
Привет, Хабр!
Напоминаем, что вслед за книгой о Kafka мы выпустили не менее интересный труд о библиотеке Kafka Streams API.

Пока сообщество только постигает границы возможностей этого мощного инструмента. Так, недавно вышла статья, с переводом которой мы хотим вас познакомить. На собственном опыте автор рассказывает, как сделать из Kafka Streams распределенное хранилище данных. Приятного чтения!
Библиотека Apache Kafka Streams по всему миру используется в энтерпрайзе для распределенной потоковой обработки поверх Apache Kafka. Один из недооцененных аспектов этого фреймворка заключается в том, что он позволяет хранить локальное состояние, производимое на основе потоковой обработки.
В этой статье я расскажу, как в нашей компании удалось выгодно задействовать эту возможность при разработке продукта по безопасности облачных приложений. При помощи Kafka Streams мы создали микросервисы с разделяемым состоянием, каждый из которых служит нам отказоустойчивым и высокодоступным источником достоверной информации о состоянии объектов в системе. Для нас это шаг вперед как в отношении надежности, так и в удобстве поддержки.
Если вас интересует альтернативный подход, позволяющий использовать единую центральную базу данных для поддержки формального состояния ваших объектов – почитайте, будет интересно…
Почему мы сочли, что пришло время менять наши подходы к работе с разделяемым состоянием
Нам требовалось поддерживать состояние различных объектов, опираясь на отчеты агентов (например: подвергался ли сайт атаке)? До перехода на Kafka Streams мы зачастую полагались для управления состоянием на единую центральную базу данных (+ сервисный API). У такого подхода есть свои недостатки: в датаинтенсивных ситуациях поддержка согласованности и синхронизации превращается в настоящий вызов. База данных может стать узким местом, либо оказываться в состоянии гонки и страдать от непредсказуемости.
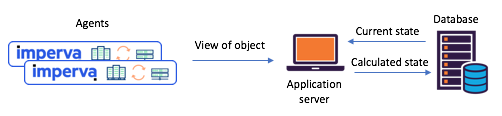
Иллюстрация 1: типичный сценарий с разделением состояния, встречавшийся на до перехода на
Kafka и Kafka Streams: агенты сообщают свои представления через API, обновленное состояние рассчитывается через центральную базу данных
Знакомьтесь с Kafka Streams – теперь стало просто создавать микросервисы с разделяемым состоянием
Примерно год назад мы решили хорошенько пересмотреть наши сценарии работы с разделяемым состоянием, чтобы разобраться с такими проблемами. Сразу же решили попробовать Kafka Streams – известно, насколько она масштабируемая, высокодоступная и отказоустойчивая, какой богатый у нее потоковый функционал (преобразования, в том числе, с сохранением состояния). Как раз то, что нам требовалось, не говоря уже о том, насколько зрелая и надежная система обмена сообщениями сложилась в Kafka.
Каждый из созданных нами микросервисов с сохранением состояния строился на основе инстанса Kafka Streams с довольно простой топологией. Он состоял из 1) источника 2) процессора с постоянным хранилищем ключей и значений 3) стока:

Иллюстрация 2: задаваемая по умолчанию топология наших потоковых инстансов для микросервисов с сохранением состояния. Обратите внимание: здесь также есть хранилище, в котором находятся метаданные о планировании.
При таком новом подходе агенты составляют сообщения, подаваемые в исходный топик, а потребители – скажем, сервис почтовых уведомлений – принимают вычисленное разделяемое состояние через сток (выходной топик).
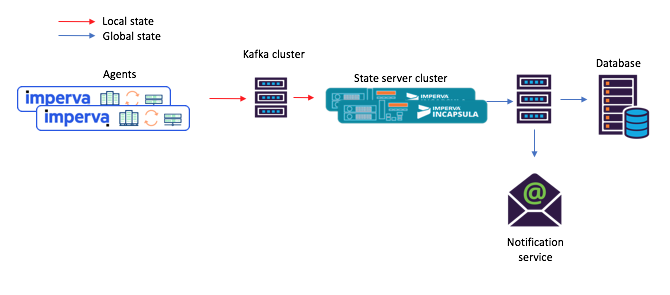
Иллюстрация 3: новый пример потока задач для сценария с разделяемыми микросервисами: 1) агент порождает сообщение, поступающее в исходный топик Kafka; 2) микросервис с разделяемым состоянием (использующий Kafka Streams) обрабатывает его и записывает вычисленное состояние в конечный топик Kafka; после чего 3) потребители принимают новое состояние
Эй, а это встроенное хранилище ключей и значений в самом деле очень полезно!
Как упоминалось выше, наша топология с разделяемым состоянием содержит хранилище ключей и значений. Мы нашли несколько вариантов его использования, и два из них описаны ниже.
Вариант #1: использование хранилища ключей и значений при вычислениях
Наше первое хранилище ключей и значений содержало вспомогательные данные, которые требовались нам для вычислений. Например, в некоторых случаях разделяемое состояние определялось по принципу «большинства голосов». В хранилище можно было держать все последние отчеты агентов о состоянии некоторого объекта. Затем, получая новый отчет от того или иного агента, мы могли сохранить его, извлечь из хранилища отчеты всех остальных агентов о состоянии того же самого объекта и повторить вычисление.
Ниже на иллюстрации 4 показано, как мы открывали доступ к хранилищу ключей и значений обрабатывающему методу процессора, так что затем можно было обработать новое сообщение.
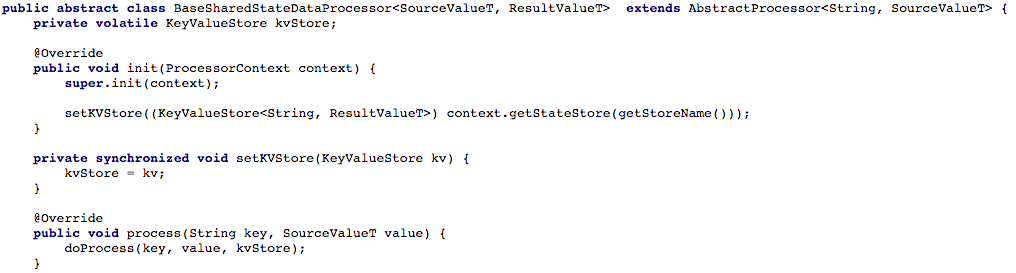
Иллюстрация 4: открываем доступ к хранилищу ключей и значений для обрабатывающего метода процессора (после этого в каждом сценарии, работающем с разделяемым состоянием, необходимо реализовать метод
Вариант #2: создание CRUD API поверх Kafka Streams
Наладив наш базовый поток задач, мы стали пробовать написать RESTful CRUD API для наших микросервисов с разделяемым состоянием. Мы хотели, чтобы можно было извлекать состояние некоторых или всех объектов, а также устанавливать или удалять состояние объекта (это полезно при поддержке серверной части).
Для поддержки всех API Get State, всякий раз, когда нам требовалось заново вычислять состояние при обработке, мы надолго укладывали его во встроенное хранилище ключей и значений. В таком случае становится достаточно просто реализовать такой API при помощи единственного экземпляра Kafka Streams, как показано в нижеприведенном листинге:
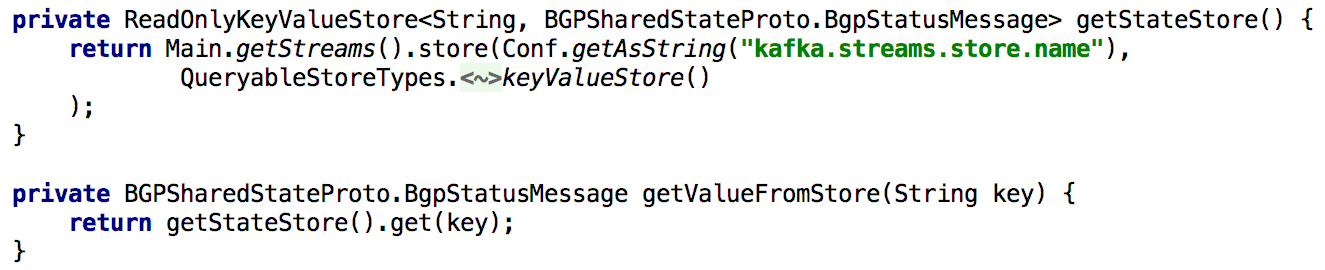
Иллюстрация 5: использование встроенного хранилища ключей и значений для получения предвычисленного состояния объекта
Обновление состояния объекта через API также несложно реализовать. В принципе, для этого нужно только создать продьюсер Kafka, а с его помощью сделать запись, в которой заключено новое состояние. Так гарантируется, что все сообщения, сгенерированные через API, будут обрабатываться точно так же, как и поступающие от других продьюсеров (напр. агентов).

Иллюстрация 6: задать состояние объекта можно при помощи продьюсера Kafka
Небольшое осложнение: у Kafka множество партиций
Далее мы хотели распределить нагрузку, связанную с обработкой, и улучшить доступность, предоставив на каждый сценарий кластер микросервисов с разделяемым состоянием. Настройка далась нам проще простого: после того, как мы сконфигурировали все инстансы так, чтобы они работали с одним и тем же ID приложения (и с теми же серверами начальной загрузки), практически все остальное делалось автоматически. Мы также задали, что каждый исходный топик будет состоять из нескольких партиций, чтобы каждому инстансу можно было присвоить подмножество таких партиций.
Также упомяну, что здесь в порядке вещей делать резервную копию хранилища состояний, чтобы, например, в случае восстановления после отказа переносить эту копию на другой инстанс. На каждое хранилище состояний в Kafka Streams создается реплицируемый топик с журналом изменений (в котором отслеживаются локальные обновления). Таким образом, Kafka постоянно подстраховывает хранилище состояний. Поэтому в случае отказа того или иного инстанса Kafka Streams хранилище состояний может быть быстро восстановлено на другом инстансе, куда перейдут соответствующие партиции. Наш тесты показали, что это делается за считанные секунды даже если в хранилище находятся миллионы записей.
Переходя от одного микросервиса с разделяемым состоянием к кластеру микросервисов, становится не столь тривиально реализовать Get State API. В новой ситуации в хранилище состояний каждого микросервиса содержится только часть общей картины (те объекты, чьи ключи отображались на конкретную партицию). Приходилось определять, на каком инстансе содержалось состояние нужного нам объекта, и мы делали это на основании метаданных потоков, как показано ниже:
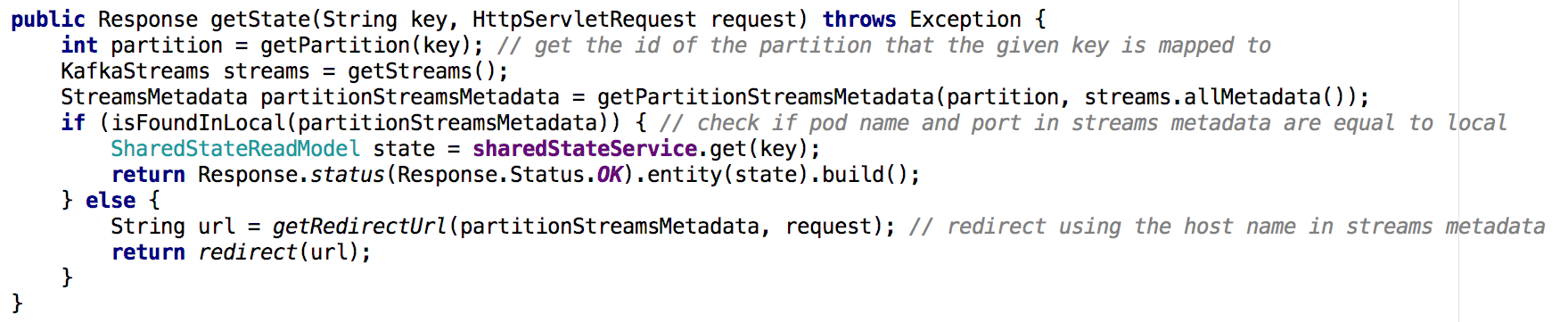
Иллюстрация 7: при помощи метаданных потоков мы определяем, с какого инстанса запрашивать состояние нужного объекта; подобный подход применялся с GET ALL API
Основные выводы
Хранилища состояний в Kafka Streams де-факто могут служить распределенной базой данных,
Благодаря этим и другим достоинствам Kafka Streams отлично подходит для поддержки глобального состояния в такой распределенной системе как наша. Kafka Streams показала себя весьма надежной в продакшене (с момента ее развертывания мы практически не теряли сообщений), и мы уверены, что этим ее возможности не ограничиваются!
Напоминаем, что вслед за книгой о Kafka мы выпустили не менее интересный труд о библиотеке Kafka Streams API.
Пока сообщество только постигает границы возможностей этого мощного инструмента. Так, недавно вышла статья, с переводом которой мы хотим вас познакомить. На собственном опыте автор рассказывает, как сделать из Kafka Streams распределенное хранилище данных. Приятного чтения!
Библиотека Apache Kafka Streams по всему миру используется в энтерпрайзе для распределенной потоковой обработки поверх Apache Kafka. Один из недооцененных аспектов этого фреймворка заключается в том, что он позволяет хранить локальное состояние, производимое на основе потоковой обработки.
В этой статье я расскажу, как в нашей компании удалось выгодно задействовать эту возможность при разработке продукта по безопасности облачных приложений. При помощи Kafka Streams мы создали микросервисы с разделяемым состоянием, каждый из которых служит нам отказоустойчивым и высокодоступным источником достоверной информации о состоянии объектов в системе. Для нас это шаг вперед как в отношении надежности, так и в удобстве поддержки.
Если вас интересует альтернативный подход, позволяющий использовать единую центральную базу данных для поддержки формального состояния ваших объектов – почитайте, будет интересно…
Почему мы сочли, что пришло время менять наши подходы к работе с разделяемым состоянием
Нам требовалось поддерживать состояние различных объектов, опираясь на отчеты агентов (например: подвергался ли сайт атаке)? До перехода на Kafka Streams мы зачастую полагались для управления состоянием на единую центральную базу данных (+ сервисный API). У такого подхода есть свои недостатки: в датаинтенсивных ситуациях поддержка согласованности и синхронизации превращается в настоящий вызов. База данных может стать узким местом, либо оказываться в состоянии гонки и страдать от непредсказуемости.
Иллюстрация 1: типичный сценарий с разделением состояния, встречавшийся на до перехода на
Kafka и Kafka Streams: агенты сообщают свои представления через API, обновленное состояние рассчитывается через центральную базу данных
Знакомьтесь с Kafka Streams – теперь стало просто создавать микросервисы с разделяемым состоянием
Примерно год назад мы решили хорошенько пересмотреть наши сценарии работы с разделяемым состоянием, чтобы разобраться с такими проблемами. Сразу же решили попробовать Kafka Streams – известно, насколько она масштабируемая, высокодоступная и отказоустойчивая, какой богатый у нее потоковый функционал (преобразования, в том числе, с сохранением состояния). Как раз то, что нам требовалось, не говоря уже о том, насколько зрелая и надежная система обмена сообщениями сложилась в Kafka.
Каждый из созданных нами микросервисов с сохранением состояния строился на основе инстанса Kafka Streams с довольно простой топологией. Он состоял из 1) источника 2) процессора с постоянным хранилищем ключей и значений 3) стока:
Иллюстрация 2: задаваемая по умолчанию топология наших потоковых инстансов для микросервисов с сохранением состояния. Обратите внимание: здесь также есть хранилище, в котором находятся метаданные о планировании.
При таком новом подходе агенты составляют сообщения, подаваемые в исходный топик, а потребители – скажем, сервис почтовых уведомлений – принимают вычисленное разделяемое состояние через сток (выходной топик).
Иллюстрация 3: новый пример потока задач для сценария с разделяемыми микросервисами: 1) агент порождает сообщение, поступающее в исходный топик Kafka; 2) микросервис с разделяемым состоянием (использующий Kafka Streams) обрабатывает его и записывает вычисленное состояние в конечный топик Kafka; после чего 3) потребители принимают новое состояние
Эй, а это встроенное хранилище ключей и значений в самом деле очень полезно!
Как упоминалось выше, наша топология с разделяемым состоянием содержит хранилище ключей и значений. Мы нашли несколько вариантов его использования, и два из них описаны ниже.
Вариант #1: использование хранилища ключей и значений при вычислениях
Наше первое хранилище ключей и значений содержало вспомогательные данные, которые требовались нам для вычислений. Например, в некоторых случаях разделяемое состояние определялось по принципу «большинства голосов». В хранилище можно было держать все последние отчеты агентов о состоянии некоторого объекта. Затем, получая новый отчет от того или иного агента, мы могли сохранить его, извлечь из хранилища отчеты всех остальных агентов о состоянии того же самого объекта и повторить вычисление.
Ниже на иллюстрации 4 показано, как мы открывали доступ к хранилищу ключей и значений обрабатывающему методу процессора, так что затем можно было обработать новое сообщение.
Иллюстрация 4: открываем доступ к хранилищу ключей и значений для обрабатывающего метода процессора (после этого в каждом сценарии, работающем с разделяемым состоянием, необходимо реализовать метод
doProcess)Вариант #2: создание CRUD API поверх Kafka Streams
Наладив наш базовый поток задач, мы стали пробовать написать RESTful CRUD API для наших микросервисов с разделяемым состоянием. Мы хотели, чтобы можно было извлекать состояние некоторых или всех объектов, а также устанавливать или удалять состояние объекта (это полезно при поддержке серверной части).
Для поддержки всех API Get State, всякий раз, когда нам требовалось заново вычислять состояние при обработке, мы надолго укладывали его во встроенное хранилище ключей и значений. В таком случае становится достаточно просто реализовать такой API при помощи единственного экземпляра Kafka Streams, как показано в нижеприведенном листинге:
Иллюстрация 5: использование встроенного хранилища ключей и значений для получения предвычисленного состояния объекта
Обновление состояния объекта через API также несложно реализовать. В принципе, для этого нужно только создать продьюсер Kafka, а с его помощью сделать запись, в которой заключено новое состояние. Так гарантируется, что все сообщения, сгенерированные через API, будут обрабатываться точно так же, как и поступающие от других продьюсеров (напр. агентов).
Иллюстрация 6: задать состояние объекта можно при помощи продьюсера Kafka
Небольшое осложнение: у Kafka множество партиций
Далее мы хотели распределить нагрузку, связанную с обработкой, и улучшить доступность, предоставив на каждый сценарий кластер микросервисов с разделяемым состоянием. Настройка далась нам проще простого: после того, как мы сконфигурировали все инстансы так, чтобы они работали с одним и тем же ID приложения (и с теми же серверами начальной загрузки), практически все остальное делалось автоматически. Мы также задали, что каждый исходный топик будет состоять из нескольких партиций, чтобы каждому инстансу можно было присвоить подмножество таких партиций.
Также упомяну, что здесь в порядке вещей делать резервную копию хранилища состояний, чтобы, например, в случае восстановления после отказа переносить эту копию на другой инстанс. На каждое хранилище состояний в Kafka Streams создается реплицируемый топик с журналом изменений (в котором отслеживаются локальные обновления). Таким образом, Kafka постоянно подстраховывает хранилище состояний. Поэтому в случае отказа того или иного инстанса Kafka Streams хранилище состояний может быть быстро восстановлено на другом инстансе, куда перейдут соответствующие партиции. Наш тесты показали, что это делается за считанные секунды даже если в хранилище находятся миллионы записей.
Переходя от одного микросервиса с разделяемым состоянием к кластеру микросервисов, становится не столь тривиально реализовать Get State API. В новой ситуации в хранилище состояний каждого микросервиса содержится только часть общей картины (те объекты, чьи ключи отображались на конкретную партицию). Приходилось определять, на каком инстансе содержалось состояние нужного нам объекта, и мы делали это на основании метаданных потоков, как показано ниже:
Иллюстрация 7: при помощи метаданных потоков мы определяем, с какого инстанса запрашивать состояние нужного объекта; подобный подход применялся с GET ALL API
Основные выводы
Хранилища состояний в Kafka Streams де-факто могут служить распределенной базой данных,
- постоянно реплицируемой в Kafka
- Поверх такой системы легко выстраивается CRUD API
- Обработка множественных партиций получается немного сложнее
- Также возможно добавить одно или несколько хранилищ состояний в потоковую топологию для хранения вспомогательных данных. Такой вариант может использоваться для:
- Долговременного хранения данных, нужных для вычислений при потоковой обработке
- Долговременного хранения данных, которые могут быть полезны при следующей инициализации потокового инстанса
- многого другого…
Благодаря этим и другим достоинствам Kafka Streams отлично подходит для поддержки глобального состояния в такой распределенной системе как наша. Kafka Streams показала себя весьма надежной в продакшене (с момента ее развертывания мы практически не теряли сообщений), и мы уверены, что этим ее возможности не ограничиваются!