
Предыстория
За последние пару лет я поучаствовал в немалом количестве собеседований. На каждом из них я спрашивал соискателей о принципе единственной ответственности(далее SRP). И большинство людей о принципе ничего не знают. И даже из тех, кто мог зачитать определение, почти никто не мог сказать как они используют этот принцип в своей работе. Не могли сказать, как SRP влияет на код, который они пишут или на ревью кода коллег. Некоторые из них также имели заблуждение, что SRP, как и весь SOLID, имеет отношение только к объектно ориентированному программированию. Также, зачастую люди не могли определить явные случаи нарушения этого принципа, просто потому что код был написан в стиле, рекомендованном известным фреймворком.
Redux — яркий пример фреймворка, гайдлайн которого нарушает SRP.
SRP имеет значение
Хочу начать с ценности этого принципа, с пользы которую он несет. А также хочу отметить, что принцип распространяется не только на ООП, но и на процедурное программирование, функциональное и даже декларативное. HTML, как представителя последнего тоже можно и нужно декомпозировать, тем более сейчас, когда он управляется UI-фреймворками, такими как React или Angular. Кроме этого принцип распространяется и на другие инженерные области. И не только инженерные, было такое выражение в военной тематике: «divide and conquer», что по большому счету воплощение того же принципа. Сложность убивает, раздели ее на части и ты победишь.
Касательно же других инженерных областей, здесь, на хабре, была интересная статья о том как у разрабатываемого самолета отказали двигатели, не перешли на реверс по команде пилота. Проблема была в том, что они неверно интерпретировали состояние шасси. Вместо того, чтобы полагаться на системы контролирующие шасси, контроллер двигателя напрямую считывал датчики, концевики и пр. находящиеся в шасси. Также в статье было упомянуто, что двигатель должен проходить длительную сертификацию до того как его поставят даже на прототип самолета. И нарушение SRP в данном случае явно приводило к тому, что при изменении конструкции шасси, код в контроллере двигателя нужно было модифицировать и заново проходить сертификацию. Хуже того, нарушение этого принципа чуть было не стоило самолета и жизни пилота. К счастью наше обыденное программирование не грозит такими последствиями, однако пренебрегать принципами написания хорошего кода все равно не стоит. И вот почему:
- Декомпозиция кода уменьшает его сложность. К примеру если решение задачи требует от вас написать код c цикломатической сложностью равной четырем, то метод несущий ответственность за решение двух таких задач одновременно потребует кода со сложностью 16. Если же это разделить на два метода, то суммарная сложность будет 8. Конечно это не всегда сводится к сумме против произведения, однако тенденция будет примерно такая в любом случае.
- Unit-тестирование декомпозированого кода упрощается и становится более эффективным.
- Декомпозированый код создает меньше сопротивления изменениям. При внесении изменений меньше вероятность внести ошибку.
- Код становится лучше структурирован. Искать что-то в коде разложеном по файлам и папкам намного легче чем в одной большой портянке.
- Отделение boilerplate кода от бизнес логики приводит к тому, что в проекте можно применить кодогенерацию.
И все эти признаки идут вместе, это признаки одного и того же кода. Вам не нужно выбирать между, например, хорошо тестируемым кодом и хорошо структурированым.
Существующие определения не работают
Одно из определений звучит так: «должна быть только одна причина, для изменения кода (класса или функции)». Проблема этого определения в том, что оно конфликтует с Open-Close принципом, вторым из группы принципов SOLID. Его определение: «код должен быть открыт для расширения и закрыт для изменения». Одна причина для изменения против полного запрета на изменения. Если подробнее раскрыть то что тут подразумевается, то окажется, что между принципами конфликта нет, однако между нечеткими определениями конфликт определенно есть.
Второе, более прямое определение звучит так: «у кода должна быть только одна ответственность». Проблема этого определения в том, что человеку свойственно все обобщать.
К примеру есть ферма, выращивающая куриц, и в этот момент у фермы только одна ответственность. И вот принимается решение разводить там еще и уток. Инстинктивно мы назовем это фермой для домашней птицы, нежели признаем, что там теперь стало две ответственности. Добавим туда овец, и это теперь ферма для домашних животных. Потом захотим выращивать там помидоры или грибы, и придумаем следующее еще более обобщенное название. Это же распространяется на «одну причину» для изменения. Эта причина может быть настолько обобщенной, насколько хватает фантазии.
Еще один пример это класс управляющий космической станцией. Он же ничего больше не делает, только космической станцией управляет. Как вам такой класс с одной ответственностью?
И, поскольку я упомянул Redux, когда соискатель знаком с этой технологией, я также задаю вопрос, а не нарушает ли типичный редюсер SRP?
Редюсер, напомню, включает в себя оператор switch, и случается что он разрастается до десятков а то и сотен case-ов. И единственная ответственность редюсера — управлять переходами состояния вашего приложения. Именно так, дословно, отвечали некоторые соискатели. И никакие намеки не могли сдвинуть это мнение с мертвой точки.
Итого, если какой то код вроде бы удовлетворяет принципу SRP, но при этом неприятно «пахнет» — знайте почему так происходит. Потому что определение «у кода должна быть одна ответственность» просто не работает.
Более подходящее определение
Из проб и ошибок у меня родилось определение получше:
Ответственность кода не должна быть слишком большой
Да, теперь нужно «измерять» ответственность у класса или функции. И если она слишком велика, то нужно эту большую ответственность разбить на несколько ответственностей меньшего размера. Возвращаясь к примеру с фермой, даже отвественность по разведению куриц может оказаться слишком большой и имеет смысл как то разделить бройлеров от несушек, например.
Но как ее померить, как определить что ответственность данного кода слишком большая?
К сожалению у меня нет математически точных методов, есть только эмпирические. И больше всего это приходит с опытом, начинающие разработчики совсем не умеют декомпозировать код, более продвинутые все лучше владеют этим, хоть и не всегда могут описать зачем они это делают и как это ложится на теории вроде SRP.
- Метрика cyclomatic complexity. К сожалению есть способы эту метрику маскировать, однако если вы ее будете собирать, то есть вероятность, что она покажет самые уязвимые места вашего приложения.
- Размер функций и классов. Функцию из 800 строк не нужно читать, чтобы понять, что с ней что то не так.
- Много импортов. Однажды я открыл файл в проекте соседней команды и увидел целый экран импортов, нажал page down и опять на экране были только импорты. Только после второго нажатия я увидел начало кода. Вы можете сказать, что все современные IDE умеют скрывать импорты под «плюсик», я же говорю, что хороший код не нуждается в сокрытии «запахов». Кроме этого, мне понадобилось переиспользовать небольшой кусочек кода и я вынес его из этого файла в другой, и за этим кусочком переехала четверть, а то и треть импортов. Этому коду явно было там не место.
- Модульные тесты. Если у вас все еще есть трудности с определением размера ответственности, заставьте себя написать тесты. Если на основное назначение функции нужно написать два десятка тестов, не считая пограничных случаев и т.д., значит нужна декомпозиция.
- То же относится к слишком большому числу подготовительных действий в начале теста и проверкам в конце. В интернете, кстати, можно встретить утопическое утверждение, что т.н. assert в тесте вообще должен быть только один. Я же считаю, что любая сколь угодно хорошая идея, будучи возведенной в абсолют, может стать до абсурдного непрактичной.
- Бизнес логика не должна напрямую зависеть от внешних инструментов. Драйвер Oracle, роуты Express-а, все это желательно отделить от бизнес логики и/или спрятать за интерфейсами.
Пара моментов:
Конечно, как я уже упомянул, есть оборотная сторона медали, и 800 методов по одной строчке может быть не лучше, чем один метод на 800 строк, во всем должен быть баланс.
Второе — я не освещаю вопрос куда положить тот или иной код в соответствии с его отвественностью. К примеру, иногда у разработчиков также возникают трудности с тем, что они тянут слишком много логики в DAL слой.
Третье — я не предлагаю каких либо конкретных жестких ограничений вроде «не более 50 строк на функцию». Данный подход предполагает лишь направление для развития разработчиков, и может быть, команд. Он работает у меня, должен заработать и для других.
И последнее, если вы будете проходить через TDD, одно только это наверняка заставить вас декомпозировать код задолго до того, как вы напишете те 20 тестов по 20 assert-ов в каждом.
Отделение бизнес логики от boilerplate кода
Разговаривая о правилах хорошего кода нельзя не обойтись без примеров. Первый пример посвящен отделению boilerplate кода.
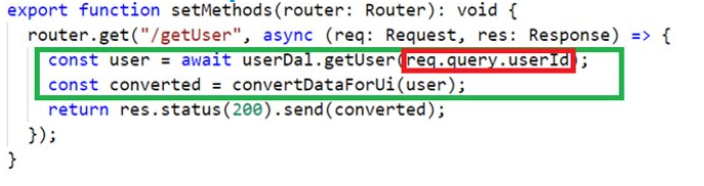
Этот пример демонстрирует то, как обычно пишут back-end код. Люди обычно пишут логику неотрывно от кода указывающего Web-серверу Express такие параметры как URL, метод запроса и т.д.
Зеленым маркером я обозначил собственно бизнес-логику, а красным — инородное вкрапление кода, взаимодействующего с параметрами запроса (query string).
Я же всегда разделяю эти две ответственности таким образом:

В этом примере все взаимодействие с Express вынесено в отдельный файл.
На первый взгляд может показаться, что второй пример не принес улучшений, стало 2 файла вместо одного, появились дополнительные строчки, которых до этого не было — имя класса и сигнатура метода. И что же тогда такое разделение кода дает? В первую очередь — «точка входа приложения» теперь не Express. Теперь это обычная Typescript функция. Или javascript функция, ли C#, кто на чем пишет WebAPI.
Это в свою очередь позволяет совершать различные действия, недоступные в первом примере. Например вы можете писать behavior-тесты без необходимости поднимать Express, без использования http запросов внутри теста. И даже нет необходимости производить какое либо мокирование, подменять Router объект своим «тестовым» объектом, теперь код приложения можно просто вызвать из теста напрямую.
Еще одна интересная возможность, которую дает такая декомпозиция — теперь можно написать генератор кода, который будет парсить userApiService и на его основе генерировать код, связующий этот сервис с Express. В своих будущих публикациях я планирую обозначить следующее: кодогенерация не сбережет время в процессе написания кода. Затраты на кодогенератор не окупятся тем, что теперь не нужно копипастить этот boilerplate. Кодогенерация окупится тем, что код ей произведенный не нуждается в поддержке, что сэкономит время и главное — нервы разработчиков в долговременной перспективе.
Divide and conquer
Этот метод написания кода существует давно, я не придумывал его сам. Я лишь пришел к тому, что он очень удобен при написании бизнес логики. И для этого я придумал еще один вымышленный пример, показывающий как можно быстро и легко писать код, который сразу хорошо декомпозирован, а также самодокументирован посредством именования методов.
Скажем, вы получаете от бизнес-аналитика задачу сделать метод, отправляющий отчет о сотрудниках в страховую компанию. Для этого:
- Данные нужно взять из БД
- Преобразовать в нужный формат
- Отправить получившийся отчет
Не всегда такие требования пишут явно, иногда такая последовательность может подразумеваться или выясниться из разговора с аналитиком. В процессе реализации метода не бросайтесь открывать соединения с базой данных или сетью, вместо этого попробуйте транслировать этот простой алгоритм в код «как есть». Примерно так:
async function sendEmployeeReportToProvider(reportId){
const data = await dal.getEmployeeReportData(reportId);?
const formatted = reportDataService.prepareEmployeeReport(data);?
await networkService.sendReport(formatted);?
}
С таким подходом получается достаточно простой, легко читаемый и тестируемый код, хотя я и считаю, что этот код тривиален и в тестировании не нуждается. И ответственнось этого метода не отправлять отчет, его ответственность — разбиение этой сложной задачи на три подзадачи.
Далее, возвращаемся к требованиям и узнаём что отчет должен состоять из зарплатной секции и секции с отработанными часами.
function prepareEmployeeReport(reportData){
const salarySection = prepareSalarySection(reportData);?
const workHoursSection = prepareWorkHoursSection(reportData);?
return { salarySection, workHoursSection };?
}
И так и дальше продолжаем разбивать задачу до тех пор пока не останется реализация маленьких методов, близких к тривиальным.
Взаимодействие с Open-Close принципом
Вначале статьи я рассказал, что определения принципов SRP и Open-Close противоречат друг другу. Первый говорит, что должна быть одна причина для изменения, второй говорит, что код должен быть закрыт для изменения. А сами принципы, не только не противоречат друг другу, наоборот, они работают в синергии друг с другом. Все 5 принципов SOLID направлены на одну благую цель — указать разработчику какой код «плохой», и как можно его поменять чтобы он стал «хороший». Ирония — я только что подменил 5 ответственностей на одну ответсвенность побольше.
Итак, в дополнение к предыдущему примеру с отсылкой отчета в страховую компанию, представим, что к нам приходит бизнес аналитик и говорит, что теперь нужно добавить вторую функциональность в проект. Этот же отчет нужно выводить на печать.
Представим, что нашелся разработчик, который считает, что SRP «не про декомпозицию».
Соответственно ему этот принцип не указал на на необходимость декомпозиции, и он реализовал всю первую задачу в одной функции. После того, как ему пришла задача, он, объединяет две отвественности в одну, т.к. между ними много общего и обобщает ее название. Теперь эта ответственность называется «обслужить отчет». Реализация этого выглядит примерно так:
async function serveEmployeeReportToProvider(reportId, serveMethod){
/*
lots of code to read and convert the report
*/
switch(serveMethod) {
case sendToProvider:
/* implementation of sending */
case print:
/* implementation of printing */
default:
throw;
}
}
Напоминает какой то код в вашем проекте? Как я уже говорил, оба прямых определения SRP не работают. Не передают разработчику информации о том, что такой код писать нельзя. И на то какой код писать можно. Для разработчика по прежнему осталась всего одна причина, для того, чтобы изменить этот код. Он просто переобозвал предыдущую причину, добавил switch и спокоен. И тут на сцену выходит принцип Open-Close принцип, который прямо говорит, что изменять уже существующий файл было нельзя. Надо было писать код так, чтобы при добавлении новой функциональности нужно было добавить новый файл, а не править уже существующий. То есть такой код плох с точки зрения сразу двух принципов. И если первый не помог это увидеть, второй должен помочь.
И как решает эту же задачу метод «divide and conquer»:
async function printEmployeeReport(reportId){
const data = await dal.getEmployeeReportData(reportId);?
const formatted = reportDataService.prepareEmployeeReport(data);?
await printService.printReport(formatted);?
}
Добавляем новую функцию. Я их иногда еще называю «функция-сценарий», потому что они не несут реализации, они определяют последовательность вызова декомпозированных кусочков нашей ответственности. Очевидно, первые две строчки, первые две декомпозированные ответственности совпадают с первыми двумя строчками реализованной ранее функции. Точно также как совпадают первые два шага двух описанных бизнес аналитиком задач.
Таким образом для добавления новой функциональности в проект мы добавили новый метод сценарий и новый printService. Старые файлы изменению не подверглись. То есть этот метод написания кода хорош сразу с позиции двух принципов. И SRP и Open-Close
Альтернатива
Также я хотел упомянуть альтернативный, конкурирующий способ получать хорошо декомпозированный код, который выглядит примерно так — сначала пишем код «в лоб», затем рефакторим его используя различные приемы, например по книге Фаулера «Рефакторинг». Эти методы напомнили мне математический подход к игре в шахматы, где вы не понимаете что именно вы делаете с точки зрения стратегии, вы лишь вычисляете «вес» вашей позиции и пытаетесь максимизировать его делая ходы. Мне этот подход не нравился по одной небольшой причине — именовать методы и переменные и без того сложно, а когда у них нет бизнес-значения это становится невозможным. К примеру если эти методики подсказывают, что нужно выделить 6 одинаковых строк отсюда и оттуда, то выделив их, как назвать этот метод? someSixIdenticalLines()?
Хочу оговориться — я не считаю этот метод плохим, я лишь не смог приучиться его использовать.
Итого
В следовании приципу можно найти выгоду.
Определение «должна быть одна ответственность» — не работает.
Есть определение получше и ряд косвенных признаков, т.н. code smells, сигнализирующих о необходимости декомпозировать.
Подход «divide and conquer» позволит сразу писать хорошо структурированый и самодокументированый код.
ookami_kb
Историческое, но запутывающее определение.
Нет, это определение совсем неправильное.
Of all the SOLID principles, the Single Responsibility Principle (SRP) might be the least well understood. That’s likely because it has a particularly inappropriate name. It is too easy for programmers to hear the name and then assume that it means that every module should do just one thing.
Make no mistake, there is a principle like that. A function should do one, and only one, thing. We use that principle when we are refactoring large functions into smaller functions; we use it at the lowest levels. But it is not one of the SOLID principles—it is not the SRP.
Historically, the SRP has been described this way:
Software systems are changed to satisfy users and stakeholders; those users and stakeholders are the “reason to change” that the principle is talking about. Indeed, we can rephrase the principle to say this:
Unfortunately, the words “user” and “stakeholder” aren’t really the right words to use here. There will likely be more than one user or stakeholder who wants the system changed in the same way. Instead, we’re really referring to a group—one or more people who require that change. We’ll refer to that group as an actor.
Thus the final version of the SRP is:
VladVR Автор
это из разряда: complexity kills, decompose it and you win.
ookami_kb
Т.е. "функция должна делать одну вещь" – это слишком расплывчато, а "Ответственность кода не должна быть слишком большой" – норм?
Довести до абсурда можно все, что угодно. Принципы и паттерны – это не законы, не надо искать в них лазейки, чтоб написать говнокод, прикрываясь "а че, я следовал букве закона".
Ну и повторюсь, декомпозиция и разбиение на подзадачи – это хорошо, но к SRP никакого отношения не имеет.
VladVR Автор
Первое не расплывчато, оно не работает вообще.
Второе работает примерно так — отправить отчет провайдеру — слишком большая ответственность. Считать данные(1), преобразовать данные(2) и отправить объект(3) в сеть — три ответственности поменьше. Суммарно они равны первой, слишком большой ответственности.
Кроме того, что люди реализуют эти три ответственности в одном методе, они еще и «переплетают» их. То есть считав одну строку или число из базы, сразу стремятся преобразовать во что то. Тут и появляется помножение сложностей двух задач.
Разбиение одной большой задачи на три маленьких это тоже самое что разбиение одной большой ответственности на три маленьких. Если вам запретить использовать большую ответственность для отговорок, и настоять на том, что ваш метод таки имеет три ответственности, то принцип SRP тут именно и при чём. Именно он скажет, что ответственность должна быть одна, следовательно метод надо разбить на три части.
ookami_kb
И все равно у вас будет функция
отправитьДанные, которая будет состоять из вызовов трех других функций. А если еще и как в вашем примере с функциейsendEmployeeReportToProvider, она будет вызывать их напрямую, без всяких интерфейсов, то все зависимости, а с ними и ответственности, никуда не денутся. Вы просто спрятали их в другие функции.Ну нет же, не "ответственность должна быть одна", а "ответственность должна быть перед одним стейкхолдером".
VladVR Автор
ookami_kb
Во-первых, не надо забывать, что эти принципы вообще-то созданы для больших приложений, где стейкхолдер далеко не один.
Во-вторых, стейкхолдер (а точнее, все-таки актор) – это не человек, а роль, и даже в небольшой компании один человек может быть несколькими акторами.
В-третьих, да, если актор все-таки один, то SRP вам не предлагает разбивать этот модуль. Но:
VladVR Автор
Эти принципы созданы не «для приложений». Эти принципы созданы для разработчиков, для того, чтобы они писали «хороший» код и не писали плохой. Причина, зачем вообще нужен SRP — при изменении кода по просьбе одного «актора», если этот код также делает что то для другого актора — появляется вероятность внести ошибку. Если перейти в плоскость ответственностей, там происходит тоже самое. Если в методе переплетены две ответственности, то меняя одну из них, появляется вероятность сломать другую.
Уже на этой точке должно быть видно, что это один и тот же принцип.
Все принципы, так или иначе, направлены на единственную благородную цель — снизить количество ошибок. Снижать цикломатическую сложность нужно, потому что чем больше сложность, тем больше вероятность внести ошибку. Повышать тестируемость кода нужно, чтобы снизить вероятность ошибок. И так далее.
И да, я в статье упоминал про таких людей, которые говорят «этот принцип тут не применим». Это неверный ответ.
ookami_kb
Верно. И SRP, и декомпозиция, и LSP – все они направлены на то, чтобы снизить количество ошибок. Но вы же не будете на основании этого утверждать, что SRP и LSP – это одно и то же?
Druu
И не просто можно — а нужно!
Зачем усложнять код, разбивая его на куски, если он хорошо выражается в рамках одной функции? Чтобы запутать потом читателя и усложнить сопровождение, тем самым?
Rukis
Затем, что это не единственная причина, по которой стоит декомпозировать функцию. Как раз чтобы облегчить восприятие и упростить сопровождение. Общую логику объемного кода проще понять, если он разбит на именованные абстракции, этими абстракциями проще управлять, повторяющиеся куски сложнее поддерживать и тд.
Druu
Вот вы момент этот быстро так проскочили, а он весьма важен.
Понятнее станет только в том случае, если разбиение действительно логично, и именование действительно хорошо отражает суть происходящих процессов. Чисто техническая декомпозиция зачастую этим критериям не удовлетворяет и наоборот усложняет понимание текста.
Опять же — не всегда, есть "ложная копипаста", выделение которой только повышает затраты.
Rukis
Естественно важен, никто не предлагает делать рефакторинг ради рефакторинга. Речь идет о том, что «если стейкхолдер всего один» — это еще не повод всё паковать в одну функцию, есть и достаточное количество других причин.
mamento
Так принцип SRP который описывает стейкхолдеров и не утверждает этого. Этот принцип работает только в одну сторону… А именно если у вас стейкхолдеров больше одного, то стоит иметь для них раздельные реализации… Кстати, это актуально даже если они дублируют друг друга. Класический пример что если у вас в компании два отдела в настоящее время считают ЗП одинаково(например использую ГРОСС), то при изменении способа подсчета в одном отеделе, не должно поведение поменяться для всех.
А разбиение на функции это уже больше к принципе KISS относится, нужно стараться держать код в таком состоянии в котором его легко понять и поддурживать. И двести строк кода, в определенных ситуация, могут быть значительно понятнее чем если их разбить на «искуственные» состовляющие.
Rukis
Всё верно. Не противоречил этому. Я выразил несогласие с высказыванием:
VolCh
Крайне редко бывает, что стейкхоллер, вернее актор, один физически. И даже если так, то, чаще всего он выступает в нескольких ролях. Вот по ролям и разделять. И помнить, что разработчик — это тоже роль, с одной стороны, а, с другой, запреты на изменения модуля они о публичном его контракте, прежде всего, о логике соответствующего уровня. Рефакторинги, оптимизации не входят, по-моему, в SRP и OCP. Если DBA жалуется на явную проблему 1+N запроса, то не надо отправлять его к главбуху, чтобы тот создал задачу на джойн запрос, а не вызов второго запроса в цикле по результатам первого.
VladVR Автор
И про «одну причину для изменения» все тоже также. Есть причина — надо поменять способ хранения данных в базе. Вторая причина — надо поменять протокол связи по сети. Если же ответственность метода воспринимать как «отправлять отчет», то обе эти причины звучат как нужно поменять отправление отчета, а остальное это детали. Акторы, юзеры, стейкхолдеры, как это все ни назови, это все об одном и том же. И проблема у всех определений одна и та же. И есть еще такой принцип в Domain Driven Design, называется Domain Distillation. Другое название, другой «уровень», а принцип тот же — декомпозируй.
nrgian
Пересечения и взаимопротивоположенные хотелки — встречаются сплошь и рядом. Если хотите противоречивые функции изолировать — придется дублировать.
Деление на мелкие части не во всех случаях поможет.
Зачастую лучше наплевать на этот принцип и согласовать хотелки между собой.
ookami_kb
Именно. SRP о том и говорит, что каждому актору – свой модуль. Какое-то перекрытие логики при этом возможно, и тут 2 пути: дублирование и вынесение общей логики в shared модуль. Что именно выбрать – it depends. Не всегда дублирование – это однозначное зло, в обоих случаях есть преимущества и недостатки.
Абсолютно согласен. Более того, я на протяжении всей это ветки говорю о том, что деление на мелкие части (декомпозиция) не имеет никакого отношения к SRP.
Ну согласовать хотелки не всегда возможно. Сегодня вы их согласовали, а завтра опять у каждого актора свои потребности. И вот как раз SRP и предлагает разделить модули, чтобы вы завтра снова не бегали их согласовывать.
VladVR Автор
Я считаю, что их надо декомпозировать еще на уровень выше. Не раскладывать в две папки в одном проекте, а разложить в два отдельных проекта. И да, SRP все еще про декомпозицию, хоть и на другом уровне. И даже в этом, абсурдном, не дающем абсолютно ничего разработчику, понимании, вопрос все равно в отделении одного от другого, мух от котлет.
ookami_kb
Не совсем так, все-таки SRP – это больше про один проект с несколькими акторами. В вашем же примере – это с самого начала однозначно разные проекты, и я бы сразу на старте сделал бы их независимыми.
Какую-то часть можно выделить в переиспользуемую библиотеку, но в основном это должны быть вспомогательные функции и утилиты (+ возможно генератор общих служебных страниц). Но бизнес-логика все-таки должна быть разделена сразу.
В DDD есть понятие Bounded Context, и даже в рамках одного проекта, например, сущность Customer может находиться в разных контекстах, с частичным дублированием логики – в случае, когда над разными контекстами работают разные команды, к shared коду надо относиться с большой опаской. И да, если вы что-то вынесли в общий код – то это становится общей ответственностью, иначе получается вот это "естественно разработчик не будет запускать «чужой проект», чтобы проверить".
Мне очень не нравится то, что большинство программистов настолько запуганы этим DRY, что у них любая строчка кода, встретившаяся в проекте больше одного раза, вызывает паническую атаку. Только вот DRY не об этом. 2 функции с абсолютно разными внутренностями могут нарушить DRY, и в то же время 2 функции с абсолютно одинаковым телом могут никак под него не попадать. И вот как раз "сплошь и рядом встречаются строчки if(isSecondProject)" – это и есть самое настоящее нарушение DRY.
Беда в том, что (как и в случае с SRP) само название DRY не передает сути принципа (а скорее даже запутывает кажущейся простотой). Но тут надо помнить, что это просто "label" для принципа, название и не должно быть исчерпывающим. Тут либо разбираться в том, что стоит за этими принципами, либо вовсе не прикрываться ими для защиты неудачного решения.
AllexIn
Определение «должна быть одна ответственность» прекрасно работает.
Просто всегда надо помнить, что одна ответственность определяет не только задачу, но и уровень на котором ответственность реализуется.
Если у нас есть ферма и у неё одна ответственность — растить животных, и она не знает ничего о существовании куриных яиц то всё ок.
Если у нас есть ферма и у неё одна ответственность — растить животных, но при этом она еще занимается менеджментом куриных яиц, значит что-то пошло не так.
Ферма на своем уровне должна управлять глобальными процессами. А яйцами управление должно происходить опосредственно через другие классы, которые работают на более низком уровне.
Поэтому «одна ответственность + работа только на одном уровне иерархии», и никакий эмпирические оценки не нужны.
submagic
Да. Очень грамотно и по сути. Одна ответственность на одном (соответствующем ей) уровне.
Один выход, входов может быть много — но все на одном общем для них уровне, всего на один ниже уровня выхода.
token
Что я только что прочитал? «принцип единственной ответственности», Angular, React, это уже какая то графомания от кода, написать статью состоящую на 99% из воды, штампов, бреда, отсылок к принципам ООП, цитат из книг, скрама, аджайла. Что вы хотели вообще всем этим сказать? Как написать функцию из четырех строк и не наделать ошибок? О чем это все?
TimsTims
KennyGin
Чем только не занимаются, лишь бы не работать. Специальная книга по рефакторингу — что, простите? Вам больше почитать что ли нечего? А книги по Hello World ещё не написали?
token
+1
что то из серии «как не дописать программу которая нихрена не делает, с использованием машинного обучения, блокчейна, тайпскрипта, аджайла и скрама, применяя все фрэймворки и паттерны вычитанные в книжках, покрыть ее тестами на 300% и попутно написав об этом несколько тонн статей»
submagic
Зря Вы так, нетривиальная задача, если подумать
JustDont
Нетривиальная. Но никому не нужная. Идеальный код за «дорого» и «долго» не интересует вообще никого, даже НАСА (им тоже достаточно рабочего). Более того, без практических метрик (например, полезности для бизнеса) идеальность кода становится сферической в вакууме и может принимать любые формы, в том числе и чудовищные.
axeax
Полезность для бизнеса очень простая. Если говнокод — мы выпустим эту фичу за 14 дней, если код норм — за 7. Другой пример. Если говнокод — новый очень дорогой разработчик будет разбираться в проекте многие месяцы. При наличии же тестов, документации и хорошему отношению к качеству кода в компании — быстрее. Понятно, что идеального кода не существует, и у каждого разработчика понятие идеального кода своё. Но есть общие принципы, которыми плохой код отличается от Не плохого
JustDont
Вы чрезмерно упрощаете. Жизнь чуть сложнее простых фраз а-ля «давайте писать хорошо и фичи будут быстро добавляться». Во-первых, можно писать сколь угодно хорошо, и не запланировать расширения в некоторую сторону, которая потом внезапно станет очень нужна. И наоборот, можно говнокодить 24/7, но сделать расширяемость именно там, где далее нужно.
Во-вторых, скорость разбираемости кода новыми людьми не обязательно в первую очередь определяется именно качеством кода. От качества она безусловно прямо пропорционально зависит, но другие детали могут быть куда важнее. Скажем, говнокод на каком-нибудь реакте может быть куда проще к освоению, чем идеальный код на перле 20-летней давности.
axeax
+
Но полезность ведь уже и не такая сферическая в вакууме становится. Попробую обе мысли более точно описать — хороший код более предсказуем (*и для бизнеса тоже)
Ну а легаси это легаси, оно не может быть плохим или хорошим
JustDont
Да, с такой формулировкой я очень даже согласен.
VladVR Автор
Мне кажется не стоит недооценивать говнокод. Вот я копаю проект, с которого меня местами бомбит. Базовый класс сервис, метод Read, внутри вызывает Write. В другом месте снаружи приходит флаг isShallow и передается в следующий метод, принимающий флаг isDeep, не инвертируя.
Ну это так, по мелочи.
C4ET4uK
Забавно, я думал нет таких разработчиков, которые не знают про эту книгу, и тем более утверждающих, что рефакторинг это что-то настолько тривиальное, что это можно сравнить с написанием Hello World.
andreyverbin
SRP и прочие принципы очень замечательные и правильные, но не имеют четкого определения и потому годиться только для красивых статей и флеймов. Можно сколько угодно уточнять определения или попытаться дать четкую формулировку языком математики. Вот тогда станет ясно, что все сложно, что у принципов нет ни определения ни границы применимости.
VladVR Автор
Принцип Open-Close вполне чёткий. Если при добавлении новой функциональности пришлось поменять существующий код — принцип нарушен. Причем он нарушен был раньше, сам факт изменения существующего кода лишь сигнализирует о нарушении.
andreyverbin
Принцип четкий, спору нет, но есть проблемы. Первая — никаких границ применимости нет. То есть непонятно, нужно ли все 100% кода делать расширяемыми во все стороны или только часть. Если часть, то значит есть некие требования, данные свыше, о том, что это часть должна быть расширяемой. Но раз есть требования к расширяемости, из которых эта расширяемость вытекает явно, то зачем принцип?
на практике всегда противоречит LSP. Усложнение системы в угоду расширяемости противоречит KISS. Попытка спрятать все за абстракциями натыкается на принцип текущих абстракций Джоэла Спольски и т.д.Вторая — расширять предлагается только то, что авторы принципа знают как расширять, а не то, что расширять обычно нужно. Например, мне надо добавить новую функциональность — ускорить обработку запросов в 3 раза. Или синхронный код сделать асинхронным. Или однопоточный, многопоточным. Код менять мне точно нужно будет, значит был нарушен open-closed принцип.
Третья — противоречия с другими, не менее священными принципам. Очень общие сигнатуры вроде
Druu
Отличный пример, который как раз демонстрирует, что цикломатическая сложность — одна из худших оценок для реальной сложности. Очевидно ведь, что при декомпозиции реальная сложность кода не только не упала — она возросла!
Т.к. логика кода осталась той же самой, но стала размазанной по двум разным участкам.
Зачем? Она же нигде не вызывается, лучше ее удалить.
VolCh
Где она возросла? Это совсем не очевидно.
Druu
Декомпозиция при прочих равных всегда увеличивает сложность. Возьмите абзац текста, порежьте на куски, перемешайте случайно, повырезайте случайные куски, сделав их параметрами, дайте случайные идентификаторы в качестве имен и сделайте сноски один на другой, чтобы можно было восстановить порядок. Достаточно очевидно, что восстановить смысл такого текста будет значительно сложнее, чем в оригинальном виде.
Надо четко понимать, что декомпозиция — это всегда трейдоф. Жертвуем простотой, чтобы добиться каких-то других профитов.
amphasis
Позвольте вмешаюсь
Во-первых, идентификаторы выдаются вовсе не случайно, мы всегда стараемся давать классам, методам, переменным осмысленные названия, это делает код легкочитаемым и самодокументированным.
Во-вторых, пример приведенный вами — это любой юридический текст, будь то договор, закон или другой нормативный акт. Представьте если бы в договоре каждое упоминание стороны не было бы заменено простым и понятным «ПОСТАВЩИК», а каждый раз цитировалось бы полностью вместе с представителем и основанием полномочий. Неужели такой договор было бы легче читать? А редактировать?
В-третьих, я соглашусь, что не любой подвергнутый декомпозиции код будет легко прочитать, однако, если это сделано правильно, его будет намного проще переиспользовать или расширить.
Druu
Так код становится легкочитаемым и самодокументированным не из-за того что вы порезали его на куски, декомпозировав, а из-за того, что вы дали читаемое и понятное пояснение этим кускам. Вы могли бы просто пометить эти куски, например, при помощи комментариев и каких-нибудь условных фич иде и получить тот же результат.
Надо же понимать какие именно действия приводят к каким эффектам.
Декомпозиция — всегда ведет к усложнению (ну, окей, быть может есть какие-то специфичные граничные кейзы, в которых она ведет просто к неупрощению).
А вот всякие пояснения и т.п. вещи из разряда "выделить кусок и кратко описать его суть" — упрощают, да. Но это не имеет отношения к декомпозиции. Просто обычно вместе с декомпозицией мы проводим и такого вот рода преобразования. Но они, очевидно, совершенно необязательны — вы можете декомпозировать и с рандомными идшниками. Или вводить пояснения без декомпозиции.
VolCh
Всё же обычно имеется в виду нормальное именование выделяемых програмных сущностей, а не обфускация. Сделав из функции с телом, допустим, 25 строк, три функции по 7-10 строк с именами, описывающими суть эти функций, а начальную превратив в вызов этих трёх функций, мы получаем возможность понять её за несколько секунд, буквально одним взглядом. Комментарии, аналогичные именам функций похожи на выделения, но возможности понять что происходит, где надо вносить изменения с одного взгляда, они не дают. С ними всегда надо читать код полностью, они помогают понять и помогают навигации в уже понятом, но, увы, понять с первого взгляда возможность если и дают, то при строгой уверенности, что эти комментарии всегда есть, что можно настроить редактор так, чтобы код между такими комментариями он сворачивал по умолчанию.
Druu
Декомпозиция — это просто разбиение. С выбором "хороших имен" оно никак не связано.
Если вы имеете ввиду декомпозицию еще с чем-то — следует отдельно уточнять. Но смысл-то в том что упрощение происходит именно за счет этого "еще чего-то", а не за счет самой декомпозиции.
Они дают ровно то же самое, что и выделение отдельных функций. С точки зрения чтения разницы никакой нет и быть не может, потому что на экране одно и то же.
VolCh
Да, декомпозиция — это просто разбиение. Но кроме этого разбиения есть другие ортогональные декомпозиции требования к коду, которые должны выполняться всегда. Одно из них — человекочитаемые имена программных сущностей со строгим соответствие названия и содержания.
На экране не одно и то же. В одном случае у нас три строки описывающие, что функция делает, подряд. А во втором условно те же строки, но не подряд, а с «шумом» в виде 7-9 строк, описывающих как функция это делает.
Rukis
Как раз таки из-за того, что порезали и дали подходящие имена. Вы приводили пример с абзацем текста, так вот, абзац текста можно написать и одним сложным составным предложением. В нем будет куча сложной пунктуации, придется много раз повторять одинаковые длинные конструкции, чтобы избавится от неоднозначности и понять такой текст будет сложно. Сложно будет и что то в него добавить не поломав логики всего высказывания.
Собственно человек только и делает, что запаковывает всё в абстракции для того, чтобы упростить понимание. Мы создаем различные объекты реального мира, конструкции, механизмы и даем этому всему лаконичные названия, даем названия действиям с этими объектами и тд.
Druu
Ну то есть не из-за декомпозиции. О чем я речь и веду.
Декомпозиция восприятие текста усложнила, но пояснения — упростили.
Но это все не имеет отношения к декомпозиции. Декомпозиция — это просто порезать на куски, все. Именования при декомпозиции вообще не предполагается.
Rukis
разве?
Далее
Еще как имеет. Мы говорим «открыть дверь» и не приводим определений для слов «открыть» и «дверь». Сами определения вырезаны из выражения и заменены на абстрактные обозначения.
Если вы решили употреблять этот термин в таком значении, значит намерено делаете его бесполезным. Осталось понять, вы это делаете только ради пустого спора или действительно, услышав, что кто-то намерен декомпозировать слишком большую функцию ужаснетесь: «о нет, они хотят порезать код на неименованные куски!».
Druu
Ну так еще раз — порежьте что-то, перемешайте, и не давайте нормального нейминга кускам. Стало проще? Не стало.
Какое же? Я взял, порезал на куски — вот декомпозиция. Декомпозиция даже не предполагает что кускам вообще даются какие-либо имена.
Это не я употребляю, это стандартное значение данного термина.
Так ведь именно так и происходит! Человек режет код невнятным образом, а потом говорит о том, что "ну я же декомпозировал, а декомпозиция — это хорошо!". Приводит какие-то абстрактные соображения, вроде цикломатической сложности или того, что "ни одной ф-и длиннее пяти строк!". Ну очевидно ведь, что цикломатическая сложность или длина ф-й с хорошими неймингами никак не связана? Значит, и показателем быть не может, разве нет? Но, между тем, эти показатели сплошь и рядом используются. Значит, люди не понимают, как оно устроено.
Вот я, как бы, за то, чтобы понимать, что именно хорошо, а что — плохо.
Резать код (что понимают чуть менее чем все под декомпозицией) — это плохо.
Давать краткие пояснения в виде неймингов или при помощи какого-то другого способа (что, обычно, под декомпозицией никто не подразумевает) — хорошо.
Akela_wolf
Это заявление уровня «Ну оно же работает». Декомпозиция — это разделение кода не на произвольные куски, лишь бы только порубить, а разбиение на логические части. Это не «порезать и перемешать», это скорее можно сравнить с переработкой текста. Берем текст, написанный сплошняком, без знаков препинания, абзацев, переносов строк и т.д. И начинаем разбивать на предложения, абзацы, главы и части, логически связанные между собой. Вот это декомпозиция, а не просто произвольное «рубление и перемешивание».
Rukis
Возможно вам не повезло с окружением. Я вообще не встречал подобного, но лучше обратиться к Макконнелуу и Фаулеру, как в их книгах применяется этот термин? И правил «ни одной ф-и длиннее пяти строк!» тоже нигде не припомню, обычно правила звучат так: «обращать внимание на функции длиннее n строк, возможно они нуждаются в рефакторинге». Иногда такие высказывания даже подтверждаются статистикой, кажется тот же Макконнелл приводил данные по корреляции длины строк метода и негативными факторами, но не суть.
У декомпозиции есть цель, если цель «не допускать функции длиннее 5 строк», то проблема именно в цели. Как правило целью декомпозиции ставят что то адекватное, например: упростить понимание кода, избавиться от вредного дублирования и тп. Цель появляется не из неоткуда, разработчик сталкивается с проблемой или руководствуясь своим опытом видит, что она возникнет. Итого, наиболее типичный случай выглядит примерно так: разработчик обнаруживает проблему, для ее решения использует декомпозицию. Создание абстракций, нейминг — вечный спутник этого процесса. Под декомпозицией в программировании (да и не только) собственно и понимают вынос части чего то в какую то отдельную абстракцию.
Проблема неуместности и неверного применения инструмента в конкретных случаях — отдельная тема.
Druu
Да вот же автор статьи цикломатическую сложность считает, далеко не надо ходить.
OlegGelezcov
Основательно проработал принципы SOLID
Я на днях получил оффер на .NET разработчика. На собеседовании меня 2 часа гоняли по базе, как устроен GC, генерейшны, как вызываются финализаторы, почему lock(this) {} плохо и т.д.
В конце они говорят, ну ок, а у тебя есть вопросы к нам?
Я говорю — вы меня только по внутренностям гоняли, почему не спрашивали по приниципам SOLID совсем?
Они отвечают — а мы никого не спрашиваем по ним, потому что они легко заучиваются.
))
saaivs
Обратная сторона SRP — это SPoF :)
Например, когда речь идёт о надёжности, то более практично использовать избыточность(этому нас учит и авиация и биология и много чего ещё).
Ни один из принципов не имеет никакой ценности сам по себе, в отрыве от контекста. Это основное правило, которое нужно знать и понимать. Остальное — дело наживное.
VladVR Автор
Я бы сказал, больше похоже, что SPoF — обратная сторона принципа DRY. Именно он призывает во чтобы то ни стало избавляться от дублирования.
SRP скорее наоборот. К примеру у нас была ситуация, где для разных пользователей была чуть разная логика проверки доступа к ресурсу. С точки зрения DRY — надо избежать дублирования. C точки зрения SRP — это две разные ответственности и им не стоит жить в одном методе.
Basim108
Спасибо за статью, полностью согласен с автором и с принципом SRP. Однако размышляя о SRP и ища в коде хорошие и наглядные примеры когда SRP помогает а когда усложняет, я наткнулся на класс List и у него полно методов и полный набор CRUD и кучу перегрузок по каждой букве из CRUD.
И вот вопрос, нужно что делать отдельный класс структура данных и отдельные классы реализациий каждого метода?
Это же будет дико не удобно:
OlegGelezcov
класс List с методами CRUD в нем не нарушают SRP, ведь ответственность у всех методов одна — сам список
А вот если в класс List добавить метод, который вычисляет, среднее время выполнения операций с списком, то это нарушение SRP. Наверно стоило бы создать какой-нибудь ListDiagnostics — его ответственностью будет статистика
maslyaev
VolCh
Откуда удесятерение? Максимум удвоение, если каждую строку начального кода обернуть в отдельную функцию.
maslyaev
Но системность от этого всё равно не появится. Будут только куча отдельных обёрнутых в функции строчек.
VolCh
Системность как раз появляется при грамотной декомпозиции. Появление слоёв данных, представления, управления, инфраструктуры и т. п. — это следствие декомпозиции.
NYMEZIDE
STP в моем понимании: класс существует и должен быть создан только для одной задачи.
Не должно быть супер-классов, которые умеют все: и в БД ходить, и бизнес-сущности менять, и запросы обрабатывать. Это будет 3 класса: доменный агрегат, репозиторий, QueryHandler. Да, они будут взаимодействовать между собой, так или иначе.
SRP распространяется и на компоненты, и на микросервисы.
Akela_wolf
Лично я считаю, что SRP — это не про объем ответственности никоим образом. Это именно — у каждой единицы кода (модуль, класс, метод, функция) должна быть единственная ответственность. То есть когда мы делаем краткое описание оно не должно быть сложносочиненным. Например: «Модуль управляет космической станцией» — это нормально с точки зрения SRP. Вообще говоря, программа в целом решает какую-то задачу и, пока она сосредоточена на решении этой задачи, не пытаясь стать Jack-of-all-trades она тоже соответствует принципу SRP. Состоит эта программа из единственного огромного метода main() или разделена на 100500 трехстрочных функций — это детали её внутреннего устройства.
Но в силу большого объема мы можем решить что модуль целесообразно разделить на подсистемы. Делаем мы это через делегирование ответственности нижележащим модулям. То есть задачу управления космической станцией разбиваем на подзадачи, например: «Поддержание ориентации в пространстве», «Корректировка орбиты», «Радиосвязь с ЦУП», «Отображение данных на приборах» и т.д., а в задаче верхнего уровня остается только управление модулями уровнем ниже. То есть, при выполнении такой декомпозиции, мы продолжаем следовать принципу SRP:
а) Модуль для которого производится декомпозиция остается с единственной ответственностью — управление нижележащими модулями.
б) Каждый из нижележащих модулей также соответствует SRP на своем уровне. Допустим модуль «Управление двигателями системы ориентации и сервоприводами солнечных батарей» очевидным образом обладает двумя ответственностями т.е. нарушает SRP.
в) При такой декомпозиции у нас могут образовываться shared модули, которые используются несколькими подсистемами, например: «Модуль баллистических вычислений», которые также соответствуют SRP.
В примере из статьи про отправку отчета: функция «отправки отчета по почте» вполне отвечает SRP. Но как только она превращается в функция «отправки отчета по почте или печати на принтере» — она перестает соответствовать SRP. Изменив функцию на «обработка запроса построения отчета» и реализовав как-то так:
мы снова в рамках SRP. Это нарушение OCP, но такая функция вполне укладывается в KISS и YAGNI. Продолжая усложнять систему, мы будем усложнять эту функцию пока не захотим провести декомпозицию, то есть делегировать ответственность другим функциям (и при декомпозиции снова будем следовать SRP).
Также SRP это про то что «одна задача должна решаться одним модулем», это сильно коррелирует с DRY. Иначе получается что мы либо размазываем одну ответственность по всем модулям программы, либо (если есть выделенный модуль) — залезаем в его область ответственности.
Например, у нас есть модуль Mailer для отправки почты. Если в handleReportRequest для отправки отчета мы используем его — все ОК. Если же мы сами начали там реализовывать взаимодействие с SMTP-сервером — этот тот самый случай залезания в чужую область ответственности и нарушение DRY.
Другой возможный пример: когда у нас каждый модуль начинает проверять права доступа (то есть нет отдельного модуля, который отвечает за контроль доступа). Таким образом, ответственность «обеспечить разграничение прав доступа» оказывается размазана по всей программе. Опять же диагностировать эту ситуацию можно через отслеживание дублирования кода (DRY). Решением этой проблемы является выделение shared модуля, берущего данную ответственность на себя.
toxicdream
Какие-то сферические советы программиста в вакууме.
По хорошему сначала собираются требования к решению задачи.
Потом — требования к коду.
Если это одноразовый скрипт — на фига вот это все.
И вообще, к чему это может привести можно посмотреть на шуточных «обучающих» примерах как этот.