
— Рад вас всех приветствовать. Меня зовут Владимир, я занимаюсь общими штуками в интерфейсах Яндекса. Про них и хочу поговорить. Наверное, если вы не очень глубоко пользуетесь нашими сервисами, у вас может возникнуть вопрос: что мы все верстаем? Что там верстать?


Есть какой-то список ответов в поисковой выдаче, иногда еще справа колонка. Каждый из вас наверняка за день справится. Если вспомнить, что есть разные браузеры и так далее, то добавим еще день на исправления багов, и тогда уже точно каждый справится.
Кто-то вспомнит, что есть еще такой интерфейс. На него с учетом всяких мелочей можно дать еще неделю и на этом разойтись. А Дима только что рассказывал, что нас так много, что нам нужна целая своя школа. И все эти люди все время верстают странички. Каждый день приходят на работу и верстают, представляете? Явно есть что-то еще.

На самом деле сервисов в Яндексе, действительно, поболее. И их даже чуть поболее, чем на этом слайде. За каждой такой ссылкой стоит куча разных интерфейсов с огромной вариативностью. Они есть для разных устройств, на разных языках. Они работают иногда даже в автомобилях и прочих разных странных вещах.

Яндекс сегодняшний — это не только веб, не только разные товары со складами, доставкой и всем таким. Машинки желтые ездят. И даже не только то, что можно съесть, и не только железяки. И не только всякие автоматические интеллекты. Но все перечисленное объединяет то, что для каждого пункта нужны интерфейсы. Зачастую — очень богатые. Яндекс — это сотни разных огромных сервисов. Мы постоянно создаем что-то новое, каждый день. У нас трудятся тысячи сотрудников, среди которых сотни именно фронтендеров, разработчиков интерфейсов. Эти люди работают в разных офисах, живут в разных часовых поясах, на работу постоянно приходят новые ребята.
При этом мы, насколько нам хватает сил, стараемся, чтобы он был однообразен, един для пользователей.

Это выдача поиска по документам в интернете. Но если мы перейдем на выдачу по картинкам — шапка совпадает, несмотря на то, что это отдельный репозиторий, которым занимается абсолютно отдельная команда, возможно, даже на других технологиях. Казалось бы, что там сложного? Ну сверстали два раза шапку, вроде дело нехитрое. За каждой кнопочкой в шапке тоже свой отдельный богатый внутренний мир. Тут появляются какие-то попапы, там тоже что-то можно понажимать. Все это переводится на разные языки, работает на разных платформах. И вот мы переходим с картинок, например, на видео, и это снова новый сервис, другая команда. Опять другой репозиторий. Но все равно та же шапка, хотя есть отличия. И все это нужно оставить единообразным.
Чего стоит, переключаясь вот так по слайдам, убедиться, что ничего никуда на пиксель не съехало? Мы стараемся, чтобы этого не происходило.

Чтобы еще чуть-чуть показать масштаб, я взял скриншот репозитория, который хранит только код фронтенда для новых браузеров — только выдачи по документам, без картинок и видео. Тут десятки тысяч коммитов и почти 400 контрибьюторов. Это только в верстке, только один проект. Вот список синих ссылок, который вы привыкли видеть.
Сергей Бережной, мой руководитель, очень любит эту историю, что раз уж нас так много собралось в компании — хочется, чтобы от нашего взаимодействия суммарно получалось как в JavaScript: один плюс один больше, чем два.
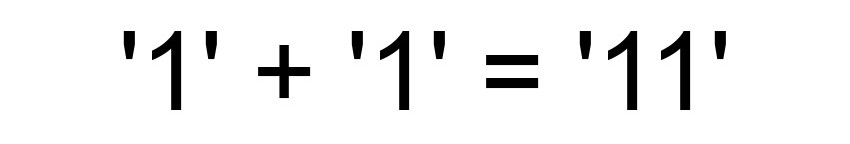
И мы пытаемся получить все что можно от взаимодействия. Первое, что приходит в голову в таких условиях, — повторное использование. Вот, например, сниппет видео на сервисе в поисковой выдаче по видео. Это какая-то картинка с подписью и еще какие-то разные элементы.
Если смотреть дальше, то вот обычная выдача по документам. Но здесь тоже есть точно такой же сниппет.

Или, вот, допустим, есть отдельный сервис Яндекс.Эфир, который чуть менее чем полностью состоит из похожих сниппетов.

Или, допустим, сниппет видео в нотификаторе, который есть на разных страницах портала.
Или вот сниппет видео, когда вы добавляете его в ваше Избранное, а потом смотрите его в ваших Коллекциях.

Похоже? Очевидно, похоже. И что? Если мы действительно позволим сервисам свои готовые компоненты легко внедрить на другие сервисы портала, то, очевидно, этот сервис, за счет того, что пользователи смогут взаимодействовать с их данными на разных площадках, получит больше пользователей. Это здорово. Пользователи от этого тоже выиграют. Они будут видеть одинаковые штучки одинаково. Они будут вести себя привычно. То есть не придется каждый раз заново угадывать, что тут имел в виду дизайнер, и как с этим взаимодействовать.
И, наконец, компания от этого получит очевидную экономию. Причем, это только кажется — чего там верстать превьюшку видео и какую-то подпись/ На самом деле чтобы она получилась именно такой, нужно провести уйму разных экспериментов, проверить разные гипотезы, подобрать размеры, цвета, отступы. Какие-то элементы добавить, возможно, потом убрать, потому что они не полетели. И то, что получилось, то, что действительно работает, — результат очень длительного процесса. И если каждый раз в каждом новом месте делать его заново, это огромное количество усилий.
А теперь представьте. Допустим, мы получили что-то, хорошо работающее. Везде-везде внедрили, а потом провели новый эксперимент и поняли, что можно еще улучшить. И опять нам придется повторить всю эту цепочку внедрения. Дорого.

О'кей, вроде очевидно, переиспользовать хорошо. Но теперь нам приходится решить целый ряд новых вопросов. Нужно понять, где хранить такой новый код. С одной стороны, вроде бы, логично. Вот у нас есть сниппет видео, его делает команда видео, у них есть репозиторий с их проектом. Наверное, надо положить туда. Но как его потом распространить в остальные репозитории всех других ребят? А если другие ребята захотят что-то свое привнести в этот сниппет? Опять не понятно.
Нужно как-то это версионировать. Нельзя что-то поменять, и чтобы оно, вуаля, всем внезапно раскатилось. Нужно как-то тестировать. Причем, мы, допустим, протестировали это на сервисе самого видео. Но что, если при интеграции в другой сервис что-то сломается? Опять не понятно.
Нужно как-то, в конце концов, обеспечить достаточно быструю доставку на разные сервисы, потому что будет странно, если у нас где-то предыдущая версия, где-то новая. Пользователь вроде кликает на одно и то же, а там разное поведение. И нам нужно как-то обеспечить возможность разработчикам разных команд вносить изменения в такой общий код. Нужно как-то научить их всем этим пользоваться. У нас достаточно долгий путь к тому, чтобы повторное использование интерфейсов стало удобным.

Начинали мы в незапамятные времена, еще в SVN, и было лампово и удобно: папочка с HTML, прямо как в Bootstrap. Вы его копипастите к себе. Рядом папочка со стилями, какой-то там JS, который тогда умел что-то просто показать/скрыть. И все.

Как-то так выглядел список компонентов. Здесь подсвечен b-domeg, который отвечал за авторизацию. Возможно, вы еще помните, на Яндексе, действительно, была такая форма для логина и пароля, с крышей. Мы называли «домик», хотя она намекала на почтовый конверт, потому что входили, обычно, в почту.
Потом мы придумали целую методологию, чтобы иметь возможность поддерживать общие интерфейсы.

Сама библиотека внутри компании обзавелась собственным сайтом с поиском и всякой таксономией.

Репозиторий сейчас выглядит вот так. Видите, тоже почти 10 тысяч коммитов и более 100 контрибьюторов.

А вот это папка того самого b-домика в новой реинкарнации. Сейчас она выглядит вот так. Там внутри уже собственных папок больше, чем на пол-экрана.

А так выглядит сайт на сегодняшний день.

В итоге, общая библиотека используется в более чем 360 репозиториях внутри Яндекса. И есть разные реализации, отлаженный релизный цикл и т. д. Казалось бы, вот, получили общую библиотеку, давайте ее теперь везде использовать, и все здорово. Проблема внедрения общих штучек куда угодно решена. На самом деле нет.

Пытаться решить проблему повторного использования на этапе, когда у вас уже есть готовый сверстанный код, слишком поздно. Это означает, что от момента, когда дизайнер нарисовал макеты сервисов, раздал их в сервисы, и, в том числе, в команду, которая занимается общими компонентами, уже прошло какое-то время. Скорее всего, к этому времени окажется так, что на каждом отдельном сервисе, или хотя бы на нескольких из них, этот же элемент интерфейса тоже сверстали. Сверстали как-то по-своему.
И даже если потом в общей библиотеке появилось общее решение, все равно окажется так, что вам придется теперь заново перевнедрять все то, что успели понаверстать на каждом сервисе. И это опять проблема. Очень сложно обосновать. Вот сидит команда. У нее есть свои цели, все уже хорошо работает. И мы такие говорим — смотрите, наконец-то у нас есть общая штучка, возьмите ее. А команда такая — у нас и так работы хватает. Зачем нам? Тем более, вдруг там что-то не будет подходить нам? Не хотим.
Вторая большая проблема — это, на самом деле, распространение информации о том, что есть эти клевые новые компоненты. Просто потому, что очень много разработчиков, они заняты своими ежедневными задачами. И у них возможности сидеть и изучать, что там происходит в районе общего, что бы это ни значило, на самом деле, тоже нет.
И самая большая проблема, это то, что принципиально невозможно одной какой-то специально выделенной командой решить проблемы общего для всех-всех сервисов. То есть, когда у нас есть команда, которая занимается видео, и она делает свой сниппет с видео, понятно, что мы с ними договоримся и сделаем этот сниппет в какой-то централизованной библиотеке. Но таких примеров на разных сервисах встречается прямо тысячи. И тут уж точно никаких рук не хватит. Поэтому единственное решение — общими компонентами должны все время заниматься вообще все.

И начать нужно, как ни странно, не с разработчиков интерфейсов, а с дизайнеров. Они это тоже понимают. У нас внутри происходит несколько одновременных попыток, чтобы этот процесс сошелся. Дизайнеры делают дизайн-системы. Я очень надеюсь, что рано или поздно получится свести их в единую общую систему, которая учитывает все потребности.

Сейчас их несколько. Как ни удивительно, задачи там стоят ровно такие же: чтобы ускорить процесс разработки, чтобы решить проблему консистентности, не изобретать заново велосипеды и не дублировать проделанную работу.

А один из способов решить проблему донесения информации — позволить разработчикам познакомиться с другими командами, включая ту, которая занимается общими компонентами интерфейсов. Мы ее с этой стороны решаем тем, что у нас появился Буткемп, который при появлении разработчика в Яндексе первым делом позволяет ему в течение восьми недель походить в разные команды, посмотреть, как там что устроено, и потом сделать выбор, где он будет работать окончательно. Но за это время у него заметно расширится кругозор. Он будет ориентироваться, где что есть.
Про общие вещи поговорили. Давайте теперь посмотрим, как это все выглядит уже ближе к процессу разработки. Допустим, у нас есть общая библиотека, которая называется Лего. И мы в ней хотим реализовать какую-то новую фичу или внести какую-то правку. Мы поправили код и выпустили версию.
Эту версию нам нужно опубликовать в npm, а дальше пойти в репозиторий какого-то проекта, где используется библиотека, и внедрить эту версию. Скорее всего, это поправить какую-то чиселку в package.json, перезапустить сборку. Возможно, еще перегенерировать package-lock, создать pull request, посмотреть, как пройдут тесты. И что мы увидим?
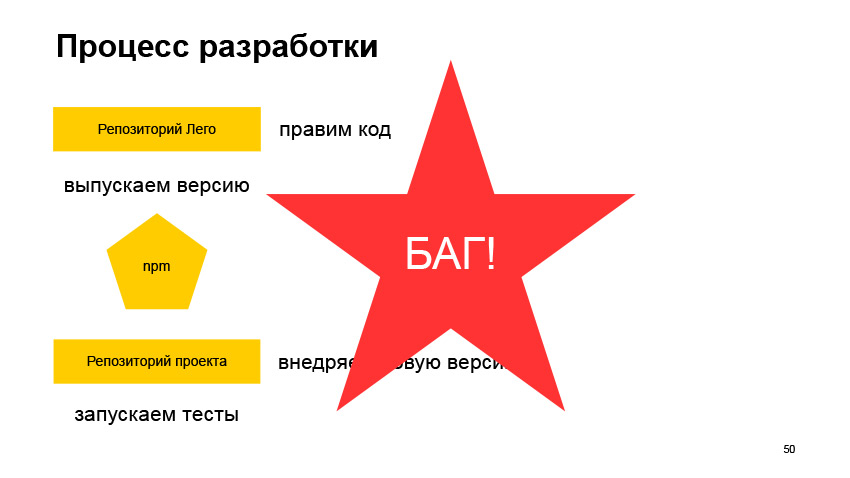
Скорее всего, мы увидим, что случился баг. Потому что очень сложно предугадать все способы использования компонента на разных сервисах. И если так и произошло, то какой у нас выход? Вот мы осознали, что не сошлось. Продолжаем переделывать. Возвращаемся в репозиторий с общей библиотекой, чиним баг, выпускаем новую версию, отправляем ее в npm, внедряем, запускаем тесты, и что там? Скорее всего, снова случится баг.
Причем это еще хорошо, когда мы внедряем в один сервис, и прямо там сразу все сломалось. Гораздо печальнее, когда мы все это проделали, внедрили в десять разных сервисов. Там ничего не сломалось. Мы уже пошли заваривать смузи, или что там нужно. В это время версия внедряется в 11-й проект, или в 25-й. И там находится баг. Мы возвращаемся по всей цепочке, делаем патч и внедряем его во все предыдущие 20 сервисов. Причем этот patch может взорваться в каком-то из предыдущих. Ну и так далее. Весело.
Выход, кажется, единственный — нужно просто очень быстро писать много кода. Тогда рано или поздно, если мы очень-очень быстро побежим, скорее всего, у нас получится успеть выкатить в продакшен версию, в которой бага еще нет. Но потом появится новая фича, и нас ничто не спасет.
Ладно. На самом деле, схема может быть примерно следующей. Нам поможет автоматизация. Именно об этом, в общем-то, весь рассказ, на самом деле. Мы придумали, что репозиторий с общей библиотекой может быть построен по схеме монорепозиториев. Вы наверняка сталкивались, сейчас много таких проектов, особенно инфраструктурных. Всякие Babel, и тому подобные штуки, живут, как монорепозитории, когда внутри лежит много разных npm-пакетов. Они, возможно, связаны как-то между собой. И управляются, например, через Lerna, чтобы все это удобно паблишить, учитывая зависимости.
Ровно по такой схеме можно организовать и проект, где хранится все общее, для всей компании. Там может быть и библиотека, которой занимается отдельная команда. И, в том числе, там могут быть пакеты, которые разрабатывает каждый отдельный сервис, но которыми он хочет делиться с другими.

Тогда схема выглядит так. Начало не отличается. Нам так или иначе нужно внести правки в общий код. А потом с помощью автоматизации мы одним махом хотим запустить тесты не только рядом с этим кодом, но сразу во всех тех проектах, куда внедрен этот общий код. И увидеть их агрегированный результат.
Тогда, даже если там случился баг, то мы еще не успели выпустить никакую версию, не опубликовали ее ни в каком npm, никуда специально не внедрили руками, не проделали всех этих лишних усилий. Мы увидели баг, тут же локально починили, опять запустили общие тесты, и все, в продакшен.
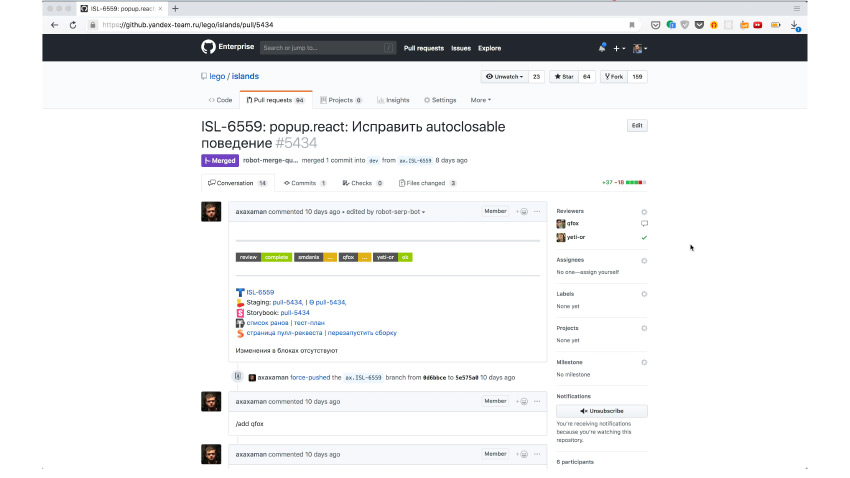
Как это выглядит на практике? Вот пулл-реквест с исправлением. Здесь видно, что автоматика призвала туда нужных ревьюверов, чтобы они проверили, что в коде все хорошо. Действительно, ревьюверы пришли и договорились, что все хорошо. И в этот момент разработчик просто пишет специальную команду /canary, прямо в пулл-реквесте.
Приходит робот и говорит — окей, я создал задачу на то, чтобы случилось следующее чудо. Чудо в том, что теперь выпустилась canary-версия с этими изменениями и она автоматически была внедрена во все репозитории, где используется этот компонент. Там запустились автотесты, как и в этом репозитории. Здесь видно, что запустилась целая куча проверок.
За каждой проверкой может стоять еще по сотне разных тестов. Но важно, что помимо локальных тестов, которые мы смогли написать на компонент отдельно, мы еще запустили тесты на каждый проект, куда она внедрилась. Там уже запустились интеграционные тесты: мы проверяем, что этот компонент нормально работает в окружении, в котором он задуман на сервисе. Это уже и правда нам гарантирует, что мы ничего не забыли, ничего никому не сломали. Если здесь все хорошо, то мы правда можем смело выпускать версию. А если здесь что-то плохо, мы здесь же и поправим.
Похоже, что нам должно это помочь. Если в вашей компании нечто похожее, вы видите, что есть части, которые вы потенциально могли бы переиспользовать, но пока вам приходится их верстать заново, поскольку нет автоматизации, — рекомендую прийти к похожему решению.

Что мы получили? Общий монорепозиторий, в котором отстроены линтеры. То есть все пишут код одинаково, в нем есть все виды тестов. Любая команда может прийти, положить свой компонент и проверить его JS unit-тестами, покрыть его скриншотами и т. д. Все уже будет из коробки. Умное код-ревью, которое я уже упоминал. Оно у нас благодаря богатым внутренним инструментам и правда умное.
Разработчик сейчас в отпуске? Звать его в пулл-реквест бессмысленно, система это учтет. Разработчик заболел? Система это тоже учтет. Если оба условия не выполнились и разработчик, кажется, свободен — ему прилетит уведомление в какой-то из его мессенджеров, по его выбору. И он такой: нет, сейчас я занят чем-то срочным или на встрече. Он может прийти туда и просто написать команду /busy. Система автоматически поймет, что нужно назначить следующего из списка.
Следующий шаг — публикация той самой canary-версии. То есть нам с любым изменением кода нужно выпустить служебный пакет, который мы сможем проверить на разных сервисах. Дальше нам нужно запустить тесты при внедрении на все эти сервисы. А когда все сошлось — запустить релизы.
Если в изменении затронута какая-то статика, которая должна загружаться с CDN, нужно ее автоматически опубликовать отдельно. Это тоже работает из коробки. При выпуске релиза нам, конечно, нужно знать, что происходило, что менялось. Но так как мы хотим, чтобы все это было автоматически, нужно, чтобы changelog был сформирован автоматом и где-то публиковался.
И наконец, если все разные сервисы разнесли свои компоненты, положили в отдельное общее место, то удобно построить витрину со списком всех компонентов, со всей документацией. Когда новый разработчик или дизайнер захочет понять, что уже есть, он спокойно воспользуется этим единым реестром.
Это практически счастье, но на самом деле понятен и следующий шаг. Это общий монорепозиторий для всех проектов сразу. Вы, наверное, можете спросить: а зачем вы так страдали и придумывали столько сложной инфраструктуры, если можно было сразу сложить все вместе? Ответ простой. Если мы и правда сложим все наши проекты вместе, то никакая из доступных сейчас систем контроля версий с этим не справится. Так что нам придется изобрести подходящую. На этом у меня все, спасибо.
Комментарии (21)

justboris
21.07.2019 14:38+1Спасибо за sneak peek в ваши процессы разработки!
tadatuta а можете рассказать поподробнее про взаимоотношение реализаций на i-bem и React? Это две отдельные кодовые базы или есть какое-то переиспользование?

tadatuta
22.07.2019 00:04Стараемся выделять в CommonJS, то, что можно использовать из i-bem и React + используем общие тесты и стили для компонентов.
justboris
22.07.2019 00:09А на файловой системе это как организуется? Файлы лежат рядом, что-то вроде такого:
desktop.blocks/ button/ button.common.js button.i-bem.js button.react.jsx
или как-то иначе?
tadatuta
22.07.2019 00:17В Лего сейчас именно так. На проектах — по-разному. Для мира i-bem четкая структура важна, а для Реакта с явными импортами код может лежать как решит каждая конкретная команда и зачастую принимают решение все-таки держать код на Реакте отдельно, но импортировать стили/тесты из тех же
desktop.blocks/**

babylon
21.07.2019 17:56-3Академию Яндекса правильнее было назвать ПТУ. Хоть одного проприетарного "академика" покажите или то, что он наакадемил. Хотя за своих вы как правило горой стоите.
Разработчик сейчас в отпуске? Звать его в пулл-реквест бессмысленно, система это учтет. Разработчик заболел? Система это тоже учтет
Скоро вас всех учтут нейросети.

Carduelis
22.07.2019 10:24Вы сначала пишете про Lerna, а затем про то, что у вас не монорепозиторий.
Как вы настроили Lerna, как бампаете версию и чем инициируете тесты в других репозиториях (с проектами продуктов)?tadatuta
22.07.2019 11:56На самом деле у нас много репозиториев, построенных по схеме монорепы и управляются с помощью lerna, поэтому за обновление версий пакетов каждого из множества монореп отвечает lerna и скрипты, которые написаны поверх нее.
В целом схема в CI такая:
1. Открытие pull request-а в репозиторий с общим кодом автоматически выпускает canary-версию затронутых пакетов
2. Во все проекты, где используется затронутый пакет, автоматически отправляется pull request с обновлением package.json и package-lock.json до версии, выпущенной в п. 1
3. Эти pull request-ы триггерят запуск тестов в затронутых репозитория
4. Отчеты по этим тестам публикуются в исходный pull request из п. 1. Если там упали обязательные проверки, влиться не получится
5. Если все проверки прошли успешно и разработчик вмержил изменения, автоматически будет выпущена стабильная версия общего пакета, а pull request-ы в проекты обновятся на использование этой стабильной версии. Так что разработчикам останется только их влить.

vintage
А что скажете насчёт этих идей в применении к вашим реалиям?
MAM: сборка фронтенда без боли
tadatuta
Мы достаточно много экспериментировали с «магической» сборкой, которая также, как и в МАМ, не требовала указания явных импортов. В частности такой подход позволил очень удобно работать с уровнями переопределения. Но сейчас скорее движемся в сторону «явное лучше неявного» и возвращаемся к классическим импортам, которые хотя и заставляют писать больше бойлерплейта, зато делают код более очевидным, не требующим знать о соглашениях, чтобы с ним разобраться.
vintage
А что стало с уровнями переопределения при "явном лучшем неявного"?
tadatuta
Реализуем их через github.com/bem/bem-react/tree/master/packages/di
vintage
То есть, если надо перекрасить кнопочку в глубине какого-то компонента, то придётся переопределить все компоненты по пути к этой кнопочке на кастомные?
tadatuta
Нет, потребуется переопределить ближайший «слот», о котором позаботился разработчик при проектировании компонента. Если он заранее догадался, что потребуется менять кнопочку, то можно будет именно ее и переопределить через реестр. Иначе — ближайшего родителя, доступного в реестре.
Подробнее о том, как работает bem-react/di можно посмотреть в докладе verybigman www.youtube.com/watch?v=nhgC_43C38Q
vintage
Вот это вот "если догадался" и смущает. Откуда разработчику знать какая кастомизация потребуется? А если он будет заводить слоты для всего на свете, то боюсь кода будет слишком много и разобраться в нём будет ни чуть не проще, чем изучить правила "магии".
babylon
В основе проектирования любой интегрирующей программной среды должны сразу лежать фундаментальные принципы, позволяющие максимально автоматизировать мониторинг и тестирование процессов разработки, а не полагаться на слотовые эвристики и закладки разработчика и что еще хуже пользователя системы. Что впрочем в данном случае одно и тоже. Дмитрий не думаю, что коллеги из Яндекса до конца осознали ваши пионерские идеи и тем более досконально разобрались в коде $mol.
tadatuta
Ровно по такой логике мы и проектировали компоненты раньше. И до сих пор большая часть кодовой базы по-прежнему реализована на идеях, схожих с MAM.
К моему личному сожалению, безграничная гибкость БЭМ-стека новым разработчикам «заходит» хуже, чем явные импорты, пусть даже и требующие рефакторить компоненты каждый раз, когда становится понятно, что вовремя забыли позаботиться о кастомизации на будущее.
babylon
tadatuta, что если (вам) сделать коллаборацию с vintage? Всем было бы интересно, что из этого получится. Общие компоненты — общими силами разных команд
tadatuta
Мы ведем разработку и обсуждение максимально открыто на github: github.com/bem/bem-react
В документации репозитория описано и как подключиться к обсуждению/разработке и мотивация, почему все сделано именно так, как оно сделано: github.com/bem/bem-react/blob/master/docs/ru/Introduction/Motivation.md
Всегда рады конструктивной критике и предложениям!
vintage
К сожалению, там нет обоснования необходимости Реакта. На мой взгляд это тупиковая ветвь развития. Его использование откатывает индустрию в каменный век и требует снова решать уже давно решённые проблемы. Мне кажется Яндекс вполне в состоянии не прогибаться под чужой маркетинг, а сам задавать тренды.