
И сейчас, во времена когда активно растет количество архитекторов, тестеров и DevOps инженеров, а разработчики Java Core оптимизируют даже работу со строками, медленно, но верно наступает пора и оптимизаторов баз данных. СУБД с каждым релизом становятся настолько умнее и сложнее, что изучение как документированных, так и недокументированных нюансов и оптимизаций требует огромного количества времени. Ежемесячно выходит огромное количество статей и проводятся крупные конференции посвященные Oracle. Простите за банальную аналогию, но в этой ситуации, когда администраторы баз данных становятся подобными пилотам самолетов с бесчисленным количеством тумблеров, кнопочек, лампочек и экранов, уже неприлично нагружать их еще и тонкостями оптимизации производительности.
Конечно, ДБА, как и пилоты, в большинстве случаев достаточно легко могут решить очевидные и простые проблемы, когда они либо легко диагностируемы, либо заметны в различных «топах» (Top events, top SQL, top segments...). И которые легко найти в MOS или Google, даже если не знают решения. Гораздо сложнее, когда даже симптомы скрываются за сложностью системы и их необходимо выудить среди огромного количества диагностической информации, собираемой самой СУБД Oracle.
Одним из наиболее простых и ярких таких примеров является анализ filter и access предиктов: в больших и нагруженных системах, часто бывает что такую проблему легко не заметить, т.к. нагрузка достаточно равномерно размазана по разным запросам (с джойнами по различным таблицам, с небольшими отличиями в условиях и тд.), да и топ сегментов ничего особенного не показывает, мол, «ну да, из этих таблиц данные нужны чаще всего и их больше». В таких случаях, можно начать анализ со статистик из SYS.COL_USAGE$: col_usage.sql
col owner format a30
col oname format a30 heading "Object name"
col cname format a30 heading "Column name"
accept owner_mask prompt "Enter owner mask: ";
accept tab_name prompt "Enter tab_name mask: ";
accept col_name prompt "Enter col_name mask: ";
SELECT a.username as owner
,o.name as oname
,c.name as cname
,u.equality_preds as equality_preds
,u.equijoin_preds as equijoin_preds
,u.nonequijoin_preds as nonequijoin_preds
,u.range_preds as range_preds
,u.like_preds as like_preds
,u.null_preds as null_preds
,to_char(u.timestamp, 'yyyy-mm-dd hh24:mi:ss') when
FROM
sys.col_usage$ u
, sys.obj$ o
, sys.col$ c
, all_users a
WHERE a.user_id = o.owner#
AND u.obj# = o.obj#
AND u.obj# = c.obj#
AND u.intcol# = c.col#
AND a.username like upper('&owner_mask')
AND o.name like upper('&tab_name')
AND c.name like upper('&col_name')
ORDER BY a.username, o.name, c.name
;
col owner clear;
col oname clear;
col cname clear;
undef tab_name col_name owner_mask;Однако, для полноценного анализа этой информации мало, т.к. она не показывает сочетаний предикатов. В этом случае нам может помочь анализ v$active_session_history и v$sql_plan:
with
ash as (
select
sql_id
,plan_hash_value
,table_name
,alias
,ACCESS_PREDICATES
,FILTER_PREDICATES
,count(*) cnt
from (
select
h.sql_id
,h.SQL_PLAN_HASH_VALUE plan_hash_value
,decode(p.OPERATION
,'TABLE ACCESS',p.OBJECT_OWNER||'.'||p.OBJECT_NAME
,(select i.TABLE_OWNER||'.'||i.TABLE_NAME from dba_indexes i where i.OWNER=p.OBJECT_OWNER and i.index_name=p.OBJECT_NAME)
) table_name
,OBJECT_ALIAS ALIAS
,p.ACCESS_PREDICATES
,p.FILTER_PREDICATES
-- поля, которые могут быть полезны для анализа в других разрезах:
-- ,h.sql_plan_operation
-- ,h.sql_plan_options
-- ,decode(h.session_state,'ON CPU','ON CPU',h.event) event
-- ,h.current_obj#
from v$active_session_history h
,v$sql_plan p
where h.sql_opname='SELECT'
and h.IN_SQL_EXECUTION='Y'
and h.sql_plan_operation in ('INDEX','TABLE ACCESS')
and p.SQL_ID = h.sql_id
and p.CHILD_NUMBER = h.SQL_CHILD_NUMBER
and p.ID = h.SQL_PLAN_LINE_ID
-- если захотим за последние 3 часа:
-- and h.sample_time >= systimestamp - interval '3' hour
)
-- если захотим анализируем предикаты только одной таблицы:
-- where table_name='&OWNER.&TABNAME'
group by
sql_id
,plan_hash_value
,table_name
,alias
,ACCESS_PREDICATES
,FILTER_PREDICATES
)
,agg_by_alias as (
select
table_name
,regexp_substr(ALIAS,'^[^@]+') ALIAS
,listagg(ACCESS_PREDICATES,' ') within group(order by ACCESS_PREDICATES) ACCESS_PREDICATES
,listagg(FILTER_PREDICATES,' ') within group(order by FILTER_PREDICATES) FILTER_PREDICATES
,sum(cnt) cnt
from ash
group by
sql_id
,plan_hash_value
,table_name
,alias
)
,agg as (
select
table_name
,'ALIAS' alias
,replace(access_predicates,'"'||alias||'".','"ALIAS".') access_predicates
,replace(filter_predicates,'"'||alias||'".','"ALIAS".') filter_predicates
,sum(cnt) cnt
from agg_by_alias
group by
table_name
,replace(access_predicates,'"'||alias||'".','"ALIAS".')
,replace(filter_predicates,'"'||alias||'".','"ALIAS".')
)
,cols as (
select
table_name
,cols
,access_predicates
,filter_predicates
,sum(cnt)over(partition by table_name,cols) total_by_cols
,cnt
from agg
,xmltable(
'string-join(for $c in /ROWSET/ROW/COL order by $c return $c,",")'
passing
xmltype(
cursor(
(select distinct
nvl(
regexp_substr(
access_predicates||' '||filter_predicates
,'("'||alias||'"\.|[^.]|^)"([A-Z0-9#_$]+)"([^.]|$)'
,1
,level
,'i',2
),' ')
col
from dual
connect by
level<=regexp_count(
access_predicates||' '||filter_predicates
,'("'||alias||'"\.|[^.]|^)"([A-Z0-9#_$]+)"([^.]|$)'
)
)
))
columns cols varchar2(400) path '.'
)(+)
order by total_by_cols desc, table_name, cnt desc
)
select
table_name
,cols
,sum(cnt)over(partition by table_name,cols) total_by_cols
,access_predicates
,filter_predicates
,cnt
from cols
where rownum<=50
order by total_by_cols desc, table_name, cnt desc;
Как видно из самого запроса, он выводит топ 50 поисковых столбцы и сами предикаты по количеству раз попаданий ASH за последние 3 часа. Несмотря на то, что ASH хранит лишь ежесекундные снепшоты, выборка на нагруженных базах очень репрезентативна. В нем можно пояснить несколько моментов:
- Поле cols — выводит сами поисковые столбцы(search columns), а total_by_cols — сумму вхождений в разрезе этих столбцов.
- Я думаю, вполне очевидно, что данная информация сама по себе недостаточный маркер проблемы, т.к. например, несколько разовых фулсканов могут легко испортить статистику, поэтому обязательно придется рассматривать и сами запросы и их частоту (v$sqlstats,dba_hist_sqlstat)
- Группировка по OBJECT_ALIAS внутри SQL_ID,plan_hash_value важна для объединения индексных и табличных предикатов по объекту, т.к. при доступе к таблице через индекс, предикаты будут разбиты по разным строкам плана:
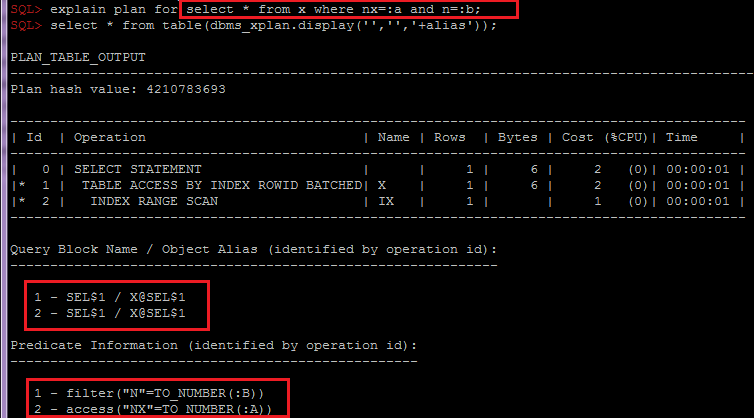
В зависимости от необходимости этот скрипт можно легко модифицировать для сбора дополнительной информации в других разрезах, например с учетом секционирования или ожиданий. И уже проанализировав эту информацию вкупе с анализом статистики таблицы и ее индексов, общей схемы данных и бизнес-логики можно передавать рекомендации разработчикам или архитекторам для выбора решения, например: варианты денормализации или изменения схемы секционирования или индексов.
Так же довольно часто забывают анализировать SQL*net траффик, а ведь там тоже много тонкостей, например: fetch-size, SQLNET.COMPRESSION, extended datatypes, позволяющие уменьшить число roundtrip'ов, и тд, но это уже тема для отдельной статьи.
В заключение, хотел бы сказать, что сейчас, когда пользователи становятся все менее терпимыми к задержкам, оптимизация производительности становится конкурентным преимуществом.
Комментарии (6)

Triffids
14.05.2019 13:45есть вопрос. а есть какие-то методы борьбы с меняющейся скоростью дисковой полки? я так понимаю скорость доступа к hdd это системная статистика, собирается в момент старта истанса, когда нагрузка на полку с других систем минимальна. а потом я наблюдаю печальку. оптимизатор выбирает нестед луп, рассчитывая на скорость простаивающей полки, а реально там в час пик скорость ниже плинтуса.
может есть какие-то методы борбы с этим?
xtender Автор
14.05.2019 13:49Да, конечно, по идее вы должны откалибровать IO именно в момент высокой нагрузки: I/O Calibration
Однако, это не всегда нужно, т.к. по дефолту оракл выставляет достаточно адекватные статистики, ну и, конечно, проверяйте свою на баги калибровки перед тем как ее запустить, т.к. я помню на старых версиях была баг с занижением в 1000 раз.
alexhott
Мне кажется если сбор статистики отключить, то получим +100% к производительности, а то и больше.
asmm
а как отключить ASH?
xtender, спасибо за статью, легко нашлось пара ошибочных мест
xtender Автор
Не за что, всегда рад помочь!
xtender Автор
Какой статистики? Статистики для оптимизатора (по таблицам, индексам и тд)?
В любом случае — нет. Неправильный сбор статистики, конечно, может усугубить перфоманс, но чаще бывают проблемы с неактуальной статистикой.