
Как быстро развернуть общее хранилище для двух серверов на базе решений drbd+ocfs2.
Для кого это будет полезно:
Туториал станет полезен системным администраторам и всем, кто выбирает способ реализации хранилища или хотят попробовать решение.
От каких решений мы отказались и почему
Часто мы сталкиваемся с ситуацией, когда нам нужно реализовать на небольшом web-кластере общее хранилище с хорошей производительностью на чтение — запись. Мы пробовали различные варианты реализации общего хранилища для наших проектов, но мало что было способно удовлетворить нас сразу по нескольким показателям. Сейчас расскажем, почему.
- Glusterfs не устроил нас производительностью на чтение и запись, возникали проблемы с одновременным чтением большого количества файлов, была высокая нагрузка на CPU. Проблему с чтением файлов можно было решить, обращаясь за ними напрямую в brick-и, но это не всегда применимо и в целом неправильно.
- Ceph не понравился избыточной сложностью, которая может быть вредна на проектах с 2-4 серверами, особенно, если проект впоследствии обслуживают. Опять же, имеются серьезные ограничения по производительности, вынуждающие строить отдельные storage кластеры, как и с glusterfs.
- Использование одного nfs сервера для реализации общего хранилища вызывает вопросы в плане отказоустойчивости.
- s3 — отличное популярное решение для некоторого круга задач, но это и не файловая система, что сужает область применения.
- lsyncd. Если мы уже начали говорить о «не-файловых системах», то стоит пройтись и по этому популярному решению. Мало того, что оно не подходит для двухстороннего обмена (но если очень хочется, то можно), так еще и не стабильно работает на большом количестве файлов. Приятным дополнением ко всему будет то, что оно является однопоточным. Причина в архитектуре программы: она использует inotify для мониторинга объектов работы, которые навешивает при запуске и при пересканировании. В качестве средства передачи используется rsync.
Туториал: как развернуть общее хранилище на базе drbd+ocfs2
Одним из наиболее удобных решений для нас стала связка ocfs2+drbd. Сейчас мы расскажем, как можно быстро развернуть общее хранилище для двух серверов на базе данных решений. Но сначала немного о компонентах:
DRBD — система хранения из стандартной поставки Linux, которая позволяет реплицировать данные между серверами блоками. Основное применение заключается в построении отказоустойчивых хранилищ.
OCFS2 — файловая система, обеспечивающая разделяемое использование одного и того же хранилища несколькими системами. Входит в поставку Linux и представляет из себя модуль ядра и userspace инструментарий для работы с ФС. OCFS2 можно использовать не только поверх DRBD, но и поверх iSCSI с множественным подключением. В нашем примере мы используем DRBD.
Все действия производятся на ubuntu server 18.04 в минимальной конфигурации.
Шаг 1. Настраиваем DRBD:
В файле /etc/drbd.d/drbd0.res описываем наше виртуальное блочное устройство /dev/drbd0:
resource drbd0 {
syncer { rate 1000M; }
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
startup { become-primary-on both; }
on drbd1 {
meta-disk internal;
device /dev/drbd0;
disk /dev/vdb1;
address 10.10.10.192:7789;
}
on drbd2 {
meta-disk internal;
device /dev/drbd0;
disk /dev/vdb1;
address 10.10.10.193:7789;
}
}meta-disk internal — использовать те же блочные устройства для хранения метаданных
device /dev/drbd0 — использовать /dev/drbd0 как путь к drbd тому.
disk /dev/vdb1 — использовать /dev/vdb1
syncer { rate 1000M; } — использовать гигабит пропускной способности канала
allow-two-primaries — важная опция, разрешающая принятие изменений на двух primary серверах
after-sb-0pri, after-sb-1pri, after-sb-2pri — опции, отвечающие за действия узла при обнаружении splitbrain. Подробнее можно посмотреть в документации.
become-primary-on both — устанавливает обе ноды в primary.
В нашем случае мы имеем две абсолютно одинаковые ВМ, с выделенной виртуальной сетью пропускной способностью в 10 гигабит.
В нашем примере сетевые имена двух нод кластера — это drbd1 и drbd2. Для правильной работы необходимо сопоставить в /etc/hosts имена и ip адреса узлов.
10.10.10.192 drbd1
10.10.10.193 drbd2Шаг 2. Настраиваем ноды:
На обоих серверах выполняем:
drbdadm create-md drbd0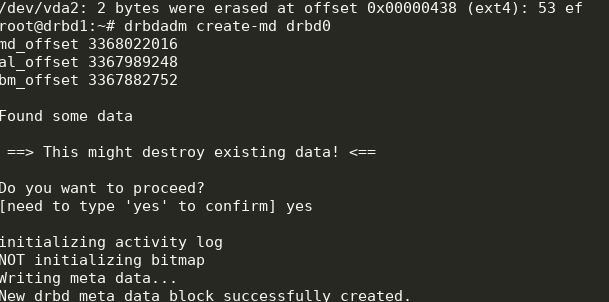
modprobe drbd
drbdadm up drbd0
cat /proc/drbdПолучаем следующее:

Можно запускать синхронизацию. На первой ноде нужно выполнить:
drbdadm primary --force drbd0Смотрим статус:
cat /proc/drbd
Отлично, началась синхронизация. Дожидаемся окончания и видим картину:

Шаг 3. Запускаем синхронизацию на второй ноде:
drbdadm primary --force drbd0
Получаем следующее:

Теперь мы можем писать в drbd с двух серверов.
Шаг 4. Установка и настройка ocfs2.
Будем использовать достаточно тривиальную конфигурацию:
cluster:
node_count = 2
name = ocfs2cluster
node:
number = 1
cluster = ocfs2cluster
ip_port = 7777
ip_address = 10.10.10.192
name = drbd1
node:
number = 2
cluster = ocfs2cluster
ip_port = 7777
ip_address = 10.10.10.193
name = drbd2
Её нужно записать в /etc/ocfs2/cluster.conf на обеих нодах.
Создаем ФС на drbd0 на любой ноде:
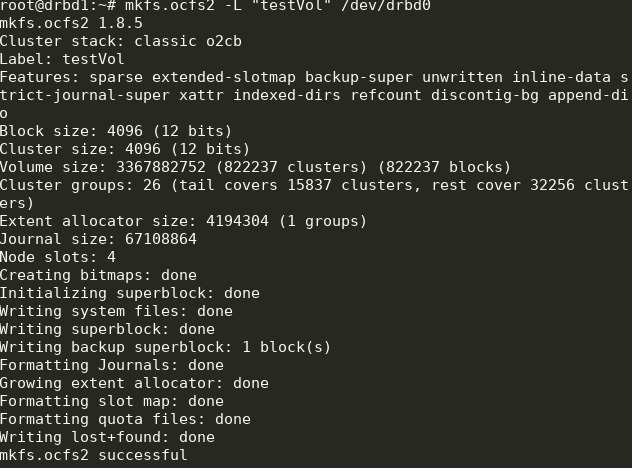
mkfs.ocfs2 -L "testVol" /dev/drbd0
Тут мы создали ФС с меткой testVol на drbd0, используя параметры по умолчанию.
В /etc/default/o2cb необходимо выставить (как в нашем файле конфигурации)
O2CB_ENABLED=true
O2CB_BOOTCLUSTER=ocfs2cluster и выполнить на каждой ноде:
o2cb register-cluster ocfs2clusterПосле чего включаем и добавляем в автозапуск все нужные нам unit-ы:
systemctl enable drbd o2cb ocfs2
systemctl start drbd o2cb ocfs2Часть этого уже будет запущена в процессе настройки.
Шаг 5. Добавляем точки монтирования в fstab на обеих нодах:
/dev/drbd0 /media/shared ocfs2 defaults,noauto,heartbeat=local 0 0Директория /media/shared при этом должна быть создана заранее.
Тут мы используем опции noauto, которая означает, что ФС не будет смонтирована при старте (предпочитаю монтировать сетевые фс через systemd) и heartbeat=local, что означает означает использование сервиса heartbeat на каждой ноде. Существует еще global heartbeat, который больше подходит для больших кластеров.
Далее можно смонтировать /media/shared и проверить синхронизацию содержимого.
Готово! В результате мы получаем более-менее отказоустойчивое хранилище с возможностью масштабирования и приличной производительностью.
Комментарии (6)

zacat
29.03.2019 14:20Про тестирование отказоустойчивости этой конфигурации ничего не сказано, кроме «более-менее отказоустойчивое хранилище». Что будет при неполадках сети (между DRBD), выхода одновременно узлов из строя и восстановления.
Cпойлерсплитбрейн
kolu4iy
29.03.2019 20:21Ещё один вопрос: я помню раньше на нагруженных виртуалках под управлением esxi не получалось использовать ocfs: она была шибко чувствительна к разбегу часов, и при подаче нагрузки, когда часы немного разбегались, во избежание split brain из предыдущего комментария вся нода падала в kernel panic. Как сегодня обстоят дела с проведением под серьезной нагрузкой?
oller
29.03.2019 21:34Любая такая система чувствительна к часам
И ведут себя они крайне плохо.
Лучшая подобная система CEPH, которую приняли в базовую поставку proxmox, но и у нее при рансинхроне часов сносит голову. Еще опа случается при проблемах в сети и частичной недоступности.
Для нормальной работы системы, нужен арбитр- третий наблюдатель, тогда на основе двух получается вывод о третьем, но и это не гарантия и могут быть проблемы.
pansa
30.03.2019 00:23Как раз самого интересного и важного нет — как оно себя ведет при отказах. И не сплитбрейном одним… Мы в 17м году поднимали стэнд на реальном железе, ничего путного из этого не получилось. Ну, да, на уровне «более-менее устойчивое» =) Т.е как в классике: «Петрович сказал будет стоять. Если дождь не пойдёт.»
Вся тематика хранения данных меня сильно удручает последние годы. :\

bzzz00
положим есть узлы хранения A и B, где A — мастер, а B с него синхронизируется. теперь B пропадает, но A продолжает принимать и обслуживать записи. далее происходит невообразимое — A падает, а B встает во весь рост. но на B нет последних N записей. его можно использовать? положим можно и теперь теперь записи принимает B. как после такой ситуации можно сихронизировать общее состояние?