

tl;dr:
- Машинное обучение ищет закономерности в данных. Но искусственный интеллект может быть «предвзят» — то есть, находить неверные паттерны. К примеру, система обнаружения рака кожи по фотографии может обращать особое внимание на снимки, сделанные во врачебном кабинете. Машинное обучение не умеет понимать: его алгоритмы лишь выявляют закономерности в числах, и если данные не репрезентативны, таким будет и результат их обработки. А отлавливать такие баги может быть непросто из-за самой механики машинного обучения.
- Самая очевидная и пугающая проблемная область — это человеческое разнообразие. Есть множество причин, почему данные о людях могут терять объективность еще на этапе сбора. Но не стоит думать, что эта проблема касается только людей: точно такие же сложности возникают при попытке обнаружить потоп на складе или вышедшую из строя газовую турбину. Одни системы могут иметь предубеждения насчет цвета кожи, другие будут предвзято относиться к датчикам Siemens.
- Такие проблемы не новы для машинного обучения, да и свойственны далеко не только ему. Неверные предположения делаются в любых сложных структурах, а понять, почему было принято то или иное решение, всегда непросто. Бороться с этим нужно комплексно: создавать инструменты и процессы для проверки — и образовывать пользователей, чтобы они не слепо следовали рекомендациям ИИ. Машинное обучение действительно делает некоторые вещи намного лучше нас, — но собаки, например, намного эффективнее людей в обнаружении наркотиков, что вовсе не повод привлекать их в качестве свидетелей и выносить приговоры на основании их показаний. А собаки, к слову, намного умнее любой системы машинного обучения.
Машинное обучение сегодня — один из самых важных фундаментальных технологических трендов. Это один из основных способов, которыми технология будет менять окружающий мир в следующее десятилетие. Некоторые аспекты этих изменений вызывают беспокойство. Например, потенциальное влияние машинного обучения на рынок труда, или его использование для неэтичных целей (допустим, авторитарными режимами). Есть еще одна проблема, которой и посвящен этот пост: предвзятость искусственного интеллекта.
Это непростая история.

ИИ от Google умеет находить котиков. Эта новость из 2012-го года была тогда чем-то особенным.
Что такое «предвзятость ИИ»?
«Сырые данные» — это одновременно и оксюморон, и плохая идея; данные нужно хорошо и заботливо готовить. —Джеффри Бокер
Где-то до 2013 года, чтобы сделать систему, которая, скажем, распознает котов на фотографиях, вам надо было описывать логические шаги. Как найти на изображении углы, распознать глаза, проанализировать текстуры на наличие меха, посчитать лапы, и так далее. Затем собрать все компоненты — и обнаружить, что это все толком не работает. Примерно как механическая лошадь — теоретически ее можно сделать, но на практике она слишком сложна для описания. На выходе у вас сотни (или даже тысячи) рукописных правил. И ни одной работающей модели.
С появлением машинного обучения мы перестали использовать «ручные» правила по распознаванию того или иного объекта. Вместо этого мы берем тысячу образцов «того», Х, тысячу образцов «иного», Y, и заставляем компьютер построить модель на основе их статистического анализа. Затем мы даем этой модели некоторый пример данных, и она с некой точностью определяет, подходит ли он к одному из наборов. Машинное обучение генерирует модель на основе данных, а не с помощью человека, который ее пишет. Результаты впечатляют, особенно в области распознавания изображений и паттернов, и именно поэтому вся тех индустрия сейчас переходит на машинное обучение (ML).
Но не все так просто. В реальном мире ваши тысячи примеров X или Y также содержат А, B, J, L, O, R и даже L. Они могут быть неравномерно распределены, и некоторые из них могут встречаться настолько часто, что система обратит на них больше внимания, чем на объекты, которые вас интересуют.
Что это значит на практике? Мой любимый пример — это когда системы распознавания изображений смотрят на травянистый холм и говорят: «овца». Понятно, почему: большая часть фотографий-примеров «овцы» сделана на лугах, где они живут, и на этих изображениях трава занимает намного больше места, чем маленькие беленькие пушистики, и именно траву системы считают самой важной.
Есть примеры и посерьёзнее. Из недавнего — один проект по обнаружению рака кожи на фотографиях. Оказалось, что дерматологи часто фотографируют линейку вместе с проявлениями рака кожи, чтобы зафиксировать размер образований. На примерах фотографий здоровой кожи линеек нет. Для системы ИИ такие линейки (точнее, пиксели, которые нами определяются как «линейка») стали одним из различий между наборами примеров, и иногда более важными, чем небольшая сыпь на коже. Так система, созданная для опознавания рака кожи, иногда вместо него опознавала линейки.
Ключевой момент здесь то, что у системы нет семантического понимания того, на что она смотрит. Мы смотрим на набор пикселей и видим в них овцу, кожу или линейки, а система — только числовую строку. Она не видит трехмерное пространство, не видит ни объектов, ни текстур, ни овец. Она просто видит паттерны в данных.
Сложность диагностики таких проблем в том, что нейронная сеть (модель, сгенерированная вашей системой машинного обучения) состоит из тысяч сотен тысяч узлов. Нет простого способа заглянуть в модель и увидеть, как она принимает решение. Наличие такого способа означало бы, что процесс достаточно прост, чтобы описать все правила вручную, без использования машинного обучения. Люди беспокоятся, что машинное обучение стало неким «черным ящиком». (Я объясню чуть позже, почему это сравнение все-таки перебор.)
Это, в общих словах, и есть проблема предвзятости искусственного интеллекта или машинного обучения: система для нахождения паттернов в данных может находить неверные паттерны, а вы можете этого не заметить. Это фундаментальная характеристика технологии, и это очевидно всем, кто работает с ней в научных кругах и в больших технологических компаниях. Но её последствия сложны, и наши возможные решения этих последствий — тоже.
Поговорим сначала о последствиях.

ИИ может неявно для нас делать выбор в пользу тех или иных категорий людей, основываясь на большом количестве незаметных сигналов
Сценарии предвзятости ИИ
Самое очевидное и пугающее, что эта проблема может проявиться, когда речь идет о человеческом разнообразии. Недавно прошел слух, что Амазон попытался построить систему машинного обучения для первичного скрининга кандидатов на работу. Так как среди работников Амазона больше мужчин, примеры «удачного найма» тоже чаще мужского пола, и в подборке резюме, предложенной системой, было больше мужчин. Амазон заметил это и не стал выпускать систему в продакшн.
Самое важное в этом примере то, что система, по слухам, отдавала предпочтение кандидатам мужского пола, несмотря на то, что пол не был указан в резюме. Система видела другие паттерны в примерах «удачного найма»: например, женщины могут использовать особенные слова для описания достижений, или иметь особенные хобби. Конечно, система не знала ни что такое «хоккей», ни кто такие «люди», ни что такое «успех», — она просто проводила статистический анализ текста. Но закономерности, которые она видела, остались бы скорее всего не замеченными человеком, а некоторые из них (например, то, что люди разного пола по-разному описывают успех) нам, вероятно, сложно было бы увидеть, даже смотря на них.
Дальше — хуже. Система машинного обучения, которая очень хорошо находит рак на бледной коже, может хуже работать с темной кожей, или наоборот. Не обязательно из-за предвзятости, а потому что вам, вероятно, нужно построить для другого цвета кожи отдельную модель, выбрав другие характеристики. Системы машинного обучения не взаимозаменяемы даже в такой узкой сфере, как распознавание изображений. Вам нужно настроить систему, иногда просто путем проб и ошибок, чтобы хорошо подмечать особенности в интересующих вас данных, пока вы не достигнете желаемой точности. Но вы можете не заметить, что система в 98% случаев точна при работе с одной группой и лишь в 91% (пусть это и точнее, чем анализ, проведенный человеком) — с другой.
Я пока использовал в основном примеры, касающиеся людей и их характеристик. На этой теме в основном и фокусируется дискуссия вокруг этой проблемы. Но важно понимать, что предвзятость по отношению к людям — лишь часть проблемы. Мы будем использовать машинное обучение для множества вещей, и ошибка выборки будет релевантна для всех них. С другой стороны, если вы работаете с людьми, предвзятость данных может быть связана не с ними.
Чтобы понять это, вернемся к примеру с раком кожи и рассмотрим три гипотетических возможности поломки системы.
- Неоднородное распределение людей: несбалансированное количество фотографий кожи разных тонов, что ведет к ложноположительным или ложноотрицательным результатам, связанным с пигментацией.
- Данные, на которых тренируется система, содержат часто встречающуюся и неоднородно распределенную характеристику, не связанную с людьми и не имеющую диагностической ценности: линейку на фотографиях проявлений рака кожи или траву на фотографиях овец. В этом случае результат будет отличаться, если на изображении система найдет пиксели чего-то, что человеческий глаз определит как «линейку».
- Данные содержат стороннюю характеристику, которую человек не может увидеть, даже если будет ее искать.
Что это значит? Мы априори знаем, что данные могут по-разному представлять разные группы людей, и как минимум можем запланировать поиск подобных исключений. Иными словами, есть куча социальных причин предполагать, что данные о группах людей уже содержат некоторое предубеждение. Если мы посмотрим на фото с линейкой, мы увидим эту линейку — мы просто игнорировали ее раньше, зная, что она не имеет значения, и забыв, что системе ничего не известно.
Но что, если все ваши фотографии нездоровой кожи сделаны в офисе, где используются лампы накаливания, а здоровой — при флуоресцентном свете? Что, если, закончив снимать здоровую кожу, перед съемкой нездоровой вы обновили операционную систему на телефоне, а Эпл или Гугл немного изменил алгоритм подавления шума? Человеку этого не заметить, сколько бы он ни искал такие особенности. А вотт система машинного использования сразу же увидит и использует это. Она ничего не знает.
Пока мы говорили о ложных корреляциях, но может случиться и так, что и данные точны, и результаты правильны, но вы не хотите их использовать по этическим, юридическим или управленческим причинам. В некоторых юрисдикциях, например, нельзя предоставлять женщинам скидку на страховку, несмотря на то, что женщины, возможно, безопаснее водят машину. Мы можем легко представить себе систему, которая при анализе исторических данных присвоит женским именам меньший коэффициент риска. Окей, давайте удалим имена из выборки. Но вспомните пример с Амазоном: система может определить пол по другим факторам (хоть она и не знает, что такое пол, да и что такое машина), а вы этого не заметите, пока регулятор задним числом не проанализирует предлагаемые вами тарифы и не взыщет с вас штраф.
Наконец, часто подразумевается, что мы будем использовать такие системы только для проектов, которые связаны с людьми и социальными взаимодействиями. Это не так. Если вы делаете газовые турбины, вы наверняка захотите применить машинное обучение к телеметрии, передаваемой десятками или сотнями датчиков на вашем продукте (аудио-, видео-, температурные, да и любые другие датчики генерируют данные, которые можно очень легко приспособить для создания модели машинного обучения). Гипотетически вы можете сказать: «Вот данные о тысяче вышедших из строя турбин, полученные перед их поломкой, а вот данные с тысячи турбин, которые не ломались. Постройте модель, чтобы сказать, в чем между ними разница». Ну а теперь представьте себе, что датчики Siemens стоят на 75% плохих турбин, и лишь на 12% хороших (связи со сбоями при этом нет). Система построит модель, чтобы находить турбины с датчиками Siemens. Упс!
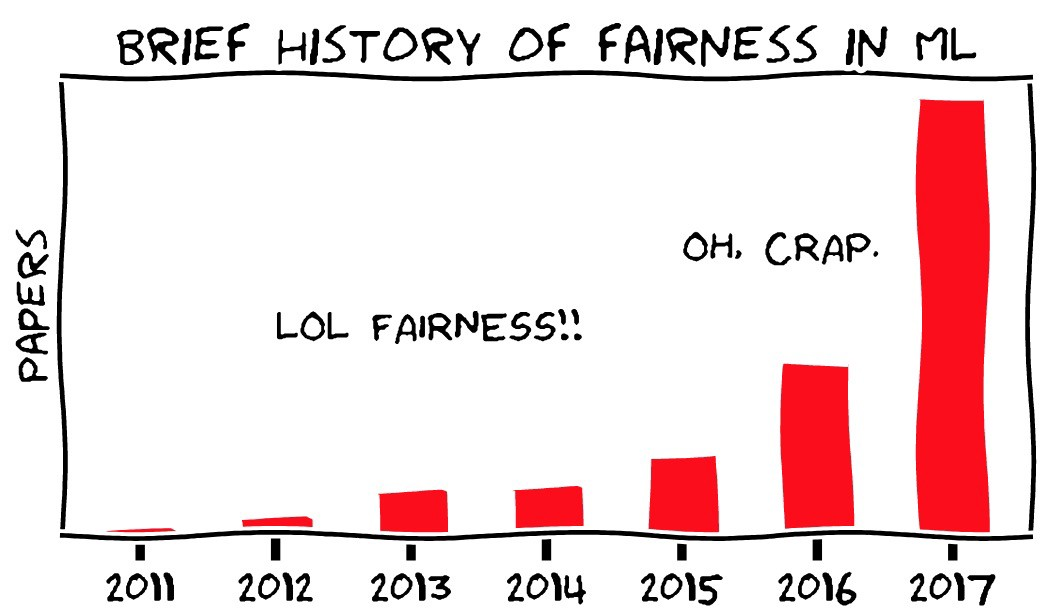
Картинка — Moritz Hardt, UC Berkeley
Управление предвзятостью ИИ
Что нам с этим поделать? Можно подойти к вопросу с трех сторон:
- Методологическая строгость при сборе и менеджменте данных для обучения системы.
- Технические инструменты для анализа и диагностики поведения модели.
- Тренинг, обучение и осторожность при внедрении машинного обучения в продукты.
В книге «Мещанин во дворянстве» Мольера есть шутка: одному мужчине рассказали, что литература делится на прозу и поэзию, и он с восхищением обнаруживает, что всю жизнь говорил прозой, сам того не зная. Наверное, статистики как-то так и чувствуют себя сегодня: сами того не замечая, они посвятили свои карьеры искусственному интеллекту и ошибке выборки. Искать ошибку выборки и переживать из-за нее — это не новая проблема, нам просто надо системно подойти к ее решению. Как упомянуто выше, в некоторых случаях это действительно проще делать, изучая проблемы, связанные с данными о людях. Мы априори предполагаем, что у нас могут быть предубеждения относительно различных групп людей, но вот предубеждение насчет датчиков Siemens нам сложно даже представить.
Новое во всем этом, конечно, то, что люди больше не занимаются статистическим анализом напрямую. Его проводят машины, которые создают большие комплексные модели, сложные для понимания. Вопрос прозрачности — один из основных аспектов проблемы предвзятости. Нам страшно, что система не просто предвзята, но что нет никакой возможности обнаружить её предвзятость, и что машинное обучение этим отличается от других форм автоматизации, которые, как предполагается, состоят из четких логических шагов, которые можно проверить.
Здесь есть две проблемы. Мы, возможно, все-таки можем проводить некий аудит систем машинного обучения. И аудит любой другой системы на самом деле нисколько не легче.
Во-первых, одно из направлений современных исследований в области машинного обучения — это поиск методов, как выявлять важный функционал систем машинного обучения. При этом, машинное обучение (в его текущем состоянии) — это совсем новая область науки, которая быстро меняется, так что не стоит думать, что невозможные сегодня вещи не могут вскоре стать вполне реальными. Проект OpenAI — интересный тому пример.
Во-вторых, идея о том, что можно проверять и понимать процесс принятия решений в существующих системах или организациях, хороша в теории, но так себе на практике. Понять, как принимаются решения в большой организации, совсем не просто. Даже если там существует формальный процесс принятия решений, он не отражает то, как люди взаимодействуют на самом деле, да и сами они часто не имеют логического системного подхода к принятию своих решений. Как сказал мой коллега Виджей Панде, люди — это тоже черные ящики.
Возьмите тысячу людей в нескольких пересекающихся компаниях и институтах, и проблема станет еще сложнее. Мы знаем постфактум, что «Спейс шаттлу» было суждено распасться на части при возвращении, и отдельные люди внутри NASA имели информацию, которая давала им повод думать, что может произойти что-то плохое, но система в целом этого не знала. NASA даже только что прошла аналогичный аудит, потеряв предыдущий шаттл, и все-таки она потеряла еще один — по очень похожей причине. Легко утверждать, что организации и люди следуют четким логическим правилам, которые можно проверить, понять и поменять — но опыт доказывает обратное. Это «заблуждение Госплана».
Я часто сравниваю машинное обучение с базами данных, особенно с реляционными — новой фундаментальной технологией, которая изменила возможности информатики и мир вокруг нее, которая стала частью всего, которую мы постоянно используем, не отдавая себе в этом отчет. У баз данных тоже есть проблемы, и они похожего свойства: система может быть построена на неверных предположениях или на плохих данных, но это сложно будет заметить, и люди, использующие систему, будут делать то, что она им говорит, не задавая вопросов. Есть куча старых шуток про работников налоговой, которые когда-то неправильно записали ваше имя, и убедить их исправить ошибку намного сложнее, чем на самом деле поменять имя. Об этом можно думать по-разному, но непонятно как лучше: как о технической проблеме в SQL, или как об ошибке в релизе Oracle, или как о сбое бюрократических институтов? Насколько сложно найти ошибку в процессе, который привел к тому, что система не имеет такой фичи, как исправление опечаток? Можно ли было понять это до того, как люди начали жаловаться?
Еще проще эту проблему иллюстрируют истории, когда водители из-за устаревших данных в навигаторе съезжают в реки. Окей, карты должны постоянно обновляться. Но насколько ТомТом виноват в том, что вашу машину сносит в море?
Я это говорю к тому, что да — предвзятость машинного обучения создаст проблемы. Но проблемы эти будут похожи на те, с которыми мы сталкивались в прошлом, и их можно будет заметить и решить (или нет) примерно настолько же хорошо, насколько это нам удавалось в прошлом. Следовательно, сценарий, при котором предвзятость ИИ нанесет ущерб, вряд ли случится с ведущими исследователями, работающими в большой организации. Скорее всего, какой-нибудь малозначительный технологический подрядчик или вендор ПО напишет что-то на коленке, используя непонятные ему опенсорсные компоненты, библиотеки и инструменты. А незадачливый клиент купится на словосочетание “искусственный интеллект” в описании продукта и, не задавая лишних вопросов, раздаст его своим низкооплачиваемым работникам, наказав им делать то, что скажет ИИ. Именно это и произошло с базами данных. Это не проблема искусственного интеллекта, и даже не проблема программного обеспечения. Это человеческий фактор.
Заключение
Машинное обучение может сделать все, чему вы можете научить собаку, — но вы никогда не можете быть уверены, чему же именно вы эту собаку научили.
Мне часто кажется, что термин «искусственный интеллект» только мешает заходить в разговоры вроде этого. Этот термин создает ложное впечатление того, что мы на самом деле создали его — этот интеллект. Что мы на пути к HAL9000 или Skynet — к чему-то, что на самом деле понимает. Но нет. Это просто машины, и их намного правильнее сравнивать, скажем, со стиральной машиной. Она намного лучше человека справляется со стиркой, но если вы положите в нее посуду вместо белья, она её… постирает. Посуда даже станет чистой. Но это будет не то, на что вы рассчитывали, и произойдет это не потому, что система имеет какие-то предубеждения относительно посуды. Стиральная машина не знает ни что такое посуда, ни что такое одежда — это всего лишь пример автоматизации, концептуально не отличающийся от того, как процессы автоматизировали раньше.
О чем бы речь ни шла, — о машинах, самолетах или базах данных — эти системы будут одновременно очень мощными и очень ограниченными. Они будут полностью зависеть от того, как люди используют эти системы, хорошие или плохие у них при этом намерения и насколько они понимают их работу.
Следовательно, говорить, что «искусственный интеллект — это математика, поэтому у него не может быть предубеждений» совершенно не верно. Но настолько же неверно утверждать, что машинное обучение «субъективно по своей природе». Машинное обучение находит паттерны в данных, и какие паттерны оно найдет, зависит от данных, а данные зависят от нас. Как и то, что мы с ними делаем. Машинное обучение действительно делает некоторые вещи намного лучше нас, — но собаки, например, намного эффективнее людей в обнаружении наркотиков, что вовсе не повод привлекать их в качестве свидетелей и выносить приговоры на основании их показаний. А собаки, к слову, намного умнее любой системы машинного обучения.
Перевод: Диана Лецкая.
Редактура: Алексей Иванов.
Сообщество: @PonchikNews.
Комментарии (10)

Wesha
30.04.2019 21:25Не могу найти произведение, но было что-то типа того, что в какой-то там марсианской подземке будущего погибли люди из-за того, что ИИ, управляющий подачей воздуха на станцию, "глядя" через камеры, научился включать подачу не когда прибывает поезд, а когда палочки на электронных часах на стене сложатся в опредлённые фигуры. А в один прекрасный день поезд опоздал, в момент его прибытия часы показывали другое время; двери открылись — а воздуха на станции нет.
Мой любимый пример — вот этот бипед. История была такая, что изначально условие было "
трахает всех самокв следующее поколение проходит тот, кто максимально удалится от точки старта за минуту". И эволюция выработала простейший выход: после старта бипед моментально падал на спину, и, отчаянно суча ногами, на спине скользил подальше от точки старта. Исследовали выматерились и исправили условие: "в следующее поколение проходит тот, кто максимально удалится от точки старта за минуту, если "таз" не опускается ниже определённого уровня". После чего бипед быстро научился ходить по-человечески.
submagic
01.05.2019 00:11Впечатляет. А теперь представьте, что за ИИ (против его создателей, так сказать..) играет ЧЕЛОВЕК.
Wesha
01.05.2019 21:34Что-то я не понял Вашего посыла. "Против создателей ИИ" (то есть против людей) играет человек, — то есть человек играет против человеков??
А вообще эволюция — она, ленивая скотина, очень любит достигать поставленных целей минимальными усилиями, заставляя постановщиков задач материться.
mtivkov
02.05.2019 22:57Питер Уоттс. Морские звезды.
Wesha
02.05.2019 23:03Спасибо!
— Он там управлял системой подземки – никаких нареканий, идеальный работник, а потом однажды эта штука просто забыла запустить вентиляторы, когда было надо. Поезд заезжает на пятнадцать метров под землю, пассажиры выходят, воздуха нет, бум!
– Эти штуки вроде как учатся на собственном опыте, правильно? – продолжает Джарвис. – Ну и все думали, что зельц научился запускать вентиляторы по какому-то очевидному признаку. Жару тела, движению, уровню углекислого газа, ну ты понимаешь. В результате выяснилось, что эта хрень просто смотрела за часами на стене. Прибытие поезда совпадало с предсказуемым набором паттернов на цифровом дисплее, поэтому она включала вертушки, когда видела один из них.
– Ага. Точно. – Джоэл качает головой. – А какие-то вандалы часы разбили. Или что-то вроде того.

rehci
30.04.2019 21:36+1ИИ может быть предвзят. Это опасно. Но еще опасней предвзятые люди, которые не хотят принимать объективные факты.
vikarti
01.05.2019 07:35Вот вспоминается книжка Weapons of Math Destruction 2016-го года. Там не столько слова про ИИ сколько более просто, про бигдату и алгоритмы. И какие последствия от того что результаты работы автоматики используются для принятие решений причем жаловаться — бесполезно (компьютер ведь (якобы)объективно все решает).

sotnikdv
01.05.2019 20:08Статья хороша и перевод неплох ИМХО.
В Европе уже требуется согласие на принятие решения без участия человека, если это несет юридические последствия. Кредит, работа и т.д.
В США ждем скоро.
Daniyar94
02.05.2019 01:11Начало статьи про предвзятость ИИ слабой формы, решается балансировкой. Где они увеличивают вес определённых features, например характеристик женщин в их резюме.
Помню был на митапе Твиттера, там они делали модель которая определяла несколько твит «токсичный». Их модель маркировала твиты, которые упоминали слова гей, лесбиянка и мусульманин, как «токсичные». Потому что дата которую они использовали содержала твиты, где эти термины упоминались в негативном контексте. Поэтому они провели ребалансировку, простым языком скормили модели твиты где использовались те же термины в позитивном контексте. Очень интересно.
submagic
Ну так об этих проблемах Станислав Лем прозорливо писал в своей «Сумме технологии» ещё много десятков лет назад. Разрабатывайте учебники для (операторов) машин: как обучить ИИ так, чтобы он всё понял правильно — и при этом ещё и не понял неправильно.