
Если вы слышали об этой файловой системе, но не знаете, зачем она, интересуетесь подробностями или ищете, с чего начать знакомство с ней — приглашаю под кат.
Введение
BTRFS (B-Tree Filesystem) — файловая система для Unix-подобных операционных систем, основанная на технике «Copy on Write» (CoW), призванная обеспечить легкость масштабирования файловой системы, высокую степень надежности и сохранности данных, гибкость настроек и легкость администрирования, сохраняя при этом высокую скорость работы. По крайней мере, так гласит главная вики-страничка.
Для соблюдения формальностей перечислим основные возможности btrfs:
- Максимальный размер файла 2^64 байт
- Динамическая таблица inode
- Дедупликация данных
- Эффективное хранение файлов как очень малых, так и очень больших размеров
- Создание сабвольюмов и снапшотов
- Квоты на размеры сабвольюмов
- Контрольные суммы для данных и метаданных
- Возможность объединить несколько накопителей в единую файловую систему
- Создание RAID конфигурации на уровне файловой системы
- Сжатие данных
- Дефрагментация данных на лету
Сразу хочу предупредить о том, что BTRFS активно развивается, и некоторые моменты могут отличаться от версии к версии. По ссылке — https://btrfs.wiki.kernel.org/index.php/Changelog можно узнать, когда какой функционал был добавлен, изменен или исправлен.
Да, BTRFS — это молодая и современная файловая система, решающая широкий спектр задач, однако не без минусов:
- Активное её развитие приводит к изменению каких-либо ключевых моментов, на которые могут опираться сторонние утилиты при работе с ней.
- Несмотря на заверения разработчиков о стабильности BTRFS, пользователи регулярно сталкиваются с проблемами, потенциально приводящими к потере данных. Как правило, они носят «плавающий» характер, вследствие чего до сих пор не изучены и не исправлены.
- Высокая подверженность фрагментации.
- Скудная и местами устаревшая документация.
Проблемам файловой системы на разных версиях ядер посвящена целая страница — https://btrfs.wiki.kernel.org/index.php/Gotchas. Очень советую туда заглядывать — выясняется много интересного и неочевидного.
Структура BTRFS
Упрощенно устройство BTRFS можно разбить на следующие уровни:

На самом низком уровне располагаются блочные устройства, представляя собой одно или несколько раздельных физических адресных пространств (таких же «физических», какими являются сами блочные устройства, но это уже детали). Посредством специальных структур аллоцированные блоки физической памяти объединяются в единое виртуальное адресное пространство.
Структуры метаданных и блоки с пользовательскими данными (экстенты) адресуются уже на логическом уровне. В результате данные, расположенные последовательно на логическом уровне, физически могут находиться на разных блочных устройствах.
Структуры метаданных можно условно разбить на уровни. Классифицировать я их, конечно, не буду — их много, и подобные низкоуровневые подробности — тема отдельной статьи. Здесь важно, что одни структуры в иерархии окажутся более высокоуровневыми, чем другие, а на самом верху окажется структура, представляющая собой сабвольюм.
Сабвольюмы — это своеобразные точки входа, или, правильнее, корневые элементы файловой системы. Они образуют отдельный слой представления данных, который инкапсулирует работу низших слоев, представляя пользовательские данные уже в привычном нам виде: директории и файлы. Кроме того, сабвольюмы являются ключевым элементом механизма CoW на BTRFS. Одинаковые файлы в двух сабвольюмах могут оказаться одним и тем же набором данных на нижележащих уровнях.
Последний слой — слой данных. Таких, какими видит их пользователь. Это файлы и директории, располагающиеся в сабвольюмах.
Но довольно теории. Пора переходить к практике!
Btrfs-progs
Это штатный комплект утилит для управления BTRFS. В зависимости от дистрибутива пакет с этими утилитами в репозитории может носить различные названия: btrfsprogs, btrfs-progs, btrfs-tools и т.п. Если же в вашем репозитарии ничего похожего не оказалось — всегда можно собрать вручную, исходники лежат недалеко — https://github.com/kdave/btrfs-progs.
Самые главные утилиты в данном пакете — это btrfs и mkfs.btrfs. Со второй, думаю, все предельно ясно — она необходима, чтобы создать BTRFS на блочном устройстве. Первая же, btrfs — это основная утилита, позволяющая делать все остальное. Этакий «швейцарский нож».
В этой статье я использовал версию v4.15.1. Утилита развивается очень активно, и от версии к версии бывают ощутимые различия. Так что если у вас не оказалось нужной команды, проверьте версию утилиты btrfs, возможно, она уже устарела.
Также, скорее всего, в пакете обнаружатся утилиты btrfsck и btrfstune.
- Первая из них служит для проверки файловой системы на ошибки и для последующих их исправлений, однако, использовать я её не рекомендую — она в статусе deprecated, её функционал перемещен в команду btrfs check.
- Вторая — позволяет производить некоторые полезные операции над btrfs, например, менять уникальный идентификатор файловой системы (FS UUID), либо включить определенный функционал файловой системы.
Кроме перечисленных выше утилит, в пакете найдутся еще несколько утилит, но они уже в основном нужны для отладки btrfs и в данной статье нам не пригодятся.
Форматирование диска в BTRFS
На практике все проще. Начнем с одного диска.
Форматирование одного диска в btrfs происходит привычной командой:
mkfs.btrfs /dev/sdc -L single_driveВ ответ утилита выведет в консоль параметры созданной файловой системы:
btrfs-progs v4.15.1
See http://btrfs.wiki.kernel.org for more information.
Label: single_drive
UUID: 59307d69-6d2f-4d2e-aae2-a5189ad3c256
Node size: 16384
Sector size: 4096
Filesystem size: 1.00GiB
Block group profiles:
Data: single 8.00MiB
Metadata: DUP 51.19MiB
System: DUP 8.00MiB
SSD detected: no
Incompat features: extref, skinny-metadata
Number of devices: 1
Devices:
ID SIZE PATH
1 1.00GiB /dev/sdc
Пройдемся по представленным параметрам.
- Label — метка, или имя файловой системы. Задается ключом
-Lи является необязательным параметром. - UUID — уникальный идентификатор, благодаря которому ядро btrfs отличает инстансы друг от друга.
- Node size — размер элементов B-дерева, в которых хранятся метаданные. Его можно задать при помощи ключа
-n | --nodesize, при этом он должен быть кратен размеру Sector size. Малый размер ноды приводит к увеличению высоты B-дерева (увеличению количества нод) и, как следствие, уменьшению конкуренции за блокировку отдельно взятой ноды. С другой стороны, малый размер ноды делает инстанс файловой системы более подверженным фрагментации. Большие же ноды, наоборот, способствуют лучшей упаковке метаданных на диске, что снижает фрагментацию.
Обратная же сторона — увеличенное времени доступа к данным для обновления одной и той же ноды несколькими потоками. На ядрах старше 3.11 по умолчанию размер ноды равен 16384 байт либо размеру страницы памяти ОС (бОльшему из этих двух значений). - Sector size — объем пространства, кратно которому выделяется и освобождается пространство на физическом уровне. Равен размеру страницы виртуальной памяти ОС, если не указано иное при помощи ключа
-s. - Filesystem size — суммарная вместимость файловой системы (данные плюс метаданные). Вручную задается ключом
-b. По умолчанию занимается весь объем блочного устройства. - Incompat features — список возможностей, включенных на созданной btrfs, ломающих обратную совместимость со старыми версиями ядер. Если же обратная совместимость необходима, то можно отключить:
--features ^extref,^skinny-metadata.
Кстати, проверить, какие возможности поддерживает текущее ядро, можно следующим вызовом:
mkfs.btrfs --features list-all - Number of devices и Devices — сколько блочных устройств задействовано в созданном инстансе btrfs, и список всех устройств соответственно.
- Отдельно стоит поговорить о параметре Block Group Profiles. Он указывает на применяемый профиль записи для каждого из трех типов данных: Data, Metadata и System. Возвращаясь к обобщенной структуре btrfs, можно сказать что:
- Data — это пользовательские данные;
- Metadata — это объединение слоя сабвольумов и слоя метаданных и экстентов;
- System — это структуры отображения адресного пространства физической памяти в непрерывное пространство логических адресов.
Под профилем записи понимается способ хранения данных на физическом уровне:
- Single — хранение данных в единственном экземпляре;
- DUP — дублирование данных на одном носителе;
- RAIDX — одна из конфигураций RAID0, RAID1, RAID10, RAID5 и RAID6.
При разметке одного блочного устройства по умолчанию btrfs применит дублирование к метаданным и системные данным, а пользовательские данные будут оставаться на носителе в единственном экземпляре. Создание же btrfs на нескольких дисках сразу по умолчанию применит профиль «RAID0» к пользовательским данным, а к метаданным — «RAID1».
Управляется данная группа параметров при помощи двух ключей:
-d для данных и -m для метаданных и системных данных.Но есть нюанс… Немного иначе обстоят дела с твердотельными накопителями. Дело в том, что если бы мы размечали SSD диск (или флешку), то по умолчанию файловая система не стала бы дублировать метаданные. Твердотельные накопители для продления времени жизни элементов памяти могут производить дедупликацию данных. Т.е. имея две логические копии данных, по факту на носителе будет записана только одна. Как результат, при выходе сегмента памяти из строя повредятся «обе копии» данных. К тому же, записывая данные дважды, попросту быстрее расходуется ресурс SSD.
Для определения типа носителя btrfs проверяет контент файла /sys/block/DEV/queue/rotational, где «DEV» — имя проверяемого блочного устройства.
Разумеется, даже в случае SSD профиль хранения данных можно задать принудительно.
Чтобы создать инстанс btrfs на нескольких устройствах, достаточно указать их через пробел:
sudo mkfs.btrfs /dev/sdc /dev/sdd -L double_driveили же с указанием профилей:
sudo mkfs.btrfs /dev/sdc /dev/sdd -d raid1 -m raid1 -L raid1_driveТут надо отметить, что носители не обязаны быть одинакового размера, даже если используется полное зеркалирование. Однако, как только на наименьшем из дисков не хватит места для выделения памяти — файловая система выдаст сообщение об отсутствии свободного пространства, хотя физически на другом носителе некоторое свободное пространство еще может оставаться.
Монтирование
Первое монтирование свежесозданной btrfs не отличается от других файловых систем:
mount /dev/sdc /mntВ случае, если файловая система располагается на нескольких дисках, то для монтирования достаточно указать любой из них.
Вообще монтирование btrfs всегда подразумевает монтирование одного или нескольких её сабвольюмов. Если в вызове команды mount не указывать, какой сабвольюм необходимо замонтировать, то btrfs прочитает из специальной записи ID сабвольюма, который необходимо монтировать по умолчанию. Эту запись в дальнейшем можно изменить командой
btrfs set-default, но при первом монтировании на btrfs присутствует только один сабвольюм — корневой. Именно он указан по умолчанию для монтирования.Корневой сабвольюм на btrfs присутствует всегда. Появляется он вместе с файловой системой и в дальнейшем не подлежит каким-либо изменениям.
Для монтирования любого другого сабвольюма, кроме дефолтного, существуют два способа:
указать путь от корневого сабвольюма btrfs:
mount -o subvol=/path/to/subvol /dev/sdc /mntлибо указать ID сабвольюма:
mount -o subvolid=257 /dev/sdc /mntКак уже упоминалось, один из сабвольюмов btrfs указан как монтируемый по умолчанию. Узнать, какой именно, можно, выполнив:
btrfs subvolume get-default /path/to/any/subvolumeУстановить сабвольюм, монтируемый по умолчанию, можно командой:
btrfs subvolume set-default 258 /path/to/any/subvolumeПуть до сабвольюма в данном случае нужен только для указания конкретного инстанса btrfs, к которому применяется команда. Кстати, это не обязательно должен быть сабвольюм, подойдет и путь до любой директории.
Команда
mount принимает огромное количество опций для управления возможностями btrfs: дефрагментация, сброс кеша, сжатие, cow, логирование, баланс, поддержка ssd и еще вагон разных специфичных для btrfs вещей. Я не буду их рассматривать в рамках данной статьи, т.к. они нужны для тонкой настройки файловой системы, и в подавляющем большинстве случаев можно обойтись и без них.Subvolume is
Сабвольюм — это ключевой элемент btrfs, исполняющий различные функции:
- хранение в себе пользовательских данных и других сабвольюмов,
- обеспечение доступа к данным (монтирование),
- механизм CoW,
- создание снапшотов.
При первом приближении сабвольюмы — это обычные директории. Их можно переименовывать/перемещать, просматривать их содержимое, размещать и изменять внутри них файлы. Каких-либо специальных утилит при этом не требуется.
Создание и удаление сабвольюма производится на подмонтированной btrfs при помощи специальных команд:
btrfs subvolume create /mnt/subvolume_name
btrfs subvolume delete /mnt/subvolume_nameЗамечу, что если попытаться удалить сабвольюм средствами файлового менеджера или утилиты rm, то операция завершится с ошибкой operation not permitted (операция не разрешена).
UPD: Начиная с версии ядра 4.18.0 удаление сабвольюмов можно производить утилитой rm или средствами файлового менеджера. Видимо, это был баг, а не фича. Спасибо хабравчанину Prototik за уточнение.
После создания сабвольюма можно посмотреть его свойства:
btrfs subvolume show /mnt/subvolume_name
Name: subx
UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a
Parent UUID: -
Received UUID: -
Creation time: 2019-03-23 17:59:28 +0100
Subvolume ID: 268
Generation: 39
Gen at creation: 35
Parent ID: 260
Top level ID: 260
Flags: -
Snapshot(s):Пройдемся по основным свойствам сабвольюма:
- Name — имя сабвольюма,
- UUID — универсальный уникальный идентификатор, служащий, в основном, для определения связей сабвольюм-снапшот,
- Parent UUID — идентификатор сабвольюма-предка, от которого произведен текущий,
- Received UUID — идентификатор сабвольюма-предка, отправленного через btrfs send,
- Subvolume ID — уникальный идентификатор для размещения в B-дереве,
- Generation — номер транзакций при последнем обновлении метаданных сабвольюма,
- Gen at creation — номер транзакции на момент создания сабвольюма,
- Parent ID — идентификатор сабвольюма, в который вложен текущий,
- Top level ID — абсолютно то же самое, что и Parent ID,
- Flags — флаги (по факту только 1 флаг — readonly),
- Snapshots — список снапшотов, снятых с данного сабвольюма.
У сабвольюма есть еще один параметр — это его путь от корневого элемента btrfs. Путь отображается при выводе списка сабвольюмов:
btrfs subvolume list /path/to/any/btrfs/mountpointНо тут все просто и наглядно — даже нет смысла приводить вывод команды.
Так же, как и с командами
get-default и set-default, тут можно указать путь до любого сабвольюма, результат от этого не изменится. Этот путь используется для того, чтобы найти корневой сабвольюм btrfs. После чего происходит чтение всего дерева сабвольюмов.Если попытаться скопировать сабвольюм, например, утилитой cp, то операция копирования выполнится успешно, но в результате будет создан не сабвольюм, а обычная директория. Однако btrfs предоставляет гораздо более гибкий инструмент для создания подобных копий — снапшоты.
Snapshot is
Снапшот — это тоже сабвольюм, просто обладающий расширенными свойствами.
Основное их отличие — наличие у снапшота записей о том, от какого сабвольюма он был произведен. Это поля Parent UUID и Received UUID. У сабвольюма эти поля тоже присутствуют, но они всегда пустые. Так что, по сути, снапшот и сабвольюм — это одно и то же.
Снапшот при создании можно заблокировать для изменений при помощи ключа
-r.btrfs subvolume snapshot create /path/to/subvol /path/to/snapshot -rВ этом случае файлы гарантировано останутся в том состоянии, в котором они пребывали на момент создания снапшота.
Флагом «только для чтения» так же можно управлять вручную, это работает для любого сабвольюма:
btrfs property get /path/to/subvol ro
btrfs property set /path/to/subvol ro trueЕсли теперь заглянуть в свойства снапшота, то увидим заполненное поле Parent UUID:
btrfs subvolume show /path/to/snapshot
Name: subx
UUID: d08612d8-596a-11e9-8647-d663bd873d93
Parent UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a
Received UUID: -
Creation time: 2019-03-23 17:59:28 +0100
Subvolume ID: 269
Generation: 39
Gen at creation: 35
Parent ID: 260
Top level ID: 260
Flags: -
Snapshot(s):Важной особенностью операции создания снапшота является то, что она нерекурсивна. Вместо вложенных сабвольюмов в снапшоте будут созданы пустые директории.
Обратимся к следующему примеру.
На файловой системе имеется сабвольюм «sub0», внутри которого расположен сабвольюм subA и директория dirB. Внутри каждого из них расположены fileA и fileB соответственно.
Снимаем снапшот:
btrfs subvolume snapshot sub0 snap0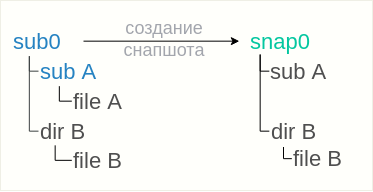
Созданный снапшот snap0 унаследует все файлы и директории своего родителя, однако, сабвольюм subA внутри снапшота не появится. Вместо него в снапшоте появится только пустая директория, т.е. содержимое сабвольюма subA унаследовано не будет.
С одной стороны, это хорошо — мы снимаем снапшот с конкретного сабвольюма, и все вложенные нас не интересуют. С другой стороны — в случае, если требуется рекурсивный снапшот, то у btrfs нет решения данной задачи. Придется искать воркэраунды.
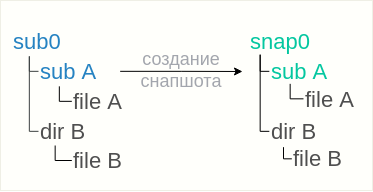
Первый обходной путь основывается на том, что снапшот был снят без флага «только для чтения», что позволяет исправить ситуацию достаточно просто:
- удалить лишнюю директорию из снапшота
rmdir snap0/subA
- снять снапшот с вложенного сабвольюма
btrfs subvolume snapshot sub0/subA snap0/subA
Если же снапшот был снят с флагом «только для чтения», то приведенный вариант не сработает, т.к. в snap0 нельзя ни удалить директорию, ни разместить снапшот. Тут вариант только один — размещать снапшоты где-то рядом с сабвольюмом snap0:
btrfs subvolume snapshot sub0/subA snapAа затем монтировать snapA внутрь снапшота snap0, директория для этого уже имеется:
mount -o subvol=snapA snap0/subA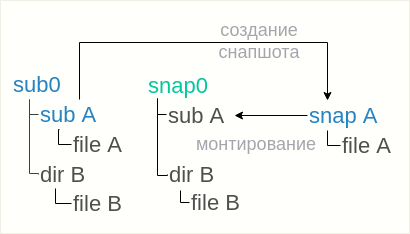
В любом случае важно понимать, что рекурсивные снапшоты все будут сняты в рамках разных операций, в разное время. Ни о каком атомарном снятии снапшота с нескольких сабвольюмов речи быть не может.
Copy on write
Немного о сабвольюмах и CoW-подходе. Представим, что на файловой системе присутствует сабвольюм и в нем расположен файл (возьмем идеальный случай — файл не фрагментирован). Далее с сабвольюма снимается снапшот.

На файловой системе появится новый сабвольюм (снапшот) ровно с тем же самым содержимым, которое было у исходного сабвольюма. Процесс создания снапшота проходит почти мгновенно — данные самого файла не копируются. Вместо этого создаются дополнительные метаданные, и снапшот наравне с родительским сабвольюмом становится владельцем файла. По сути, файл на диске остался один, но теперь принадлежит одновременно как сабвольюму, так и снапшоту.
Если теперь изменить файл в сабвольюме, то изменения никак не повлияют на файл в снапшоте. Если при создании снапшоту не был выставлен флаг «только для чтения», то файл в снапшоте также можно изменять.
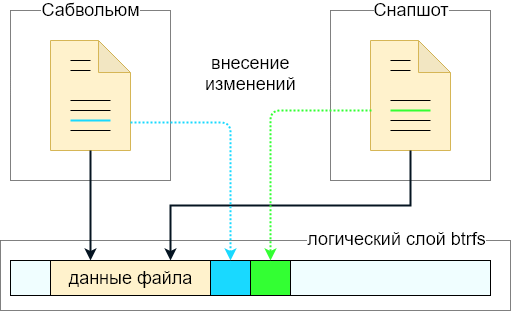
Технически, при изменении файла записываются только эти изменения. Так что на диске будет храниться исходный файл плюс некоторая дельта, отличающая исходный файл от измененного. Если же удалить один из сабвольюмов (под вторым я имею в виду снапшот), то лишние данные, более никем не используемые, будут вычищены с диска, а на диске останется только актуальная версия файла (с точки зрения оставшегося сабвольюма).
Небольшое замечание: При удалении сабвольюм исчезнет с глаз пользователя мгновенно, и утилита вернет управление в терминал, однако сами данные на диске будут вычищены фоновым процессом в течение некоторого времени. Т.е., в отличие от удаления обычной директории, здесь не придется ждать реального завершения операции удаления. Если же необходимо синхронизироваться с эти процессом и дождаться его завершения, можно при вызове delete указать ключ
--commit-after. Команда btrfs subvolume list, вызванная с ключом -d, выведет список сабвольюмов, которые были удалены пользователем и на текущий момент находятся в процессе удаления с диска.Ко всему прочему, btrfs позволяет клонировать файлы на файловой системе, не прибегая к снапшотам. Делается это обычным копированием с указанием ключа
--reflink:cp -ax --reflink=always /original/file /copied/fileКлюч
reflink=always сообщает файловой системе, что мы хотим задействовать механизм CoW при копировании. После копирования файлы можно изменять независимо друг от друга, так что мы получаем то же самое поведение, как и после создания снапшота. Так зачем тогда нужны сабвольюмы?Сабвольюмы на btrfs играют роль высокоуровнего средства управления целыми наборами данных: во-первых, это атомарное снятие снапшота со всех данных сабвольюма (в случае с --reflink атомарность лишь на уровне файла), во-вторых — есть возможность посмотреть, кто от кого наследуется, или быстро «откатить» набор данных на более раннюю версию, и т.п.
Таким образом, btrfs предоставляет возможность фиксировать состояния файлов в желаемые моменты времени, применяя сабвольюмы как высокоуровневое средство управления этими состояниями.
Восстановление сабвольума
На просторах необъятного часто встречается вопрос: «У меня есть сабвольюм, у меня есть снапшот, как сделать реверт?» Данный подход не применим к btrfs, т.к. нет самой возможности «откатить сабвольюм». Вместо этого btrfs предлагает стратегию замены сабвольюма на его снапшот. Действительно, зачем что-то ревертить, если сам снапшот — это и есть тот объект, который мы хотим получить при помощи реверта.
Представим себе такой сценарий: на btrfs расположен сабвольюм, в котором располагаются файлы какой-либо базы данных (ну или другие важные данные). С этого сабвольюма периодически снимаются снапшоты, и в определенный момент возникает необходимость откатить данные. В этом случае мы просто избавляемся от сабвольюма и вместо него начинаем использовать снятый с него снапшот, либо — если не хотим испортить еще и эти данные — снимаем со снапшота еще один снапшот. Если оригинальный сабвольюм не был замонтирован и использовался как обычная директория, то его необходимо либо удалить либо переместить/переименовать, а на его место поместить снапшот.
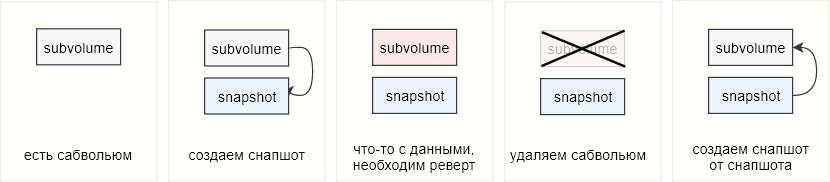
В консоли это может выглядеть примерно так:
- переименовываем сабвольюм
mv the_subvolume the_subvol.old - помещаем на место сабвольюма его снапшот
btrfs subvolume snapshot the_snapshot the_subvolume
Если же сабвольюм был замонтирован и использовался через точку монтирования, то достаточно отмонтировать сабвольюм и подмонтировать на его место снапшот.

- Отмонтируем сабвольюм
umount /mnt/ - Можно создать снапшот снапшота, чтобы не испортить последние уцелевшие данные:
btrfs subvolume snapshot /path/to/snapshot /path/to/snapshot_copy - монтируем снапшот:
mount -o subvol=path/to/snapshot_copy /mnt
Для полноты картины попробую еще раз и немного по-другому. Сабвольюм, в котором происходят изменения — это ветка main.
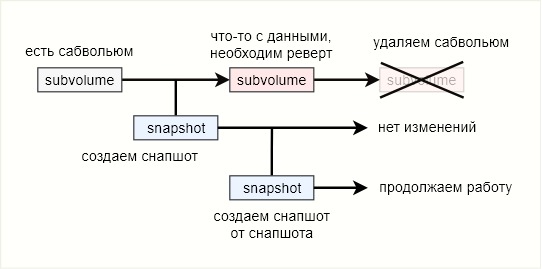
При создании снапшота происходит фиксация состояния файлов на диске. С этого момента снапшот — это бранч ветки main. Все дальнейшие изменения в main никак не повлияют на снапшот. Откат же к снапшоту означает прекращение использования ветки main и полное переключение на бранч. Ветку main при этом за ненадобностью можно удалить. Таким образом, btrfs — это практически система контроля версий, но без возможности обратно смержить ветки.
Дерево файловой системы
Одним из неочевидных моментов, связанных с использованием btrfs, является то, как следует разбивать данные системы на сабвольюмы. Разумеется, какого-либо «правильного» подхода в данном вопросе не существует. Но можно выделить 3 способа организации структуры сабвольюмов: плоская структура, вложенная и смешанная.
Плоская структура означает расположение сабвольюмов плоским списком в корневом сабвольюме. Например, отдельными сабвольумами можно выделить корень файловой системы (назовем его root), пользовательскую директорию home, директорию с сайтом /var/www и базу данных, расположенную например в /var/database.
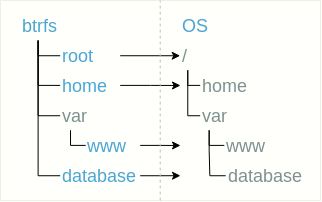
Некоторые сабвольюмы для удобства можно размещать в директориях, как, например, в случае с сабвольюмом var/www.
При таком подходе все сабвольюмы необходимо замонтировать. Сабвольюм root должен иметь точку монтирования /, а внутри себя содержать директории home и var. После монтирования root в /home должен монтироваться сабвольюм home, а в /var/www и /var/database — сабвольюмы var/www и database соответственно.
Таким образом, дерево btrfs-сабвольюмов можно произвольным образом отобразить в виртуальной файловой системе ОС, а там уже на что фантазии хватит.
Плюсы:
- пользователю видны только замонтированные сабвольюмы,
- легко заменить сабвольюм (отмонтировать один, примонтировать другой),
- легко удалить сабвольюм.
Минусы:
- легко запутаться что куда монтируется,
- для каждого сабвольюма должна быть запись в fstab, а если происходят «откаты» к снапшотам, то соответствующие записи в fstab необходимо еще и обновлять.
Вложенная структура сабвольюмов предполагает простое использование сабвольюмов вместо некоторых директорий.
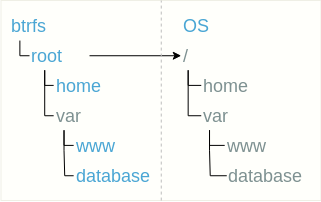
В этом случае кроме корневого сабвольюма монтировать больше ничего не требуется.
Плюсы:
- все сабвольюмы видны, структура проста для восприятия,
- не нужно ничего монтировать лишний раз, все как с «обычной» файловой системой.
Минусы:
- все сабвольюмы видны, возможно, некоторые хотелось бы спрятать от пользователя,
- сложно удалить/заменить сабвольюм (причиной тому — вложенные сабвольюмы).
Ну и третий подход — смешанный. Он предполагает комбинацию первых двух для извлечения максимальной выгоды из обоих. Однако, не исключено что именно данный подход приведет к сложной, тяжело изменяемой, запутанной структуре с огромным количеством записей в fstab. Все зависит от

Добавление/удаление диска, баланс
btrfs может похвастаться прекрасным функционалом — возможностью «на горячую» добавить блочные устройства непосредственно в процессе работы файловой системы:
btrfs device add /path/to/device /path/to/btrfsИли удалить:
btrfs device remove /path/to/device /path/to/btrfsКстати, в одном вызове добавления/удаления можно указать несколько дисков.
Опять же, указываемый путь — это путь до любого сабвольюма той btrfs, к которой будет применена команда.
Проверим, сколько и какие блочные устройства находятся под управлением btrfs:
btrfs filesystem show /path/to/btrfs
Label: none uuid: 52961dda-df84-4e2d-9727-e93e7738df81
Total devices 2 FS bytes used 192.00KiB
devid 1 size 20.00GiB used 132.00MiB path /dev/sdc
devid 2 size 50.00GiB used 0.00B path /dev/sdd
0.00B в поле used нам сообщает о том, что добавленный диск пуст. Для наполнения его данными согласно профилю записи необходимо выполнить баланс:
btrfs balance start /path/to/btrfsКоманда balance перераспределяет данные на дисках согласно выбранному профилю записи. Например, в случае RAID1 баланс приведет к клонированию данных с первоначального устройства, в случае RAID0 — к более равномерному распределению данных по двум дискам, и т.д.
В результате баланса, если до этого на диске присутствовали пустоты, то данные на диске будут записаны более плотным образом, т.е. получится дефрагментация. Однако важно понимать, что это не совсем «та» дефрагментация. В данном случае команда balance не смотрит на логическое содержимое, а оперирует лишь блоками данных. Она не обращает внимание на то, что какой-либо файл размазан по диску. Вместо этого balance переносит блоки данных из одного места в другое. Т.е. файл, фрагментированный до баланса, останется фрагментированным и после него. Но! Фрагментированность на уровне блоков данных все же уменьшится, и этим можно пользоваться.
Для избежания путаницы скажем так: операция balance уменьшает фрагментированность на уровне блоков данных, но не влияет на фрагментированность файлов.
Также команда balance предоставляет возможность сменить профиль записи. Например, на диске использовался профиль DUP, а после добавления диска решили сделать полноценный RAID1. Для этого необходимо воспользоваться фильтром
convert:btrfs balance start -dconvert=raid1 -mconvert=raid1 /path/to/btrfsПри помощи опций
-dconvert и -mconvert задаются новые профили записи для данных и метаданных соответственно. Существует также опция -sconvert, которая предназначена для смены профиля записи системных данных, однако с ней придется еще дописать ключик -f (--force) для принудительного выполнения операции.Вообще, основное назначение фильтров — это задание правил для операции balance: какие блоки обработать, а какие не трогать. Так, например, можно затронуть только блоки, записываемые с определенным профилем записи (фильтр profiles), или блоки занятые выше определенного процента (фильтр usage), либо затронуть только группы блоков, имеющих отношение к определенному диску (фильтр devid) и т.п. Кстати, их еще можно комбинировать. В целом возможности фильтров очень обширны и в основном необходимы для проведения выборочного баланса данных.
Фрагментация
К сожалению, btrfs «благодаря» своей архитектуре крайне подвержена такому явлению, как фрагментация. Дело в том, что данные записываются всегда в новое расположение на диске. Даже если прочитать файл, ничего не сделать с данными и записать их обратно в тот же файл, то данные попадут на диске в новую область. То же самое произойдет, если обновить данные в файле только частично — изменения запишутся в новую область на диске. Таким образом, частые изменения весьма сильно фрагментируют файлы, увеличивая «разбросанность» фрагментов, в общем случае — по нескольким дискам. Это приводит к увеличенной нагрузке на CPU и неоправданному расходу памяти. Сильнее всего фрагментированности подвержены базы данных и образы виртуальных машин.
Оценить фрагментированность файлов можно при помощи утилиты filefrag (не входит в btrfs-progs).
filefrag /path/to/your/fileОна показывает количество экстентов, задействованных для хранения файла. Проще говоря — чем меньше экстентов задействовано, тем меньше фрагментированность файла.
Для борьбы с фрагментацией на btrfs существует два метода: дефрагментация и флаг
nocow.Дефрагментацию можно применять к отдельному файлу либо к сабвольюму/директории, в т. ч. рекурсивно. Команда выглядит следующим образом:
btrfs filesystem defragment /path/to/file/or/dirНадо сказать, что не всегда эта команда приводит к ожидаемым результатам. Небольшие несильно фрагментированные файлы (10 — 20 экстентов) после дефрагментации могут оказаться разбиты на еще большее число частей. К тому же на некоторых версиях ядра дефрагментация btrfs приводит к поломке дедуплицированности файлов, производя их реальные физические копии. Т.е. снапшоты на физическом уровне станут полноценными копиями.
Второй способ борьбы с фрагментированностью — это атрибут файла
nocow.chattr +C /path/to/fileАтрибут
nocow можно выставить только новому или пустому файлу. Он отключает механизм copy on write, благодаря чему btrfs при обновлении содержимого файла будет всегда работать с фиксированной дисковой областью, записывая данные поверх существующих (на физическом уровне). Из минусов nocow — он отключает еще и проверку чексуммы для данного файла. Другими словами, нет cow — нету и checksum.Разумеется, вручную выставлять атрибут
nocow каждому файлу — это дело неблагодарное. Если выставить этот флаг директории/сабвольюму, то все новые файлы, созданные в нем, унаследуют флаг автоматически. Это же касается и создаваемых вложенных директорий. Если же на момент включения атрибута в директории уже находились какие-либо данные, то на них это никак не повлияет — атрибут nocow можно выставить только новому или пустому файлу.И еще один способ автоматического выставления флага
nocow — это монтирование файловой системы с указанием опции nodatacow:mount -o subvol=path/to/subvol,nodatacow /dev/sdXX /path/to/mountpointДанная опция вызовет автоматическое подключение опции
nodatasum, так что для новых создаваемых файлов чексуммы вычисляться не будут.Как обычно, есть нюанс: нельзя подмонтировать только один сабвольюм с опцией
nocow. Либо все сабвольюмы будут иметь опцию nocow, либо ни один. Все решает первый подмонтированный сабвольюм: если у него была указана опция nodatacow, то и все последующие монтирования пройдут с этой опцией автоматически.Неочевидный момент возникает, если выставить файлу флаг
nocow и снять снапшот с сабвольюма, в котором этот файл расположен. В этом случае btrfs игнорирует флаг nocow, если на обновляемый блок данных ссылается более одного сабвольюма. Поэтому, несмотря на флаг nocow (кстати, файл в снапшоте его также унаследует), изменения любого из файлов будут попадать на диске в новую область, и файл снова станет фрагментированным. Если же блок данных в файле обновить несколько раз, то первый раз он попадет в новую область на диске, а при последующих записях будет обновляться в этой новой области «на месте».Трюки и фейлы
При использовании btrfs-progs можно не писать полное название команды:
btrfs sub cre = btrfs subvolume create Достаточно лишь совпадения первых символов, которые однозначно определят команду:
su = subvolume,
fi = filesystem,
ba = balance,
de = device;
думаю, принцип понятен.
Создать снапшот директории, увы, btrfs не под силу, но есть обходной путь:
- создайте сабвольум
btrfs subvolume create ./subvol - скопируйте файлы из директории в сабвольум:
cp -ax --reflink=always your/dir/. ./subvol
с ключомreflink=alwaysбудет задействован механизм CoW, т.е. данные не будут скопированы, но будут созданы ссылки на них на низком уровне btrfs. - Теперь сабвольюм содержит все файлы, которые были в директории, и можно снять с него снапшот.
Выставить атрибут
nocow существующему файлу с данными нельзя. Однако можно пойти следующим путем:- создать пустой файл
touch nocowfile - выставить ему флаг
nocow - выделить место на диске под новый файл
fallocate -l10g nocowfile - скопировать содержимое существующего файла в
cp -v oldcowfile nocowfile
Если на btrfs закончилось место, то даже удаление какого-либо файла может вызывать ошибку «No space left on device». Для решения рекомендуется подключить к btrfs временный накопитель размерами желательно не менее 1GB. После чего произвести чистку данных. Затем удалить временный накопитель.
Операция balance, вызванная без указания профилей записи, неявно меняет их с dup на raid1. О чем, кстати, написано на странице Gotchas. Происходит это после добавления диска к btrfs, на которой используется профиль записи dup. Напомню, что форматирование одиночного диска в btrfs использует профиль dup по умолчанию для метаданных и системных данных.
Пожалуй, самое важное
Избегайте создания низкоуровневых клонов блочных устройств с btrfs. Будучи «умной» файловой системой, при некоторых операциях (чаще всего, при монтировании) btrfs самостоятельно перечитывает системные данные на блочных устройствах, чтобы найти все части файловой системы. Если в процессе поиска будет обнаружено два блочных устройства с одинаковыми UUID, то btrfs воспримет их как части одного и того же инстанса. Если же при этом эти два устройства окажутся оригиналом и его клоном, то после монтирования одному только драйверу известно, как будет происходить работа файловой системы, но ясно, что ничем хорошим это не закончится. В худшем случае — закончится необратимым повреждением данных.
Если же очень хочется клонировать диски с btrfs низкоуровневым способом, то необходимо соблюдать крайнюю осторожность. В общем случае клон не должен быть виден ядру ОС как блочное устройство, пока в системе присутствует оригинал, и наоборот. Обеспечив это условие, можно изменить UUID клона (ну или оригинала, тут по желанию). В этом поможет утилита btrfstune, которая поставляется вместе с пакетом btrfs-progs:
btrfstune -u /path/to/deviceИ снова: btrfstune, будучи «умной» утилитой, будет изменять UUID не только на диске, а на всей файловой системе. Это значит, что при вызове она пойдет читать все блочные устройства, дабы заменить UUID на всех устройствах, относящихся к файловой системе.
Вместо заключения
Если на данном моменте вы ничего не поняли — это нормально. Btrfs нетривиальна и сразу может не поддаться. Каждый раз, когда мне казалось, что вот теперь-то я её понял, она подкидывала сюрприз и заставляла переосмысливать существующие вещи. Не могу сказать, что я все понял и на текущий момент — в процессе написания находил что-то новое, хотя и писал уже на основе имеющегося опыта.
Я бы сравнил процесс освоения btrfs с переходом от процедурного стиля программирования к объектно-ориентированному. Первое впечатление — «вау как круто», но затем упорно продолжаешь писать процедурный код, обернутый в классы.
В статье я старался не лить воду — писать все по делу. Не смотря на это, получилось довольно объемно. Но рассказать удалось далеко не все — про btrfs можно еще писать и писать. Эта статья — лишь верхушка айсберга. Самое начало, чтобы понять её философию и начать использовать. А сейчас на этом пора заканчивать.
Спасибо, что дочитали до конца. Надеюсь, не утомил. Пишите в комментариях, о чем Вам еще бы было интересно узнать.
Делайте бэкапы, господа. И пусть они вам никогда не пригодятся.
Комментарии (41)

DSolodukhin
24.07.2019 10:55+1Совсем недавно она перешла из статуса «еще не пригодно» в статус «стабильна».
Скорее из статуса «еще не пригодно» в статус «уже не пригодно». RH задепрекейтила Btrfs и обещает совсем дропнуть в будущем.frickelangelo Автор
24.07.2019 12:01На замену btrfs RH пообещала пользователям выпустить аналог под названием Stratis, позаимствовав многие концепты у btrfs и zfs. Отлично же — будут аналоги, будет конкуренция, будет развитие. Может, это и подтолкнет btrfs к качественному скачку в стабильности.
DSolodukhin
24.07.2019 12:25Может, это и подтолкнет btrfs к качественному скачку в стабильности.
Сомнительно, разработчики уйдут, пользовательская база станет меньше, с чего вдруг должен возникнуть этот скачок. Если за предыдущие годы, пока была поддержка со стороны RH, и в Suse тоже как дефолтная система использовалась, так и не довели до ума, то теперь шансов еще меньше.
Что касается Stratis, посмотрим, конечно, что из этого получится. Но всё таки это не новая ФС, это по факту dev-mapper + XFS.
demfloro
24.07.2019 15:19Red Hat её особо и не разрабатывала последние годы, Её активно разрабатывает SUSE как минимум с 2014-го.
git shortlog -sne -- fs/btrfs/929 Chris Mason <chris.mason@oracle.com>
655 David Sterba <dsterba@suse.com>
394 Linus Torvalds <torvalds@linux-foundation.org>
392 Nikolay Borisov <nborisov@suse.com>
357 Filipe Manana <fdmanana@suse.com>
312 Liu Bo <bo.li.liu@oracle.com>
312 Miao Xie <miaox@cn.fujitsu.com>
303 Josef Bacik <josef@redhat.com>
265 Josef Bacik <jbacik@fusionio.com>
208 Anand Jain <anand.jain@oracle.com>
205 David Sterba <dsterba@suse.cz>
155 Qu Wenruo <wqu@suse.com>
147 Jeff Mahoney <jeffm@suse.com>
147 Qu Wenruo <quwenruo@cn.fujitsu.com>
142 Josef Bacik <jbacik@fb.com>
128 Al Viro <viro@zeniv.linux.org.uk>
113 Chris Mason <clm@fb.com>
105 Stefan Behrens <sbehrens@giantdisaster.de>
delphersf
24.07.2019 11:17А что сейчас в тренде из стабильного и с разными возможностями, раз уж BTRFS не стабильная?
frickelangelo Автор
24.07.2019 13:02Под данные критерии подходит ZFS. На хабре про неё есть неплохие вводные статьи.

divanikus
24.07.2019 14:06ZFS похоже что наилучший выбор сейчас. Набор функций примерно такой же, сама ФС проверена временем и стабильна. Есть правда и минусы:
— в отличие от BTRFS использование в контейнерах ограничено: нельзя внутри контейнера создать или удалить вложенный volume — в BTRFS можно;
— недавний конфликт с разработчиками ядра из-за несовместимой лицензии, из-за чего из ветки 5.х выпилили необходимые для ZFS функции, из-за чего производительность снизится. однако это проблему скорее всего обойдут, если не уже обошли, реализацией этих функций на стороне ZFS.kazenniy
25.07.2019 16:14

Prototik
24.07.2019 19:20+1Замечу, что если попытаться удалить сабвольюм средствами файлового менеджера или утилиты rm, то операция завершится с ошибкой operation not permitted (операция не разрешена).
Замечу, что начиная с какой-то там версии ядра это уже не так

aborouhin
24.07.2019 19:43+2BTRFS использую для личного бекапа (важной для меня части оного) уже 4 года. Около 2 Тб и более миллиона файлов. На разделе, зашифрованном LUKS. RAID на уровне ФС не использую, т.к. «внизу» аппаратный RAID-контроллер.
BTRFS выбрана прежде всего ради удобных снапшотов. Все файлы синхронизируются с различными облаками и нужна была версионность, чтобы при необходимости откатить нежелательные правки / случаи порчи данных, которые благодаря облачной синхронизации моментально расползаются на все машины. А ZFS на момент выбора не прокатывала из-за её аппетита к RAM.
Снапшоты делаются с помощью snapper. Раз в месяц запускается btrfs scrub, проверяющий те самые контрольные суммы, которые в статье упомянуты (а вот scrub почему-то нет). Это весомый дополнительный бонус, гарантия от случайного повреждения данных, каковое на таких объёмах весьма вероятно.
Поломал я её до состояния «всё снести и выкачать из облака заново» один раз, и то по своему собственному невежеству, т.к. в лоб запустил btrfsck, которую вообще запускать не надо. Потом почитал про то, как надо, и больше так не буду (в том случае надо было сделать btrfs-zero-log)
В общем, выбором доволен. Если бы выбирал с нуля — сейчас, когда на домашнем сервере уже 96 Гб RAM, а не 8 Гб, как было 4 года назад, может, выбрал бы и ZFS. Но повода менять уже настроенное и работающее решение не вижу.
Но да, у меня это как минимум третья, а для части данных и четвёртая копия, так что даже самый катастрофический сценарий к безвозвратной потере данных не приводит.pansa
25.07.2019 00:00Очень странно, 2 Тб это копейки и для ZFS достаточно 2-3Гб памяти. Главное не включать дедупликацию — это слишком неоднозначная и хитрая фича, которая стреляет позже. В принципе, при небольшом тюнинге 120Тб пулы вполне работают с 64Гб памяти в весьма нагруженном режиме. Правда, на фре…
aborouhin
25.07.2019 00:21Ну, видимо, ZFS on Linux 4-летней давности не отличалась подобной скромностью требований :)
myemuk
24.07.2019 21:49Если на btrfs закончилось место, то даже удаление какого-либо файла может вызывать ошибку «No space left on device». Для решения рекомендуется подключить к btrfs временный накопитель размерами желательно не менее 1GB. После чего произвести чистку данных. Затем удалить временный накопитель.
Как-то приходилось скачивать большие файлы, а потом их удалять. Первый раз, увидел такую картину, что половина диска свободна, а записать новый файл не могу — место закончилось. Трюк с подключением временного внешнего диска нашел не сразу, но он много раз спасал, когда я забывал вовремя балансировку запускать. Может сейчас получше с ней, но уже года 2 как ext4 обратно перешел.

gdt
25.07.2019 20:24Можно ли слово «subvolume» перевести как, например, подраздел?
frickelangelo Автор
25.07.2019 23:02Нет. Иначе придется объяснять почему подразделы не имеют ничего общего с разделами. То же самое если перевести как «подтом» — ничего общего с томами.
vvm13
После этого всё остальное в этой статье избыточно.
SystemXFiles
Аналогично подумал, когда прочитал этот абзац. Зачем рассказывать о ФС, которые способна необратимо потерять информацию из-за собственных багов. Может конечно это привлечет кого-нибудь для помощи в разработке, но с такой ситуацией пользоваться ей вообще желания нет.
frickelangelo Автор
Полагаю, что заверения о стабильности взялись не с потолка. Как минимум, проблемы возникают точно не в стандартных сценариях. В статье хотелось максимально честно отразить обе стороны btrfs. Возможно, стоило указать на минусы ближе к концу статьи — спасибо за фидбек, учтем в будущем. Теперь про спор на тему «надо ли ею пользоваться». Увы, но в общем случае он не разрешим — у каждого частного случая свои задачи и требования. Другое дело узнать что такая ФС, в принципе, существует и познакомиться с подходом в организации хранения и
распространенияуправления данными, думаю, многим интересно. Ну и хочу отметить что словами «зачем… если ...» можно похоронить любой молодой проект.katzen
Кто определяет стандартность сценария?
Если ФС теряет данные, то ФС нужно переделывать, а не использовать.
frickelangelo Автор
Чтобы не потерять данные делайте Veeam бэкапы.
SystemXFiles
Потеря данных так или иначе нештатная ситуация и потому всегда стоит уменьшать вероятность подобного исхода, в противном случае это прямая дорога в ад.
katzen
:-) Отличная шутка!
gbg
«Рубанули хост с виртуалками, после чего две навсегда ушли в аут» — это насколько «нестандартно»?
Пока утилита восстановления, извините, сегфолтится при попытке такое починить, Btrfs получает официальный бейдж БАРАХЛО-ФС.
frickelangelo Автор
Делайте бэкапы с помощью Veeam.
gbg
«Покупайте наших слонов! ©»
Спасибо, я как-то с rbd2qcow2 прекрасно справляюсь.
divanikus
Судя по официальной вики, наибольшие шансы потери данных в режимах raid56, они официально нестабильны. Остальное достаточно стабильно для production. Для raid56 я бы рекомендовал raidz/raidz2 в ZFS, личный опыт строго положительный.
frickelangelo Автор
Почему же избыточно? Как минимум есть те кому интересно узнать что в linux мире существует не только extfs и swap. Что есть иные подходы к организации данных на носителях.
Radjah
mdadm, lvm, вот это всё. А сверху хоть черта лысого в качестве ФС можно сделать.
ИМХО в данном случае не стоит валить всё в одну кучу.
frickelangelo Автор
Вот это самая большая проблема — объяснять btrfs людям, хорошо знакомым с lvm. Нету на btrfs томов. Есть subvolume. Это не блочное устройство и не может быть трактовано как оное. Сабвольум гораздо ближе к понятию директория, чем к lvm тому.
Radjah
Я про встроенные RAID.
frickelangelo Автор
Странно что вы адресуете это именно мне. Правильнее это высказывать разработчикам BTRFS, не находите?
Loxmatiymamont
По такому принципу все статьи про CEPH тоже избыточны. А их нынче развелось как-то подозительно не мало…
gbg
За 8 кластеро-лет ни разу не терял данные по причине багов в CEPH. Может, в консерватории что-то не так?
Loxmatiymamont
Это называется ошибка выжившего.
Kabdim
Второй год / живет на btrfs и как-то ни разу еще не сталкивался.
iborzenkov
У меня примерно пятый год на сервере диск со всеми данными и на домашнем корень, тоже нормально все, особенно с контейнерами хорошо, гораздо лучше чем стандартная.
pansa
У меня такая же нога и не болит.
katzen
Один пользователь — не статистика.
alexyr
Инкрементальные бекапы на другой носитель решают 99.999% таких проблем! А делаются они быстро и легко. Кто не делает бекапы, может потерять данные на любой системе. Для меня преимущества и удобство BTRFS перевешивают «возможные» потери данных. Восстановление из резервной копии тоже как два пальца! Я так даже устанавливал систему в виртуалке, настраивал всё что нужно и накатывал её простым переносом как резервную копию (с правкой fstab)