
Всем привет
Позвольте поделиться с вами небольшим лайфхаком, который я успешно применяю около пары лет — создание последовательных числовых кодов для текстовых сообщений в исходном коде в процессе непосредственного редактирования исходного кода в Visual Studio:

Об этой задаче я стал задумываться, когда в коде стало «образовываться» несколько десятков сообщений пользователю/обработчиков ошибок/исключений и стало невозможно мириться с тем, что при получении очередного сообщения в runtime стало уже трудно ориентироваться откуда оно появилось. Возникло стойкое желание пронумеровать все сообщения последовательными индексами, которые бы выводились в начале каждого сообщения, но чтобы эту последовательность можно было создать во время набора исходного кода только с помощью клавиатуры, на «лету» (on demand), чтобы не отвлекаться от процесса кодирования.

Делается это следующим образом:
- Создать enum для кодов ошибок.
- Специальный синтаксис кодов в enum: "_число". (вначале числа идёт подчёркивание, т.к. enum требует всё-таки символьных имён).
- «Оцифровыватель» формата "_число" в собственно число.
- Магия инкрементирования числового кода «на лету».
1,2:
/// "База данных" по кодам ошибок
public enum MCodes{
_000,
_001,
_002,
}
3: «Оцифровыватель» формата "_число" в собственно число
static class _MCodeExtensions{
/// mini formar error message - краткий формат представления ошибки.
public static string mfem(this MCodes mcode) {
//string str = $"{nameof(rcode)} = {rcode}, {nameof(mcode)} = {mcode}";
int val = Int32.Parse(mcode.ToString().Substring(1));
string str = $"{nameof(mcode)} = {val}";
return str;
}
}
4. Магия
Магия состоит в использовании возможностей IntelliSense для Visual Studio:
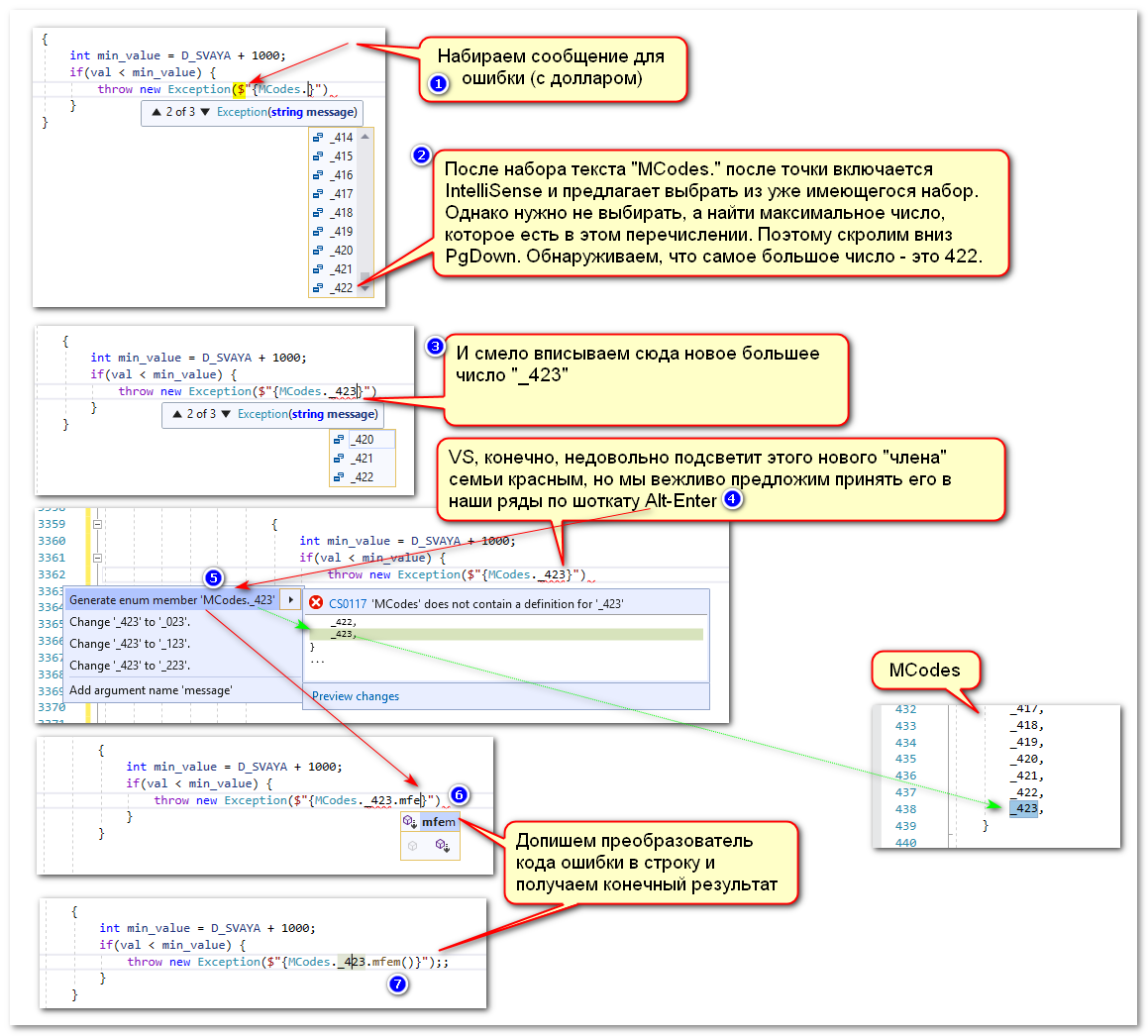
На самом деле эти действия выполняются достаточно быстро (замедленная съёмка):

Использование
«Обычно» числа с подчёркиванием достаточно редко используются в исходном коде, поэтому найти это число по Ctrl-F (поиск в текущем файле) или Ctrl-Shift-F (поиск во всём проекте) достаточно точно укажет на место ошибки.
(Конечно, можно открыть enum, найти код, нажать Shift-F12, но это из разряда правильный долгий путь...)
Недостатки
1. Если вы копируете куски кода со вставленными кодами ошибок, то, естественно, и коды ошибок будут уже не уникальными. Для борьбы с ними требуется периодически просматривать enum MCodes c проверкой, что какой-то код используется не больше одного раза
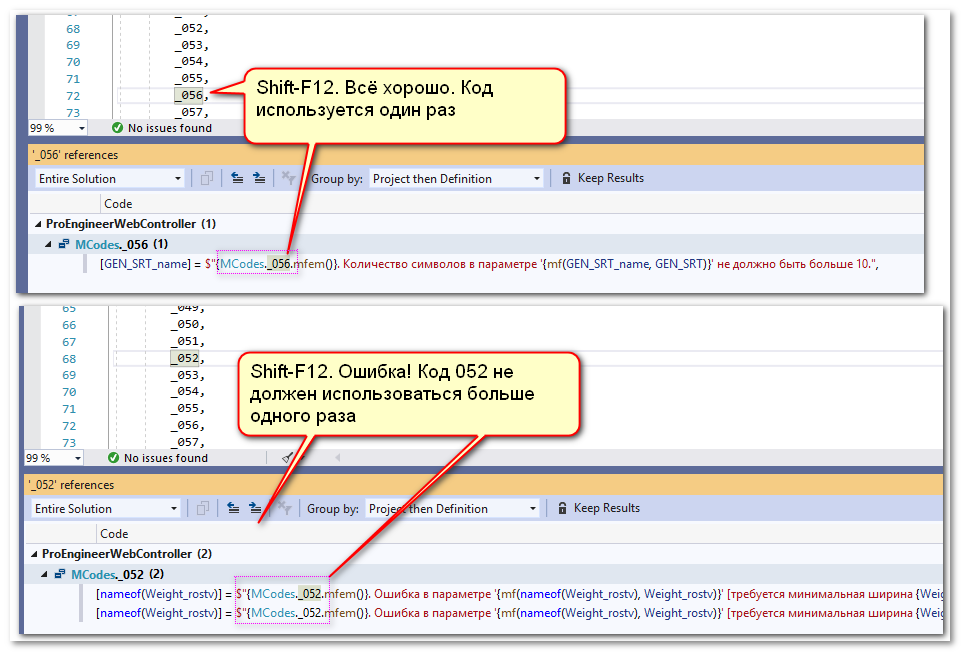
Очень помогают shortcat-ы F12 и Shift-F12.
2. Можно ошибиться в набираемом формате и написать не "_число", а что-то другое, не преобразуемое в число. Да, будет исключение.
Заключение
Нумерация сообщений, особенно об ошибках, иногда оказывает неоценимую услугу в отладке и поиске причин появления разных сообщений. Надеюсь, что этот способ поможет упростить эту задачу.
Кажется, что это минимум телодвижений?
P.S.
Это моё исключительно субъективное отношение к кодам ошибок, но вдруг и вам это чем-то поможет. Можно применять не только для инкрементации кодов ошибок, но и других последовательностей. Естественно, кастомизация решения на ваш вкус.
Причина использования формата числа в enum в виде "_число" в том, что за enum фактически скрывается int, а сам член enum нумеруется от начала последовательности (синтаксически его можно назначить, но автоматически через IntelliSense это не делается, а тратить на это времени совсем не хочется). А так же само значение этого члена зависит от местоположения. И если местоположение поменяется, то номер уже станет другим. Поэтому в коде везде игнорируется само значение.
Немного теории про Перечисления enum.
Комментарии (63)

Oxoron
26.07.2019 11:58Автоматизируй это, парень. С Roslyn проверяй, используется ли Message в исключении, и указывается ли в нем код. Если нет — показывай Warning, в предлагаемом фиксе добавляй значение к Enum, добавляй новое значение в Message. Тогда твои коды будут добавляться в Enum и конструктор исключения двумя клавишами: Ctrl+Enter, Enter.
Edge Case — когда сообщение генерируется не в конструкторе исключения, тут придется поработать.
Если будешь такое реализовывать\открывать — стучись, помогу.
AlexZaharow Автор
26.07.2019 12:17Cпасибо. Буду иметь в виду.
Можешь какой-нибудь скрин сделать? Я с Roslyn не работал.
Я бы вообще хотел разработать такой шаблон кода, который бы мне сразу генерировал следующий номер, а не я его «выдумывал». Вообще был бы крутяк. Сейчас чуть глянул — может действительно Roslyn может решить эту задачу?
a-tk
26.07.2019 12:52+1Почему бы сразу не мелочиться и не использовать GUID-ы в качестве кода ошибок? Практически гарантированная уникальность, простота генерации (Tools — Create GUID), никаких коллизий в ветках.

lair
26.07.2019 13:06+1простота генерации (Tools — Create GUID)
В решарпере сниппет есть, не выходя из кода вообще.
lair
Не очень понятно, какую задачу вы решаете, и зачем вам для этого числовые коды. Чтобы "ориентироваться, откуда сообщение появилось" есть call stack и caller information. Для всего остального есть структурное логирование.
AlexZaharow Автор
Зато теперь очень просто общаться с пользователями:
— Назовите код сообщения?
— 172.
— Ок. Причина в следующем…
И я как разработчик точно знаю по коду, что случилось, чем пытаться в коде найти текст, который пользователь мне диктует, да ещё и по памяти. А ведь тексты сообщений бывают и одинаковые.
Я предпочитаю ставить обращение ко мне пользователей на «числовые» рельсы, чтобы было минимум субъективности. Да и пользователь, когда видит код сообщения, то у него больше уверенности, что это сообщение имеет чёткое объяснение и он его в 99% случаев точно получит.
Это моё субъективное отношение. Я ведь не против остальных методов.
Однако считаю, что начать текст сообщение надо с чего-то конкретного. Я предлагаю начать сообщение с конкретного числа, а не с фантазии программиста. И описанным методом сгенерировать такое число, надеюсь, будет очень просто.
lair
Нет, это если речь о любой записи.
Если вы можете по числу сказать, в чем причина ошибки, просто сразу выведите эту причину ошибки пользователю, избавьте его от необходимости с вами общаться.
И обратите внимание, это не та же задача, что в начале. Я об этом и говорю: какую задачу вы пытаетесь решить?
Ровно с той же вероятностью, с которой бывают одинаковые числовые коды.
Зачем? Это вопрос, с которого я начал, и я считаю его очень важным: зачем надо начинать текст сообщения "с чего-то конкретного"?
… а еще эти коды можно генерить полностью автоматически во время сборки приложения.
Oxoron
Можно добавлять в код номер сборки, но там свои заморочки.
lair
А это зависит от модели развертывания в первую очередь.
Да нет, достаточно любой разговор с пользователем начинать с фразы "назовите точную версию из About".
Oxoron
Это если у приложения есть About. Это дополнительная нагрузка на (вероятно) технически неграмотного юзера. Это необходимость разработчику открыть релиз систему -> найти версию кода по версии билда -> каким-то образом найти сообщение, которое получило наш код. Муторно это.
lair
А если не сообщать версию, то разработчик по номеру отдаст ответ не по той версии, и он не подойдет.
AlexZaharow Автор
Во-первых, с чего вдруг смысл сообщения меняется от номера версии приложения. Очень плохо.
Во-вторых. Ответ может не подойти даже если вы говорите об одной и той же версии. Неужели тупик?
Oxoron
lair говорит правильные вещи (в контексте данной ветки).
AlexZaharow Автор
Лично мне совсем не очевидна эта проблема. Может вам немного развернуть ответ? Лично я на первый взгляд считаю, что автогенерация кодов сообщений сама по себе плохая идея, но, возможно, что я понимаю её в другом контексте, чем вы. Вы не уточните?
Oxoron
Представь себе проект, условный Web API. 10 контроллеров, 20 сервисов, 30 репозиториев. Всего 100 исключений на проект. Запустили мы релиз 1.0, все исключения во время билда получили свой номер. То есть, в кодовой базе эти номера не отразились.
Приходит клиент, хочет фичу. Мы ввели новый контроллер, сервис, перименовали один из старых. Билдим релиз 2.0. Нумерация исключений поменялась. Если раньше исключение в ImportantController имело номер 32, сейчас оно имеет номер 43.
Я не смог придумать алгоритм, по которому одному исключению будет присваиваться один номер в разных версиях. Имена файла\класса\методы изменятся во время рефакторинга. Номер строки тоже.
Какие выходы? Либо зашивать в апп номер версии (через конфиг или константу) и вставлять его в сообщения, либо зашивать коды в VCS. Номер версии автоматический, не сильно упрощает гуглеж кодов, удлиняет коды, может быть полезен при логах. Зашивка кода в VCS тоже может породить конфликты при слияниях, автоматизируется при желании, придется продумывать вопросы вроде «что делать, если мы немного изменили сообщение?».
AlexZaharow Автор
Я не очень понял в чём тогда логика? Вот прямо сейчас я ищу ошибки так:
Попробую предложить начальное административное решение, что перед началом работы каждому участвующему сотруднику выделить диапазон кодов — тебе 0-1000, тебе 1001-2000 и т.д. Поверьте, тыщу кодов можно дооолго «расходовать». Я полтора года пишу одну программу и у меня дошло до 480. Кончился диапазон — вот тебе новый. Понятно, что не панацея, вон у микрософта какие коды. Но мы ведь не windows пишем.))) Хотя от этого утверждения качество не должно быть на последнем месте.Если код сообщения меняется во время билда, то как мне искать причину в исходниках, если указанная мной цепочка разорвана?
Oxoron
Вопрос: если оно спорное, почему о нем зашла речь?
Представьте себе, у вас есть ошибка: "_267 Не могу удалить документ 12345". На следующий релиз она превращается в "_267 Не могу удалить документ {documentId}". Затем вы добавляете "_267 Не могу удалить документ {documentId}. Причина: {reason}." Через полгода кто-то добавляет "_267 Модуль {module} не может удалить документ {documentId}. Причина: {reason}."
Еще через два года кто-то пытается решить баг и видит сообщение "_267 Не могу удалить документ 12345". Открывает IDE, ищет код _267, и удивляется: ни слова о модуле, никаких данных о причине.
Или сценарий: открывает ваш коллега IDE, ищет _267 — а такого кода нет. Удалили его, после миграции на новый движок.
Автокоды с зашивкой версии такие сценарии покрывают. Но ручная вставка кодов с настройкой логера (чтоб логер версии сам вставлял) будет проще.
AlexZaharow Автор
Нет цели экономить коды. Пишите новые. Поменяли сообщение — берите новый код.(если считаете, что действительно смысл сообщения поменялся).
А вот добавить номер версии не проблема — я предлагал кастомизировать функцию mfem() на свой вкус. Это также означало, что в неё можно зашить и номер версии.
Oxoron
Кажется, вы слегка изменили свою позицию, пока писали ответ. Я позволю себе продолжить: «для анализа вообще багов неважно, как часто вы ренумеруете коды, если ваш код привязан к номеру коммита». Можете заводить новый код хоть в каждом коммите — главное, чего вы добиваетесь:
Но это верно только для анализа багов. Для других участников вашей команды больше кодов — больше проблем.
Получается цепочка:
AlexZaharow Автор
Вполне может быть, что нумерация ошибок в таком виде хорошо годится для одномодульного приложения, которую пишет один программист и вне этого кейса уже требуется доработка такого подхода. Кроме того предложенный способ внедрения кода сообщения не годится для автоматической обработки исключений. Там нужен другой подход. Да, нужно приложить усилия, чтобы адаптировать такой подход. Но хотя бы есть какой-то элементарный бесплатный способ сквозной нумерации, который не требует каких-то внешних библиотек и сред для несложной утилиты или сервиса, микросервиса. Вот когда потребуется что-то более сложное — ок. Тогда объективно инструмент не подходит и вы берёте что-то тяжеловеснее.
lair
С того, что логика приложения меняется.
Oxoron
Можно «зашить» версию в код ошибки. Будет код ошибки вроде "${code}~~~{version}###{message}", где code=$"{fileNumber}.{line}". Тогда не нужны About, нет нагрузки на юзера, можно автоматизировать открытие нужного файла по коду ошибки, можно зашить стек как цепочку кодов. Только вот кто даст времени\денег на такое удовольствие?
lair
Возьмите уже структурное логирование.
Тот же человек, которому нужно сокращение расходов на поддержку. Если такого нет, то и с кодами можно не заморачиваться.
Oxoron
Разумно.
У вас больше опыта работы с большими проектами. Оцените примерно затраты на код\тестирование\согласование для 2 вариантов: авторского и с автогенерацией кодов (пускай даже Guid-ов).
lair
В моем опыте авторский вариант не пройдет согласование, именно потому, что польза от него не очевидна.
AlexZaharow Автор
А с чего вы советуете начать?
«Критикуешь — предлагай», помните такой принцип?
lair
Я, для начала, возражаю, что это "неотъемлемое право".
Я советую начать с конкретной формулировки задачи, которую вы решаете. Я, собственно, с этого начал свой первый комментарий, и так и не получил ответа до сих пор.
AlexZaharow Автор
Вы точно уверены, что не понимаете задачу?
lair
Где и кем оно зафиксировано?
Да, совершенно.
AlexZaharow Автор
Тут как в ресторане — лучше пусть пользователь расскажет вам, что у него есть вопрос, чем расскажет своим знакомым, какая у вас плохая программа. Маркетинг, рынок и всё такое. Хотите, чтобы вашу программу покупали — не нарушайте права пользователей на получение ответов на их вопросы. Да, бывают, скажем так, альтернативные пользователи, которые хотят иногда странного. Но они бывают везде. И поэтому для достижения результата с максимальной скоростью нужны цыфры. Так проще.
Ok. А какую проблему c вашей точки зрения я решаю? Давайте начнём с того, что вы поняли из того, что прочитали?
lair
Это не право. Это возможность, которую разработчик решил предоставить своим пользователям (или решил не предоставлять). И если решил предоставлять — то на тех условиях, на которых он счел нужным.
Понятия не имею.
Я об этом уже писал в первом комментарии. Вы пишете: "при получении очередного сообщения в runtime стало уже трудно ориентироваться откуда оно появилось". Для этой проблемы (в C#) есть типовые решения, которые вы игнорируете.
AlexZaharow Автор
Простите, а как вы умудрились в одном ответе дать два противоречивых утверждения? Вы утверждаете, что понятия не имеете о решаемой мною задачи:
и тут же даёте совет: Но если вы не имеете понятия о задаче, то как вы можете утверждать что для неё есть типовые решения?lair
Это два разных ответа, вообще-то.
Это первый, на вопрос "А какую проблему c вашей точки зрения я решаю?"
А это — второй, на вопрос "что вы поняли из того, что прочитали?"
AlexZaharow Автор
Я знаю что я написал. Вы не ответили на вопрос, что вы поняли из того что прочитали. Вы просто скопировали текст. Это совершенно не объясняет того, что вы поняли.
lair
Отнюдь. Я вполне ответил на этот вопрос. Если вы чего-то из моего ответа не понимаете...
AlexZaharow Автор
Я так понимаю, что вы не решаете задачи, а просто выражаете своё мнение, что вам что-то непонятно. У вас есть право озвучить, что вам что-то непонятно. Однако. Неправильно рассчитывать на то, что если вы сами не будете прикладывать усилий, чтобы понять, то ожидать, что по какой-то причине другой человек вам обязан что-то разжёвывать и доказывать — это ваше личное, глубокое заблуждение.
Лёгкий троллинг иногда приемлем, но не надо выходить за рамки приличия.
Вам же нечего сказать по делу? Не так ли? Если есть, то будьте любезны находиться в рамках технического обсуждения, а не переходить на личности.
lair
Вы понимаете неправильно. Я как раз обычно решаю задачи, просто прежде чем их решать, я уточняю, какую же задачу надо решить.
Ровно наоборот. Мне вполне есть, что сказать "по делу", и я даже уже сказал приличную часть из этого.
Техническое обсуждение начинается с постановки задачи. Я уже несколько раз сказал, что решаемая вами задача не озвучена, но вы так и продолжаете обсуждать решение (неизвестно чего).
AlexZaharow Автор
Чёткой постановки задачи не было. Но это не значит, что нет задачи. Так понятнее?
lair
Это неудивительно.
Но это может значить, что решали не ту задачу, которую нужно.
dopusteam
С этого бы и начали, что постановки задачи на было, к чему весь этот цирк на n комментариев?
lair
А я с этого и начал в самом первом комментарии: "Не очень понятно, какую задачу вы решаете". И потом еще раз повторил: "Я советую начать с конкретной формулировки задачи, которую вы решаете".
dopusteam
Мой комментарий автору предназначался, видимо в мобильной версии промахнулся)
AlexZaharow Автор
Как автор статьи я должен с уважением относиться ко всем пользователей, которые обратились с вопросом. И хотя бы быть вежливым. Всё-таки я давал обещание хабру в этом. )))
mayorovp
Локализация. Одно и то же сообщение может читаться пользователем, сисадмином и программистом — и все трое могут говорить на трех разных языках.
Плюс коды ошибок проще гуглить. Вот всю прошлую неделю я пытался починить Sharepoint — и по русскоязычным сообщениям об ошибках я не мог найти ничего вразумительного. Под конец я даже, к стыду своему, начал переходить по ссылкам на qaru от отчаянья...
lair
О, вот это реально хороший пойнт. Но он, как уже говорилось, прекрасно решается без человеческого участия, автогенерацией кодов при сборке приложения.
(впрочем, въедливости ради: этот пойнт опирается на подразумеваемую, но не зафиксированную ситуацию, при которой у нас информация поступает от пользователя, а не… другими, более эффективными способами)
mayorovp
Неа, автогенерация — плохая идея, ведь надо поддерживать согласованность кодов в разных версиях программы.
lair
А вот это как раз предположение, что (а) согласованность поддерживать надо и (б) нет другого идентификатора, по которому можно поддерживать согласованность (девелоперского сообщения об ошибке, например). Эти предположения могут быть верными, но не всегда, и если они включены в задачу, их надо явно озвучивать.
mayorovp
Конечно же согласованность поддерживать надо. Когда одно и то же сообщение имеет номер E123 в одной версии программы, и номер E152 в другой — по этому номеру больше нельзя найти ничего полезного.
Девелоперское сообщение об ошибке — это, конечно же, хорошо — вот только оно ни никак не помогает сгенерировать стабильный номер при сборке из исходников с нуля.
lair
Ну то есть теперь нас еще и волнует возможность гуглить ошибки?
Но ладно, допустим. Что делать, если некое сообщение об ошибке потеряло актуальность? Никогда больше не использовать этот код?
Отнюдь. Если девелоперские сообщения стабильны, то есть больше одного способа сделать из них коды при сборке исходников.
mayorovp
Не теперь, а с самого начала. Перечитайте моё сообщение, с которого началась эта ветка.
Да, это будет правильным решением.
Например? Я вижу только один способ: хеширование. Но это мне кажется так себе затеей.
lair
Я имею в виду, что это еще одно неявное требование, которое нуждается в фиксации.
Интересно, как это гарантировать. Безотносительно способа генерации кодов, я имею в виду.
Например, сборка их в отдельный список, порядковые номера из которого использовать как коды.
Почему?
mayorovp
А как избежать вставки очередного сообщения в середину списка?
Потому что код сообщения теперь нельзя найти в исходниках. А ещё код сообщения теперь меняется от незначительных правок, вроде исправления опечатки. А ещё коллизии.
lair
Использованием списка от прошлого билда.
Это зависит от процесса сборки, а не от того, как генерить код. Иными словами, эта проблема будет (или не будет) всегда, когда код сообщения генерится автоматически, а не задается разработчиком явно.
Я же начал с того, что чтобы это работало, сообщения должны быть стабильны. Если они не стабильны, работать не будет.
mayorovp
Ага, вот уже билды перестали быть воспроизводимыми.
Именно так и есть.
lair
Зависит от того, как вы храните список от прошлого билда.
… и это осознанный выбор между удобством в одном месте и удобством в другом.
vitesse
Согласен с lair, но добавил бы ещё, что можно использовать разные типы exceptions (как стандартные, так и свои) для разных мест в коде, чтоб потом «ориентироваться откуда оно появилось». И вообще решение автора смотрится достаточно громоздко, запутанно, в команде из нескольких человек — будет вызывать конфликты.
AlexZaharow Автор
А если не использовать такого подхода, то конфликтов не будет? Это выходит за рамки технических решений. Но ведь чтобы конфликтов не было к ним нужно готовиться, а не применять разные методики без проверки на удобство или граничные условия.