
Здравствуйте, коллеги!
Возможно, название сегодняшней публикации лучше смотрелось бы с вопросительным знаком — сложно сказать. В любом случае, сегодня мы хотим предложить вам краткий экскурс, который познакомит вас с библиотекой Dask, предназначенной для распараллеливания задач на Python. Надеемся в дальнейшем вернуться к этой теме более основательно.

Снимок взят по адресу
Dask – без преувеличения наиболее революционный инструмент для обработки данных, который мне попадался. Если вам нравятся Pandas и Numpy, но иногда вам не удается справиться с данными, не умещающимися в RAM, то Dask – именно то, что вам нужно. Dask поддерживает фрейм данных Pandas и структуры данных (массивы) Numpy. Dask можно запускать либо на локальном компьютере, либо масштабировать, а затем запускать в кластере. В сущности, вы пишете код всего один раз, а затем выбираете: использовать ли его на локальной машине, либо развертывать в кластере из множества узлов, используя для всего этого самый обычный синтаксис Python. Сама по себе данная возможность великолепна, но я решил написать эту статью именно для того, чтобы подчеркнуть: каждый Data Scientist (как минимум, использующий Python) должен использовать Dask. С моей точки зрения волшебство Dask заключается в том, что, минимально изменив код, можно распараллеливать его, пользуясь вычислительными мощностями, которые уже имеются, например, у меня на ноутбуке. При параллельной обработке данных программа выполняется быстрее, приходится меньше ждать, соответственно, больше времени остается на аналитику. В частности, в этой статье мы поговорим об объекте
В качестве знакомства с Dask приведу пару примеров, просто чтобы дать вам представление о его полностью ненавязчивом и естественном синтаксисе. Важнейший вывод, который я хочу подсказать в данном случае – уже имеющихся у вас знаний будет достаточно для работы; вам не придется изучать новый инструмент для обращения с большими данными, например, Hadoop или Spark.
В Dask предлагается 3 параллельные коллекции, в которых можно хранить объем данных, превышающий по размеру RAM, а именно: Dataframes, Bags и Arrays. В каждом из этих типов коллекций можно хранить данные, сегментировав их между RAM и жестким диском, а также распределять данные по множеству узлов в кластере.
Dask DataFrame состоит из измельченных датафреймов, таких, как в Pandas, поэтому позволяет использовать подмножество возможностей из синтаксиса запросов Pandas. Ниже приведен пример кода, загружающий все csv-файлы за 2018 год, разбирающий поле с временной меткой и запускающий запрос Pandas:
Пример Dask Dataframe
В Dask Bag можно хранить и обрабатывать коллекции питонических объектов, не умещающихся в памяти. Dask Bag отлично подходит для обработки логов и коллекций документов в формате json. В этом примере с кодом все файлы в формате json за 2018 год загружаются в структуру данных Dask Bag, каждая запись json проходит синтаксический разбор, а данные о пользователях фильтруются при помощи лямбда-функции:
Пример Dask Bag
Структура данных Dask Arrays поддерживает срезы в стиле Numpy. В следующем примере множество данных HDF5 дробится на блоки размерностью (5000, 5000):
Пример Dask Array
Другое не менее точное название этого раздела могло бы звучать «Смерть последовательного цикла». Мне то и дело встречается распространенный паттерн: перебираем список элементов, после чего выполняем с каждым элементом метод Python, но с разными входными аргументами. Среди распространенных сценариев обработки данных – вычисление совокупностей признаков (feature aggregate) для каждого клиента или выполнение агрегации событий из лога для каждого студента. Вместо применения функции к каждому аргументу в рамках последовательного цикла объект Dask Delayed позволяет обрабатывать множество элементов параллельно. При работе с Dask Delayed все вызовы функций ставятся в очередь, ставятся в граф выполнения, после чего планируется их обработка.
Мне всегда было немного лениво писать собственный механизм обработки потоков или использовать asyncio, так что я даже не буду показывать вам подобных примеров для сравнения. С Dask можно не менять ни синтаксиса, ни стиля программирования! Нужно всего лишь аннотировать или обернуть метод, который будет выполнен параллельно с
В нижеприведенном примере два метода аннотированы
Количество потоков можно задать (например,
Итак, я продемонстрировал, насколько тривиально будет добавить параллельную обработку задач в проект из области Data Science при помощи Dask. Незадолго до написания этой статьи я применил Dask, чтобы разделить данные о пользовательских потоках кликов (истории посещений) на 40-минутные сеансы, после чего агрегировать признаки по каждому пользователю для последующей кластеризации. Расскажите, а каким образом вам доводилось использовать Dask!
Возможно, название сегодняшней публикации лучше смотрелось бы с вопросительным знаком — сложно сказать. В любом случае, сегодня мы хотим предложить вам краткий экскурс, который познакомит вас с библиотекой Dask, предназначенной для распараллеливания задач на Python. Надеемся в дальнейшем вернуться к этой теме более основательно.
Снимок взят по адресу
Dask – без преувеличения наиболее революционный инструмент для обработки данных, который мне попадался. Если вам нравятся Pandas и Numpy, но иногда вам не удается справиться с данными, не умещающимися в RAM, то Dask – именно то, что вам нужно. Dask поддерживает фрейм данных Pandas и структуры данных (массивы) Numpy. Dask можно запускать либо на локальном компьютере, либо масштабировать, а затем запускать в кластере. В сущности, вы пишете код всего один раз, а затем выбираете: использовать ли его на локальной машине, либо развертывать в кластере из множества узлов, используя для всего этого самый обычный синтаксис Python. Сама по себе данная возможность великолепна, но я решил написать эту статью именно для того, чтобы подчеркнуть: каждый Data Scientist (как минимум, использующий Python) должен использовать Dask. С моей точки зрения волшебство Dask заключается в том, что, минимально изменив код, можно распараллеливать его, пользуясь вычислительными мощностями, которые уже имеются, например, у меня на ноутбуке. При параллельной обработке данных программа выполняется быстрее, приходится меньше ждать, соответственно, больше времени остается на аналитику. В частности, в этой статье мы поговорим об объекте
dask.delayed и о том, как он вписывается в поток задач науки о данных. Знакомство с Dask
В качестве знакомства с Dask приведу пару примеров, просто чтобы дать вам представление о его полностью ненавязчивом и естественном синтаксисе. Важнейший вывод, который я хочу подсказать в данном случае – уже имеющихся у вас знаний будет достаточно для работы; вам не придется изучать новый инструмент для обращения с большими данными, например, Hadoop или Spark.
В Dask предлагается 3 параллельные коллекции, в которых можно хранить объем данных, превышающий по размеру RAM, а именно: Dataframes, Bags и Arrays. В каждом из этих типов коллекций можно хранить данные, сегментировав их между RAM и жестким диском, а также распределять данные по множеству узлов в кластере.
Dask DataFrame состоит из измельченных датафреймов, таких, как в Pandas, поэтому позволяет использовать подмножество возможностей из синтаксиса запросов Pandas. Ниже приведен пример кода, загружающий все csv-файлы за 2018 год, разбирающий поле с временной меткой и запускающий запрос Pandas:
import dask.dataframe as dd
df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp'])
df.groupby(df.timestamp.dt.hour).value.mean().compute()Пример Dask Dataframe
В Dask Bag можно хранить и обрабатывать коллекции питонических объектов, не умещающихся в памяти. Dask Bag отлично подходит для обработки логов и коллекций документов в формате json. В этом примере с кодом все файлы в формате json за 2018 год загружаются в структуру данных Dask Bag, каждая запись json проходит синтаксический разбор, а данные о пользователях фильтруются при помощи лямбда-функции:
import dask.bag as db
import json
records = db.read_text('data/2018-*-*.json').map(json.loads)
records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()Пример Dask Bag
Структура данных Dask Arrays поддерживает срезы в стиле Numpy. В следующем примере множество данных HDF5 дробится на блоки размерностью (5000, 5000):
import h5py
f = h5py.File('myhdf5file.hdf5')
dset = f['/data/path']
import dask.array as da
x = da.from_array(dset, chunks=(5000, 5000))Пример Dask Array
Параллельная обработка в Dask
Другое не менее точное название этого раздела могло бы звучать «Смерть последовательного цикла». Мне то и дело встречается распространенный паттерн: перебираем список элементов, после чего выполняем с каждым элементом метод Python, но с разными входными аргументами. Среди распространенных сценариев обработки данных – вычисление совокупностей признаков (feature aggregate) для каждого клиента или выполнение агрегации событий из лога для каждого студента. Вместо применения функции к каждому аргументу в рамках последовательного цикла объект Dask Delayed позволяет обрабатывать множество элементов параллельно. При работе с Dask Delayed все вызовы функций ставятся в очередь, ставятся в граф выполнения, после чего планируется их обработка.
Мне всегда было немного лениво писать собственный механизм обработки потоков или использовать asyncio, так что я даже не буду показывать вам подобных примеров для сравнения. С Dask можно не менять ни синтаксиса, ни стиля программирования! Нужно всего лишь аннотировать или обернуть метод, который будет выполнен параллельно с
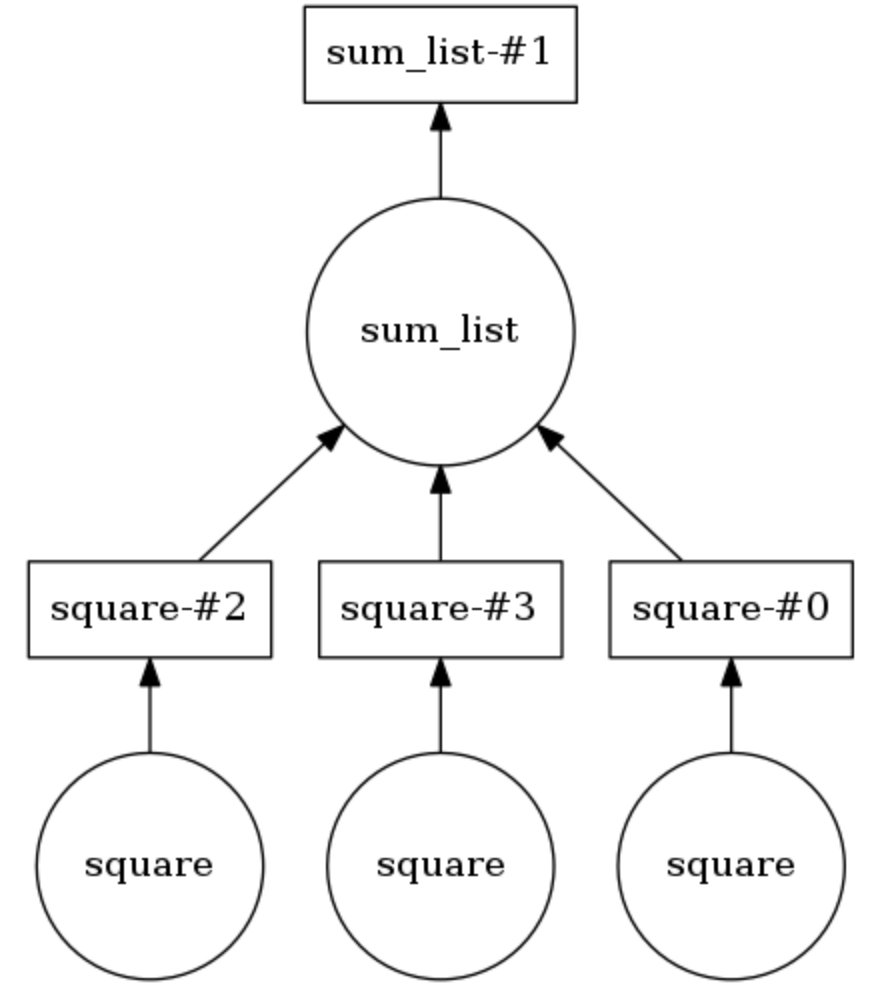
@dask.delayed и вызвать вычислительный метод после выполнения кода цикла.Пример вычислительного графа Dask
В нижеприведенном примере два метода аннотированы
@dask.delayed. Три числа хранятся в списке, их нужно возвести в квадрат, а затем все вместе просуммировать. Dask строит вычислительный граф, обеспечивающий параллельное выполнение метода для возведения в квадрат, после чего результат этой операции передается методу sum_list. Вычислительный граф можно вывести на экран, вызвав calling .visualize(). Calling .compute() выполняет вычислительный граф. Как понятно по выводу, элементы списка обрабатываются не по порядку, а параллельно.Количество потоков можно задать (например,
dask.set_options( pool=ThreadPool(10) ), а также их легко подкачивать, чтобы пользоваться процессами у себя на ноутбуке или ПК (напр., dask.config.set( scheduler=’processes’ ).Итак, я продемонстрировал, насколько тривиально будет добавить параллельную обработку задач в проект из области Data Science при помощи Dask. Незадолго до написания этой статьи я применил Dask, чтобы разделить данные о пользовательских потоках кликов (истории посещений) на 40-минутные сеансы, после чего агрегировать признаки по каждому пользователю для последующей кластеризации. Расскажите, а каким образом вам доводилось использовать Dask!
Комментарии (2)

paantya
01.06.2019 18:14Я верно понимаю, что тут количество потоков, не совсем то, что при классическом распараллеливании?
Тыкался, но до конца не понял, какое значение в зависимости от чего выставлять.
Понятное дело, что чем больше, тем лучше, до какого-то момента, но вот бы понять до какого. В документации не нашёл явного описания (или проморгал :\)
Kordamon
Спасибо за статью. А можно привести примеры кода для самых интересных частей («Параллельная обработка в Dask» и «Пример вычислительного графа Dask»)?