

Поисковая модель должна быть способна к «самокалибровке». То есть она должна быть способна взять свои алгоритмы, их удельный вес и сравнить смоделированные данные с общедоступными поисковыми системами, чтобы выявить наиболее точный поисковый механизм, позволяющий смоделировать любую среду.
Однако анализировать тысячи параметров, пытаясь найти наилучшее их сочетание – это астрономически дорого в плане вычислительной обработки, а также очень сложно.
Так как же, в таком случае, создать самокалибрующуюся поисковую модель? Выходит, единственное, что нам остается – обратиться за помощью к… птицам. Да-да, вы не ослышались, именно к пернатым!
Оптимизация с использованием роя частиц (PSO)
Нередко случается так, что грандиозные проблемы находят самые неожиданные решения. Так, например, стоит обратить внимание на оптимизацию с использованием роя частиц, которая представляет собой метод искусственного интеллекта, впервые упомянутая в 1995 году и базирующаяся на социально-психологической поведенческой модели толпы. Техника на самом деле смоделирована на основе концепции поведения птиц в стае.
На самом деле все алгоритмы, работающие на правилах, которые мы создали сегодня, по-прежнему не могут быть использованы для поиска хотя бы приблизительных решений самых сложных проблем численной максимизации или минимизации. Зато используя такую простую модель как птичья стая, вы сразу же сможете получить ответ. Мы не раз слышали ужасающие прогнозы о том, как однажды искусственный интеллект захватит наш мир. Однако в данном конкретном случае он как раз-таки становится нашим ценнейшим помощником.
Ученые занимались разработкой и реализацией множества проектов, посвященных Роевому интеллекту. Так, в феврале 1998 года был запущен проект «Millibot», ранее известный как «Cyberscout» — программа, задействованная морской пехотой США. Cyberscout был, по сути, легионом крошечных роботов, которые могли внедряться в здание, охватывая всю его территорию. Способность этих высокотехничных крох общаться и передавать между собою информацию дала возможность «рою» роботов действовать как единому целому организму, превращая весьма трудоемкую задачу по исследованию целого здания в неторопливую прогулку по коридору (у большинства из роботов была возможность проехать не более пары метров).
Почему это работает?
В PSO действительно классным является то, что методика не делает решительно никаких предположений о той проблеме, которую вы пытаетесь решить. Она представляет собой нечто среднее между основанным на правилах алгоритме, пытающимся выработать решение, и нейронных сетях искусственного интеллекта, которые ставят своей целью исследовать проблематику. Таким образом, данный алгоритм – это компромисс между исследовательским и эксплуататорским поведением.
Не имея исследовательскую природу, этот оптимизационный подход, алгоритм, несомненно, превратился бы в то, что статистики называют «локальным максимумом» (решение, которое представляется оптимальным, но не является таковым на самом деле).
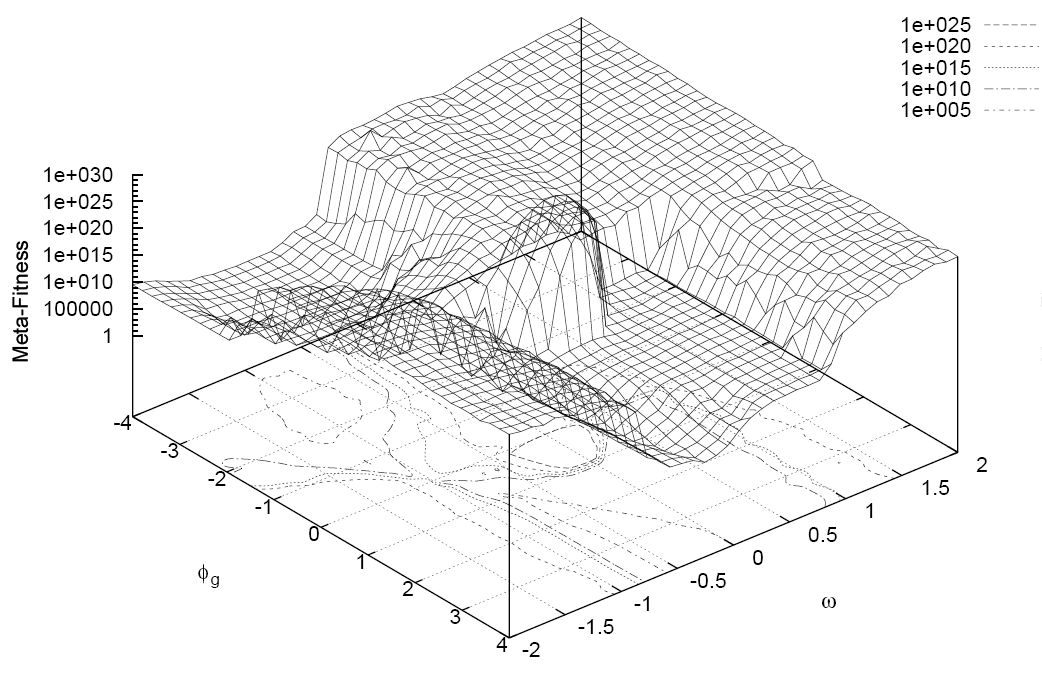
В первую очередь вы начинаете с ряда «стай» или догадок. В поисковой модели это могут быть различные весовые коэффициенты скоринговых алгоритмов. К примеру, имея 7 разных входов, вы начнете, как минимум, с 7 различных предположений относительно этих весов.

Идея PSO состоит в том, чтобы каждое из этих предположений находилось как можно дальше от остальных. Не вдаваясь в 7-мерные расчеты, вы можете использовать несколько техник, чтобы убедиться, что ваши отправные точки являются оптимальными.
После этого вы начнете развивать свои догадки. В ходе этого вы будете имитировать поведение птиц в стае в ситуации, когда возле них оказалась пища. Одна из случайных догадок (стай) окажется ближе других, и каждая последующая догадка будет скорректирована на основании общей информации.
Визуализация, показанная ниже, наглядно демонстрирует данный процесс.
Реализация
К счастью, существует целый ряд возможностей для реализации данного метода в разных языках программирования. И самое замечательное в оптимизации с использованием роя частиц то, что ее легко претворить в реальность! Техника имеет минимум параметров настройки (является показателем сильного алгоритма) и очень небольшой список недостатков.
В зависимости от вашей проблемы, реализация задумки может оказаться в локальном минимуме (не является оптимальным решением). Вы можете легко исправить это путем внедрения топологии соседства, которая быстро сведет цикл обратной связи к лучшим из близлежащих предположений.
Основная часть вашей работы будет состоять в разработке «приспособленческой функции» или алгоритма ранжирования, который вы будете использовать для определения степени близости к целевой корреляции. В нашем случае с SEO мы должны будем соотносить данные с неким заданным объектом вроде результатов Google или любой другой поисковой системы.

Если у вас есть работающая скоринговая система, ваш алгоритм PSO будет пытаться максимизировать показатели через триллионы потенциальных комбинаций. Скоринговая система может быть такой же простой, как выполнение корреляции Пирсона между вашей поисковой моделью и результатами поиска пользователей сети. Или же она может стать такой же сложной, как одновременное задействование этих корреляций и присвоение баллов каждому конкретному сценарию.
Корреляция относительно «черного ящика»
В последнее время многие сео-оптимизаторы пытаются выполнять корреляцию относительно «черного ящика» Google. Эти усилия, конечно, имеют право на жизнь, однако являются все же достаточно бесполезными. И вот почему.
Во-первых, корреляция не всегда подразумевает наличие причинно-следственной связи. Особенно если точки входа в ваш черный ящик располагаются не слишком близко к точкам выхода. Давайте рассмотрим это на примере, когда точки входа располагаются очень близко к соответствующим им точкам выхода — бизнес по перевозке мороженного. Когда на улице тепло, люди покупают больше мороженного. Здесь легко увидеть, что точка входа (температура воздуха) тесно привязана к точке выхода (мороженное).
К сожалению, большинство сео-оптимизаторов не используют статистическую близость между своими оптимизациями (входами) и соответствующими им поисковыми результатами (выходами).
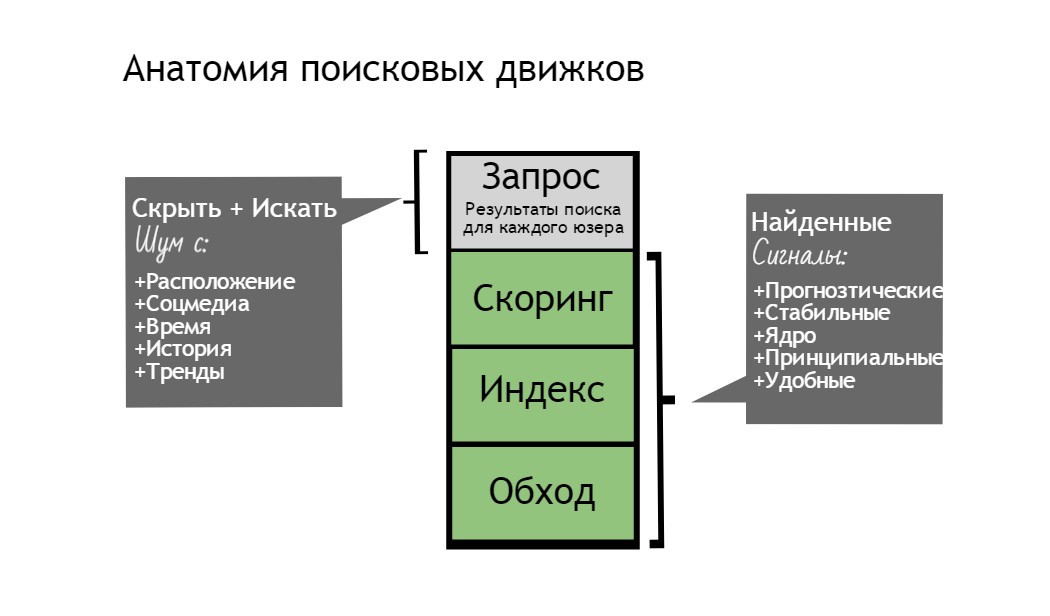
Более того, их входы или оптимизации находятся перед компонентами обхода в поисковой системе. Фактически типичная оптимизация должна пройти через 4 уровня: обход содержимого, индексирование, скоринг и, в конечном итоге, уровень запроса в реальном времени. Попытка корреляции подобным способом не может дать ничего кроме напрасных ожиданий.
На самом деле, Google обеспечивает существенный коэффициент шума, подобно тому, как правительство США создает шум вокруг своей сети GPS, в силу чего гражданские лица не имеют возможность получать такие же точные данные как военные. Это называется уровнем запросов в реальном времени. И этот пласт становится серьезным сдерживающим фактором для тактики SEO-корреляции.
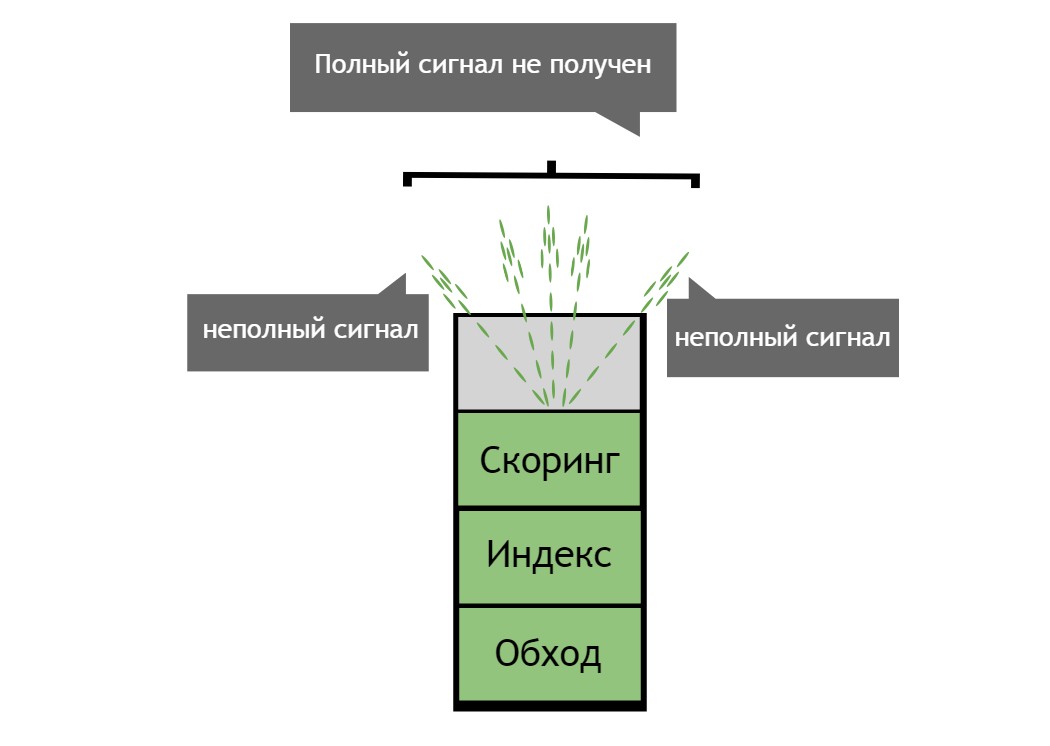
В качестве примера здесь можно привести садовый шланг. Находясь на скоринговом слое поисковой системы, вы получаете взгляд компании на то, что происходит вокруг. Вода, выходящая из садового шланга, организованна и предсказуема – то есть вы можете изменить положение шланга и предсказать соответствующее изменение движения потока воды (результаты поиска).
В нашем случае слой запросов распыляет эту воду (результаты поиска) в миллионы капелек (вариации результатов поиска), зависящих от пользователя. Большинство изменяющихся сегодня алгоритмов возникают на основе уровня запросов с тем, чтобы для того же количества пользователей произвести большее количество вариаций поисковых результатов. Алгоритм Колибри от Google является одним из примеров. Сдвиги на уровне запросов позволяют поисковым системам генерировать больше торговых площадок для своих PPC-объявлений.
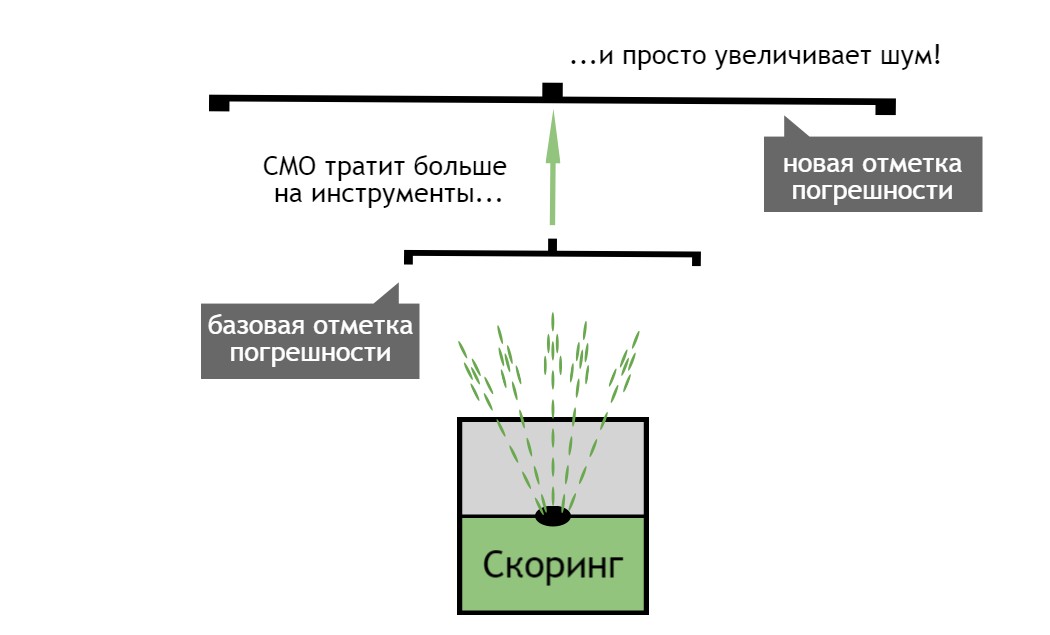
Уровень запросов – это взгляд пользователей, а не компании на то, что происходит. Следовательно, корреляции, выведенные таким образом, будут крайне редко иметь причинно-следственные связи. И это при условии, что вы имеете один инструмент, чтобы находить и моделировать данные. Как правило же, сео-оптимизаторы используют целый ряд входных данных, что будет способствовать повышению шумов и снижению вероятности поиска причинно-следственной связи.
Поиск причинно-следственных связей в SEO
Чтобы получить корреляцию для работы с моделью поисковой системы нужно как можно значительнее затянуть входы и выходы. В модели поисковой системы входные или переменные данные должны находиться в скоринговом слое или над ним. Как это сделать? Мы должны разбить черный ящик поисковой системы на ключевые компоненты, а далее построить модель поисковика с нуля.
Оптимизировать выходы даже сложнее в силу ужасающих шумов, возникающих из-за слоя запросов в реальном времени, который за счет каждого пользователя создает миллионы вариаций. Как минимум, нам нужно будет сделать такие входы для нашей модели поисковой системы, которые будут располагаться перед обычным слоем с вариациями запросов. Это гарантирует, что хотя бы одна и сравниваемых сторон стабильна.
Построив модель поисковой системы с нуля, мы сможем отображать результаты поиска, идущие не от уровня запросов, а прямо от скорингового слоя. Это даст нам более стабильную и точную взаимосвязь между входами и выходами, которые мы пытаемся соотнести. И тогда благодаря этим прочным и показательным связям между входами и выходами корреляция станет отражать причинно-следственную связь. Сделав акцент на одном входе, мы получим прямую связь с теми результатами, которые мы видим. Затем мы сможем сделать классический seo-анализ, чтобы определить вариант оптимизации, который будет выгоден для имеющейся модели поисковой системы.
Итоги
Ситуации, когда какая-нибудь простая вещь в природе приводит к научным открытиям или технологическим прорывам не может не восхищать. Имея модель поисковой системы, которая позволяет нам открыто соединить скоринговые входы с не персонализированными результатами поиска, мы можем связать корреляцию с причинно-следственной связью.
Добавьте к этому оптимизацию методом роя частиц, и вы имеете технический прорыв – самокалибрующуюся поисковую модель.
Комментарии (5)

alexeygrigorev
17.07.2015 14:27+1Не совсем понятно, что же за функцию вы оптимизируете. «Самокалибрующаяся поисковая модель» звучит слишком обще…
Из текста я понял, что функция должна предсказать рейтинг сайте в выдаче гугла/яндекса. А какие параметры подаются на вход? И почему обычные методы оптимизации как градиентный спуск или ньютоновский метод не подходят?


fortunato
19.07.2015 12:16Очень интересно) а что вы в итоге используете из библиотек?
как реализовали?
ServPonomarev
Другими словами, Вы создали модель скрытых параметров скорингового алгоритма Гугла и роевым способом нашли эти параметры. Теперь, имея модель, похожую на модель скоринга Гугла, можно подбирать такие параметры своих сайтов, что-бы иметь высокий скоринг, а значит — высокую позицию в выдаче.
Умное решение. Но Гугл тоже самообучающийся, и заметив падение релевантности от вашего поискового спама, будет изменять свою скоринговую модель. Получается наличие обратной связи в системе «скоринг Гугла — ваша модель скоринга гугла». Обратная связь даст колебания и прочие эффекты — будет забавно за этим понаблюдать.
bethrezen
Качества поисковой выдачи вы имели в виду?
С точки зрения оценки ответ может быть релевантным, даже если имеется какой-то спам(например спамные ссылки).
Если этим пользуется один оптимизатор/агентство, то и сайтов с такими признаками немного. В общей массе это может быть на уровне погрешности. Другое дело, если это уйдет в массы и все подряд будут использовать одну и ту же технику.