
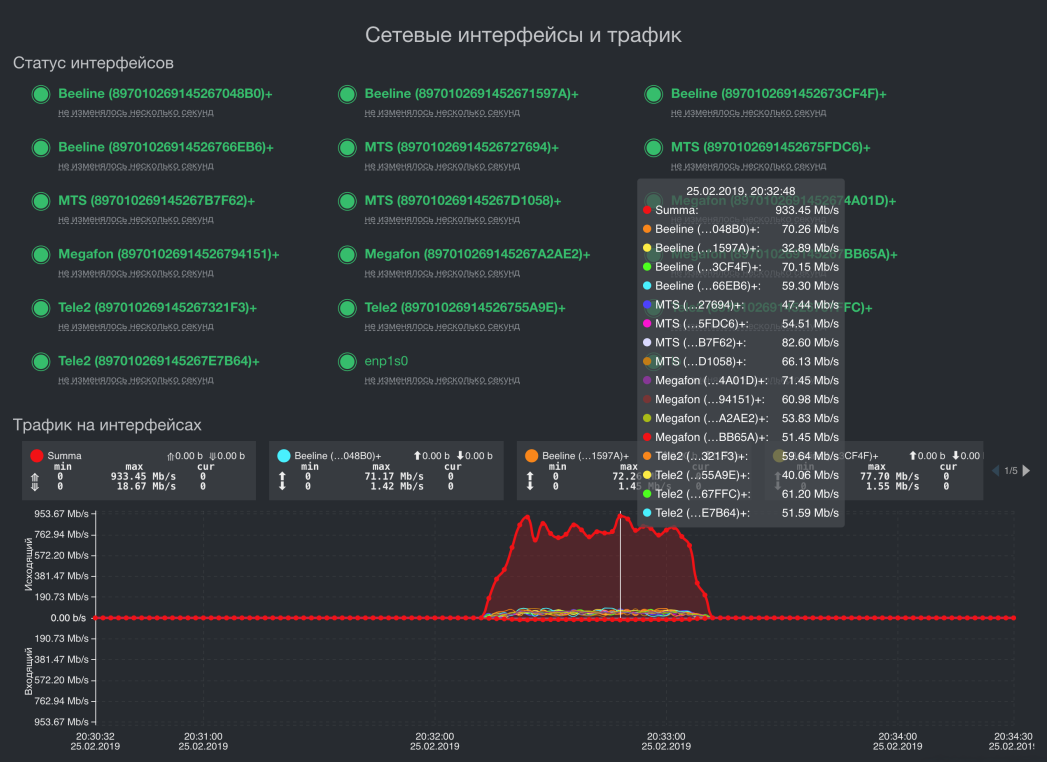
Суммирование скорости на 16-ти модемах 4-х сотовых операторов. Исходящая скорость в один поток — 933.45 Мбит/с
Введение
Привет! Это статья про то, как мы написали для себя новую систему мониторинга. От существующих она отличается возможностью высокочастотного синхронного получения метрик и очень маленьким потреблением ресурсов. Частота опроса может достигать 0.1 миллисекунды с точностью синхронизации между метриками в 10 наносекунд. Все бинарные файлы занимают 6 мегабайт.
О проекте
У нас довольно специфичный продукт. Мы производим комплексное решение для суммирования пропускной способности и отказоустойчивости каналов передачи данных. Это когда есть несколько каналов, допустим Оператор1 (40Мбит/с) + Оператор2 (30Мбит/с)+ Что-то еще(5 Мбит/с), в результате получается один стабильный и быстрый канал, скорость которого будет примерно такой: (40+30+5)x0.92=75x0.92=69 Мбит/с.
Такие решения востребованы там, где емкость любого одного канала недостаточна. Например транспорт, системы видео-наблюдения и потоковой видео-трансляции в реальном времени, трансляция прямых теле- радио- эфиров, любые загородные объекты где из операторов связи есть только представители большой четверки и скорости на одном модеме/канале недостаточно.
Для каждого из этих направлений мы выпускаем отдельную линейку устройств, однако программная их часть почти одинаковая и качественная система мониторинга — один из главных ее модулей, без правильной реализации которого продукт был бы невозможен.
За несколько лет, нам удалось создать многоуровневую быструю, кроссплатформенную и легковесную систему мониторинга. Чем и хотим поделиться с уважаемым сообществом.
Постановка задачи
Система мониторинга обеспечивает получение метрик двух принципиально разных классов: метрики реального времени и все остальные. К системе мониторинга было всего следующие требования:
- Высокочастотное синхронное получение метрик реального времени и передача их с систему управления связью без задержек.
Высокая частота и синхронизация разных метрик — не просто важна, она жизненно необходима для анализа энтропии каналов передачи данных. Если в одном канале передачи данных средняя задержка 30 миллисекунд, то ошибка в синхронизации между остальными метриками всего на одну миллисекунду, приведет к деградации скорости результирующего канала примерно на 5%. Если мы ошибемся в синхронизации на 1 миллисекунду в 4-х каналах, деградация скорости легко может упасть до 30%. Кроме этого, энтропия в каналах меняется очень быстро, поэтому если измерять ее реже чем один раз в 0.5 миллисекунд, на быстрых каналах с маленькой задержкой мы получим высокую деградацию скорости. Разумеется, такая точность нужна не для всех метрик и не во всех условиях. Когда задержка в канале будет 500 миллисекунд, а мы работаем и с такими, то погрешность в 1 миллисекунду почти не будет заметна. Также, для метрик систем жизнеобеспечения нам хватает частоты опроса и синхронизации в 2 секунды, однако сама по себе система мониторинга должна уметь работать со сверхвысокими частотами опроса и сверхточной синхронизацией метрик. - Минимальное потребление ресурсов и единый стек.
Конечное устройство может представлять из себя как мощный бортовой комплекс, который может анализировать ситуацию на дороге или вести биометрическую фиксацию людей, так и одноплатный компьютер размером в ладонь, который носит под бронежилетом боец спецназа для передачи видео в реальном времени в условиях плохой связи. Несмотря на такое разнообразие архитектур и вычислительных мощностей, нам хотелось бы иметь одинаковый программный стек. - Зонтичная архитектура
Метрики должны собираться и агрегироваться на конечном устройстве, иметь локальную систему хранения и визуализацию в режиме реального времени и ретроспективно. В случае наличия связи — передавать данные в центральную систему мониторинга. Когда связи нет — очередь на отправку должна накапливаться и не потреблять оперативную память. - API для интеграции в систему мониторинга заказчика, потому что никому не нужно много систем мониторинга. Заказчик должен собирать данные от любых устройств и сетей в единый мониторинг.
Что получилось
Чтобы на нагружать и без того внушительный лонгрид, я не буду приводить примеры и измерения всех систем мониторинга. Это потянет еще на одну статью. Просто скажу, что нам не удалось найти систему мониторинга, которая способна взять две метрики одновременно с погрешностью менее 1 миллисекунды и которая одинаково эффективно работает как на ARM архитектуре с 64Мбайт ОЗУ так и на х86_64 архитектуре с 32 Гбайт ОЗУ. Поэтому мы решили написать свою, которая умеет вот это вот все. Вот что у нас получилось:
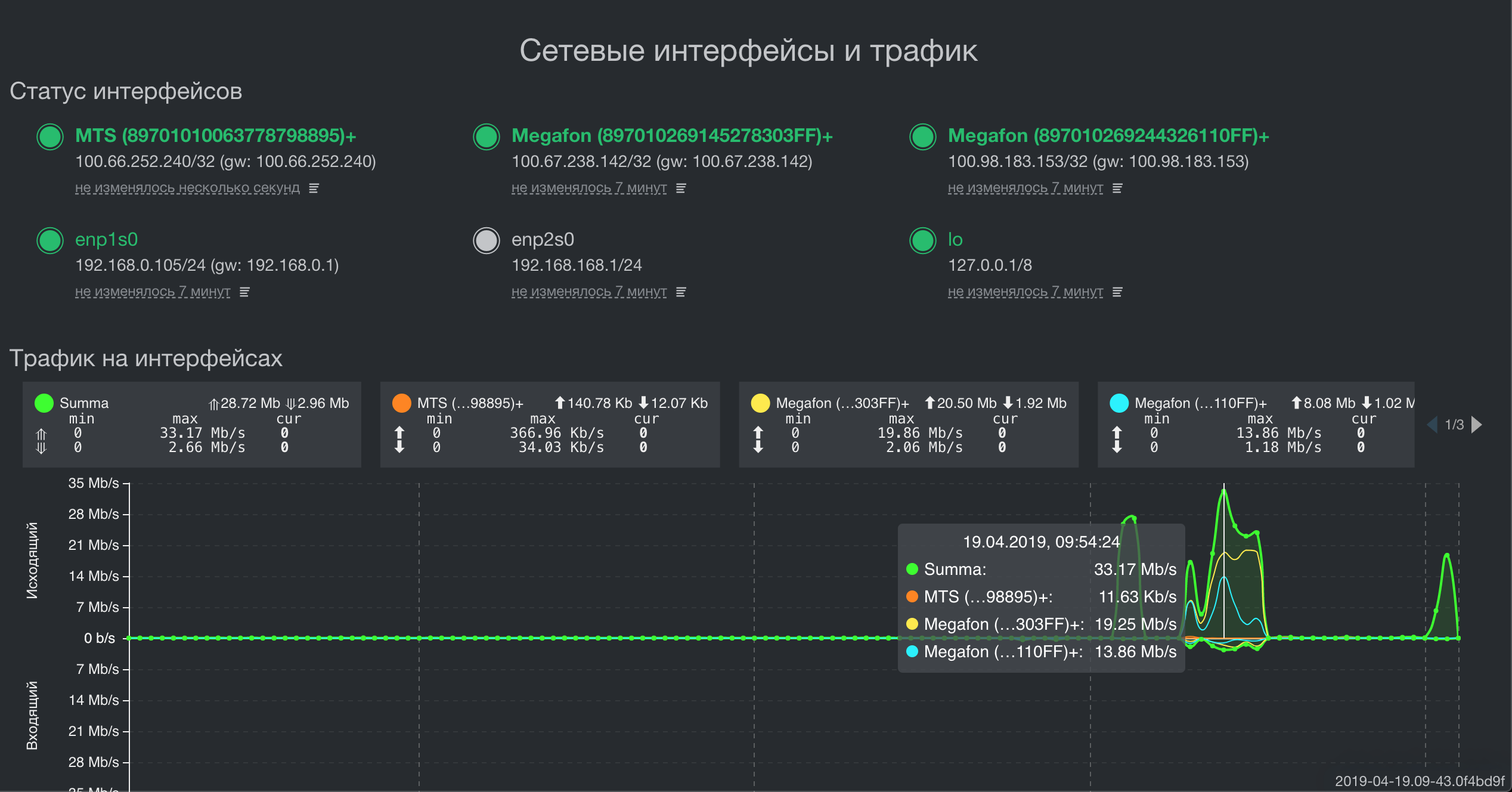
Суммирование пропускной способности трех каналов для разной топологии сети
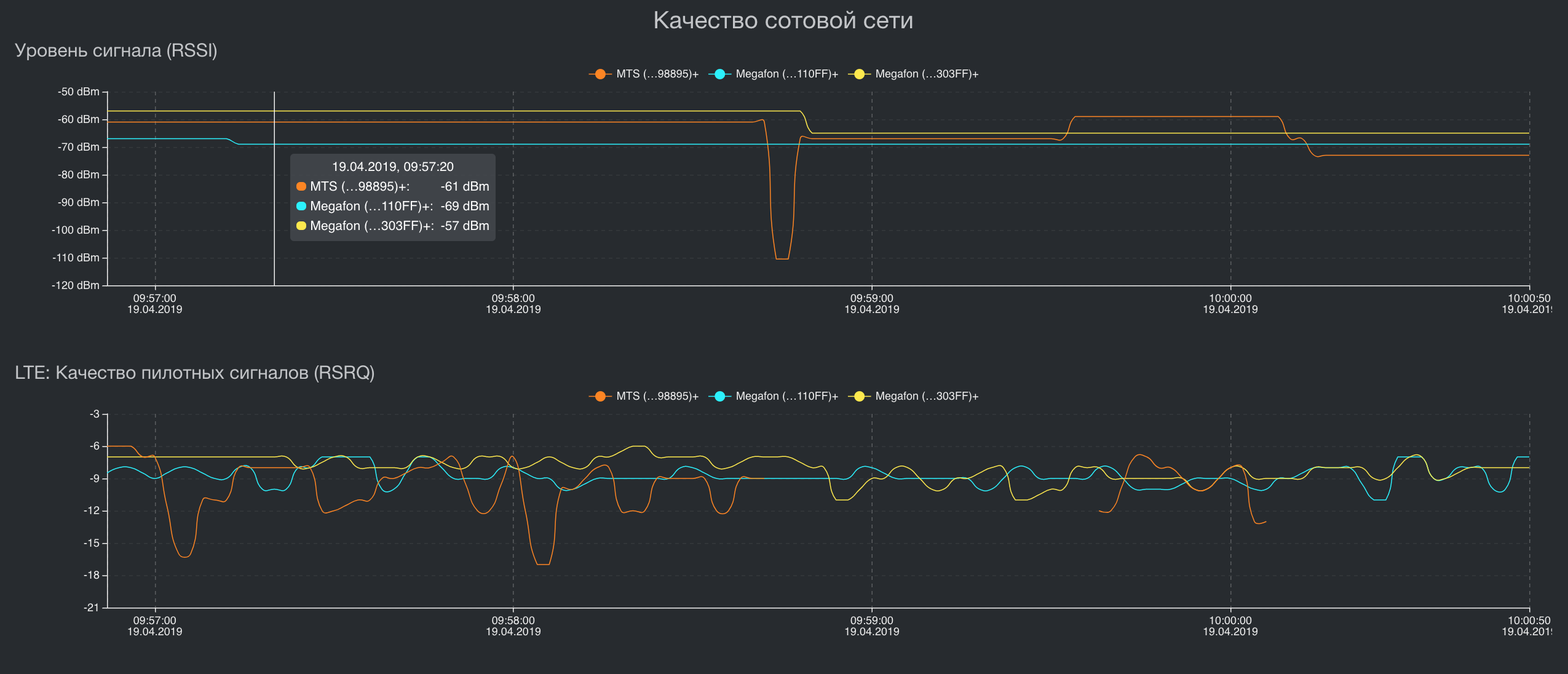
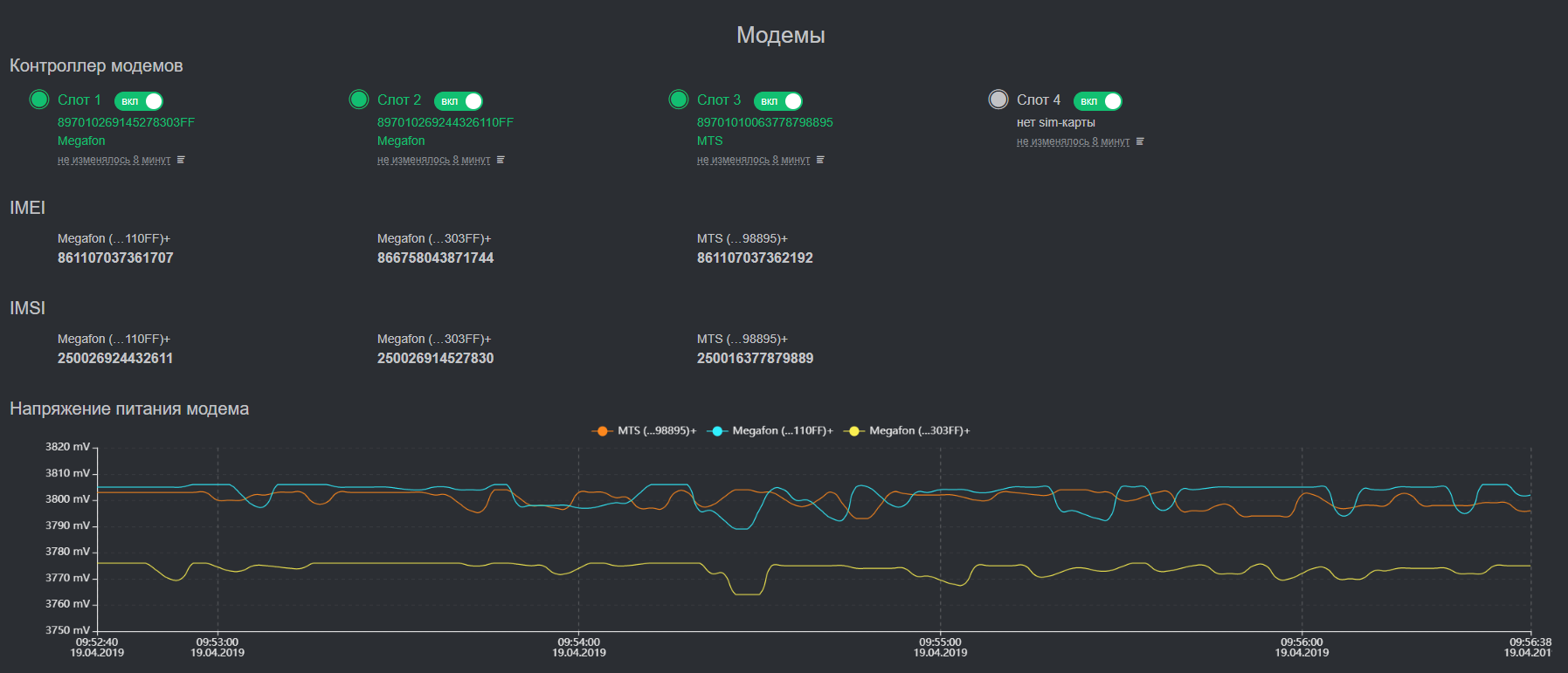
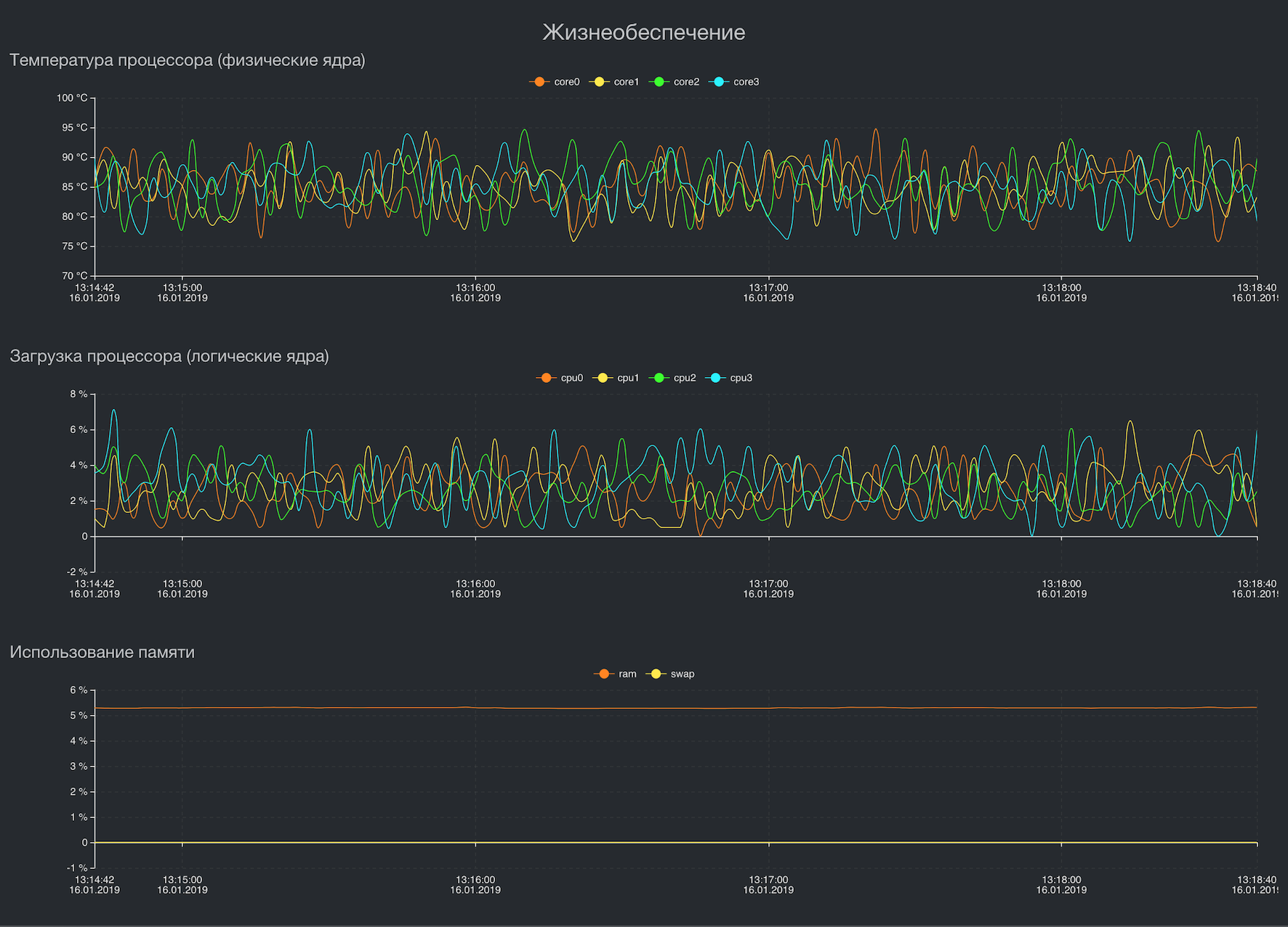
Визуализация некоторых ключевых метрик
Архитектура
В качестве основного языка программирования, как на устройстве так и в ЦОДе, мы используем Golang. Он значительно упростил жизнь своей реализацией многозадачности и возможностью получить один статически слинкованный исполняемый бинарный файл для каждого сервиса. В результате мы значительно экономим в ресурсах, способах и трафике деплоя сервиса на конечные устройства, времени разработки и отладки кода.
Система реализована по классическому модульному принципу и содержит в себе несколько подсистем:
- Регистрация метрик.
Каждая метрика обслуживается собственным потоком и синхронизируется через каналы. Нам удалось получить точность синхронизации до 10 наносекунд. - Хранение метрик
Мы выбирали между тем, чтобы написать свое хранилище для временных рядов или использовать что-то из имеющегося. База данных нужна для ретроспективных данных, которые подлежат последующей визуализации.Т.е в ней нет данных о задержках в канале каждые 0.5 миллисекунд или показаниях ошибок в транспортной сети, но есть скорость на каждом интерфейсе каждые 500 миллисекунд. Помимо высоких требований к кроссплатформенности и малому потреблению ресурсов, нам крайне важно иметь возможность обработать. данные там же где они хранятся. Это колоссально экономит вычислительный ресурс. Мы с 2016-го года используем СУБД Tarantool в этом проекте и пока в горизонте не видим ему замены. Гибкий, с оптимальным потреблением ресурсов, более чем адекватной техподдержкой. Также в Tarantool реализован GIS модуль. Он конечно не такой мощный как PostGIS, но его хватает для наших задач хранения некоторых метрик привязанных к локации (актуально для транспорта). - Визуализация метрик
Тут все относительно просто. Берем данные из хранилища и показываем их либо в реальном времени либо ретроспективно. - Синхронизация данных с центральной системой мониторинга.
Центральная система мониторинга принимает данные от всех устройств, хранит их с заданной ретроспективой и через API отдает их в систему мониторинга Заказчика. В отличии от классических систем мониторинга, в которых "голова" ходит и собирает данные — у нас обратная схема. Устройства сами отправляют данные тогда, когда есть связь. Это очень важный момент, поскольку он позволяет получить данные с устройства за те промежутки времени, в которые оно было не доступно и не нагружать каналы и ресурсы в то время когда устройство недоступно. В качестве центральной системы мониторинга мы используем Influx monitoring server. В отличии от аналогов, умеет импортировать ретроспективные данные (т.е с меткой времени отличной от момента получения метрики) Собранные метрики визуализирует доработанная напильником Grafana. Этот стандартный стек был выбран еще и потому, что имеет готовые API интеграции практическ с любой системой мониторинга заказчика. - Синхронизация данных с центральной системой управления устройствами.
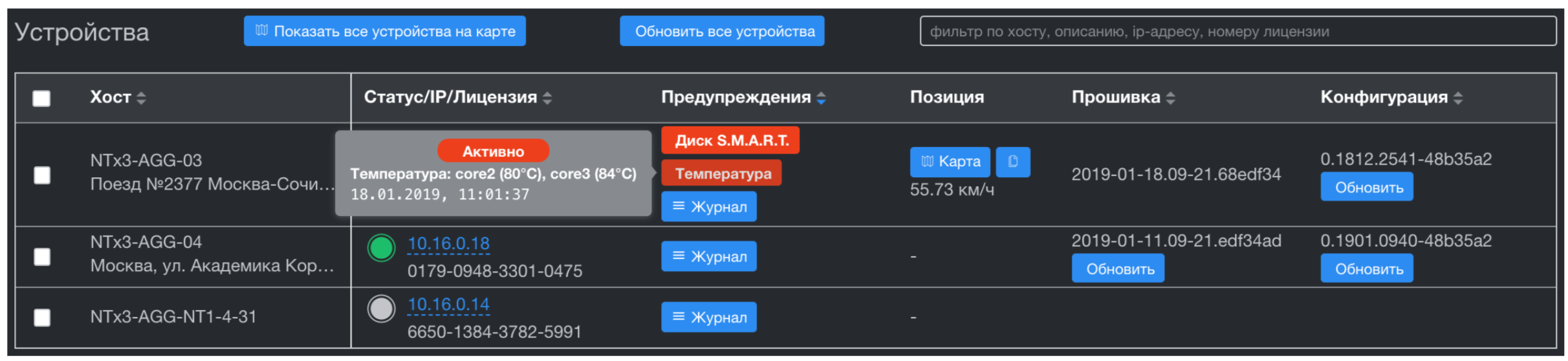
Система управления устройствами реализует Zero Touch Provisioning (обновление прошивки, конфигурации и т.д.) и в отличии от системы мониторинга, получает только проблемы по устройствам. Это триггеры работы бортовых аппаратных сторожевых сервисов и все метрики систем жизнеобеспечения: температура CPU и SSD, нагрузка CPU, свободное место и S.M.A.R.T здоровье на дисках. Хранилище подсистемы построено также на Tarantool. Это дает нам значительную скорость в агрегации временных рядов по тысячам устройств, а также полностью решает вопрос синхронизации данных с этими устройствами. В Tarantool встроена прекрасная система очередей и гарантированной доставки. Эту важную фичу мы получили из коробки, прекрасно!
Система управления сетью
Что дальше
Пока самым слабым звеном у нас является центральная система мониторинга. Она реализована на 99.9% на стандартном стеке и у нее есть ряд недостатков:
- InfluxDB теряет данные при отключения питания. Как правило, Заказчик оперативно забирает все что приходит от устройств и в самой БД нет данных старше 5 минут, однако в будущем это может стать болью.
- Grafana имеет ряд проблем с агрегацией данных и синхронностью их отображения. Самая частая проблема — когда в базе лежит временной ряд с интервалом в 2 секунды начиная скажем с 00:00:00, а Grafana начинает показывать данные в агрегации с +1 секунду. В результате пользователь видит пляшущий график.
- Избыточное количество кода для API интеграции со сторонними системами мониторинга. Можно сделать гораздо компактнее и конечно переписать на Go )
Полагаю все вы прекрасно видели как выглядит Grafana и без меня знаете ее проблемы, поэтому не буду перегружать пост картинками.
Заключение
Я сознательно не стал описывать технические детали, а описал лишь опорный дизайн этой системы. Во первых, чтобы технически полно описать систему потребуется еще одна статья. Во вторых, далеко не всем будет это интересно. Напишите в комментариях какие технические детали вам хотелось бы узнать.
Если у кого-то возникнут вопросы за пределами этой статьи, мне можно писать на адрес a.rodin @ qedr.com
Комментарии (6)

r1alex Автор
14.05.2019 17:53Не боролись. Этот модуль написан на С
На Go написаны приложения простраства пользователя. Регистрация метрик по каналам передачи и принятие решений на основе этих метрик реализованы на уровне ядра операционной системы. Любой другой способ накладывает задержки которые своей погрешностью искажают картину энтропии. Сервис на Go только забирает эти метрики через отдельный API
pronvis
15.05.2019 01:17Почему Go с его GC, а не Rust?
Почему С, а не Rust?
Не холивара ради, а интереса для спрашиваю. Можно было ведь вместо двух языков использовать один. Там и с памятью строго и в голову себе сложнее выстрелить.r1alex Автор
15.05.2019 01:34+1От синтаксиса Раста у меня вывих мозга. И писать модули ядра на С как то привычнее.
serge-phi
Как боролись с задержками от сборки мусора? Использовали предварительное выделение памяти и отключали сборщик?