault Tolerance)
Один компонент может быть зависим от другого компонента. Если в одной системе происходит ошибка, другая подсистема не должна упасть.
Восстанавливаемость (Resilience)
Сбои отдельных компонент происходят каждый день. Это нормально. Важно, насколько быстро мы можем восстановиться после сбоя.
Синхронный сценарий отказа системы
Что это?
Инстинкт большого бизнеса — обслуживать много клиентов одновременно. Так же как для кухни пиццерии, работающей на доставку невозможно работать так же, как хозяйка на кухне дома, код разработанный для синхронного исполнения не может успешно работать для массового обслуживания клиентов на сервере.
Есть фундаментальная разница между выполнением алгоритма в единственном экземпляре, и выполнением того же алгоритма сервером в рамках массового обслуживания.
Посмотрите на картинку ниже. Слева видим, как запросы происходят между двумя сервисами. Это RPC-вызовы. Следующий запрос завершается после предыдущего. Очевидно, этот подход не масштабируется — дополнительные заказы выстроятся в очередь.
Чтобы обслуживать много заказов нам нужен правый вариант:
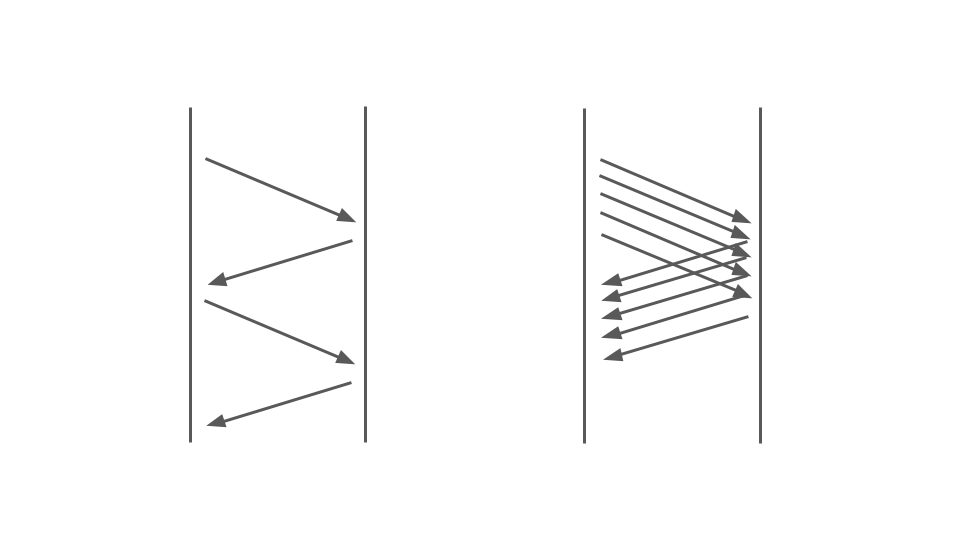
На работу блокирующего кода в синхронном приложении сильно влияет используемая модель многопоточности, а именно — preemptive multitasking. Она сама по себе может приводит к отказам.
Упрощенно, preemptive multitasking можно было бы проиллюстрировать так:

Цветные блоки – реальная работа, которую выполняет CPU, и мы видим, что полезной работы, обозначенной зеленым на диаграмме, довольно мало на общем фоне. Нам нужно пробуждать поток, усыплять его, а это накладные расходы. Такое усыпление/пробуждение происходит при синхронизации на любых синхронизационных примитивах.
Очевидно, эффективность работы CPU уменьшится, если разбавить полезную работу большим количеством синхронизаций. Насколько же сильно preemptive multitasking может повлиять на эффективность?
Рассмотрим результаты синтетического теста:
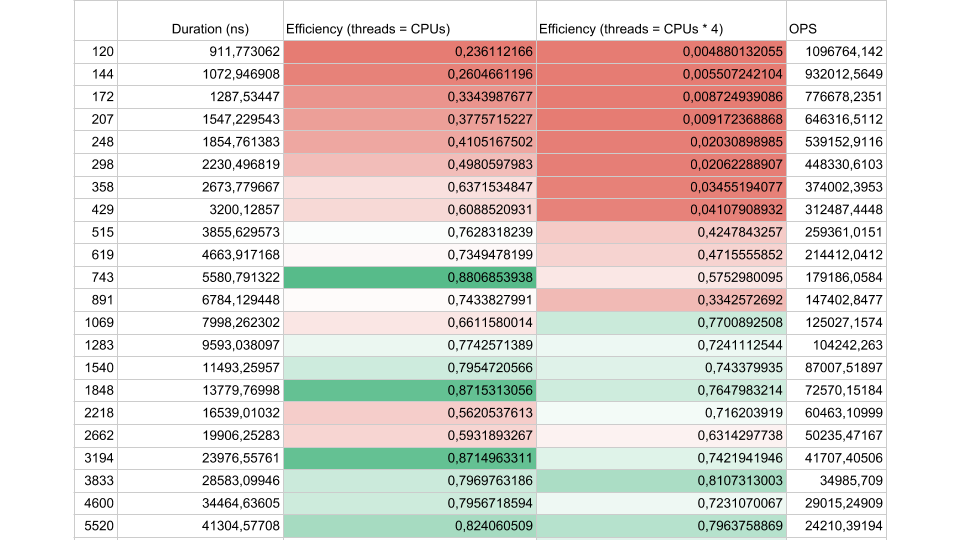
Если интервал работы потока между синхронизациями около 1000 наносекунд, эффективность довольно мала, даже если количество Threads равно количеству ядер. В этом случае эффективность около 25%. Если же количество Threads в 4 раза больше, эффективность драматически падает, до 0,5%.
Вдумайтесь, в облаке вы заказали виртуальную машину, у которой 72 ядра. Она стоит денег, а вы используете меньше половины одного ядра. Именно это может произойти в многопоточном приложении.
Если задач меньше, но их продолжительность больше, эффективность возрастает. Мы видим, что при 5000 операций в секунду, в обоих случаях эффективность 80-90%. Для многопроцессорной системы это очень хорошо.
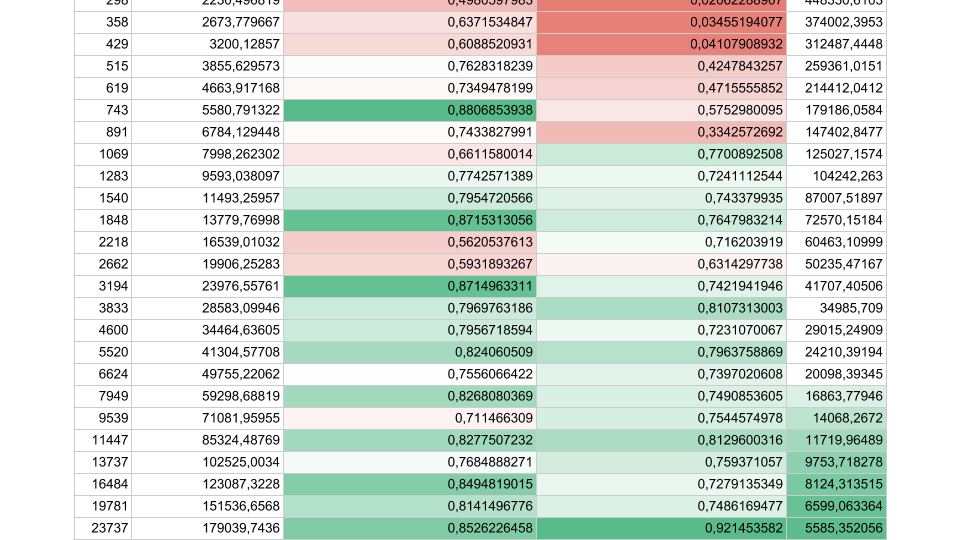
В реальных наших приложениях продолжительность одной операции между синхронизациями лежит где-то посредине, поэтому проблема актуальна.
Что же происходит?
Обратите внимание на результат нагрузочного тестирования. В данном случае это было так называемое «тестирование на выдавливание».
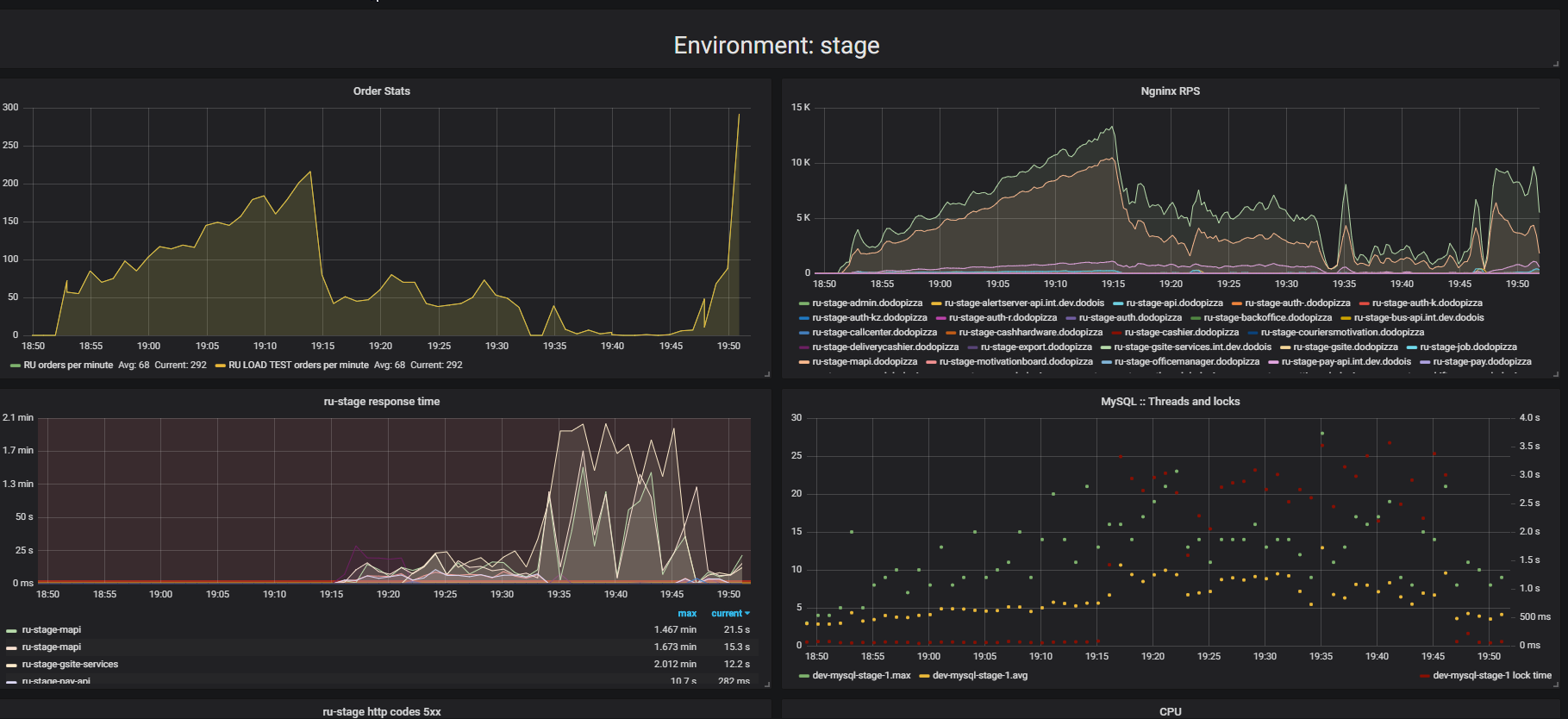
Суть теста в том, что используя нагрузочный стенд, мы подаём всё больше искусственных запросов в систему, пытаемся оформить как можно больше заказов в минуту. Мы стараемся нащупать предел, после которого приложение откажется обслуживать запросы сверх своих возможностей. Интуитивно мы ожидаем, что система будет работать на пределе, отбрасывая дополнительные запросы. Именно так происходило бы реальной жизни, например — при обслуживании в ресторане, который переполнен клиентами. Но происходит нечто иное. Клиенты сделали больше заказов, а система стала обслуживать меньше. Система стала обслуживать так мало заказов, что это можно считать полным отказом, поломкой. Такое происходит с многими приложениями, но должно ли так быть?
На втором графике время оформления запроса вырастает, за этот интервал обслуживается меньше запросов. Запросы, которые пришли раньше, обслуживаются значительно позже.
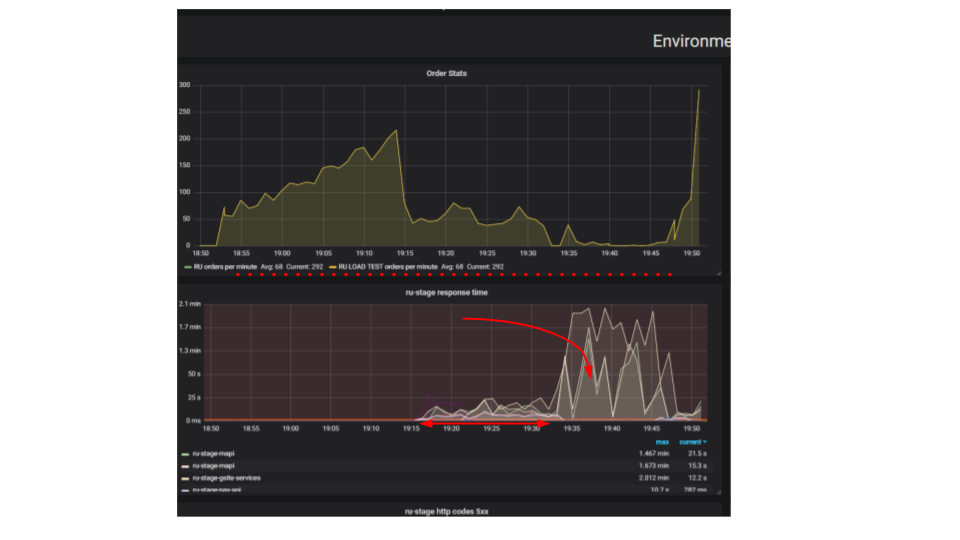
Почему приложение останавливается? Был алгоритм, он работал. Мы его запускаем со своей локальной машины, он работает очень быстро. Мы думаем, что если возьмём в сто раз более мощную машину и запустим сто одинаковых запросов, то они должны выполниться за это же время. Оказывается, что запросы от разных клиентов сталкиваются между собой. Между ними возникает Contention и это основополагающая проблема в распределенных приложениях. Отдельные запросы борются за ресурсы.
Пути поиска проблемы
Если сервер не работает, первым делом попробуем найти и устранить тривиальные проблемы блокировок внутри приложения, в базе данных и при файловом вводе/выводе. Есть еще целый класс проблем в сетевом взаимодействии, но мы пока ограничимся этими тремя, этого достаточно, чтобы научиться распознавать аналогичные проблемы, и нас прежде всего интересуют проблемы, порождающие Contention — борьбу за ресурсы.
In-process locks
Вот типичный запрос в блокирующем приложении.
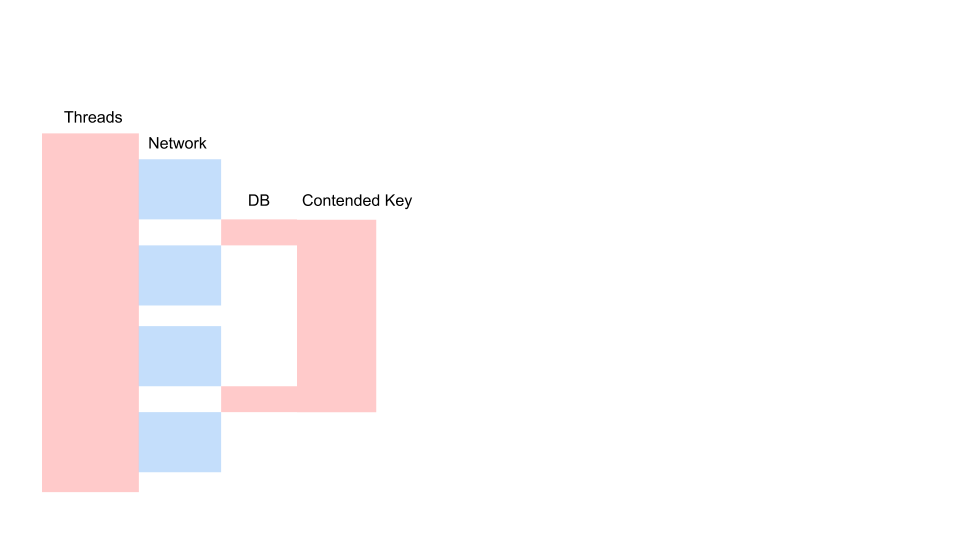
Это разновидность Sequence Diagram, описывающей алгоритм взаимодействия кода приложения и базы данных в результате какой-то условной операции. Мы видим, что делается сетевой вызов, потом в базе данных что-то происходит — база данных незначительно используется. Потом делается ещё один запрос. На весь период используется транзакция в базе данных и некий ключ, общий для всех запросов. Это может быть два разных клиента или два разных заказа, но один и тот же объект меню ресторана, хранящийся в той же базе данных, что и заказы клиентов. Мы работаем, используя транзакцию для консистенции, у двух запросов происходит Contention на ключе общего объекта.
Посмотрим, как это масштабируется.
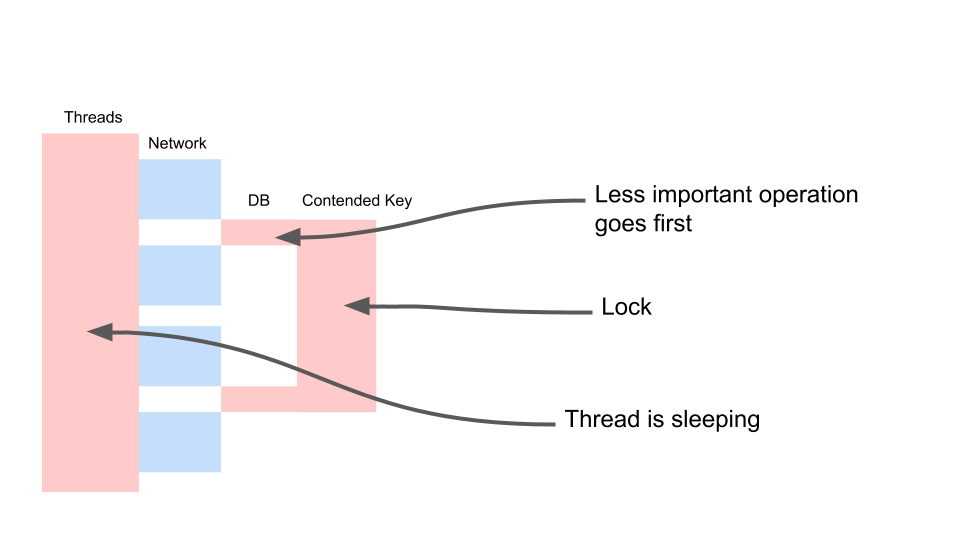
Thread спит большую часть времени. Он, по факту, ничего не делает. У нас держится лок, который мешает другим процессам. Самое обидное, что наименее полезная операция в транзакции, которая залочила ключ, происходит в самом начале. Она удлиняет скоуп транзакции во времени.
Мы с этим будем бороться вот так.
var fallback = FallbackPolicy<OptionalData>
.Handle<OperationCancelledException>()
.FallbackAsync<OptionalData>(OptionalData.Default);
var optionalDataTask = fallback
.ExecuteAsync(async () => await CalculateOptionalDataAsync());
//…
var required = await CalculateRequiredData();
var optional = await optionalDataTask;
var price = CalculatePriceAsync(optional, required);Это Eventual Consistency. Мы предполагаем, что некоторые данные у нас могут быть менее свежие. Для этого нам нужно по-другому работать с кодом. Мы должны принять, что данные имеют другое качество. Мы не будем смотреть, что произошло раньше — управляющей поменял что-то в меню или клиент нажал кнопку «оформить». Для нас нет разницы, кто из них нажал кнопку на две секунды раньше. И для бизнеса разницы в этом нет.
Раз разницы нет, мы можем сделать вот такую вещь. Условно назовем её optionalData. То есть какое-то значение, без которого мы можем обойтись. У нас есть fallback — значение, которое мы берём из кэша или передаём какое-то значение по умолчанию. И для самой главной операции (переменная required) мы будем делать await. Мы жёстко будем дожидаться его, а уже потом будем ждать ответа на запросы необязательных данных. Это нам позволит ускорить работу. Есть ещё один существенный момент — эта операция вообще может не выполниться по какой-то причине. Предположим — код этой операции не оптимален, и в данный момент там есть баг. Если операция не смогла выполниться, делаем fallback. А дальше мы работаем с этим как с обычным значением.
DB Locks
Примерно такой расклад у нас получается, когда мы переписали на async и поменяли модель консистентности.
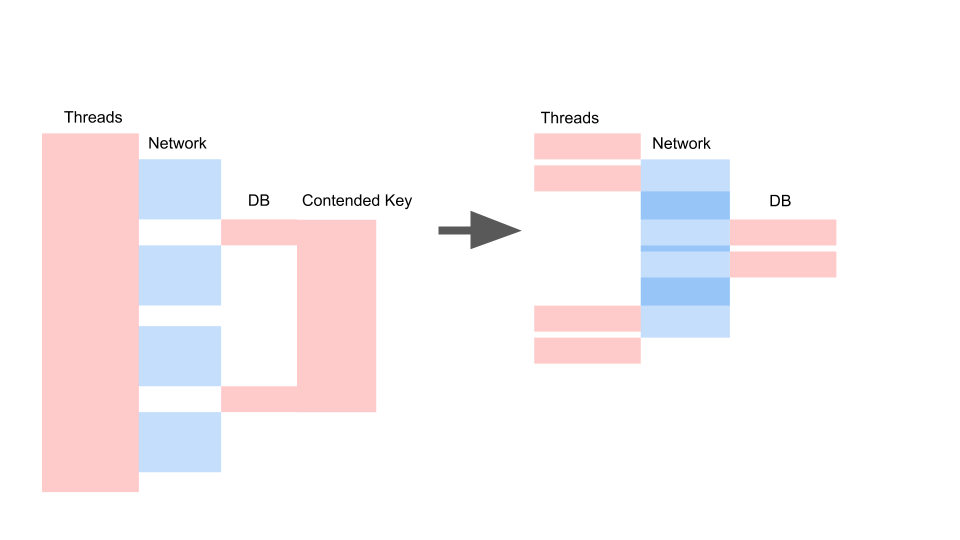
Здесь важно не то, что запрос стал быстрее по времени. Важно то, что у нас нет Contention. Если мы добавляем запросов, то у нас насыщается только левая сторона картинки.
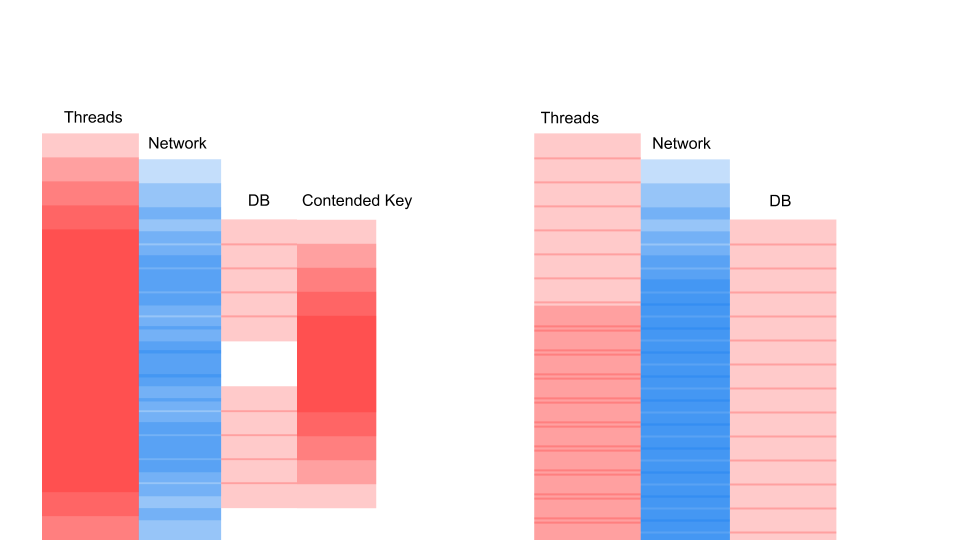
Это блокирующий запрос. Здесь Threads накладываются друг на друга и ключи, на которых происходит Contention. Справа у нас нет вообще транзакции в базе данных и они спокойно выполняются. Правый случай может работать в таком режиме бесконечно. Левый приведёт к падению сервера.
Sync IO
Иногда нам нужны файловые логи. Удивительно, но система логирования может дать такие неприятные сбои. Latency на диске в Azure — 5 миллисекунд. Если мы пишем подряд файл, это всего лишь 200 запросов в секунду. Всё, приложение остановилось.

Просто волосы дыбом встают, когда видишь это — более 2000 Threads расплодилось в приложении. 78% всех Threads — один и тот же call stack. Они остановились на одном и том же месте и пытаются войти в монитор. Этот монитор разграничивает доступ к файлу, куда мы все логируем. Конечно же такое надо выпиливать.

Вот что нужно делать в NLog, чтобы его сконфигурировать. Мы делаем асинхронный target и пишем в него. А асинхронный target пишет в настоящий файл. Конечно какое-то количество сообщений в логе можем потерять, но что важнее для бизнеса? Когда система упала на 10 минут, мы потеряли миллион рублей. Наверное, лучше потерять несколько сообщений в логе сервиса, который ушёл в отказ и перезагрузился.
Всё очень плохо
Contention — большая проблема многопоточных приложений, которая не позволяет просто масштабировать однопоточное приложение. Источники Contention нужно уметь идентифицировать и устранять. Большое количество Threads губительно для приложений, и блокирующие вызовы нужно переписывать на async.
Мне пришлось переписать немало legacy с блокирующих вызовов на async, я сам частенько выступал инициатором такой модернизации. Довольно часто кто-нибудь подходит и спрашивает: «Слушай, мы уже две недели переписываем, уже почти все async. А на сколько оно станет быстрее работать?» Ребята, я вас расстрою — оно не станет быстрее работать. Оно станет ещё медленнее. Ведь TPL — это одна конкурентная модель поверх другой — cooperative multitasking over preemptive multitasking, и это накладные расходы. В одном из наших проектов — примерно +5% к использованию CPU и нагрузка на GC.
Есть ещё одна плохая новость — приложение может работать значительно хуже после простого переписывания на async, без осознания особенностей конкурентной модели. Об этих особенностях я расскажу очень подробно в следующей статье.
Тут встает вопрос — а надо ли переписывать?
Синхронный код переписывают на async для того, чтобы отвязать модель конкурентного исполнения процесса (Concurrency Model), и отвязаться от модели Preemptive Multitasking. Мы увидели, что количество Threads может отрицательно влиять на производительность, поэтому нужно освободиться от необходимости увеличивать количество Threads для повышения Concurrency. Даже если у нас есть Legacy, и мы не хотим переписывать этот код — это главная причина его переписать.
Хорошая новость напоследок — мы теперь кое-что знаем о том, как избавиться от тривиальных проблем Contention блокирующего кода. Если вы такие проблемы обнаружите в своем блокирующем приложении, то самое время от них избавиться еще до переписывания на async, потому что там они не пропадут сами по себе.
Комментарии (19)

euroUK
19.02.2019 12:39Есть ещё одна плохая новость — приложение может работать значительно хуже после простого переписывания на async, без осознания особенностей конкурентной модели. Об этих особенностях я расскажу очень подробно в следующей статье.
Откровения от Додо Пиццы. Оказывается, асинк не спасает, когда в лог пишем последовательно!georgepolevoy Автор
19.02.2019 12:55В случае с NLog — у него синхронный интерфейс, поэтому thread, выполняющий логирование будет ждать завершения метода, например Logger.Info, и проблема будет общей как для блокирующего кода, так и async/await. Конфигурация асинхронного логгера будет означать, что метод не будет ожидать записи в файл, а просто поставит сообщение в очередь. Это решает проблему и для блокирующего кода, и async/await. Пропускная способность логгера с такой конфигурацией возрастает в десятки раз.
mayorovp
19.02.2019 13:19Не нравится мне ваша картинка с конфигом NLog.
Во-первых, при таком комбинировании способов записи асинхронная запись может заблокировать блокирующую — и проблема вернётся, пусть и в меньшем объёме.
Во-вторых, строчки в логе при вашем способе могут идти вразнобой.
В-третьих, раз уж вы упёрлись в скорость работы с логом — нужно сами логи тоже ускорять. Как минимум,
keepFileOpen="true"прописать...
vvzvlad
19.02.2019 14:08Во-вторых, строчки в логе при вашем способе могут идти вразнобой
А оно критично? Я думал, сейчас почти все пишется с именем сервиса и таймстампом, и кладется куда-нибудь типа elasticsearch для построения нормальных запросов, а не поиска в логе глазами.mayorovp
19.02.2019 14:35Эдак можно сразу отправлять логи куда-нибудь по сети, не заморачиваясь хранением их на диске. Если логи хранятся на диске в текстовом формате — значит, чтение их человеком предусмотрено в качестве одного из вариантов.
georgepolevoy Автор
19.02.2019 14:36del
mayorovp
19.02.2019 14:40Посмотрите свой конфиг ещё раз! Есть записи, которые копятся в очереди, и периодически записываются вместе. А есть записи, которые пишутся напрямую в файл построчно.
Первые записи будут блокировать вторые, как раз из-за сериализации таргетом «file». Первые и вторые записи будут идти вперемешку.georgepolevoy Автор
19.02.2019 14:47это тестовый конфиг, для бенчмарка. конечно вы правы — не нужно одновременно в оба логгера писать. либо в синхронный, либо в асинхронный
georgepolevoy Автор
19.02.2019 14:44Асинхронный таргет NLog не означает одновременной попытки записывать что-либо в файл, да это и невозможно, файл здесь — последовательное устройство. То, что в NLog назывется асинхронной записью, на самом деле просто очередь, которая сбрасывается в файл через временные интервалы. Поэтому порядок сохраняется. Сами логи не нужно ускорять, и keepFileOpen ничего не прибавляет, потому что логи сбрасываются раз в несколько секунд. Скорость асинхронного лога становится в десятки раз больше, потому что на скорость в основном влияет не скорость записи на диск, а latency доступа к диску, то есть все упирается в количество обращений к диску.

QSandrew
20.02.2019 06:30-1А когда будет пиццерия на Республике, Астана?
georgepolevoy Автор
20.02.2019 14:24Это зависит от партнеров франчайзи, а не от разработчиков :) Попробуйте найти информацию на странице vk.com/dodofranchise
Vplusplus
20.02.2019 08:34Если написать ядро вашей системы на C/C++ и грамотно спроектировать основную БД, где будут храниться только необходимые данные для текущей работы? А все остальные сервисы, не требующие «realtime», будут эти данные извлекать по мере возможности и самостоятельно хранить и обрабатывать.
Т.е. отделить котлеты от мух — то, что жизненно необходимо для обслуживания текущих заказов клиентов пишем быстро и просто, всё остальное (бухгалтерия, расчет заказов поставщикам, аналитика, з/п и пр.) — на любом зоопарке.
Ну не верю я, что на любом современном процессоре с производительностью порядка 30ГФлопс/ядро нельзя рассчитать заказы пиццы!

SerP1983
20.02.2019 15:46На весь период используется транзакция в базе данных и некий ключ, общий для всех запросов.
Мы работаем, используя транзакцию для консистенции, у двух запросов происходит Contention на ключе общего объекта
Самое обидное, что наименее полезная операция в транзакции, которая залочила ключ, происходит в самом начале.
А можете пояснить, что за такой «общий ключ для всех запросов»? Это тоже самое, что и «ключ общего объекта»? И как его или их лочит транзакция? А то как-то непонятно.georgepolevoy Автор
20.02.2019 15:47один и тот же объект меню ресторана, хранящийся в той же базе данных, что и заказы клиентов
SerP1983
20.02.2019 19:00Все равно непонятно. Ок. Попробую спросить по-другому. Этот ключ, который объект меню ресторана, физически — это запись в БД? И под "лочит" понимается update lock в БД?
MonkAlex
georgepolevoy Автор
Конечно мы ждем улучшений когда привносим async, но конечный результат нужно тестировать, чтобы ответить на вопрос об «ускорении». Первый же, и самый очевидный результат, который можно предсказать без всякого тестирования, это то, что TPL привносит свой overhead, и не стоит его игнорировать.