
- CPU лимиты
- Docker и server class machine
- CPU лимиты (да, опять) и фрагментация памяти
- Обрабатываем Java-OOM
- Оптимизируем потребление памяти
- Ограничиваем потребление памяти: heap, non-heap, direct memory
- Ограничиваем потребление памяти: Native Memory Tracking
- Java и диски
- Как за всем уследить?
CPU лимиты
Раньше мы жили в kvm-виртуалках с ограничениями CPU и памяти и, переезжая в Docker, выставили похожие ограничения в cgroups. И первой неувязкой, с которой мы столкнулись, были именно CPU лимиты. Сразу скажу, что эта проблема уже не актуальна для свежих версий Java 8 и Java ? 10. Если вы идёте в ногу со временем, можете смело пропускать этот раздел.
Итак, мы запускаем небольшой сервис в контейнере и видим, что он плодит огромное количество тредов. Или потребляет CPU гораздо больше, чем ожидалось, таймаутится почём зря. Или вот ещё реальная ситуация: на одной машине сервис нормально запускается, а на другой, с теми же настройками — падает, прибитый OOM-киллером.
Разгадка оказывается очень простой — просто Java не видит ограничений
--cpus, выставленных в докере и считает, что ей доступны все ядра хост-машины. А их может быть очень много (в нашем стандартном сетапе — 80).Библиотеки подстраивают размеры тред-пулов под количество доступных процессоров — отсюда огромное количество тредов.
Сама Java таким же образом масштабирует количество тредов GC, отсюда потребление CPU и таймауты — сервис начинает тратить большое количество ресурсов на сборку мусора, используя львиную долю отпущенной ему квоты.
Также библиотеки (в частности Netty) могут в определённых случаях подстраивать размеры офф-хип памяти под количество CPU, что приводит к большой вероятности выхода за выставленные контейнеру лимиты при запуске на более мощном железе.
Сначала, по мере проявления этой проблемы, мы пытались использовать следующие воркэраунды:
— пробовали использовать в паре сервисов libnumcpus — библиотеку, которая позволяет «обмануть» Java, задав иное число доступных процессоров;
— явно указывали количество GC-тредов,
— явно задавали лимиты на использование direct byte buffers.
Но, конечно же, с такими костылями передвигаться не очень удобно, и настоящим решением стал переезд на Java 10 (а затем и Java 11), в котором все эти проблемы отсутствуют. Справедливости ради, стоит сказать, что в восьмёрке тоже всё стало хорошо с апдейта 191, выпущенного в октябре 2018 года. К тому времени для нас это было уже неактуально, чего и вам желаю.
Это один из примеров, когда обновление версии Java даёт не только моральное удовлетворение, но и реальный ощутимый профит в виде упрощения эксплуатации и повышения производительности сервиса.
Docker и server class machine
Итак, в Java 10 появились (и были бекпортированы в Java 8) опции
-XX:ActiveProcessorCount и -XX:+UseContainerSupport, учитывающие по умолчанию лимиты cgroups. Теперь-то всё стало замечательно. Или нет?Через некоторое время после того как мы пересели на Java 10 / 11, мы стали замечать некоторые странности. Почему-то в некоторых сервисах графики GC выглядели так, будто в них не использовался G1:
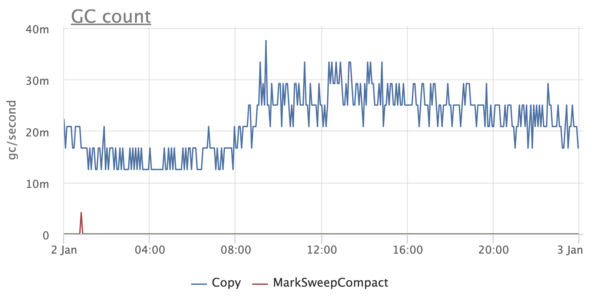
Это было, мягко говоря, немного неожиданно, так как мы точно знали, что G1 является дефолтным коллектором, начиная с Java 9. При этом в каких-то сервисах этой проблемы нет — включается G1, как и ожидалось.
Начинаем разбираться и натыкаемся на интересную вещь. Оказывается, если Java запущена меньше чем на 3 процессорах и с лимитом памяти меньше 2 ГБ, то она считает себя клиентской и не даёт использовать ничего, кроме SerialGC.
К слову, это затрагивает только выбор GC и никак не связано с параметрами -client / -server и JIT-компиляцией.
Очевидно, когда мы пользовались Java 8, она не учитывала лимиты докера и считала, что у неё много процессоров и памяти. После обновления на Java 10 многие сервисы, у которых лимиты выставлены ниже, внезапно стали использовать SerialGC. К счастью, лечится это очень просто — явным выставлением опции
-XX:+AlwaysActAsServerClassMachine.CPU лимиты (да, опять) и фрагментация памяти
Рассматривая графики в мониторинге, мы как-то заметили, что Resident Set Size контейнера чересчур большой — аж в три раза больше чем максимальный размер хипа. Не может ли здесь быть дело в каком-то очередном хитром механизме, который масштабируется по числу процессоров в системе и не знает об ограничениях докера?
Оказывается, механизм вовсе не хитрый — это всем хорошо известный malloc из glibc. Если коротко, то в glibc для выделения памяти используются так называемые арены. При создании каждому треду присваивается одна из арен. Когда тред с помощью glibc хочет выделить определённое количество памяти в нативном хипе под свои нужды и вызывает malloc, то память выделяется в присвоенной ему арене. Если арена обслуживает несколько тредов, то эти треды будут за неё конкурировать. Чем больше арен, тем меньше конкуренции, но тем больше фрагментации, так как у каждой арены свой список свободных областей.
На 64-битных системах количество арен по умолчанию выставляется в 8 * количество CPU. Очевидно, для нас это огромный оверхед, потому что контейнеру доступны не все CPU. Более того, для Java-приложений конкуренция за арены не так актуальна, так как большинство аллокаций делается в Java-хипе, память под который можно целиком выделить при старте.
Эта особенность malloc известна уже очень давно, как и её решение — использовать переменную окружения
MALLOC_ARENA_MAX для явного указания числа арен. Это очень легко сделать для любого контейнера. Вот эффект от указания MALLOC_ARENA_MAX = 4 для нашего основного бэкенда: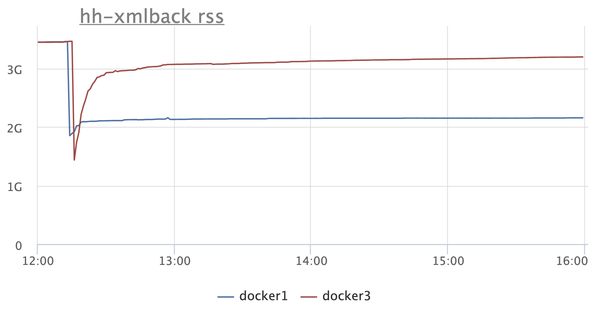
На графике RSS двух инстансов: в одном (синий) включаем
MALLOC_ARENA_MAX, другой (красный) просто рестартуем. Разница очевидна.Но после этого возникает резонное желание разобраться, на что Java вообще тратит память. Можно ли запустить на Java микросервис с лимитом памяти в 300-400 мегабайт и не бояться, что он упадёт с Java-OOM или не будет прибит системным OOM-киллером?
Обрабатываем Java-OOM
Прежде всего, надо подготовиться к тому, что OOM неизбежны, и надо их правильно обрабатывать — как минимум сохранять хип-дампы. Как ни странно, даже в этой простой затее есть свои нюансы. К примеру, хип-дампы не перезаписываются — если уже сохранён хип-дамп с тем же именем, то новый просто не будет создан.
Java умеет автоматически добавлять порядковый номер дампа и process id в название файла, но это нам ничем не поможет. Порядковый номер не пригодится, потому что это OOM, а не штатно запрошенный хипдамп — приложение после него рестартует, обнуляя счётчик. А process id не подходит, так как в докере он всегда одинаковый (чаще всего 1).
Поэтому мы пришли к такому варианту:
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-XX:HeapDumpPath=/var/crash/java.hprof
-XX:OnOutOfMemoryError="mv /var/crash/java.hprof /var/crash/heapdump.hprof"Он довольно прост и при некоторых доработках можно даже научить хранить его не только последний хипдамп, но для наших нужд и этого более чем достаточно.
Java OOM — это не единственное, с чем нам придётся столкнуться. У каждого контейнера есть ограничение на занимаемую им память, и оно может быть превышено. Если так происходит, то контейнер убивается системным OOM-киллером и рестартует (мы используем
restart_policy: always). Естественно, это нежелательно, и мы хотим научиться правильно выставлять лимиты на используемые JVM ресурсы.Оптимизируем потребление памяти
Но прежде чем настраивать лимиты, нужно убедиться, что JVM не тратит ресурсы впустую. Мы уже сумели сократить потребление памяти с помощью лимита на количество CPU и переменной
MALLOC_ARENA_MAX. Есть ли ещё какие-то «почти бесплатные» способы это сделать?Оказывается, есть ещё пара трюков, которые позволят сэкономить немного памяти.
Первый — это использование опции
-Xss (или -XX:ThreadStackSize), контролирующей размер стека для тредов. По умолчанию для 64-битной JVM это 1 МБ. Мы выяснили, что нам хватает и 512 КБ. StackOverflowException пока из-за этого ни разу не ловили, но допускаю, что подойдёт это далеко не всем. Да и профит от этого совсем небольшой.Второй — флаг
-XX:+UseStringDeduplication (при включённом G1 GC). Он позволяет сэкономить на памяти, схлопнув дублирующиеся строки за счёт дополнительной нагрузки на процессор. Трейдоф между памятью и CPU зависит только от конкретного приложения и настройки самого механизма дедупликации. Читайте доку и тестируйте в своих сервисах, у нас эта опция пока не нашла своего применения.И, наконец, способ, который тоже подойдёт не всем (но нам зашло) — использовать jemalloc вместо родного malloc. Эта имплементация заточена на уменьшение фрагментации памяти и лучшую поддержку многопоточности по сравнению с malloc из glibc. Для наших сервисов jemalloc дал немного больше выигрыша по памяти, чем malloc с
MALLOC_ARENA_MAX=4, при этом не сказавшись сколько-нибудь заметно на производительности.Остальные варианты, в том числе описанные у Алексея Шипилёва в JVM Anatomy Quark #12: Native Memory Tracking, показались довольно опасными либо приводили к заметной деградации производительности. Тем не менее, в образовательных целях рекомендую прочесть эту статью.
А пока двинемся к следующей теме и, наконец, попробуем научиться ограничивать потребление памяти и подбирать правильные лимиты.
Ограничиваем потребление памяти: heap, non-heap, direct memory
Чтобы всё правильно сделать, надо вспомнить, из чего вообще состоит память в Java. Для начала посмотрим на пулы, состояние которых можно замониторить через JMX.
Первое, само собой, хип. Тут всё просто: задаём
-Xmx, но как сделать это правильно? К сожалению, универсального рецепта тут нет, всё зависит от приложения и профиля нагрузки. Для новых сервисов мы начинаем с относительно разумного размера хипа (128 Мб) и при необходимости увеличиваем или уменьшаем его. Для поддержки уже существующих есть мониторинг с графиками потребления памяти и метриками GC.Одновременно с
-Xmx мы выставляем -Xms == -Xmx. У нас нет оверселлинга памяти, поэтому в наших интересах, чтобы сервис по максимуму использовал те ресурсы, которые мы ему выдали. В дополнение, в рядовых сервисах мы включаем -XX:+AlwaysPreTouch и механизм Transparent Huge Pages: -XX:+UseTransparentHugePages -XX:+UseLargePagesInMetaspace. Однако, прежде чем включать THP, внимательно прочитайте документацию и протестируйте, как сервисы ведут себя с этой опцией в течение длительного времени. Не исключены сюрпризы на машинах с недостаточным запасом оперативной памяти (к примеру, нам пришлось выключить THP на тестовых стендах).Далее — non-heap. В non-heap память входят:
— Metaspace и Compressed Class Space,
— Code Cache.
Рассмотрим эти пулы по порядку.
Про Metaspace, конечно же, все слышали, не буду подробно про него рассказывать. В нём хранятся метаданные классов, байткод методов и так далее. По сути, использование Metaspace напрямую зависит от числа и размера загруженных классов и определить его можно, как и хип, только запустив приложение и сняв метрики через JMX. По умолчанию Metaspace ничем не ограничен, но сделать это довольно легко с помощью опции
-XX:MaxMetaspaceSize.Compressed Class Space входит в состав Metaspace и появляется, когда включена опция
-XX:+UseCompressedClassPointers (включена по умолчанию для хипов меньше 32 ГБ, то есть когда она может дать реальный выигрыш по памяти). Размер этого пула можно ограничить опцией -XX:CompressedClassSpaceSize, но особого смысла в этом нет, так как Compressed Class Space включается в Metaspace и суммарный объём закоммиченной памяти для Metaspace и Compressed Class Space в итоге ограничивается одной опцией -XX:MaxMetaspaceSize.Кстати, если смотреть на показания JMX, то там объём non-heap памяти всегда рассчитывается как сумма Metaspace, Compressed Class Space и Code Cache. На самом деле надо суммировать только Metaspace и CodeCache.
Итак, в non-heap остался только Code Cache — хранилище скомпилированного JIT-компилятором кода. По умолчанию его максимальный размер выставлен в 240 МБ и для небольших сервисов это в несколько раз больше, чем нужно. Размер Code Cache можно выставить опцией
-XX:ReservedCodeCacheSize. Правильный размер можно определить, только запустив приложение и проследив за ним под типичным профилем нагрузки.Тут важно не ошибиться, так как недостаточный размер Code Cache приводит к удалению из кеша холодного и старого кода (опция
-XX:+UseCodeCacheFlushing включена по умолчанию), а это, в свою очередь, может привести к более высокому потреблению CPU и к деградации производительности. Было бы здорово, если можно было кидать OOM при переполнении Code Cache, для этого даже есть флаг -XX:+ExitOnFullCodeCache, но, к сожалению, он доступен только в девелоперской версии JVM.Последний пул, о котором есть информация в JMX, — direct memory. По умолчанию его размер не ограничен, поэтому важно задать ему какой-то лимит — как минимум на него будут ориентироваться библиотеки вроде Netty, активно использующие direct byte-буфферы. Задать лимит несложно при помощи флага
-XX:MaxDirectMemorySize, а в определении правильного значения нам, опять же, поможет только мониторинг.Итак, что у нас пока получается?
Java process memory =
Heap + Metaspace + Code Cache + Direct Memory =
-Xmx +
-XX:MaxMetaspaceSize +
-XX:ReservedCodeCacheSize +
-XX:MaxDirectMemorySizeДавайте попробуем нарисовать всё на графике и сравнить с RSS докер-контейнера.
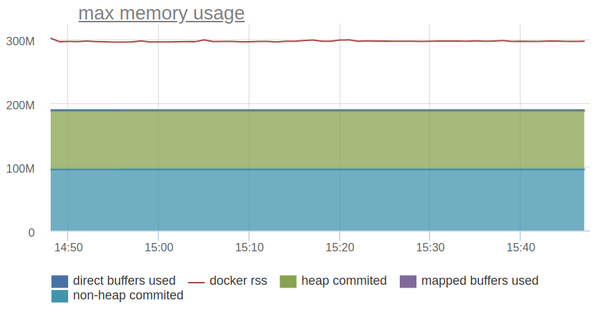
Линия сверху — это RSS контейнера и он раза в полтора больше, чем потребление памяти JVM, которое мы можем замониторить через JMX.
Копаем дальше!
Ограничиваем потребление памяти: Native Memory Tracking
Разумеется, помимо heap, non-heap и direct memory, JVM использует целую кучу других пулов памяти. Разобраться с ними нам поможет флаг
-XX:NativeMemoryTracking=summary. Включив эту опцию, мы сможем получать информацию о пулах, известных JVM, но недоступных в JMX. Подробнее об использовании этой опции можно почитать в документации.Начнём с самого очевидного — памяти, занимаемой стеками тредов. NMT выдаёт для нашего сервиса примерно следующее:
Thread (reserved=32166KB, committed=5358KB)
(thread #52)
(stack: reserved=31920KB, committed=5112KB)
(malloc=185KB #270)
(arena=61KB #102)Кстати, её размер можно узнать и без Native Memory Tracking, воспользовавшись jstack и немного поковырявшись в
/proc/<pid>/smaps. Андрей Паньгин выкладывал специальную утилиту для этого.Размер Shared Class Space оценить ещё проще:
Shared class space (reserved=17084KB, committed=17084KB)
(mmap: reserved=17084KB, committed=17084KB)Это механизм Class Data Sharing, включаемый опциями
-Xshare и -XX:+UseAppCDS. В Java 11 опция -Xshare по умолчанию выставлена в auto, а это значит, что если у вас есть архив $JAVA_HOME/lib/server/classes.jsa (в официальном докер-образе OpenJDK он есть), то он будет загружаться memory map-ом при старте JVM, ускоряя время запуска. Соответственно, размер Shared Class Space легко определить, если вы знаете размер jsa-архивов.Далее идут нативные структуры сборщика мусора:
GC (reserved=42137KB, committed=41801KB)
(malloc=5705KB #9460)
(mmap: reserved=36432KB, committed=36096KB)У Алексея Шипилёва в уже упомянутом руководстве по Native Memory Tracking сказано, что они занимают примерно 4-5% от размера хипа, но в нашем сетапе для небольших хипов (до нескольких сотен мегабайт) оверхед доходил до 50% от размера хипа.
Довольно много места могут занимать таблицы символов:
Symbol (reserved=16421KB, committed=16421KB)
(malloc=15261KB #203089)
(arena=1159KB #1)В них хранятся названия методов, сигнатуры, а также ссылки на интернированные строки. К сожалению, оценить размер таблицы символов представляется возможным только пост-фактум, с помощью Native Memory Tracking.
Что остаётся? Согласно Native Memory Tracking довольно много всего:
Compiler (reserved=509KB, committed=509KB) Internal (reserved=1647KB, committed=1647KB) Other (reserved=2110KB, committed=2110KB) Arena Chunk (reserved=1712KB, committed=1712KB) Logging (reserved=6KB, committed=6KB) Arguments (reserved=19KB, committed=19KB) Module (reserved=227KB, committed=227KB) Unknown (reserved=32KB, committed=32KB)
Но на всё это уходит довольно мало места.
К сожалению, многие из упомянутых областей памяти нельзя ни ограничить, ни контролировать, а если и можно было бы, то конфигурация превратилась бы в сущий ад. Даже наблюдение за их состоянием — нетривиальная задача, так как включение Native Memory Tracking немного просаживает производительность приложения и включать его на продакшене в критичном сервисе — не лучшая идея.
Всё же, ради интереса попробуем отразить на графике всё, о чём сообщает Native Memory Tracking:

Неплохо! Оставшаяся разница — это оверхед на фрагментацию / аллокацию памяти (он совсем небольшой, так как мы используем jemalloc) или память, которую выделили нативные либы. Мы как раз пользуемся одной такой для эффективного хранения префиксного дерева.
Итак, для наших нужд достаточно ограничить то, что можно: Heap, Metaspace, Code Cache, Direct Memory. На всё остальное мы оставляем некий разумный задел, определяемый по результатам практических замеров.
Разобравшись с CPU и памятью, переходим к следующему ресурсу, за который могут конкурировать приложения — к дискам.
Java и диски
И с ними всё очень плохо: они медленные и могут приводить к ощутимым затупам приложения. Поэтому мы максимально отвязываем Java от дисков:
- Все логи приложения мы пишем в локальный сислог по UDP. Это оставляет некоторую вероятность, что нужные логи потеряются где-то по пути, но, как показала практика, такие случаи очень редки.
- Логи JVM будем писать в tmpfs, для этого нужно всего лишь подмонтировать в докере в нужное место волюмом
/dev/shm.
Если мы пишем логи в сислог или в tmpfs, а само приложение ничего, кроме хип-дампов, на диск не пишет, то выходит, что на этом историю с дисками можно считать закрытой?
Конечно же, нет.
Обращаем внимание на график длительности stop-the-world пауз и видим печальную картину — Stop-The-World-паузы на хостах по сотням миллисекунд, а на одном хосте вообще могут доходить до секунды:
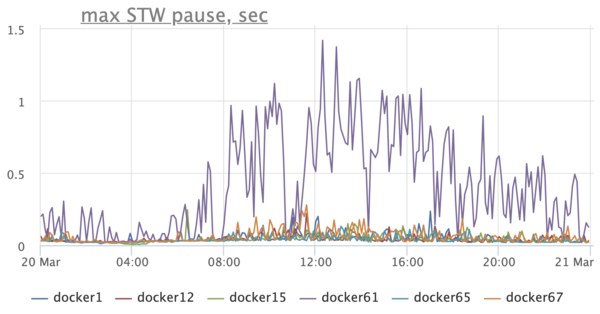
Надо ли говорить, что это негативно сказывается на работе приложения? Вот, к примеру, график, отражающий время ответа сервиса по мнению клиентов:
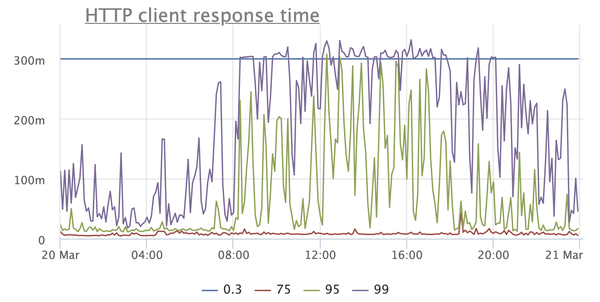
Это очень простой сервис, по большей части отдающий закешированные ответы, так откуда там такие запредельные тайминги, начиная с 95 персентили? В других сервисах аналогичная картина, к тому же с завидным постоянством сыпятся таймауты при взятии коннекшена из пула соединений к базе, при выполнении запросов и так далее.
При чём же тут диски? — спросите вы. Оказывается, очень даже при чём.
Детальный разбор проблемы показал, что долгие STW-паузы возникают из-за того, что треды долго идут до сейфпойнта. Почитав код JVM, мы поняли, что во время синхронизации тредов на сейфпойнте JVM может записывать через memory map файл
/tmp/hsperfdata*, в который она экспортирует некоторую статистику. Этой статистикой пользуются утилиты типа jstat и jps.Отключаем её на одной машине опцией
-XX:+PerfDisableSharedMem и…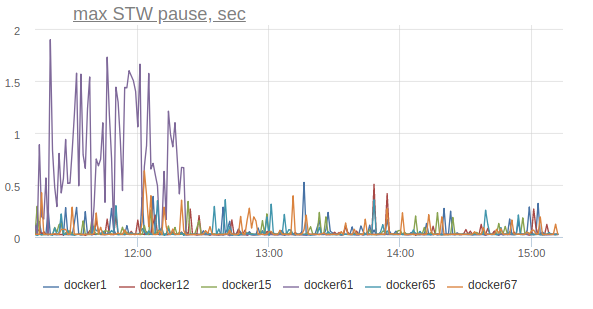
Метрики тредпула Jetty стабилизируются:
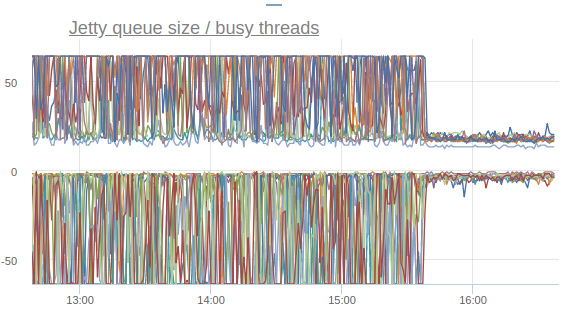
А персентили времени ответа начинают приходить в норму (повторюсь, это эффект от включения опции только на одной машине):
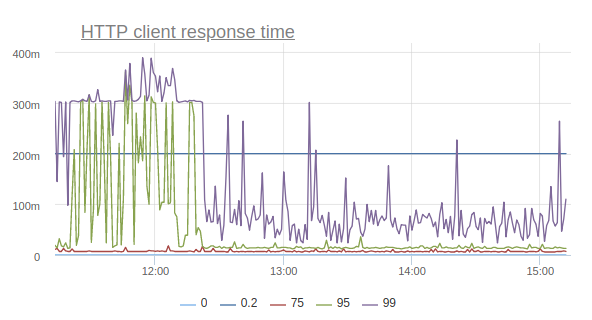
Таким образом, благодаря выключению одной опции мы сумели снизить количество таймаутов, количество ретраев, и даже поправить общие персентили времени ответа сайта.
Как за всем уследить?
Для того чтобы поддерживать Java-сервисы в докере, нужно, прежде всего, научиться за ними следить.
Мы запускаем свои сервисы на базе собственного фреймворка Nuts and Bolts, и поэтому можем обвесить все критичные места нужными нам метриками. В дальнейшем это очень сильно помогает при расследовании инцидентов и вообще в понимании того, как сервис живёт на продакшене. Метрики мы посылаем в статсд, на практике это оказывается более удобно, чем JMX.
По метрикам мы стараемся строить графики, отражающие внутреннее состояние сервиса и позволяющие быстро диагностировать причины аномалий. Некоторые из подобных графиков я уже приводил в пример выше.
Мы также отправляем в statsd и внутренние метрики JVM, например потребление памяти (heap, верно посчитанный non-heap и общую картину):
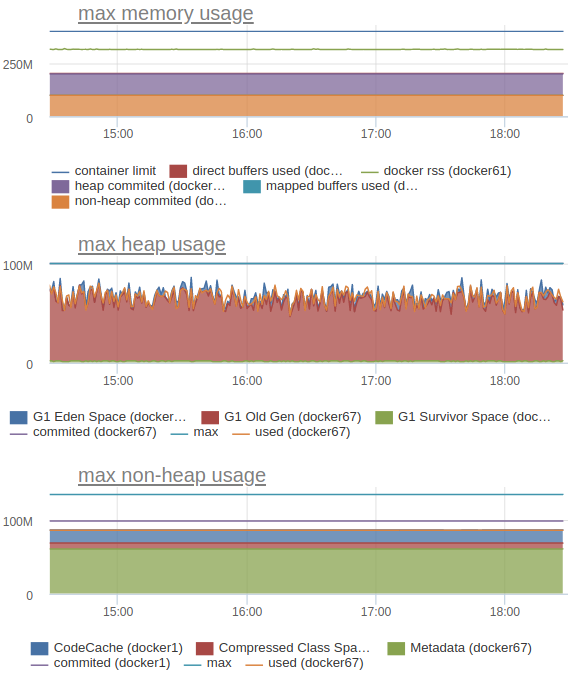
В частности, это позволяет нам понимать, какие лимиты выставлять для каждого конкретного сервиса.
Ну и напоследок — как на постоянной основе следить за тем, что лимиты выставлены грамотно, а сервисы, живущие на одном хосте, не мешают друг другу? В этом нам сильно помогает ежедневное нагрузочное тестирование. Так как у нас (пока) два дата-центра, то нагрузочное тестирование настроено так, чтобы увеличивать RPS на сайте вдвое.
Механизм нагрузочного тестирования очень прост: утром запускается крон, который парсит логи за предыдущий час и формирует из них профиль типичной анонимной нагрузки. К анонимной нагрузке добавляется ряд работодательских и соискательских страниц. После этого профиль нагрузки экспортируется в формат ammo-файлов для Яндекс.Танка. В заданное время Яндекс.Танк стартует:
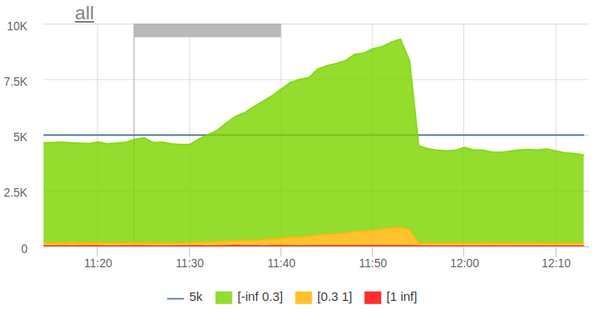
Нагрузка автоматически останавливается при превышении небольшого порога пятисоток.
За время своего существования нагрузочное тестирование позволило нам выявить целый ряд проблем ещё до того, как они зааффектили реальных пользователей. Кроме того, оно даёт нам уверенность в том, что при выпадении одного дата-центра другой, оставшийся в живых, выдержит всю нагрузку.
В заключение
Наш опыт показывает, что Java в Docker — это не только удобно, но и в итоге довольно экономично. Надо только научиться их готовить.
Комментарии (19)

agzamovr
31.05.2019 19:49+1Отличная статья, спасибо большое!
Поправьте -XX+AlwaysActAsServerClassMachine на-XX:+AlwaysActAsServerClassMachine. И переменная окружения должна бытьMALLOC_ARENA_MAXвместоMALLOC_ARENAS_MAX.
Hixon10
01.06.2019 00:34+1Спасибо за статью!
Еще можно послушать доклад Дмитрия — www.youtube.com/watch?v=m1XIdu2IKnM&list=PLojTLDAO4jjIRjDPIQjc4iG7CfR6m8pfc&index=4&t=0s

slonopotamus
01.06.2019 14:04Есть ли смысл в MALLOC_ARENA_MAX>1 для JVM?
Montmorency Автор
01.06.2019 17:25Безусловно есть, чем больше арен, тем меньше конкуренции за них при вызове malloc. Но это с точки зрения теории, на практике всё зависит от приложения. Для наших типовых сервисов сокращение числа арен до 4 не повлияло никак на их производительность. Больше мы не эксперименировали, т.к. jemalloc зашёл лучше.
slonopotamus
01.06.2019 17:54Вы вот вроде бы что-то ответили, но что — я так и не понял. Смысл есть, но зависит от приложения, но вы не пробовали.
Montmorency Автор
01.06.2019 19:04Попробую развернуть)
Чем меньше арен, тем больше contention при использовании malloc. Теоретически это может привести к деградации производительности (тут всё зависит от приложения — насколько интенсивно в нём используется malloc).
На наших типовых сервисах мы не заметили никакого проседания при уменьшении числа арен с 640 (8 * 80) до 4. Ещё меньше ставить не пробовали, так как стали повсеместно внедрять jemalloc.
Cloud66
01.06.2019 17:13Очень интересная статья, но есть множество спорных моментов.
Вы отключаете overcommit памяти в Ось?
Если нет, то по сути большинство ограничений не уменьшают потребление памяти, если помнить о «ленивом» выделении памяти линуксом. Даже commited memory в NMT не отображает потребление памяти, а лишь максимальное, если jvm ее затребует. Поэтому, большинством этих настроек просто промениваете OOMKiller на OutOfMemoryError, StackOverFlow и т.д. Не знаю, есть ли такая цель, мне кажется общее ограничение дополнительно дает возможность для перераспределения памяти между областями если понадобится (overcommit).
1.-XX:ThreadStackSize ограничивает максимальный размер стэка потока, если вашим потоком столько не нужно, память не расходуется по 1мб на стэк, минимум от 228кб, то того размера который нужен. Уменьшение параметра потребление RSS не уменьшит
2. MALLOC_ARENA_MAX аналогично, в вашей же ссылке на сайт ibm какой-то бред, считать превышение vsz над rss мемори ликом и чинить это, хотя как раз и написано, что они оптимизируют virtual memory size, вы тоже оптимизируете vsz? Непонятно тогда откуда у вас график по уменьшению rss, наверняка это не rss, так как настройка влияет только на virtual memory, на RSS не влияет.
3. Code cache аналогично, если вы знаете что 240мб у вас не потребляется, то значит и памяти столько не используется. Ограничить можно, думаю что вытеснение кода при переполнении все таки менее болезненно, чем OOMKiller, но вы же хотите делать ExitOnFullCodeCache, значит вас это не волновало.
4. MaxMetaSpace аналогично, потребляется столько сколько нужно. Ставя настройку вы просто ограничиваете потенциальную утечку этим разделом, чтобы получить OutOfMemoryError, а не OOMKiller
slonopotamus
01.06.2019 17:57По пункту 2. MALLOC_ARENA_MAX влияет именно на RSS, мы тоже с этим сталкивались: slonopotamus.livejournal.com/186275.html
Cloud66
01.06.2019 18:39В вашей статье из 4 ссылок 3 про virtual memory size и в одной про native memory leak. Да выходит если есть memory leak, то уменьшение кол-ва арен зажмет утечку в меньших рамках, это все объясняет, согласен, и если не удается починить утечку, то нужно уменьшать,
slonopotamus
01.06.2019 18:54Конкретно в нашем случае никакой утечки не было. Но пиковое необходимое количество памяти превышало имеющуюся в наличии оперативку.
Montmorency Автор
01.06.2019 19:01Спасибо за вопросы, попробую ответить по пунктам.
1. Честно говоря, не припомню, чтобы документация описывала ThreadStackSize как максимальный размер стека. Пруфа в виде ссылки на код у меня, к сожалению, под рукой нет, однако практика показывает, что объём закоммиченной под пул Threads памяти (по показаниям native memory tracking) уменьшается с уменьшением -XX:ThreadStackSize, независимое подтверждение есть у Алексея Шипилева в JVM Anatomy Quark #12: Native Memory Tracking.
2. На графике изображён именно RSS (метрика, которую сообщает cgroups). Большое число арен (которое масштабируется по числу цпу на хосте) ведёт к неоправданной фрагментации памяти, естественно это отражается на RSS.
3 и 4. Да, вы правы, от ограничения CodeCache и Metaspace JVM не начнёт потреблять меньше памяти, поэтому они в разделе «ограничения», а не «оптимизации». Для нас основной вопрос был в том, есть ли смысл разрешать приложению потреблять 240 Мб, когда ему больше 32 не нужно. Так что речь тут речь в основном о рациональном использовании ресурсов (лимиты в cgroups можем выставить поменьше и знать точно, сколько каких контейнеров поместится в хост-машину). Ну и получить Java-ООМ приятнее, чем системный — не надо лишний раз гадать что израсходовало память (для полного счастья не хватает ExitOnFullCodeCache).Cloud66
01.06.2019 19:241. commited memory != RSS, при дефолтных настройках vm.overcommit_memory,
vm.overcommit_ratio на linux.Montmorency Автор
01.06.2019 21:30Я немного не о том. JVM (насколько я понимаю этот механизм) при создании треда вызывает pthread_attr_setstacksize со значением, высчитанным как раз из ThreadStackSize.
pthread_attr_setstacksize задаёт минимальный размер стека (он же становится максимальным для не-main треда): man7.org/linux/man-pages/man3/pthread_attr_setstacksize.3.html
ViceCily
01.06.2019 17:58Спасибо за статью. Спорные моменты конечно есть, но однозначно годится в качестве отправной точки в оптимизации размеров контейнеров с java-приложениями.
Montmorency Автор
01.06.2019 19:07Если не трудно — можете озвучить? (понятно, что многое зависит от конкретных сервисов, профиля нагрузки, я старался по это оговаривать) Возможно смогу более развёрнуто что-то изложить.
qasta
03.06.2019 19:06Наш опыт показывает, что Java в Docker — это не только удобно, но и в итоге довольно экономично. Надо только научиться их готовить.
С учётом того, что до этого у вас был kvm, а теперь Docker, в чём именно вышла экономия? Вы подходили с реальными цифрами (например, что с той же самой нагрузкой справляется парк машин на 20% серверов меньше и т.п.)? Ну или требуется меньше дискового пространства на 40%? Я про реальные цифры. Это было бы очень интересно узнать.Montmorency Автор
04.06.2019 11:42+1Передал этот вопрос нашей команде эксплуатации:
Экономия по оперативной памяти — в kvm виртуалке свое ядро, система и стек приложений, на это 500-1000MB памяти надо закладывать, а это примерно двойной оверхед для мелких сервисов. Плюс контейнер может отдать память в систему сразу, а виртуалка только после рестарта (kvm baloon у нас приводил к проблемам).
По объёму и пропускной способности диска ещё выиграли — на каждую виртуалку раньше выделяли образ минимум по 10GB, c учётом того что у нас до 30 контейнеров на хост — это уже значительный оверхед на пустом месте, потому что большая часть железа работает в блейдах, где максимум 2 диска 2.5". И в нехватку дискового пространства гораздо чаще бы упирались — предсказать сколько места понадобится заранее не всегда возможно.
Производительность дисковой подсистемы с kvm отличается в разы от хостовой с некоторыми драйверами, до 200% оверхеда спокойно могло быть в некоторых случаях.
Ну и оверхед управления этим всем — рулить 1000 виртуалок вместо 1000 контейнеров с учётом прочих задач — это ещё наверное пару человек пришлось бы нанимать (тот же ресайз образа виртуалки это не самая быстрая задача, + ковыряние с srv-iov и настройками на каждой виртуалке). Релизы бы стали медленнее, если бы каждый плейбук еще системные конфиги на машины приносил, как было раньше
nerumb
Спасибо за статью!